AMS 新聞視訊廣告的雲原生容器化之路
作者
卓曉光,騰訊廣告高階開發工程師,負責新聞視訊廣告整體後臺架構設計,有十餘年高效能高可用海量後臺服務開發和實踐經驗。目前正帶領團隊完成雲原生技術棧的全面轉型。
吳文祺,騰訊廣告開發工程師,負責新聞視訊廣告流量變現相關後臺開發工作,熟悉雲原生架構在生產實踐中的應用,擁有多年高效能高可用後臺服務開發經驗。目前正推動團隊積極擁抱雲原生。
陳宏釗,騰訊廣告高階開發工程師,負責新聞視訊廣告流量變現相關後臺開發工作,擅長架構優化升級,有豐富的海量後臺服務實踐經驗。目前專注於流量場景化方向的廣告系統探索。
一、引言
新聞視訊廣告團隊主要負責騰訊新聞、騰訊視訊、騰訊微視等媒體廣告流量的廣告變現提收工作,在媒體流量日益複雜,廣告變現效率逐步提升的背景下,團隊需要負責開發並維護的後臺服務數量增長迅猛,服務維護成本與日俱增,傳統的基於物理機的部署以及運維方案已經成為了制約團隊人效進一步提高的瓶頸。
自2019年開始,公司鼓勵各研發團隊將服務遷移上雲,並對服務進行雲原生改造。為了響應公司的號召,在充分調研了服務上雲的收益後,我們決定將團隊維護的業務分批上雲,提升後臺服務的部署及運維效率。
二、業務上雲「三步走」
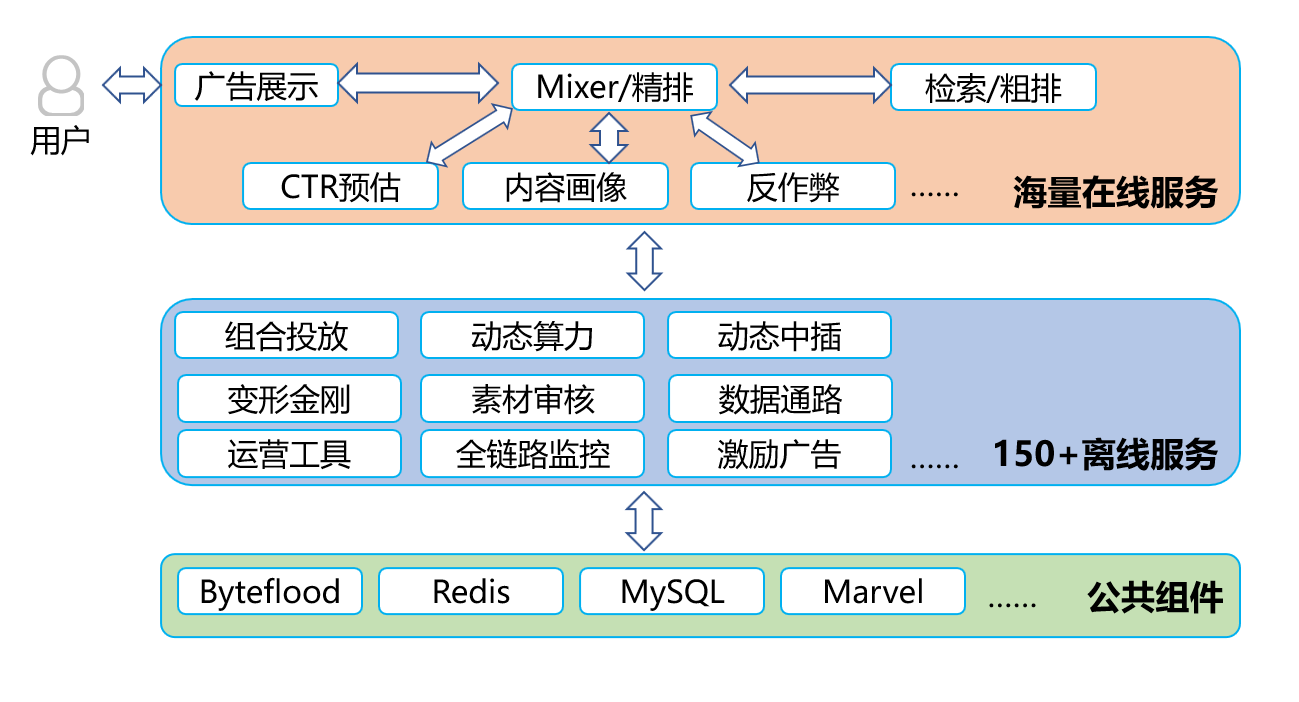
圖2-1 新聞視訊廣告後臺整體架構圖
新聞視訊廣告主要承接來自騰訊新聞、騰訊視訊、片多多以及騰訊微視的廣告流量接入並負責提升流量的變現效率,具體包括流量接入、形態優化、ecpm 優化等等。如上圖所示,由於接入的業務需求複雜多樣,而且彼此之間有顯著差異,比如內容廣告、激勵廣告等,導致新聞視訊廣告的後臺服務具有如下特點:
- 請求量大,線上服務需要承接來自流量方的海量請求,服務效能及穩定性要求高;
- 服務數量眾多,不同服務之間負載差異大,同一服務不同時間段負載變化大,人力運維成本高;
- 依賴的外部元件多,服務釋出與運維的流程都與傳統的物理機模式深度繫結,歷史包袱重,平滑上雲挑戰大。
針對以上這些問題,我們在服務遷移上雲的過程中,客製化了」三步走「計劃:
- 搭建上雲依賴的基礎元件並規範上雲流程;
- 離線服務快速上雲;
- 海量線上服務平滑上雲;
三、第一步——搭建基礎元件&規範上雲流程
為了提高服務上雲效率,方便各個服務負責人自行將服務遷移上雲,我們首先搭建了雲服務基礎元件,並輸出了服務上雲的規範,主要包括容器化 CI/CD 和服務平滑上雲兩部分。
3.1 容器化 CI/CD 設定
想要上雲,首先要考慮的問題就是如何將服務在雲平臺上部署。我們對物理機和雲平臺的部署情況做對比。
| 物理機 | 雲平臺 | |
|---|---|---|
| 排程單位 | 伺服器 | Pod |
| 單位數量 | 少 | 多 |
| 數量變化 | 相對固定,審批流程通過後才能增加或減小單位數量 | 彈性較大,動態縮擴容隨負載隨時變化 |
表3-1 物理機和雲平臺的部署情況對比
可以看到,物理機和雲平臺面臨的情況完全不同。在物理機時代,我們採用織雲部署服務,在織雲平臺手工設定伺服器目標,管理二進位制和部署,而轉向雲平臺後,大量 Pod 動態變化組成的叢集,與假定管理物件都是固定 ip 的伺服器的織雲並不契合。因此,我們轉向採用藍盾實現自動化整合與部署。
藍盾將整合與釋出流程整合並統一管理,程式碼合入即自動觸發編譯、迴歸、稽核和釋出流程,無需額外人工。為了相容已有的物理機服務的釋出流程,保證混合部署服務的版本一致,二進位制包仍然使用織雲管理,由藍盾流水線編譯產物後推播至織雲。藍盾流水線從織雲拉取二進位制後和運維提供的包含必要 agent 的基礎映象打包,將環境與二進位制標準化,模版化,以映象的方式作為最終產物釋出,拉起即用,便於 pod 快速部署與擴容,減少了手工標準化伺服器的工作量。最終,我們達成了如下目標:
- 自動化部署,節約人力;
- 相容物理機發布流程,便於混合部署;
- 模版化環境,方便快速擴容。
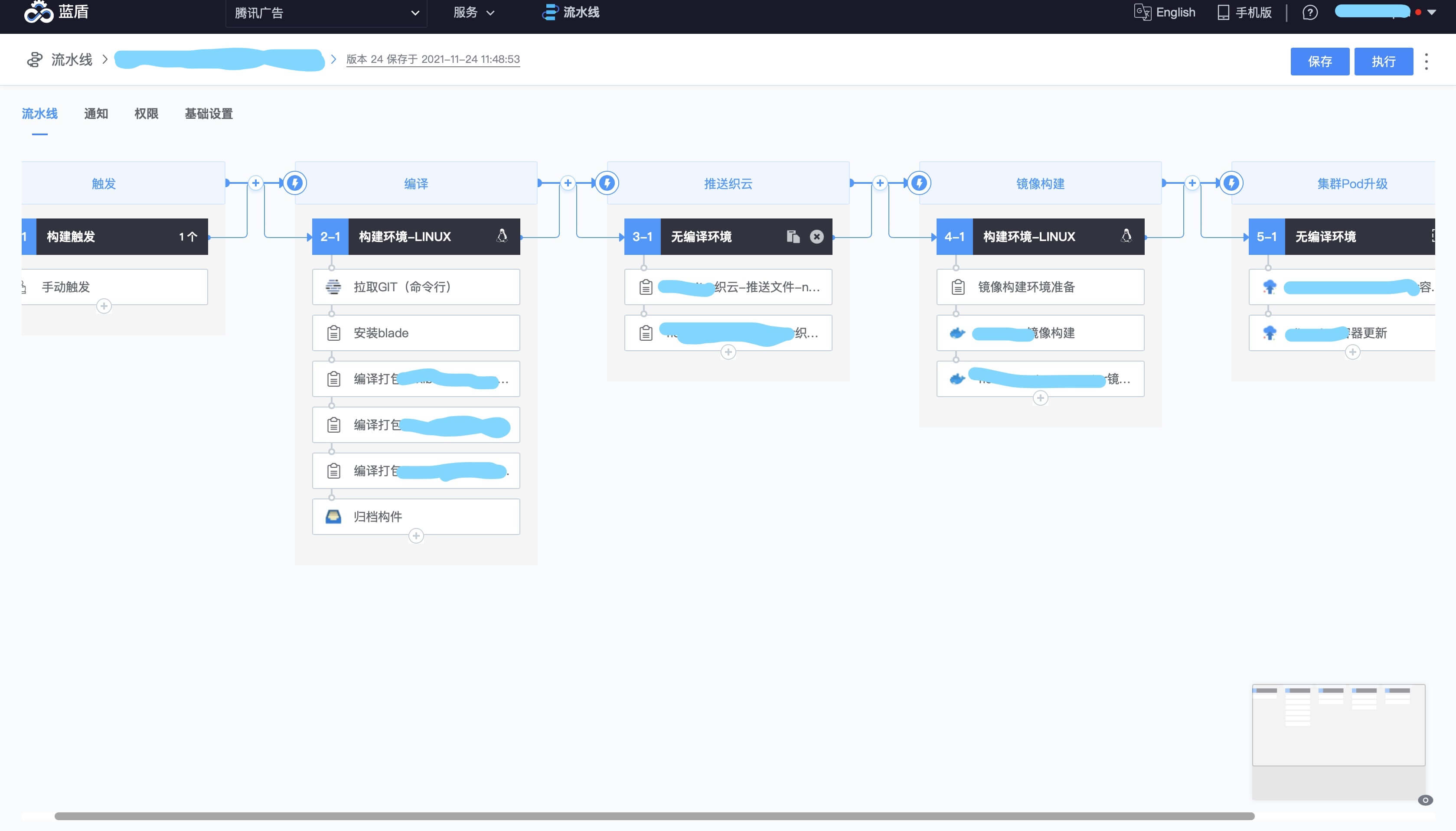
圖3-1 藍盾實現 CI/CD 流水線
3.2 後臺服務平滑上雲
3.2.1 基礎元件平滑上雲
新聞視訊廣告後臺服務依賴北極星、智研等基礎元件提供負載均衡、指標上報等基礎功能,然而在將這些基礎元件遷移上雲後,我們發現它們並不能如期提供能力,影響了服務正常執行。經過深入排查分析,我們發現,這些元件不能正常工作的原因主要包括以下2點:
- 容器的 ip 不屬於 idc 網段,這些基礎元件在容器中的 agent 與它們的 server 無法連通;
- 容器 ip 會隨著容器的升級和遷移而發生變化,元件註冊的 ip 頻繁失效。
而這2個問題都是由於 TKE 平臺為容器設定預設的 Overlay 網路策略導致的。為了解決上述的問題,TKE 平臺方建議我們採用「浮動 ip」和「刪除或縮容 APP 時回收」等高階網路策略。浮動 ip 策略不同於 overlay,分配由運維指定的 idc 網段的 ip,其他 idc 機器上的服務可以直接存取;「刪除或縮容 APP 時回收」策略將 ip 與對應的 pod 繫結,即使 pod 更新與遷移,ip 也不會發生改變。
我們在新增工作負載時,在高階設定中設定浮動 ip 與刪除或縮容 APP 時回收的策略,保證增量負載的元件工作正常;同時修改已有負載的 yaml 設定,新增如下圖的設定項,將存量負載的設定對齊增量負載。雙管齊下,最終解決了網路策略對基礎元件的影響,促進基礎元件與雲平臺的協同工作。
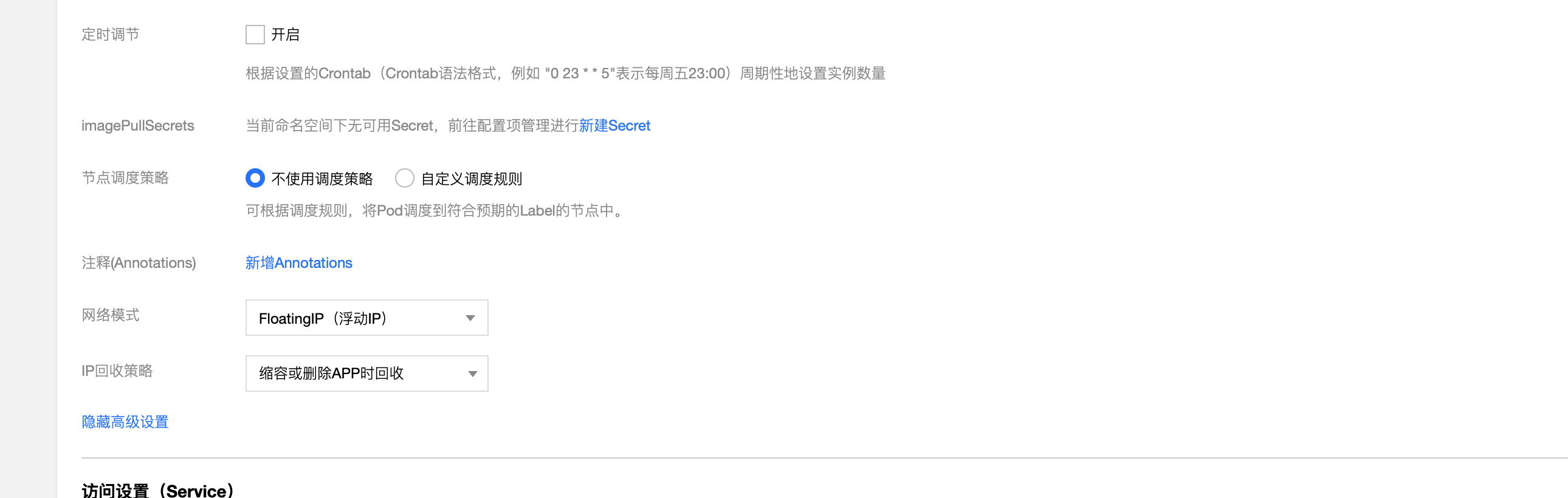
圖3-2 TKE 平臺新增負載策略選擇
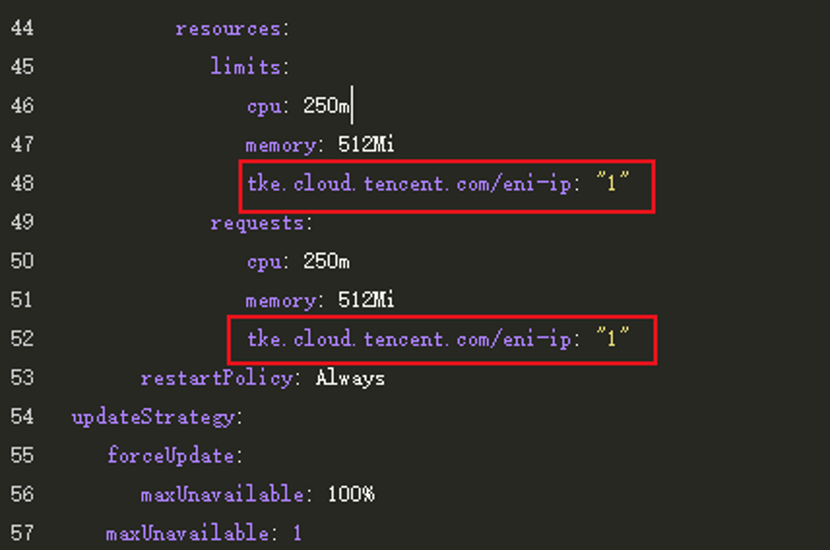
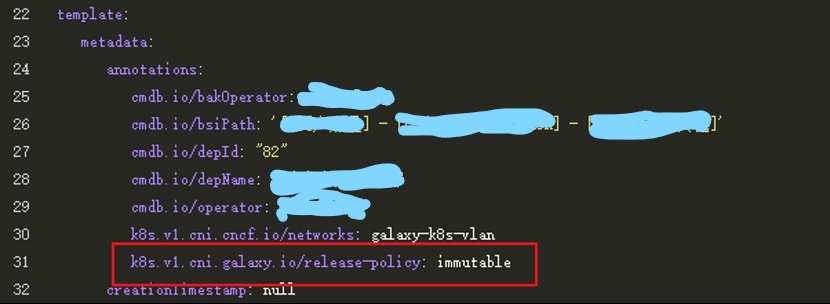
圖3-3 TKE 平臺存量設定修改
3.2.2 流量平滑遷移
將服務成功部署上雲後,接下來就需要讓雲上叢集承接外部流量,發揮職能。新聞視訊流量當前都路由至物理機,若直接全量切換存取雲服務,會面臨如下問題:
- 雲上叢集服務未經過流量考驗,可能導致未知的問題線上上暴露;
- 新叢集未充分預熱,可以承受的 QPS 較低。
可以想見,這樣激進的操作極其危險,容易引發事故甚至叢集崩潰,因此我們需要將流量平滑的切至雲平臺,留下充裕的時間應對上雲過程中出現的問題。
針對平滑切換的目標,我們提出了兩個上雲指導方針:
- 小步慢跑。分多階段遷移流量,每一次僅將少量的流量切換至雲平臺,切換後,觀察系統監控以及業務指標監控無異常後,再進行下一次的流量遷移。
- 灰度驗證。對標物理機的釋出操作,挪出部分資源搭建灰度叢集,每一次流量切換前,先在灰度叢集上面實驗,灰度叢集驗證完成後,再在正式叢集上執行對應的操作。
最終,我們在全量切換前提前發現問題並解決,保證線上服務的穩定,實現了流量平滑順暢的遷移。
四、第二步——150+離線服務的快速上雲
新聞視訊廣告的離線後臺服務數量眾多,服務總數150+;功能也很複雜多樣,既有視訊特徵抽取等高計算量的服務,也有僅提供通知能力的低負載的服務。在上雲過程中,如何為紛雜繁多的離線服務,設計與之適應的資源選取、優化與排程方案?對於這個問題,我們總結出了一套符合新聞視訊廣告離線業務特點的上雲方案。
4.1 離線服務資源分配方案
4.1.1 資源分配模板設計
為了提升 CPU 和記憶體的利用率,我們希望對不同種類的服務分配合適的資源,保證資源充分利用。在上雲過程中,我們總結出一套分配資源的方法。離線服務的單個 pod,CPU 限制在0.25核-16核之間,記憶體最小不能低於512M,在滿足下限的同時,最好與核數保持1:2的比例。遵循這套方法有什麼好處呢?下面是我們總結的原因:
- 若 CPU 核數大於32,可能導致 TKE 平臺在排程時,找不到空閒的核數足以滿足要求的節點,導致 Pod 擴容失敗;
- 若 CPU 核數大於32,可能導致 TKE 平臺的資源碎片化,降低叢集的整體資源利用率;
- 如果容器分配的 CPU 低於0.25核,或者記憶體低於512M,會導致北極星等公共元件的 agent 無法正常執行,容器無法正常拉起。
在實際的使用中,我們結合上雲的實戰經驗,總結出不同型別服務的推薦設定表格如下所示。
| 離線定時輪詢服務 |
| 離線運營類服務 |
| 離線計算類服務 |
表4-1 不同型別服務的推薦設定
4.1.2 基礎映象簡化
按照推薦設定表格的設定,我們將離線服務部署在 TKE 平臺上。一開始,服務能夠平穩的執行,然而,隨著時間的推移,公共映象中的 agent 越來越多,agent 佔用的資源越來越大,對於通知服務等分配資源較少的服務,agent 的資源佔用提升後,甚至超過服務本身使用的資源,導致 OOM 或容器無法拉起等異常表現。
我們既想要優化不斷增長的agent數量帶來的資源消耗提升,又想要享受公共映象的更新,有沒有兩全其美的辦法呢?答案是肯定的。我們在 CI/CD 流水線構建業務映象時,通過 RUN 命令新增刪除多餘 agent 的流程。在刪除 Agent 流程的內部,我們設定標記服務依賴的必要映象,反選其他無用的 agent,執行刪除。由於RUN命令新增了一層不可變檔案層,不影響該層以前的公共映象檔案層,公共映象更新 agent 時,也會作用到業務映象。通過這種方式,我們既節省了 agent 使用的資源,保證低資源分配的服務正常執行,又享受了公共映象自動更新 agent 帶來的便利。
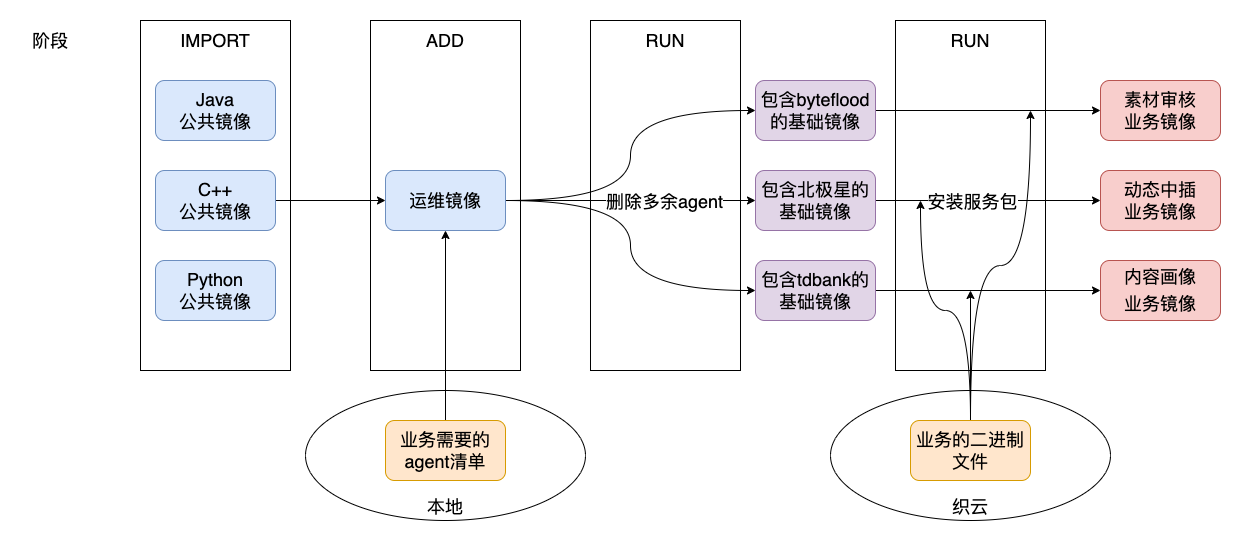
圖4-1 映象瘦身示意圖
4.2 離線服務 HPA 設定方案
很多離線服務的負載並不是穩定不變的,白天與夜晚的負載往往會有較大差異,如果為這些服務分配恆定的資源,可能會導致服務負載高峰期資源過載,負載低谷期資源閒置。因此,我們希望分配給容器的資源,能夠隨著服務負載的變化而變化。為此,我們選擇使用HPA元件實現彈性縮擴容。
4.2.1 HPA設定模板設計
想要使用 HPA,首先需要選取觸發是否應該縮擴容的指標。選取衡量指標的核心思想,是儘量選取變化最大的指標,避免變化較小的指標限制 Pod 數量的變化,導致其他負載指標的變化超出資源限制。對於離線任務而言,一般來說,CPU 使用率更容易隨著任務的開啟和結束髮生變化,而記憶體一般儲存相對固定的上下文,比較穩定,選取 CPU 使用率作為判定標準比較合理。
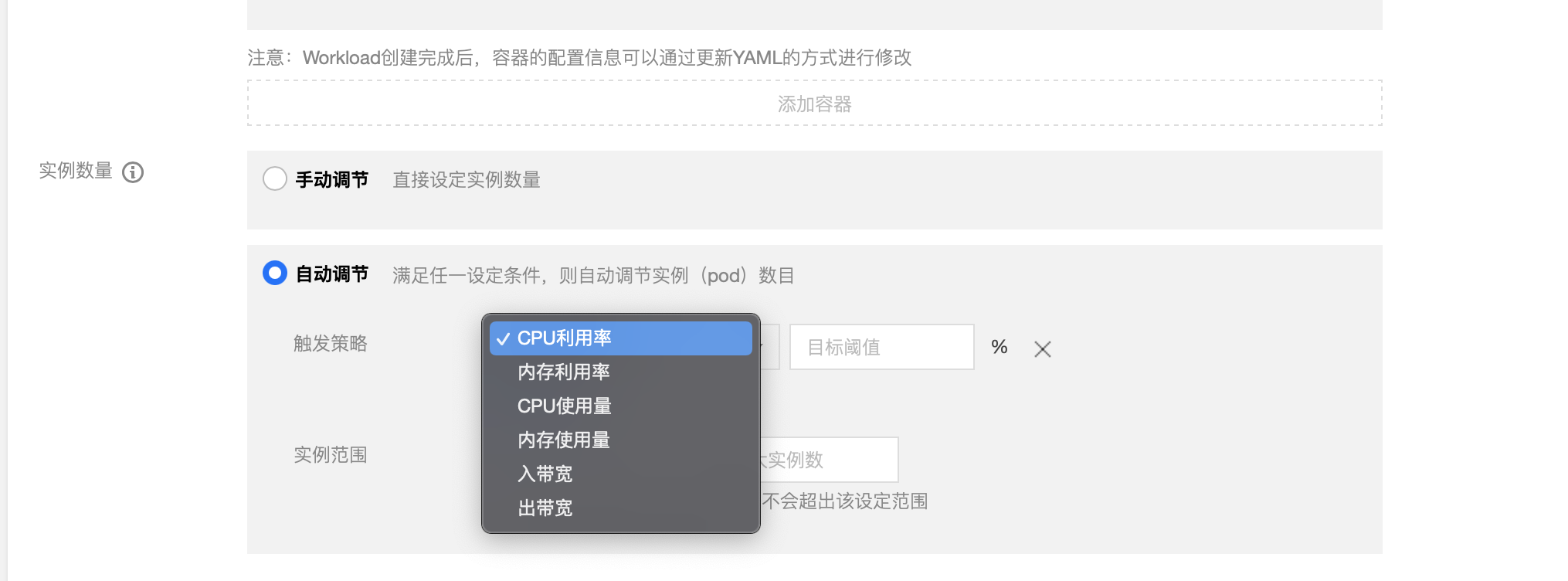
圖4-2 選取 CPU 利用率作為 HPA 的衡量指標
其次,我們要指定 Pod 數量的上限和下限。上限可以避免不正確的設定造成大量 Pod 建立,空耗叢集資源,影響叢集穩定性。而下限有兩個作用,第一,確保 Pod 數量符合 HPA 元件的最小副本不為零的限制,避免元件採集不到 metrics,無法獲取縮擴容調整所依賴的指標後,失去調節副本數量的功能,從而使叢集陷入 Pod 數量恆定為0,無 pod 可供服務的情況;第二,若少量 Pod 因故障陷入無法服務的狀態,保證一定數量的 Pod 可以減小故障對服務的衝擊。
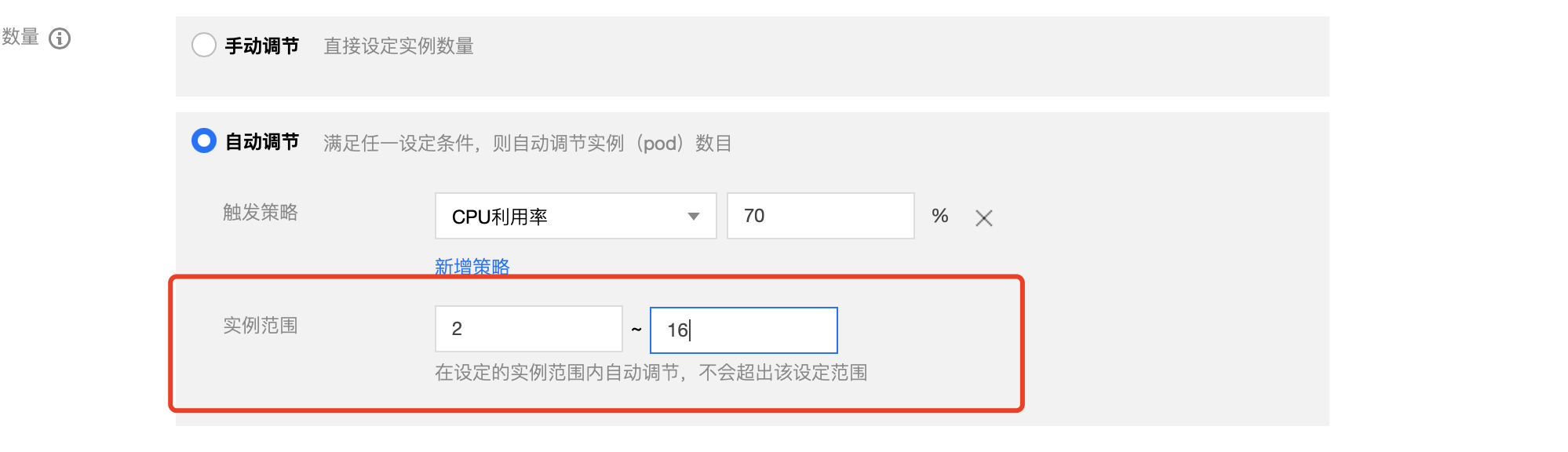
圖4-3 設定 HPA 調整範例數量的上下限
最後,我們需要根據具體的負載變化曲線,決定彈性縮擴容的策略。
- 如果負載曲線在每一天每一個時段下都高度一致,我們可以考慮使用 CronHPA 元件,人工指定不同時段的 Pod 數量,定期排程。
- 如果負載曲線每天都在發生變化,不論趨勢還是數值,我們都可以使用 HPA 設定,設定 CPU 使用率參考值,要求叢集在利用率超過或低於指定值時進行 Pod 數量的調整,將 Pod 的 CPU 使用率維持在容忍範圍內。
- 如果負載曲線每天發生變化,但是存在定時發生的尖峰,為了避免叢集自行調整的速度慢於負載增長的速度,導致叢集被壓垮,我們可以結合 CronHPA 與 HPA 使用,平時將控制權交給 HPA,在尖峰到來前使用 CronHPA 提前擴容,既保證尖峰不會沖垮叢集,又能享受叢集自動調整 Pod 數量帶來的便利。
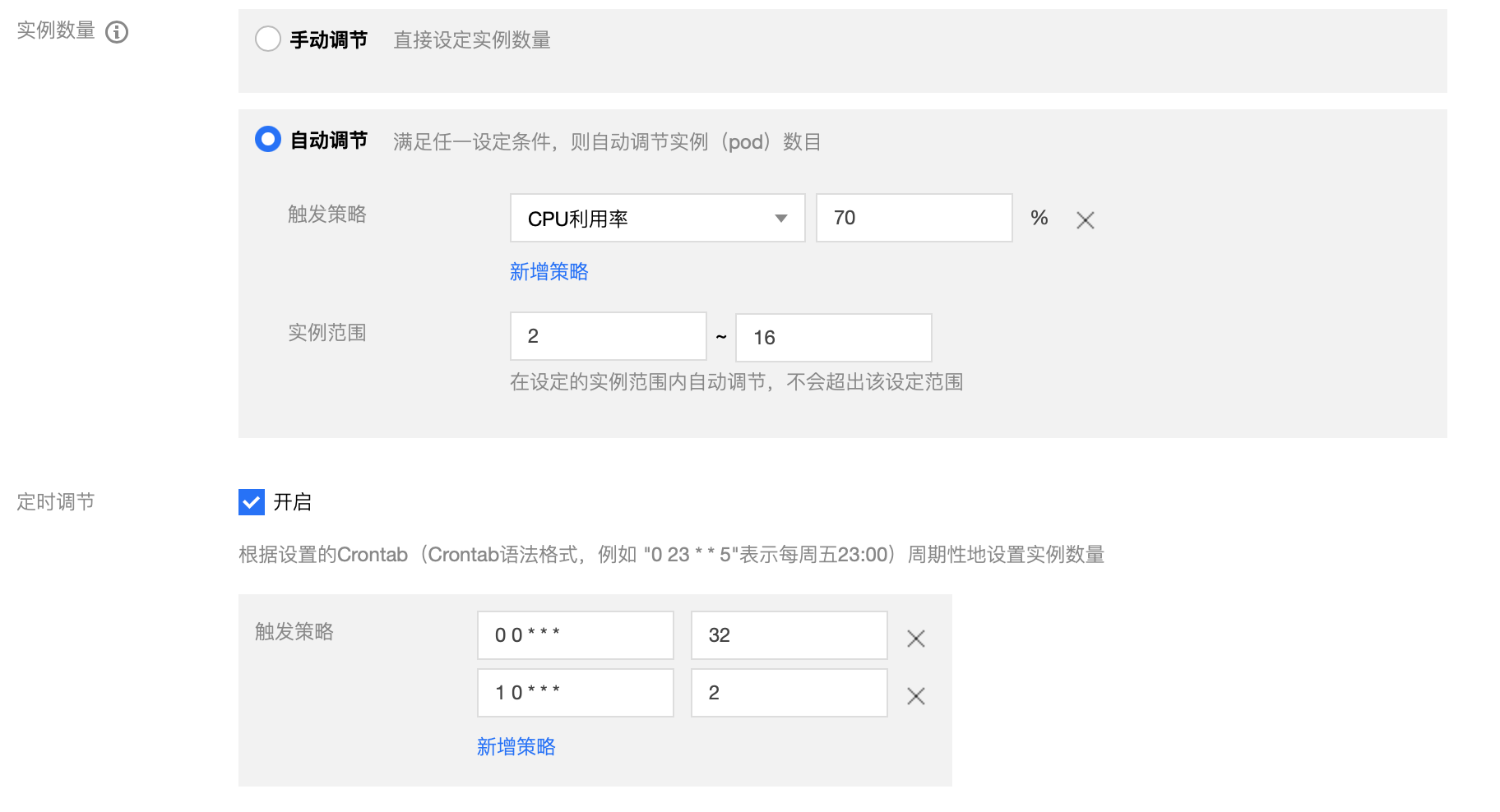
圖4-5 結合 CronHPA 與 HPA 共同使用
由此,我們完成了 HPA 的設定,通過多樣的策略,實現了叢集分配資源隨著服務負載變化。
4.2.2 IP 白名單自動變更
服務 Pod 數量動態變化,會導致部分服務執行的環境中,IP 地址經常改變。而廣告業務服務存取下游介面時,大多需要通過靜態的 IP 白名單校驗。靜態的 IP 白名單不再適合雲原生環境下部署的服務,我們希望推動下游的 IP 白名單支援動態新增容器 IP,擁抱雲原生。為此,我們根據下游許可權的敏感等級,使用不同的處理方式完成改造。
- 對於敏感等級較低的介面,我們推動介面作者提供 IP 自動上報的介面,為每一位使用者下發憑證,服務啟動前使用呼叫介面,上報當前的 IP 地址加入白名單。例如北極星為我們提供了上報指令碼,我們僅需要在容器的啟動指令碼內呼叫上報指令碼即可完成上報。由於服務執行期間,IP 將不再變更,因此僅需要上報 Pod 拉起時的 IP,即可保障服務的穩定執行。
- 對於敏感等級高的介面,作者不信賴來自使用者的操作,擔心使用者的錯誤操作擊穿白名單保護,例如 CDB 團隊就擔心廣告隱私資料洩漏。我們推動這些團隊與 TKE 平臺方合作,開放授權給 TKE 平臺,使用者申請鑑權憑證後託管在 TKE 平臺上,由 TKE 平臺拉起容器的時候負責上報新的 IP。
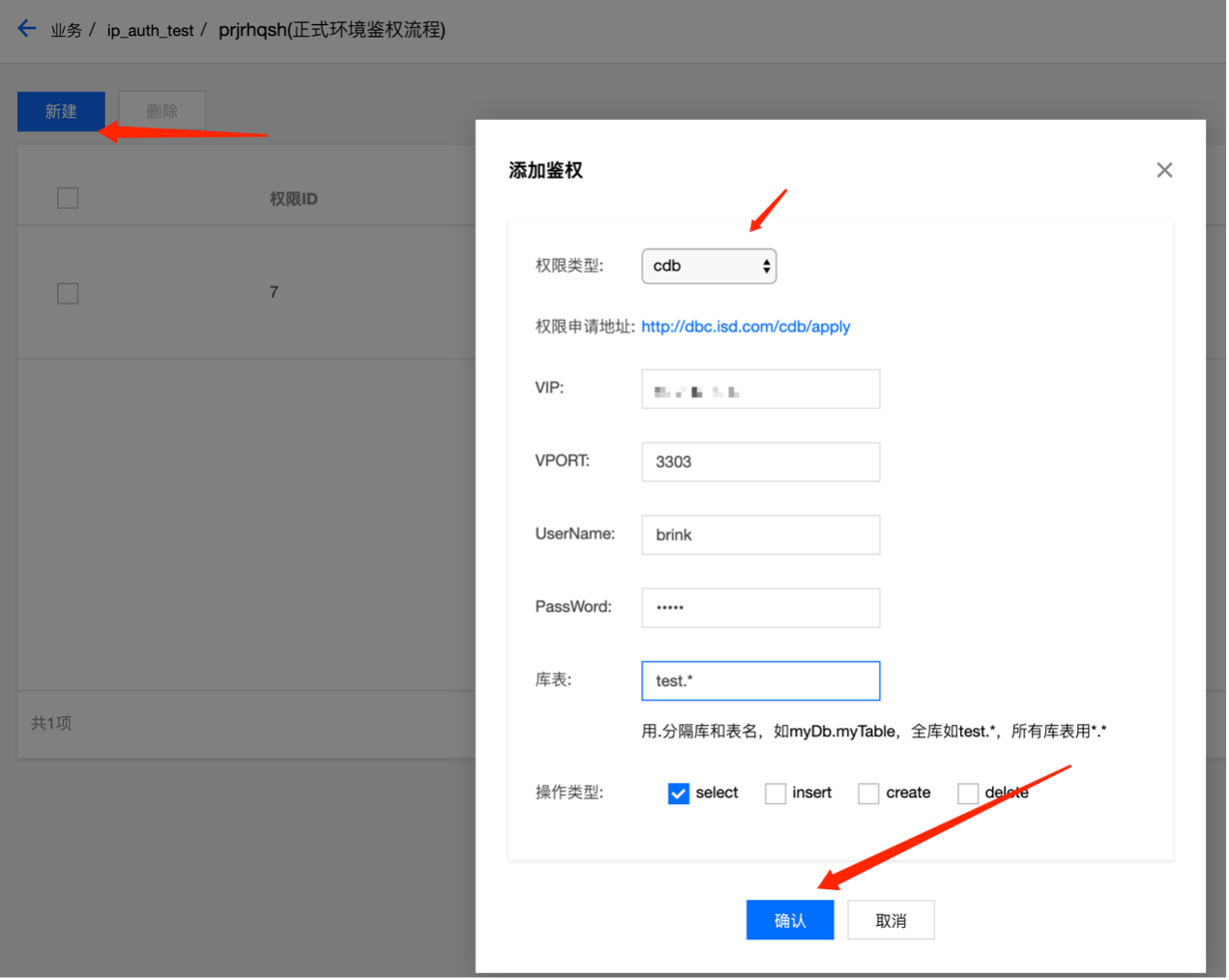
圖4-6 TKE 平臺設定授權
最終,我們實現了下游介面對容器縮擴容的感知,自動化更新白名單,保障服務在彈性縮擴容生效的情況下正常工作。
五、第三步——海量線上服務的平滑上雲
新聞視訊廣告系統承載百億級別的流量,後臺線上服務的QPS最高可以達到幾十萬的級別,在遷移上雲後同樣需要保證服務的高效能、高可用以及可延伸等。為了滿足這個要求,我們與運維、TKE平臺方共同合作,解決上雲過程中所遇到的問題,保障海量線上服務順利平滑上雲。
5.1 計算密集型服務延時毛刺優化
廣告系統中,線上服務大多屬於計算密集型,需要較高的效能保證計算按時完成。如果相關的計算邏輯在不同的 CPU 核間頻繁排程,會引發 cache miss 頻率的提升,程式效能降低,請求時延經常出現毛刺。因此,部署在物理機器上的服務大量使用綁核能力,手工指定服務執行的 CPU,提升區域性性,提升程式效能。
然而上雲後,平臺對 CPU 資源進行虛擬化管理,服務在容器內通過「/proc/cpuinfo」獲取到的是分配隔離和重排序後的虛擬 CPU 列表,與節點實際的 CPU 列表大相徑庭。使用虛擬的 CPU 列表進行綁核操作,不僅可能繫結到未分配的 CPU,效能不符合預期,甚至會繫結到不存在的 CPU,引發程式錯誤。
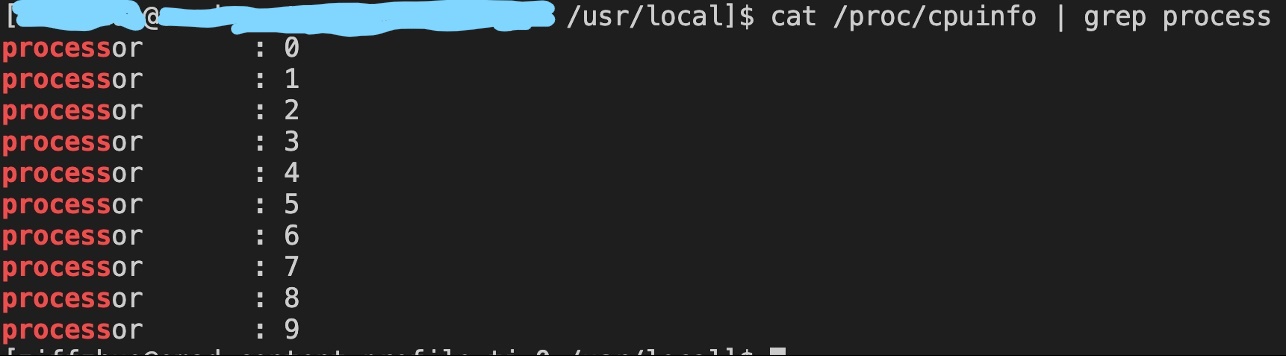
圖5-1 96核機器節點上,某容器內虛擬化的 CPU 列表
因此,需要找到一種在雲平臺上獲取實際 CPU 列表的辦法。我們考慮到雲平臺通過 cgroup 管理並隔離資源,可以嘗試在 cgroup 中尋找獲取實際 CPU 列表的介面。於是我們查詢資料發現,cgroup 提供「/sys/fs/cgroup/cpuset/cpuset.cpus」子系統,可以獲取到虛擬 CPU 列表在物理列表上的實際對映範圍,符合我們的要求。我們修改綁核功能中獲取 CPU 列表的程式碼,將讀取 proc 子系統的部分改為讀取 cgroup 子系統,從而成功實現雲上服務的綁核功能。

圖5-2 cgroup 實際分配的 CPU 列表
5.2 線上服務的高可用性保障
線上服務的生命週期分為三個階段,服務啟動,準備就緒,服務銷燬。服務只有處於準備就緒階段才對外可用。而叢集的可用性,取決於加入負載均衡的服務中準備就緒的比例。因此,要想提高服務的可用性,可以從兩個方向努力:
- 降低服務啟動的時長,提升準備就緒狀態在服務生命週期的佔比。
- 降低存取服務的失敗率,保證載入和銷燬階段的服務不加入負載均衡。
5.2.1 降低服務啟動時長
想要服務的啟動時長,需要分析服務啟動過程中,有哪些耗時佔比高的操作。經過分析,我們發現,廣告服務在服務啟動的過程中,其中有一個步驟是通過檔案同步服務 byteflood,訂閱同步廣告、素材、廣告主等資料的檔案到容器本地。這個步驟非常耗時,占上下文載入階段的耗時大頭。有沒有什麼辦法能夠降低這個步驟的耗時呢?
深入探索後,我們找到了優化的空間。原來,byteflood 每次都需要拉取全量的資料檔案。為什麼不能增量拉取呢?因為 byteflood 元件在容器中同步到原生的檔案,儲存在容器的可變層,一旦容器由於升級或者遷移觸發重建,則資料檔案全部丟失,必須重新拉取全量檔案。看來,只需要持久化儲存資料檔案,我們就可以避免檔案丟失,採用增量拉取的方式更新資料,從而降低資料訂閱步驟的耗時,縮短上下文的載入時長,提高服務的可用性。
我們採用掛載外部資料卷(volume)的方式儲存資料檔案。外部資料卷獨立於容器檔案系統,容器重建不會影響外部資料卷中的檔案,保證了資料檔案的持久化。

圖5-3 使用掛載點持久化訂閱資料檔案
然而,使用 volume 掛載後,我們遇到了路徑不一致的新問題。由於TKE平臺規範限制,掛載的路徑和物理機上不一致,為了保持雲服務和物理機的服務設定一致,我們想要通過軟鏈將設定路徑指向掛載路徑。但是掛載的行為發生在容器拉起時,而服務程序啟動前,即需要保證設定路徑包含資料檔案。如果需要在pod啟動後手工維護軟鏈,不僅生效時間可能在服務程序執行讀取操作後導致服務讀不到資料,而且生成的軟鏈同樣面臨容器重建後被丟棄的問題。為此,我們將容器的entrypoint,即容器啟動時呼叫的命令,替換為自行實現的啟動指令碼,在指令碼內加入生成軟鏈的語句,服務啟動語句放在軟鏈的後面。容器啟動即執行軟鏈操作,無需手工處理,重建也能保證再次執行,解決了設定路徑的問題。
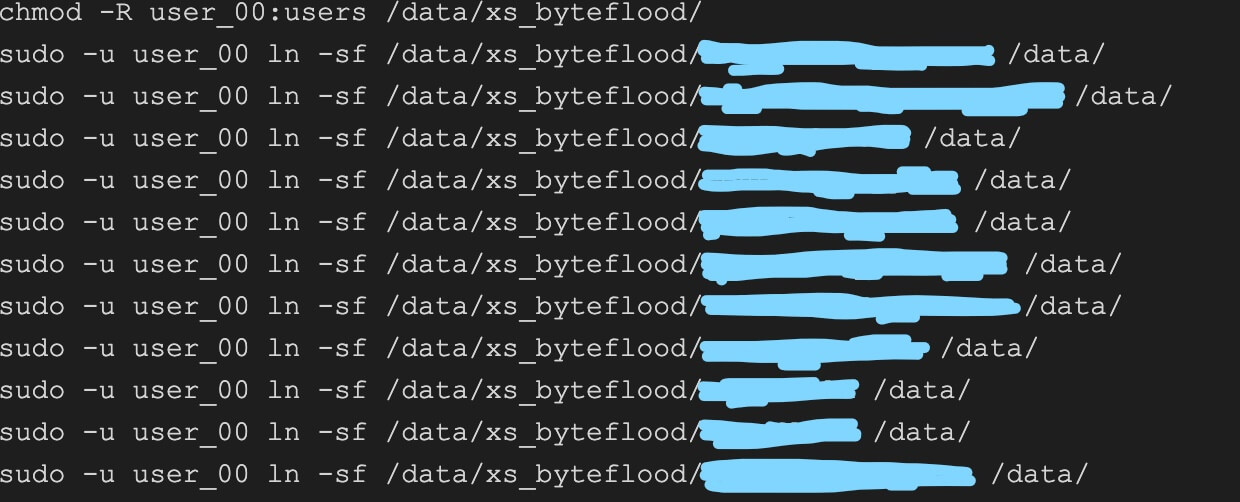
圖5-4 軟鏈指向實際掛載路徑,對齊設定路徑
最終,我們成功的外掛了資料檔案,將服務啟動時長從5分鐘降低到10秒鐘,效果顯著。
5.2.2 降低存取服務的失敗率
容器內服務的狀態若處於載入中或者已銷燬,將無法處理請求,如果這些無法處理請求的容器的 IP 處於負載均衡的列表中,就會降低叢集可用性。想要降低請求存取服務的失敗率,必須保證負載均衡關聯的服務均處於準備就緒的狀態,而保證負載均衡關聯的服務均處於準備就緒的狀態,關鍵在於將負載均衡的關聯狀態納入服務的生命週期管理,服務脫離載入狀態前,不允許容器加入負載均衡,服務如果需要變更至銷燬狀態,需要在變更前將容器地址從負載均衡服務中剔除。
平臺側已經將公司的負載均衡服務——北極星——納入容器的生命週期,不將 Not Ready 的容器加入北極星,容器銷燬時將容器地址從北極星剔除。然而,由於容器的生命週期不同於服務生命週期。容器進入 Ready 狀態時,服務可能仍在載入上下文,被加入北極星卻無法提供服務;容器銷燬時,平臺發起剔除的請求,但是北極星元件內部狀態並非即時更新,可能在容器銷燬後,依然轉發流量到已銷燬的容器。需要找到合適的方法,使北極星感知服務生命的週期,避免流量轉發至載入或銷燬狀態的服務。
想要禁止載入狀態的服務加入負載均衡,可以藉助平臺方提供的就緒檢查功能。就緒檢查通過定期檢查業務的 tcp 埠狀態,判斷服務是否已經載入完成,若未載入完成,則將 Pod 狀態設定為 Unhealthy,同時禁止上游的北極星將流量轉發到這個容器,直到載入完成。通過就緒檢查,我們保證在服務載入完成前,不會有請求傳送至服務所在的 Pod。
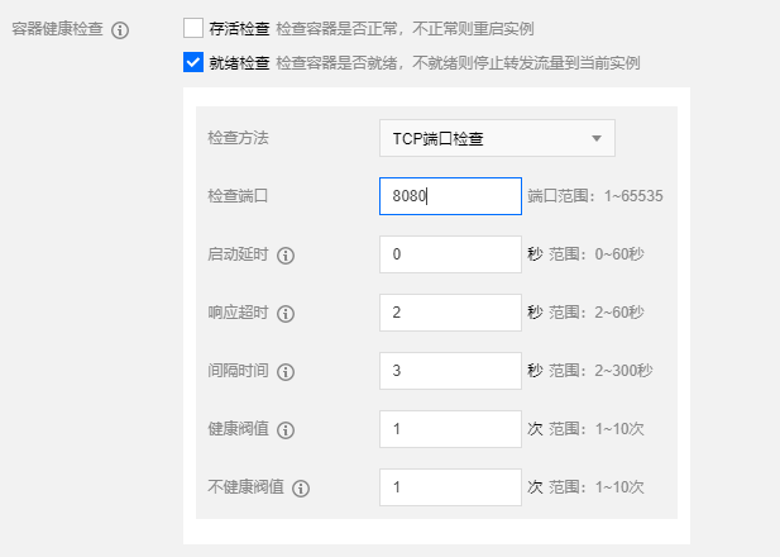
圖5-5 設定就緒檢查
想要保證服務變更至銷燬狀態前將服務地址踢出負載均衡,同樣需要藉助 TKE 平臺的功能——後置指令碼。平臺側允許業務方指定一段指令碼,該指令碼將在容器銷燬前執行。我們在該指令碼內執行等待一段時間的操作,保證上游的負載均衡器更新狀態後,再銷燬容器。通過後置指令碼,我們保證容器在銷燬前,負載均衡不再向該容器轉發任何請求。
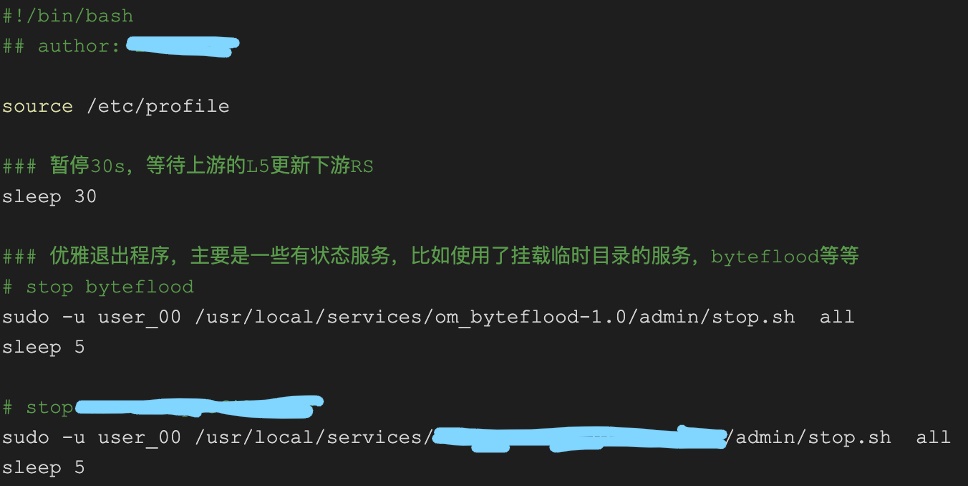
圖5-6 後置指令碼範例
5.3 高並行服務連線失敗優化
新聞視訊流量大部分線上服務需要承載海量請求,同時處理大量的並行,例如品效合一後臺服務。在這些服務遷移到 TKE 平臺的過程中,隨著流量的逐步增長,系統失敗量顯著增加,特別的,一些使用短連線的服務出現了大量連線失敗的情況。為此,我們和運維以及 TKE 平臺方的同學共同合作,排查並解決了問題,順利推進新聞視訊團隊業務線上服務全部上雲,同時也增加了大家將海量服務遷移上雲的信心。
經過排查,我們發現錯誤率的提升主要由兩點導致。
-
- 核心的流量統計功能長期佔用 CPU 導致網路處理延遲。 kubernetes 通過 ipvs 模組管理 NAT 規則控制流量轉發容器,而 ipvs 預設開啟流量統計功能,他向核心註冊計時器觸發統計操作。計時器觸發時,通過自旋鎖佔用 CPU,遍歷規則統計。一旦節點上 Pod 數量較多,規則數量多,則計時器長期佔用 CPU,影響服務程序處理回包。
-
- 連線數超出 NAT 連線追蹤表的上限導致新連線被丟棄。 kubernetes 通過 nf_conntrack 模組記錄連線資訊,而 nf_conntrack 的實際實現為固定大小的雜湊表。一旦表被填滿,新增的連線會被丟棄。
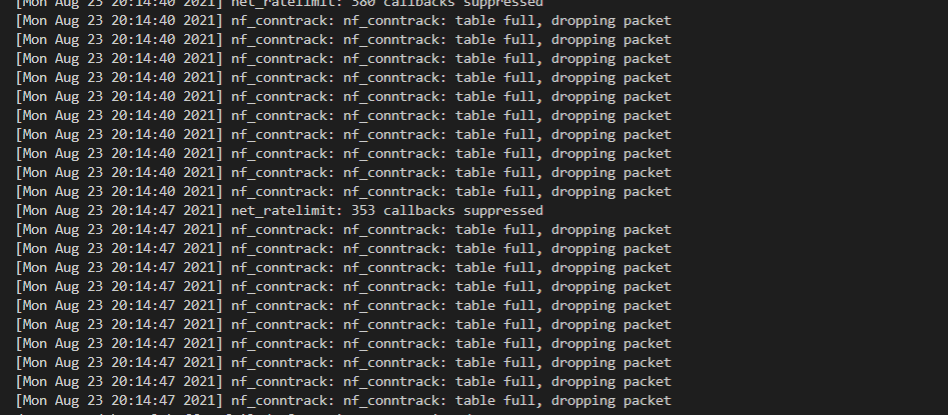
圖5-7 服務紀錄檔展示的連線表容量已滿的錯誤
針對第一點,我們希望關閉核心模組 ipvs 的流量統計功能。然而叢集的 tlinux 版本與外網版有區別,缺少流量統計功能的開關。平臺方推動新增叢集 tlinux 修補程式同步機制,將外網版本的修補程式應用在叢集節點上,新增流量統計開關的核心引數。我們設定關閉統計功能後,錯誤數量下降顯著。
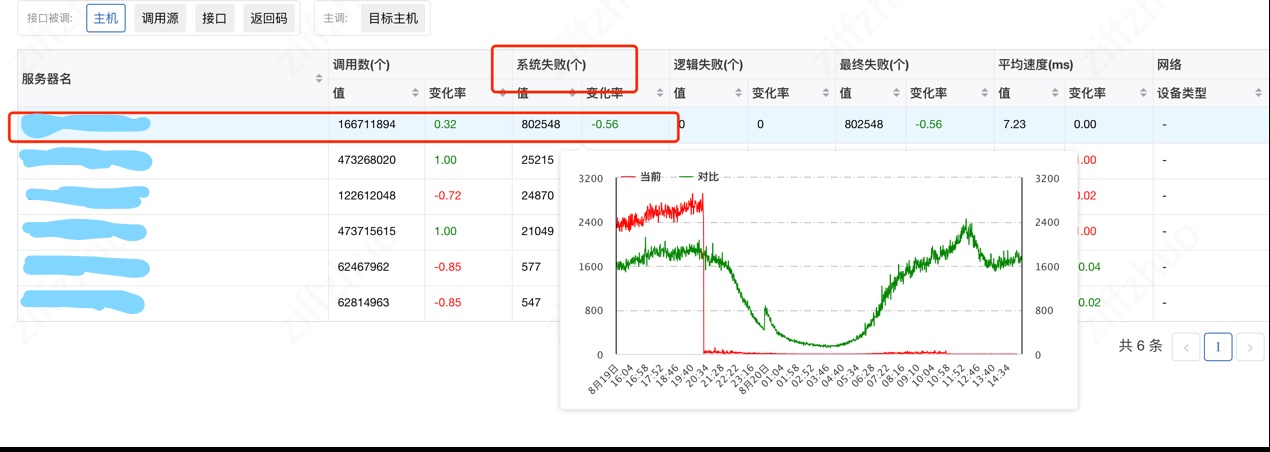
圖5-8 安裝修補程式並關閉統計功能後的效果
針對第二點,我們希望增大連線追蹤表的大小,避免連線丟棄的問題。平臺方及時響應,調整核心引數,保證追蹤表大小大於當前連線數。修改設定後,服務紀錄檔不再列印「table full」,錯誤數量也大為降低。
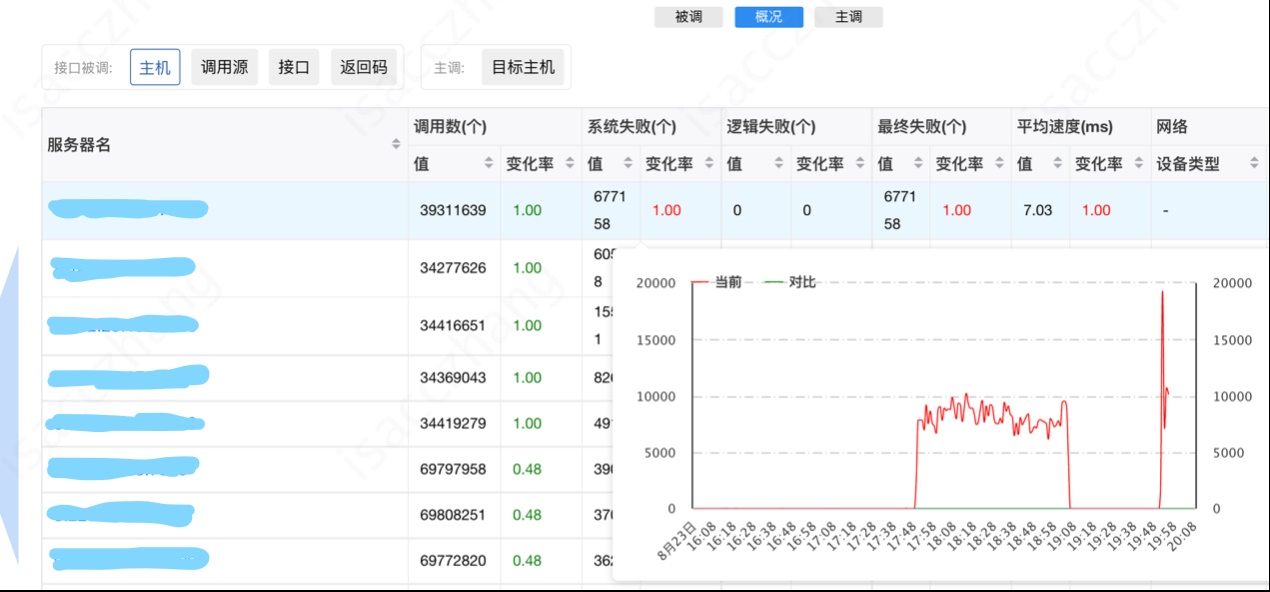
圖5-9 提升 tke 流量權重後錯誤數飆升
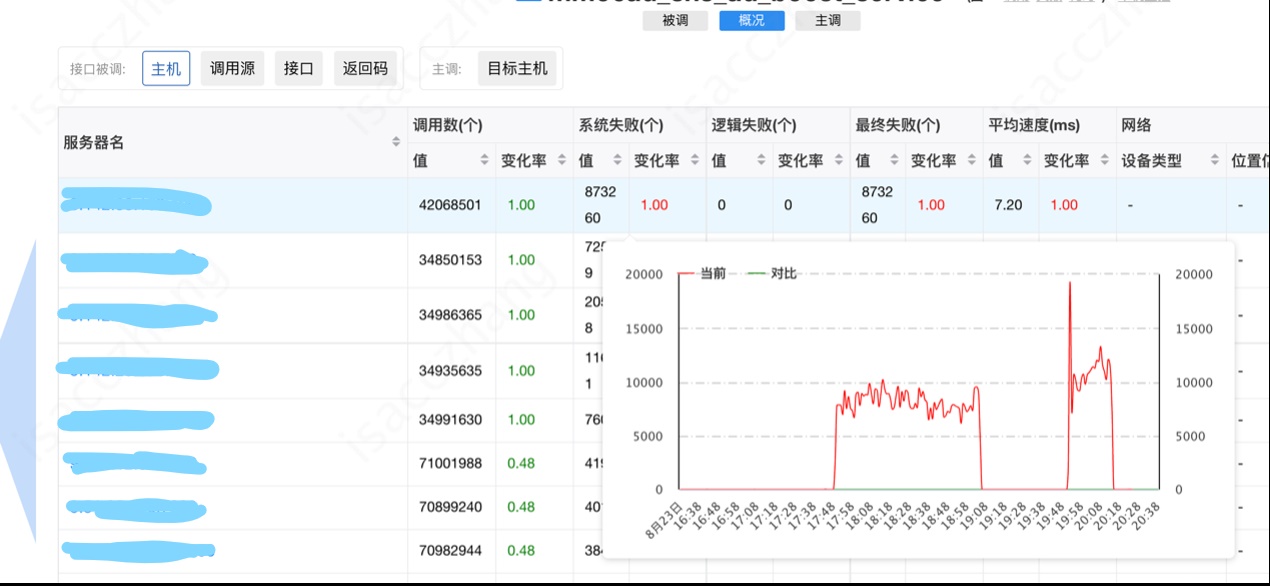
圖5-10 調整雜湊表大小後錯誤數幾乎跌零
在 TKE 平臺方的幫助下,我們共同解決了業務上雲過程中存在的高並行環境下連線失敗問題,成功的將新聞視訊流量的線上服務都遷移至 TKE 平臺。
六、成果展示
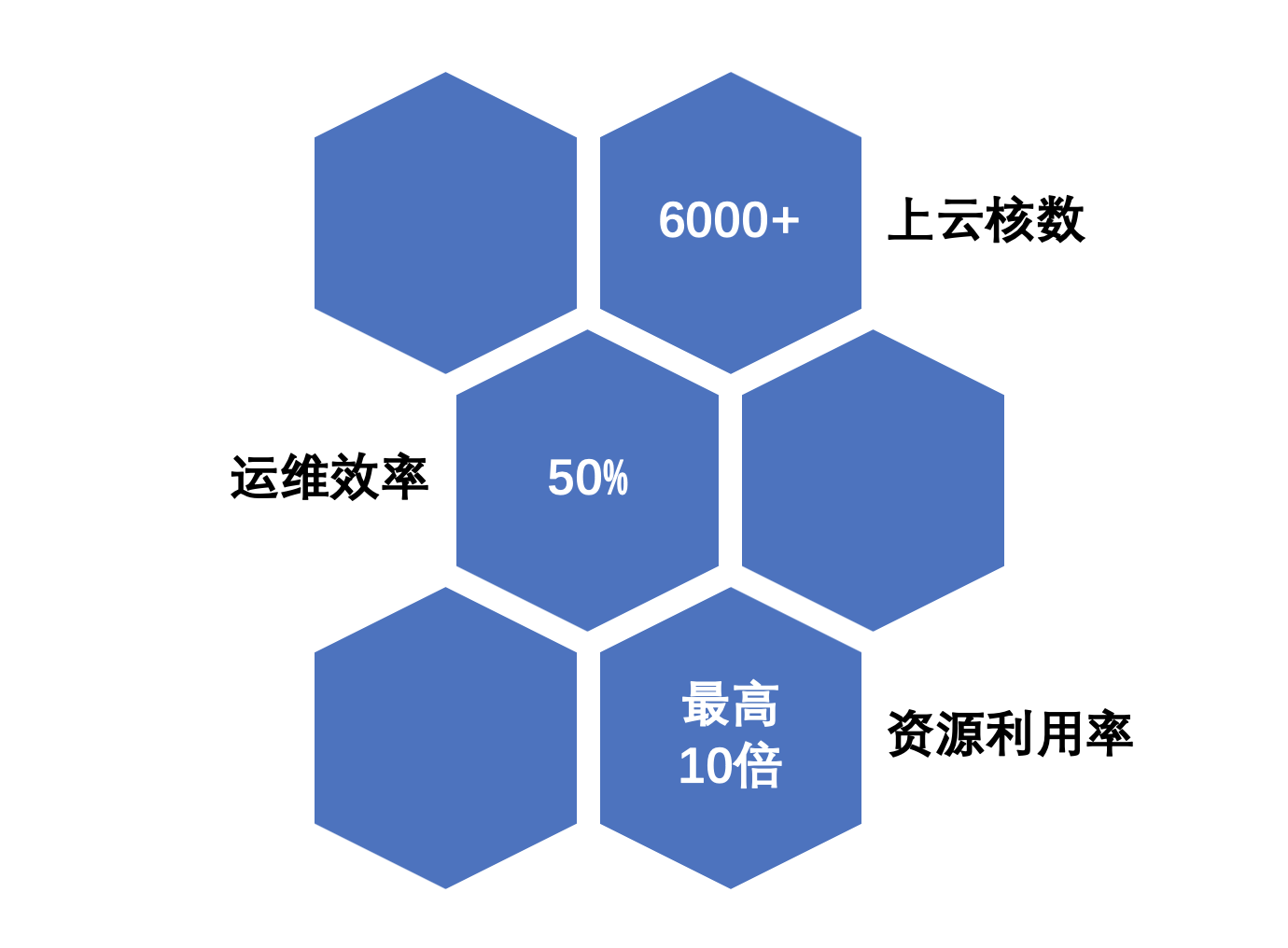
圖6-1 上雲成果
| 比較項 | 上雲前 | 上雲後 |
|---|---|---|
| 資源分配 | 人工申請,彈性低 | 靈活調整 |
| 資源管理 | 人工 | 平臺自動分配 |
| 資源利用 | 經常面臨浪費 | 低谷縮容,高峰擴容,充分利用 |
| 關注點 | 包含機器和服務 | 專注服務 |
表6-1 上雲前後情況對比
新聞視訊廣告團隊積極擁抱雲原生,在 TKE 平臺以及運維團隊的共同作業與支援下,推動150+後臺服務全部上雲,上雲負載累計核心達到6000+,大大提升了運維效率和資源利用率。資源利用率最高提升至原來的10倍,運維效率提升超過50%,上雲過程中,針對服務的特點客製化化改造適配雲原生,沉澱了針對海量服務、離線服務等多套上雲實踐方案,有效提高了服務上雲效率。
關於我們
更多關於雲原生的案例和知識,可關注同名【騰訊雲原生】公眾號~
福利:
①公眾號後臺回覆【手冊】,可獲得《騰訊雲原生路線圖手冊》&《騰訊雲原生最佳實踐》~
②公眾號後臺回覆【系列】,可獲得《15個系列100+篇超實用雲原生原創乾貨合集》,包含Kubernetes 降本增效、K8s 效能優化實踐、最佳實踐等系列。
③公眾號後臺回覆【白皮書】,可獲得《騰訊雲容器安全白皮書》&《降本之源-雲原生成本管理白皮書v1.0》
④公眾號後臺回覆【光速入門】,可獲得騰訊雲專家5萬字精華教學,光速入門Prometheus和Grafana。
【騰訊雲原生】雲說新品、雲研新術、雲遊新活、雲賞資訊,掃碼關注同名公眾號,及時獲取更多幹貨!!
