redis資料結構知識圖文詳解

推薦學習:
redis的資料結構:String(字串)、List(列表)、hash(雜湊)、Set(集合)、Shorted Set(有序集合)
底層資料結構:簡單動態字串、雙向連結串列、壓縮列表、雜湊表、跳錶、整數陣列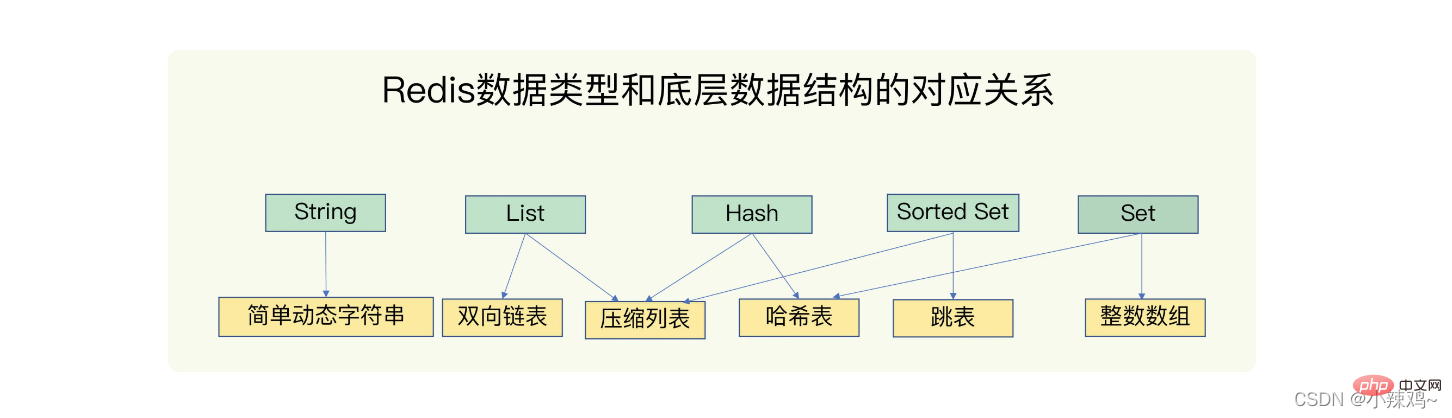
1.雜湊表:一個雜湊表其實就是一個陣列,陣列中的每一個元素稱為一個雜湊桶。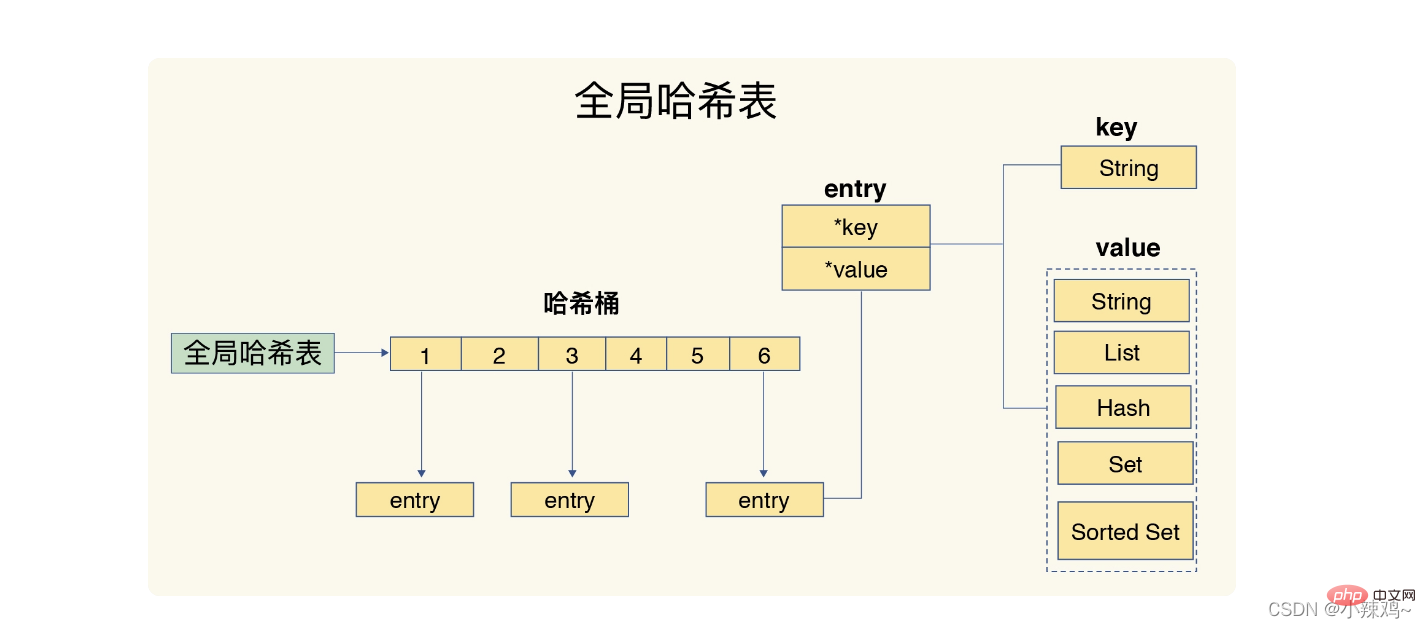
雜湊衝突和rehash可能會帶來操作阻塞。
redis解決雜湊衝突的方法是鏈式雜湊,而rehash是增加現有hash桶的數量。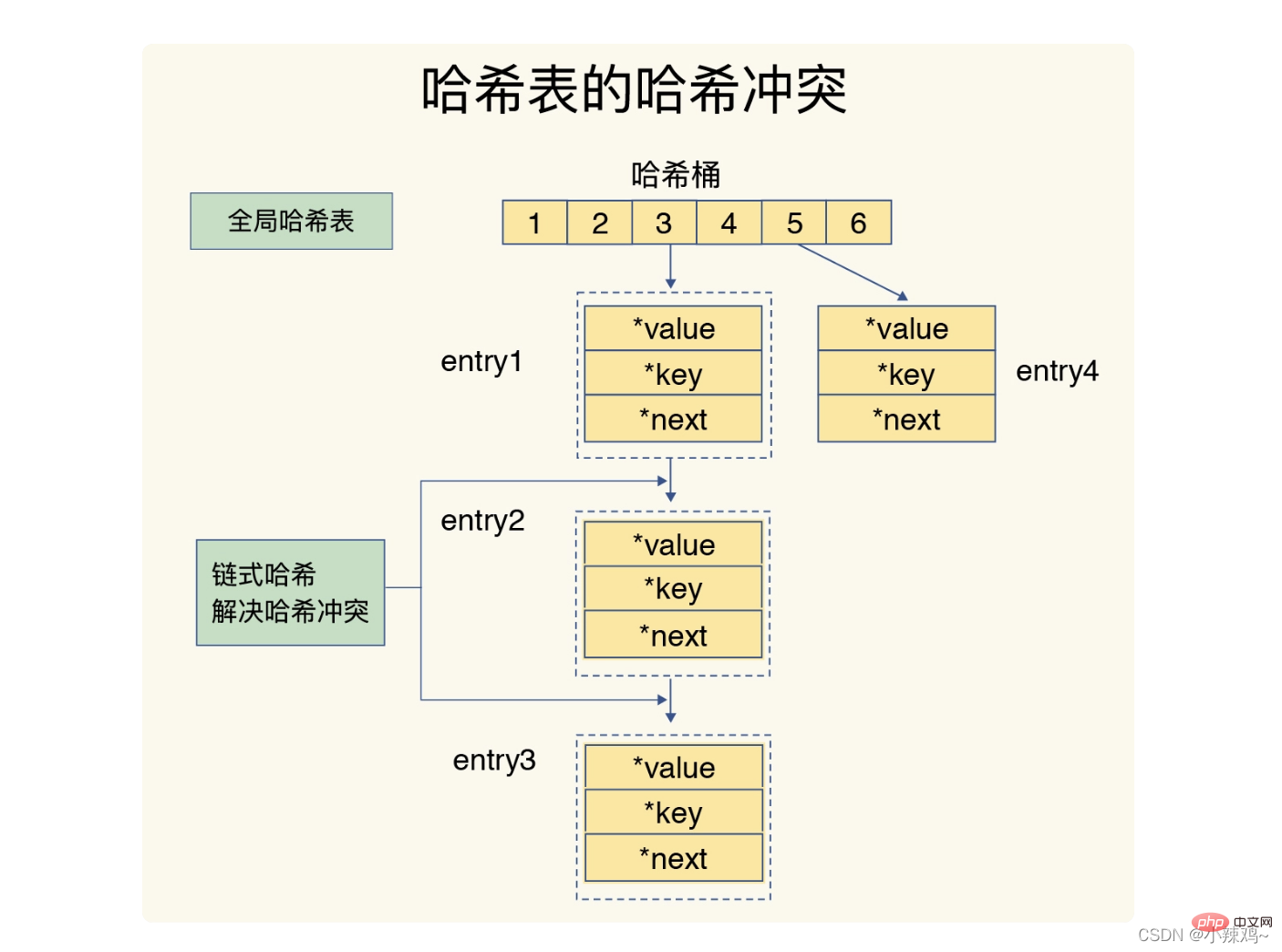
rehash的操作步驟:1.給雜湊表分配更大的空間,例如是當前hash表大小的兩倍
2.把雜湊表1中的資料重新對映並拷貝到hash表2上
3.釋放雜湊表1的空間
第二步涉及大量資料拷貝操作,如果一次性把雜湊表1中的資料都遷移完,會造成執行緒阻塞,無法服務其他請求。為了避免這一問題,redis採用漸進式rehash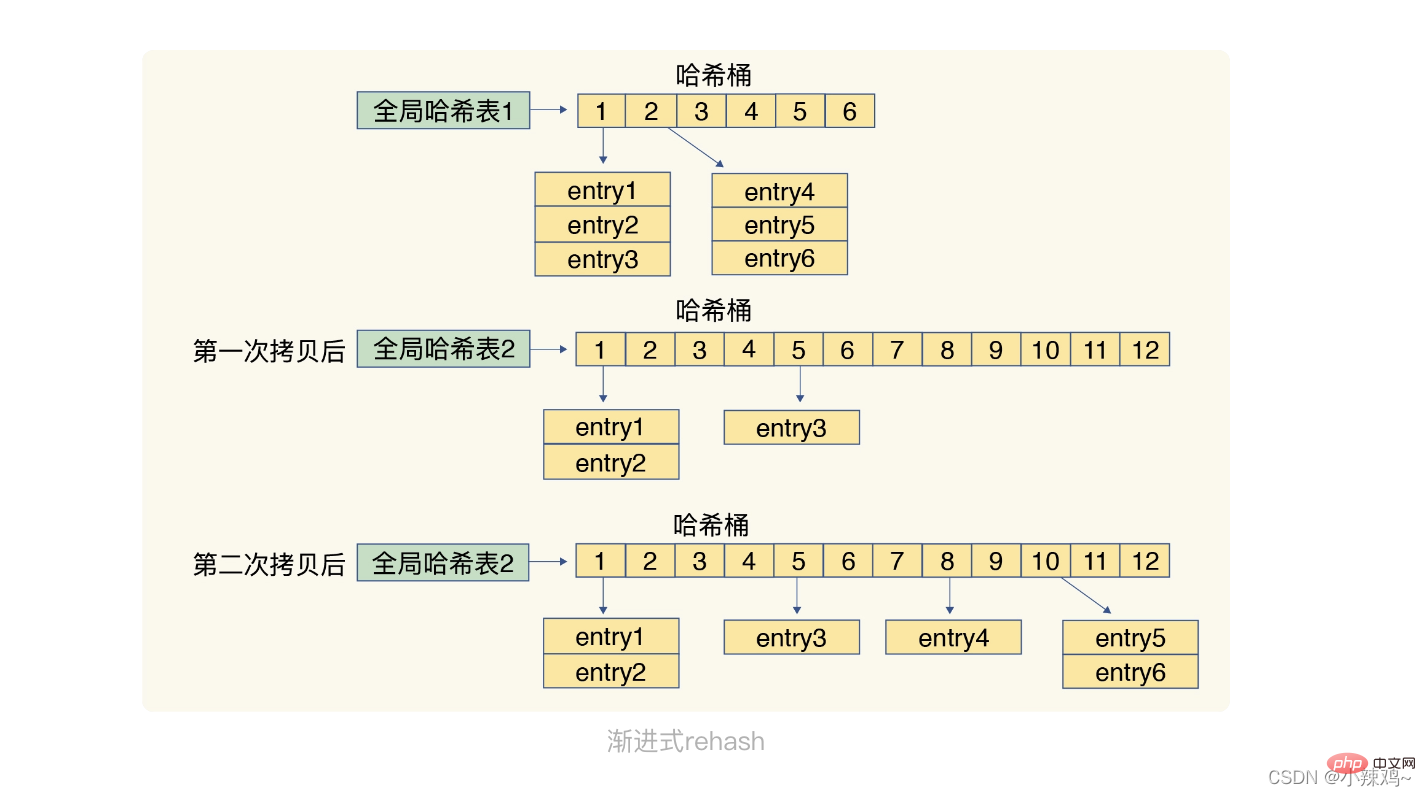
整數陣列和雙向連結串列的複雜度都是O(N)
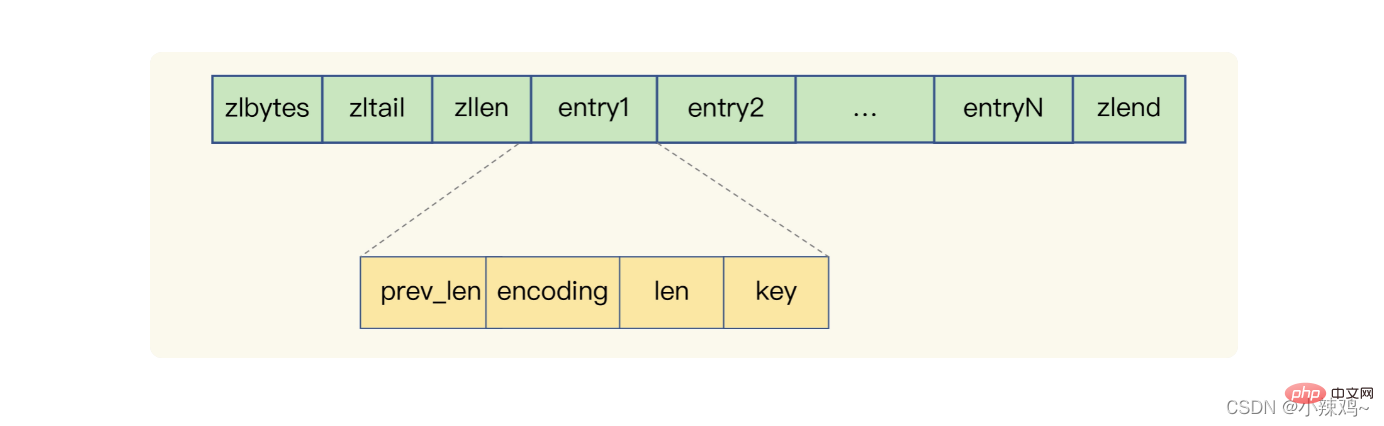
壓縮列表在表頭有三個資料分別是列表長度、列表尾的偏移量和列表中entry個數
壓縮列表在表尾還有一個元素zlend代表列表結束
跳錶:有序連結串列只能逐一查詢元素,而跳錶在連結串列的基礎上增加了多級索引,通過索引位置的幾次跳轉實現資料的快速定位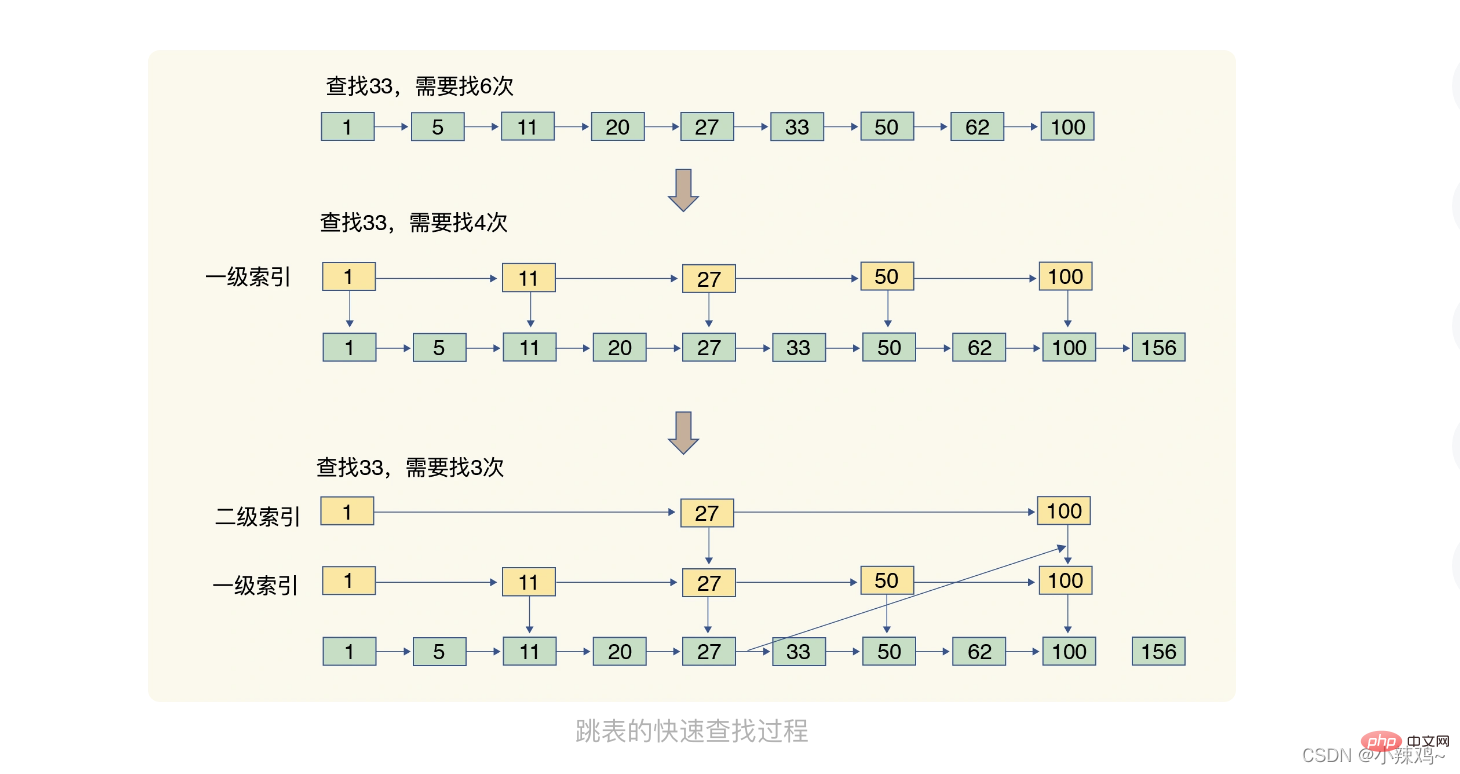
以下五種結構的時間複雜度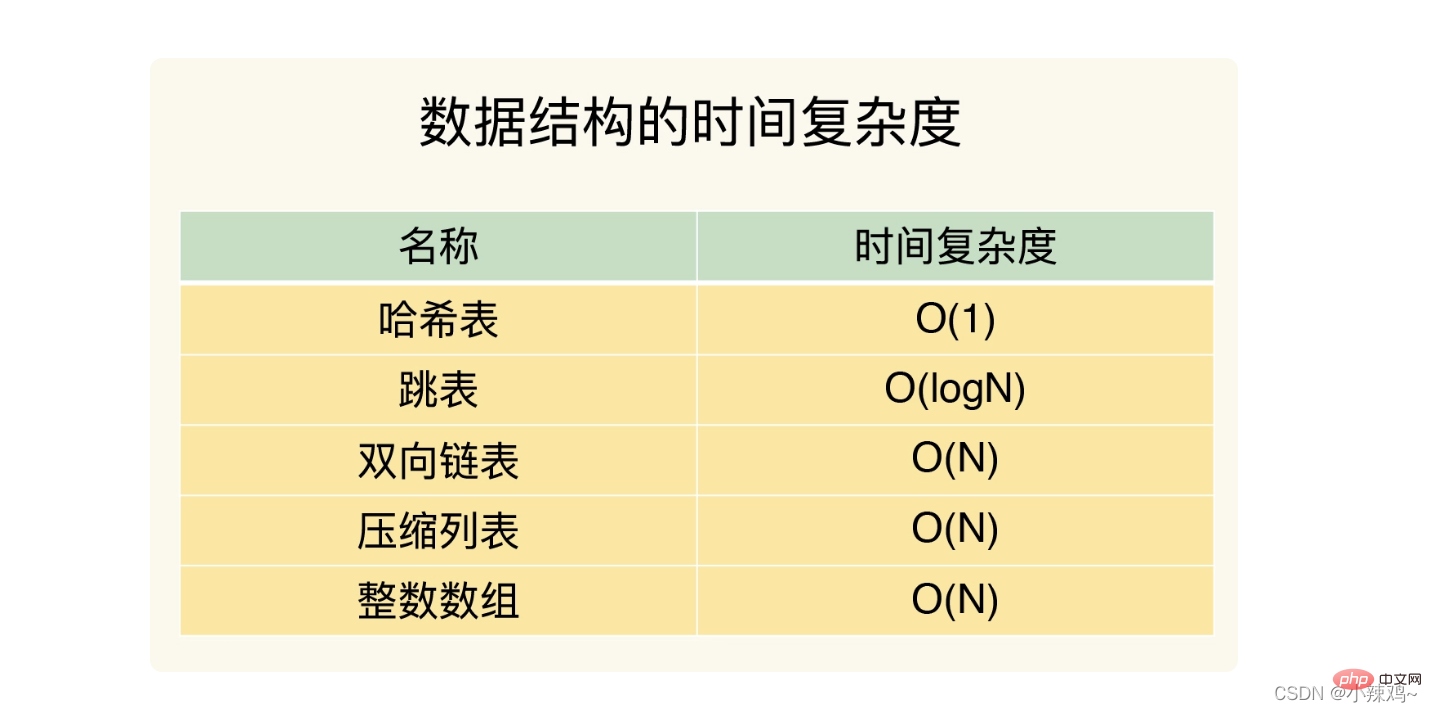
String型別
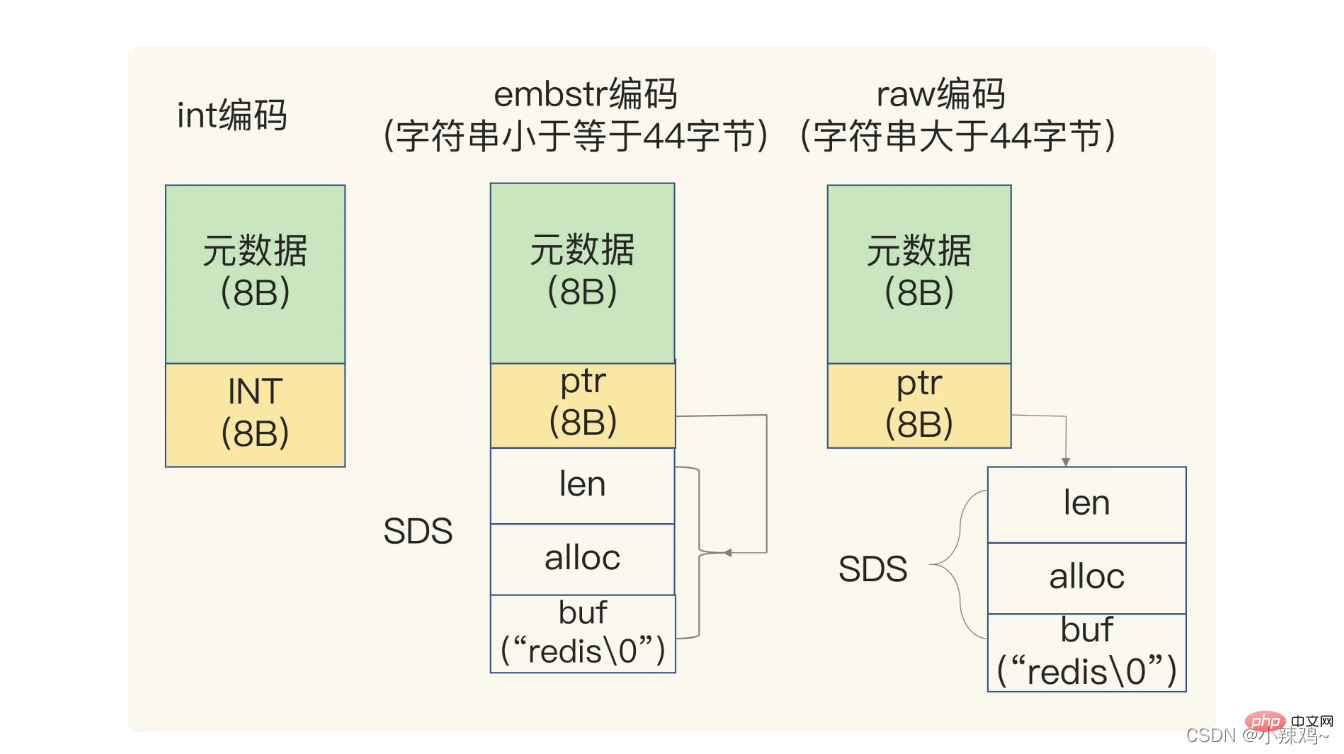
String型別並不適用於所有場景,它有一個明顯的短板就是它在儲存資料時所消耗的記憶體空間較多。因為String型別需要額外記憶體空間記錄資料長度、空間使用等資訊,這些資訊也叫做後設資料。
當儲存的資料包含字元的時候,string會用簡單動態字串SDS結構體來儲存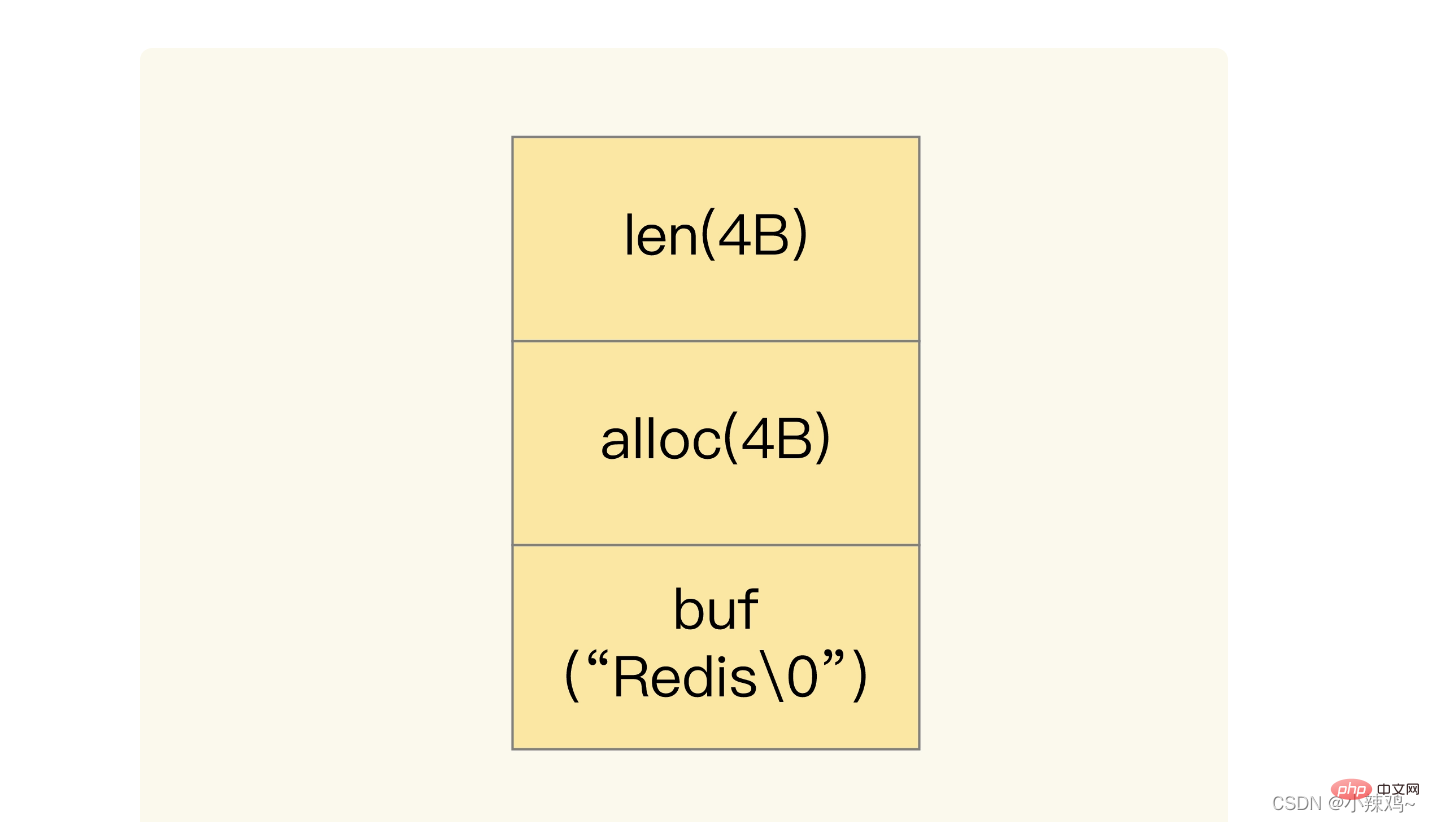
len是buf已用長度 alloc是buf實際分配長度
因為redis資料型別有很多,不同的資料型別有相同的後設資料要記錄,所以redis會用一個RedisObject結構體來統一記錄這些後設資料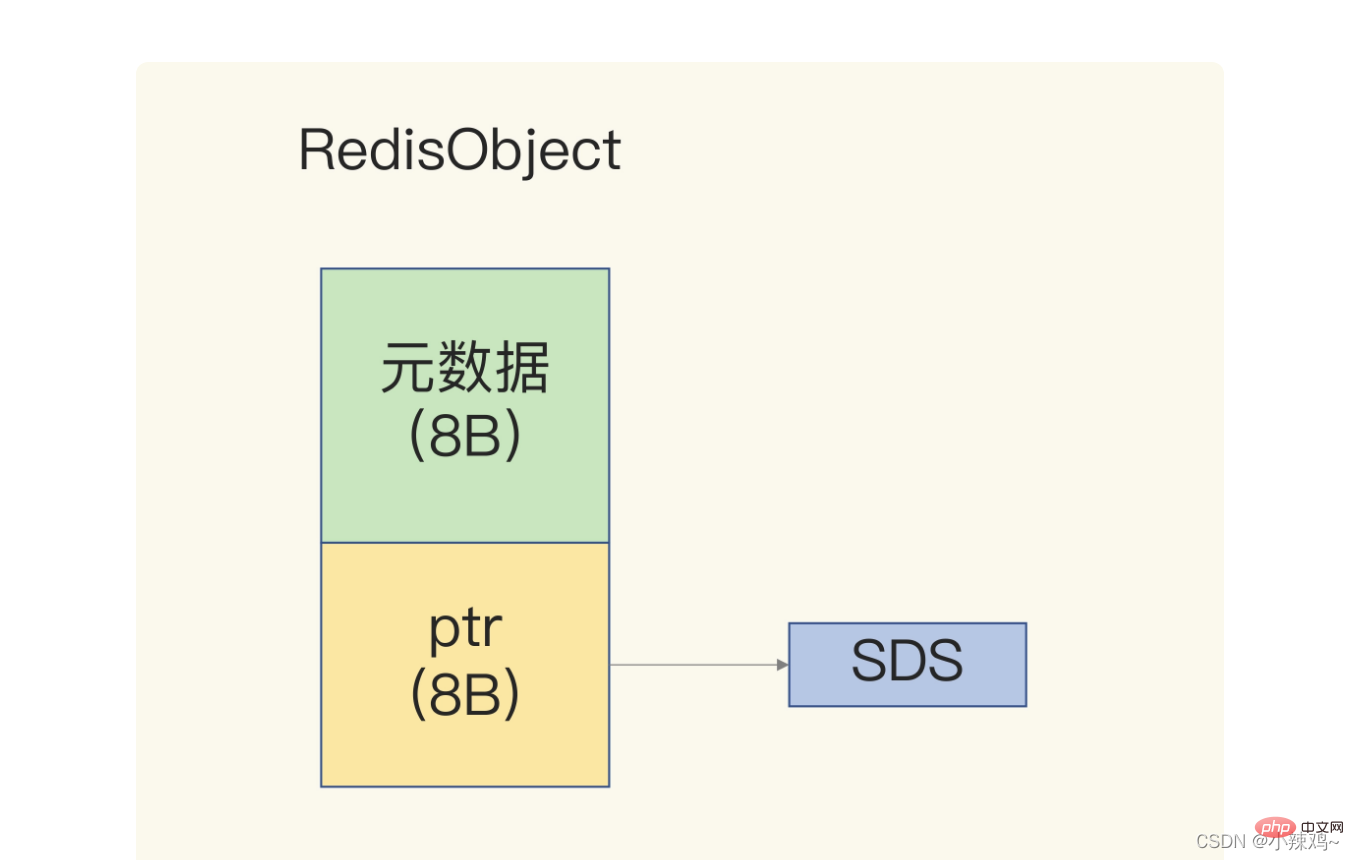
當儲存Long型別的時候,RedisObject的指標就直接賦值為整數資料了,這樣就不用額外的指標再指向整數了,節省了指標的空間開銷。
如果儲存的字串小於44位元組,sds和後設資料會被分配到一塊連續的記憶體區域,被稱為embstr編碼
如果儲存的字串大於44位元組,SDS和後設資料會分開存放,被稱為raw編碼
另外redis會使用一個全域性hash表儲存所有鍵值對,hash表的每一項都是一個dictEntry的結構體,用來指向一個鍵值對,可以看到key+value+next會使用24位元組,但是實際佔用32位元組,這是因為jemalloc 在分配記憶體時,會根據我們申請的位元組數 N,找一個比 N 大,但是最接近 N 的 2 的冪次數作為分配的空間,這樣可以減少頻繁分配的次數。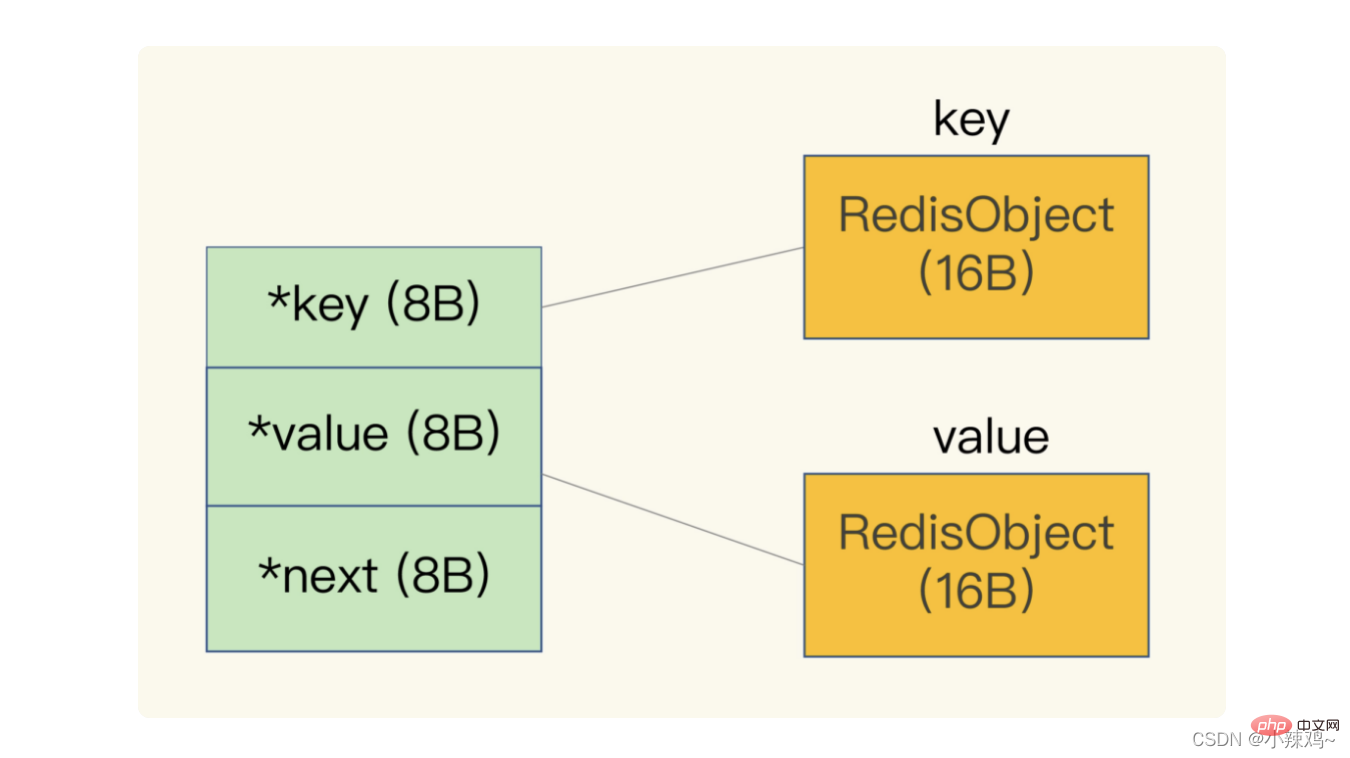
用什麼資料結構可以節省記憶體呢?
壓縮列表:zlbytes代表列表長度,zltail代表列表尾偏移量,zllen代表列表中的entry個數,zlend代表列表結束,perv_len代表前一個entry長度,encoding代表編碼方式,len代表自身長度,key是實際儲存的資料。redis基於壓縮列表實現了list、hash和Sorted Set
如何用集合型別儲存單值的鍵值對?
在儲存單值的鍵值對的時候,可以採用Hash的二級編碼,就是把單值的數值拆分成兩部分,前一部分作為Hash的key,後一部分作為Hash的value
以圖片 ID 1101000060 和圖片儲存物件 ID 3302000080 為例,我們可以把圖片 ID 的前 7 位(1101000)作為 Hash 型別的鍵,把圖片 ID 的最後 3 位(060)和圖片儲存物件 ID 分別作為 Hash 型別值中的 key 和 value。127.0.0.1:6379> info memory# Memoryused_memory:1039120127.0.0.1:6379> hset 1101000 060 3302000080(integer) 1127.0.0.1:6379> info memory# Memoryused_memory:1039136
Hash型別有兩種底層實現結構:1.壓縮列表 2.Hash表
hash列表存在兩個閥值,一旦超過這兩個閥值就會從壓縮列表轉換為Hash表
hash-max-ziplist-entries表示用壓縮列表儲存時雜湊列表集合中最大元素個數
hash-max-ziplist-value表示用壓縮列表儲存時雜湊集合單個元素的最大長度
集合統計模式
1.聚合統計
2.排序統計
3.二值狀態統計
4.基數統計
redis的三種擴充套件資料型別
1.Bitmap:
2.HyperLogLog
3.GEO:
面向LBS應用的GEO資料型別
GEO的底層結構是根據Sorted Set來實現的,Sorted Set可以根據元素的權重排序,支援範圍查詢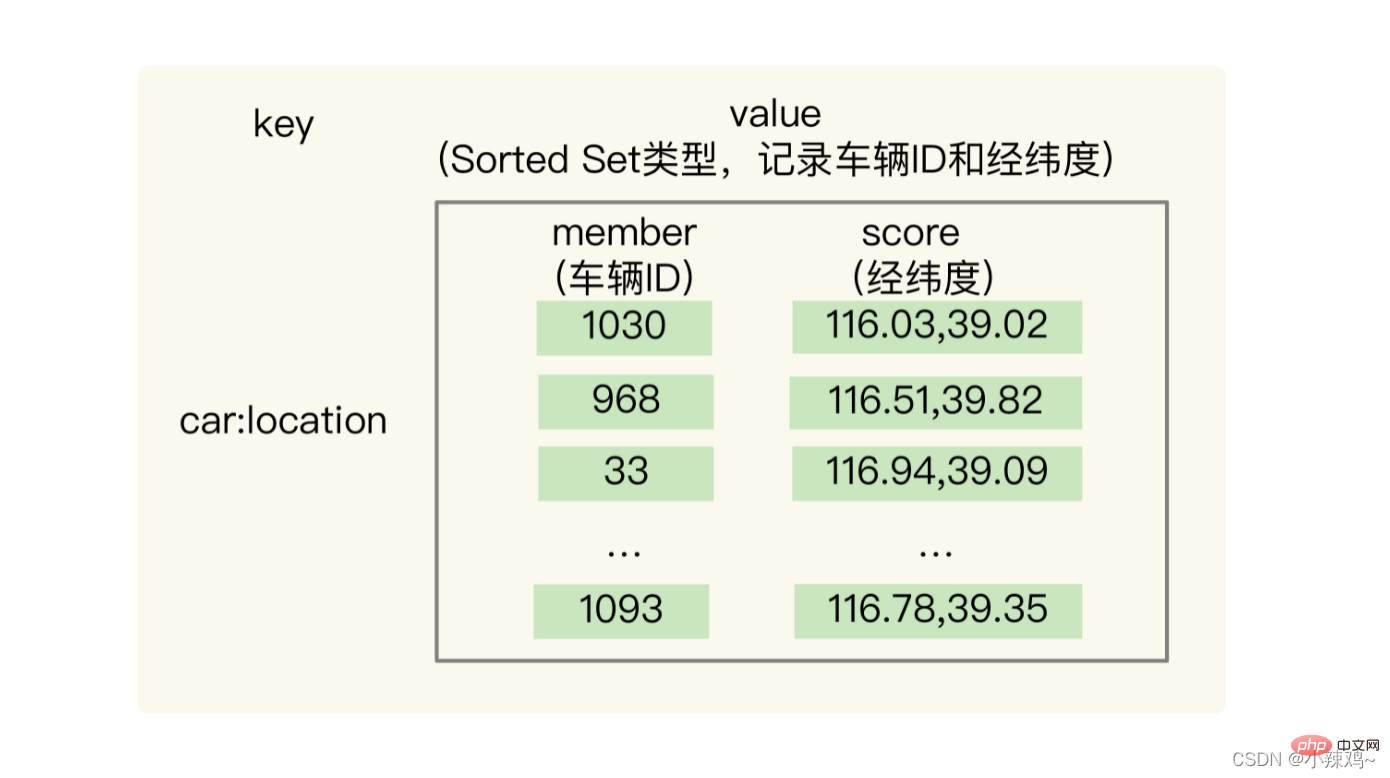
sorted Set的權重分數是一個浮點數(float型別),而經緯度是兩個數,需要用GeoHash 編碼
GeoHash編碼是通過「二分割區間,區間編碼」的方式進行的。
先把經度和緯度換算成編碼的格式,然後再進行交叉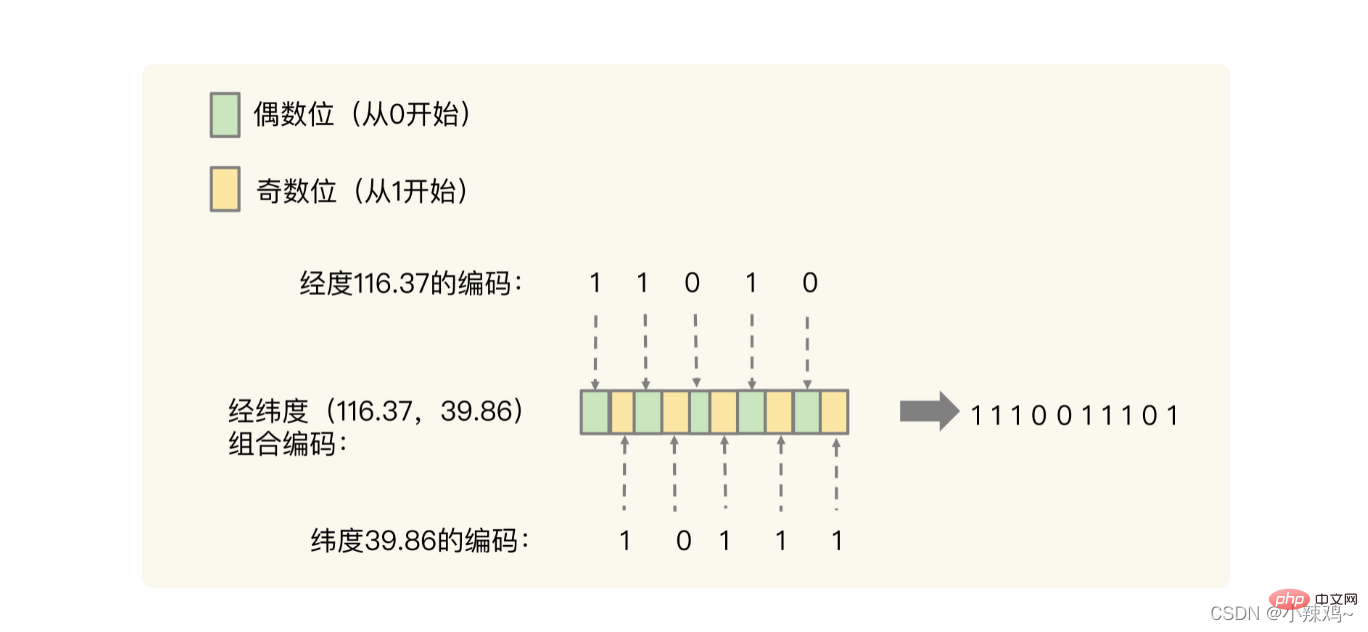
實際上交叉的目的是下圖所示的概念,交叉後實際上就可以定位到二維空間上的一個方格中,我們使用 Sorted Set 範圍查詢得到的相近編碼值,在實際的地理空間上,也是相鄰的方格,例如1110011101和1111011101是空間位置相鄰的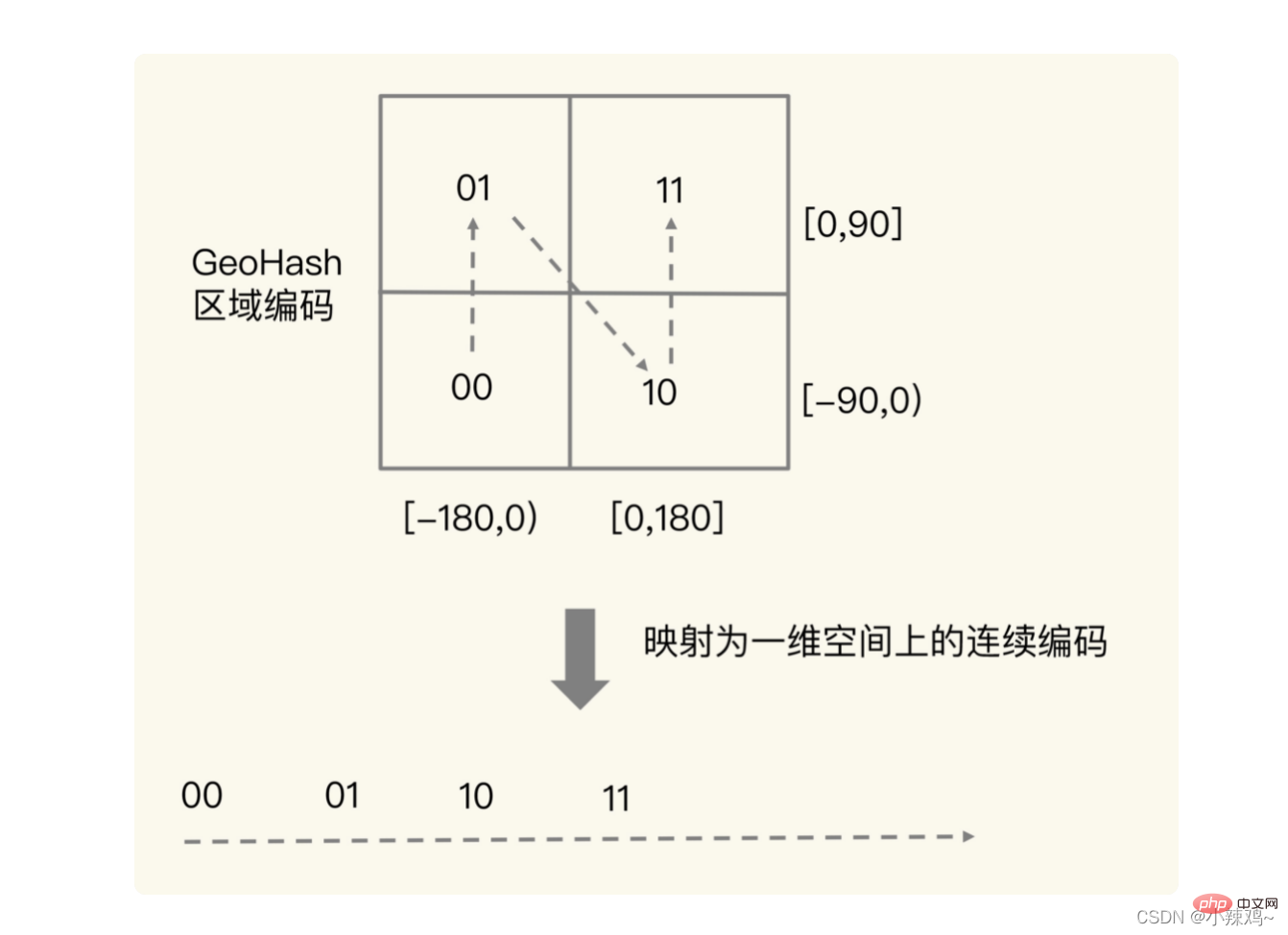
但是會存在編碼相鄰,但是方格實際不相鄰的情況。所以為了避免這種情況發生我們可以同時查詢給定經緯度周圍4個或者8個方格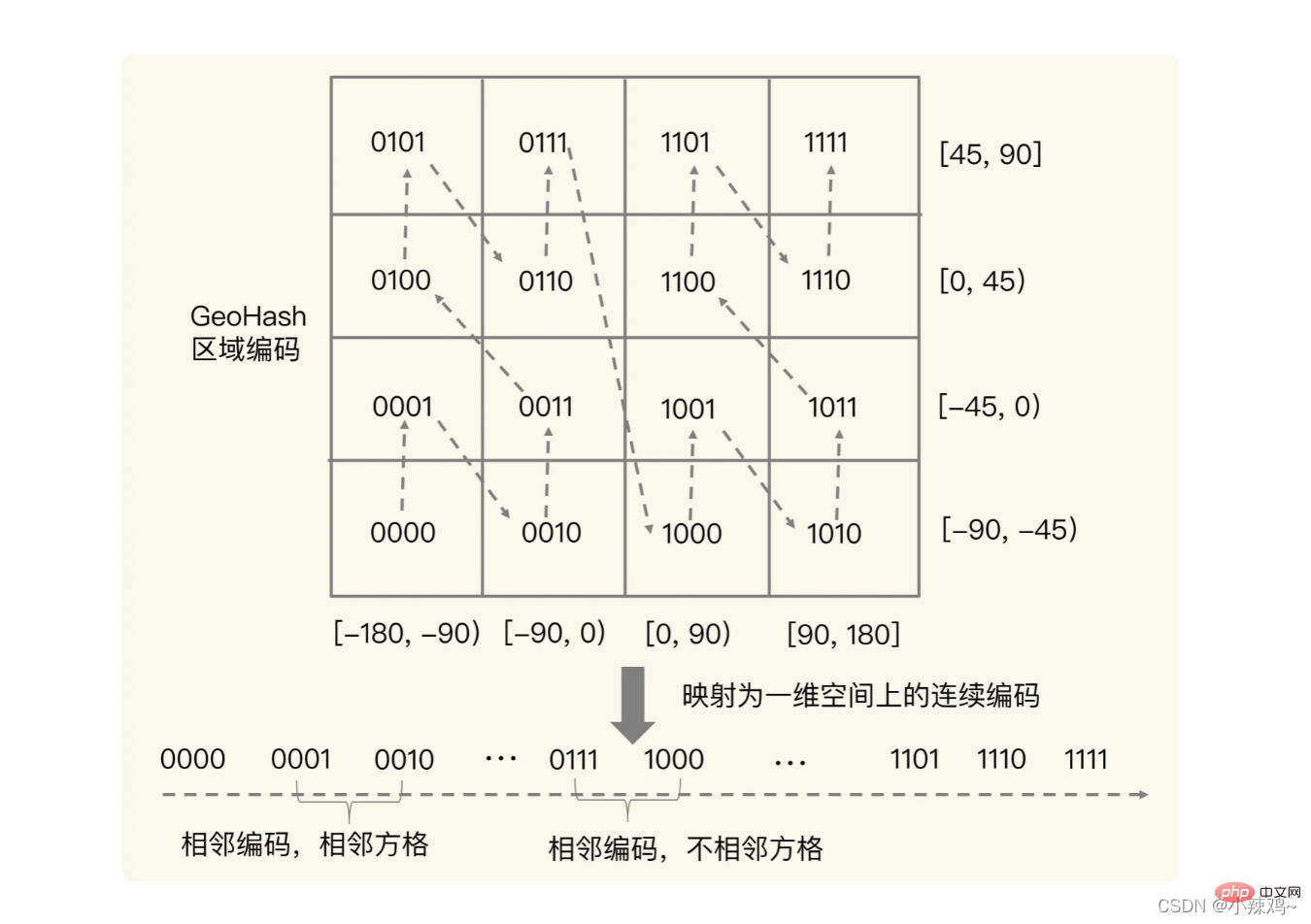
如何操作GEO型別?
在使用GEO型別時,我們經常使用到的兩個命令分別時GEOADD和GEORADIUS
GEOADD:用於把一組經緯度資訊和相對應的一個ID記錄到GEO型別集合中。
使用方法:假設車輛ID是33,經緯度位置是(116.034579,39.030452),我們可以用一個 GEO 集合儲存所有車輛的經緯度,集合 key 是 cars:locations。只需要執行以下命令就可以把ID號為33的車輛的當前經緯度位置存入到GEO中。
GEOADD cars:locations 116.034579 39.030452 33
GEORADIUS:根據輸入經緯度的位置,查詢以這個經緯度為中心一定範圍內的其他元素
如何自定義資料型別?
redis的基本物件結構包含type、encoding、lru和refcount、*ptr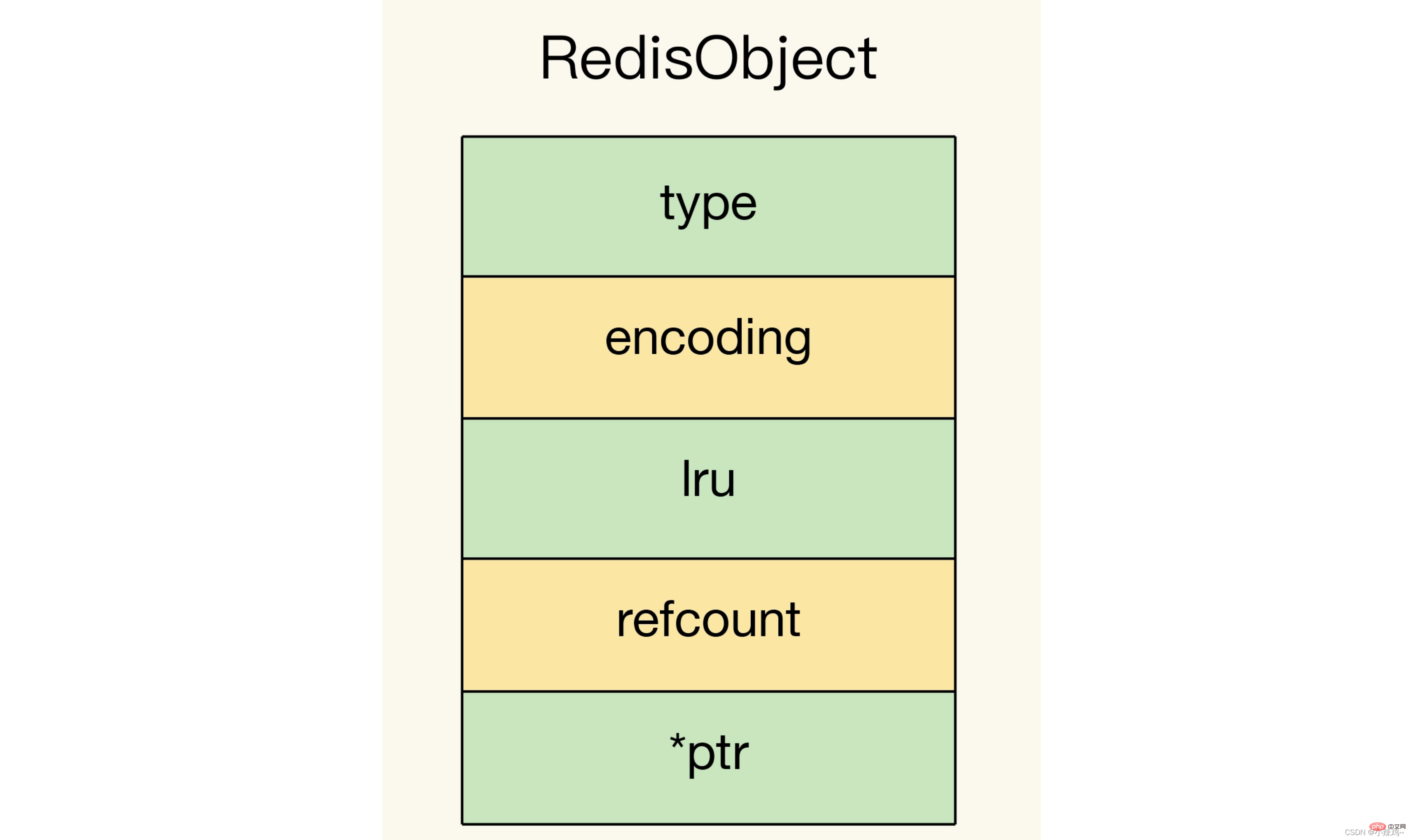
開發一個名字叫NewTypeObject的資料結構,具體有以下四個步驟
如何在redis中儲存時間序列資料?
1.基於Hash和Sorted Set儲存:為什麼要基於兩種資料結構進行查詢呢?
Hash型別可以實現單鍵的快速查詢,這就滿足了時間序列單鍵查詢需求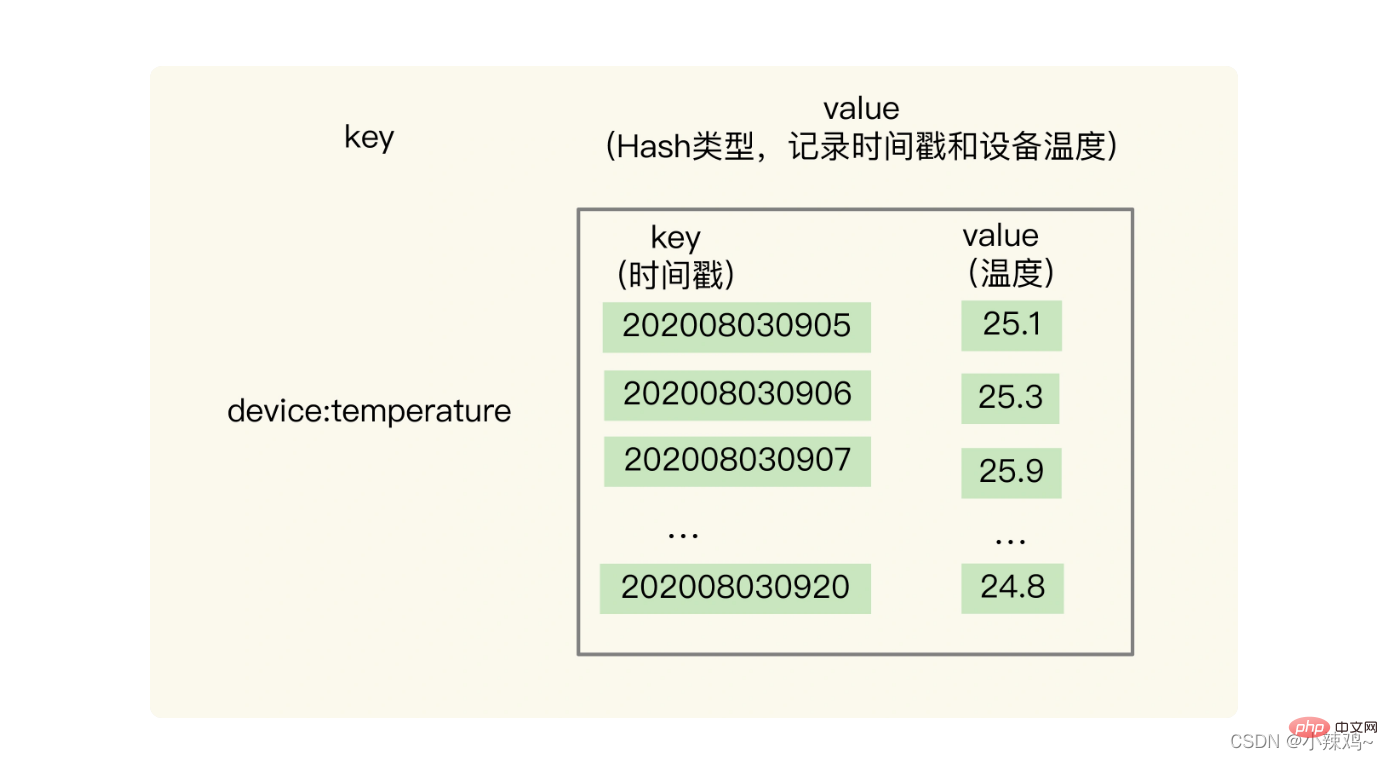
但是hash型別有一個短板就是不支援範圍查詢,為了支援時間戳範圍查詢我們需要通過Sorted Set,因為它根據元素的權重分數來排序的,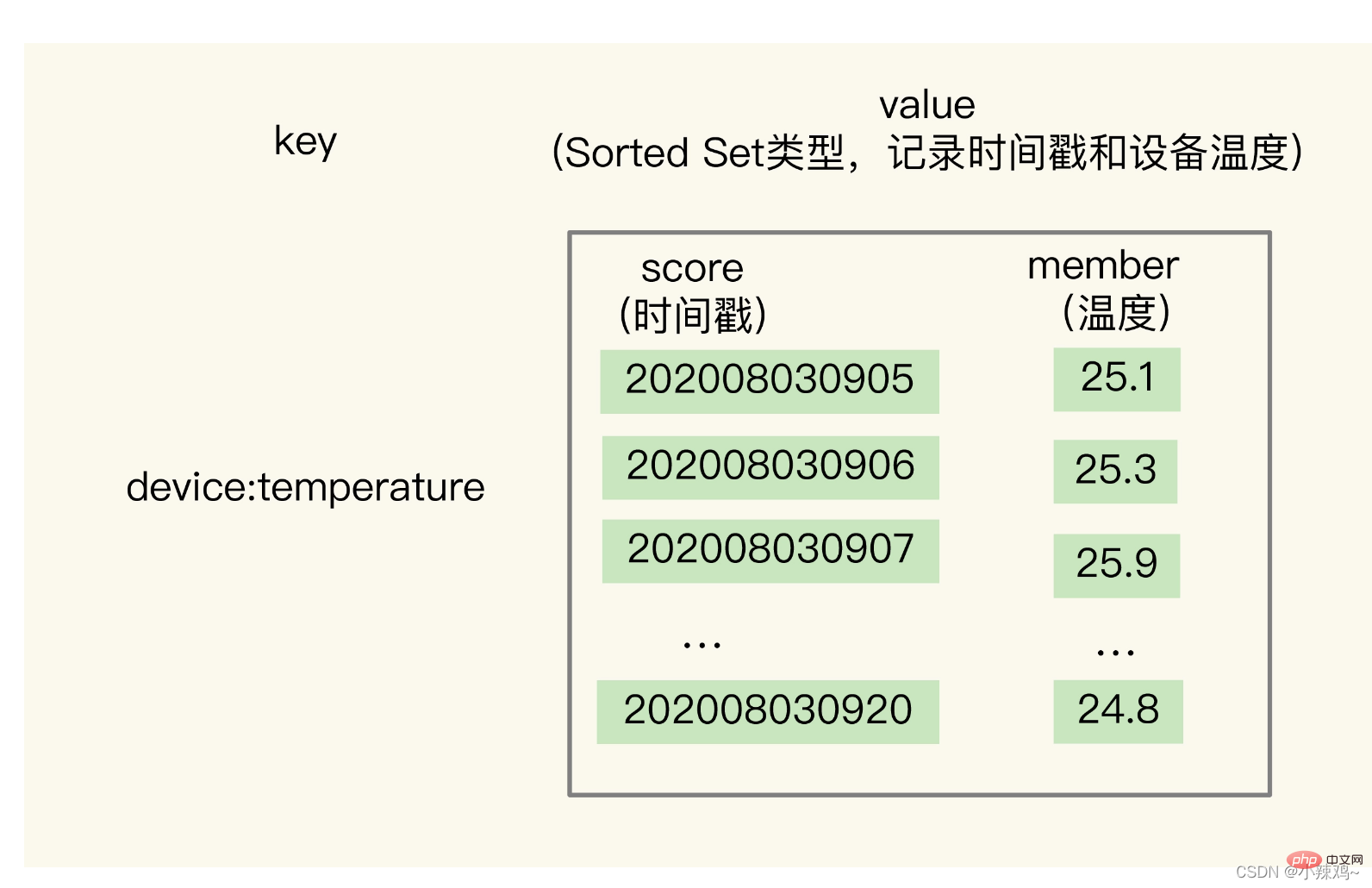
那麼我們怎麼保證這兩個操作的原子性呢?
需要通過MULTI和EXEC兩個命令:
MULTI表示開始,收到這個命令redis就會將命令放入到佇列中
EXEC表示結束,收到這個命令就會開始執行佇列中的命令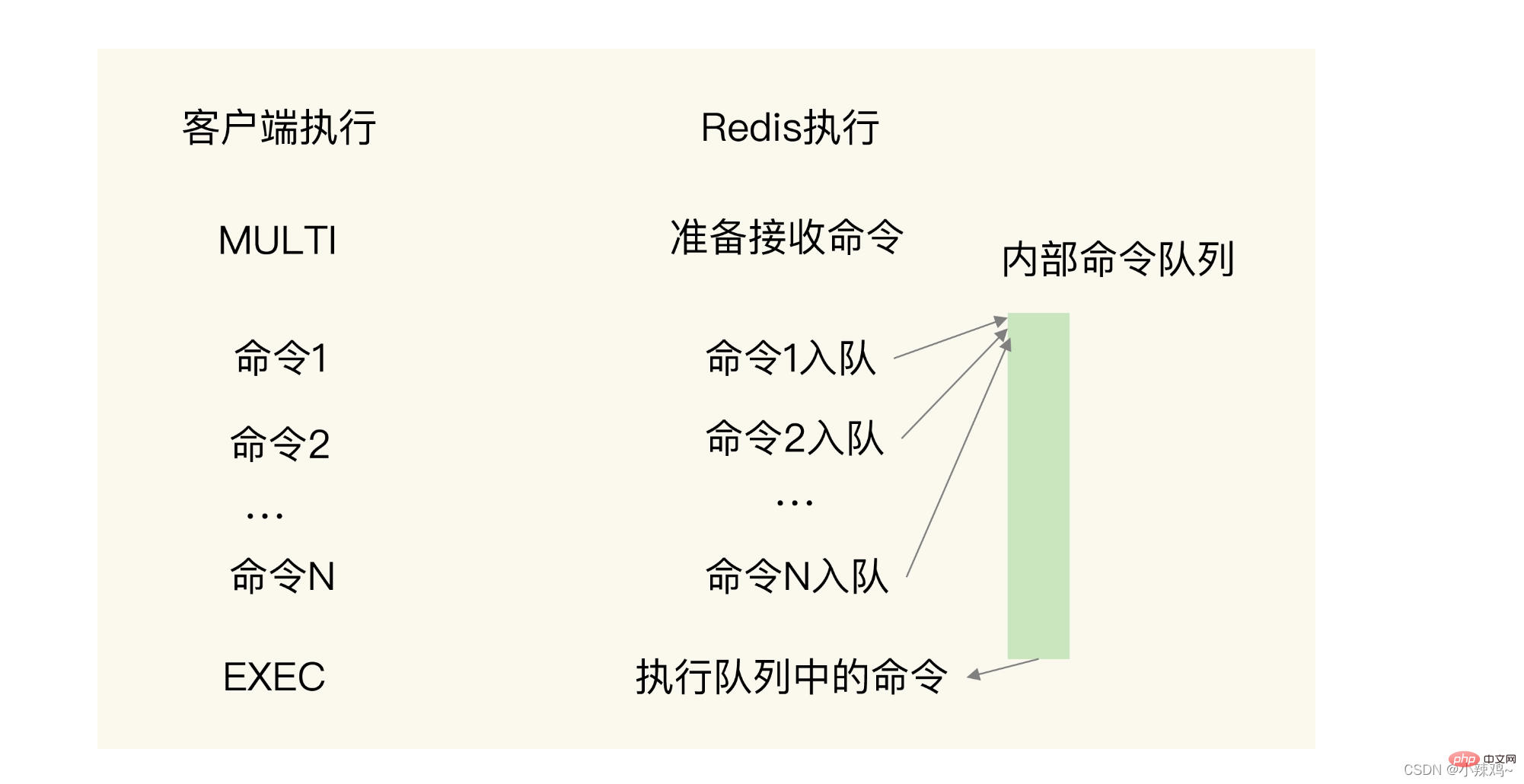
但是如果採用hash和Sorted Set則只支援範圍查詢而不支援聚合計算。如果在使用者端做聚合計算,會導致大量的網路傳輸。所以可以在redis上通過RedisTimeSeries進行聚合計算。
推薦學習:
以上就是redis資料結構知識圖文詳解的詳細內容,更多請關注TW511.COM其它相關文章!