JavaScript字串常見基礎方法精講

【相關推薦:、】
不論在何種程式語言中,字串都是重要的資料型別,跟隨我瞭解更多JavaScript字串知識吧!
前言
字串就是由字元組成的串,如果學習過C、Java就應該知道,字元本身也可以獨立成為一個型別。但是,JavaScript沒有單個的字元型別,只有長度為1的字串。
JavaScript的字串採用固定的UTF-16編碼,不論我們編寫程式時採用何種編碼,都不會影響。
寫法
字串有三種寫法:單引號、雙引號、反引號。
let single = 'abcdefg';//單引號let double = "asdfghj";//雙引號let backti = `zxcvbnm`;//反引號
單、雙引號具有相同的地位,我們不做區分。
字串格式化
反引號允許我們使用${...}優雅的格式化字串,取代使用字串加運算。
let str = `I'm ${Math.round(18.5)} years old.`;console.log(str);程式碼執行結果:

多行字串
反引號還可以允許字串跨行,當我們編寫多行字串的時候非常有用。
let ques = `Is the author handsome? A. Very handsome; B. So handsome; C. Super handsome;`;console.log(ques);
程式碼執行結果:
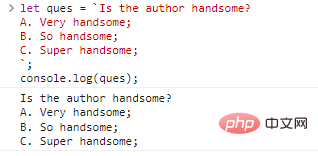
是不是看起來覺得也沒有什麼?但是使用單雙引號是不能實現的,如果想要得到同樣的結果可以這麼寫:
let ques = 'Is the author handsome?\nA. Very handsome;\nB. So handsome;\nC. Super handsome;';console.log(ques);
以上程式碼包含了一個特殊字元\n,它是我們程式設計過程中最常見的特殊字元了。
特殊字元
字元\n又名"換行符",支援單雙引號輸出多行字串。當引擎輸出字串時,若遇到\n,就會另換一行繼續輸出,從而實現多行字串。
雖然\n看起來是兩個字元,但是隻佔用一個字元位置,這是因為\在字串中是跳脫符,被跳脫符修飾的字元就變成了特殊字元。
特殊字元列表
| 特殊字元 | 描述 |
|---|---|
\n | 換行符,用於新起一行輸出文字。 |
\r | 回車符,將遊標移到行首,在Windows系統中使用\r\n表示一個換行,意思是遊標需要先到行首,然後再到下一行才可以換一個新的行。其他系統直接使用\n就可以了。 |
\' \" | 單雙引號,主要是因為單雙引號是特殊字元,我們想在字串中使用單雙字元就要跳脫。 |
\\ | 反斜槓,同樣因為\是特殊字元,如果我們就是想輸出\本身,就要對其跳脫。 |
\b \f \v | 退格、換頁、垂直標籤——已經不再使用。 |
\xXX | 編碼為XX的十六進位制Unicode字元,例如:\x7A表示z(z的十六進位制Unicode編碼為7A)。 |
\uXXXX | 編碼為XXXX的十六進位制Unicode字元,例如:\u00A9表示 © 。 |
\u{X...X}(1-6個十六進位制字元) | UTF-32編碼為X...X的Unicode符號。 |
舉個例子:
console.log('I\'m a student.');// \'console.log("\"I love U\"");// \"console.log("\\n is new line character.");// \nconsole.log('\u00A9')// ©console.log('\u{1F60D}');//程式碼執行結果:
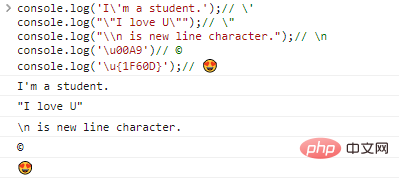
有了跳脫符\的存在,理論上我們可以輸出任何字元,只要找到它對應的編碼就可以了。
避免使用\'、\"
對於字串中的單雙引號,我們可以通過在單引號中使用雙引號、在雙引號中使用單引號,或者直接在反引號中使用單雙引號,就可以巧妙的避免使用跳脫符,例如:
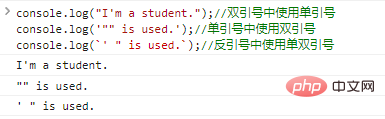
console.log("I'm a student.");
//雙引號中使用單引號console.log('"" is used.');
//單引號中使用雙引號console.log(`' " is used.`);
//反引號中使用單雙引號程式碼執行結果如下:
.length
通過字串的.length屬性,我們可以獲得字串的長度:
console.log("HelloWorld\n".length);//11這裡\n只佔用了一個字元。
《基礎型別的方法》章節我們探究了
JavaScript中的基礎型別為什麼會有屬性和方法,你還記得嗎?
存取字元、charAt()、for…of
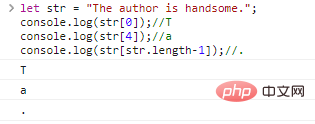
字串是字元組成的串,我們可以通過[字元下標]存取單個的字元,字元下標從0開始:
let str = "The author is handsome."; console.log(str[0]);//Tconsole.log(str[4]);//aconsole.log(str[str.length-1]);//.
程式碼執行結果:
我們還可以使用charAt(post)函數獲得字元:
let str = "The author is handsome.";console.log(str.charAt(0)); //Tconsole.log(str.charAt(4)); //aconsole.log(str.charAt(str.length-1));//.
二者執行效果完全相同,唯一的區別在於越界存取字元時:
let str = "01234";console.log(str[9]);//undefinedconsole.log(str.charAt(9));//""(空串)
我們還可以使用for ..of遍歷字串:
for(let c of '01234'){
console.log(c);}字串不可變
JavaScript中的字串一經定義就不可更改,舉個例子:
let str = "Const";str[0] = 'c' ;console.log(str);
程式碼執行結果:
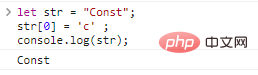
如果想獲得一個不一樣的字串,只能新建:
let str = "Const";str = str.replace('C','c');console.log(str);看起來我們似乎改變了字串,實際上原來的字串並沒有被改變,我們得到的是replace方法返回的新字串。
.toLowerCase()、.toUpperCase()
轉換字串大小寫,或者轉換字串中單個字元的大小寫。
這兩個字串的方法比較簡單,舉例帶過:
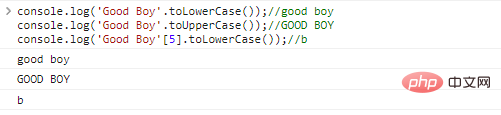
console.log('Good Boy'.toLowerCase());//good
boyconsole.log('Good Boy'.toUpperCase());//GOOD
BOYconsole.log('Good Boy'[5].toLowerCase());//b程式碼執行結果:
.indexOf()、.lastIndexOf() 查詢子串
.indexOf(substr,idx)函數從字串的idx位置開始,查詢子串substr的位置,成功返回子串首字元下標,失敗返回-1。
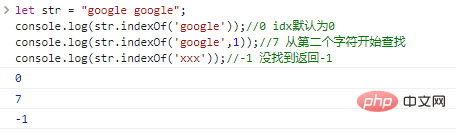
let str = "google google";console.log(str.indexOf('google'));
//0 idx預設為0console.log(str.indexOf('google',1));
//7 從第二個字元開始查詢console.log(str.indexOf('xxx'));
//-1 沒找到返回-1程式碼執行結果:
如果我們想查詢字串中所有子串位置,可以使用迴圈:
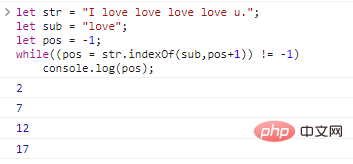
let str = "I love love love love u.";let sub = "love";let pos = -1;while((pos = str.indexOf(sub,pos+1)) != -1)
console.log(pos);程式碼執行結果如下:
.lastIndexOf(substr,idx)倒著查詢子串,首先查詢最後一個符合的串:
let str = "google google";console.log(str.lastIndexOf('google'));//7 idx預設為0按位元取反技巧(不推薦,但要會)
由於indexOf()和lastIndexOf()方法在查詢不成功的時候會返回-1,而~-1 === 0。也就是說只有在查詢結果不為-1的情況下使用~才為真,所以我們可以:
let str = "google google";if(~indexOf('google',str)){
...}通常情況下,我們不推薦在不能明顯體現語法特性的地方使用一個語法,這會在可讀性上產生影響。好在以上程式碼只出現在舊版本的程式碼中,這裡提到就是為了大家在閱讀舊程式碼的時候不會產生困惑。
補充:
~是按位元取反運運算元,例如:十進位制的數位2的二進位制形式為0010,~2的二進位制形式就是1101(二補數),也就是-3。簡單的理解方式,
~n等價於-(n+1),例如:~2 === -(2+1) === -3
.includes()、.startsWith()、.endsWith()
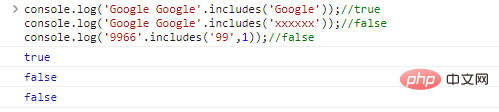
.includes(substr,idx)用於判斷substr是否在字串中,idx是查詢開始的位置console.log('Google Google'.includes('Google'));//trueconsole.log('Google Google'.includes('xxxxxx'));//falseconsole.log('9966'.includes('99',1));//false程式碼執行結果:
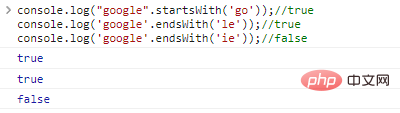
.startsWith('substr')和.endsWith('substr')分別判斷字串是否以substr開始或結束console.log("google".startsWith('go'));//trueconsole.log('google'.endsWith('le'));//trueconsole.log('google'.endsWith('ie'));//false程式碼執行結果:
.substr()、.substring()、.slice()
.substr()、.substring()、.slice()均用於取字串的子串,不過用法各有不同。
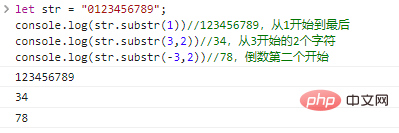
.substr(start,len)返回字串從
start開始len個字元組成的字串,如果省略len,就擷取到原字串的末尾。start可以為負數,表示從後往前第start個字元。let str = "0123456789";console.log(str.substr(1))//123456789,從1開始到最後console.log(str.substr(3,2))//34,從3開始的2個字元console.log(str.substr(-3,2))//78,倒數第二個開始
程式碼執行結果:
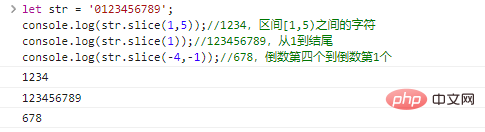
.slice(start,end)返回字串從
start開始到end結束(不包括)的字串。start和end可以為負數,表示倒數第start/end個字元。let str = '0123456789';console.log(str.slice(1,5));//1234,區間[1,5)之間的字元console.log(str.slice(1));//123456789,從1到結尾console.log(str.slice(-4,-1));//678,倒數第四個到倒數第1個
程式碼執行結果:
.substring(start,end)作用幾乎和
.slice()相同,差別在兩個地方:- 允許
end > start; - 不允許負數,負數視為
0;
舉例:
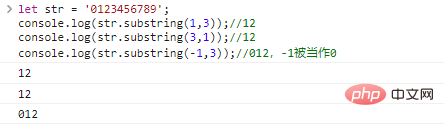
let str = '0123456789';console.log(str.substring(1,3));//12console.log(str.substring(3,1));//12console.log(str.substring(-1,3));//012,-1被當作0
程式碼執行結果:
- 允許
對比三者的區別:
| 方法 | 描述 | 引數 |
|---|---|---|
.slice(start,end) | [start,end) | 可負 |
.substring(start,end) | [start,end) | 負值為0 |
.substr(start,len) | 從start開始長為len的子串 | 可負 |
方法多了自然就選擇困難了,這裡建議記住
.slice()就可以了,相比於其他兩種更靈活。
.codePointAt()、String.fromCodePoint()
我們在前文中已經提及過字串的比較,字串按照字典序進行排序,每個字元背後都是一個編碼,ASCII編碼就是一個重要的參考。
例如:
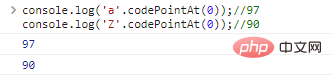
console.log('a'>'Z');//true字元之間的比較,本質上是代表字元的編碼之間的比較。JavaScript使用UTF-16編碼字串,每個字元都是一個16為的程式碼,想要知道比較的本質,就需要使用.codePointAt(idx)獲得字元的編碼:
console.log('a'.codePointAt(0));//97console.log('Z'.codePointAt(0));//90程式碼執行結果:
使用String.fromCodePoint(code)可以把編碼轉為字元:
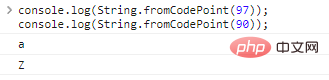
console.log(String.fromCodePoint(97));console.log(String.fromCodePoint(90));
程式碼執行結果如下:
這個過程可以用跳脫符\u實現,如下:
console.log('\u005a');//Z,005a是90的16進位制寫法console.log('\u0061');//a,0061是97的16進位制寫法下面我們探索一下編碼為[65,220]區間的字元:
let str = '';for(let i = 65; i<=220; i++){
str+=String.fromCodePoint(i);}console.log(str);程式碼執行部分結果如下:

上圖並沒有展示所有的結果,快去試試吧。
.localeCompare()
基於國際化標準ECMA-402,JavaScript已經實現了一個特殊的方法(.localeCompare())比較各種字串,採用str1.localeCompare(str2)的方式:
- 如果
str1 < str2,返回負數; - 如果
str1 > str2,返回正數; - 如果
str1 == str2,返回0;
舉個例子:
console.log("abc".localeCompare('def'));//-1為什麼不直接使用比較運運算元呢?
這是因為英文字元有一些特殊的寫法,例如,á是a的變體:
console.log('á' < 'z');//false雖然也是a,但是比z還要大!!
此時就需要使用.localeCompare()方法:
console.log('á'.localeCompare('z'));//-1常用方法
str.trim()去除字串前後空白字元,str.trimStart()、str.trimEnd()刪除開頭、結尾的空格;let str = " 999 ";console.log(str.trim());//999
str.repeat(n)重複n次字串;let str = '6';console.log(str.repeat(3));//666
str.replace(substr,newstr)替換第一個子串,str.replaceAll()用於替換所有子串;let str = '9+9';console.log(str.replace('9','6'));//6+9console.log(str.replaceAll('9','6'));//6+6
還有很多其他方法,我們可以存取手冊獲取更多知識。
進階內容
生僻字、emoji、特殊符號
JavaScript使用UTF-16編碼字串,也就是使用兩個位元組(16位)表示一個字元,但是16位資料只能表示65536個字元,對於常見字元自然不在話下,但是對於生僻字(中文的)、emoji、罕見數學符號等就力不從心了。
這種時候就需要擴充套件,使用更長的位數(32位)表示特殊字元,例如:
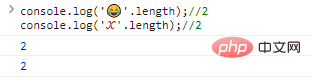
console.log(''.length);//2console.log('?'.length);//2程式碼執行結果:
這麼做的結果是,我們無法使用常規的方法處理它們,如果我們單個輸出其中的每個位元組,會發生什麼呢?
console.log(''[0]);console.log(''[1]);程式碼執行結果:
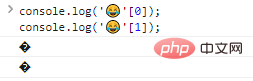
可以看到,單個輸出位元組是不能識別的。
好在String.fromCodePoint()和.codePointAt()兩個方法是可以處理這種情況的,這是因為二者是最近才加入的。在舊版本的JavaScript中,只能使用String.fromCharCode()和.charCodeAt()兩個方法轉換編碼和字元,但是他們不適用於特殊字元的情況。
我們可以通過判斷一個字元的編碼範圍,判斷它是否是一個特殊字元,從而處理特殊字元。如果一個字元的程式碼在0xd800~0xdbff之間,那麼他是32位字元的第一部分,它的第二部分應該在0xdc00~0xdfff。
舉個例子:
console.log(''.charCodeAt(0).toString(16));//d83
dconsole.log('?'.charCodeAt(1).toString(16));//de02程式碼執行結果:

規範化
在英文中,存在很多基於字母的變體,例如:字母 a 可以是 àáâäãåā 的基本字元。這些變體符號並沒有全部儲存在UTF-16編碼中,因為變化組合太多了。
為了支援所有的變體組合,同樣使用多個Unicode字元表示單個變體字元,在程式設計過程中,我們可以使用基本字元加上「裝飾符號」的方式表達特殊字元:
console.log('a\u0307');//ȧ
console.log('a\u0308');//ȧ
console.log('a\u0309');//ȧ
console.log('E\u0307');//Ė
console.log('E\u0308');//Ë
console.log('E\u0309');//Ẻ程式碼執行結果:
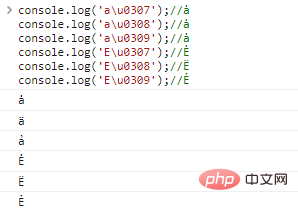
一個基礎字母還可以有多個裝飾,例如:
console.log('E\u0307\u0323');//Ẹ̇
console.log('E\u0323\u0307');//Ẹ̇程式碼執行結果:
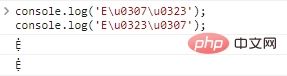
這裡存在一個問題,在多個裝飾的情況下,裝飾的排序不同,實際上展示的字元是一樣的。
如果我們直接比較這兩種表示形式,卻會得到錯誤的結果:
let e1 = 'E\u0307\u0323';
let e2 = 'E\u0323\u0307';
console.log(`${e1}==${e2} is ${e1 == e2}`)程式碼執行結果:
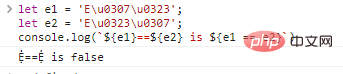
為了解決這種情況,有一個**Unicode規範化演演算法,可以將字串轉為通用**格式,由str.normalize()實現:
let e1 = 'E\u0307\u0323';
let e2 = 'E\u0323\u0307';
console.log(`${e1}==${e2} is ${e1.normalize() == e2.normalize()}`)
程式碼執行結果:

【相關推薦:、】
以上就是JavaScript字串常見基礎方法精講的詳細內容,更多請關注TW511.COM其它相關文章!