整理分享Java語言表示式的五個謎題

推薦學習:《》
謎題一:奇數性
下面的方法意圖確定它那唯一的引數是否是一個奇數。這個方法能夠正確運轉嗎?
public static boolean isOdd(int i){
returni%2==1:
}奇數可以被定義為被2整除餘數為1的整數。表示式i%2計算的是i整除2時所產生的餘數,因此看起來這個程式應該能夠正確運轉。遺憾的是,它不能;它在四分之一的時間裡返回的都是錯誤的答案。
為什麼是四分之一?因為在所有的int數值中,有一半都是負數,而isOdd方法對於對所有負奇數的判斷都會失敗。在任何負整數上呼叫該方法都回返回false,不管該整數是偶數還是奇數。這是Java對取餘操作符(%)的定義所產生的後果。該操作符被定義為對於所有的int數值a和所有的非零int數值b,都滿足下面的恆等式:
(a/b)*b+(a%b)==a
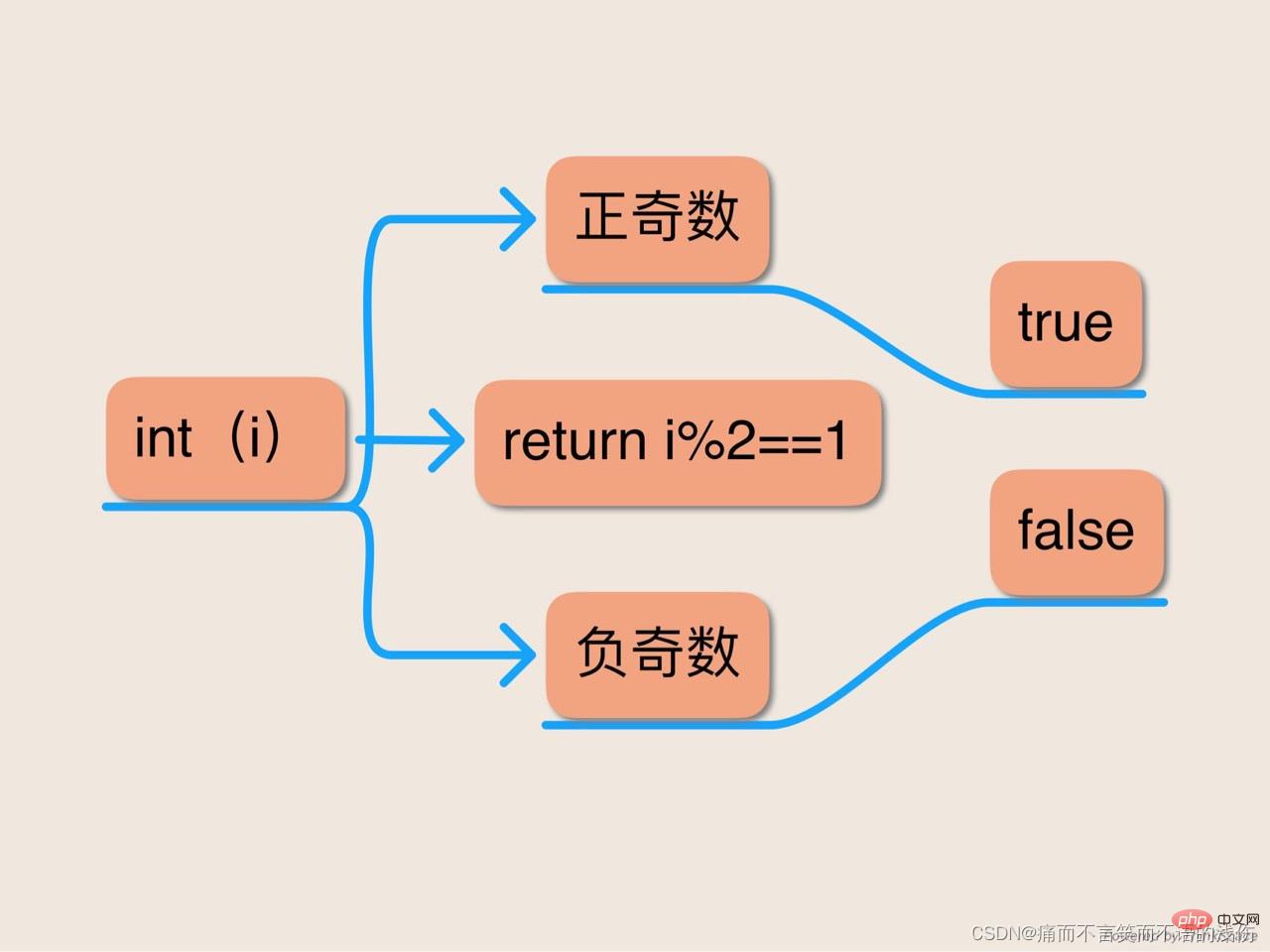
換句話說,如果你用b整除a,將商乘以b,然後加上餘數,那麼你就得到了最初的值a。該恆等式具有正確的含義,但是當與Java的截尾整數整除操作符相結合時,它就意味著:當取餘操作返回一個非零的結果時,它與左運算元具有相同的正負符號。
當i是一個負奇數時,i%2等於-1而不是1,因此isOdd方法將錯誤地返回false。為了防止這種意外,請測試你的方法在為每一個數值型引數傳遞負數、零和正數數值時,其行為是否正確。這個問題很容易訂正。只需將i%2與0而不是與1比較,並且反轉比較的含義即可:
public static boolean isOdd(inti){
returni%2!=0;
}如果你正在在一個效能臨界(performance-critical)環境中使用isOdd方法,那麼用位元運算符AND(&)來替代取餘操作符會顯得更好:
public static boolean isOdd(inti){
return(i&1)!=0;
}總之,無論你何時使用到了取餘操作符,都要考慮到運算元和結果的符號。該操作符的行為在其運算元非負時是一目瞭然的,但是當一個或兩個運算元都是負數時,它的行為就不那麼顯而易見
了。
謎題二:找零時刻
請考慮下面這段話所描述的問題:
Tom在一家汽車配件商店購買了一個價值$1.10的火花塞,但是他錢包中都是兩美元一張的鈔票。如果他用一張兩美元的鈔票支付這個火花塞,那麼應該找給他多少零錢呢?
下面是一個試圖解決上述問題的程式,它會列印出什麼呢?
public class Change{
public static void main(String args[]){
Systemoutprintln(2.00-1.10);
}
}你可能會很天真地期望該程式能夠列印出0.90但是它如何才能知道你想要列印小數點後兩位小數呢?
如果你對在DoubletoString檔案中所設定的將 double型別的值轉換為字串的規則有所瞭解你就會知道該程式列印出來的小數,是足以將 double型別的值與最靠近它的臨近值區分出來的最短的小數,它在小數點之前和之後都至少有一位。因此,看起來,該程式應該列印0.9是合理的。
這麼分析可能顯得很合理,但是並不正確。如果你執行該程式,你就會發現它列印的是:
0.8999999999999999
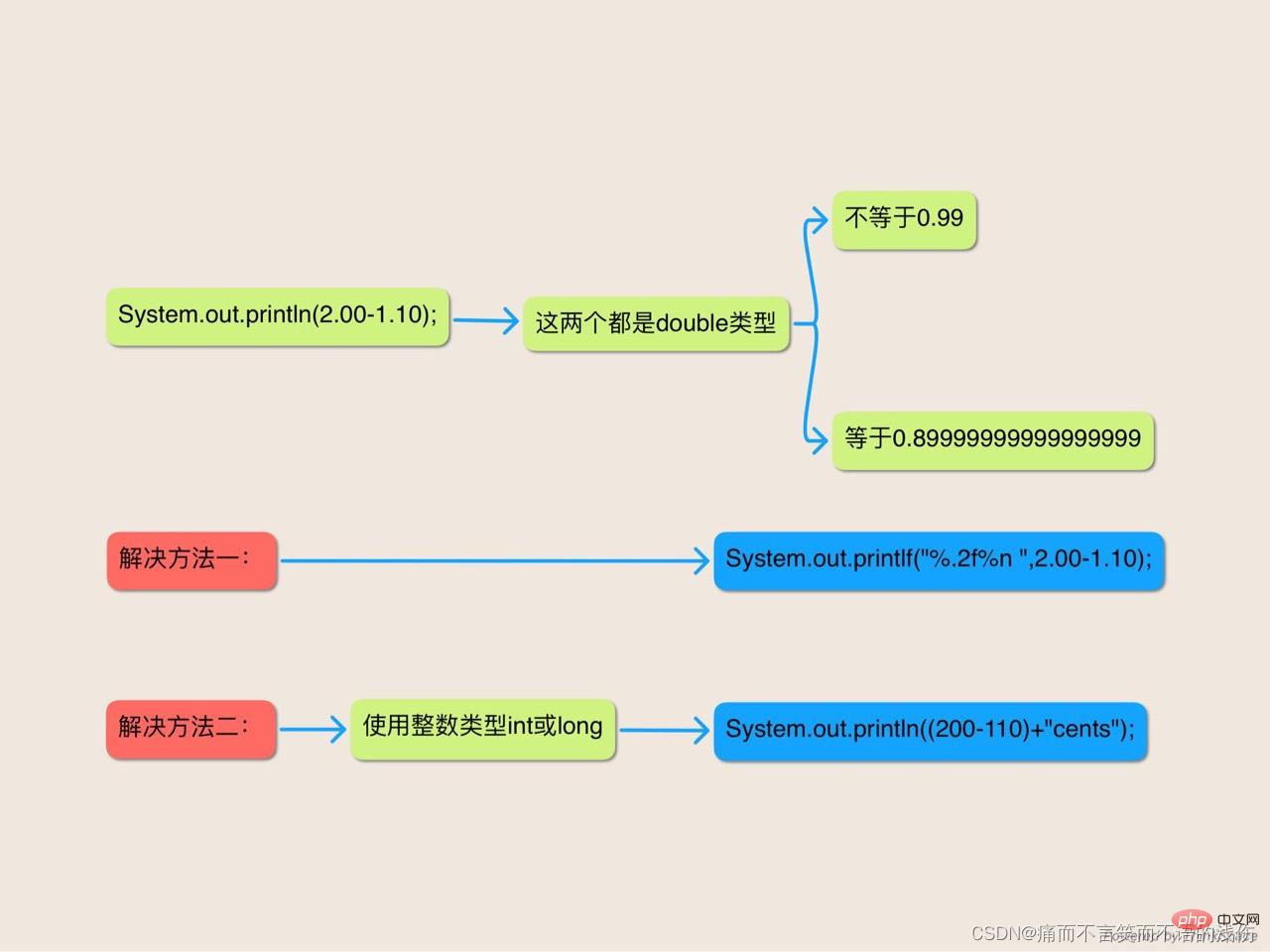
問題在於1.1這個數位不能被精確表示成為一個 double,因此它被表示成為最接近它的double值。該程式從2中減去的就是這個值。遺憾的是,這個計算的結果並不是最接近0.9的double值。表示結果的double值的最短表示就是你所看到的列印出來的那個可惡的數位。
更一般地說,問題在於並不是所有的小數都可以用二進位制浮點數來精確表示的。
如果你正在用的是JDK5.0或更新的版本,那麼你可能會受其誘惑,通過使用printf工具來設定輸出精度的方訂正該程式:
//拙劣的解決方案-仍舊是使用二進位制浮點數
System.out.printf("%.2f%n",2.00-1.10);這條語句列印的是正確的結果,但是這並不表示它就是對底層問題的通用解決方案:它使用的仍日是二進位制浮點數的double運算。浮點運算在一個範圍很廣的值域上提供了很好的近似,但是它通常不能產生精確的結果。二進位制浮點對於貨幣計算是非常不適合的,因為它不可能將0.1-或者10的其它任何次負冪--精確表示為一個長度有限的二進位制小數解決該問題的一種方式是使用某種整數型別,例如int或long,並且以分為單位來執行計算。如果你採納了此路線,請確保該整數型別大到足夠表示在程式中你將要用到的所有值。對這裡舉例的謎題來說,int就足夠了。下面是我們用int型別來以分為單位表示貨幣值後重寫的println語句。這個版本將列印出正確答案90分:
Systemoutprintln((200-110)+"cents")
解決該問題的另一種方式是使用執行精確小數運算的BigDecimal。它還可以通過JDBC與SQL DECIMAL型別進行互操作。這裡要告誡你一點:一定要用BigDecimal(String)構造器,而千萬不要用BigDecimal(double)。後一個構造器將用它的引數的精確」值來建立一個範例:new BigDecimal(1)將返回一個表示0100000000000000055511151231257827021181583404541015625BigDecimal。通過正確使用BigDecimal,程式就可以列印出我們所期望的結果0.90:
import java.math.BigDecimal;
public class Changel {
public static void main(String args[]){
System.out.println(newBigDecimal(2.00")
subtract(new BigDecimal("1.10")));
}
}這個版本並不是十分地完美,因為Java並沒有為 BigDecimal提供任何語言上的支援。使用
BigDecimal的計算很有可能比那些使用原始型別的計算要慢一些,對某些大量使用小數計算的程式來說,這可能會成為問題,而對大多數程式來說,這顯得一點也不重要。
總之,在需要精確答案的地方,要避免使用 float和double;對於貨幣計算,要使用int、long或BigDecimal。對於語言設計者來說,應該考慮對小數運算提供語言支援。一種方式是提供對操作符過載的有限支援,以使得運運算元可以被塑造為能夠對數值參照型別起作用,例如BigDecimal。另一種方式是提供原始的小數型別,就像COBOL與PL/I所作的一樣。
謎題三:長整數
這個謎題之所以被稱為長整除是因為它所涉及的程式是有關兩個long型數值整除的。被除數表示的是一天裡的微秒數;而除數表示的是一天裡的毫秒數。這個程式會列印出什麼呢?
public class Longpision{
public static void main(String args[]){
final long MICROS PER DAY=24*60*60*1000*1000;
final long MILLIS PER DAY=24*60*60*1000;
Systemoutprintln(MICROS PER DAY/ MILLIS PER DAY);
}
}這個謎題看起來相當直觀。每天的毫秒數和每天的微秒數都是常數。為清楚起見,它們都被表示成積的形式。每天的微秒數是(24小時/天*60分鐘/小時*60秒/分鐘*1000毫秒/秒*1000微秒/毫秒)。而每天的毫秒數的不同之處只是少了最後一個因子1000。當你用每天的毫秒數來整除每天的微秒數時,除數中所有的因子都被約掉了,只剩下1000,這正是每毫秒包含的微秒數。
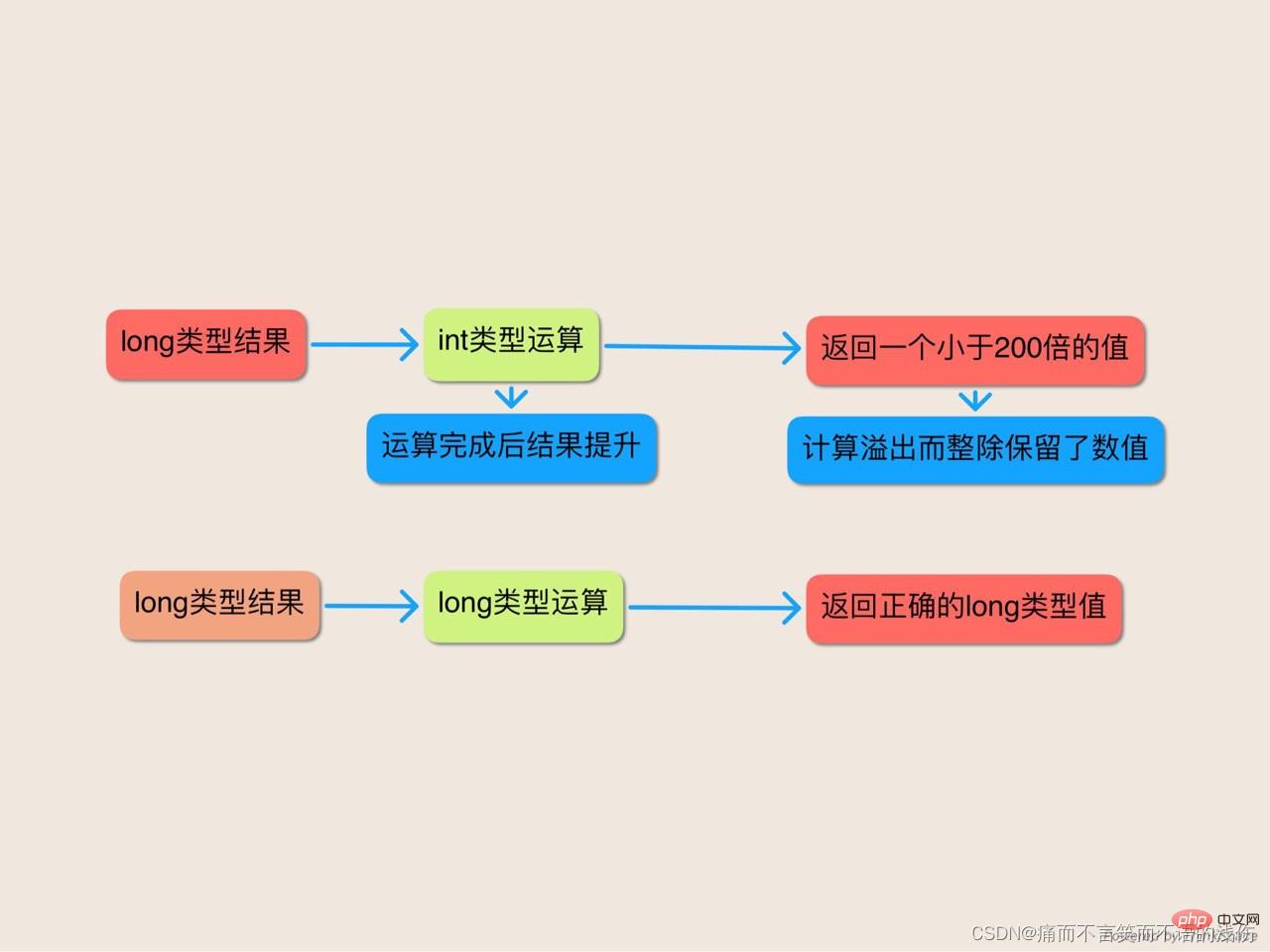
除數和被除數都是long型別的,long型別大到了可以很容易地儲存這兩個乘積而不產生溢位。因此,看起來程式列印的必定是1000。遺憾的是,它列印的是5。這裡到底發生了什麼呢?
問題在於常數MICROS PER DAY的計算確實」溢位了。儘管計算的結果適合放入long中,並且其空間還有富餘,但是這個結果並不適合放入 int中。這個計算完全是以int運算來執行的,並且只有在運算完成之後,其結果才被提升到long,而此時已經太遲了:計算已經溢位了,它返回的是一個小了200倍的數值。從int提升到 long是一種拓寬原始型別轉換(widening primitive conversion),它保留了(不正確的)數值。這個值之後被MILLIS PER DAY整除,而MILLIS PER DAY的計算是正確的,因為它適合int運算。這樣整除的結果就得到了5。
那麼為什麼計算會是以int運算來執行的呢?為所有乘在一起的因子都是int數值。當你將兩個int數值相乘時,你將得到另一個int數值。Java不具有目標確定型別的特性,這是一種語言特性,其含義是指儲存結果的變數的型別會影響到計算所使用的型別。
通過使用long常數來替代int常數作為每一個乘積的第一個因子,我們就可以很容易地訂正這個程式。這樣做可以強制表示式中所有的後續計算都用long運作來完成。儘管這麼做只在MICROS PER DAY表示式中是必需的,但是在兩個乘積中都這麼做是一種很好的方式。相似地,使用long作為乘積的「第一個」數值也並不總是必需的,但是這麼做也是一種很好的形式。在兩個計算中都以long數值開始可以很清楚地表明它們都不會溢位。下面的程式將列印出我們所期望的1000:
public class Longpision{
public static void main(String args[)
final long MICROS PER DAY=24L*60*60*1000*1000:
final long MILLIS PER DAY=24L*60*60*1000;
SystemoutprintlnMICROS PER DAY MILLIS PER DAY);
}
}這個教訓很簡單:當你在操作很大的數位時,千萬要提防溢位--它可是一個緘默殺手。即使用來儲存結果的變數已顯得足夠大,也並不意味著要產生結果的計算具有正確的型別。當你拿不準時,就使用long運算來執行整個計算。
語言設計者從中可以吸取的教訓是:也許降低默溢位產生的可能性確實是值得做的一件事。這可以通過對不會產生緘默溢位的運算提供支援來實現。程式可以丟擲一個異常而不是直接溢位。就像Ada所作的那樣,或者它們可以在需要的時候自動地切換到一個更大的內部表示上以防止溢位,就像Lisp所作的那樣。這兩種方式都可能會遭受與其相關的效能方面的損失。降低緘默溢位的另一種方式是支援目標確定型別,但是這麼做會顯著地增加型別系統的複雜度。
謎題四:初級問題
得啦,前面那個謎題是有點棘手,但它是有關整除的,每個人都知道整除是很麻煩的。那麼下面的程式只涉及加法,它又會列印出什麼呢?
public class Elementary{
public static void main(String]args) {
Systemoutprintln(12345+54321);
}
}從表面上看,這像是一個很簡單的謎題--簡單到不需要紙和筆你就可以解決它。加號的左運算元的各個位是從1到5升序排列的,而右運算元是降序排列的。因此,相應各位的和仍然是常數,程式必定列印66666。對於這樣的分析,只有一個問題:當你執行該程式時,它列印出的是17777。難道是Java對列印這樣的非常數位抱有偏見嗎?不知怎麼的,這看起來並不像是一個合理的解釋。
事物往往有別於它的表象。就以這個問題為例,它並沒有列印出我們想要的輸出。請仔細觀察+操作符的兩個運算元,我們是將一個int型別的12345加到了long型別的54321上。請注意左運算元開頭的數位1和右運算元結尾的小寫字母1之間的細微差異。數位1的水平筆劃(稱為「臂(arm)」)和垂直筆劃(稱為「莖(stem)」)之間是一個銳角,而與此相對照的是,小寫字母l的臂和莖之間是一個直角。

在你大喊「噁心!」之前,你應該注意到這個問題確實已經引起了混亂,這裡確實有一個教訓:在 long型字面常數中,一定要用大寫的L,千萬不要用小寫的1。這樣就可以完全掐斷這個謎題所產生的混亂的源頭。
System.out.println(12345+5432L);
相類似的,要避免使用單獨的一個1字母作為變數名。例如,我們很難通過觀察下面的程式碼段來判斷它到底是列印出列表1還是數位1。
List l=new ArrayList<String>() ;
l.add("Foo");
System.outprintln(1);
總之,小寫字母l和數位1在大多數打字機字型中都是幾乎一樣的。為避免你的程式的讀者對二者產生混淆,千萬不要使用小寫的1來作為long型字面常數的結尾或是作為變數名。Java從C程式語言中繼承良多,包括long型字面常數的語法。也許當初允許用小寫的1來編寫long型字面常數本身就是一個錯誤。
謎題五:十六進位制的趣事
下面的程式是對兩個十六進位制(hex)字面常數進行相加,然後列印出十六進位制的結果。這個程式會列印出什麼呢?
public class JoyOfHex{
public static void main(String[] args){
System.out.println(
Long.toHexString(0x100000000L+0xcafebabe));
}
}看起來很明顯,該程式應該列印出1cafebabe。畢竟,這確實就是十六進位制數位10000000016與 cafebabe16的和。該程式使用的是long型運算,它可以支援16位元十六進位制數,因此運算溢位是不可能的。
然而,如果你執行該程式,你就會發現它列印出來的是cafebabe,並沒有任何前導的1。這個輸出表示的是正確結果的低32位元,但是不知何故第33位丟失了。
看起來程式好像執行的是int型運算而不是long型運算,或者是忘了加第一個運算元。這裡到底發生了什麼呢?
十進位制字面常數具有一個很好的屬性,即所有的十進位制字面常數都是正的,而十六進位制和八進位制字面常數並不具備這個屬性。要想書寫一個負的十進位制常數,可以使用一元取反操作符(-)連線一個十進位制字面常數。以這種方式,你可以用十進位制來書寫任何int或long型的數值,不管它是正的還是負的,並且負的十進位制常數可以很明確地用一個減號符號來標識。但是十六進位制和八進位制字面常數並不是這麼回事,它們可以具有正的以及負的數值。如果十六進位制和八進位制字面常數的最高位被置位了,那麼它們就是負數。在這個程式中,數位Oxcafebabe是一個int常數,它的最高位被置位了,所以它是一個負數。它等於十進位制數值-889275714。
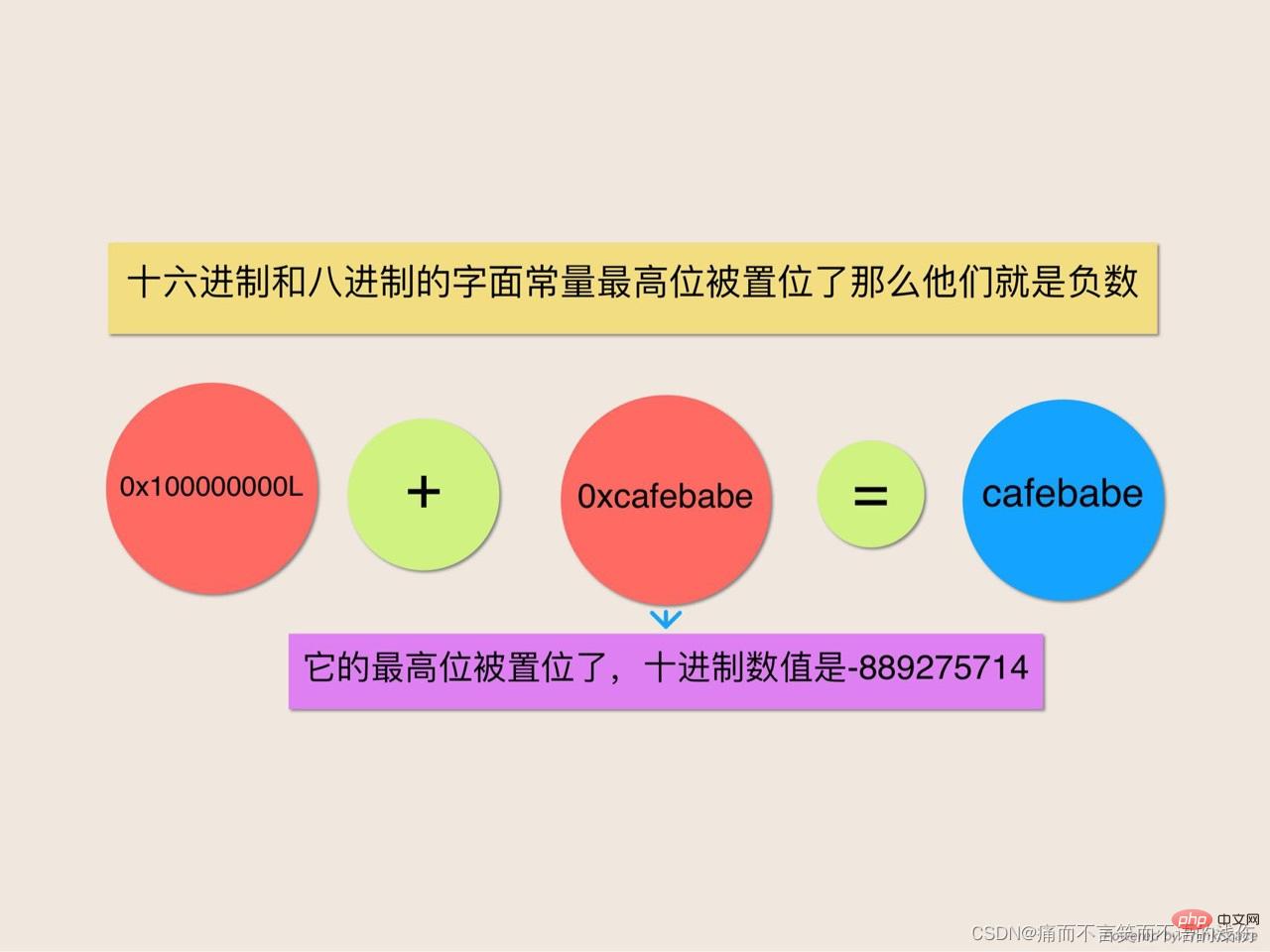
該程式執行的這個加法是一種「混合型別的計算(mixed-type computation)左運算元是long型別的,而右運算元是int型別的。為了執行該計算,Java將int型別的數值用拓寬原始型別轉換提升為一個long型別,然後對兩個long型別數值相加。因為int是一個有符號的整數型別,所以這個轉換執行的是符合擴充套件:它將負的int型別的數值提升為一個在數值上相等的long型別數值。這個加法的右運算元0xcafebabe被提升為了long型別的數值0xffffffffcafebabeL。這個數值之後被加到了左運算元0x100000000L上。當作為int型別來被審視時,經過符號擴充套件之後的右運算元的高32位元是-1,而左運算元的高32位元是1,將這兩個數相加就得到了0,這也就解釋為什麼在程式輸出中前導1丟失了。下面所示是用手寫的加法實現。(在加法上面的數位是進位。)
1111111 0xffffffffcafebabeL +0x0000000100000000L 0x00000000cafebabeL
訂正該程式非常簡單,只需用一個long十六進位制字面常數來表示右運算元即可。這就可以避免了具有破壞力的符號擴充套件,並且程式也就可以列印出我們所期望的結果1cafebabe:
public class JoyOfHex{
public static void main(String[] args){
System.outprintln(
LongtoHexString(0x100000000L+0xcafebabeL));
}
}這個謎題給我們的教訓是:混合型別的計算可能會產生混淆,尤其是十六進位制和八進位制字面常數無需顯式的減號符號就可以表示負的數值。為了避免這種窘境,通常最好是避免混合型別的計算。對於語言的設計者們來說,應該考慮支援無符號的整數型別,從而根除符號擴充套件的可能性。可能會有這樣的爭辯:負的十六進位制和八進位制字面常數應該被禁用,但是這可能會挫傷程式設計師,他們經常使用十六進位制字面常數來表示那些符號沒有任何重要含義的數值。
推薦學習:《》
以上就是整理分享Java語言表示式的五個謎題的詳細內容,更多請關注TW511.COM其它相關文章!