深入瞭解MySQL索引結構

推薦學習:
資料庫儲存單位
首先我們要知道,由於為了實現持久化,只能將索引儲存在硬碟上,通過索引來進行查詢的時候就會產生硬碟的 I/O 操作,因此,設計索引時需要儘可能的減少查詢次數,從而減少 I/O 耗時。
此外還需要知道一個很重要的原理:資料庫管理儲存空間的基本單位是頁(Page),一個頁中儲存多條行記錄(Row)。
計算機系統對磁碟 I/O 會做預讀優化,當一次I/O時,除了當前磁碟地址的資料以外,還會把相鄰的資料也讀取到記憶體緩衝池中,每一次 I/O 讀取的資料成為一頁,InnoDB 預設的頁大小是 16KB。
連續的 64 個頁組成一個區(Extent),一個或多個區組成一個段(Segment),一個或多個段組成表空間(Tablespace)。InnoDB 有兩種表空間型別,共用表空間表示多張表共用一個表空間,獨立表空間表示每張表的資料和索引全部存在獨立的表空間中。
資料頁結構如下(圖源:極客時間《MySQL 必知必會》):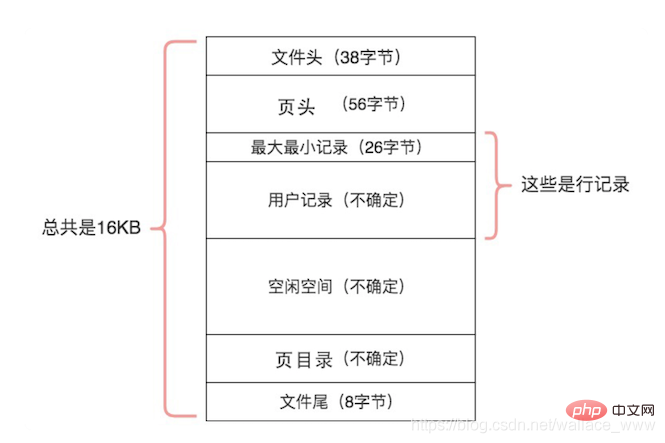
資料頁的 7 個結構內容可以大致分為以下三類:
- 檔案通用部分,用於校驗頁傳輸完整
- 檔案頭(File Header): 表述頁資訊,檔案頭中使用 FIL_PAGE_PREV 和 FIL_PAGE_NEXT 構成一個雙向連結串列,分別指向前後的資料頁。
- 頁頭(File Header):記錄頁的狀態資訊
- 檔案尾(File Trailer): 校驗頁是否完整
- 記錄部分,用於儲存資料記錄
- 最大最小記錄(Infimum/Supremum):虛擬的行記錄,表示資料頁的最大記錄和最小記錄。
- 使用者記錄(User Record)和空閒空間(Free Space): 用於儲存資料行記錄內容
- 索引部分,用於提高記錄的檢索效率
- 頁目錄(Page Directory):儲存使用者記錄的相對位置
詳情可參考淘寶的資料庫核心月報
索引資料結構
很自然的,我們會想到查詢演演算法中涉及到的一些常用資料結構,比如二叉查詢樹,二叉平衡樹等等,實際上,Innodb 的索引是用 B+ 樹 來實現的,下面我們來看看為何會選擇這種索引結構。
二元樹的侷限性
先來簡單回顧一下二元搜尋樹(Binary Search Tree)的定義,二元搜尋樹中,如果要查詢的 key 大於根節點,則在右子樹中搜尋,如果 key 小於根節點,則在左子樹中搜尋,直到找到 key 為止,時間複雜度為 O(logn)。比如數列 [4,2,6,1,3,5,7],會生成如下二元搜尋樹: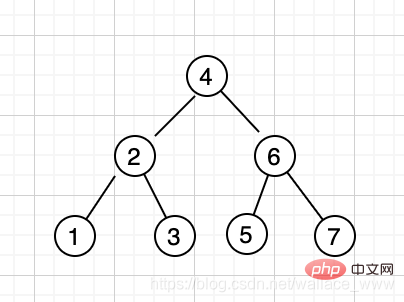
但是在某些特殊情況下,二元樹的深度會非常大,比如 [1,2,3,4,5,6,7],則會生成如下的樹: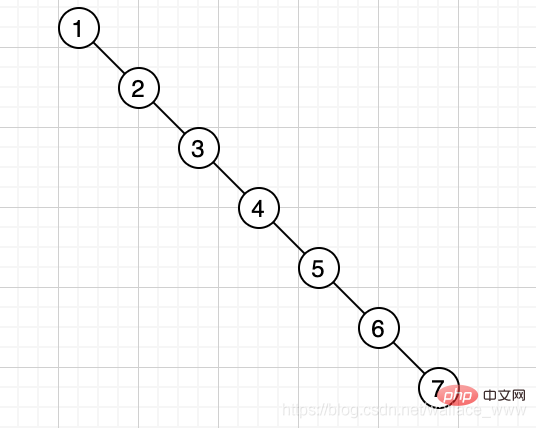
在下面這種情況中,最壞的情況下需要查 7 次才能夠查到想要的結果,查詢時間變成了 O(n)。
為了優化這種情況,就有了平衡二元搜尋樹(AVL 樹),AVL 樹是指左右子樹的高度相差不超過 1 的樹,搜尋時間複雜度為 O(logn),這已經是比較理想的搜尋樹了,但是在動輒幾千萬行記錄的資料庫中,樹的深度還是會很高,依然不是最理想的結構。
B 樹
那麼,如果從二元樹擴充套件到 N 叉樹呢,很容易想象到,N 叉樹可以大大的減少樹的深度,實際上,4 層樹結構就已經可以支撐幾十 T 的資料了。
B 樹(Balance Tree)就是這樣的一種 N 叉樹, B 樹也稱為 B- 樹,滿足如下定義:
設 k 為 B 樹的度 (degree, 表示每個節點最多能有多少個子節點),
- 每個磁碟塊中最多包含
k - 1個關鍵字 和k個子節點的指標 - 葉子節點中,只有關鍵字,沒有子節點指標
- 每個結點中的關鍵字都按照從小到大的順序排列,每個關鍵字的左子樹中的所有關鍵字都小於它,而右子樹中的所有關鍵字都大於它。
- 所有葉子節點位於同一層。
上面已經提到,每一次 I/O 會預讀一個磁碟塊的資料,大小為一頁,用一個磁碟塊的內容表示一次 I/O,B 樹的結構如下圖 (圖源:極客時間 SQL 必知必會):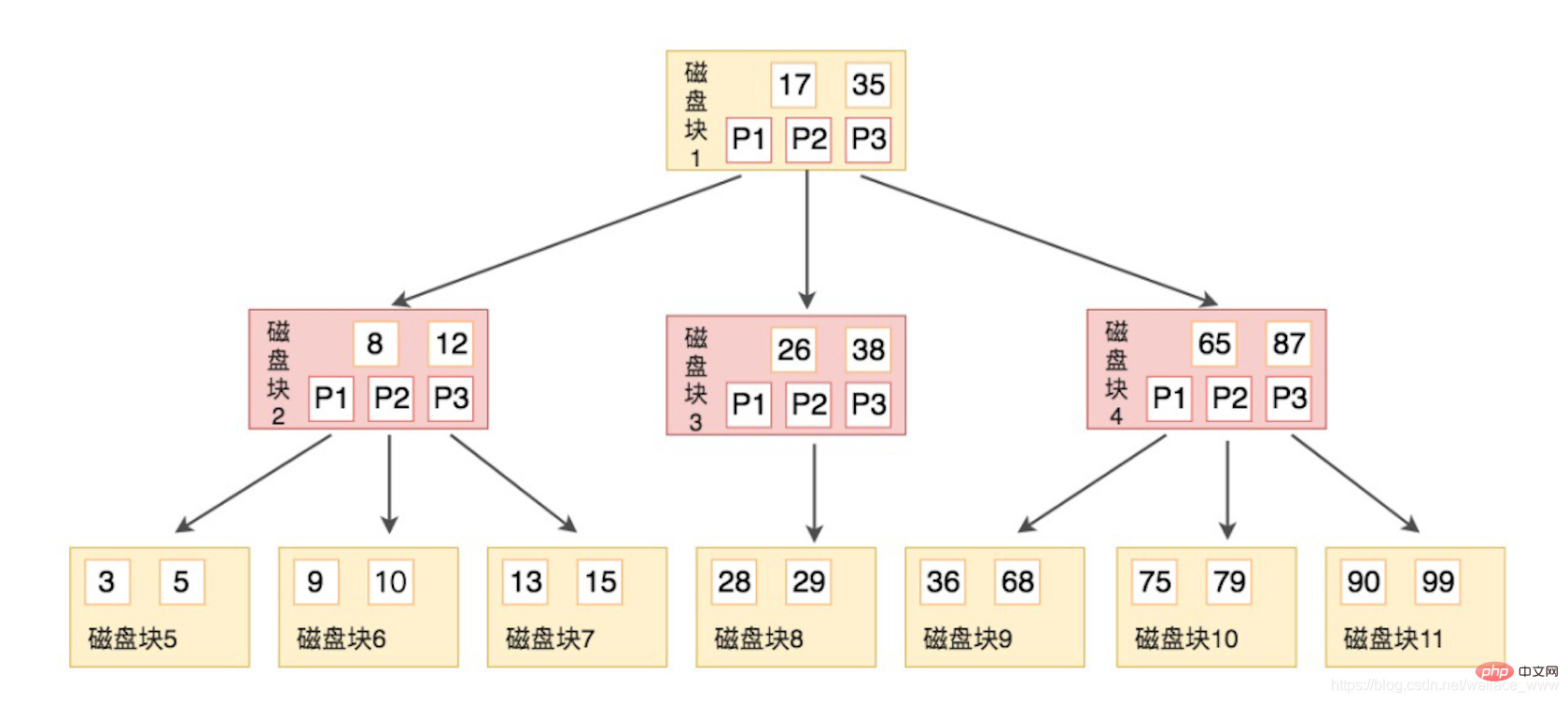
B 樹也是有序的,由於子節點指標一定比關鍵字多 1,所以正好可以用關鍵字劃分子節點的區段,如圖中的例子,每個節點有 2 個關鍵字,3 個子節點,如磁碟塊 2 ,第一個位元組點的關鍵字 3,5 小於自身的第一個子節點 8,第二個子節點的 9,10 在 8 和 12 之間,第三個子節點的值 13,15 大於自身的第二個子節點 12。
假設我們現在要查詢 9,步驟如下:
- 與根節點磁碟塊 1 (17,35) 比較,小於 17,繼續在指標 P1 中查詢,對應磁碟塊 2
- 與磁碟塊 2 (8,12) 比較,位於兩者之間,繼續在指標 P2 查詢,對應磁碟塊 6
- 與磁碟塊 6 (9, 10) 比較,找到 9
可以看到,雖然做了很多次比較的操作,但是由於進行了預讀,所以在磁碟塊內部的比較是在記憶體中進行的,不耗費磁碟 I/O,上述操作只需要進行 3 次 I/O 即可完成,已經是比較理想的結構了。
B+ 樹索引
B+ 樹在 B 樹的基礎上進行了進一步的改進,B+ 樹和 B 樹的區別有以下幾點:
- B+ 樹的構建方式是,對於父節點中的關鍵字,左子樹的所有關鍵字小於它,右子樹的所有關鍵字都大於等於它
- 非葉子節點僅用於索引,不會儲存資料記錄
- 父節點的關鍵字也會出現在子節點中,並且都是子節點中的最大值(或者最小值)
- 所有關鍵字都會出現在葉子節點中,葉子節點構成一個有序連結串列,按從小到大排序。
範例如下,本例中,父節點的關鍵字都是子節點中的最小值 (圖源:極客時間 SQL 必知必會):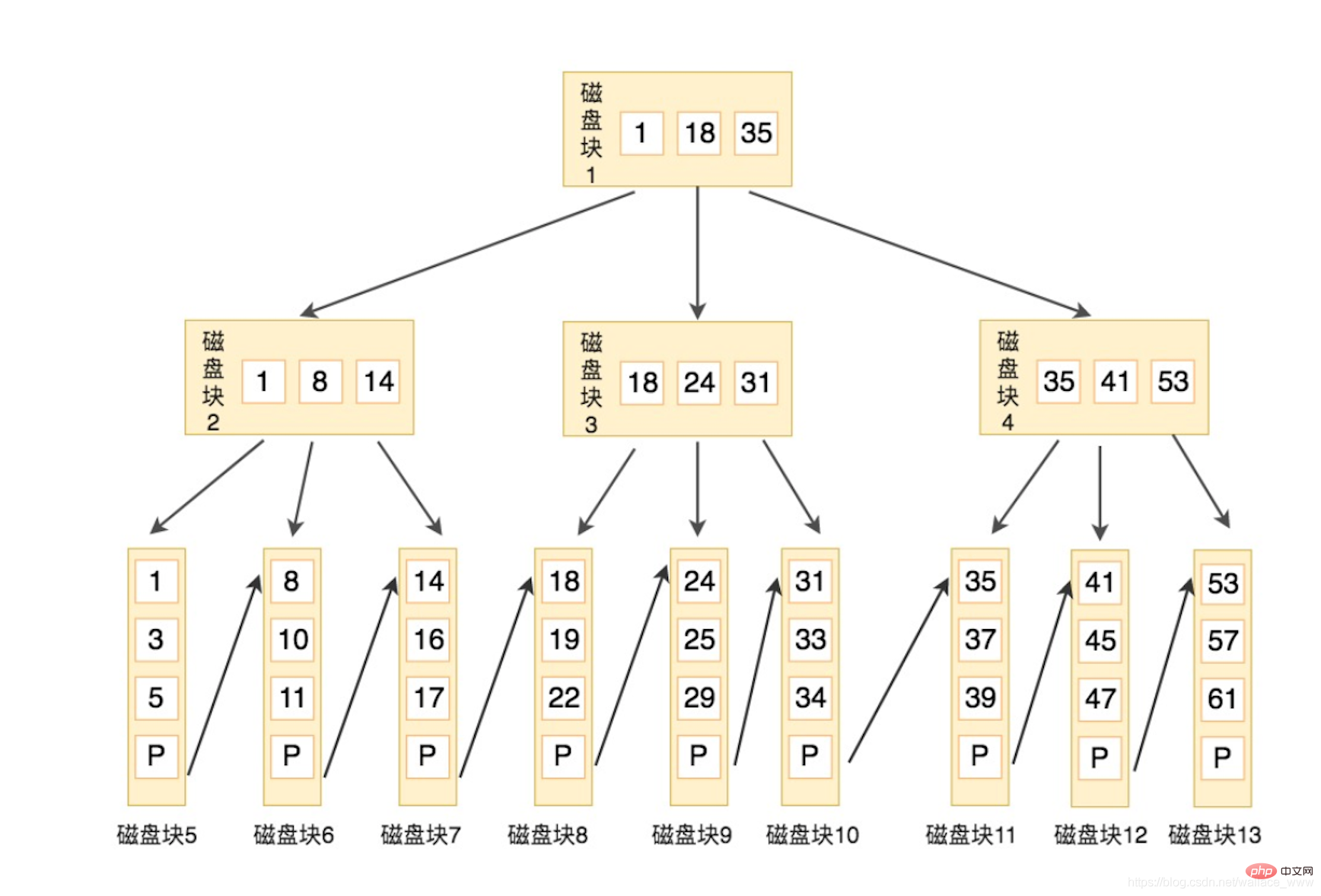
假設要查詢關鍵字 16,查詢步驟如下:
- 與根節點磁碟 1 (1,18,35) 比較,16 在 1 和 18 之間,得到指標 P1,指向磁碟 2
- 找到磁碟 2 (1,8,14),16 大於 14,得到指標P3,指向磁碟 7
- 找到磁碟 7 (14,16,17),找到16
B+ 樹優點:
- 內部節點不儲存資料,因此每個內部節點可以儲存的記錄數量遠大於 B樹,樹的高度更低,I/O 更少,每次 I/O 讀取的資料頁裡內容更多
- 可以支援範圍查詢,直接在葉子節點組成的有序連結串列遍歷即可
- 所有資料都儲存在葉子節點,因此查詢效率更穩定
HASH 索引
MySQL 的 memory 儲存引擎預設的索引結構是 Hash 索引,Hash 是一種函數, 稱為雜湊函數,通過特定演演算法(如 MD5, SHA1,SHA2 等)將任意長度的輸入轉換為固定長度的輸出,輸入和輸出一一對應,本文不會對 hash 函數做深入的介紹,詳情請參考 百度百科。
Hash 查詢的效率為 O(1),效率非常高,python 的 dict,golang 中的 map,java 中的 hash map 都是基於 hash 實現的,在 Redis 這樣的 Key-Value 資料庫也是由 Hash 實現。
對於精確查詢而言,Hash 索引的效率會比 B+ 樹索引更高,但是 Hash 索引有一些侷限性,因此不是最主流的索引結構。
- 因為 Hash 索引指向的資料是無序的,所以Hash 索引不能範圍查詢,也不支援 ORDER BY 排序。
- 由於 Hash 是精確匹配,因此也不能進行模糊查詢。
- Hash 索引不支援聯合索引的最左匹配原則,聯合索引只有在完全匹配時生效。因為 Hash 索引計算 Hash 值的時候是將索引合併後再一起計算 Hash 值,而不會計算每個索引的單獨 Hash 值。
- 如果被索引欄位的重複值很多,那就會造成大量的 Hash 衝突,這時候查詢就會變得非常耗時。
基於上述原因考慮,Mysql InnoDB 引擎不支援 Hash 索引,但是在記憶體結構中有一個自適應 Hash 索引的功能,當某個索引值使用非常頻繁的時候,會在 B+ 樹索引的基礎上自動建立一個 Hash 索引,來提高查詢效能。
自適應 Hash 索引可以理解為一種 「索引的索引」,採用 Hash 索引儲存 B+ 樹索引中的頁面地址,迅速定位到對應的葉子節點。可以通過 innodb_adaptive_hash_index 變數來檢視。
推薦學習:
以上就是深入瞭解MySQL索引結構的詳細內容,更多請關注TW511.COM其它相關文章!