一起來分析MySQL的update語句是怎樣執行的

推薦學習:
前期準備
首先建立一張表,然後插入三條資料:
CREATE TABLE T( ID int(11) NOT NULL AUTO_INCREMENT, c int(11) NOT NULL, PRIMARY KEY (ID)) ENGINE=InnoDB DEFAULT CHARSET=utf8 COMMENT='測試表';INSERT INTO T(c) VALUES (1), (2), (3);
讓後執行更新操作:
update T set c=c+1 where ID=2;
在說更新操作前,大家先來看一下sql語句在MySQL中的執行流程~
SQL語句的執行過程
![[外鏈圖片轉存失敗,源站可能有防盜鏈機制,建議將圖片儲存下來直接上傳(img-oRuDIrVS-1646917447700)(/upload/2021/10/image-3b172ec1cf324d3ea025e518547a668a.png)]](https://s3.ap-northeast-1.wasabisys.com/img.tw511.com/202203/de3a399263525d833da4c85452796cff-0hdd4bx54haj.png)
如圖所示:MySQL資料庫主要分為兩個層級:服務層和儲存引擎層服務層:server層包括聯結器、查詢快取、分析器、優化器、執行器,包括大多數MySQL中的核心功能所有跨儲存引擎的功能也在這一層實現,包括 儲存過程、觸發器、檢視等。 儲存引擎層:儲存引擎層包括MySQL常見的儲存引擎,包括MyISAM、InnoDB和Memory等,最常用的是InnoDB,也是現在MySQL的預設儲存引擎。
server層中的元件介紹
聯結器: 需要MySQL使用者端登入,需要一個 聯結器 來連線使用者和MySQL資料庫,「mysql -u 使用者名稱 -p 密碼」 進行MySQL登入,在完成 TCP握手 後,聯結器會根據輸入的使用者名稱和密碼驗證登入身份。
查詢快取: MySQL在得到一個執行請求後,會首先去 查詢快取 中查詢,是否執行過這條SQL語句,之前執行過得語句以及結果會以 key-value對的形式,放在記憶體中。key是查詢語句,value是查詢的結果。如果通過key能夠查詢到這條SQL語句,直接返回SQL的執行結果。若不存在快取中,就會繼續後面的執行階段。執行完成後,執行結果就會被放入查詢快取中。優點是效率高。但是查詢快取不建議使用, 因為在MySQL中對某張表進行了更新操作,那麼所有的查詢快取就會失效,對於更新頻繁的資料庫來說,查詢快取的命中率很低。需要注意:在MySQL8.0版本,查詢快取功能就刪除了,不存在查詢快取的功能了
分析器: 分為詞法分析和語法分析
- 詞法分析: 首先,MySQL會根據SQL語句進行解析,分析器會先做 詞法分析,你寫的SQL就是由多個字串和空格組成的一條SQL語句,MySQL需要識別出裡面的字串是什麼,代表什麼。
- 語法分析: 然後進行 語法分析, 根據詞法分析的結果,語法分析器會根據語法規則,判斷輸入的這個SQL語句是否滿足MySQL語法。如果SQL語句不正確,就提示:You have an error in your SQL suntax
優化器: 經過分析器分析後,SQL就合法了,但在執行之前,還需要進行優化器的處理,優化器會判斷使用了哪種索引,使用哪種連線,優化器的作用 就是確定效率最高的執行方案。
執行器: 在執行階段,MySQL首先會判斷有沒有執行語句的許可權,若無許可權,返回沒有許可權的錯誤;若有許可權,就開啟表繼續執行。開啟表時,執行器會根據標的引擎定義,去使用該引擎提供的介面,對於有索引的表,執行的邏輯類似。
瞭解完SQL語句的執行流程我們接下來詳細分析一下上面update T set c=c+1 where ID=2;是如何執行的。
Update語句分析
update T set c=c+1 where ID=2;
在執行update更新操作的時候,跟這個表有關的查詢快取會失效,所以這條語句就會把表 T 上所有快取結果都清空。接下來,分析器會經過語法分析和詞法分析,知道了這是一條更新語句後,優化器決定要使用哪一個索引,然後執行器負責具體的執行,先找到這一行,然後做更新。
按照我們平常的思路,就是 找出這條記錄,把它的值改好,儲存就OK了 。但我們追究一下細節,由於涉及到修改資料,所以涉及到紀錄檔了。更新操作涉及到兩個重要的紀錄檔模組。redo log(重做紀錄檔),bin log(歸檔紀錄檔)。MySQL中的這兩個紀錄檔也是必學的。
redo log(重做紀錄檔)
- 在 MySQL 裡,如果每一次的更新操作都需要寫進磁碟,然後磁碟也要找到對應的那條記錄,然後再更新,整個過程 IO 成本、查詢成本都很高。
MySQL裡使用WAL(預寫式紀錄檔)技術,WAL 的全稱是Write-Ahead Logging,它的關鍵點就是 先寫紀錄檔,再寫磁碟。 - 具體來說,當有一條記錄需要更新的時候,InnoDB 引擎就會先把記錄寫到 redo log裡面,並更新記憶體,這個時候更新就算完成了。同時,InnoDB 引擎會在適當的時候,將這個操作記錄更新到磁碟裡面,而這個更新往往是在系統比較空閒的時候做。
- InnoDB 的 redo log 是固定大小的,比如可以設定為一組 4 個檔案,每個檔案的大小是 1GB,那麼總共就可以記錄 4GB 的操作。從頭開始寫,寫到末尾就又回到開頭回圈寫。
聽完上面對redo log紀錄檔的介紹後,小夥伴們可能會問:redo log紀錄檔儲存在哪?, 資料庫資訊儲存在磁碟上,redo log紀錄檔也儲存在磁碟上,為什麼要先寫到redo log中再寫到資料庫中呢?,redo log紀錄檔如果存滿資料了怎麼辦?等等。接下來就解答一下這些疑問。
redo log儲存在哪裡?
InnoDB引擎先把記錄寫到redo log 中,redo log 在哪,它也是在磁碟上,這也是一個寫磁碟的過程, 但是與更新過程不一樣的是,更新過程是在磁碟上隨機IO,費時。 而寫redo log 是在磁碟上順序IO。效率要高。
redo log 空間是固定,那它會不會用完呢?
首先不用擔心 redo log 會用完空間,因為它是迴圈利用的。例如 redo log 紀錄檔設定為一組4個檔案,每個檔案分別為1G。它寫的流程如下圖: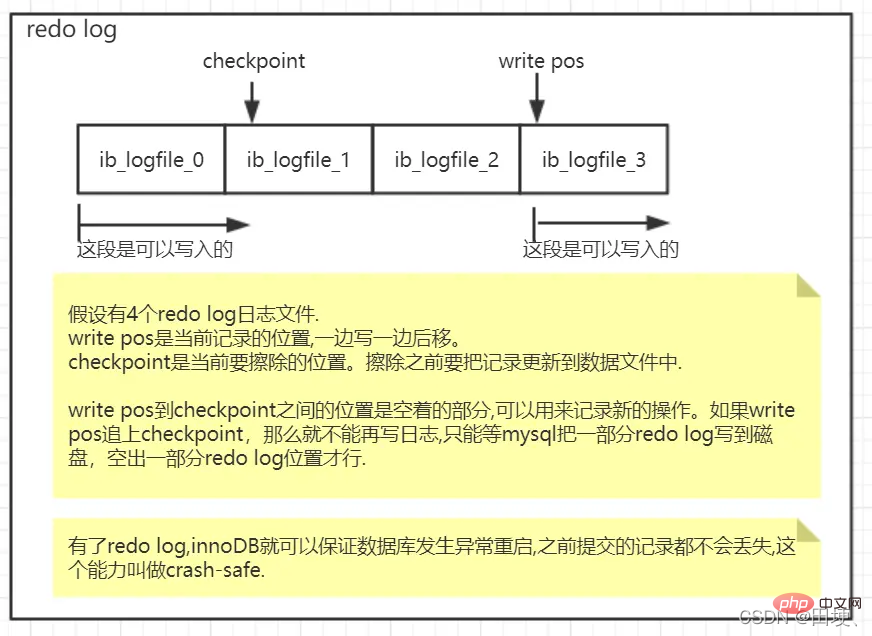
簡單總結一下: redo log紀錄檔是Innodb儲存引擎特有的機制,可以用來應對異常恢復,Crash-safe,redo可以保證mysql異常重新啟動時,將未提交的事務回滾,已提交的事務安全落庫。
crash-safe: 有了 redo log,InnoDB 就可以保證即使資料庫發生異常重新啟動,之前提交的記錄都不會丟失,這個能力稱為crash-safe。
binlog(歸檔紀錄檔)
redo log是innoDB 引擎特有的紀錄檔。而binlog是mysql server層的紀錄檔。
其實bin log紀錄檔出現的時間比redo log早,因為最開始MySQL是沒有InnoDB儲存引擎的,5.5之前是MyISAM。但是 MyISAM 沒有 crash-safe 的能力,binlog 紀錄檔只能用於歸檔。而 InnoDB 是另一個公司以外掛形式引入 MySQL 的,既然只依靠 binlog 是沒有 crash-safe 能力的,所以 InnoDB 使用另外一套紀錄檔系統——也就是 redo log 來實現 crash-safe 能力。
redo log和bin log的總結
- redo log是為了保證innoDB引擎的crash-safe能力,也就是說在mysql異常宕機重新啟動的時候,之前提交的事務可以保證不丟失;(因為成功提交的事務肯定是寫入了redo log,可以從redo log恢復)
- bin log是歸檔紀錄檔,將每個更新操作都追加到紀錄檔中。這樣當需要將紀錄檔恢復到某個時間點的時候,就可以根據全量備份+bin log重放實現。 如果沒有開啟binlog,那麼資料只能恢復到全量備份的時間點,而不能恢復到任意時間點。如果連全量備份也沒做,mysql宕機,磁碟也壞了,那就很尷尬了。。
redo log和bin log的區別:
- redo log 是 InnoDB 引擎特有的;bin log 是 MySQL 的 Server 層實現的,所有引擎都可以使用。
- redo log 是物理紀錄檔,記錄的是「在某個資料頁上做了什麼修改」;bin log 是邏輯紀錄檔,記錄的是這個語句的原始邏輯,比如「給 ID=2 這一行的 c 欄位加 1 」。
- redo log 是迴圈寫的,空間固定會用完;binlog 是可以追加寫入的。「追加寫」是指 binlog 檔案寫到一定大小後會切換到下一個,並不會覆蓋以前的紀錄檔。
InnoDB引擎部分在執行這個簡單的update語句的時候的內部流程
update T set c=c+1 where ID=2;
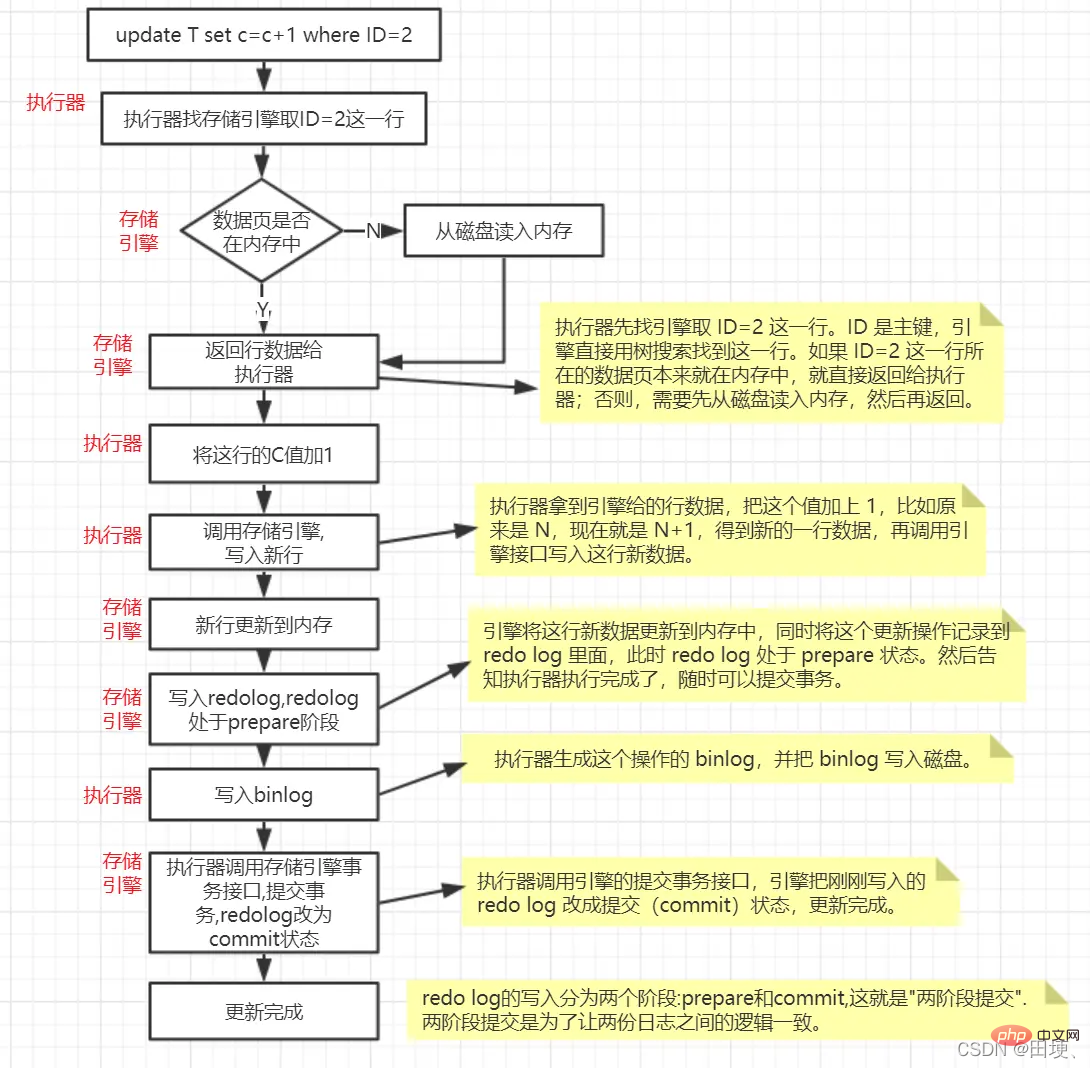
手動用begin開啟事務,然後執行update語句,再然後執行commit語句,那上面的update更新流程之前 哪些是update語句執行之後做的,哪些是commit語句執行之後做的?
事實上,redo log在記憶體中有一個
redo log buffer,binlog 也有一個binlog cache.所以在手動開啟的事務中,你執行sql語句,其實是寫到redo log buffer和binlog cache中去的(肯定不可能是直接寫磁碟紀錄檔,一個是效能差一個是回滾的時候不可能去回滾磁碟紀錄檔吧),然後當你執行commit的時候,首先要將redo log的提交狀態遊prepare改為commit狀態,然後就要把binlog cache重新整理到binlog紀錄檔(可能也只是flush到作業系統的page cache,這個就看你的mysql設定),redo log buffer重新整理到redo log 紀錄檔(重新整理時機也是可以設定的)。 如果你回滾的話,就只用把binlog cache和redo log buffer中的資料清除就行了。
在update過程中,mysql突然宕機,會發生什麼情況?
如果redolog寫入了,處於prepare狀態,binlog還沒寫入,那麼宕機重新啟動後,redolog中的這個事務就直接回滾了。
如果redolog寫入了,binlog也寫入了,但redolog還沒有更新為commit狀態,那麼宕機重新啟動以後,mysql會去檢查對應事務在binlog中是否完整。如果是,就提交事務;如果不是,就回滾事務。 (redolog處於prepare狀態,binlog完整啟動時就提交事務,為啥要這麼設計? 主要是因為binlog寫入了,那麼就會被從庫或者用這個binlog恢復出來的庫使用,為了資料一致性就採用了這個策略)
redo log和binlog是通過xid這個欄位關聯起來的。
推薦學習:
以上就是一起來分析MySQL的update語句是怎樣執行的的詳細內容,更多請關注TW511.COM其它相關文章!