DCM:一個能夠改善所有應用資料互動場景的中介軟體新秀
摘要:幾乎所有涉及應用資料互動的場景都可以通過DCM來改善應用結構,提升開發與計算效率。
本文分享自華為雲社群《DCM:中介軟體家族迎來新成員》,作者: 石臻臻的雜貨鋪。
DCM是什麼
現代應用無時無刻不在與資料打交道,資料計算無處不在,報表統計、資料分析、業務處理不一而足。當前資料處理的主要手段仍然是以關聯式資料庫為代表的相關技術,雖然使用高階語言(如Java)寫死也能實現各類計算,但遠不如資料庫(SQL)方便,資料庫在當代資料處理中仍然發揮舉足輕重的作用。
不過,隨著資訊科技的發展,儲存與計算分離、微服務、前置計算、邊緣計算等架構與概念的興起,過於沉重、封閉的資料庫在應對這些場景時越來越顯得捉襟見肘。資料庫要求資料入庫才能計算,但面對豐富的多樣資料來源時,資料入庫不僅效率低資源消耗大,實時性也無法保障,而有的資料只是臨時使用卻要入庫持久化就更得不償失了。另外對於微服務、邊緣計算等需要將計算能力前置到應用端的場景,資料庫也很難嵌入使用。
在這樣的背景下,如果有一種不依賴資料庫、具備開放計算能力、能夠與應用嵌入整合使用的資料計算處理技術,那麼這些問題就都能夠很好地解決,這就是資料計算中介軟體(Data Computing Middleware,簡稱DCM)。DCM的應用場景非常廣泛,可以說無處不在,在優化應用開發、微服務實現、儲存過程替代、資料庫解耦、ETL輔助、多樣性資料來源計算、BI資料準備等等多方面都能發揮重要的作用,幾乎所有涉及應用資料互動的場景都可以通過DCM來改善應用結構,提升開發與計算效率。
DCM應用場景
優化應用開發
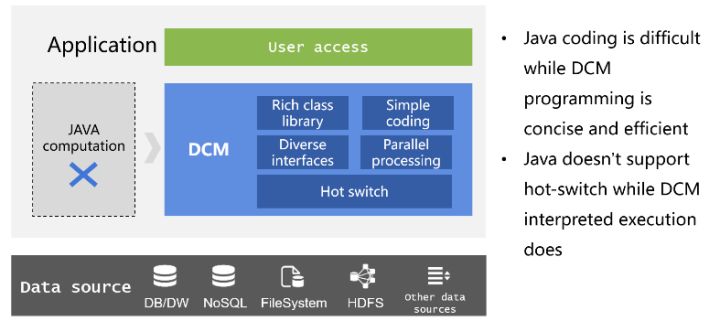
應用中資料處理邏輯只能通過編碼實現,使用原生的Java實現由於缺少必要的結構化計算類庫往往比較困難,即使用新增加的Stream/Kotlin也並沒有明顯改善。藉助ORM技術可以一定程度緩解開發困境,但仍然缺乏專業的結構化資料型別,集合運算不夠方便,同時讀寫資料庫時程式碼繁瑣,複雜計算也難以實現。ORM的這些缺點經常導致業務邏輯的開發效率不僅沒有明顯提升,甚至還大幅降低。此外,這些實現方式還會導致應用結構問題。Java實現的計算邏輯必須與主應用一起部署導致緊耦合,同時由於不支援熱部署開發運維也很麻煩。
如果藉助DCM的敏捷計算、易整合、熱切換等特性,在應用中替代Java實現資料處理邏輯,就可以很好解決上述問題,不僅開發效率提升,還可以優化應用結構,實現計算模組的解耦,同時支援熱部署。
多樣性資料來源計算
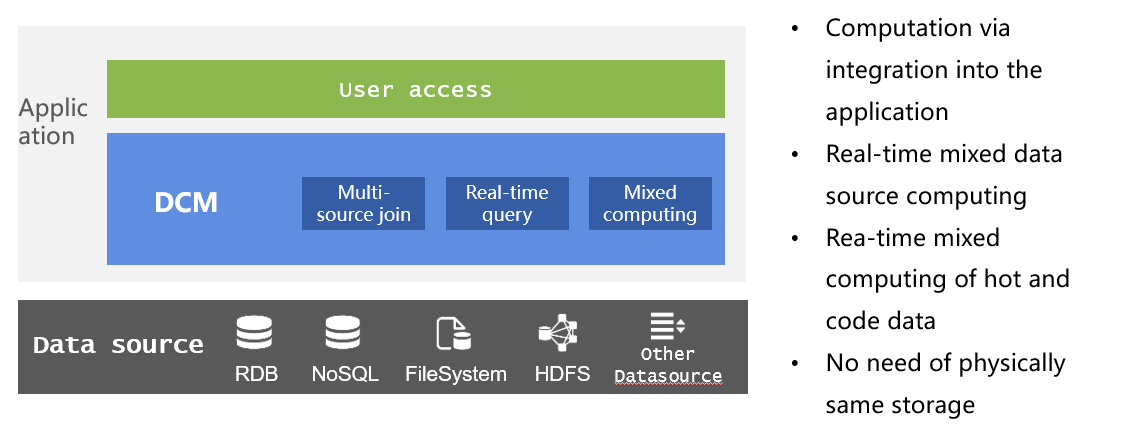
現代應用還經常面臨多樣性資料來源問題,通過資料庫處理不僅需要資料入庫,效率低下,還無法保障資料的實時性。不同資料來源有各自的優勢,RDB計算能力較強,但IO吞吐能力弱;NoSQL的IO效率高,但計算能力很弱;而文字等檔案資料完全沒有計算能力,但使用非常靈活。強迫這些資料入庫就會喪失這些原資料來源的優勢。
通過DCM的多源混算能力,不僅可以直接對RDB、文字、Excel、JSON、XML、NoSQL以及其他網路介面資料進行混合計算,保證資料與計算的實時性,而且還能同時保留各類資料來源的優點,充分發揮其效力。
微服務實現
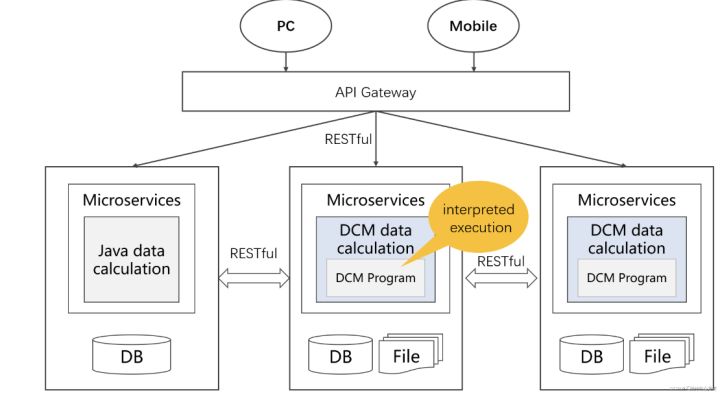
當前微服務實現時仍然大量依賴Java和資料庫實施資料處理,Java的缺點在於實現複雜、無法熱切換;而資料庫由於有「庫」的限制,多源資料要入庫才能計算,靈活性很低,不僅資料時效性無法保證,也無法充分發揮各類資料來源的優勢。
將可整合的DCM分別嵌入中臺或微服務的各個環節完成資料採集整理、資料處理以及前置的資料計算任務,利用開放的計算體系可以充分發揮多資料來源自身的優勢,靈活性增強。多源資料處理、實時計算、熱部署這些問題均能迎刃而解。
儲存過程替代
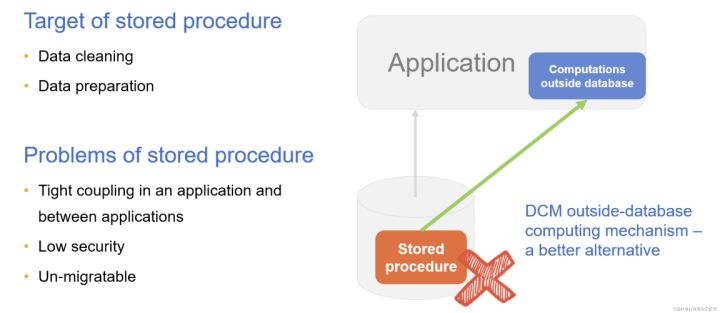
以往為了實現複雜計算或整理資料常常會使用儲存過程,儲存過程在庫內計算有一定優勢,但缺點也很明顯。儲存過程缺乏可移植性,編輯偵錯困難,建立和使用儲存過程需要較高許可權存在安全問題,為前端應用服務的儲存過程還會造成資料庫與應用緊耦合。
通過DCM將儲存過程外接到應用中,可以實現「庫外儲存過程」,資料庫則主要用於儲存,將儲存過程從資料庫中解耦出來就可以很好解決儲存過程帶來的各類問題。
報表BI資料準備
為報表提供資料準備是DCM的重要場景,以往使用資料庫為報表準備資料存在實現難度高、耦合性強等問題,而報表本身計算能力不足又無法完成很多複雜計算。通過DCM的庫外強計算能力就可以為報表提供一個專門的資料計算層,不僅可以解耦資料庫為資料庫減負,還可以彌補報表工具自身的計算能力不足。邏輯上分層後,報表開發維護都很清爽。
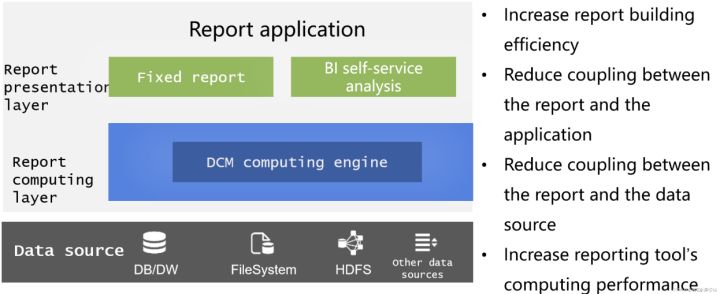
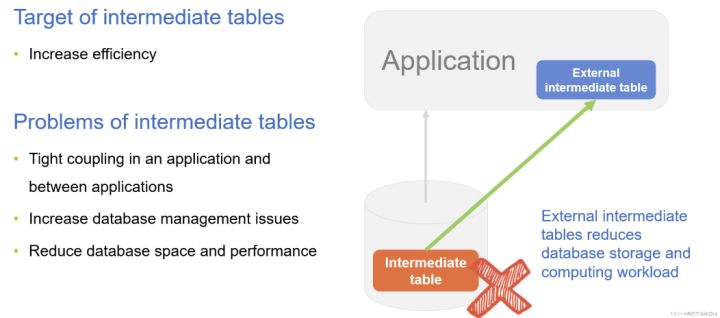
中間表消除
有時為了加快查詢效率事先將要查詢的資料加工成結果表儲存在資料庫中,這就是中間表。另外,有些複雜計算需要儲存中間結果也會存成中間表;多樣資料來源也要先存成中間表才能在資料庫中混合計算。與儲存過程類似,中間表一旦建立就可能被多個應用(模組)使用,造成應用與資料庫的緊耦合,同時由於中間表無法輕易刪除,數量會越積越多。中間表數量過多會引發資料庫容量和效能問題,儲存中間表需要空間,加工中間表則需要資料庫計算資源。
通過DCM可以將中間表外接到檔案系統,利用DCM實施計算,解耦資料庫減輕資料庫儲存和計算負擔。這裡的關鍵是DCM使得檔案也擁有了計算能力,所以才能將庫內的中間表置於庫外,原來中間表放在庫內主要為了獲得資料庫的計算能力,現在有DCM的計算能力中間表存成什麼形式就不重要了,外接到檔案系統反而更優。
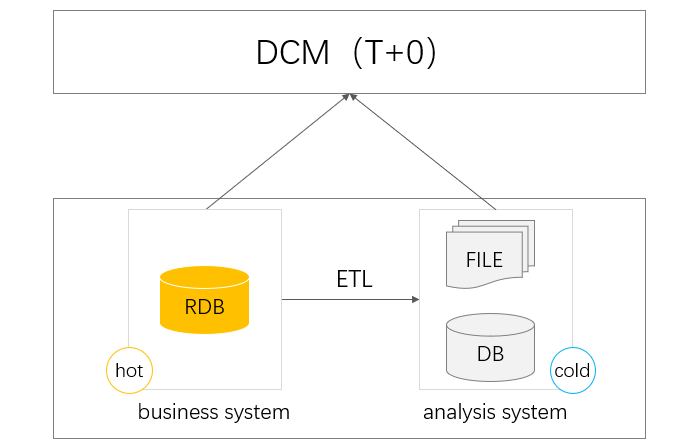
T+0查詢
資料量積累到一定程度時基於生產庫查詢會影響交易,這時就會將大量的歷史資料剝離到其他歷史資料庫中,進行冷熱資料分離。這時如果要查詢全量資料就要完成跨庫查詢、冷熱資料路由等工作。資料庫對於跨庫查詢尤其是跨異構庫存在很多問題,不僅效率低下,還存在資料傳輸不穩定、可延伸性低等很多不足,無法很好實現T+0全量資料查詢。
而這些問題都可以通過DCM來解決,由於具備獨立且完善的計算能力,可以分別從不同的資料庫取數計算,因此可以很好適應異構資料庫的情況,還可以根據資料庫的資源狀況決定計算是在資料庫還是DCM中實施,非常靈活。在計算實現上,DCM的敏捷計算能力還可以簡化T+0查詢中的複雜計算,提升開發效率。
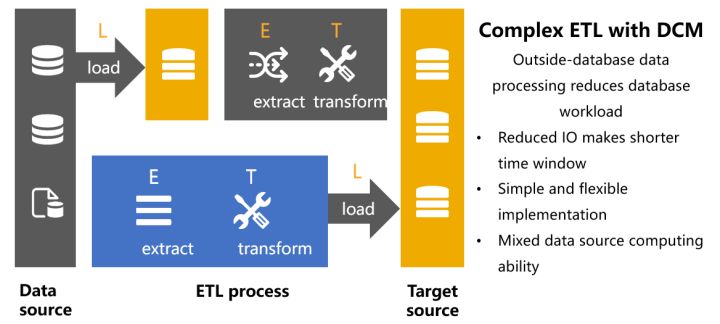
ETL
ETL需要對資料淨化轉換再載入到目標端,但由於源端資料可能來源多處(文字、資料庫、web)加上資料質量參差不齊,因此E和T這兩個步驟會涉及大量資料計算。目前除了資料庫以外,其他資料來源並不太具備這樣的計算能力,想要完成這些計算就要先載入到資料庫再進行,這就形成了LET。大量無用的資料儲存在資料庫中會佔用大量儲存空間,極易引發容量問題。而將清洗和轉換的計算工作都壓給資料庫又會增加資料處理時間,再疊加大量未經清洗轉換的原始資料入庫時間,有限的ETL時間視窗很可能不夠,如果無法在規定時間完成ETL工作就會影響第二天的業務。
在ETL任務中引入DCM就可以按順序完成清洗E、轉換T、載入L,解決LET面臨的各種問題。藉助DCM的開放計算能力,在庫外對多源資料實施清洗轉換,DCM擁有強計算能力可以應對各類複雜計算,最後將整理後資料裝在到目標端,實現真正的ETL。
DCM特性
可以看到,DCM的應用場景非常廣泛。那麼要很好應對這些場景,一個優秀的DCM應該具備哪些特點呢?
相容性(Compatible)
首先DCM需要具備很好的相容性,可以跨平臺使用,各類作業系統、雲平臺、應用伺服器下均可以很好執行,這決定了DCM的使用範圍。
此外,相容性還意味著可以相容多樣性資料來源,無論何種資料來源都可以直接使用並進行混合計算,這要求DCM擁有足夠強的開放性。
熱部署(Hot-deploy)
資料處理是一種高頻且穩定性較差的場景,在業務開展過程中經常要新增修改計算任務,這就要求DCM應該具備熱部署特性,修改資料處理邏輯無需重啟應用(服務)就能生效。
高效能(Efficient)
計算效能是資料計算場景重點關注的方面,有時會成為最主要的關注點,所謂天下武功無快不破。DCM應該能夠高效處理資料,提供諸如高效能運算庫、高效能存方案、平行計算等高效能保障機制。
敏捷性(Agile)
敏捷性要求DCM能夠快速實現資料處理邏輯,具備完備的計算能力,尤其面對複雜計算場景通過足夠簡單的編碼就能完成資料處理,同時可以高效執行。這需要DCM提供敏捷程式設計機制和易於使用的開發環境等支援。
擴充套件性(Scalable)
當計算容量無法滿足需要時,DCM應該具備靈活的橫向擴充套件能力。擴充套件性對當代應用十分重要,擴充套件能力的好壞決定了DCM的上限。
整合性(Embeddable)
DCM應該能夠很好與應用整合嵌入使用,在應用內充當計算引擎,作為應用的一部分隨應用一起打包部署。這樣應用本身就獲得了強計算能力,不再強依賴資料庫後,可以很好應對儲存與計算分離、微服務和邊緣計算等場景。並且,良好的整合性還是敏捷性的另一方面體現,DCM很輕,隨時隨地都能嵌入與應用結合使用。
如果將DCM這幾個特性的首字母組合起來,與CHEESE(乳酪)很接近(CHEASE),而DCM的作用就像夾在漢堡裡的乳酪一樣,如果缺少,味道和營養都會差很多。

這樣能否作為理想的DCM就可以使用CHEASE的標準去考察。這裡不妨看一下一些主流技術對DCM的滿足情況。
現有技術的情況
SQL
資料庫是使用SQL的主要陣地,資料庫通常具備較強的計算能力,一些頭部資料庫的計算效能也很強,基本可以滿足高效能(E)的需要。而且資料庫過於封閉,資料要入庫才能計算,無法很好滿足多樣性資料來源場景的需要,相容性(C)較差。
對於整合性(E),由於絕大部分資料庫都是獨立使用的,極少數(如SQLite)支援嵌入的資料庫往往功能和效能都達不到要求,因此資料庫幾乎不滿足整合性的要求。
而SQL作為專用的集合計算語言,實現簡單計算很方便,但複雜計算用SQL表達很繁瑣,經常要巢狀多層,實際業務中經常能看到幾千行的「長」SQL,不僅難寫,維護也不方便,所以SQL不太符合敏捷性(A)的要求。
與資料庫類似的Hadoop相關技術也存在同樣的問題,封閉性導致相容性差、敏捷性不足、基本不具備整合性等缺點,雖然在擴充套件性方面表現要優於資料庫,但總體並不符合DCM的要求。Spark的表現要略好,但Scala不支援熱部署,實現複雜計算也不夠方便,而Spark SQL仍然存在SQL的那些問題。這些技術都過於沉重,很難滿足DCM在敏捷性、整合性、熱部署等方面的需要。
Java
Java作為原生的程式語言可以很好跨平臺執行,也可以通過編碼完成多資料來源計算任務,因此相容性(C)很好。而且對於大部分都採用Java開發的應用來說,整合性(E)也不在話下。
但Java的缺點也很明顯,作為編譯型語言無法實現熱部署(H)。由於缺少必要的結構化計算類庫完成簡單的分組彙總也要幾十行程式碼,就別提複雜計算了。雖然現在微服務架構中也經常使用Java寫死完成資料處理,但其實計算實現要比SQL複雜得多,沒辦法,計算前置就不能再用資料庫,難寫也得挺著,因此敏捷性(A)極其不足。雖然在Java8以後引入了Stream,但計算能力並沒有實質改善(Kotlin也存在類似的問題)。
使用Java雖然理論上也能實現各類高效能演演算法,但是如果只是為某個應用/專案服務,要實現這些高效能演演算法封裝投入就太大了,因此從實際應用角度來看,Java並不具備高效能(E)特性。擴充套件性(S)也存在同樣的問題。因此綜合來看,Java很難作為優秀的DCM技術使用。
Python
Python作為大火的一類計算技術不得不提一下。Python的相容性(C)較強,無論是跨平臺還是對接多資料來源都能支援。尤其是豐富的資料處理包讓Python的適用範圍極廣。
Python在結構化資料處理相比於Java等技術有相當的優勢,但卻難說很完善,尤其在處理有序分組等複雜計算時會很繞,Python在敏捷性(A)上略有所欠缺。
不僅如此,Pandas的效能(E)也往往達不到要求,尤其針對巨量資料量計算方面,這跟演演算法的實現效率有很大關係,敏捷語法可以很方便地實現高效能演演算法,反之就很困難。同樣,在擴充套件性(S)方面,Python也不盡如人意,本質上來講作為程式語言的Python要擁有良好的擴充套件性需要投入大量資源開發完成,這點與Java是一樣的。
Python最大的問題是整合性(E),很難與現有應用整合在一起使用。雖然可以通過諸如sidecar模式進行服務間呼叫,但本質上與DCM要求與應用結合嵌入在一起(同一個程序)相去甚遠。Python的主要應用場景並非像Java一樣做企業級應用開發,各有用途,勉強不來。歸根到底,專業的事兒還需要專業的工具來做。
專業資料計算中介軟體SPL
開源集算器SPL是專業的資料計算中介軟體,具備不依賴資料庫的完備計算能力,同時開放的計算能力可以混合計算多樣性資料,同時解釋執行的SPL天然支援熱部署,良好的整合性可以很方便嵌入應用中,讓應用擁有強計算能力,充分發揮DCM的效力。
相容性
SPL採用Java開發,跨平臺能力與Java一致,可以很好執行在各類作業系統、雲平臺下。而在多資料來源支援方面,SPL具備開放的計算能力,可以對接多種資料來源,RDB、NoSQL、CSV、Excel、JSON/XML、Hadoop、RESTful、Webservice都可以直接對接並進行混合計算,不需要入庫,資料實時性和計算實時性都可以很好保障。

多源計算支援很好解決了原來資料庫無法跨源計算、無法計算外部資料的問題,再加上SPL完備的計算能力和相對SQL更簡潔的語法,對於應用來說就獲得了與資料庫相當(超過)的計算能力。
除了原生計算語法,SPL還提供了SQL支援(相當SQL92標準),可以使用SQL查詢文字、Excel、NoSQL等非RDB資料來源,這樣就極大方便了熟悉SQL的應用開發人員。

DCM只有在開放計算體系的支援下才能擁有足夠強的相容性,才能適應更多的應用場景。
熱部署
SPL採用解釋執行機制,天然支援熱部署。這樣對於一些穩定性差經常需要新增、修改計算邏輯的業務(如報表、微服務)非常友好。
高效能
在效能方面,SPL提供了諸多高效能演演算法與高效能儲存機制。在前面提到的DCM消除中間表和ETL場景中,資料往往要落地成檔案儲存在資料庫外,這時採用SPL的檔案格式儲存可以獲得比文字等開放格式高很多的效能。
SPL提供了兩種儲存型別:集檔案和組表。集檔案採用了壓縮技術(佔用空間更小讀取更快),儲存了資料型別(無需解析資料型別讀取更快),支援可追加資料的倍增分段機制,利用分段策略很容易實現平行計算,保證計算效能。組表支援列式儲存,在參與計算的列數(欄位)較少時會有巨大優勢。組表上還實現了minmax索引,同時支援倍增分段,這樣不僅能享受到列存的優勢,也更容易並行提升計算效能。
SPL還支援各種高效能演演算法。比如常見的TopN運算,在SPL中TopN被理解為聚合運算,這樣可以將高複雜度的排序轉換成低複雜度的聚合運算,而且很還能擴充套件應用範圍。
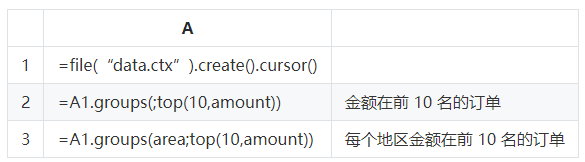
這裡的語句中沒有排序字樣,也不會產生大排序的動作,在全集還是分組中計算TopN的語法基本一致,而且都會有較高的效能,類似的演演算法在SPL中還有很多。
SPL也很容易實施平行計算,發揮多CPU的優勢。SPL有很多計算函數都提供並行機制,如檔案讀取、過濾、排序只要增加一個@m選項就可以自動實施平行計算,簡單方便。同時也可以顯示編寫並行程式,通過多執行緒並行提升計算效能。
敏捷性
SPL提供了原生的計算語法和簡潔易用的IDE環境,在IDE中不僅可以很方便編碼偵錯,過程計算的每步計算結果都可以實時檢視,網格式編碼程式碼天然整齊,通過格子名稱參照中間計算結果無需定義變數,簡單方便。
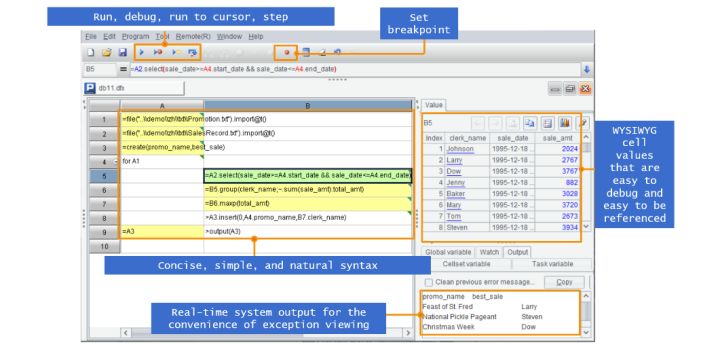
同時,基於SPL豐富的計算類庫實施結構化資料計算更方便,分組彙總、迴圈、過濾、集合運算、有序計算等應有盡有。

SPL尤其擅長複雜計算,原來SQL要巢狀很多層的計算使用SPL卻可以很方便實現。比如根據股票記錄計算某隻股票最長連續上漲多少天?SPL就比SQL簡單很多。
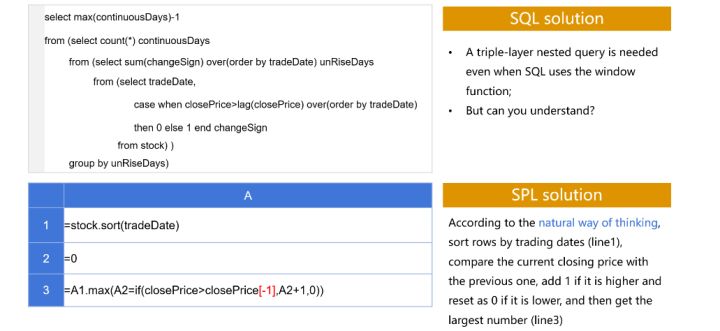
上面SQL巢狀了3層,讀起來都很繞就別提寫了;下面的SPL完全按照自然思維、簡單3行就能實現,高下立判。
良好的敏捷性不僅能提升開發效率,很多高效能演演算法通過SPL可以很方便實現。演演算法不僅要能想出來,還要能實現,最好實現還簡單,SPL提供了這種可能。
擴充套件性
對於計算效能要求較高的場景,SPL還可以部署單獨的計算服務,同時支援多機分散式叢集,支援負載均衡和容錯機制,當計算資源達到上限時可以通過橫向擴容增加算力,具備良好的擴充套件性。
在分散式計算中,使用者可根據資料和計算任務的特點靈活客製化資料分佈及冗餘方案,有效減少節點間資料傳輸量,以獲得更高效能,實現可控資料分佈。
SPL採用無中心叢集設計,叢集沒有永久的中心主控節點,允許程式設計師用程式碼控制參與計算的節點,從而有效避免單點失效。同時SPL會根據每個節點空閒程度(執行緒數量)決定是否分配任務,實現負擔和資源的有效平衡。
在容錯方面,SPL提供內外存兩種資料容錯機制,外存冗餘式容錯和記憶體備胎式容錯。支援計算容錯,節點故障時自動將該節點計算任務遷移掉其他節點繼續完成。
整合性
作為DCM與應用結合方面,SPL提供了標準JDBC/ODBC/RESTful介面,應用可以像呼叫儲存過程一樣請求SPL計算結果。
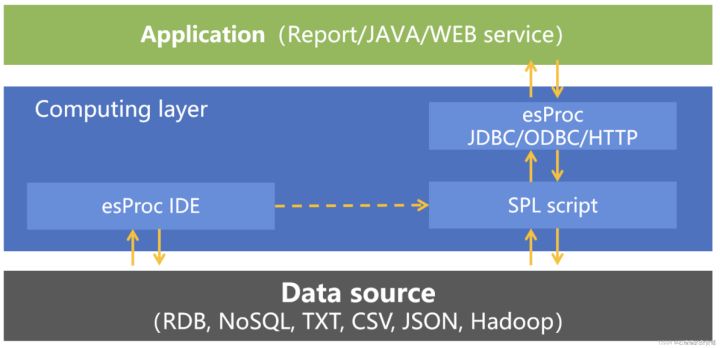
邏輯上SPL作為DCM介於應用和資料來源之間實施資料處理,對上提供計算服務,對下遮蔽多樣性資料來源差異,充分彰顯了DCM的重要作用。
JDBC呼叫SPL 程式碼範例:
Class.forName("com.esproc.jdbc.InternalDriver"); Connection conn =DriverManager.getConnection("jdbc:esproc:local://"); CallableStatement st = conn.prepareCall("{call splscript(?, ?)}"); st.setObject(1, 3000); st.setObject(2, 5000); ResultSet result=st.execute();
綜合起來,從DCM的6個特性(CHEASE)來看,SPL在各方面能力綜合起來十分均衡,整體遠優於其他技術,是DCM的理想選擇。
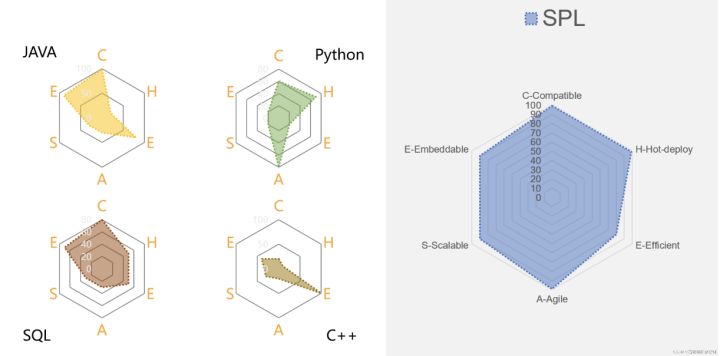
SPL資料