騰訊一面:記憶體滿了,會發生什麼?
作者:小林coding
計算機八股文刷題網站:https://xiaolincoding.com
大家好,我是小林。
前幾天有位讀者留言說,面騰訊時,被問了兩個記憶體管理的問題:


先來說說第一個問題:虛擬記憶體有什麼作用?
- 第一,由於每個程序都有自己的頁表,所以每個程序的虛擬記憶體空間就是相互獨立的。程序也沒有辦法存取其他程序的頁表,所以這些頁表是私有的。這就解決了多程序之間地址衝突的問題。
- 第二,頁表裡的頁表項中除了實體地址之外,還有一些標記屬性的位元,比如控制一個頁的讀寫許可權,標記該頁是否存在等。在記憶體存取方面,作業系統提供了更好的安全性。
然後今天主要是聊聊第二個問題,「系統記憶體緊張時,會發生什麼?」
發車!
記憶體分配的過程是怎樣的?
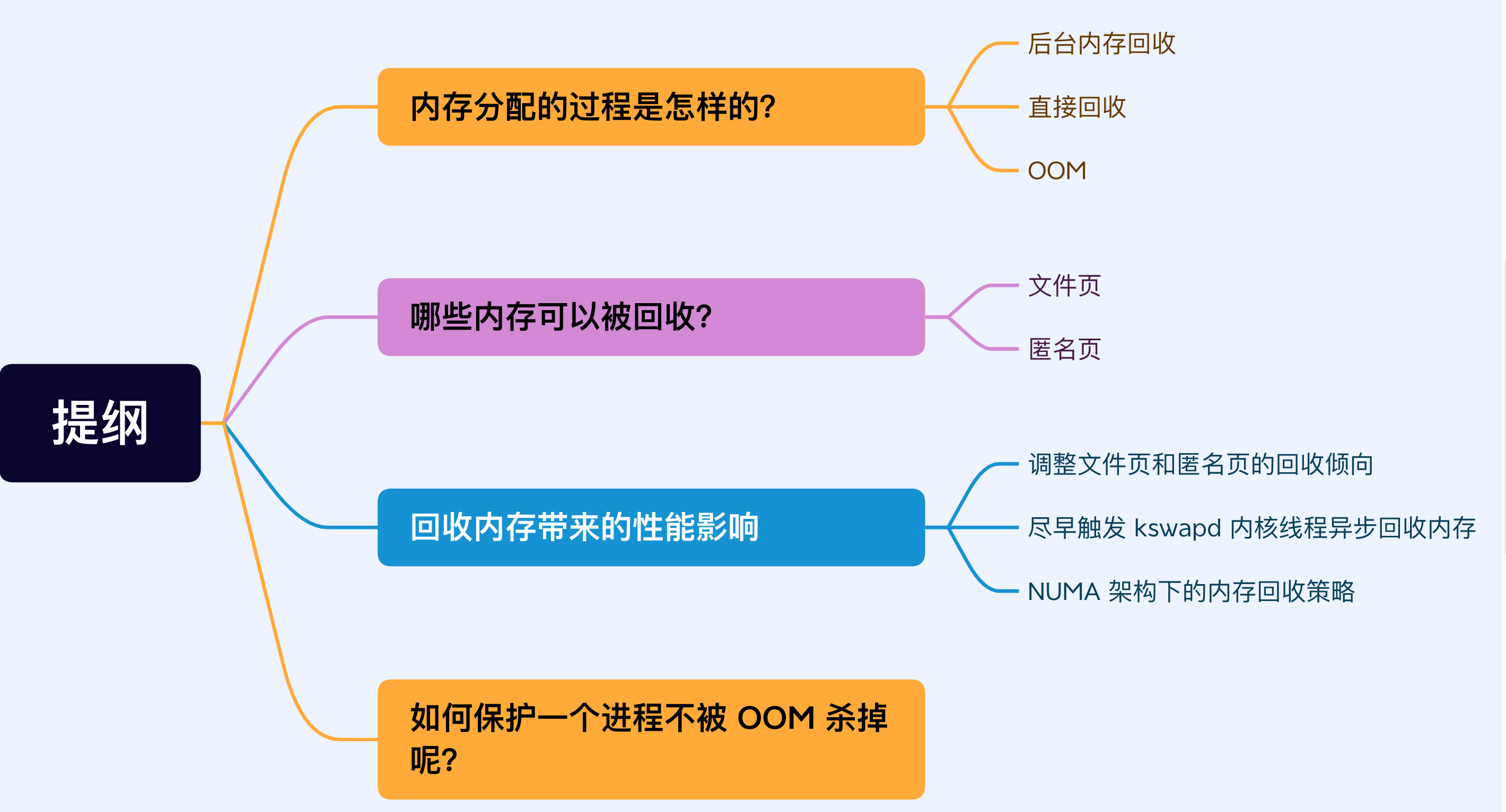
應用程式通過 malloc 函數申請記憶體的時候,實際上申請的是虛擬記憶體,此時並不會分配實體記憶體。
當應用程式讀寫了這塊虛擬記憶體,CPU 就會去存取這個虛擬記憶體, 這時會發現這個虛擬記憶體沒有對映到實體記憶體, CPU 就會產生缺頁中斷,程序會從使用者態切換到核心態,並將缺頁中斷交給核心的 Page Fault Handler (缺頁中斷函數)處理。
缺頁中斷處理常式會看是否有空閒的實體記憶體,如果有,就直接分配實體記憶體,並建立虛擬記憶體與實體記憶體之間的對映關係。
如果沒有空閒的實體記憶體,那麼核心就會開始進行回收記憶體的工作,回收的方式主要是兩種:直接記憶體回收和後臺記憶體回收。
- 後臺記憶體回收(kswapd):在實體記憶體緊張的時候,會喚醒 kswapd 核心執行緒來回收記憶體,這個回收記憶體的過程非同步的,不會阻塞程序的執行。
- 直接記憶體回收(direct reclaim):如果後臺非同步回收跟不上程序記憶體申請的速度,就會開始直接回收,這個回收記憶體的過程是同步的,會阻塞程序的執行。
如果直接記憶體回收後,空閒的實體記憶體仍然無法滿足此次實體記憶體的申請,那麼核心就會放最後的大招了 ——觸發 OOM (Out of Memory)機制。
OOM Killer 機制會根據演演算法選擇一個佔用實體記憶體較高的程序,然後將其殺死,以便釋放記憶體資源,如果實體記憶體依然不足,OOM Killer 會繼續殺死佔用實體記憶體較高的程序,直到釋放足夠的記憶體位置。
申請實體記憶體的過程如下圖:
哪些記憶體可以被回收?
系統記憶體緊張的時候,就會進行回收內測的工作,那具體哪些記憶體是可以被回收的呢?
主要有兩類記憶體可以被回收,而且它們的回收方式也不同。
- 檔案頁(File-backed Page):核心快取的磁碟資料(Buffer)和核心快取的檔案資料(Cache)都叫作檔案頁。大部分檔案頁,都可以直接釋放記憶體,以後有需要時,再從磁碟重新讀取就可以了。而那些被應用程式修改過,並且暫時還沒寫入磁碟的資料(也就是髒頁),就得先寫入磁碟,然後才能進行記憶體釋放。所以,回收乾淨頁的方式是直接釋放記憶體,回收髒頁的方式是先寫回磁碟後再釋放記憶體。
- 匿名頁(Anonymous Page):應用程式通過 mmap 動態分配的堆記憶體叫作匿名頁,這部分記憶體很可能還要再次被存取,所以不能直接釋放記憶體,它們回收的方式是通過 Linux 的 Swap 機制,Swap 會把不常存取的記憶體先寫到磁碟中,然後釋放這些記憶體,給其他更需要的程序使用。再次存取這些記憶體時,重新從磁碟讀入記憶體就可以了。
檔案頁和匿名頁的回收都是基於 LRU 演演算法,也就是優先回收不常存取的記憶體。LRU 回收演演算法,實際上維護著 active 和 inactive 兩個雙向連結串列,其中:
- active_list 活躍記憶體頁連結串列,這裡存放的是最近被存取過(活躍)的記憶體頁;
- inactive_list 不活躍記憶體頁連結串列,這裡存放的是很少被存取(非活躍)的記憶體頁;
越接近連結串列尾部,就表示記憶體頁越不常存取。這樣,在回收記憶體時,系統就可以根據活躍程度,優先回收不活躍的記憶體。
活躍和非活躍的記憶體頁,按照型別的不同,又分別分為檔案頁和匿名頁。可以從 /proc/meminfo 中,查詢它們的大小,比如:
# grep表示只保留包含active的指標(忽略大小寫)
# sort表示按照字母順序排序
[root@xiaolin ~]# cat /proc/meminfo | grep -i active | sort
Active: 901456 kB
Active(anon): 227252 kB
Active(file): 674204 kB
Inactive: 226232 kB
Inactive(anon): 41948 kB
Inactive(file): 184284 kB
回收記憶體帶來的效能影響
在前面我們知道了回收記憶體有兩種方式。
- 一種是後臺記憶體回收,也就是喚醒 kswapd 核心執行緒,這種方式是非同步回收的,不會阻塞程序。
- 一種是直接記憶體回收,這種方式是同步回收的,會阻塞程序,這樣就會造成很長時間的延遲,以及系統的 CPU 利用率會升高,最終引起系統負荷飆高。
可被回收的記憶體型別有檔案頁和匿名頁:
- 檔案頁的回收:對於乾淨頁是直接釋放記憶體,這個操作不會影響效能,而對於髒頁會先寫回到磁碟再釋放記憶體,這個操作會發生磁碟 I/O 的,這個操作是會影響系統效能的。
- 匿名頁的回收:如果開啟了 Swap 機制,那麼 Swap 機制會將不常存取的匿名頁換出到磁碟中,下次存取時,再從磁碟換入到記憶體中,這個操作是會影響系統效能的。
可以看到,回收記憶體的操作基本都會發生磁碟 I/O 的,如果回收記憶體的操作很頻繁,意味著磁碟 I/O 次數會很多,這個過程勢必會影響系統的效能,整個系統給人的感覺就是很卡。
下面針對回收記憶體導致的效能影響,說說常見的解決方式。
調整檔案頁和匿名頁的回收傾向
從檔案頁和匿名頁的回收操作來看,檔案頁的回收操作對系統的影響相比匿名頁的回收操作會少一點,因為檔案頁對於乾淨頁回收是不會發生磁碟 I/O 的,而匿名頁的 Swap 換入換出這兩個操作都會發生磁碟 I/O。
Linux 提供了一個 /proc/sys/vm/swappiness 選項,用來調整檔案頁和匿名頁的回收傾向。
swappiness 的範圍是 0-100,數值越大,越積極使用 Swap,也就是更傾向於回收匿名頁;數值越小,越消極使用 Swap,也就是更傾向於回收檔案頁。
[root@xiaolin ~]# cat /proc/sys/vm/swappiness
0
一般建議 swappiness 設定為 0(預設就是 0),這樣在回收記憶體的時候,會更傾向於檔案頁的回收,但是並不代表不會回收匿名頁。
儘早觸發 kswapd 核心執行緒非同步回收記憶體
如何檢視系統的直接記憶體回收和後臺記憶體回收的指標?
我們可以使用 sar -B 1 命令來觀察:

圖中紅色框住的就是後臺記憶體回收和直接記憶體回收的指標,它們分別表示:
- pgscank/s : kswapd(後臺回收執行緒) 每秒掃描的 page 個數。
- pgscand/s: 應用程式在記憶體申請過程中每秒直接掃描的 page 個數。
- pgsteal/s: 掃描的 page 中每秒被回收的個數(pgscank+pgscand)。
如果系統時不時發生抖動,並且在抖動的時間段裡如果通過 sar -B 觀察到 pgscand 數值很大,那大概率是因為「直接記憶體回收」導致的。
針對這個問題,解決的辦法就是,可以通過儘早的觸發「後臺記憶體回收」來避免應用程式進行直接記憶體回收。
什麼條件下才能觸發 kswapd 核心執行緒回收記憶體呢?
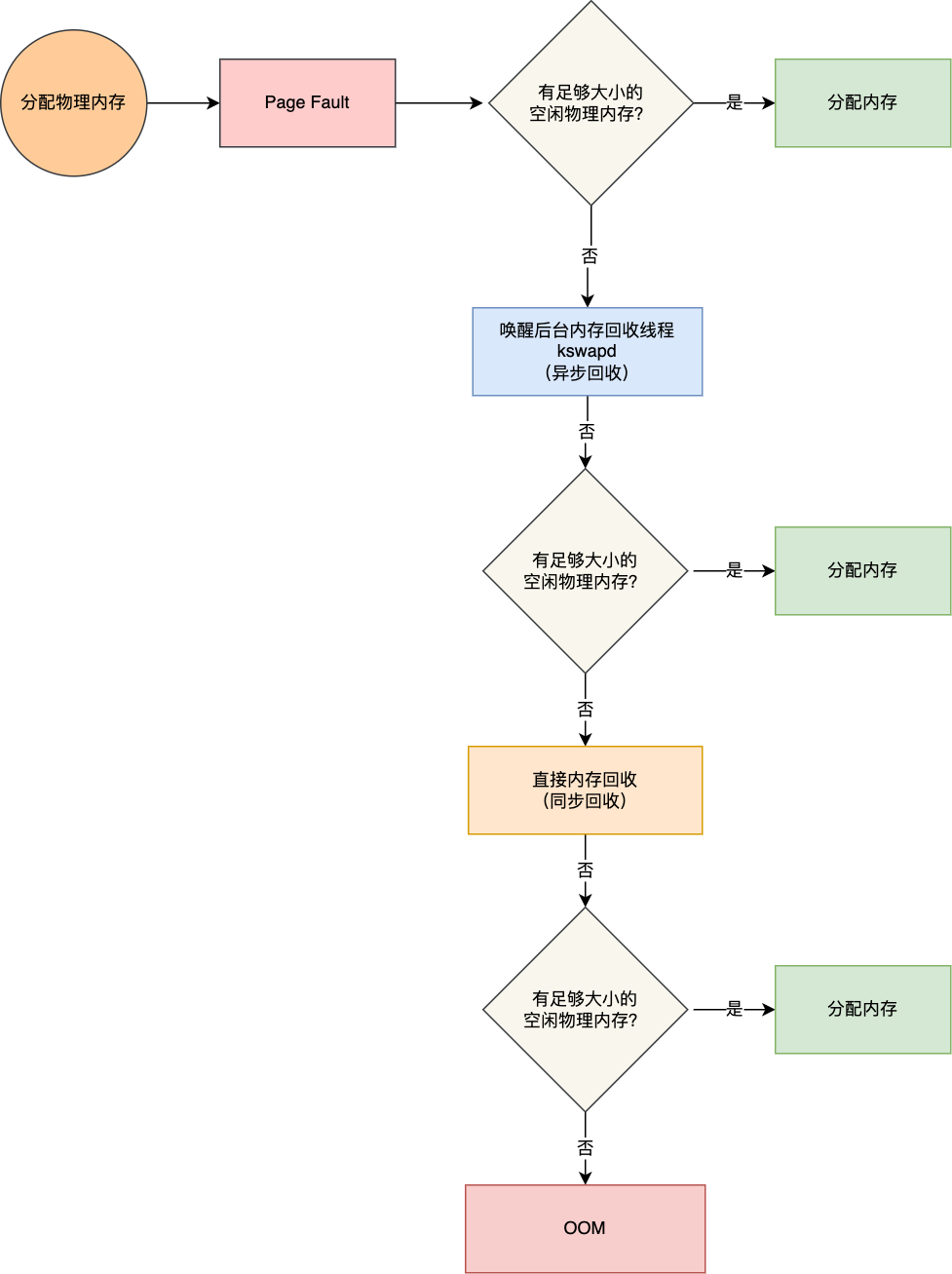
核心定義了三個記憶體閾值(watermark,也稱為水位),用來衡量當前剩餘記憶體(pages_free)是否充裕或者緊張,分別是:
- 頁最小閾值(pages_min);
- 頁低閾值(pages_low);
- 頁高閾值(pages_high);
這三個記憶體閾值會劃分為四種記憶體使用情況,如下圖:
kswapd 會定期掃描記憶體的使用情況,根據剩餘記憶體(pages_free)的情況來進行記憶體回收的工作。
-
圖中綠色部分:如果剩餘記憶體(pages_free)大於 頁高閾值(pages_high),說明剩餘記憶體是充足的;
-
圖中藍色部分:如果剩餘記憶體(pages_free)在頁高閾值(pages_high)和頁低閾值(pages_low)之間,說明記憶體有一定壓力,但還可以滿足應用程式申請記憶體的請求;
-
圖中橙色部分:如果剩餘記憶體(pages_free)在頁低閾值(pages_low)和頁最小閾值(pages_min)之間,說明記憶體壓力比較大,剩餘記憶體不多了。這時 kswapd0 會執行記憶體回收,直到剩餘記憶體大於高閾值(pages_high)為止。雖然會觸發記憶體回收,但是不會阻塞應用程式,因為兩者關係是非同步的。
-
圖中紅色部分:如果剩餘記憶體(pages_free)小於頁最小閾值(pages_min),說明使用者可用記憶體都耗盡了,此時就會觸發直接記憶體回收,這時應用程式就會被阻塞,因為兩者關係是同步的。
可以看到,當剩餘記憶體頁(pages_free)小於頁低閾值(pages_low),就會觸發 kswapd 進行後臺回收,然後 kswapd 會一直回收到剩餘記憶體頁(pages_free)大於頁高閾值(pages_high)。
也就是說 kswapd 的活動空間只有 pages_low 與 pages_min 之間的這段區域,如果剩餘內測低於了 pages_min 會觸發直接記憶體回收,高於了 pages_high 又不會喚醒 kswapd。
頁低閾值(pages_low)可以通過核心選項 /proc/sys/vm/min_free_kbytes (該引數代表系統所保留空閒記憶體的最低限)來間接設定。
min_free_kbytes 雖然設定的是頁最小閾值(pages_min),但是頁高閾值(pages_high)和頁低閾值(pages_low)都是根據頁最小閾值(pages_min)計算生成的,它們之間的計算關係如下:
pages_min = min_free_kbytes
pages_low = pages_min*5/4
pages_high = pages_min*3/2
如果系統時不時發生抖動,並且通過 sar -B 觀察到 pgscand 數值很大,那大概率是因為直接記憶體回收導致的,這時可以增大 min_free_kbytes 這個設定選項來及早地觸發後臺回收,然後繼續觀察 pgscand 是否會降為 0。
增大了 min_free_kbytes 設定後,這會使得系統預留過多的空閒記憶體,從而在一定程度上降低了應用程式可使用的記憶體量,這在一定程度上浪費了記憶體。極端情況下設定 min_free_kbytes 接近實際實體記憶體大小時,留給應用程式的記憶體就會太少而可能會頻繁地導致 OOM 的發生。
所以在調整 min_free_kbytes 之前,需要先思考一下,應用程式更加關注什麼,如果關注延遲那就適當地增大 min_free_kbytes,如果關注記憶體的使用量那就適當地調小 min_free_kbytes。
NUMA 架構下的記憶體回收策略
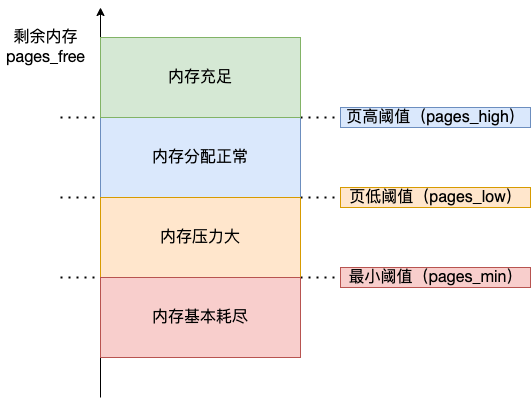
什麼是 NUMA 架構?
再說 NUMA 架構前,先給大家說說 SMP 架構,這兩個架構都是針對 CPU 的。
SMP 指的是一種多個 CPU 處理器共用資源的電腦硬體架構,也就是說每個 CPU 地位平等,它們共用相同的物理資源,包括匯流排、記憶體、IO、作業系統等。每個 CPU 存取記憶體所用時間都是相同的,因此,這種系統也被稱為一致儲存存取結構(UMA,Uniform Memory Access)。
隨著 CPU 處理器核數的增多,多個 CPU 都通過一個匯流排存取記憶體,這樣匯流排的頻寬壓力會越來越大,同時每個 CPU 可用頻寬會減少,這也就是 SMP 架構的問題。
 SMP 與 NUMA 架構
SMP 與 NUMA 架構
為了解決 SMP 架構的問題,就研製出了 NUMA 結構,即非一致儲存存取結構(Non-uniform memory access,NUMA)。
NUMA 架構將每個 CPU 進行了分組,每一組 CPU 用 Node 來表示,一個 Node 可能包含多個 CPU 。
每個 Node 有自己獨立的資源,包括記憶體、IO 等,每個 Node 之間可以通過互聯模組匯流排(QPI)進行通訊,所以,也就意味著每個 Node 上的 CPU 都可以存取到整個系統中的所有記憶體。但是,存取遠端 Node 的記憶體比存取本地記憶體要耗時很多。
NUMA 架構跟回收記憶體有什麼關係?
在 NUMA 架構下,當某個 Node 記憶體不足時,系統可以從其他 Node 尋找空閒記憶體,也可以從本地記憶體中回收記憶體。
具體選哪種模式,可以通過 /proc/sys/vm/zone_reclaim_mode 來控制。它支援以下幾個選項:
- 0 (預設值):在回收本地記憶體之前,在其他 Node 尋找空閒記憶體;
- 1:只回收本地記憶體;
- 2:只回收本地記憶體,在本地回收記憶體時,可以將檔案頁中的髒頁寫回硬碟,以回收記憶體。
- 4:只回收本地記憶體,在本地回收記憶體時,可以用 swap 方式回收記憶體。
在使用 NUMA 架構的伺服器,如果系統出現還有一半記憶體的時候,卻發現系統頻繁觸發「直接記憶體回收」,導致了影響了系統效能,那麼大概率是因為 zone_reclaim_mode 沒有設定為 0 ,導致當本地記憶體不足的時候,只選擇回收本地記憶體的方式,而不去使用其他 Node 的空閒記憶體。
雖然說存取遠端 Node 的記憶體比存取本地記憶體要耗時很多,但是相比記憶體回收的危害而言,存取遠端 Node 的記憶體帶來的效能影響還是比較小的。因此,zone_reclaim_mode 一般建議設定為 0。
如何保護一個程序不被 OOM 殺掉呢?
在系統空閒記憶體不足的情況,程序申請了一個很大的記憶體,如果直接記憶體回收都無法回收出足夠大的空閒記憶體,那麼就會觸發 OOM 機制,核心就會根據演演算法選擇一個程序殺掉。
Linux 到底是根據什麼標準來選擇被殺的程序呢?這就要提到一個在 Linux 核心裡有一個 oom_badness() 函數,它會把系統中可以被殺掉的程序掃描一遍,並對每個程序打分,得分最高的程序就會被首先殺掉。
程序得分的結果受下面這兩個方面影響:
- 第一,程序已經使用的實體記憶體頁面數。
- 第二,每個程序的 OOM 校準值 oom_score_adj。它是可以通過
/proc/[pid]/oom_score_adj來設定的。我們可以在設定 -1000 到 1000 之間的任意一個數值,調整程序被 OOM Kill 的機率。
函數 oom_badness() 裡的最終計算方法是這樣的:
// points 代表打分的結果
// process_pages 代表程序已經使用的實體記憶體頁面數
// oom_score_adj 代表 OOM 校準值
// totalpages 代表系統總的可用頁面數
points = process_pages + oom_score_adj*totalpages/1000
用「系統總的可用頁面數」乘以 「OOM 校準值 oom_score_adj」再除以 1000,最後再加上程序已經使用的物理頁面數,計算出來的值越大,那麼這個程序被 OOM Kill 的機率也就越大。
每個程序的 oom_score_adj 預設值都為 0,所以最終得分跟程序自身消耗的記憶體有關,消耗的記憶體越大越容易被殺掉。我們可以通過調整 oom_score_adj 的數值,來改成程序的得分結果:
- 如果你不想某個程序被首先殺掉,那你可以調整該程序的 oom_score_adj,從而改變這個程序的得分結果,降低該程序被 OOM 殺死的概率。
- 如果你想某個程序無論如何都不能被殺掉,那你可以將 oom_score_adj 設定為 -1000。
我們最好將一些很重要的系統服務的 oom_score_adj 設定為 -1000,比如 sshd,因為這些系統服務一旦被殺掉,我們就很難再登陸進系統了。
但是,不建議將我們自己的業務程式的 oom_score_adj 設定為 -1000,因為業務程式一旦發生了記憶體漏失,而它又不能被殺掉,這就會導致隨著它的記憶體開銷變大,OOM killer 不停地被喚醒,從而把其他程序一個個給殺掉。
參考資料:
- https://time.geekbang.org/column/article/277358
- https://time.geekbang.org/column/article/75797
- https://www.jianshu.com/p/e40e8813842f
總結
核心在給應用程式分配實體記憶體的時候,如果空閒實體記憶體不夠,那麼就會進行記憶體回收的工作,主要有兩種方式:
- 後臺記憶體回收:在實體記憶體緊張的時候,會喚醒 kswapd 核心執行緒來回收記憶體,這個回收記憶體的過程非同步的,不會阻塞程序的執行。
- 直接記憶體回收:如果後臺非同步回收跟不上程序記憶體申請的速度,就會開始直接回收,這個回收記憶體的過程是同步的,會阻塞程序的執行。
可被回收的記憶體型別有檔案頁和匿名頁:
- 檔案頁的回收:對於乾淨頁是直接釋放記憶體,這個操作不會影響效能,而對於髒頁會先寫回到磁碟再釋放記憶體,這個操作會發生磁碟 I/O 的,這個操作是會影響系統效能的。
- 匿名頁的回收:如果開啟了 Swap 機制,那麼 Swap 機制會將不常存取的匿名頁換出到磁碟中,下次存取時,再從磁碟換入到記憶體中,這個操作是會影響系統效能的。
檔案頁和匿名頁的回收都是基於 LRU 演演算法,也就是優先回收不常存取的記憶體。回收記憶體的操作基本都會發生磁碟 I/O 的,如果回收記憶體的操作很頻繁,意味著磁碟 I/O 次數會很多,這個過程勢必會影響系統的效能。
針對回收記憶體導致的效能影響,常見的解決方式。
- 設定 /proc/sys/vm/swappiness,調整檔案頁和匿名頁的回收傾向,儘量傾向於回收檔案頁;
- 設定 /proc/sys/vm/min_free_kbytes,調整 kswapd 核心執行緒非同步回收記憶體的時機;
- 設定 /proc/sys/vm/zone_reclaim_mode,調整 NUMA 架構下記憶體回收策略,建議設定為 0,這樣在回收本地記憶體之前,會在其他 Node 尋找空閒記憶體,從而避免在系統還有很多空閒記憶體的情況下,因本地 Node 的本地記憶體不足,發生頻繁直接記憶體回收導致效能下降的問題;
在經歷完直接記憶體回收後,空閒的實體記憶體大小依然不夠,那麼就會觸發 OOM 機制,OOM killer 就會根據每個程序的記憶體佔用情況和 oom_score_adj 的值進行打分,得分最高的程序就會被首先殺掉。
我們可以通過調整程序的 /proc/[pid]/oom_score_adj 值,來降低被 OOM killer 殺掉的概率。
完!