
今天是 OneFlow 開源的 610 天,OneFlow v0.7.0 正式釋出。歡迎下載體驗最新版本:
本次更新包含以下重點:
-
完善地提供了一種可以幫助使用者輕鬆使用多機多卡執行的機制 :Global Tensor是 OneFlow 為社群帶來的分散式執行的易用方案,用它可以方便地實現各種分散式並行策略,極大提高分散式實現的靈活性和易用性。基於 Global Tensor,OneFlow已支援 ResNet50、Wide and Deep、GPT、Bert、Swin-Transformer、InsightFace 等模型的並行化。
-
持續完善 nn.Graph 功能,支援包括 ZeRO 、GradAcc、Checkpointing、Pipeline 相關的高階功能,豐富了 graph.debug 模式。新增支援任意 2D SBP 轉換、支援 2D SBP 的半自動推導、支援斷點續訓等。 新增 OneFlow Feature Stages 標識,並給 nn.Graph 所提供的每一個功能都增加該標識。就 nn.Graph 整體而言, 基礎功能進入 Beta Stage,可以支援對該功能的大部分需求;高階功能進入 Alpha Stage,可支援對該功能的標準需求。
-
深度優化 Eager 效能, 在 V100 顯示卡上測試 Swin-Transformer 模型的單卡效能相比 v0.6.0 提升 3 倍。
-
運算元相關進展:在單機單卡場景下,OneFlow 對 PyTorch 的相容性進一步完善,OneFlow 已經支援的運算元都保證和 PyTorch 的介面、語意、結果一致;另外設計了一套自動測試框架來驗證一致性,常見網路可以做到import oneflow as torch 來完成遷移。相較於 v0.6.0, OneFlow 新增 16 個運算元,優化 6 個運算元的效能,修復 16 個運算元存在的 bug。
-
支援 Einsum 運算元和 View 機制。
-
OneFlow 正式接入 MLIR 編譯器生態。
-
釋出 OneFlow-Serving v0.1.0,提供了開箱即用的 Triton OneFlow backend 映象(https://github.com/Oneflow-Inc/serving)。
-
釋出 LiBai(李白) v0.1.0:這是一個針對 Transformer 的大規模分散式並行訓練程式碼庫,相比 Megatron-LM 等客製化化程式碼庫,基於模組化設計的 LiBai 為分散式訓練提供了一系列模型和訓練元件,讓分散式下的模型訓練像單卡一樣方便(https://github.com/Oneflow-Inc/libai)。
-
釋出 Flow-Vision v0.1.0:新增 DeiT、ConvNeXt、ReXNet 等模型,完善了使用教學和檔案(https://github.com/Oneflow-Inc/vision)
以下為版本更新詳情。
1 分散式
Global Tenso
Global Tensor 是OneFlow釋出的一套全新的分散式計算介面,可以很方便地支援包括資料並行、模型並行和流水並行在內的任意並行方式。不同於普通 Tensor(下文叫 Local Tensor),Global Tensor 是一種全域性視角下的 Tensor, 它的資料以特定方式分佈在叢集中的一組計算節點上,每個節點儲存了該 Tensor 的部分或全部資料。placement 和 SBP 是每個 Global Tensor 的基本屬性,描述了其資料在叢集中的分佈方式。
Global Tensor 的資料分佈方式
Global Tensor 支援三種不同的資料分佈方式,我們將其統稱為 SBP。
-
Split (dim):資料以dim 維度平均切分並分佈到每一個計算節點上。
-
Broadcast:資料在每一個計算節點間進行復制。
-
PartialSum:資料為每一個計算節點的 element-wise 加和。
統一的計算介面
Global Tensor 具有和 Local Tensor 基本一致的計算介面,支援以很少的改動就可以將一個單卡的程式碼轉換成分散式方式執行。
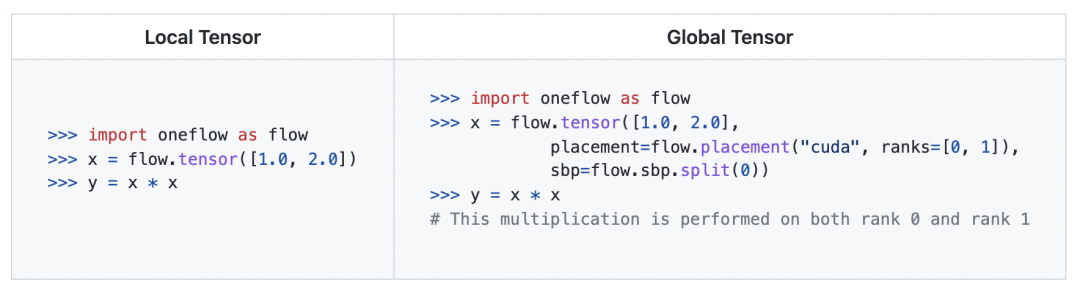
支援 Local Tensor 與 Global Tensor 的轉換
-
Local Tensor 可以使用 Tensor.to_global 介面建立一個 Global Tensor,並將該 Local Tensor 作為它在當前節點的本地分量。
-
Global Tensor 可以使用 Tensor.to_local 介面返回它在當前節點的本地分量。
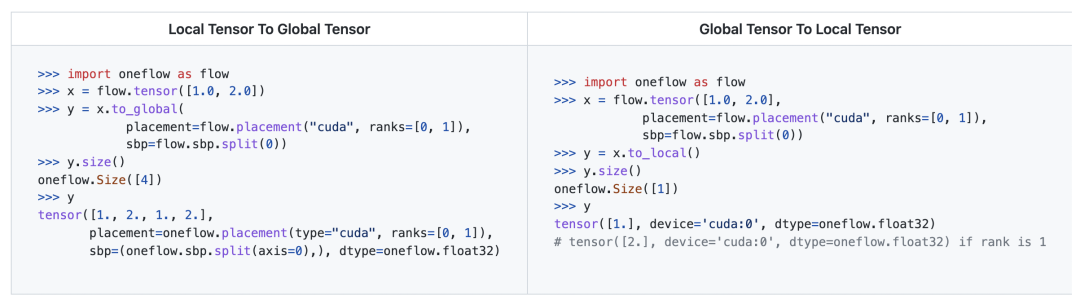
支援 Global Tensor 在叢集中重新分佈
Global Tensor 使用 Tensor.to_global 介面支援在叢集中進行資料的重新分佈,既可以選擇分佈到另外一組節點上,也可以改變它在這組節點上的分佈方式(即改變 SBP )。 重新分佈通常會發生跨程序的資料通訊,Tensor.to_global 這個介面很好地遮蔽了複雜的底層通訊邏輯。
>>> import oneflow as flow>>> x = flow.tensor([1.0, 2.0], placement=flow.placement("cuda", ranks=[0, 1]), sbp=flow.sbp.split(0))>>> y = x.to_global(placement=flow.placement("cuda", ranks=[2, 3]), sbp=flow.sbp.broadcast)
OneFlow 中每一種計算介面都定義了一套其所能支援的輸入和輸出的 SBP 組合,Global Tensor 支援自動重新分佈,以滿足執行某個計算介面對其 SBP 的要求。比如下面的程式碼:
>>> import oneflow as flow>>> x = flow.randn(4, 4,placement=flow.placement("cuda", ranks=[0, 1]),sbp=flow.sbp.split(0))>>> y = flow.randn(4, 4,placement=flow.placement("cuda", ranks=[0, 1]),sbp=flow.sbp.split(1))>>> z = x + y
當執行 x + y 時由於 x 是按第 0 維切分,y 是按第 1 維切分,它們在每個節點上的分量無法直接完成相加,那麼它就會自動將 x 的 SBP 轉換成flow.sbp.split(1) 或者將 y 自動轉換成flow.sbp.split(0) ,計算得到的結果 z 的 SBP 為 flow.sbp.split(1) 或 flow.sbp.split(0) 。
注意
-
Global Tensor 目前不支援和 DDP 介面混合使用;
-
Global Tensor 的程式碼要求所有節點一起執行,有分支的程式碼可能會因為執行路徑分散而導致程序死鎖,我們會持續改進這裡的使用者體驗。
2 持續完善 nn.Graph 的功能
新增 OneFlow Feature Stages 標識
OneFlow Feature Stages 標識 OneFlow 功能的成熟度等級依次為 Pre-alpha Stage、Alpah Stage、Beta Stage、Release candidate (RC) Stage、 Stable Stage 。它給使用者提供功能的狀態說明,以瞭解該功能下所提供的保證,如功能完備性、API 穩定性、檔案等;它還為開發者提供完善功能的標準,並據此推進對應功能走向成熟。
nn.Graph v0.7.0 進展概述
-
基礎功能進入 Beta Stage,可以支援對該功能的大部分需求;
-
高階功能進入 Alpha Stage,可支援對該功能的標準需求;
-
已經支援了 ResNet50、Wide and Deep、GPT、Bert、Swin-Transformer、InsightFace 等模型。
nn.Graph 靜態圖下 Feature
-
Static Graph下的 Op 動靜轉換功能,從 Alpha Stage 到 Beta Stage
-
新增所有合法 Op 在 nn.Graph 做靜態執行的單測,自動化單測功能完備;
-
新增支援更為靈活的輸入輸出,包括 List/Tuple/Dict 以及它們的巢狀,修復返回大小為 1 的 Tuple 問題;
-
新增後向的自動測試。
-
-
Static Graph 下的 Optimizer 和 LR Scheduler, 從 Alpha Stage 進步到 Beta Stage
-
新增更多的內建 LR scheduler,例如 WarmupLR, CosineAnnealingWarmRestarts 等常見的 scheduler ,同時提供 SequentialLR 和 ChainedScheduler 來為 scheduler 提供不同的組合能力;
-
重構了 scheduler 的 get_lr 函數,將其改造成純函數的實現,目的是為了把 lr 的計算由迭代解切換到解析解,為 scheduler 的組合使用提供支撐;
-
add_optimizer介面新增引數 is_sparse。用以支援 graph 模式下的稀疏更新,支援稀疏更新的 optimizer 有 Adam 和 SGD。Eager 模式下的 optimizer 還未支援稀疏更新策略,後續版本會同稀疏張量一起支援。功能狀態為 Pre-alpha Stage; -
新增 LR 和 Step 的 Debug 列印功能,開啟 LR Scheduler 的verbose 開關即可。
-
-
Static Graph 下新增state_dict 和load_state_dict ,支援斷點續訓,功能狀態為 Beta Stage
-
Static Graph 下的 Debug,從 Alpha Stage 進入 Beta Stage
-
新增 debug(2) 、
debug(3),可以分 nn.Module 去定位問題,可定位 C++ 層 Op 對應的 Python 程式碼,可定位 Op 的前向圖建立和推理; -
新增顯示記憶體開銷。
-
-
Static Graph 下新增 ZeRO-DP 的支援,在資料並行下縮減和 Optimizer 關聯的視訊記憶體開銷,功能狀態為 Alpha Stage
-
Static Graph 下的 Global Tensor,多種並行執行,整體狀態為 Alpha 和 Beta 之間
-
已在 LiBai 等多個模型庫中使用;
-
已經在 OneFlow 模型庫中廣泛使用,單測的覆蓋在進行中;
-
1D Global Tensor支援只定義 Source Tensor 的 SBP,下游可以自動推導,而且效果良好,Beta Stage;
-
新增 2D Global Tensor 支援只定義 Source Tensor 的 SBP ,下游可以自動推導,而且效果良好,Alpha Stage;
-
新增支援 1D to ND 與 ND to 1D 的轉換, Alpha Stage;
-
新增支援任意 2D SBP 的轉換, Alpha Stage;
-
1D&2D 單 Op 的測試在覆蓋中,Pre-alpha Stage;
-
支援選擇半自動推導 SBP的挑選策略,Pre-alpha Stage。
-
-
Static Graph 下的梯度累積(Gradient Accumulation),重構和修復 Reshape 的支援,新增 API 檔案,當前介面為mini-batch 的輸入,下個版本將更新為體驗更好的micro-batch 的輸入,功能狀態從 Pre-Alpha 到 Alpha;
-
Static Graph 下的流水並行,完善了教學,在 Libai 等多個模型庫進入使用,功能狀態為 Beta;
-
Static Graph 下的自動混合精度 AMP,新增 API 檔案,功能狀態 Pre-Alpha 到 Alpha;
-
Static Graph 下的 Activation Checkpointing,新增 API 檔案,功能狀態從 Pre-Alpha 到 Alpha;
-
Static Graph 下的多種 Op Fuse 優化,新增 API 檔案,功能狀態 Pre-Alpha 到 Alpha;
-
Static Graph 下的 XLA/TensorRT/OpenVINO 執行,新增 API 檔案,功能狀態 Pre-Alpha 到 Alpha。
教學
-
En https://docs.oneflow.org/en/master/basics/08_nn_graph.html
-
中 https://docs.oneflow.org/master/basics/08_nn_graph.html
API檔案
-
En https://oneflow.readthedocs.io/en/master/graph.html
-
中 https://start.oneflow.org/oneflow-api-cn/graph.html
流水並行的教學
-
En https://docs.oneflow.org/en/master/parallelism/06_pipeline.html
-
中 https://docs.oneflow.org/master/parallelism/06_pipeline.html
nn.Graph 靜態圖下的模型支援
-
支援ResNet50單機單卡和單機多卡( https://github.com/Oneflow-Inc/models/tree/main/Vision/classification/image/resnet50)
-
支援了Wide and Deep模型( https://github.com/Oneflow-Inc/models/tree/main/RecommenderSystems/wide_and_deep)
-
支援了Libai中的GPT、Bert、Swin Transformer( https://github.com/Oneflow-Inc/libai)
-
修復了以上多種模型的支援中遇到的功能問題
3 深度優化 Eager 效能
-
深度優化 Eager 效能,OneFlow 在 V100 顯示卡上測試 Swin-Transformer 模型效能,單卡比 PyTorch 快25%, 8卡 DDP 比 PyTorch 快10%
-
優化 DDP 中的 NCCL 通訊排程邏輯
-
DDP 支援 AllReduce fuse 優化,減少碎片化的 AllReduce 引起的額外開銷,在 ResNet50 上測試有約 5% 的效能提升
-
VM 支援指令融合優化,大幅節省零碎小 Kernel 的排程開銷
-
優化了 CPU 負載較高時的額外記憶體開銷
-
Eager DataLoader 支援程序間記憶體共用優化
-
深度優化 Clip Grad 效能
4 運算元相關進展
-
OneFlow 成功適配 oneDNN 用於 CPU 運算元加速,unary 和 binary element-wise 等 CPU 運算元的效能提升 4 倍,Swin-Transformer 的 dataloader 速度提升 2.5 倍。
-
DataLoader 新增程序間記憶體共用功能,大幅提升 DataLoader 在 DDP 情況下的效能。
-
新增 Bool 型別 Tensor。
-
新增 To_contiguous 運算元服務於 view 機制。
-
新增 Scalar div 運算元。
-
新增 Lamb 優化器。
-
新增 Polynomial Learning Rate Scheduler。
-
新增 Tensor_split,As_strided 運算元。
-
新增 Cumprod 運算元。
-
新增 Tensor.T() 和 oneflow.t() 運算元。
-
新增 Normalize 運算元。
-
新增 div 和 sub 運算元的 inplace 版本。
-
新增 Module.zero_grad 功能。
-
新增 Scalar Tensor 作為索引來做 list indexing 的功能。
-
新增 Leaky ReLU 運算元的 half 型別支援。
-
新增 Mask Select 運算元支援。
-
新增 Bool 型別的 Broadcast 及 Allgather 等非 reduce 通訊操作。
-
基於自動測試框架開發支援 eager global 的自動測試。
-
優化 ReduceSum CUDA Kernel 的效能。
-
優化 Gather 運算元的 CUDA Kernel 的效能。
-
優化 NCHW 情況下的 MaxPool 和 AvgPool 運算元的 CUDA Kernel效能。
-
優化 PReLU 運算元的後向計算部分,一般情況下可以節省較多視訊記憶體。
-
優化 LayerNorm 後向 Kernel,進一步節省視訊記憶體。
-
Conv1D/2D/3D 和 DeConv1D/2D/3D Kernel,stride 和 dilation 引數支援單個 int 傳參,新增 Tensor.zero_() 介面,對齊 PyTorch tensor.norm,torch.max,torch.min 用法,flow.nn.functional.dropout 支援 inplace。
-
修復 BatchNorm 模組在 affine 引數為 False 執行報錯的 bug。
-
修復 Maximum,Mimimum 反向的 bug。
-
修復 Var 運算元 在某些情況下結果不符合預期的 bug。
-
修復 Tensor deepcopy 時行為不正確的 bug。
-
修復 Slice 運算元輸入 index 是 scalar tensor 時的 bug。
-
修復 BinaryCrossEntropy 在 half 情況下可能產生 nan 的 bug。
-
修復 Pow 運算元底數和指數分別為實數和 Tensor 型別時報錯的 bug。
-
修復 Stack 運算元后向的 bug。
-
修復 Clip grad 在預設設定下並在 CUDA 上執行時 CPU 同步導致的效率過低問題。
-
修復 Batch Gather 和 Unsorted Batch Segment Sum 運算元的 sbp 推導,global 單測通過。
-
修復 Affine Grid 運算元的 Physical Shape 推導,並修復某些 SBP 情況下計算結果不符合預期的 bug ,global 單測通過。
-
修復 Arange 運算元 不支援產生 0 size tensor 的問題,global 單測通過。
-
修復 Flip 運算元 SBP 推導不正確的問題,global 單測通過。
-
修復 Advanced Indexing 和 ZerosLike 運算元 SBP 的 bug。
-
修復 Eager global inplace 可能不成功的 bug。
5 支援 Einsum & View 機制
新增 einsum 運算元,einsum 提供了一套既簡潔又優雅的規則,可實現包括但不限於內積、外積、張量乘法、張量轉置和張量收縮(tensor contraction)等張量操作,熟練運用 einsum 可以很方便實現各種複雜的張量操作且不容易出錯。
新增 view 機制 。通過 view 機制,一些常用運算元可以實現 Tensor 的記憶體複用/共用,這樣就能省去 Kernel Launch/Compute 的過程,並達到節省視訊記憶體的效果。目前,新增了 reshape, view, squeeze, unsqueeze 等不會改變 tensor.is_contiguous() 屬性的 view 運算元, 後續會增加更多 view 運算元(如 transpose, permute, narrow, expand, unfold 等)。
6 編譯器相關進展
OneFlow 正式接入 MLIR 生態,OneFlow Dialect 元件已經完備。成功完成了 OneFlow Job(OneFlow nn.Graph 的計算圖)和 MLIR 的 RoundTrip,並對 OneFlow 所有的運算元在 CI 流程中進行 RoundTrip 測試。
基於 MLIR DRR 實現了一系列自動 Fused 運算元的靜態圖優化,加速 OneFlow 模型訓練和推理。
7 OneFlow Serving
OneFlow Serving 釋出 v0.1.0 版本,特性如下:
-
提供用於推理的 OneFlow C++ API,支援載入模型和靜態圖推理。
-
模型訓練者可以在 Python 中執行 flow.save(graph) 來同時儲存模型權重和 MLIR 格式的計算圖,用於在 C++ API 中載入並推理(暫不支援在 Python API 中載入計算圖)。
-
支援自動使用 TensorRT 和 OpenVINO 推理 OneFlow 模型,無需模型轉換(基於 OneFlow XRT 模組),在 NVIDIA GPU 和 Intel CPU 上可以取得更好的加速效果。
-
實現 Triton OneFlow backend
-
提供開箱即用的 Docker 映象
-
支援 auto configuration,部署時只需要給出模型路徑,不需要寫 Triton 組態檔
-
-
在 OF 智慧雲上線了一個 使用 Triton OneFlow backend 進行部署的專案( https://oneflow.cloud/drill/#/project/public/code?id=7fc904d8dbe0069820da5d6d32a764fe ),歡迎試玩。
8 LiBai(李白)
LiBai是一個針對 Transformer 的大規模分散式並行訓練程式碼庫,相比於 Megatron-LM 等客製化化程式碼庫,基於模組化設計的LiBai為分散式訓練提供了一系列模型和訓練元件,旨在讓分散式下的模型訓練像單卡一樣方便,v0.1.0 版本主要支援下面的特性和模型:
特性:
-
資料並行 (Data Parallelism)
-
1維張量並行 (1D Tensor Parallelism)
-
流水線並行 (Pipeline Parallelism)
-
單卡和多卡統一的分散式網路層 (Unified Distributed Layers)
-
可延伸新的並行方式 (Extensible for new parallelism)
-
混合精度訓練 (Mixed Precision Training)
-
後向重計算 (Activation Checkpointing)
-
梯度累加 (Gradient Accumulation)
-
梯度裁剪 (Gradient Clip)
-
零冗餘優化器 (ZeRO)
-
更靈活的 "LazyConfig" 設定系統
-
易於使用的 Trainer 和 Evaluator
-
支援影象和文字的資料預處理
模型:
-
Bert (3D 並行)
-
GPT-2 (3D 並行)
-
ViT (3D 並行)
-
Swin-Transformer (資料並行)
-
在 projects/中支援微調任務
-
在 projects/中支援文字分類任務
9 flow-vison
flowvision 釋出 v0.1.0 穩定版本,在之前的版本基礎上作了以下改進:
-
新增 trunc_normal_ 初始化方法
-
新增 DeiT 模型,重構 VisionTransformer 模型
-
新增 ConvNeXt 模型
-
新增 ReXNet 模型
-
支援 PolyLRScheduler 和 TanhLRScheduler 學習率調整策略
-
修復在 SSD 模型中 F.normalize 的使用
-
修復 EfficientNet 和 Res2Net 中的 Bug
-
修復 vit_small_patch32_384 模型與 res2net50_48w_2s 模型的權重問題
-
重構 model zoo 並對已有模型進行了更全面完整的測試
-
重構 load_state_dict_from_url 方法,自動儲存下載的權重至 cache 資料夾
-
完善 Getting Started 和 flowvision.models 的相關檔案
flowvision 的 v0.2.0 版本已經在推進, 將在 v0.1.0 版本上新增大量模型並完善檔案,敬請期待。
其他人都在看
歡迎下載體驗OneFlow新一代開源深度學習框架: