論文閱讀 Predicting Dynamic Embedding Trajectory in Temporal Interaction Networks
6 Predicting Dynamic Embedding Trajectory in Temporal Interaction Networks
link:https://arxiv.org/abs/1908.01207
Abstract
本文提出了一種在嵌入空間中顯示建模使用者/專案的未來軌跡的模型JODIE。該模型基於RNN模型,用於學習使用者和專案的嵌入軌跡。JODIE可以進行未來軌跡的預測。本文還提出了 t-Batch演演算法,利用該方法可以建立時間相同的batch,並使訓練速度提高9倍。
Conclusion
在本文中,提出了一個稱為JODIE的rnn模型,該模型從一系列時間互動中學習使用者和專案的動態嵌入。JODIE學習預測使用者和專案的未來嵌入,這使得它能夠更好地預測未來使用者專案互動和使用者狀態的變化。還提出了一種訓練資料批次處理方法,使JODIE比類似基線快一個數量級
未來的工作有幾個方向。學習單個使用者和專案的嵌入是昂貴的,可以學習使用者或專案組的軌跡,以減少引數的數量。另一個方向是描述相似實體的軌跡。最後,一個創新的方向是根據許多使用者可能與之互動的缺失預測專案設計新專案。
Figure and table
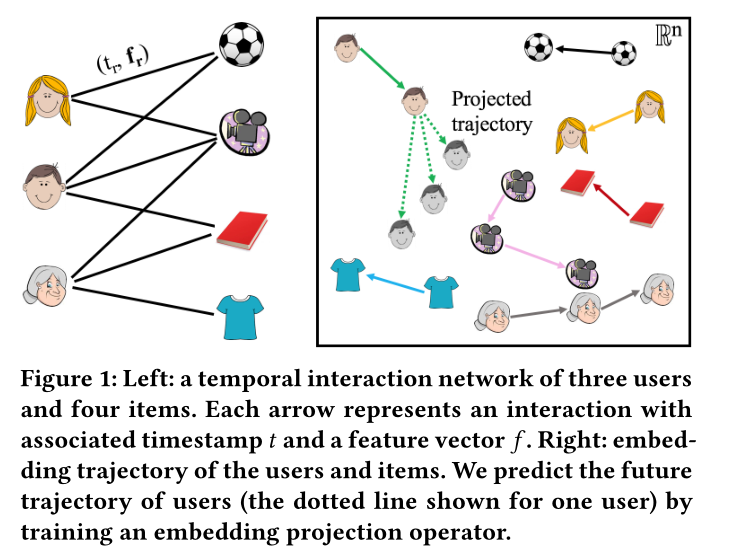
圖1 左邊是一個時序互動網路(二部圖),包含三個使用者和四個物品。連線表示在時間t和特徵向量f下的互動。右邊是使用者和物品的嵌入軌跡圖,通過訓練一個嵌入預測操作(可訓練引數矩陣)預測使用者的特徵軌跡。圖中虛線就是使用者的估計預測。
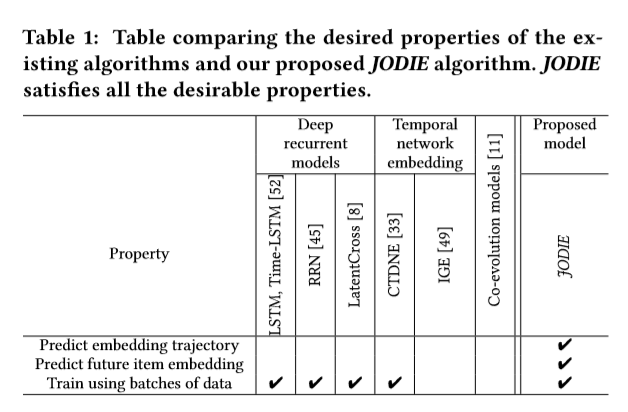
表1 對比了已存在的各種演演算法和JODIE的用途,JODIE全部滿足(自己論文肯定全部滿足啊。。。)
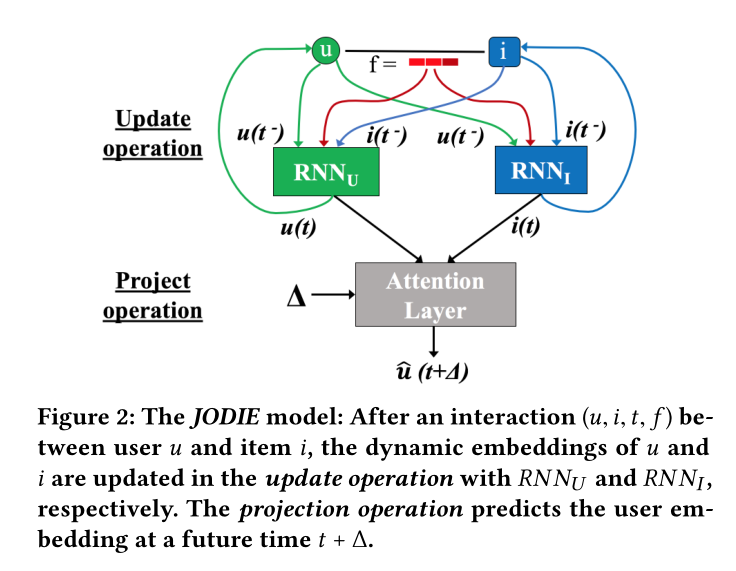
圖2 JODIE模型:JODIE在一次互動\((u,i,t,f)\)後,通過\(RNN_U\)和\(RNN_I\)兩個模組更新\(u\)和\(i\)的動態嵌入,接著預測操作去預測\(t+∆\)時間的使用者嵌入

表2 符號的含義
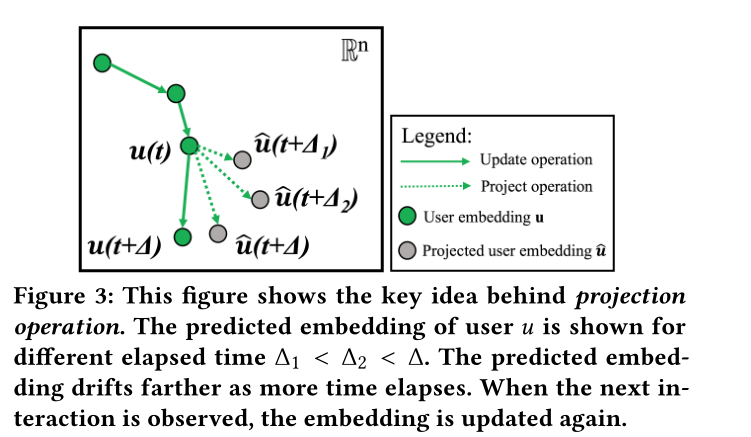
圖3 展示了預測操作。這裡預測了使用者在三個間隔時間的嵌入位置,其中\(∆_1 < ∆_2 < ∆\)。隨著時間的推移,預測的嵌入會漂移得更遠。當觀察到下一次互動時,嵌入將再次更新。
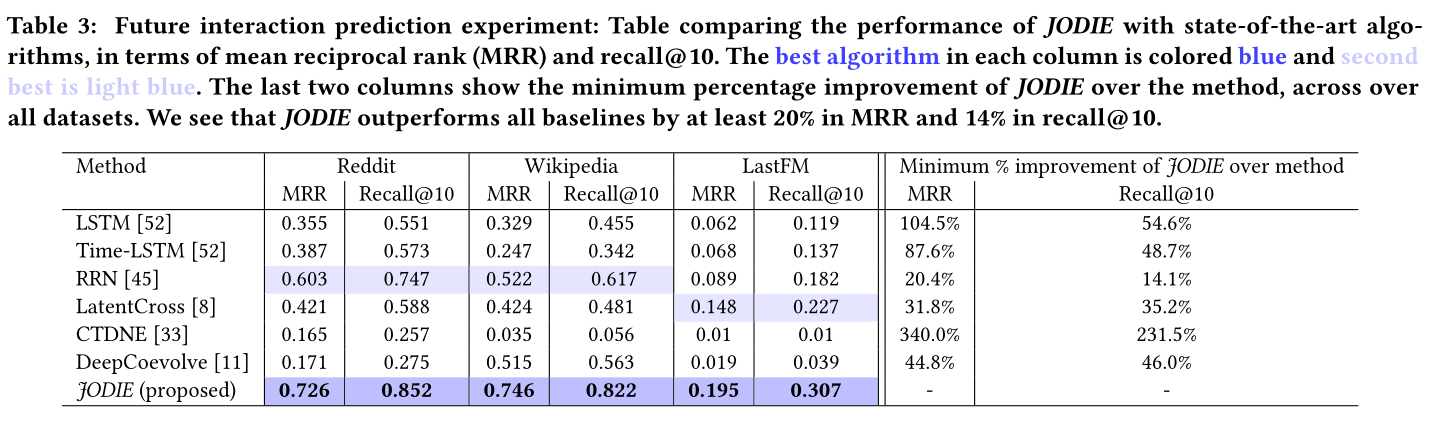
表3 互動預測實驗:這張表展示了各類演演算法在不同的資料集上表現,用MRR和recall作為指標
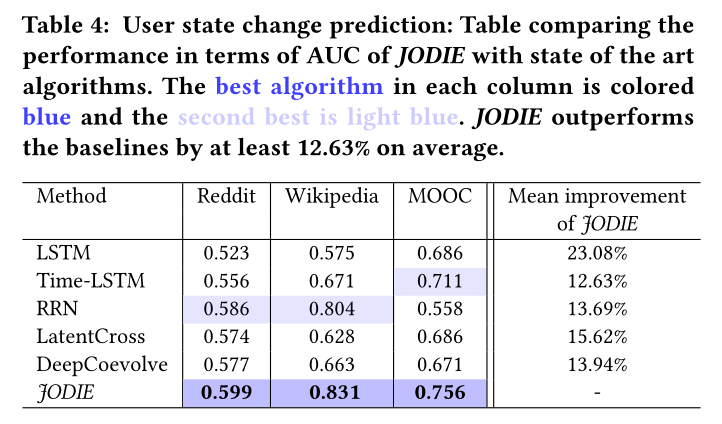
表4 使用者狀態更改預測:用auc做指標
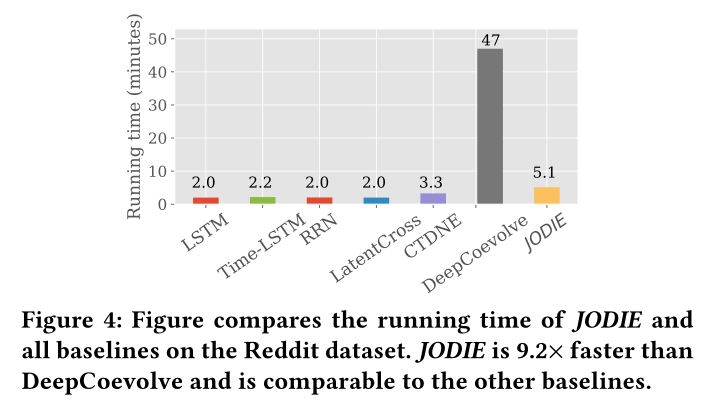
圖4 執行時間對比
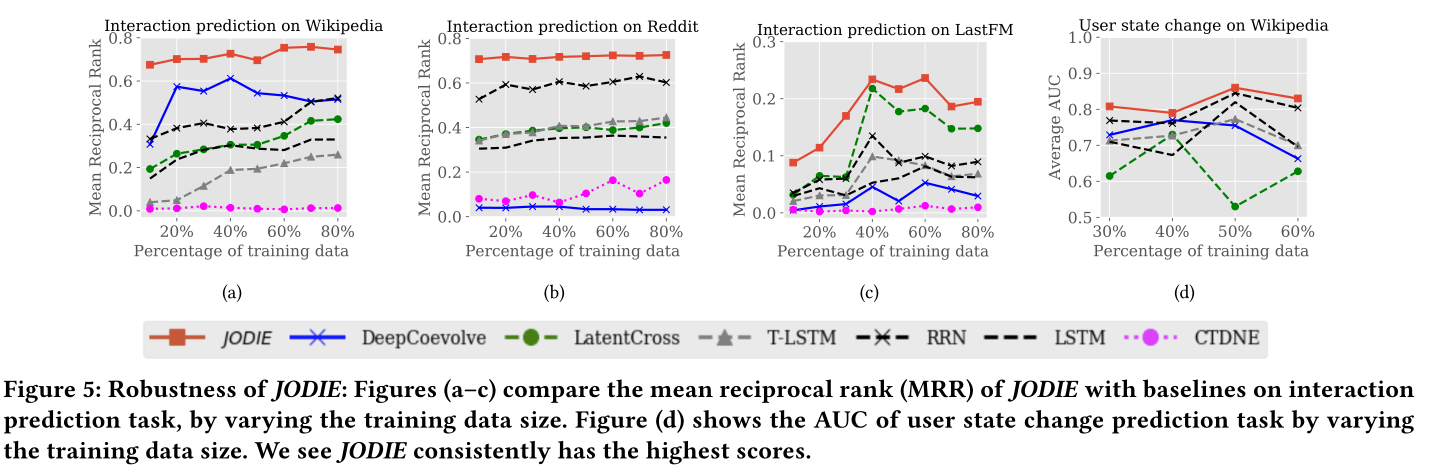
圖5 魯棒性對比
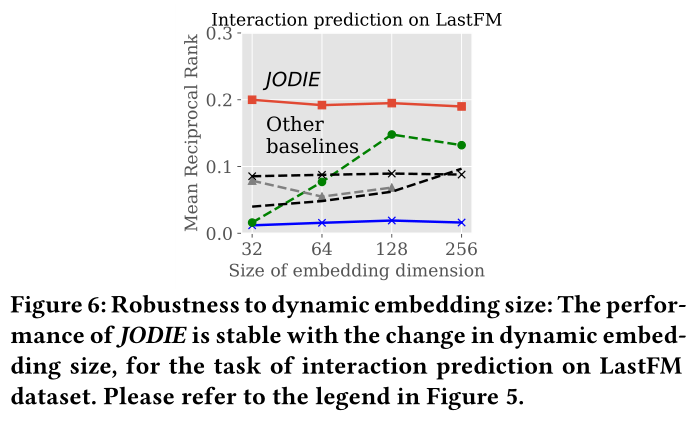
圖6 動態嵌入尺寸的魯棒性對比
Introduction
本文提出了一個工業場景中實際的四個問題
先前的方法都是等到使用者有互動才會去更新他的嵌入。比如一個今天購買的使用者,其嵌入已更新。如果在第二天、一週後甚至一個月後返回平臺,嵌入將保持不變。因此,無論她什麼時候回來,都會對她做出同樣的預測和建議。然而,使用者的意圖會隨著時間的推移而改變,因此她的嵌入需要更新(預測)到查詢時間。這裡的挑戰是如何隨著時間的推移準確預測使用者/專案的嵌入軌跡。
實體有隨時間改變的屬性,也有不隨時間改變的屬性。現有的方法一般只會考慮二者其一
許多現有方法通過為每個使用者的所有專案打分來預測使用者專案互動。複雜性過高,推薦相關場景需要較低的時間複雜度(原文近乎恆定時間:near-constant time)
現在的大多數模型都是通過將互動序列化依次處理,以保證時間順序資訊。同樣時間代價較大。
本文模型JODIE學習從時間互動中生成所有使用者和專案的嵌入軌跡。在使用使用者的嵌入進行互動預測時,並不會直接使用上一次的使用者嵌入,而是先通過一個預測,預測使用者在所需時間的嵌入位置,通過通過預測預測的嵌入進行下一步的操作。(解決了第一個問題)
本文提出的模型JODIE學習從時間互動中生成所有使用者和專案的嵌入軌跡。每個使用者和專案都有兩個嵌入屬性:靜態嵌入和動態嵌入。靜態嵌入表示實體的長期平穩特性,而動態嵌入表示時變特性,並使用JODIE演演算法進行學習。(解決了第二個問題)
JODIE模型由兩個主要元件組成:更新操作和預測操作。JODIE的更新操作有兩個RNN來生成使用者和專案嵌入。至關重要的是,這兩個RNN被耦合起來,以合併使用者和專案之間的相互依賴性。耦合的含義是:再一次互動後,使用者RNN根據互動專案的嵌入去更新使用者嵌入。同樣的,專案RNN使用使用者嵌入去更新專案嵌入。(這就帶來了特徵交叉)
在以往的工作中如果想預測使用者下一步的互動專案,通常會對所有專案進行打分,這樣將會帶來線形時間的複雜度。本文提出的方案是利用模型預測的嵌入,在嵌入空間找儘可能接近的嵌入,使用位置敏感雜湊(LSH)技術在固定時間內高效完成。(解決了第三個問題)
作者還提出了t-batch的操作。大多數現有模型通過依次處理每個互動來學習嵌入,以保持互動之間的時間依賴性。在本文中,通過建立獨立互動的訓練batch來訓練JODIE,這樣每個batch中的互動都可以並行處理。操作為迭代地從互動網路中選擇獨立的邊集,在每個批次中,每個使用者和專案最多出現一次,用每個使用者(和專案)的互動時序排序遞增增作為順序。(解決了第四個問題)
Method
3 JODIE: JOINT DYNAMIC USER-ITEM EMBEDDING MODEL
在本節,將提出JODIE其具體模型。該模型學習使用者的嵌入\(\boldsymbol{u}(t) \in \mathbb{R}^{n},\forall u \in \mathcal{U}\)和專案嵌入\(\boldsymbol{i}(t) \in \mathbb{R}^{n},\forall i \in \mathcal{I}\),其中\(\forall t \in[0, T]\)來自時序使用者項互動的有序序列\(S_{r}=\left(u_{r}, i_{r}, t_{r}, f_{r}\right)\)。該互動由使用者\(u_r \in \mathcal{U}\)和專案\(i_r \in \mathcal{I}\)在時間\(t_r \in \mathbb{R}^+,0<t_{1} \leq t_{2} \ldots \leq f_{r}\)產生,每個互動都有一個相關的特徵向量\(f_r\)(例如,表示貼文文字的向量)。
JODIE由使用者和物品的互動去訓練更新操作。JODIE訓練一個預測操作,該操作使用以前觀察到的狀態和經過的時間來預測使用者未來的嵌入。當觀察到使用者和專案的下一次互動時,它們的嵌入會再次更新。
為每個使用者和專案分配了兩個嵌入:靜態嵌入和動態嵌入。我們使用這兩種嵌入來編碼實體的長期靜態特性和動態特性。
靜態嵌入:\(\overline{\boldsymbol{u}} \in \mathbb{R}^{d} \forall u \in \mathcal{U} \text { , } \overline{\boldsymbol{i}} \in \mathbb{R}^{d} \forall i \in \mathcal{I}\)不會隨時間變化。這些用於表示固定屬性,例如使用者的長期興趣。本文使用獨熱碼作為使用者和專案的靜態嵌入。
動態嵌入:為每個使用者\(u\)和專案\(i\)分配一個動態嵌入,表示為\(u(t) \in \mathbb{R}^{n} \text { , } i(t) \in \mathbb{R}^{n}\)分別位於時間\(t\)的嵌入。這些嵌入會隨著時間的推移而變化,以模擬其隨時間變化的行為和屬性。使用者/專案的動態嵌入順序是指其軌跡。
接下來介紹更新和預測操作
*3.1 Embedding update operation
在更新操作中,使用者\(u\)和專案\(i\)在時間t之間的互動\(S=(u,i,t,f)\)用於生成它們的動態嵌入\(u(t)\)和\(i(t)\)。圖2示出了更新操作。
我們的模型使用兩個遞迴神經網路進行更新,所有使用者共用\(RNN_U\)來更新使用者嵌入,所有專案共用\(RNN_I\)來更新專案嵌入。使用者RNN和專案RNN的隱藏狀態分別表示使用者和專案嵌入。
這兩個RNN是相互遞迴(mutually-recursive)的。當用戶\(u\)與專案\(i\)互動時,\(RNN_U\)在時間\(t\)將嵌入\(i(t)\)作為輸入專案,更新嵌入\(u(t^−)\) 。$i(t^−) $表示為上一個時刻的專案嵌入。
作者提到了原來普遍用的使用專案獨熱碼來訓練的缺點
a) 獨熱碼只包含關於項的id的資訊,而不包含項的當前狀態
b)當實際資料集有數百萬項時,獨熱碼的維度變得非常大,不利於訓練
本文使用專案的動態嵌入,因為它反映了專案的當前狀態,從而導致更有意義的動態使用者嵌入和更容易的訓練。出於同樣的原因,\(RNN_I\)使用動態使用者嵌入\(u(t)\)更新專案\(i\)的動態嵌入$i(t^−) \((這是時間\)t\(之前\)u$的嵌入)。這會導致嵌入之間的相互遞迴依賴關係。見下式
其中
\(∆_u\)表示自u上次互動(與任何專案)以來的時間,\(∆_i\)表示自i上次互動(與任何使用者)以來的時間。(引入了時間間隔資訊)。
$ f$是互動特徵向量
\(W^u_1 , . . .W^u_4\)和\(W^i_1 , . . .W^i_4\)是可訓練矩陣
$ σ $是啟用函數sigmoid
RNN的變體,如LSTM、GRU和T-LSTM,在實驗上表現出類似的效能,有時甚至更差,因此在模型中使用RNN來減少可訓練引數的數量。(所以不是模型越新越好,不能單純迷戀新技術)
*3.2 Embedding projection operation
在本節 作者介紹了自己模型的另外一個核心工作,預測操作。通過這個操,模型預測了使用者未來的嵌入軌跡。該操作可以用於下游任務,例如連結預測等。
圖3展示了預測操作的想法。在t時刻,\(u(t)\)表示使用者的嵌入,假設有三個時間間隔\(∆_1 < ∆_2 < ∆\),對於每個時間間隔,預測他們的嵌入軌跡\(\hat{u}(t+∆_1),\hat{u}(t+∆_2),\hat{u}(t+∆)\),由圖3可以看到作者認為時間間隔和嵌入平移距離成正比。
接著通過\({u}(t+∆)\)的真實位置和\(\hat{u}(t+∆)\)的預測位置去訓練預測操作裡的可訓練矩陣。
該操作需要兩個輸入,\(u(t)\)和\(∆\),但是這裡並不是簡單的將嵌入和時間間隔拼接起來,而是通過哈達瑪積的操作將時間和嵌入結合,因為先前的研究表明,神經網路對處理拼接特徵的效果不是很好。
本文首先將\(∆\)通過線性層\(W_p\)計算,輸出時間上下文向量\(\boldsymbol{w}:w = W_p∆\)。\(W_p\)初始化為0均值的高斯分佈。然後,將預測嵌入作為時間上下文向量與先前嵌入的元素乘積,如下所示
向量\(1+w\)作為時間注意向量來縮放過去的使用者嵌入。若\(∆ = 0\),則\(w=0\),投影嵌入與輸入嵌入向量相同。\(∆\)值越大,預測嵌入向量與輸入嵌入向量的差異越大。
作者發現,線性層最適合預測嵌入,因為它等效於嵌入空間中的線性變換。將非線性新增到變換中會使投影操作非線性,在實驗中發現這會降低預測效能。因此,我們使用如上所述的線性變換。(本來我打算說是不是非線性的會更好的一點,結果在這就解釋了為什麼不用非線性層)
3.3 Training to predict next item embedding
本節作者將會介紹如何去預測下一個專案嵌入
在之前說過,本文的模型和之前大多數模型的區別並不是去計算兩個嵌入之間的連線概率的(類似CTR),而是輸出一個嵌入。這樣做的優點是可以將計算量從線性(每個專案數一個概率)減少到接近常數。JODIE只需要對預測層進行一次前向傳遞,並輸出一個預測項嵌入。然後,通過使用位置敏感雜湊(LSH)技術,可以在近乎恆定的時間內返回嵌入最接近的項。為了維護LSH資料結構,會在專案的嵌入更新時對其進行更新。
因此JODIE通過訓練模型,最小化預測嵌入\(\tilde{j}(t+\Delta)\)和真實嵌入\(\left[\bar{j}, j\left(t+\Delta^{-}\right)\right]\)的L2距離 寫作\(\left\|\tilde{j}(t+\Delta)-\left[\bar{j}, j\left(t+\Delta^{-}\right)\right]\right\|_{2}\)。此處$ [x, y]\(代表拼接操作。上標「-」表示時間\)t$之前的嵌入.(符號定義見表2)
在時間\(t + ∆\)之前使用使用者預測嵌入\(\widehat{\boldsymbol{u}}(t+\Delta)\)和專案嵌入\(i(t+\Delta^{-})\)進行預測。
使用專案嵌入\(i(t+\Delta^{-})\)有兩點原因
(a)專案i可能在t到t+∆時間之間和其他使用者進行互動,因此,嵌入包含了更多的最新資訊
(b)使用者經常連續地與同一專案互動,包含專案嵌入有助於簡化預測。
我們使用靜態和動態嵌入來預測預測項j的靜態和動態嵌入。
使用完全連線的線性層進行預測,如下所示
其中\(W1...W4\)和偏置向量\(B\)構成線性層。
綜上 損失如下
第一個損失項使預測的嵌入誤差最小化。新增最後兩個術語是為了規範損失,並防止使用者和專案的連續動態嵌入分別變化過大。\(λ_U\)和\(λ_I\)是縮放引數,以確保損耗在相同範圍內。值得注意的是,在訓練期間不使用負取樣,因為JODIE直接輸出預測項的嵌入。
如何將損失擴充套件到分類預測
可以訓練另一個預測函數:\(Θ :\mathbb{R}^{n+d}→ C\)(靜態嵌入是d維,動態嵌入是n維)在互動後使用使用者的嵌入來預測標籤。其中還是會加入縮放引數將損失來防止過擬合,不只是訓練最小化交叉熵損失。
*3.4 t-Batch: Training data batching
這個方法將使模型並行化訓練,且保持原有的時間依賴性。即對於互動\(S_r\),需要在\(S_k\)的前面 ,其中\(∀_r < k\)。
現有的並行方法都是利用使用者使用者分成不同的批次然後並行處理。但是JODIE由於兩個RNN模型是相互遞迴(mutually-recursive)的,所以這會在與同一專案互動的兩個使用者之間建立相互依賴關係,從而防止將使用者拆分為單獨的批並並行處理它們。
所以提出了在構建批次時應該滿足的兩個條件
1:可並行訓練
2:若按照索引的遞增順序處理,應保持互動的時間順序
t-batch提出了通過選擇互動網路的獨立邊緣集來建立每個批次,即同一批次中的兩個互動不共用任何公共使用者或專案。
具體說一下這個演演算法的流程,分兩步
1 選擇:這一步將會從邊集中選擇互無公共節點的邊出來,並且保證每個邊\((u,i)\)的時間戳都是最小的。
2 減少:在一次的batch訓練後,這一步將吧上一步選出來的邊從圖中刪除。接著回到1。
Experiment
4 EXPERIMENTS
靜態向量和動態嵌入維度為128,eopch選擇50
選擇三個種類的演演算法baseline:
(1) Deep recurrent recommender models
RRN:C.-Y. Wu, A. Ahmed, A. Beutel, A. J. Smola, and H. Jing.Recurrent recommender networks. In WSDM, 2017.
LatentCross :A. Beutel, P. Covington, S. Jain, C. Xu, J. Li, V. Gatto, and E. H. Chi. Latent cross: Making use of context in recurrent recommender systems. In WSDM, 2018.
Time-LSTM:Y. Zhu, H. Li, Y. Liao, B. Wang, Z. Guan, H. Liu, and D. Cai. What to do next:modeling user behaviors by time-lstm. In IJCAI, 2017.
(2) Dynamic co-evolution models
DeepCoevolve:H. Dai, Y. Wang, R. Trivedi, and L. Song. Deep coevolutionary network: Embedding user and item features for recommendation. arXiv:1609.03675, 2016.
(3) Temporal network embedding models
CTDNE:G. H. Nguyen, J. B. Lee, R. A. Rossi, N. K. Ahmed, E. Koh, and S. Kim. Continuous-time dynamic network embeddings. In WWW BigNet workshop, 2018.
資料集:
Reddit post dataset:這個公共資料集由使用者在subreddits上釋出的一個月的貼文組成。我們選擇了1000個最活躍的子站點作為專案,選擇了10000個最活躍的使用者。這導致672447次互動。我們將每篇文章的文字轉換為表示其LIWC類別的特徵向量。
Wikipedia edits:他的公共資料集是維基百科頁面編輯一個月的編輯資料。選擇編輯次數最多的1000個頁面作為專案和編輯,這些編輯至少以使用者身份進行了5次編輯(總共8227個使用者)。這產生了157474個互動。與Reddit資料集類似,我們將編輯文字轉換為LIWC特徵向量。
LastFM song listens:這個公共資料集有一個月的WhoListen(誰聽哪首歌)資訊。我們選擇了所有1000名使用者和1000首收聽最多的歌曲,產生了1293103次互動。在此資料集中,互動沒有功能。
4.1 Experiment 1: Future interaction prediction
sota見表三
4.2 Experiment 2: User state change prediction
sota見表4
4.3 Experiment 3: Runtime experiment
執行時間見圖4
4.4 Experiment 4: Robustness to the proportion of training data
sota見圖5
4.5 Experiment 5: Embedding size
sota見圖6
Summary
這篇文章的重點是在做使用者和專案之間的預測時,不是直接用使用者的嵌入來做,而是經過一個預測操作後先預測使用者的動態嵌入隨時間的移動結果,在利用這個結果去和專案做預測(專案亦然)。整個論文simple but effective,結構明確,而且適當解釋了為什麼,例如為什麼要用rnn,為什麼要用線性變化的∆,讀下來賞心悅目!