一起分析Redis熱點資料問題解決方案

推薦學習:
關於 Redis 熱點資料 & 大 key 大 value 問題也是容易被問的高階問題,不如一次痛快點學完,讓面試官無話可說,個人工作經驗中,熱點資料問題在工作中相比雪崩更容易遇到,只是大部分時候熱點不夠熱,都會被提前告警解決,但這個問題一旦控制不了造成的線上問題也是足夠讓你今年績效墊底了,廢話不說進入正題。
正常情況下,Redis 叢集中資料都是均勻分配到每個節點,請求也會均勻的分佈到每個分片上,但在一些特殊場景中,比如外部爬蟲、攻擊、熱點商品等,最典型的就是明星在微博上宣佈離婚,吃瓜群眾紛紛湧入留言,導致微博評論功能崩潰,這種短時間內某些 key 存取量過於大,對於這種相同的 key 會請求到同一臺資料分片上,導致該分片負載較高成為瓶頸問題,導致雪崩等一系列問題。
1、面試官:你在專案中有沒有遇到 Redis 熱點資料問題,一般都是什麼原因引起的?
問題分析:上次聽群裡大佬面試阿里 p7 就被問到這個問題,難度指數五顆星,對我等小白著實是加分項。
答:關於熱點資料問題我有話要說,這個問題我早在剛剛學習使用 Redis 時就從已經意識到了,所以在使用時會刻意避免,堅決不會給自己挖坑,熱點資料最大的問題會造成 Reids 叢集負載不均衡(也就是資料傾斜)導致的故障,這些問題對於 Redis 叢集都是致命打擊。
先說說造成 Reids 叢集負載不均衡故障的主要原因:
- 高存取量的 Key,也就是熱 key,根據過去的維護經驗一個 key 存取的 QPS 超過 1000 就要高度關注了,比如熱門商品,熱門話題等。
- 大 Value,有些 key 存取 QPS 雖然不高,但是由於 value 很大,造成網路卡負載較大,網路卡流量被打滿,單臺機器可能出現千兆 / 秒,IO 故障。
- 熱點 Key + 大 Value 同時存在,伺服器殺手。
那麼熱點 key 或大 Value 會造成哪些故障呢:
- 資料傾斜問題:大 Value 會導致叢集不同節點資料分佈不均勻,造成資料傾斜問題,大量讀寫比例非常高的請求都會落到同一個 redis server 上,該 redis 的負載就會嚴重升高,容易打掛。
- QPS 傾斜:分片上的 QPS 不均。
- 大 Value 會導致 Redis 伺服器緩衝區不足,造成 get 超時。
- 由於 Value 過大,導致機房網路卡流量不足。
- Redis 快取失效導致資料庫層被擊穿的連鎖反應。
2、面試官:真實專案中,那熱點資料問題你是如何準確定位的呢?
答:這個問題的解決辦法比較寬泛,要具體看不同業務場景,比如公司組織促銷活動,那參加促銷的商品肯定是有辦法提前統計的,這種場景就可以通過預估法。對於突發事件,不確定因素,Redis 會自己監控熱點資料。大概歸納下:
- 提前獲知法:
根據業務,人肉統計 or 系統統計可能會成為熱點的資料,如,促銷活動商品,熱門話題,節假日話題,紀念日活動等。 - Redis 使用者端收集法:
呼叫端通過計數的方式統計 key 的請求次數,但是無法預知 key 的個數,程式碼侵入性強。public Connection sendCommand(final ProtocolCommand cmd, final byte[]... args) { //從引數中獲取key String key = analysis(args); //計數 counterKey(key); //ignore } Redis 叢集代理層統計:
像 Twemproxy,codis 這些基於代理的 Redis 分散式架構,統一的入口,可以在 Proxy 層做收集上報,但是缺點很明顯,並非所有的 Redis 叢集架構都有 proxy。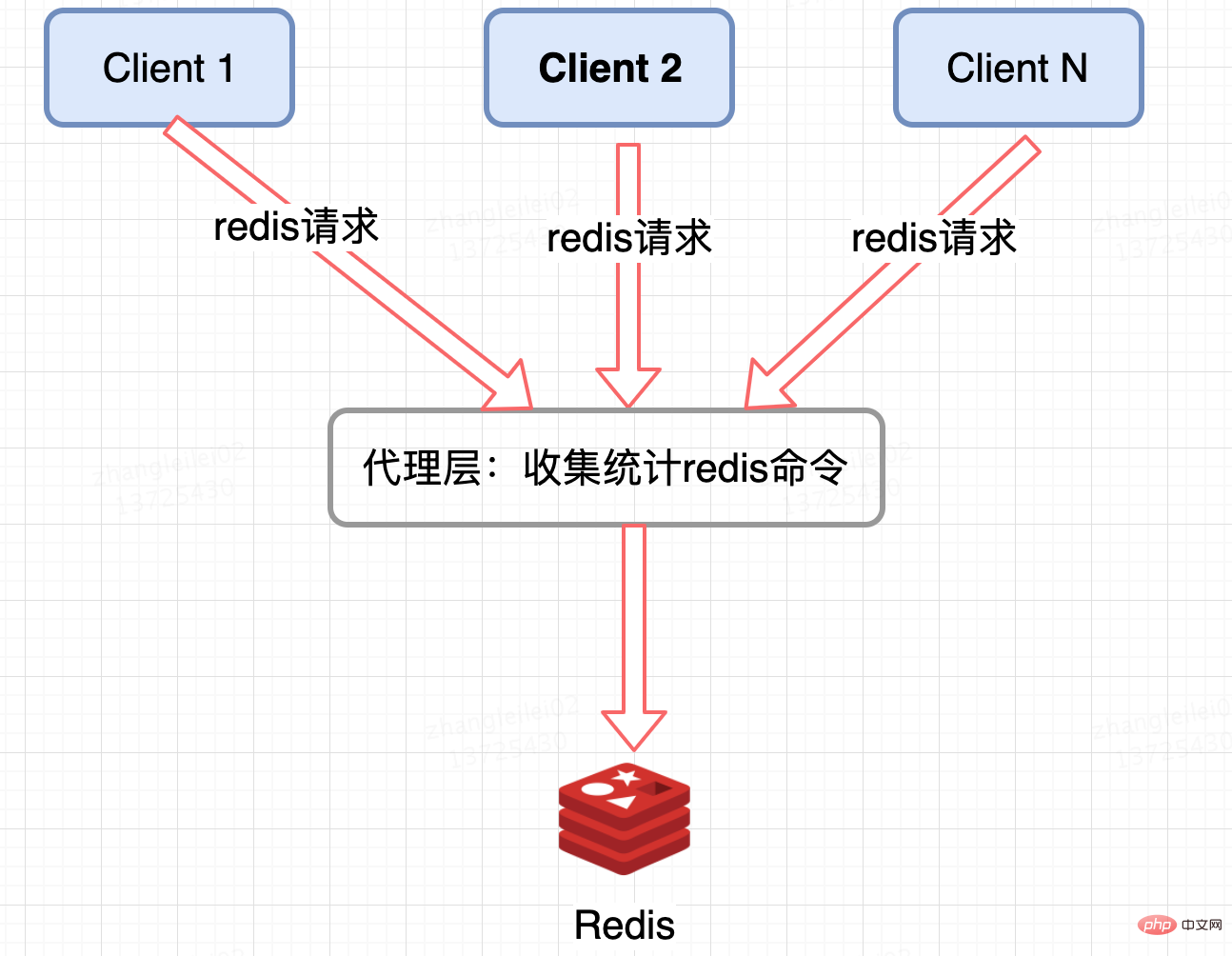
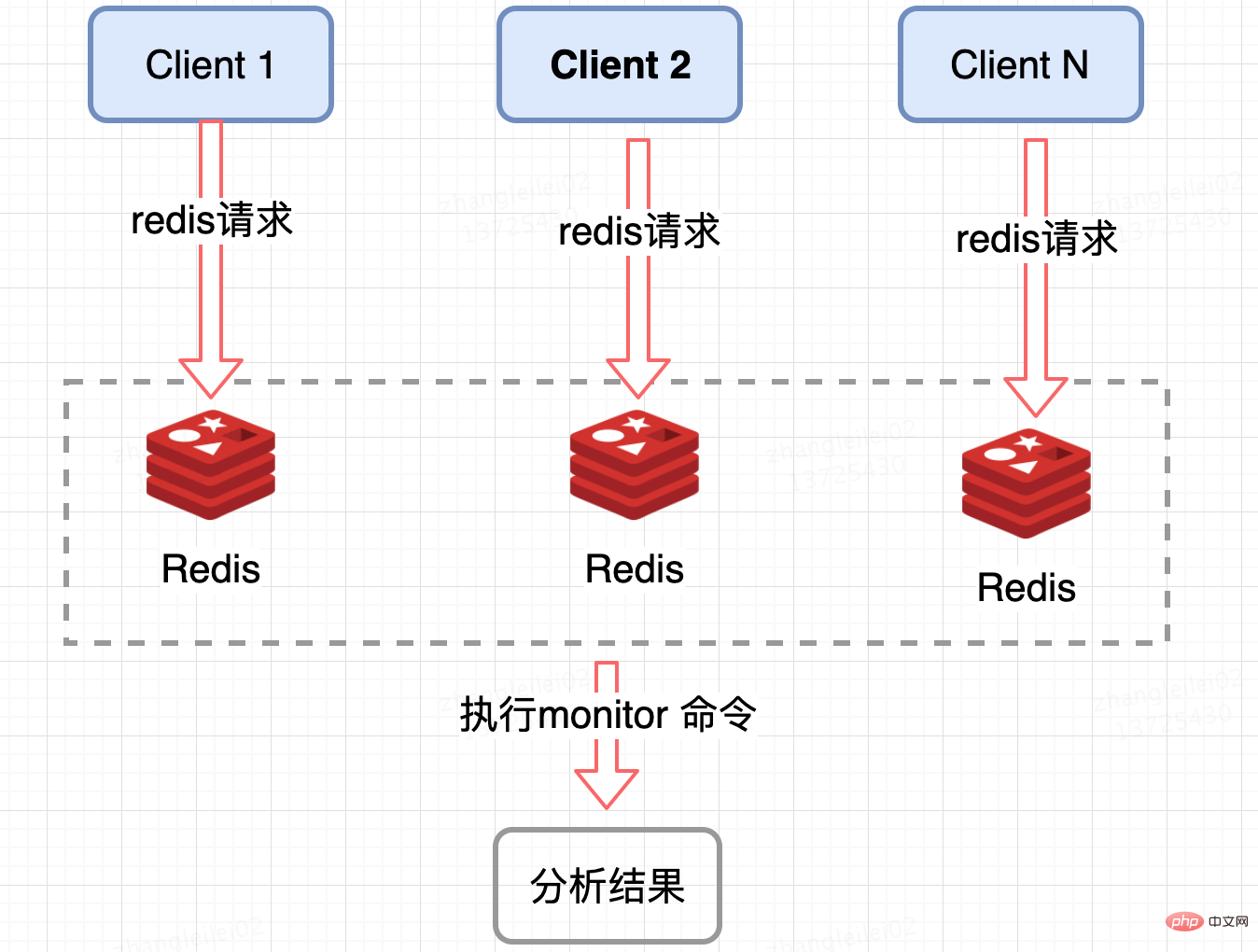
Redis 伺服器端收集:
監控 Redis 單個分片的 QPS,發現 QPS 傾斜到一定程度的節點進行 monitor,獲取熱點 key, Redis 提供了 monitor 命令,可以統計出一段時間內的某 Redis 節點上的所有命令,分析熱點 key,在高並行條件下,會存在記憶體暴漲和 Redis 效能的隱患,所以此種方法適合在短時間內使用;同樣只能統計一個 Redis 節點的熱點 key,對於叢集需要彙總統計,業務角度講稍微麻煩一點。
以上為說的這 4 個方法都是現在業界比較常用的,方法,我通過學習 Redis 原始碼還有一個新的想法。第 5 種:修改 Redis 原始碼。
修改 Redis 原始碼:(從讀原始碼中想到的思路)
我發現 Redis4.0 為我們帶來了許多新特性,其中便包括基於 LFU 的熱點 key 發現機制,有了這個新特性,我們就可以在此基礎上實現熱點 key 的統計,這個只是我的個人思路。
面試官心理:小夥子還挺有想法,思路挺開闊,還打起了修改原始碼的注意,我都沒這個野心。團隊裡就需要這樣的人。
(發現問題,分析問題,解決問題,不等面試官發問,直接講述如何解決熱點資料問題,這才是核心內容)
3、如何解決熱點資料問題
答:關於如何治理熱點資料問題,解決這個問題主要從兩個方面考慮,第一是資料分片,讓壓力均攤到叢集的多個分片上,防止單個機器打掛,第二是遷移隔離。
概括總結:
- key 拆分:
如果當前 key 的型別是一個二級資料結構,例如雜湊型別。如果該雜湊元素個數較多,可以考慮將當前 hash 進行拆分,這樣該熱點 key 可以拆分為若干個新的 key 分佈到不同 Redis 節點上,從而減輕壓力 - 遷移熱點 key:
以 Redis Cluster 為例,可以將熱點 key 所在的 slot 單獨遷移到一個新的 Redis 節點上,這樣這個熱點 key 即使 QPS 很高,也不會影響到整個叢集的其他業務,還可以客製化化開發,熱點 key 自動遷移到獨立節點上,這種方案也較多副本。 - 熱點 key 限流:
對於讀命令我們可以通過遷移熱點 key 然後新增從節點來解決,對於寫命令我們可以通過單獨針對這個熱點 key 來限流。 - 增加本地快取:
對於資料一致性不是那麼高的業務,可以將熱點 key 快取到業務機器的本地快取中,因為是業務端的本地記憶體中,省去了一次遠端的 IO 呼叫。但是當資料更新時,可能會造成業務和 Redis 資料不一致。
面試官:你回答得很好,考慮得很全面。
4、面試官:關於 Redis 最後一個問題,Redis 支援豐富的資料型別,那麼這些資料型別儲存的大 Value 如何解決,線上有遇到這種情況嗎?
問題分析:相比熱點 key 大概念,大 Value 的概念比好好理解,由於 Redis 是單執行緒執行的,如果一次操作的 value 很大會對整個 redis 的響應時間造成負面影響,因為 Redis 是 Key - Value 結構資料庫,大 value 就是單個 value 佔用記憶體較大,對 Redis 叢集造成最直接的影響就是資料傾斜。
答:(想難倒我?我可是有備而來。)
我先說說多大的 Value 算大,根據公司基礎架構給出的經驗值可做以下劃分:
注:(經驗值不是標準,都是根據叢集運維人員長期觀察線上 case 總結出來的)
- 大:string 型別 value > 10K,set、list、hash、zset 等集合資料型別中的元素個數 > 1000。
- 超大: string 型別 value > 100K,set、list、hash、zset 等集合資料型別中的元素個數 > 10000。
由於 Redis 是單執行緒執行的,如果一次操作的 value 很大會對整個 redis 的響應時間造成負面影響,所以,業務上能拆則拆,下面舉幾個典型的分拆方案:
- 一個較大的 key-value 拆分成幾個 key-value ,將操作壓力平攤到多個 redis 範例中,降低對單個 redis 的 IO 影響
- 將分拆後的幾個 key-value 儲存在一個 hash 中,每個 field 代表一個具體的屬性,使用 hget,hmget 來獲取部分的 value,使用 hset,hmset 來更新部分屬性。
- hash、set、zset、list 中儲存過多的元素
類似於場景一中的第一個做法,可以將這些元素分拆。
以 hash 為例,原先的正常存取流程是:
hget(hashKey, field); hset(hashKey, field, value)
現在,固定一個桶的數量,比如 10000,每次存取的時候,先在本地計算 field 的 hash 值,模除 10000,確定該 field 落在哪個 key 上,核心思想就是將 value 打散,每次只 get 你需要的。
newHashKey = hashKey + (hash(field) % 10000); hset(newHashKey, field, value); hget(newHashKey, field)
推薦學習:
以上就是一起分析Redis熱點資料問題解決方案的詳細內容,更多請關注TW511.COM其它相關文章!