做一個能對標阿里雲的前端APM工具(下)
上篇請存取這裡做一個能對標阿里雲的前端APM工具(上)
樣本多樣性問題
上一小節中的實施方案是微觀的,即單次性的、具體的。但是從宏觀上看,我需要保證效能測試是公允的,符合大眾預期的。為了達到這種效果,最簡單的方式就是保證測試的多樣性,讓足夠多人存取產生足夠多的樣本來,但這對於一個為個人服務的工具網站來說是不現實的。
於是我打算藉助機器的力量,在世界各地建造機器人程式來模擬存取。機器人程式原理非常簡單,藉助 headless chrome 來模擬使用者的存取:
const url = 'https://www.site2share.com/folder/20020507';
const browser = await puppeteer.launch();
const page = await browser.newPage();
await page.goto(url);
await page.waitForSelector('.single-folder-container');
await page.waitForTimeout(1000 * 30);
browser.close();
注意程式會等到 .single-folder-container 元素出現之後才進入關閉流程,在關閉前會等待30秒鐘來保證有足夠的時間將指標資料上傳到 Application Insights。
為了達到重複存取的效果,我給機器人制定的執行策略非常簡單,每五分鐘執行一次。這種輕量級的定時任務應用非常適用於部署在 Azure Serverless 上,同時 Azure Serverless 也支援在部署時指定區域,這樣就能達到模擬全球不同地區存取的效果
雖然每一個 Serverless Function 都能設定獨立的執行間隔,但考慮到可維護性,比如將來希望將5分鐘執行間隔提高到2分鐘時不去修改27裡的每一個 function,我決定將所有 function 交給 Azure Logic App 進行管理
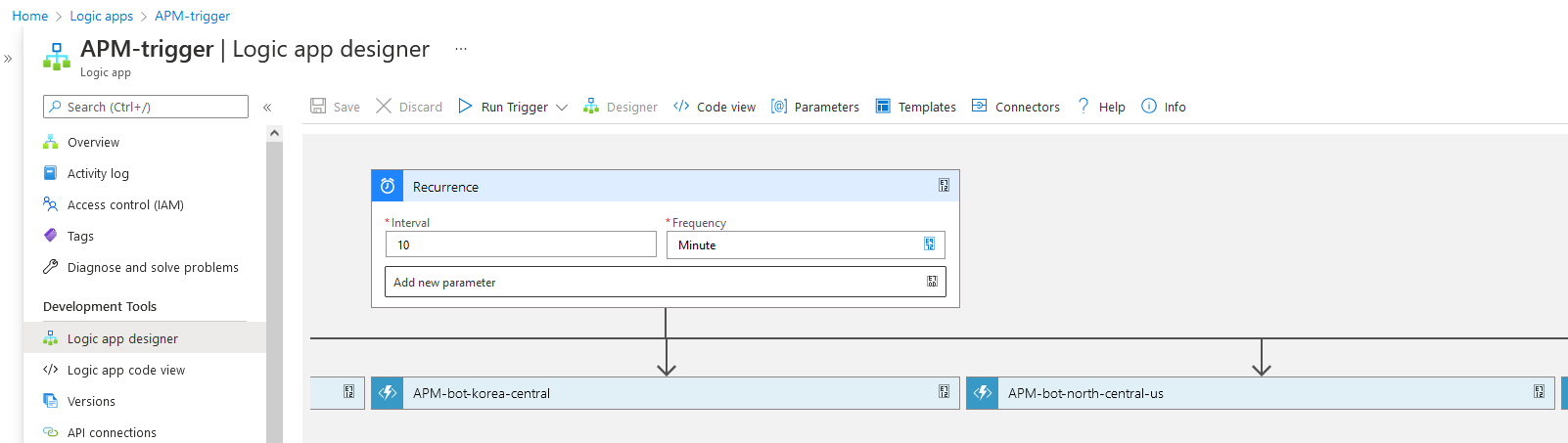
Azure Logic App 在我看來是一款視覺化低程式碼工具。它能夠允許非程式設計人員以點選拖拽的形式建立工作流。初始化變數、分支判斷、迴圈、響應或者傳送網路請求,都可以僅用滑鼠辦到。
我們的場景總結下來就兩句話:
- 距離上次進行效能測試是不是已達五分鐘
- 如果是的話再次傳送效能測試請求
那麼我們可以依次建立一套工作流
- 工作流的觸發器為一個定時任務,每十分鐘執行一次
- 定時任務執行時連帶執行所有的 Azure Function
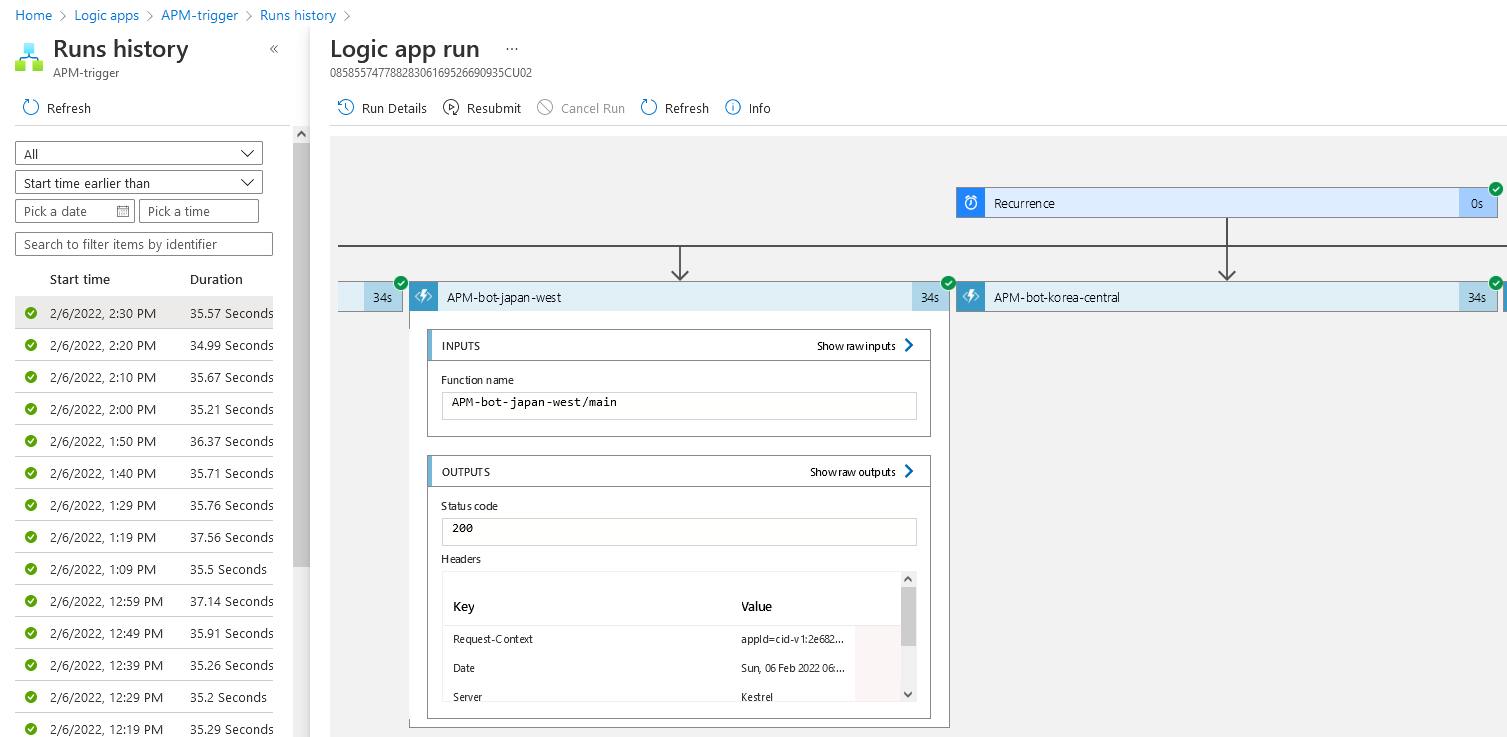
Azure Logic App 還會將每次的執行情況記錄下來,甚至每個函數的輸入和輸出,某種意義上這也起到了監控執行的作用
審視資料,發現問題
工具開發完成之後不間斷的執行了七天,這七天時間內共產生了 219613 條資料。看看我們能從這二十萬資料鍾能發現什麼
首先我們要看一個最重要的指標:關鍵元素的出現時機
customMetrics
| where timestamp between (datetime(2022-02-01) .. datetime(2022-02-06))
| where name has 'folder-detail:visible'
| extend location =strcat(client_City, ":", client_StateOrProvince, ":", client_CountryOrRegion)
| summarize metric_count=count(), avg_duration=round(avg(valueMax)) by location
| where metric_count > 100
| order by avg_duration asc
指標資料我按照國家地區排序,在我看來地區會是影響速度的關鍵因素,最終結果如下。抱歉我使用的名稱是 avg_duration 這個有誤導的名稱,實際上這個指標應該是一個 startTime,即從瀏覽器開始載入頁面的開始為起點,到看到元素的時間。下面的 first-contentful-paint 同理
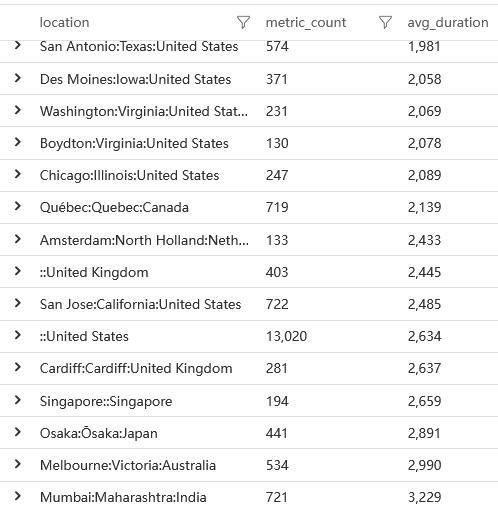
從肉眼上我們可以感知到,大部分使用者會在3秒左右才會看到實質性內容。接下來我們要做的就是探索3秒鐘的時間去哪了。
順便也可以查詢一下瀏覽器提供的 first-contentful-paint 資料如何。上面的查詢語句在之後會頻繁被用到,所以我們可以提取一個函數出來
let queryMetricByName = (inputName: string) {
customMetrics
| where timestamp between (datetime(2022-02-01) .. datetime(2022-02-06))
| where name has inputName
| extend location =strcat(client_City, ":", client_StateOrProvince, ":", client_CountryOrRegion)
| summarize metric_count=count(), avg_duration=round(avg(valueMax)) by location
| where metric_count > 100
| order by avg_duration asc
};
接著用這個函數查詢 first-contentful-paint 指標
queryMetricByName('browser:first-contentful-paint')
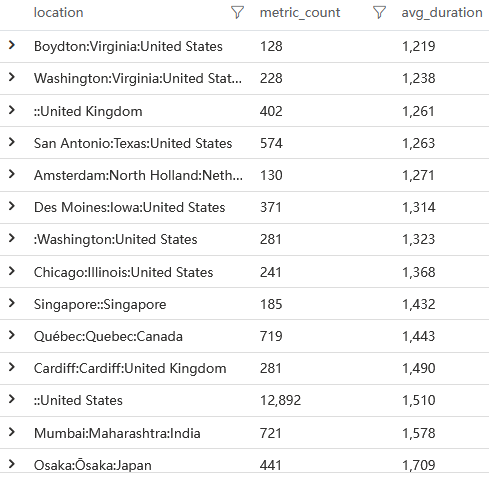
瀏覽器認為使用者在 1.5 秒左右就看到了一些有用的內容了,但是從我們剛剛查詢到的關鍵元素出現時機看來並非如此
我們先看看指令碼的資源載入情況,以 runtime 指令碼為例,我們看看它的平均載入時間
queryMetricByName('resource:script:https://www.site2share.com/runtime-es2015.ffba78f539fb511f7b4b.js')
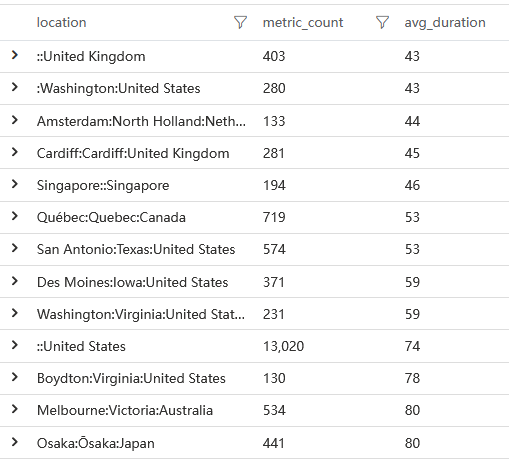
平均時間不過 100ms
而 http 請求指標資料呢
queryMetricByName('resource:xmlhttprequest')
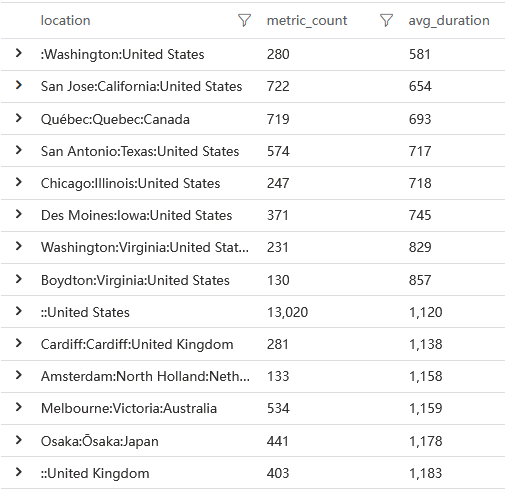
相比資源載入而言,平均1s的請求時長已經是資源載入時長的好幾倍了,它有很大的嫌疑。接著我們繼續看後端 SQL 查詢資料效能
queryMetricByName('APM:GET_SINGLE_FOLDER:FIND_BY_ID')

首先要理解一下為什麼這裡只有一類地理位置的資料,因為之前所有的前端資料都又不同地區的機器人感知產生。因為我的後端伺服器只有一臺。雖然機器人從世界各地存取,但是查詢總髮生在這一臺伺服器上
這裡就很有意思了。也就是說平均請求時間我們需要花上一秒鐘,但是實際的 SQL 查詢時間只需要100毫秒
為了還原犯罪事實,我們不妨從選取一次具體的請求,看看從後端到前端的時間線是怎麼樣的。這個時候 Application Insights 的 Telementry Correlation 的功能就體現出來了,我們只需要指定一個 operation_id 即可
(requests | union dependencies | union pageViews | union customMetrics)
| where timestamp > ago(90d)
| where operation_Id == "57b7b55cda794cedb9e016cec430449e"
| extend fetchStart = customDimensions.fetchStart
| project timestamp, itemType, name, valueSum, fetchStart, id, operation_ParentId, operation_Id, customDimensions
| order by timestamp asc
我們於是得到了所有的結果
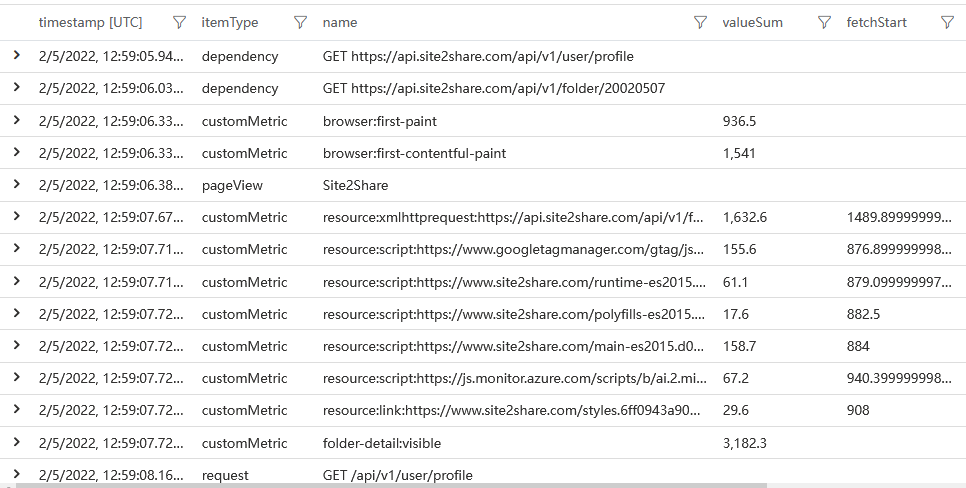
我們只需要 fetchStart 和 valueSum (也就是 duration) 就可以把整個流程圖畫出來
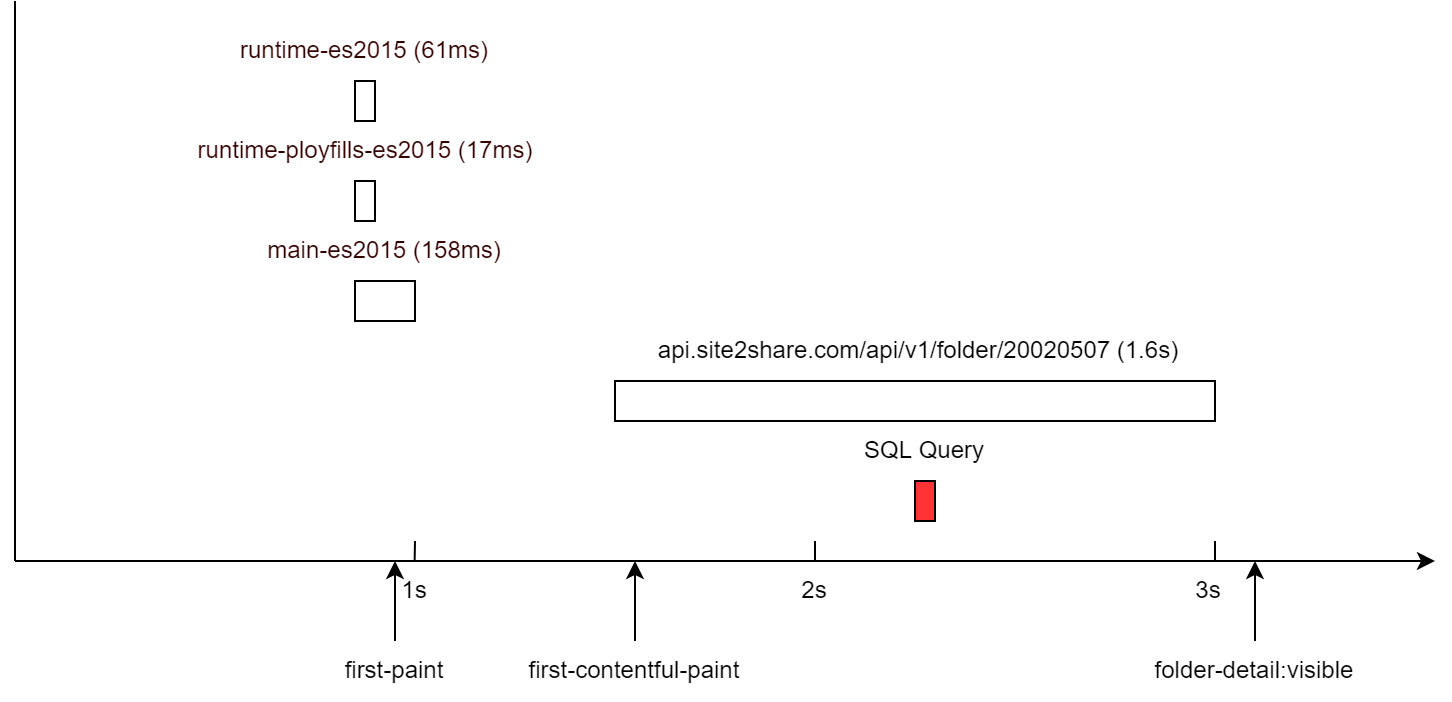
指令碼資源在1s鍾之內就載入完畢了。很明顯,瓶頸在於介面的 RTT(Round-Trip Time)太長。抱歉沒錢在世界各地部署後端節點。
總結
我自己寫到這裡覺得這篇文章有炫技或者是多此一舉的嫌疑。因為即使沒有這套工具。憑藉工程師的經驗,你也應該大致能猜到問題出在哪。
首先肯定不會是前端資源,一方面在多次存取的場景中瀏覽器的快取機制不會讓資源載入成為瓶頸;其次前端我使用的是 Azure Static Web App 服務,在 Azure CDN 的加持下即使是首次存取靜態資源也不會是問題
至於 SQL 效能,你一定要相信商用的 MySQL 效能絕對比你本地開發環境的 MySQL 效能還要好。對這種體量的應用和查詢來說,你的程式碼想把查詢效能變得很差都很難。
所以問題只可能出現在介面的 RTT 上。
但我不認為這個方案無價值可言,對於我個人來說一個切實可行且能夠落地的程式碼會比所謂摘抄自教科書上所謂的業界方案更重要;另一方面我在這個方案上看到了很多種可能性,比如它可以支援更多種類的指標採集,又比如利用 Headless Chrome 自帶的開發者工具我們可以洞見更多網站潛在的效能問題,也許者幾十萬條資料還能夠幫助我們預測某時某刻的效能狀況。
對比阿里
阿里雲有兩個工具我們可以拿來對比,一個是阿里雲的前端前端效能監控工具
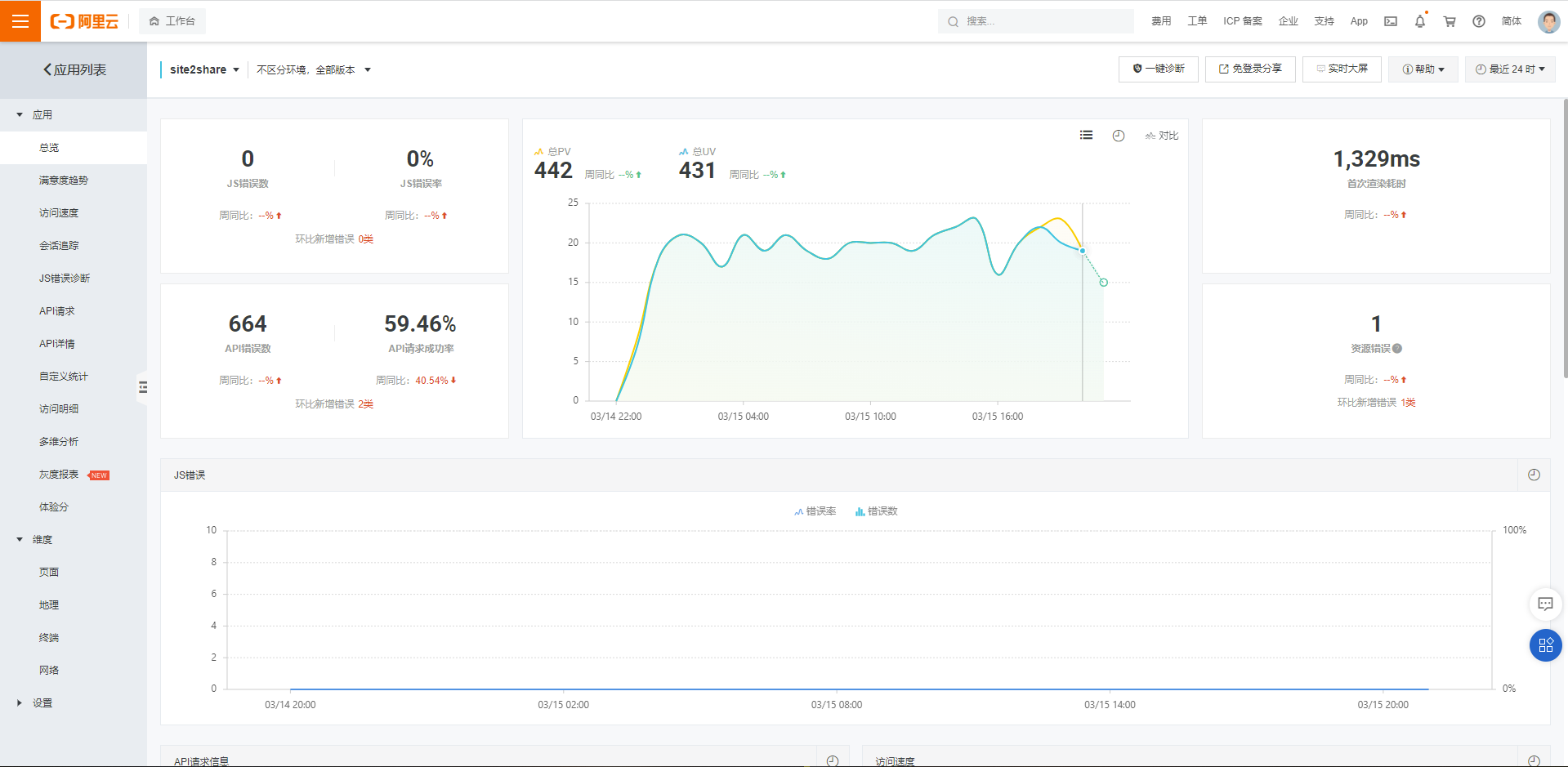
我沒法將整個頁面截圖給你,但是總體看來,統計的資訊有
• JS錯誤資訊
• API請求資訊
• PV/UV
• 頁面效能(首次渲染耗時,完全載入時間)
• 存取的各個維度(地理位置、網路、終端分佈)
從上圖的左側子選單可以看出,對每一類資訊它都已經給出了預訂製的報告詳情。你可以把它理解為對於 Application Insights 資料進行加工後顯得對人類更友好的產品。因為 Application Insights 是非常底層儲存於表中的資料,你需要自己編寫查詢語句然後生成報表
另一個和我們功能很像的工具是雲撥測,在這個工具內你可以選擇測試發起的城市,來看看不同人群對於你網站的效能體驗如何。比如我選擇了美國和北京
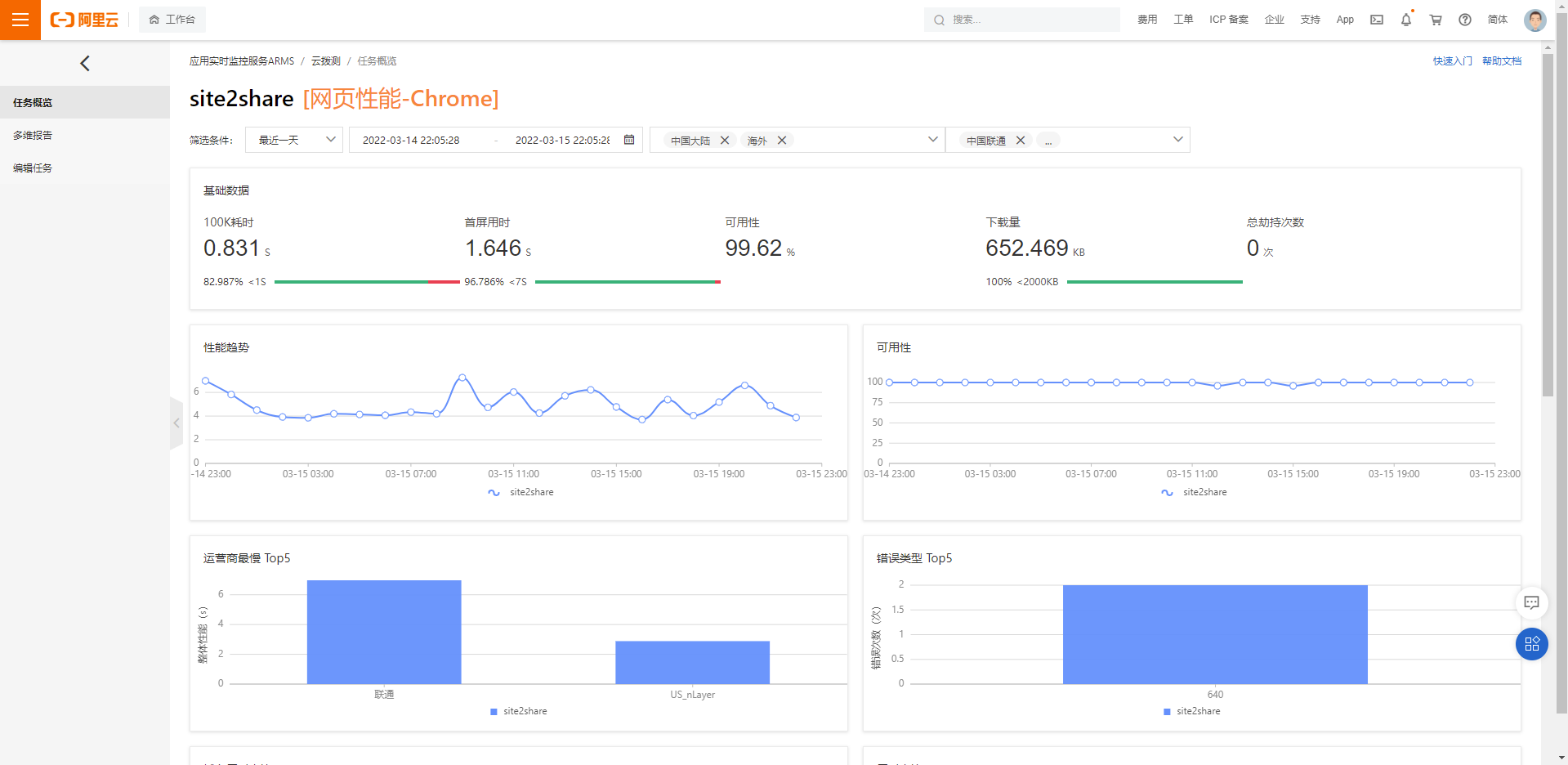
甚至對於每一次存取,我們都能看到它的詳細資料,甚至包括我們之前說的 DNS 的情況
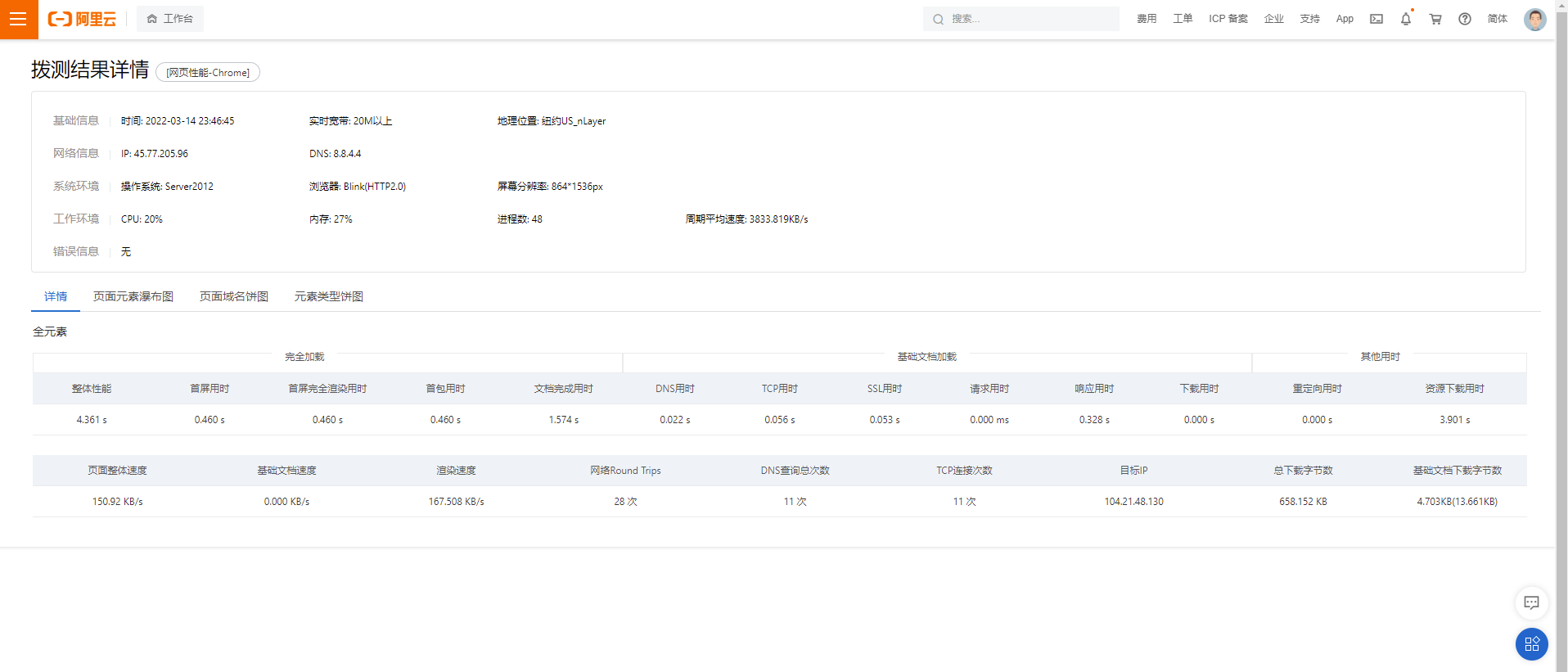
如此強大的功能不是我個人開發出的工具能夠匹敵的。
但是面對這些無所不能的工具,假設它們能把成千上百個指標準確的呈現在你面前,我想問的是,你真的需要它們嗎?或者說,你關心的究竟是什麼?
你可能會喜歡:
- 做一個能對標阿里雲的前端APM工具(上)
- 效能指標的信仰危機
- React + Redux 效能優化(一):理論篇
- React + Redux 效能優化(二)工具篇: Immutablejs
- Mobx 與 Redux 的效能對比
- 用 100 行程式碼提升 10 倍的效能
- 儀表盤場景前端優化經驗談
- 讓我們再聊聊瀏覽器資源載入優化
- Javascript高效能動畫與頁面渲染