基於 GraphQL 的 BFF 實踐
隨著軟體工程的發展,系統架構越來越複雜,分層越來越多,分工也越來越細化。我們知道,網際網路是離使用者最近的行業,前端頁面可以說無時無刻不在變化。前端本質上還是使用者互動和資料展示,頁面的高頻變化意味著對資料需求的高頻變化。在絕大多數場景中,頁面資料都來自於伺服器端,因此對頁面變化的感知勢必會傳遞到伺服器端,而伺服器端是要做業務能力沉澱的,需要逐步完善領域模型,沉澱商業邏輯,所以就產生了一個矛盾,一個領域能力沉澱和高頻資料變化的矛盾。
為了解決這個矛盾,在業界不斷的探索實踐中,逐漸在架構層面演化出一個 BFF 層,Backend For Frontend,顧名思義,專門響應前端需求的伺服器端。
我們知道,不同的團隊,因為其面臨的業務場景不同,在面對相似問題的時候,通常解法也會不同。本文會結合筆者之前的 BFF 實踐經驗,介紹一種基於 GraphQL 的 BFF 實現。
BFF
Backend For Frontend 在 15/16 年的時候開始逐步受到關注,經過多年的實踐和發展,業界已經有了非常多的解決方案,各種技術棧的實踐都有。個人認為,要想準確的理解 BFF,需要拋開具體的技術細節和業務場景,從團隊共同作業的角度來看。
BFF 的誕生是為了解決伺服器端領域能力沉澱和前端多樣化的資料需求之間的矛盾的。因此,凡是有助於減少前端和伺服器端之間的衝突,降低開發成本的,都屬於 BFF 討論的範圍。
我們從下面幾個方面討論一下 BFF 的適用場景。
-
資料聚合裁剪
通常,為了降低頁面對伺服器端開發的影響,伺服器端會單獨分離出一層 API 層,專門響應頁面需求。但是由於缺乏一些明確的約束和指導,由於各種各樣的原因,慢慢的 API 層中會出現一些業務邏輯,導致 API 層與業務層邊界模糊,影響到對頁面需求的響應。
-
SSR
現在提到 SSR,通常會理解成基於 NodeJS + React/Vue 的伺服器端渲染。其實,在早些時候,還有基於模板的實現,知名的模板引擎有 Apache Velocity(Java)、EJS(JS)等。
-
上傳下載
上傳下載是一個比較常見的業務場景,但是常常因為功能比較通用化,很難作為一個業務能力被沉澱到業務系統中。
-
介面轉發
在一些場景中,不需要聚合其他介面就能滿足頁面需求,可以直接將頁面請求轉發給領域服務。但是往往又因為需要登入、鑑權等一系列的校驗邏輯,導致無法直接通過 Nginx 做轉發,需要一層服務來處理,比如上面說的 API 層。
在這些問題中,我們可以看到,有些問題伺服器端開發比較擅長,有些問題前端開發比較擅長。這也正好印證了 BFF 本身的定位。
在構建 BFF 服務的時候,我們需要回答好一個問題,那就是由誰來構建 BFF?
我們先來分析下前端和伺服器端構建 BFF 的優缺點。
| 誰來構建 | 優勢 | 劣勢 |
|---|---|---|
| 前端 | 能對頁面的多樣化需求做出快速反應,幾乎沒有溝通成本 | 需要具備後端開發能力,對人的要求更高;同時需要前端深入理解業務模型 |
| 伺服器端 | 對業務模型理解更加透徹;服務管理的工具更豐富 | 對頁面的需求不敏感 |
從表格中我們可以看到,不管是前端還是伺服器端來構建 BFF,都有其優勢和劣勢。因此我們還是需要結合具體的場景和需求來判斷和選擇。
如果在系統中資料聚合裁剪需求比較複雜,而頁面變化相對可控,那麼可以選擇由伺服器端來建設 BFF。如果業務中頁面變化頻率很高,比如行銷頁面,那麼由前端來負責構建 BFF 相對來說總體更優。
總之,不管是前端做還是伺服器端做,主要還是要看哪種成本更低,對需求的及時交付幫助更大。
GraphQL
前面討論了 BFF 適用的幾種場景,其中資料聚合裁剪可以說是最常見、衝突最大的一個。GraphQL 及其生態給出了一套解決方案。

在官方定義中,GraphQL 有兩層含義:
- 一種用於 API 的查詢語言。
- 一種執行時,使用現有資料完成這些查詢的執行時。
在上面這張圖中,我們通過 DSL 來描述系統中的型別。每一個型別就是一個節點,多個節點以及節點之間的關係最終會生成一張圖。我們所有的查詢都是基於這張圖來做的。可以形象的理解一下,我們每一次查詢,都是從圖中的某一個節點開始,拎出一棵樹出來。
GraphQL 有如下幾個特點:
- 按需返回資料,不多不少,且資料有極強的確定性
- 端上描述需要的資料欄位、巢狀結構等,伺服器按描述返回。同時欄位型別、欄位是否為空等都有明確的約定。
- 合併請求
- 可以將頁面中的多個資料請求合併成一個 GraphQL 查詢。在弱網環境下尤其有用。
- 完善的型別系統
- 通過 Schema 描述系統中所有的模型,包括欄位型別、模型結構、模型之間的關係等。通過內省模式可以查詢到系統中的所有 Schema 資訊,效果同 API 檔案。
- 圍繞型別系統,可以開發出很多高效的工具,比如使用者端程式碼生成工具 GraphQL Code Generator。
- API 的平滑升級,無版本
- 新增欄位不影響已有查詢
- 標記 Deprecated 欄位在內省模式中會自動標出
- 欄位細粒度控制
- 通過定義合適的 Resolver,可以對系統中任意模型、任意欄位進行細粒度控制。比如型別轉換、監控埋點等。
基於 GraphQL 的 BFF 實踐
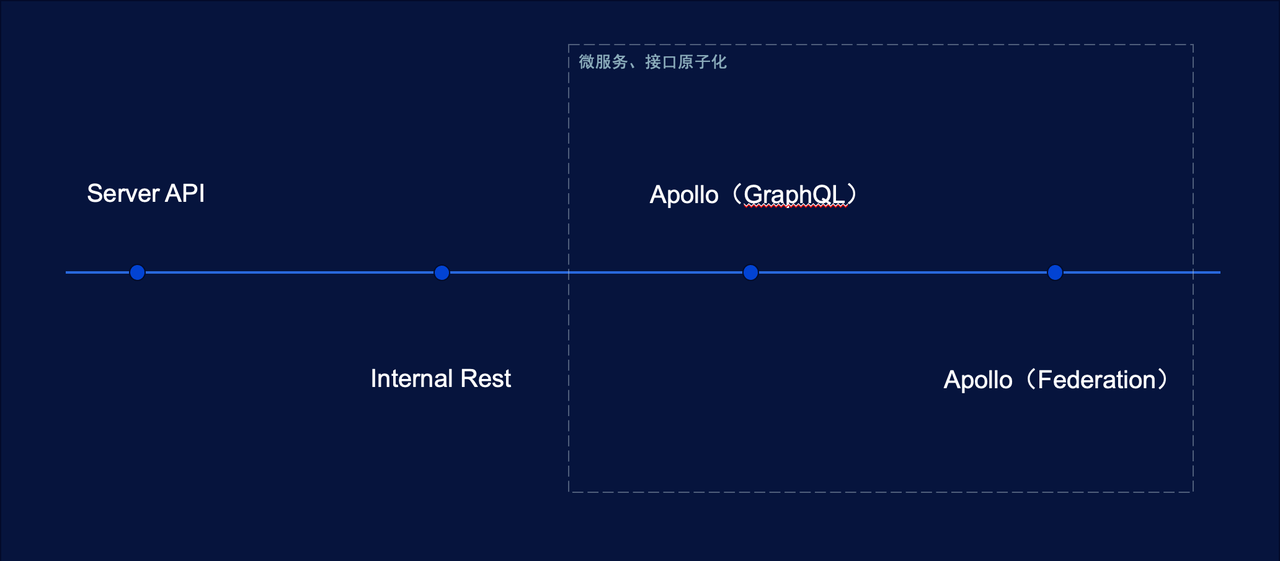
圖中從左到右分別有四個演變階段。在虛線框以前,主要是伺服器端在負責頁面的資料聚合。其中 Server API 是業務邏輯直接對外提供 API。Internal Rest 是分化出來的 API 層,專職於頁面資料聚合。隨著微服務的推廣,伺服器端逐漸按領域劃分微服務,對外提供原子化的介面。業務按照領域劃分出微服務以後,人員的組織架構也會相應的調整(康威定律),原有的 Internal Rest 層沒有專職團隊負責,程式碼逐漸腐化、難以維護,進而影響迭代交付速度。
這時候,我們就在思考通過一些技術手段來解決這個問題。下面是我們的具體實踐經歷,以及後來的方案演進。
NestJS + Apollo GraphQL
社群中有很多優秀的 NodeJS 框架,比如 koa、express、eggjs 等,我們之所以選擇了 NestJS 主要是兩點考慮。一是 NestJS 原生採用 TypeScript 開發,提供了完善的型別支援,對於伺服器端開發而言,其重要性是不言而喻的。二是 NestJS 提供了豐富的框架能力,比如說攔截器、過濾器、守衛等,相比中介軟體來說,功能更豐富,定位也更明確。
Apollo GraphQL 是社群裡比較成功的 GraphQL 解決方案,有豐富的商業化案例。而且,NestJS 對 Apollo 有官方的整合支援。
下面我們通過一個樣例來展示一下上面介紹的 GraphQL 相關的能力。
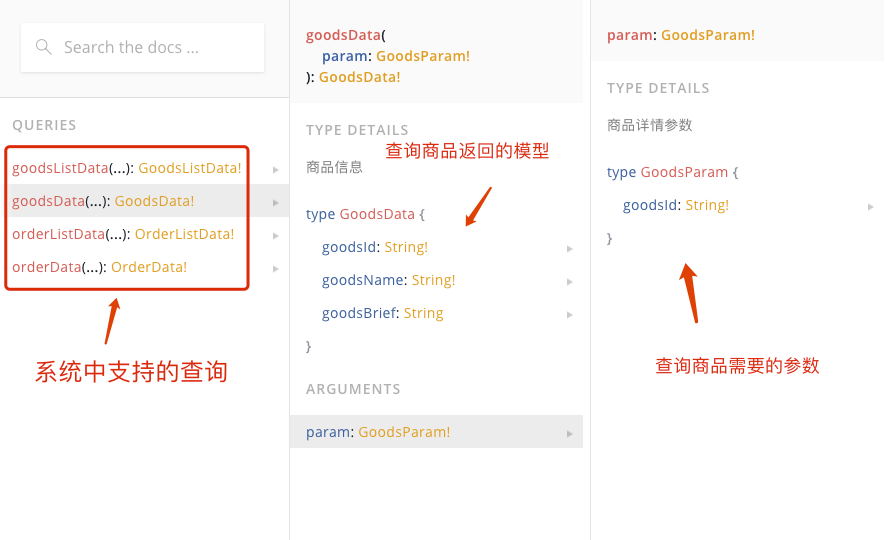
在樣例中,我們定義了商品和訂單兩個模型,並定義了一些查詢。下面是內省模式下看到的系統中的模型資訊。
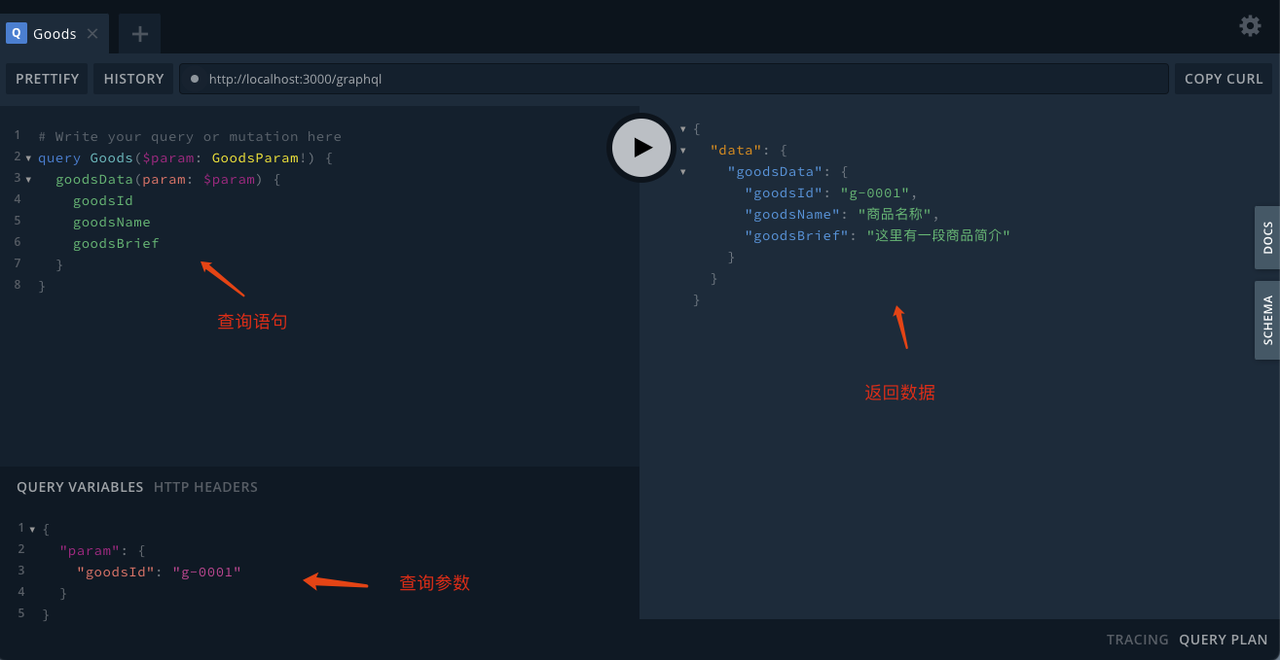
我們可以在 playground 中進行資料查詢,如下是查詢商品資訊的樣例。
訂單資訊中通常還需要關聯查詢商品資訊,下面是查詢樣例。
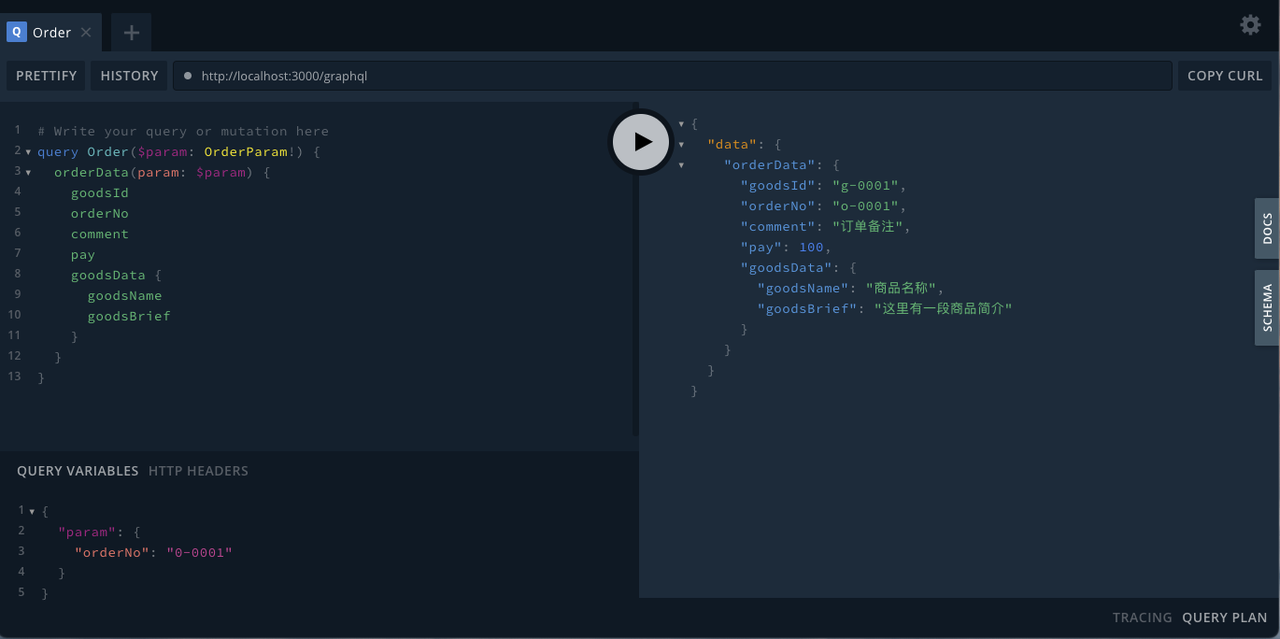
可以看到,GraphQL 很好的解決了資料聚合裁剪的問題。但是在業務量級提升、系統覆蓋業務越來越多的時候,逐漸暴露出兩個嚴重的問題。第一個是可靠性問題,單體服務容易出現單點故障。第二個是釋出效率問題,不同業務由於使用了同一個 BFF 服務,常常出現釋出衝突,需要排隊等待。因此我們又進行了第二階段的探索。
Apollo Federation
我們先用一張圖簡單描述一下 Federation 架構的組成。
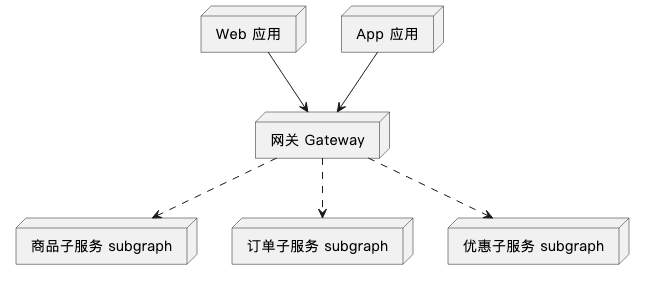
在 Federation 架構中,各個團隊只負責自身業務範圍內的子圖構建,在閘道器層,Federation Gateway 會將這些子圖拼裝成一張完整的圖。這樣就可以在保證 GraphQL 能力的同時,各個團隊能夠互不干擾、高效開發。
我們再來看一看 Federation 的樣例,最終對外提供的能力還是商品和訂單的查詢,效果與前面的 demo 一致,但是系統中原來的單體服務被拆分成了三個,一個閘道器,一個商品服務,一個訂單服務,這三個服務的開發迭代互不影響。
這裡有個問題我們需要關注一下,在 gateway 的定義程式碼中,我們可以看到子服務列表是寫死的。
import { Module } from '@nestjs/common';
import { GraphQLGatewayModule } from '@nestjs/graphql';
const graphqlGatewayModule = GraphQLGatewayModule.forRootAsync({
useFactory: async () => ({
server: {
path: '/graphql',
},
gateway: {
serviceList: [
{
name: 'goods',
url: 'http://localhost:3001/goods/graphql',
},
{
name: 'order',
url: 'http://localhost:3002/order/graphql',
},
],
},
}),
});
如果新增一個服務,就需要修改閘道器程式碼並重新發布,十分不便。我們需要一個自動化的服務序號產生器制。
Schema 整合系統
Apollo Federation 本身提供了一個 Schema 整合系統,其架構如下:
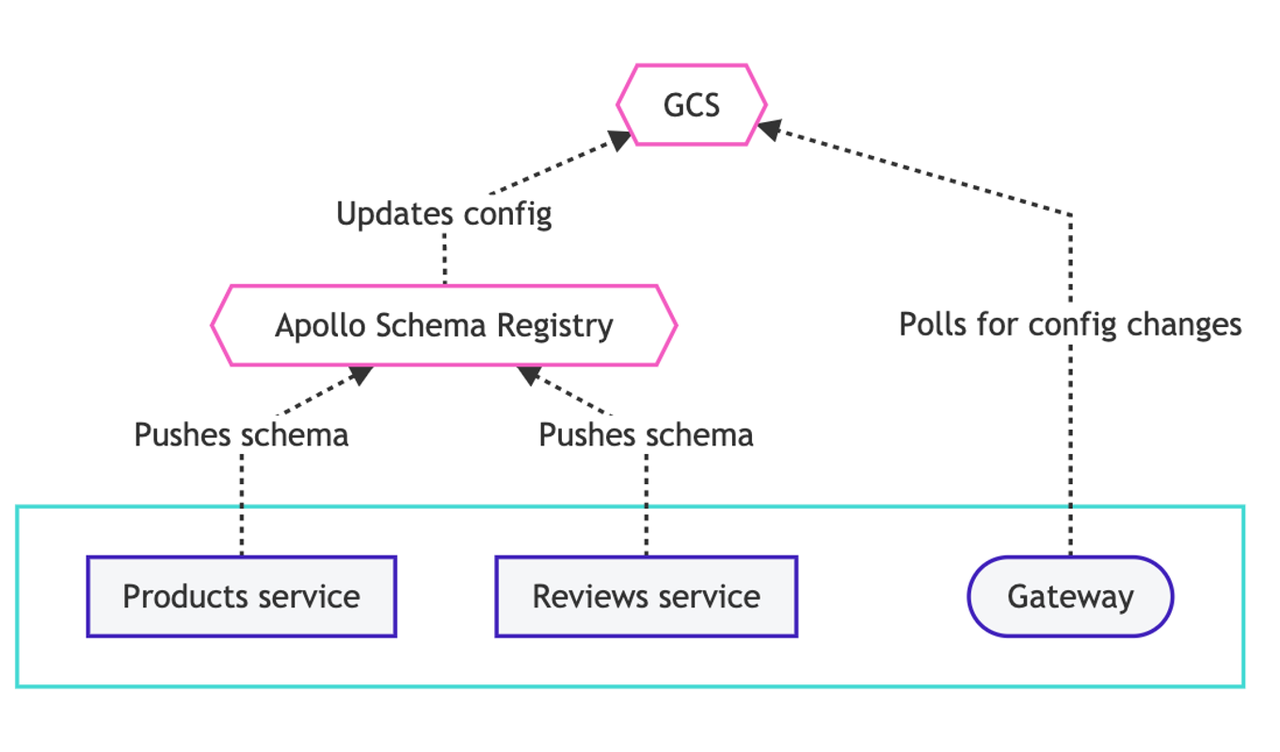
子服務將 schema 推播到 Apollo 官方的 registry 中,然後 registry 會將最新的資訊推播給一個遠端服務。閘道器再從這個遠端服務通過輪詢的方式拉取設定。
因此,我們仿照這個架構,設計開發了我們自己的 schema 整合系統。
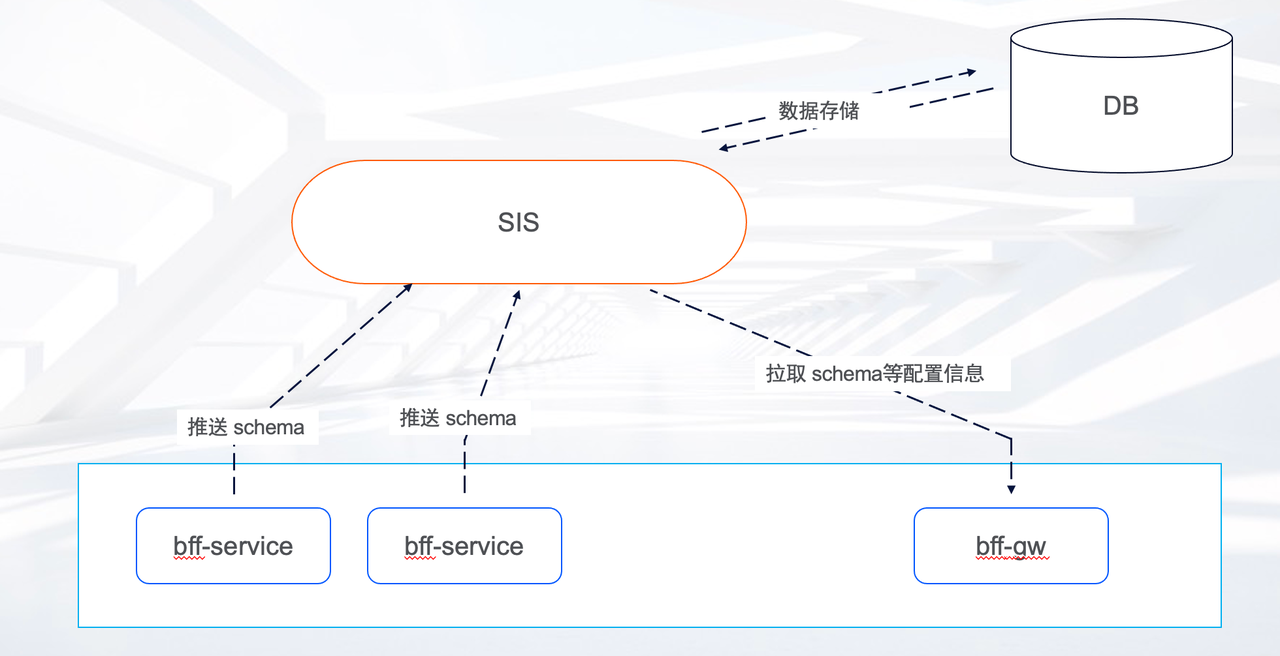
效果類似,子服務將各自的 schema 推播給 SIS(Schema Integration System),SIS 在完成必要的校驗以後,生成最新的有效設定資訊,閘道器再通過輪詢的方式將設定資訊拉取到本地,動態更新。
實現閘道器的動態更新,依賴了一個內部 API,還處於實驗階段,需要持續關注後面官方的迭代計劃。
基礎設施建設
經過不斷的迭代,整個 BFF 層已經形成了一套解決方案,周邊有著完善的基礎設施建設。
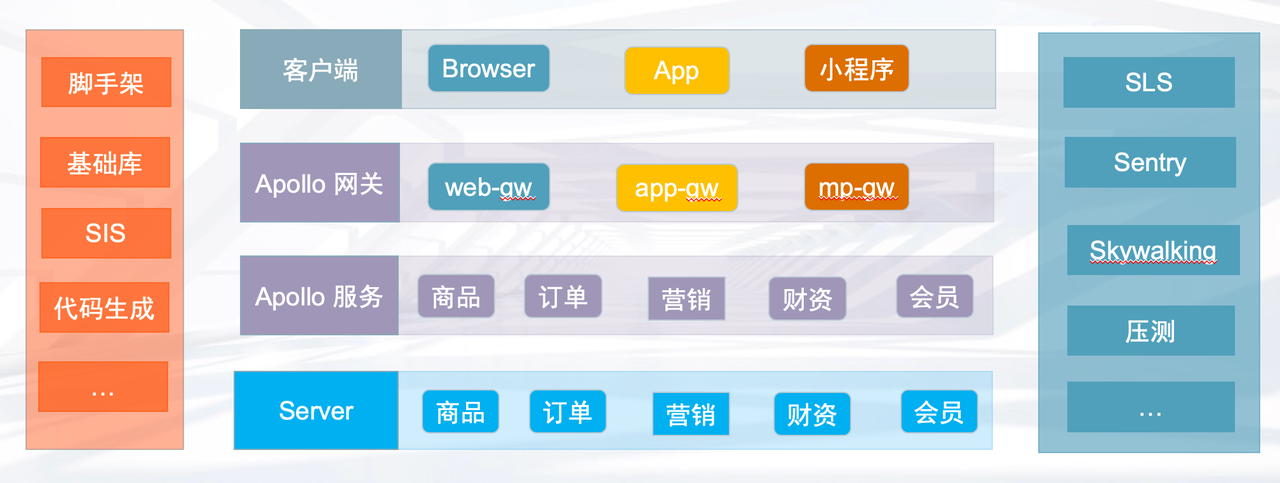
左邊一欄屬於開發階段的基建,有專案腳手架、程式碼自動生成工具等提效工具。右邊一欄屬於運維階段的基建,有阿里雲 SLS 紀錄檔系統、Sentry 錯誤告警系統、Skywalking 鏈路監控系統等。
反思
前端來構建 BFF 層,通過引入 GraphQL 來解決資料聚合裁剪的問題,整個專案經過了多輪的迭代和演進,功能越來越完善,共同作業效率越來越高。
隨著 BFF 層的展開,對前端的要求也越來越高,雖然是使用 JavaScript,但因為是完全的伺服器端開發,前端需要學習很多伺服器端開發的基礎技能,同時思維方式也需要轉變,從資料的消費方轉變成資料的生產方,需要考慮向後相容等一系列問題。
當然我們可以通過一系列的工程手段降低這些隱形成本,但是長遠看,前端同學的伺服器端開發能力、運維能力還是必不可少的。
總結和展望
本文介紹了利用 GraphQL 來做資料聚合裁剪的 BFF 實踐經驗。從最初的單體服務到後面的服務拆分,經過了多輪的迭代演進,以及不斷完善的周邊基礎設施,整個 BFF 最終形成了一個比較完善的解決方案。同時,BFF 也帶來了如何快速構建伺服器端開發能力等新的問題和挑戰。
正如文章開頭所說,不同的業務場景,不同的開發團隊都會導致 BFF 的技術選擇和實踐形式的不同。技術手段取決於業務場景和目標。適合自己的才是最好的。
 關注微信公眾號,獲取最新推播~
關注微信公眾號,獲取最新推播~
 加微信,深入交流~
加微信,深入交流~