歸納整理Java並行知識點

推薦學習:《》
1.並行跟並行有什麼區別?
從作業系統的角度來看,執行緒是CPU分配的最小單位。
- 並行就是同一時刻,兩個執行緒都在執行。這就要求有兩個CPU去分別執行兩個執行緒。
- 並行就是同一時刻,只有一個執行,但是一個時間段內,兩個執行緒都執行了。並行的實現依賴於CPU切換執行緒,因為切換的時間特別短,所以基本對於使用者是無感知的。
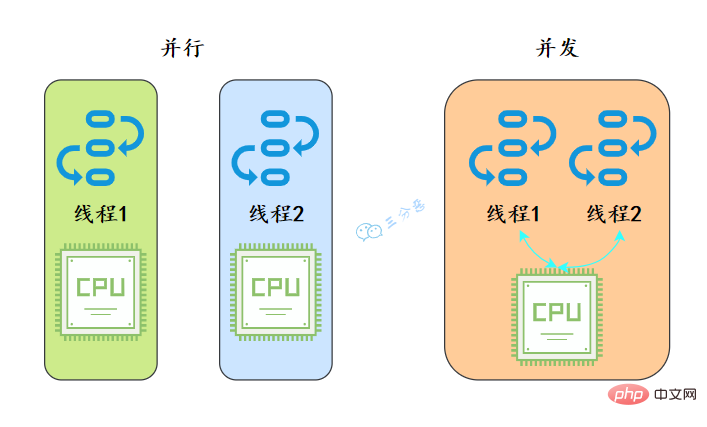
就好像我們去食堂打飯,並行就是我們在多個視窗排隊,幾個阿姨同時打菜;並行就是我們擠在一個視窗,阿姨給這個打一勺,又手忙腳亂地給那個打一勺。

2.說說什麼是程序和執行緒?
要說執行緒,必須得先說說程序。
- 程序:程序是程式碼在資料集合上的一次執行活動,是系統進行資源分配和排程的基本單位。
- 執行緒:執行緒是程序的一個執行路徑,一個程序中至少有一個執行緒,程序中的多個執行緒共用程序的資源。
作業系統在分配資源時是把資源分配給程序的, 但是 CPU 資源比較特殊,它是被分配到執行緒的,因為真正要佔用CPU執行的是執行緒,所以也說執行緒是 CPU分配的基本單位。
比如在Java中,當我們啟動 main 函數其實就啟動了一個JVM程序,而 main 函數在的執行緒就是這個程序中的一個執行緒,也稱主執行緒。
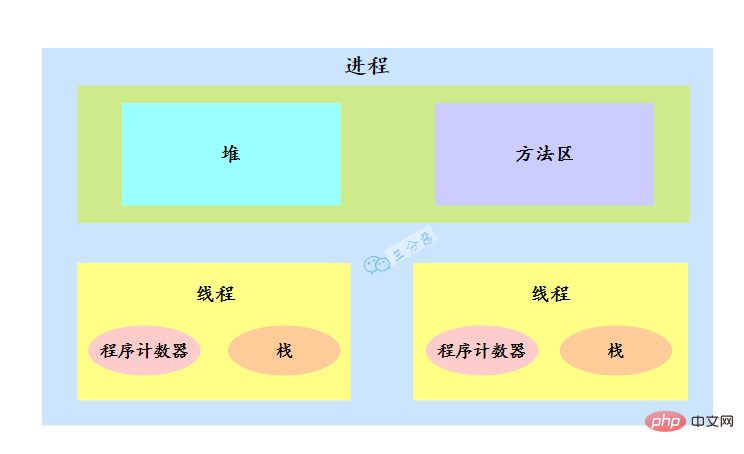
一個程序中有多個執行緒,多個執行緒共用程序的堆和方法區資源,但是每個執行緒有自己的程式計數器和棧。
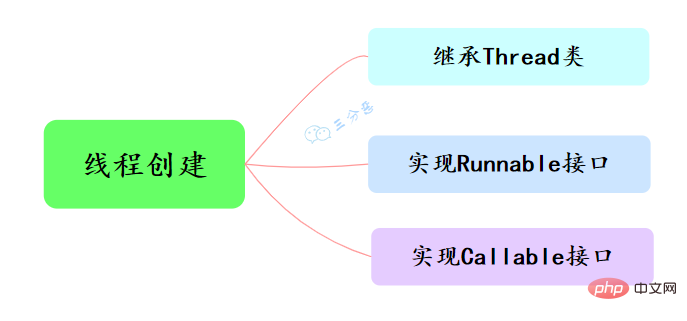
3.說說執行緒有幾種建立方式?
Java中建立執行緒主要有三種方式,分別為繼承Thread類、實現Runnable介面、實現Callable介面。
- 繼承Thread類,重寫run()方法,呼叫start()方法啟動執行緒
public class ThreadTest {
/**
* 繼承Thread類
*/
public static class MyThread extends Thread {
@Override
public void run() {
System.out.println("This is child thread");
}
}
public static void main(String[] args) {
MyThread thread = new MyThread();
thread.start();
}}- 實現 Runnable 介面,重寫run()方法
public class RunnableTask implements Runnable {
public void run() {
System.out.println("Runnable!");
}
public static void main(String[] args) {
RunnableTask task = new RunnableTask();
new Thread(task).start();
}}上面兩種都是沒有返回值的,但是如果我們需要獲取執行緒的執行結果,該怎麼辦呢?
- 實現Callable介面,重寫call()方法,這種方式可以通過FutureTask獲取任務執行的返回值
public class CallerTask implements Callable<String> {
public String call() throws Exception {
return "Hello,i am running!";
}
public static void main(String[] args) {
//建立非同步任務
FutureTask<String> task=new FutureTask<String>(new CallerTask());
//啟動執行緒
new Thread(task).start();
try {
//等待執行完成,並獲取返回結果
String result=task.get();
System.out.println(result);
} catch (InterruptedException e) {
e.printStackTrace();
} catch (ExecutionException e) {
e.printStackTrace();
}
}}4.為什麼呼叫start()方法時會執行run()方法,那怎麼不直接呼叫run()方法?
JVM執行start方法,會先建立一條執行緒,由建立出來的新執行緒去執行thread的run方法,這才起到多執行緒的效果。
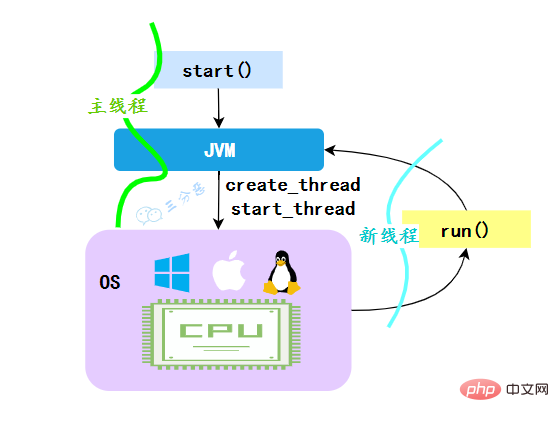
**為什麼我們不能直接呼叫run()方法?**也很清楚, 如果直接呼叫Thread的run()方法,那麼run方法還是執行在主執行緒中,相當於順序執行,就起不到多執行緒的效果。
5.執行緒有哪些常用的排程方法?
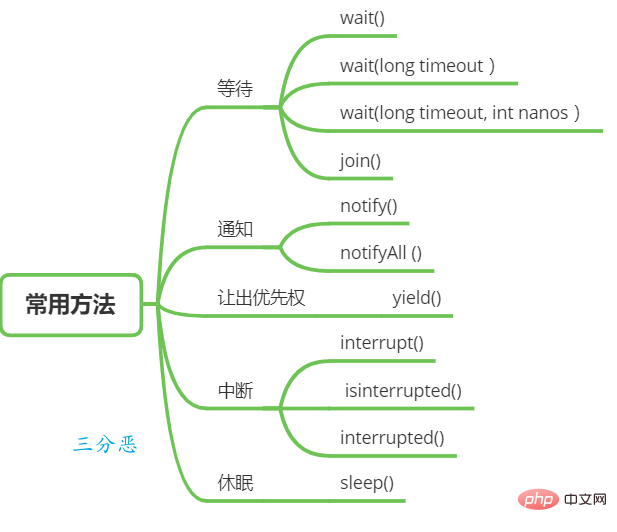
執行緒等待與通知
在Object類中有一些函數可以用於執行緒的等待與通知。
wait():當一個執行緒A呼叫一個共用變數的 wait()方法時, 執行緒A會被阻塞掛起, 發生下面幾種情況才會返回 :
(1) 執行緒A呼叫了共用物件 notify()或者 notifyAll()方法;
(2)其他執行緒呼叫了執行緒A的 interrupt() 方法,執行緒A丟擲InterruptedException異常返回。
wait(long timeout) :這個方法相比 wait() 方法多了一個超時引數,它的不同之處在於,如果執行緒A呼叫共用物件的wait(long timeout)方法後,沒有在指定的 timeout ms時間內被其它執行緒喚醒,那麼這個方法還是會因為超時而返回。
wait(long timeout, int nanos),其內部呼叫的是 wait(long timout)函數。
上面是執行緒等待的方法,而喚醒執行緒主要是下面兩個方法:
- notify() : 一個執行緒A呼叫共用物件的 notify() 方法後,會喚醒一個在這個共用變數上呼叫 wait 系列方法後被掛起的執行緒。 一個共用變數上可能會有多個執行緒在等待,具體喚醒哪個等待的執行緒是隨機的。
- notifyAll() :不同於在共用變數上呼叫 notify() 函數會喚醒被阻塞到該共用變數上的一個執行緒,notifyAll()方法則會喚醒所有在該共用變數上由於呼叫 wait 系列方法而被掛起的執行緒。
Thread類也提供了一個方法用於等待的方法:
join():如果一個執行緒A執行了thread.join()語句,其含義是:當前執行緒A等待thread執行緒終止之後才
從thread.join()返回。
執行緒休眠
- sleep(long millis) :Thread類中的靜態方法,當一個執行中的執行緒A呼叫了Thread 的sleep方法後,執行緒A會暫時讓出指定時間的執行權,但是執行緒A所擁有的監視器資源,比如鎖還是持有不讓出的。指定的睡眠時間到了後該函數會正常返回,接著參與 CPU 的排程,獲取到 CPU 資源後就可以繼續執行。
讓出優先權
- yield() :Thread類中的靜態方法,當一個執行緒呼叫 yield 方法時,實際就是在暗示執行緒排程器當前執行緒請求讓出自己的CPU ,但是執行緒排程器可以無條件忽略這個暗示。
執行緒中斷
Java 中的執行緒中斷是一種執行緒間的共同作業模式,通過設定執行緒的中斷標誌並不能直接終止該執行緒的執行,而是被中斷的執行緒根據中斷狀態自行處理。
- void interrupt() :中斷執行緒,例如,當執行緒A執行時,執行緒B可以呼叫錢程interrupt() 方法來設定執行緒的中斷標誌為true 並立即返回。設定標誌僅僅是設定標誌, 執行緒A實際並沒有被中斷, 會繼續往下執行。
- boolean isInterrupted() 方法: 檢測當前執行緒是否被中斷。
- boolean interrupted() 方法: 檢測當前執行緒是否被中斷,與 isInterrupted 不同的是,該方法如果發現當前執行緒被中斷,則會清除中斷標誌。
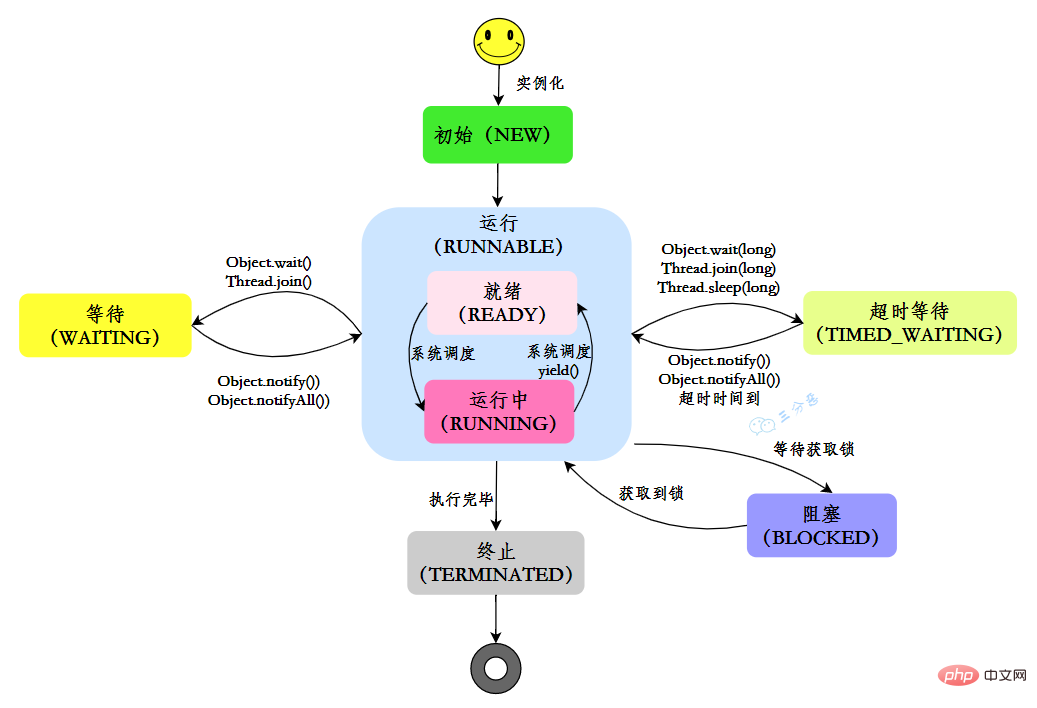
6.執行緒有幾種狀態?
在Java中,執行緒共有六種狀態:
| 狀態 | 說明 |
|---|---|
| NEW | 初始狀態:執行緒被建立,但還沒有呼叫start()方法 |
| RUNNABLE | 執行狀態:Java執行緒將作業系統中的就緒和執行兩種狀態籠統的稱作「執行」 |
| BLOCKED | 阻塞狀態:表示執行緒阻塞於鎖 |
| WAITING | 等待狀態:表示執行緒進入等待狀態,進入該狀態表示當前執行緒需要等待其他執行緒做出一些特定動作(通知或中斷) |
| TIME_WAITING | 超時等待狀態:該狀態不同於 WAITIND,它是可以在指定的時間自行返回的 |
| TERMINATED | 終止狀態:表示當前執行緒已經執行完畢 |
執行緒在自身的生命週期中, 並不是固定地處於某個狀態,而是隨著程式碼的執行在不同的狀態之間進行切換,Java執行緒狀態變化如圖示:
7.什麼是執行緒上下文切換?
使用多執行緒的目的是為了充分利用CPU,但是我們知道,並行其實是一個CPU來應付多個執行緒。
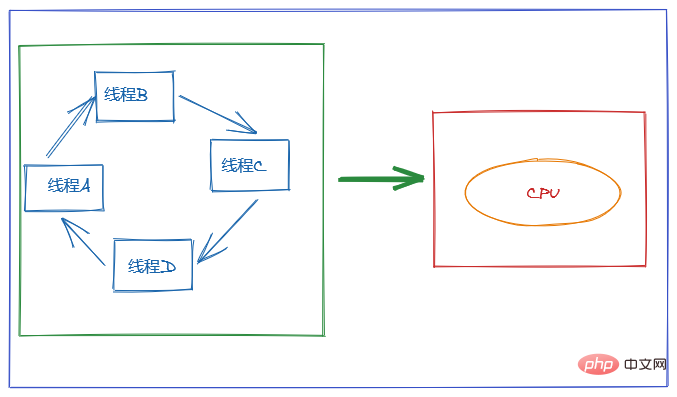
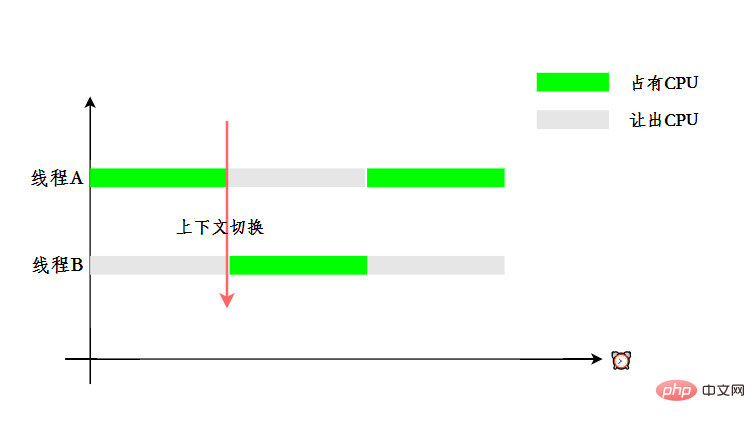
為了讓使用者感覺多個執行緒是在同時執行的, CPU 資源的分配採用了時間片輪轉也就是給每個執行緒分配一個時間片,執行緒在時間片內佔用 CPU 執行任務。當執行緒使用完時間片後,就會處於就緒狀態並讓出 CPU 讓其他執行緒佔用,這就是上下文切換。
8.守護執行緒瞭解嗎?
Java中的執行緒分為兩類,分別為 daemon 執行緒(守護執行緒)和 user 執行緒(使用者執行緒)。
在JVM 啟動時會呼叫 main 函數,main函數所在的錢程就是一個使用者執行緒。其實在 JVM 內部同時還啟動了很多守護執行緒, 比如垃圾回收執行緒。
那麼守護執行緒和使用者執行緒有什麼區別呢?區別之一是當最後一個非守護執行緒束時, JVM會正常退出,而不管當前是否存在守護執行緒,也就是說守護執行緒是否結束並不影響 JVM退出。換而言之,只要有一個使用者執行緒還沒結束,正常情況下JVM就不會退出。
9.執行緒間有哪些通訊方式?
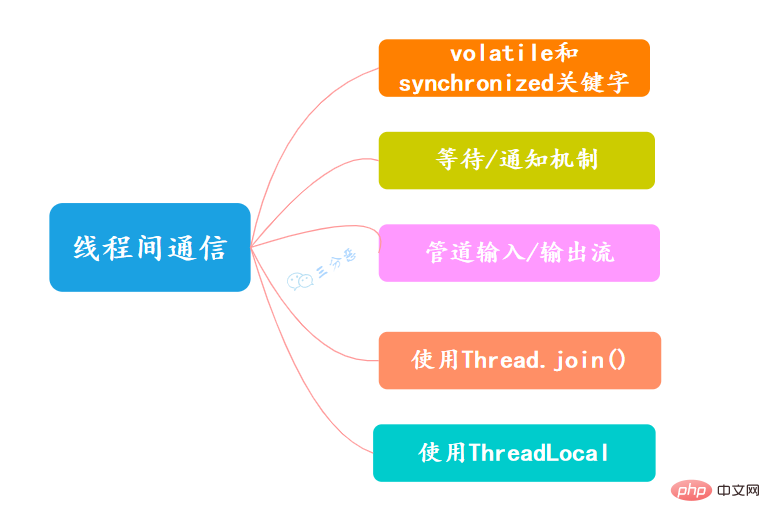
- volatile和synchronized關鍵字
關鍵字volatile可以用來修飾欄位(成員變數),就是告知程式任何對該變數的存取均需要從共用記憶體中獲取,而對它的改變必須同步重新整理回共用記憶體,它能保證所有執行緒對變數存取的可見性。
關鍵字synchronized可以修飾方法或者以同步塊的形式來進行使用,它主要確保多個執行緒在同一個時刻,只能有一個執行緒處於方法或者同步塊中,它保證了執行緒對變數存取的可見性和排他性。
- 等待/通知機制
可以通過Java內建的等待/通知機制(wait()/notify())實現一個執行緒修改一個物件的值,而另一個執行緒感知到了變化,然後進行相應的操作。
- 管道輸入/輸出流
管道輸入/輸出流和普通的檔案輸入/輸出流或者網路輸入/輸出流不同之處在於,它主要用於執行緒之間的資料傳輸,而傳輸的媒介為記憶體。
管道輸入/輸出流主要包括瞭如下4種具體實現:PipedOutputStream、PipedInputStream、 PipedReader和PipedWriter,前兩種面向位元組,而後兩種面向字元。
- 使用Thread.join()
如果一個執行緒A執行了thread.join()語句,其含義是:當前執行緒A等待thread執行緒終止之後才從thread.join()返回。。執行緒Thread除了提供join()方法之外,還提供了join(long millis)和join(long millis,int nanos)兩個具備超時特性的方法。
- 使用ThreadLocal
ThreadLocal,即執行緒變數,是一個以ThreadLocal物件為鍵、任意物件為值的儲存結構。這個結構被附帶線上程上,也就是說一個執行緒可以根據一個ThreadLocal物件查詢到繫結在這個執行緒上的一個值。
可以通過set(T)方法來設定一個值,在當前執行緒下再通過get()方法獲取到原先設定的值。
關於多執行緒,其實很大概率還會出一些筆試題,比如交替列印、銀行轉賬、生產消費模型等等,後面老三會單獨出一期來盤點一下常見的多執行緒筆試題。
ThreadLocal
ThreadLocal其實應用場景不是很多,但卻是被炸了千百遍的面試老油條,涉及到多執行緒、資料結構、JVM,可問的點比較多,一定要拿下。
10.ThreadLocal是什麼?
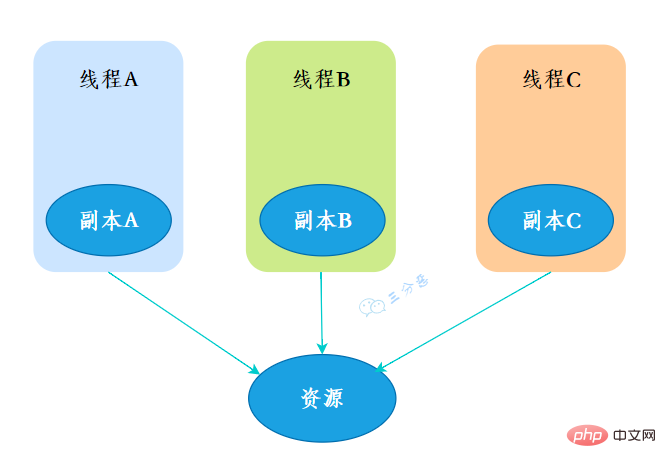
ThreadLocal,也就是執行緒本地變數。如果你建立了一個ThreadLocal變數,那麼存取這個變數的每個執行緒都會有這個變數的一個本地拷貝,多個執行緒操作這個變數的時候,實際是操作自己本地記憶體裡面的變數,從而起到執行緒隔離的作用,避免了執行緒安全問題。
- 建立
建立了一個ThreadLoca變數localVariable,任何一個執行緒都能並行存取localVariable。
//建立一個ThreadLocal變數public static ThreadLocal<String> localVariable = new ThreadLocal<>();
- 寫入
執行緒可以在任何地方使用localVariable,寫入變數。
localVariable.set("鄙人三某」);- 讀取
執行緒在任何地方讀取的都是它寫入的變數。
localVariable.get();
11.你在工作中用到過ThreadLocal嗎?
有用到過的,用來做使用者資訊上下文的儲存。
我們的系統應用是一個典型的MVC架構,登入後的使用者每次存取介面,都會在請求頭中攜帶一個token,在控制層可以根據這個token,解析出使用者的基本資訊。那麼問題來了,假如在服務層和持久層都要用到使用者資訊,比如rpc呼叫、更新使用者獲取等等,那應該怎麼辦呢?
一種辦法是顯式定義使用者相關的引數,比如賬號、使用者名稱……這樣一來,我們可能需要大面積地修改程式碼,多少有點瓜皮,那該怎麼辦呢?
這時候我們就可以用到ThreadLocal,在控制層攔截請求把使用者資訊存入ThreadLocal,這樣我們在任何一個地方,都可以取出ThreadLocal中存的使用者資料。
很多其它場景的cookie、session等等資料隔離也都可以通過ThreadLocal去實現。
我們常用的資料庫連線池也用到了ThreadLocal:
- 資料庫連線池的連線交給ThreadLoca進行管理,保證當前執行緒的操作都是同一個Connnection。
12.ThreadLocal怎麼實現的呢?
我們看一下ThreadLocal的set(T)方法,發現先獲取到當前執行緒,再獲取ThreadLocalMap,然後把元素存到這個map中。
public void set(T value) {
//獲取當前執行緒
Thread t = Thread.currentThread();
//獲取ThreadLocalMap
ThreadLocalMap map = getMap(t);
//講當前元素存入map
if (map != null)
map.set(this, value);
else
createMap(t, value);
}ThreadLocal實現的祕密都在這個ThreadLocalMap了,可以Thread類中定義了一個型別為ThreadLocal.ThreadLocalMap的成員變數threadLocals。
public class Thread implements Runnable {
//ThreadLocal.ThreadLocalMap是Thread的屬性
ThreadLocal.ThreadLocalMap threadLocals = null;}ThreadLocalMap既然被稱為Map,那麼毫無疑問它是<key,value>型的資料結構。我們都知道map的本質是一個個<key,value>形式的節點組成的陣列,那ThreadLocalMap的節點是什麼樣的呢?
static class Entry extends WeakReference<ThreadLocal<?>> {
/** The value associated with this ThreadLocal. */
Object value;
//節點類
Entry(ThreadLocal<?> k, Object v) {
//key賦值
super(k);
//value賦值
value = v;
}
}這裡的節點,key可以簡單低視作ThreadLocal,value為程式碼中放入的值,當然實際上key並不是ThreadLocal本身,而是它的一個弱參照,可以看到Entry的key繼承了 WeakReference(弱參照),再來看一下key怎麼賦值的:
public WeakReference(T referent) {
super(referent);
}key的賦值,使用的是WeakReference的賦值。
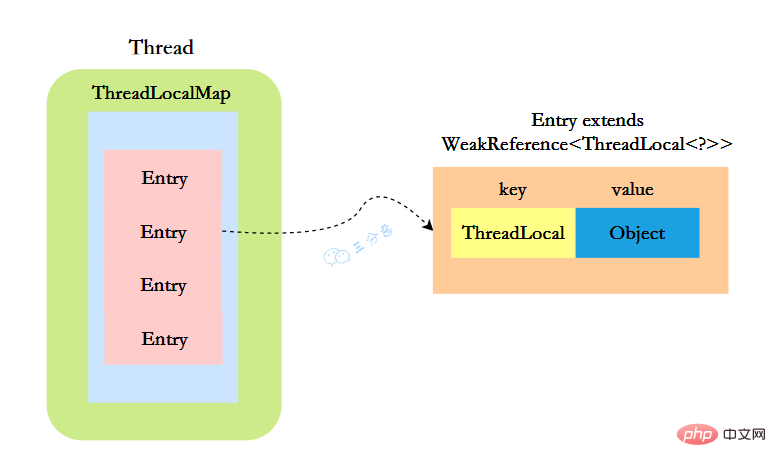
所以,怎麼回答ThreadLocal原理?要答出這幾個點:
- Thread類有一個型別為ThreadLocal.ThreadLocalMap的範例變數threadLocals,每個執行緒都有一個屬於自己的ThreadLocalMap。
- ThreadLocalMap內部維護著Entry陣列,每個Entry代表一個完整的物件,key是ThreadLocal的弱參照,value是ThreadLocal的泛型值。
- 每個執行緒在往ThreadLocal裡設定值的時候,都是往自己的ThreadLocalMap裡存,讀也是以某個ThreadLocal作為參照,在自己的map裡找對應的key,從而實現了執行緒隔離。
- ThreadLocal本身不儲存值,它只是作為一個key來讓執行緒往ThreadLocalMap裡存取值。
13.ThreadLocal 記憶體洩露是怎麼回事?
我們先來分析一下使用ThreadLocal時的記憶體,我們都知道,在JVM中,棧記憶體執行緒私有,儲存了物件的參照,堆記憶體執行緒共用,儲存了物件範例。
所以呢,棧中儲存了ThreadLocal、Thread的參照,堆中儲存了它們的具體範例。
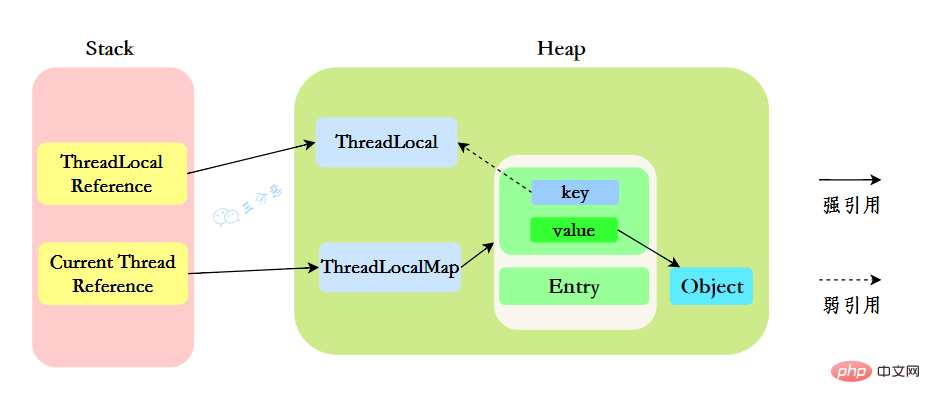
ThreadLocalMap中使用的 key 為 ThreadLocal 的弱參照。
「弱參照:只要垃圾回收機制一執行,不管JVM的記憶體空間是否充足,都會回收該物件佔用的記憶體。」
那麼現在問題就來了,弱參照很容易被回收,如果ThreadLocal(ThreadLocalMap的Key)被垃圾回收器回收了,但是ThreadLocalMap生命週期和Thread是一樣的,它這時候如果不被回收,就會出現這種情況:ThreadLocalMap的key沒了,value還在,這就會造成了記憶體漏失問題。
那怎麼解決記憶體漏失問題呢?
很簡單,使用完ThreadLocal後,及時呼叫remove()方法釋放記憶體空間。
ThreadLocal<String> localVariable = new ThreadLocal();try {
localVariable.set("鄙人三某」);
……} finally {
localVariable.remove();}那為什麼key還要設計成弱參照?
key設計成弱參照同樣是為了防止記憶體漏失。
假如key被設計成強參照,如果ThreadLocal Reference被銷燬,此時它指向ThreadLoca的強參照就沒有了,但是此時key還強參照指向ThreadLoca,就會導致ThreadLocal不能被回收,這時候就發生了記憶體漏失的問題。
14.ThreadLocalMap的結構瞭解嗎?
ThreadLocalMap雖然被叫做Map,其實它是沒有實現Map介面的,但是結構還是和HashMap比較類似的,主要關注的是兩個要素:元素陣列和雜湊方法。
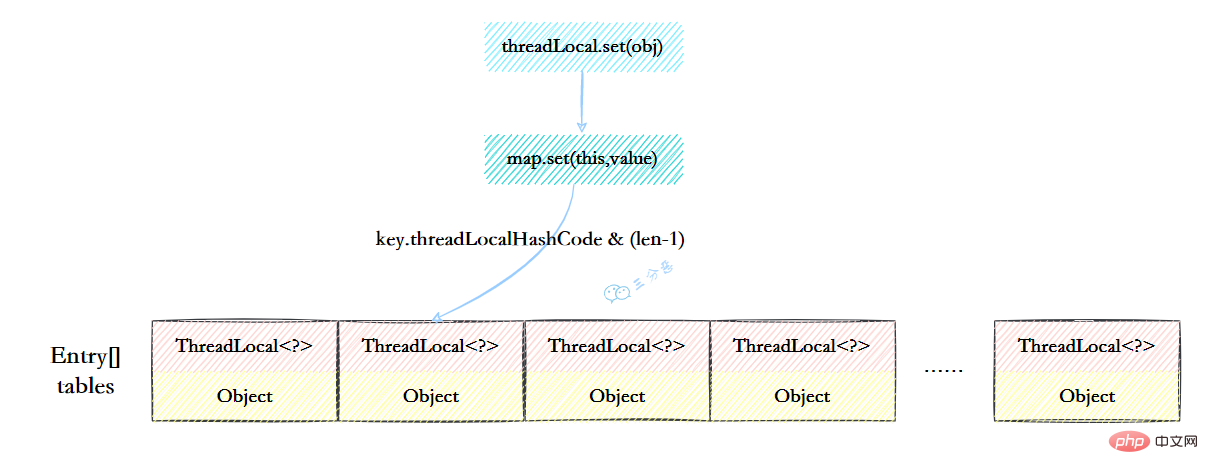
元素陣列
一個table陣列,儲存Entry型別的元素,Entry是ThreaLocal弱參照作為key,Object作為value的結構。
private Entry[] table;
雜湊方法
雜湊方法就是怎麼把對應的key對映到table陣列的相應下標,ThreadLocalMap用的是雜湊取餘法,取出key的threadLocalHashCode,然後和table陣列長度減一&運算(相當於取餘)。
int i = key.threadLocalHashCode & (table.length - 1);
這裡的threadLocalHashCode計算有點東西,每建立一個ThreadLocal物件,它就會新增0x61c88647,這個值很特殊,它是斐波那契數 也叫 黃金分割數。hash增量為 這個數位,帶來的好處就是 hash 分佈非常均勻。
private static final int HASH_INCREMENT = 0x61c88647;
private static int nextHashCode() {
return nextHashCode.getAndAdd(HASH_INCREMENT);
}15.ThreadLocalMap怎麼解決Hash衝突的?
我們可能都知道HashMap使用了連結串列來解決衝突,也就是所謂的鏈地址法。
ThreadLocalMap沒有使用連結串列,自然也不是用鏈地址法來解決衝突了,它用的是另外一種方式——開放定址法。開放定址法是什麼意思呢?簡單來說,就是這個坑被人佔了,那就接著去找空著的坑。
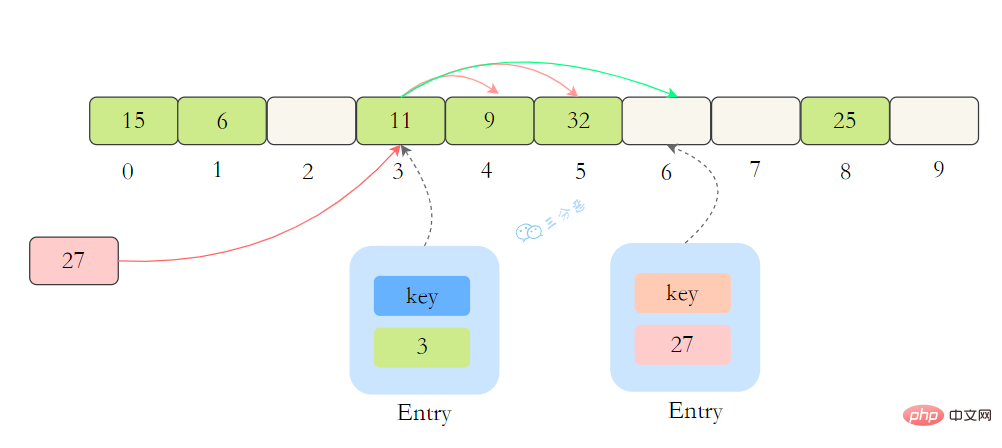
如上圖所示,如果我們插入一個value=27的資料,通過 hash計算後應該落入第 4 個槽位中,而槽位 4 已經有了 Entry資料,而且Entry資料的key和當前不相等。此時就會線性向後查詢,一直找到 Entry為 null的槽位才會停止查詢,把元素放到空的槽中。
在get的時候,也會根據ThreadLocal物件的hash值,定位到table中的位置,然後判斷該槽位Entry物件中的key是否和get的key一致,如果不一致,就判斷下一個位置。
16.ThreadLocalMap擴容機制瞭解嗎?
在ThreadLocalMap.set()方法的最後,如果執行完啟發式清理工作後,未清理到任何資料,且當前雜湊陣列中Entry的數量已經達到了列表的擴容閾值(len*2/3),就開始執行rehash()邏輯:
if (!cleanSomeSlots(i, sz) && sz >= threshold)
rehash();再著看rehash()具體實現:這裡會先去清理過期的Entry,然後還要根據條件判斷size >= threshold - threshold / 4 也就是size >= threshold* 3/4來決定是否需要擴容。
private void rehash() {
//清理過期Entry
expungeStaleEntries();
//擴容
if (size >= threshold - threshold / 4)
resize();}//清理過期Entryprivate void expungeStaleEntries() {
Entry[] tab = table;
int len = tab.length;
for (int j = 0; j < len; j++) {
Entry e = tab[j];
if (e != null && e.get() == null)
expungeStaleEntry(j);
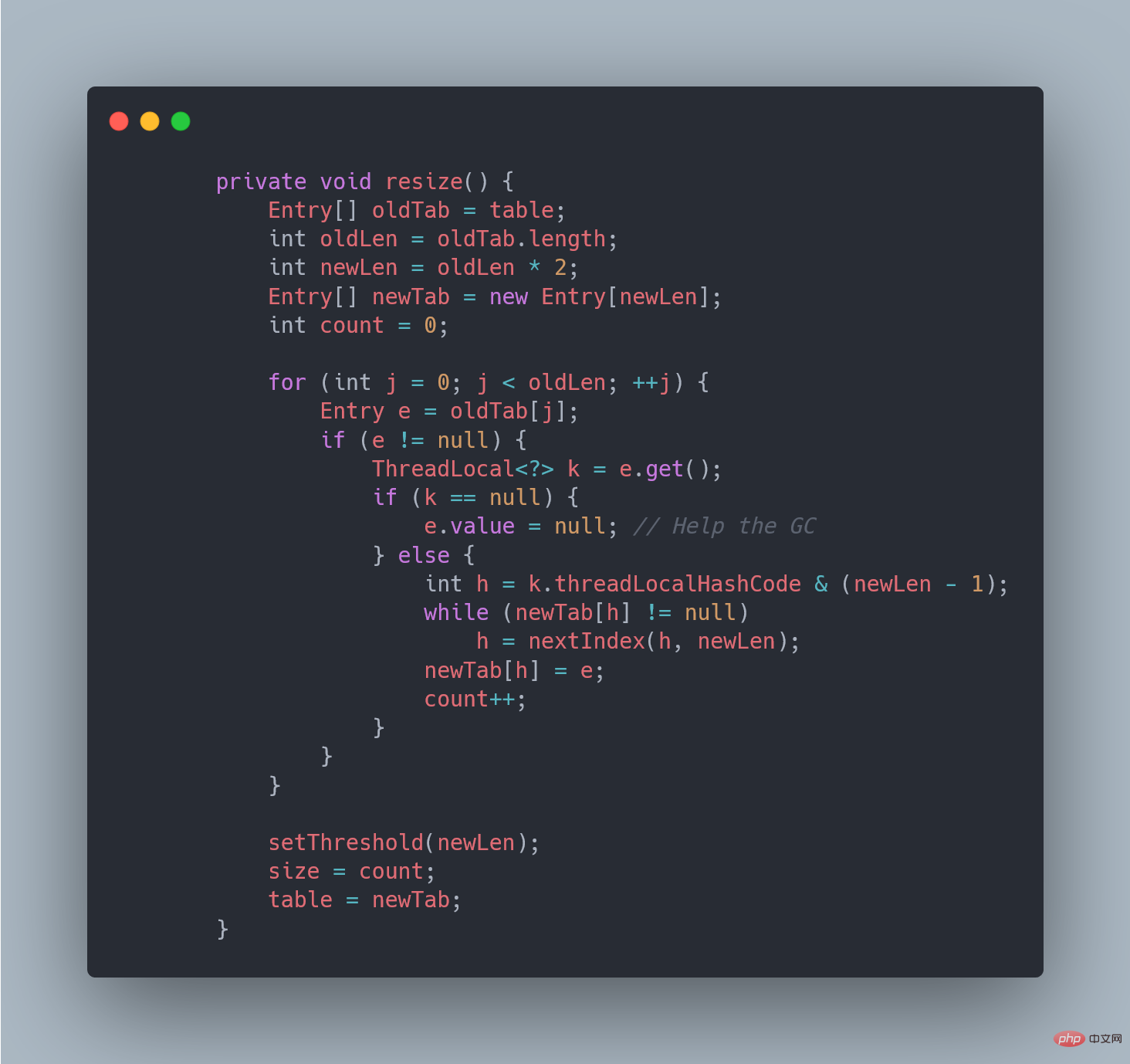
}}接著看看具體的resize()方法,擴容後的newTab的大小為老陣列的兩倍,然後遍歷老的table陣列,雜湊方法重新計算位置,開放地址解決衝突,然後放到新的newTab,遍歷完成之後,oldTab中所有的entry資料都已經放入到newTab中了,然後table參照指向newTab
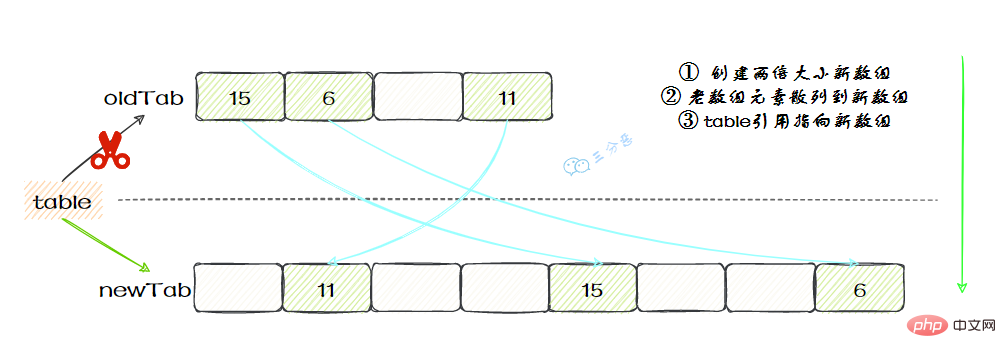
具體程式碼:
17.父子執行緒怎麼共用資料?
父執行緒能用ThreadLocal來給子執行緒傳值嗎?毫無疑問,不能。那該怎麼辦?
這時候可以用到另外一個類——InheritableThreadLocal。
使用起來很簡單,在主執行緒的InheritableThreadLocal範例設定值,在子執行緒中就可以拿到了。
public class InheritableThreadLocalTest {
public static void main(String[] args) {
final ThreadLocal threadLocal = new InheritableThreadLocal();
// 主執行緒
threadLocal.set("不擅技術");
//子執行緒
Thread t = new Thread() {
@Override
public void run() {
super.run();
System.out.println("鄙人三某 ," + threadLocal.get());
}
};
t.start();
}}那原理是什麼呢?
原理很簡單,在Thread類裡還有另外一個變數:
ThreadLocal.ThreadLocalMap inheritableThreadLocals = null;
在Thread.init的時候,如果父執行緒的inheritableThreadLocals不為空,就把它賦給當前執行緒(子執行緒)的inheritableThreadLocals。
if (inheritThreadLocals && parent.inheritableThreadLocals != null)
this.inheritableThreadLocals =
ThreadLocal.createInheritedMap(parent.inheritableThreadLocals)18.說一下你對Java記憶體模型(JMM)的理解?
Java記憶體模型(Java Memory Model,JMM),是一種抽象的模型,被定義出來遮蔽各種硬體和作業系統的記憶體存取差異。
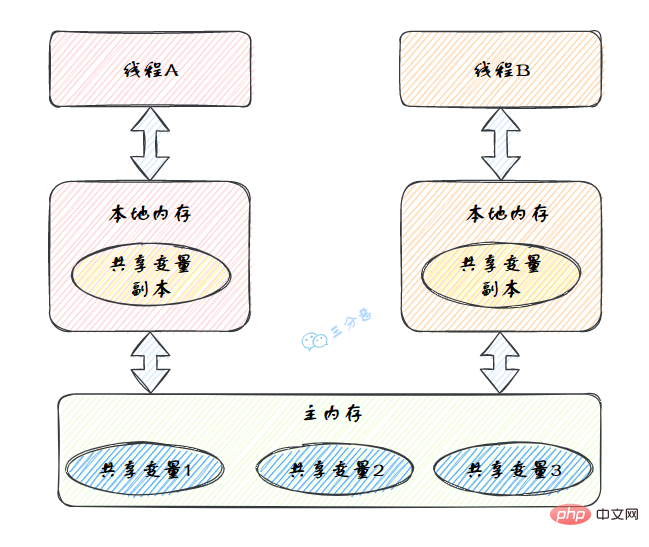
JMM定義了執行緒和主記憶體之間的抽象關係:執行緒之間的共用變數儲存在主記憶體(Main Memory)中,每個執行緒都有一個私有的本地記憶體(Local Memory),本地記憶體中儲存了該執行緒以讀/寫共用變數的副本。
Java記憶體模型的抽象圖:
本地記憶體是JMM的 一個抽象概念,並不真實存在。它其實涵蓋了快取、寫緩衝區、暫存器以及其他的硬體和編譯器優化。
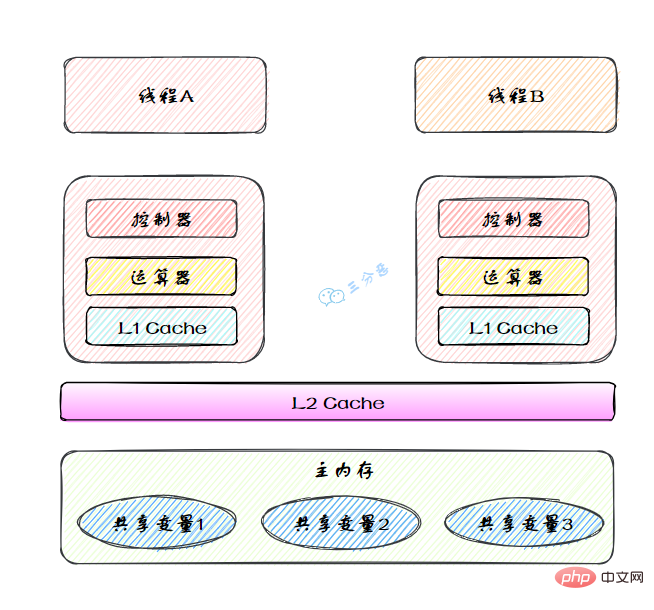
圖裡面的是一個雙核 CPU 系統架構 ,每個核有自己的控制器和運算器,其中控制器包含一組暫存器和操作控制器,運算器執行算術邏輔運算。每個核都有自己的一級快取,在有些架構裡面還有一個所有 CPU 共用的二級快取。 那麼 Java 記憶體模型裡面的工作記憶體,就對應這裡的 Ll 快取或者 L2 快取或者 CPU 暫存器。
19.說說你對原子性、可見性、有序性的理解?
原子性、有序性、可見性是並行程式設計中非常重要的基礎概念,JMM的很多技術都是圍繞著這三大特性展開。
- 原子性:原子性指的是一個操作是不可分割、不可中斷的,要麼全部執行並且執行的過程不會被任何因素打斷,要麼就全不執行。
- 可見性:可見性指的是一個執行緒修改了某一個共用變數的值時,其它執行緒能夠立即知道這個修改。
- 有序性:有序性指的是對於一個執行緒的執行程式碼,從前往後依次執行,單執行緒下可以認為程式是有序的,但是並行時有可能會發生指令重排。
分析下面幾行程式碼的原子性?
int i = 2;int j = i;i++;i = i + 1;
- 第1句是基本型別賦值,是原子性操作。
- 第2句先讀i的值,再賦值到j,兩步操作,不能保證原子性。
- 第3和第4句其實是等效的,先讀取i的值,再+1,最後賦值到i,三步操作了,不能保證原子性。
原子性、可見性、有序性都應該怎麼保證呢?
- 原子性:JMM只能保證基本的原子性,如果要保證一個程式碼塊的原子性,需要使用
synchronized。 - 可見性:Java是利用
volatile關鍵字來保證可見性的,除此之外,final和synchronized也能保證可見性。 - 有序性:
synchronized或者volatile都可以保證多執行緒之間操作的有序性。
20.那說說什麼是指令重排?
在執行程式時,為了提高效能,編譯器和處理器常常會對指令做重排序。重排序分3種型別。
- 編譯器優化的重排序。編譯器在不改變單執行緒程式語意的前提下,可以重新安排語句的執行順序。
- 指令級並行的重排序。現代處理器採用了指令級並行技術(Instruction-Level Parallelism,ILP)來將多條指令重疊執行。如果不存在資料依賴性,處理器可以改變語句對應 機器指令的執行順序。
- 記憶體系統的重排序。由於處理器使用快取和讀/寫緩衝區,這使得載入和儲存操作看上去可能是在亂序執行。
從Java原始碼到最終實際執行的指令序列,會分別經歷下面3種重排序,如圖:

我們比較熟悉的雙重校驗單例模式就是一個經典的指令重排的例子,Singleton instance=new Singleton();對應的JVM指令分為三步:分配記憶體空間–>初始化物件—>物件指向分配的記憶體空間,但是經過了編譯器的指令重排序,第二步和第三步就可能會重排序。
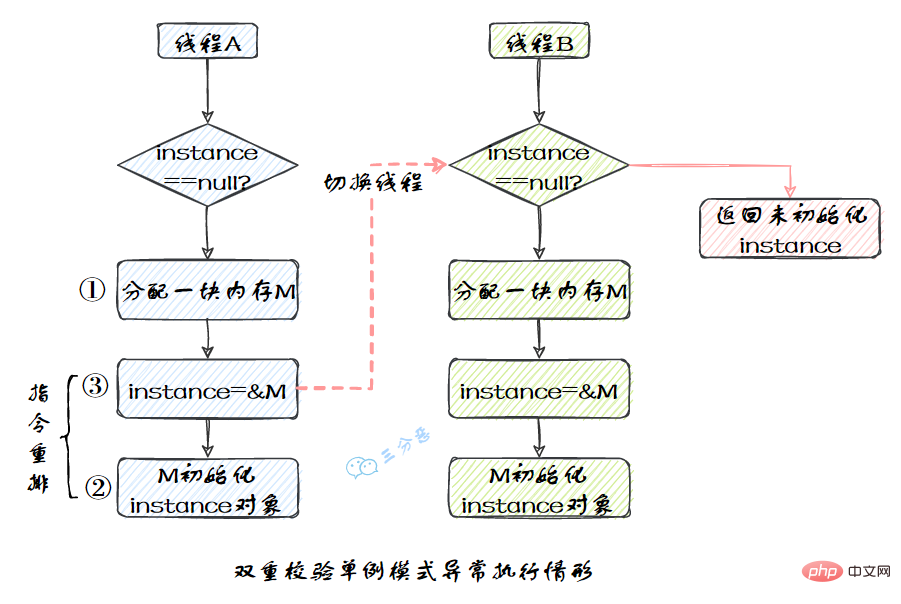
JMM屬於語言級的記憶體模型,它確保在不同的編譯器和不同的處理器平臺之上,通過禁止特定型別的編譯器重排序和處理器重排序,為程式設計師提供一致的記憶體可見性保證。
21.指令重排有限制嗎?happens-before瞭解嗎?
指令重排也是有一些限制的,有兩個規則happens-before和as-if-serial來約束。
happens-before的定義:
- 如果一個操作happens-before另一個操作,那麼第一個操作的執行結果將對第二個操作可見,而且第一個操作的執行順序排在第二個操作之前。
- 兩個操作之間存在happens-before關係,並不意味著Java平臺的具體實現必須要按照 happens-before關係指定的順序來執行。如果重排序之後的執行結果,與按happens-before關係來執行的結果一致,那麼這種重排序並不非法
happens-before和我們息息相關的有六大規則:
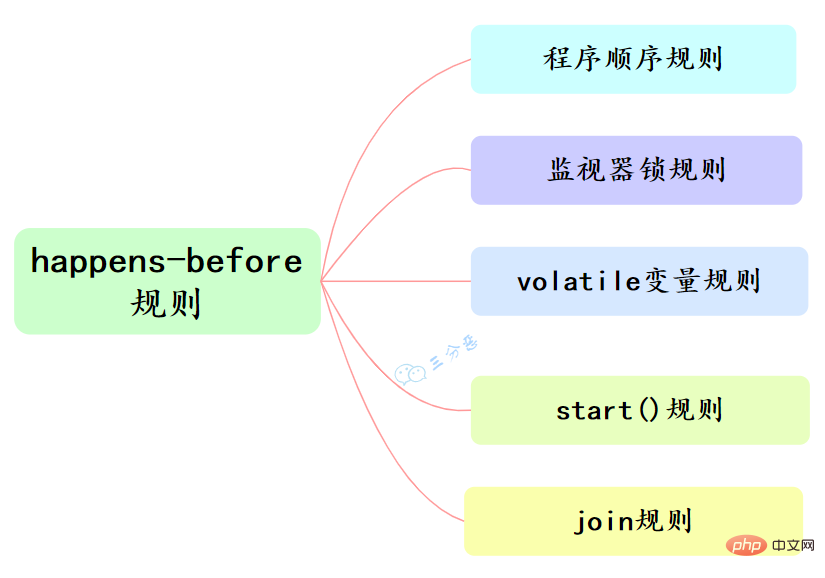
- 程式順序規則:一個執行緒中的每個操作,happens-before於該執行緒中的任意後續操作。
- 監視器鎖規則:對一個鎖的解鎖,happens-before於隨後對這個鎖的加鎖。
- volatile變數規則:對一個volatile域的寫,happens-before於任意後續對這個volatile域的讀。
- 傳遞性:如果A happens-before B,且B happens-before C,那麼A happens-before C。
- start()規則:如果執行緒A執行操作ThreadB.start()(啟動執行緒B),那麼A執行緒的 ThreadB.start()操作happens-before於執行緒B中的任意操作。
- join()規則:如果執行緒A執行操作ThreadB.join()併成功返回,那麼執行緒B中的任意操作 happens-before於執行緒A從ThreadB.join()操作成功返回。
22.as-if-serial又是什麼?單執行緒的程式一定是順序的嗎?
as-if-serial語意的意思是:不管怎麼重排序(編譯器和處理器為了提高並行度),單執行緒程式的執行結果不能被改變。編譯器、runtime和處理器都必須遵守as-if-serial語意。
為了遵守as-if-serial語意,編譯器和處理器不會對存在資料依賴關係的操作做重排序,因為這種重排序會改變執行結果。但是,如果操作之間不存在資料依賴關係,這些操作就可能被編譯器和處理器重排序。為了具體說明,請看下面計算圓面積的程式碼範例。
double pi = 3.14; // Adouble r = 1.0; // B double area = pi * r * r; // C
上面3個操作的資料依賴關係:
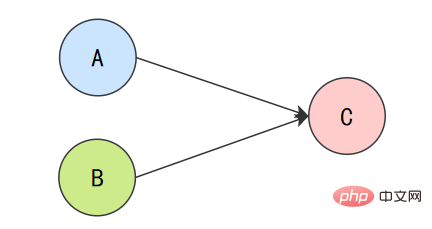
A和C之間存在資料依賴關係,同時B和C之間也存在資料依賴關係。因此在最終執行的指令序列中,C不能被重排序到A和B的前面(C排到A和B的前面,程式的結果將會被改變)。但A和B之間沒有資料依賴關係,編譯器和處理器可以重排序A和B之間的執行順序。
所以最終,程式可能會有兩種執行順序:
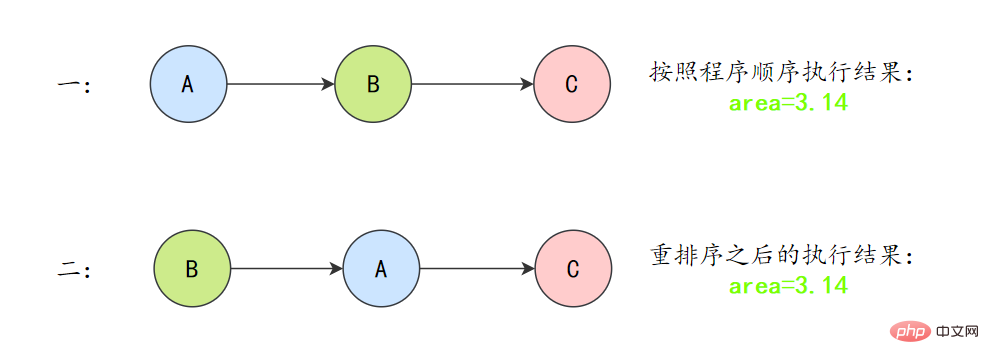
as-if-serial語意把單執行緒程式保護了起來,遵守as-if-serial語意的編譯器、runtime和處理器共同編織了這麼一個「楚門的世界」:單執行緒程式是按程式的「順序」來執行的。as- if-serial語意使單執行緒情況下,我們不需要擔心重排序的問題,可見性的問題。
23.volatile實現原理了解嗎?
volatile有兩個作用,保證可見性和有序性。
volatile怎麼保證可見性的呢?
相比synchronized的加鎖方式來解決共用變數的記憶體可見性問題,volatile就是更輕量的選擇,它沒有上下文切換的額外開銷成本。
volatile可以確保對某個變數的更新對其他執行緒馬上可見,一個變數被宣告為volatile 時,執行緒在寫入變數時不會把值快取在暫存器或者其他地方,而是會把值重新整理回主記憶體 當其它執行緒讀取該共用變數 ,會從主記憶體重新獲取最新值,而不是使用當前執行緒的本地記憶體中的值。
例如,我們宣告一個 volatile 變數 volatile int x = 0,執行緒A修改x=1,修改完之後就會把新的值重新整理回主記憶體,執行緒B讀取x的時候,就會清空本地記憶體變數,然後再從主記憶體獲取最新值。
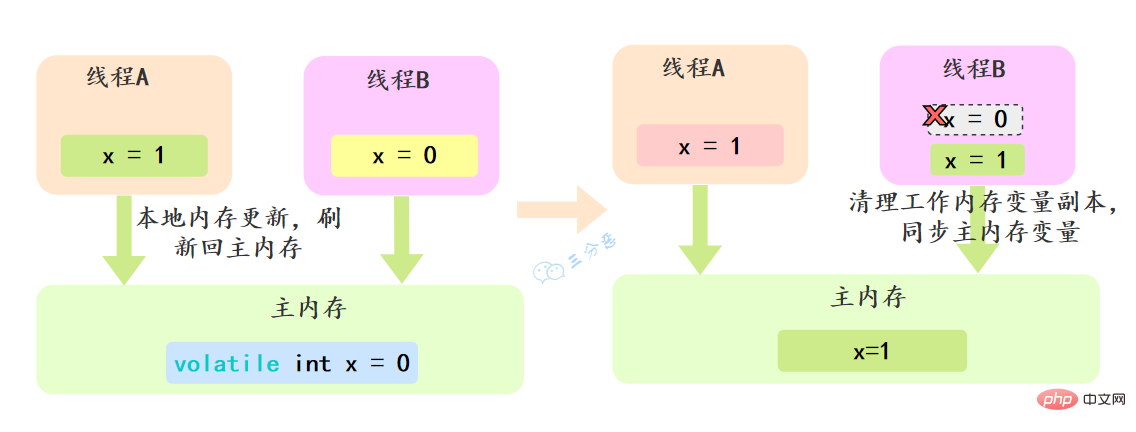
volatile怎麼保證有序性的呢?
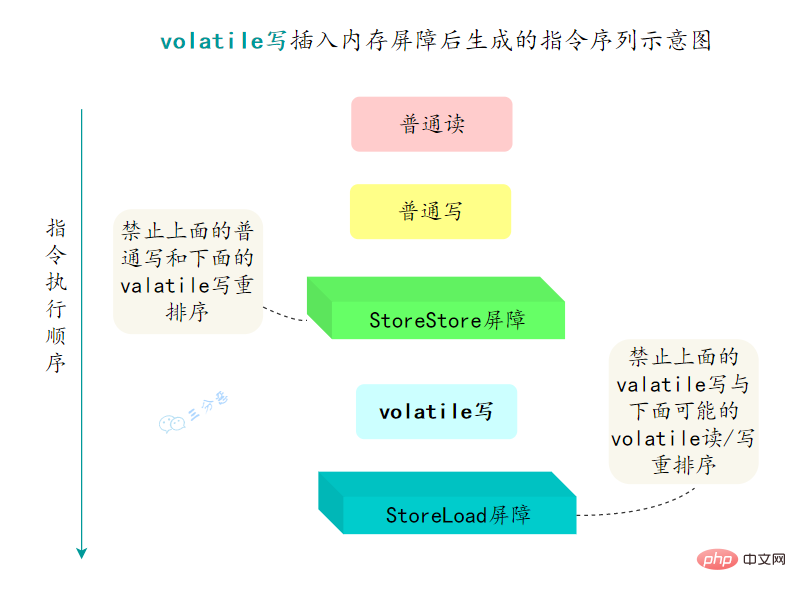
重排序可以分為編譯器重排序和處理器重排序,valatile保證有序性,就是通過分別限制這兩種型別的重排序。
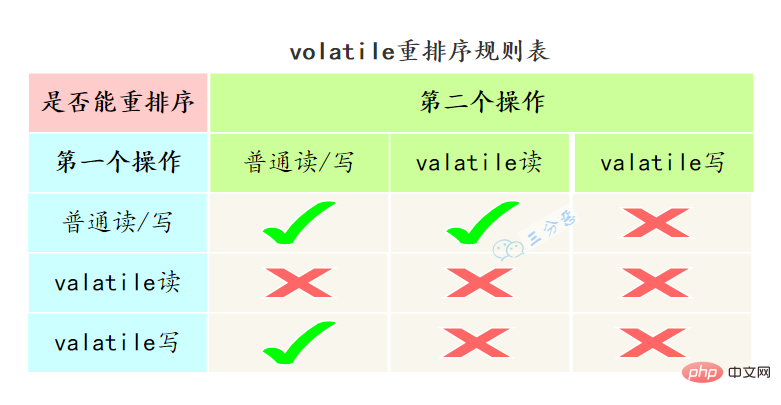
為了實現volatile的記憶體語意,編譯器在生成位元組碼時,會在指令序列中插入記憶體屏障來禁止特定型別的處理器重排序。
- 在每個volatile寫操作的前面插入一個
StoreStore屏障 - 在每個volatile寫操作的後面插入一個
StoreLoad屏障 - 在每個volatile讀操作的後面插入一個
LoadLoad屏障 - 在每個volatile讀操作的後面插入一個
LoadStore屏障
24.synchronized用過嗎?怎麼使用?
synchronized經常用的,用來保證程式碼的原子性。
synchronized主要有三種用法:
- 修飾實體方法: 作用於當前物件範例加鎖,進入同步程式碼前要獲得 當前物件範例的鎖
synchronized void method() {
//業務程式碼}修飾靜態方法:也就是給當前類加鎖,會作⽤於類的所有物件範例 ,進⼊同步程式碼前要獲得當前 class 的鎖。因為靜態成員不屬於任何⼀個範例物件,是類成員( static 表明這是該類的⼀個靜態資源,不管 new 了多少個物件,只有⼀份)。
如果⼀個執行緒 A 調⽤⼀個範例物件的⾮靜態 synchronized ⽅法,⽽執行緒 B 需要調⽤這個範例物件所屬類的靜態 synchronized ⽅法,是允許的,不會發⽣互斥現象,因為存取靜態 synchronized ⽅法佔⽤的鎖是當前類的鎖,⽽存取⾮靜態 synchronized ⽅法佔⽤的鎖是當前範例物件鎖。
synchronized void staic method() {
//業務程式碼}- 修飾程式碼塊 :指定加鎖物件,對給定物件/類加鎖。 synchronized(this|object) 表示進⼊同步程式碼庫前要獲得給定物件的鎖。 synchronized(類.class) 表示進⼊同步程式碼前要獲得 當前 class 的鎖
synchronized(this) {
//業務程式碼}25.synchronized的實現原理?
synchronized是怎麼加鎖的呢?
我們使用synchronized的時候,發現不用自己去lock和unlock,是因為JVM幫我們把這個事情做了。
synchronized修飾程式碼塊時,JVM採用
monitorenter、monitorexit兩個指令來實現同步,monitorenter指令指向同步程式碼塊的開始位置,monitorexit指令則指向同步程式碼塊的結束位置。反編譯一段synchronized修飾程式碼塊程式碼,
javap -c -s -v -l SynchronizedDemo.class,可以看到相應的位元組碼指令。

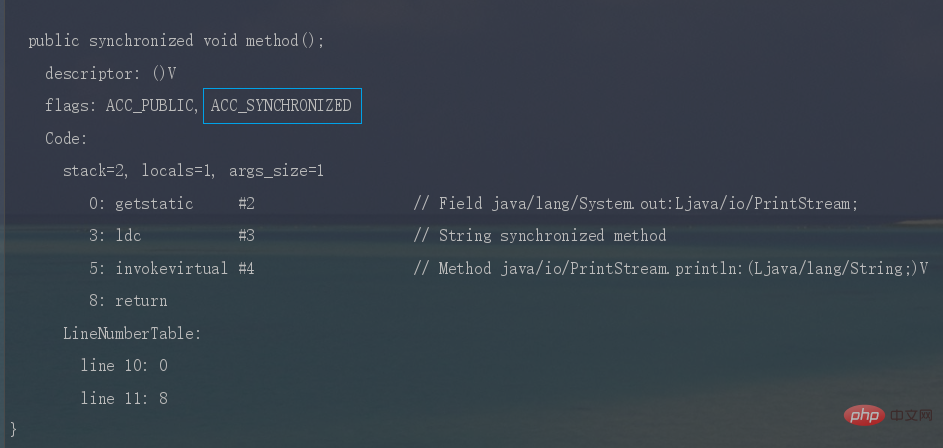
synchronized修飾同步方法時,JVM採用
ACC_SYNCHRONIZED標記符來實現同步,這個標識指明瞭該方法是一個同步方法。同樣可以寫段程式碼反編譯看一下。
synchronized鎖住的是什麼呢?
monitorenter、monitorexit或者ACC_SYNCHRONIZED都是基於Monitor實現的。
範例物件結構裡有物件頭,物件頭裡面有一塊結構叫Mark Word,Mark Word指標指向了monitor。
所謂的Monitor其實是一種同步工具,也可以說是一種同步機制。在Java虛擬機器器(HotSpot)中,Monitor是由ObjectMonitor實現的,可以叫做內部鎖,或者Monitor鎖。
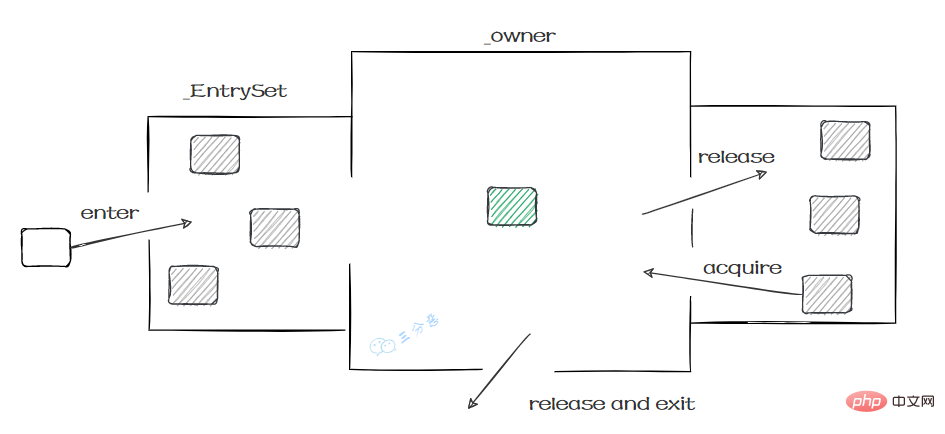
ObjectMonitor的工作原理:
- ObjectMonitor有兩個佇列:_WaitSet、_EntryList,用來儲存ObjectWaiter 物件列表。
- _owner,獲取 Monitor 物件的執行緒進入 _owner 區時, _count + 1。如果執行緒呼叫了 wait() 方法,此時會釋放 Monitor 物件, _owner 恢復為空, _count - 1。同時該等待執行緒進入 _WaitSet 中,等待被喚醒。
ObjectMonitor() {
_header = NULL;
_count = 0; // 記錄執行緒獲取鎖的次數
_waiters = 0,
_recursions = 0; //鎖的重入次數
_object = NULL;
_owner = NULL; // 指向持有ObjectMonitor物件的執行緒
_WaitSet = NULL; // 處於wait狀態的執行緒,會被加入到_WaitSet
_WaitSetLock = 0 ;
_Responsible = NULL ;
_succ = NULL ;
_cxq = NULL ;
FreeNext = NULL ;
_EntryList = NULL ; // 處於等待鎖block狀態的執行緒,會被加入到該列表
_SpinFreq = 0 ;
_SpinClock = 0 ;
OwnerIsThread = 0 ;
}可以類比一個去醫院就診的例子[18]:
首先,患者在門診大廳前臺或自助掛號機進行掛號;
隨後,掛號結束後患者找到對應的診室就診:
- 診室每次只能有一個患者就診;
- 如果此時診室空閒,直接進入就診;
- 如果此時診室內有其它患者就診,那麼當前患者進入候診室,等待叫號;
就診結束後,走出就診室,候診室的下一位候診患者進入就診室。
![就診-圖片來源參考[18]](https://s3.ap-northeast-1.wasabisys.com/img.tw511.com/202203/92c6a0f084147b389658bdf8cacd7a4e-31bfu0q4khhrt.png)
這個過程就和Monitor機制比較相似:
- 門診大廳:所有待進入的執行緒都必須先在入口Entry Set掛號才有資格;
- 就診室:就診室**_Owner**裡裡只能有一個執行緒就診,就診完執行緒就自行離開
- 候診室:就診室繁忙時,進入等待區(Wait Set),就診室空閒的時候就從**等待區(Wait Set)**叫新的執行緒
所以我們就知道了,同步是鎖住的什麼東西:
- monitorenter,在判斷擁有同步標識 ACC_SYNCHRONIZED 搶先進入此方法的執行緒會優先擁有 Monitor 的 owner ,此時計數器 +1。
- monitorexit,當執行完退出後,計數器 -1,歸 0 後被其他進入的執行緒獲得。
26.除了原子性,synchronized可見性,有序性,可重入性怎麼實現?
synchronized怎麼保證可見性?
- 執行緒加鎖前,將清空工作記憶體中共用變數的值,從而使用共用變數時需要從主記憶體中重新讀取最新的值。
- 執行緒加鎖後,其它執行緒無法獲取主記憶體中的共用變數。
- 執行緒解鎖前,必須把共用變數的最新值重新整理到主記憶體中。
synchronized怎麼保證有序性?
synchronized同步的程式碼塊,具有排他性,一次只能被一個執行緒擁有,所以synchronized保證同一時刻,程式碼是單執行緒執行的。
因為as-if-serial語意的存在,單執行緒的程式能保證最終結果是有序的,但是不保證不會指令重排。
所以synchronized保證的有序是執行結果的有序性,而不是防止指令重排的有序性。
synchronized怎麼實現可重入的呢?
synchronized 是可重入鎖,也就是說,允許一個執行緒二次請求自己持有物件鎖的臨界資源,這種情況稱為可重入鎖。
synchronized 鎖物件的時候有個計數器,他會記錄下執行緒獲取鎖的次數,在執行完對應的程式碼塊之後,計數器就會-1,直到計數器清零,就釋放鎖了。
之所以,是可重入的。是因為 synchronized 鎖物件有個計數器,會隨著執行緒獲取鎖後 +1 計數,當執行緒執行完畢後 -1,直到清零釋放鎖。
27.鎖升級?synchronized優化了解嗎?
瞭解鎖升級,得先知道,不同鎖的狀態是什麼樣的。這個狀態指的是什麼呢?
Java物件頭裡,有一塊結構,叫Mark Word標記欄位,這塊結構會隨著鎖的狀態變化而變化。
64 位虛擬機器器 Mark Word 是 64bit,我們來看看它的狀態變化:
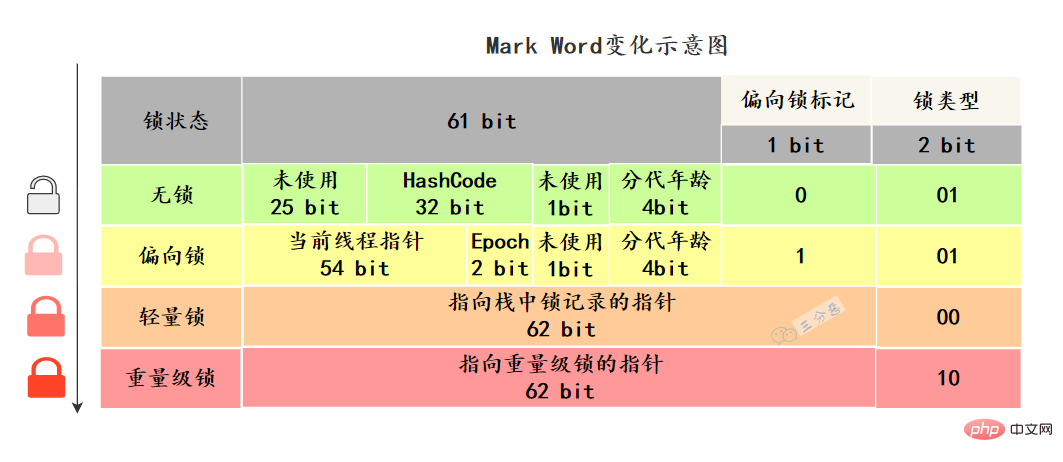
Mark Word儲存物件自身的執行資料,如雜湊碼、GC分代年齡、鎖狀態標誌、偏向時間戳(Epoch) 等。
synchronized做了哪些優化?
在JDK1.6之前,synchronized的實現直接呼叫ObjectMonitor的enter和exit,這種鎖被稱之為重量級鎖。從JDK6開始,HotSpot虛擬機器器開發團隊對Java中的鎖進行優化,如增加了適應性自旋、鎖消除、鎖粗化、輕量級鎖和偏向鎖等優化策略,提升了synchronized的效能。
偏向鎖:在無競爭的情況下,只是在Mark Word裡儲存當前執行緒指標,CAS操作都不做。
輕量級鎖:在沒有多執行緒競爭時,相對重量級鎖,減少作業系統互斥量帶來的效能消耗。但是,如果存在鎖競爭,除了互斥量本身開銷,還額外有CAS操作的開銷。
自旋鎖:減少不必要的CPU上下文切換。在輕量級鎖升級為重量級鎖時,就使用了自旋加鎖的方式
鎖粗化:將多個連續的加鎖、解鎖操作連線在一起,擴充套件成一個範圍更大的鎖。
鎖消除:虛擬機器器即時編譯器在執行時,對一些程式碼上要求同步,但是被檢測到不可能存在共用資料競爭的鎖進行消除。
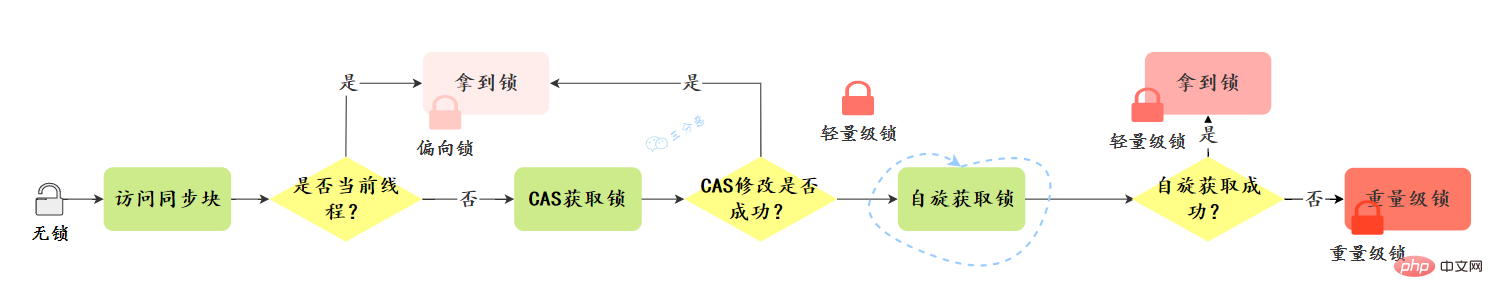
鎖升級的過程是什麼樣的?
鎖升級方向:無鎖–>偏向鎖—> 輕量級鎖---->重量級鎖,這個方向基本上是不可逆的。

我們看一下升級的過程:
偏向鎖:
偏向鎖的獲取:
- 判斷是否為可偏向狀態–MarkWord中鎖標誌是否為‘01’,是否偏向鎖是否為‘1’
- 如果是可偏向狀態,則檢視執行緒ID是否為當前執行緒,如果是,則進入步驟’5’,否則進入步驟‘3’
- 通過CAS操作競爭鎖,如果競爭成功,則將MarkWord中執行緒ID設定為當前執行緒ID,然後執行‘5’;競爭失敗,則執行‘4’
- CAS獲取偏向鎖失敗表示有競爭。當達到safepoint時獲得偏向鎖的執行緒被掛起,偏向鎖升級為輕量級鎖,然後被阻塞在安全點的執行緒繼續往下執行同步程式碼塊
- 執行同步程式碼
偏向鎖的復原:
- 偏向鎖不會主動釋放(復原),只有遇到其他執行緒競爭時才會執行復原,由於復原需要知道當前持有該偏向鎖的執行緒棧狀態,因此要等到safepoint時執行,此時持有該偏向鎖的執行緒(T)有‘2’,‘3’兩種情況;
- 復原----T執行緒已經退出同步程式碼塊,或者已經不再存活,則直接復原偏向鎖,變成無鎖狀態----該狀態達到閾值20則執行批次重偏向
- 升級----T執行緒還在同步程式碼塊中,則將T執行緒的偏向鎖升級為輕量級鎖,當前執行緒執行輕量級鎖狀態下的鎖獲取步驟----該狀態達到閾值40則執行批次復原
輕量級鎖:
輕量級鎖的獲取:
- 進行加鎖操作時,jvm會判斷是否已經時重量級鎖,如果不是,則會在當前執行緒棧幀中劃出一塊空間,作為該鎖的鎖記錄,並且將鎖物件MarkWord複製到該鎖記錄中
- 複製成功之後,jvm使用CAS操作將物件頭MarkWord更新為指向鎖記錄的指標,並將鎖記錄裡的owner指標指向物件頭的MarkWord。如果成功,則執行‘3’,否則執行‘4’
- 更新成功,則當前執行緒持有該物件鎖,並且物件MarkWord鎖標誌設定為‘00’,即表示此物件處於輕量級鎖狀態
- 更新失敗,jvm先檢查物件MarkWord是否指向當前執行緒棧幀中的鎖記錄,如果是則執行‘5’,否則執行‘4’
- 表示鎖重入;然後當前執行緒棧幀中增加一個鎖記錄第一部分(Displaced Mark Word)為null,並指向Mark Word的鎖物件,起到一個重入計數器的作用。
- 表示該鎖物件已經被其他執行緒搶佔,則進行自旋等待(預設10次),等待次數達到閾值仍未獲取到鎖,則升級為重量級鎖
大體上省簡的升級過程:
完整的升級過程:
![synchronized 鎖升級過程-來源參考[14]](https://s3.ap-northeast-1.wasabisys.com/img.tw511.com/202203/2ef068e2d2216314dc9ad545dda17019-365csrcjryjpe.png)
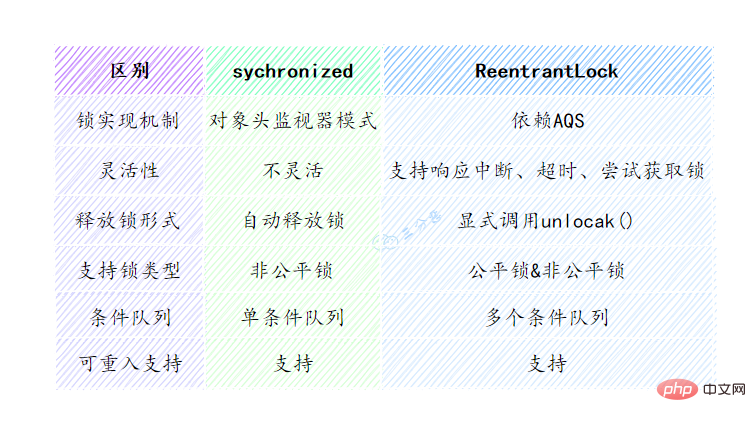
28.說說synchronized和ReentrantLock的區別?
可以從鎖的實現、功能特點、效能等幾個維度去回答這個問題:
- 鎖的實現: synchronized是Java語言的關鍵字,基於JVM實現。而ReentrantLock是基於JDK的API層面實現的(一般是lock()和unlock()方法配合try/finally 語句塊來完成。)
- 效能: 在JDK1.6鎖優化以前,synchronized的效能比ReenTrantLock差很多。但是JDK6開始,增加了適應性自旋、鎖消除等,兩者效能就差不多了。
- 功能特點: ReentrantLock 比 synchronized 增加了一些高階功能,如等待可中斷、可實現公平鎖、可實現選擇性通知。
- ReentrantLock提供了一種能夠中斷等待鎖的執行緒的機制,通過lock.lockInterruptibly()來實現這個機制
- ReentrantLock可以指定是公平鎖還是非公平鎖。而synchronized只能是非公平鎖。所謂的公平鎖就是先等待的執行緒先獲得鎖。
- synchronized與wait()和notify()/notifyAll()方法結合實現等待/通知機制,ReentrantLock類藉助Condition介面與newCondition()方法實現。
- ReentrantLock需要手工宣告來加鎖和釋放鎖,一般跟finally配合釋放鎖。而synchronized不用手動釋放鎖。
下面的表格列出出了兩種鎖之間的區別:
29.AQS瞭解多少?
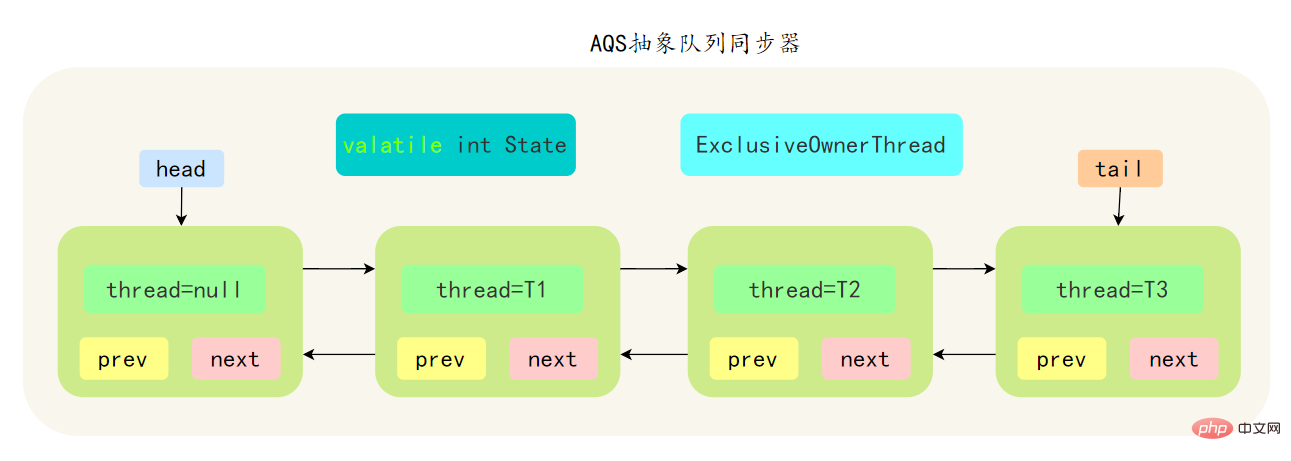
AbstractQueuedSynchronizer 抽象同步佇列,簡稱 AQS ,它是Java並行包的根基,並行包中的鎖就是基於AQS實現的。
- AQS是基於一個FIFO的雙向佇列,其內部定義了一個節點類Node,Node 節點內部的 SHARED 用來標記該執行緒是獲取共用資源時被阻掛起後放入AQS 佇列的, EXCLUSIVE 用來標記執行緒是 取獨佔資源時被掛起後放入AQS 佇列
- AQS 使用一個 volatile 修飾的 int 型別的成員變數 state 來表示同步狀態,修改同步狀態成功即為獲得鎖,volatile 保證了變數在多執行緒之間的可見性,修改 State 值時通過 CAS 機制來保證修改的原子性
- 獲取state的方式分為兩種,獨佔方式和共用方式,一個執行緒使用獨佔方式獲取了資源,其它執行緒就會在獲取失敗後被阻塞。一個執行緒使用共用方式獲取了資源,另外一個執行緒還可以通過CAS的方式進行獲取。
- 如果共用資源被佔用,需要一定的阻塞等待喚醒機制來保證鎖的分配,AQS 中會將競爭共用資源失敗的執行緒新增到一個變體的 CLH 佇列中。
 先簡單瞭解一下CLH:Craig、Landin and Hagersten 佇列,是 單向連結串列實現的佇列。申請執行緒只在本地變數上自旋,它不斷輪詢前驅的狀態,如果發現 前驅節點釋放了鎖就結束自旋
先簡單瞭解一下CLH:Craig、Landin and Hagersten 佇列,是 單向連結串列實現的佇列。申請執行緒只在本地變數上自旋,它不斷輪詢前驅的狀態,如果發現 前驅節點釋放了鎖就結束自旋
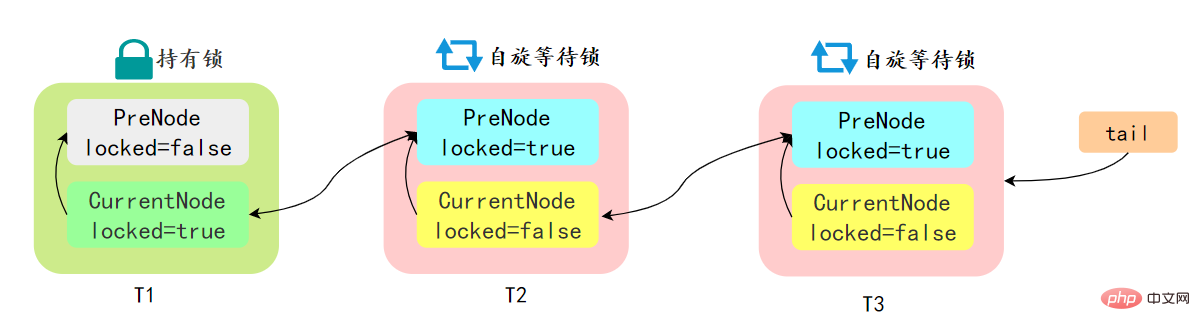
AQS 中的佇列是 CLH 變體的虛擬雙向佇列,通過將每條請求共用資源的執行緒封裝成一個節點來實現鎖的分配:
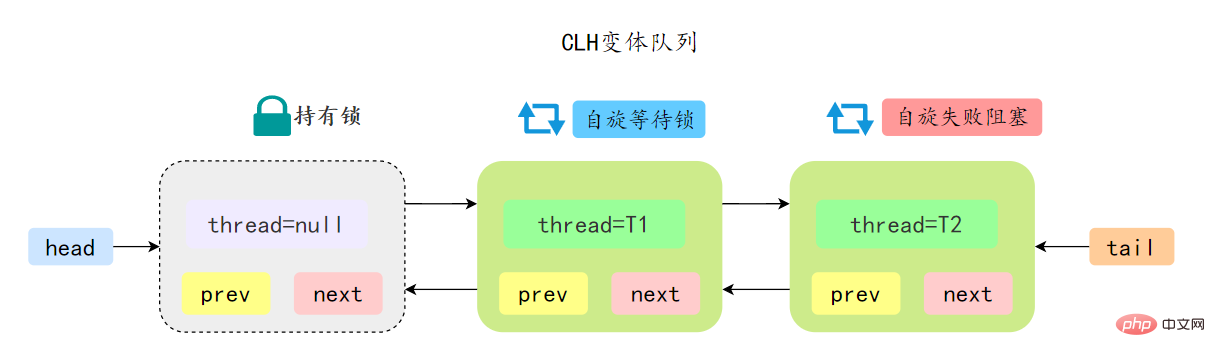
AQS 中的 CLH 變體等待佇列擁有以下特性:
- AQS 中佇列是個雙向連結串列,也是 FIFO 先進先出的特性
- 通過 Head、Tail 頭尾兩個節點來組成佇列結構,通過 volatile 修飾保證可見性
- Head 指向節點為已獲得鎖的節點,是一個虛擬節點,節點本身不持有具體執行緒
- 獲取不到同步狀態,會將節點進行自旋獲取鎖,自旋一定次數失敗後會將執行緒阻塞,相對於 CLH 佇列效能較好
ps:AQS原始碼裡面有很多細節可問,建議有時間好好看看AQS原始碼。
30.ReentrantLock實現原理?
ReentrantLock 是可重入的獨佔鎖,只能有一個執行緒可以獲取該鎖,其它獲取該鎖的執行緒會被阻塞而被放入該鎖的阻塞佇列裡面。
看看ReentrantLock的加鎖操作:
// 建立非公平鎖
ReentrantLock lock = new ReentrantLock();
// 獲取鎖操作
lock.lock();
try {
// 執行程式碼邏輯
} catch (Exception ex) {
// ...
} finally {
// 解鎖操作
lock.unlock();
}new ReentrantLock()建構函式預設建立的是非公平鎖 NonfairSync。
公平鎖 FairSync
- 公平鎖是指多個執行緒按照申請鎖的順序來獲取鎖,執行緒直接進入佇列中排隊,佇列中的第一個執行緒才能獲得鎖
- 公平鎖的優點是等待鎖的執行緒不會餓死。缺點是整體吞吐效率相對非公平鎖要低,等待佇列中除第一個執行緒以外的所有執行緒都會阻塞,CPU 喚醒阻塞執行緒的開銷比非公平鎖大
非公平鎖 NonfairSync
- 非公平鎖是多個執行緒加鎖時直接嘗試獲取鎖,獲取不到才會到等待佇列的隊尾等待。但如果此時鎖剛好可用,那麼這個執行緒可以無需阻塞直接獲取到鎖
- 非公平鎖的優點是可以減少喚起執行緒的開銷,整體的吞吐效率高,因為執行緒有機率不阻塞直接獲得鎖,CPU 不必喚醒所有執行緒。缺點是處於等待佇列中的執行緒可能會餓死,或者等很久才會獲得鎖
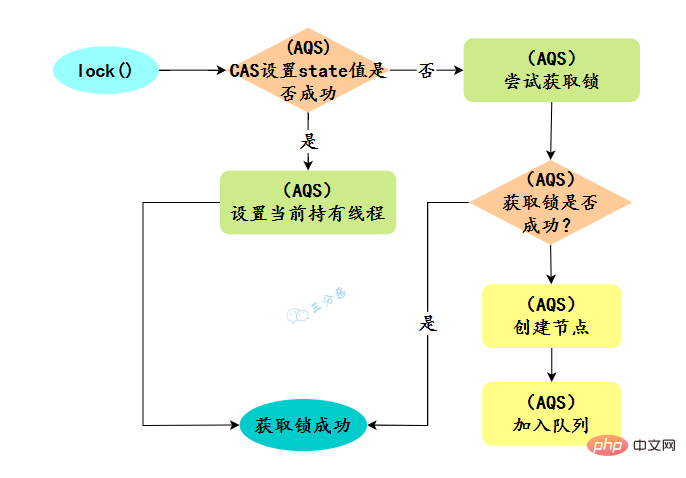
預設建立的物件lock()的時候:
- 如果鎖當前沒有被其它執行緒佔用,並且當前執行緒之前沒有獲取過該鎖,則當前執行緒會獲取到該鎖,然後設定當前鎖的擁有者為當前執行緒,並設定 AQS 的狀態值為1 ,然後直接返回。如果當前執行緒之前己經獲取過該鎖,則這次只是簡單地把 AQS 的狀態值加1後返回。
- 如果該鎖己經被其他執行緒持有,非公平鎖會嘗試去獲取鎖,獲取失敗的話,則呼叫該方法執行緒會被放入 AQS 佇列阻塞掛起。
31.ReentrantLock怎麼實現公平鎖的?
new ReentrantLock()建構函式預設建立的是非公平鎖 NonfairSync
public ReentrantLock() {
sync = new NonfairSync();}同時也可以在建立鎖建構函式中傳入具體引數建立公平鎖 FairSync
ReentrantLock lock = new ReentrantLock(true);--- ReentrantLock// true 代表公平鎖,false 代表非公平鎖public ReentrantLock(boolean fair) {
sync = fair ? new FairSync() : new NonfairSync();}FairSync、NonfairSync 代表公平鎖和非公平鎖,兩者都是 ReentrantLock 靜態內部類,只不過實現不同鎖語意。
非公平鎖和公平鎖的兩處不同:
- 非公平鎖在呼叫 lock 後,首先就會呼叫 CAS 進行一次搶鎖,如果這個時候恰巧鎖沒有被佔用,那麼直接就獲取到鎖返回了。
- 非公平鎖在 CAS 失敗後,和公平鎖一樣都會進入到 tryAcquire 方法,在 tryAcquire 方法中,如果發現鎖這個時候被釋放了(state == 0),非公平鎖會直接 CAS 搶鎖,但是公平鎖會判斷等待佇列是否有執行緒處於等待狀態,如果有則不去搶鎖,乖乖排到後面。
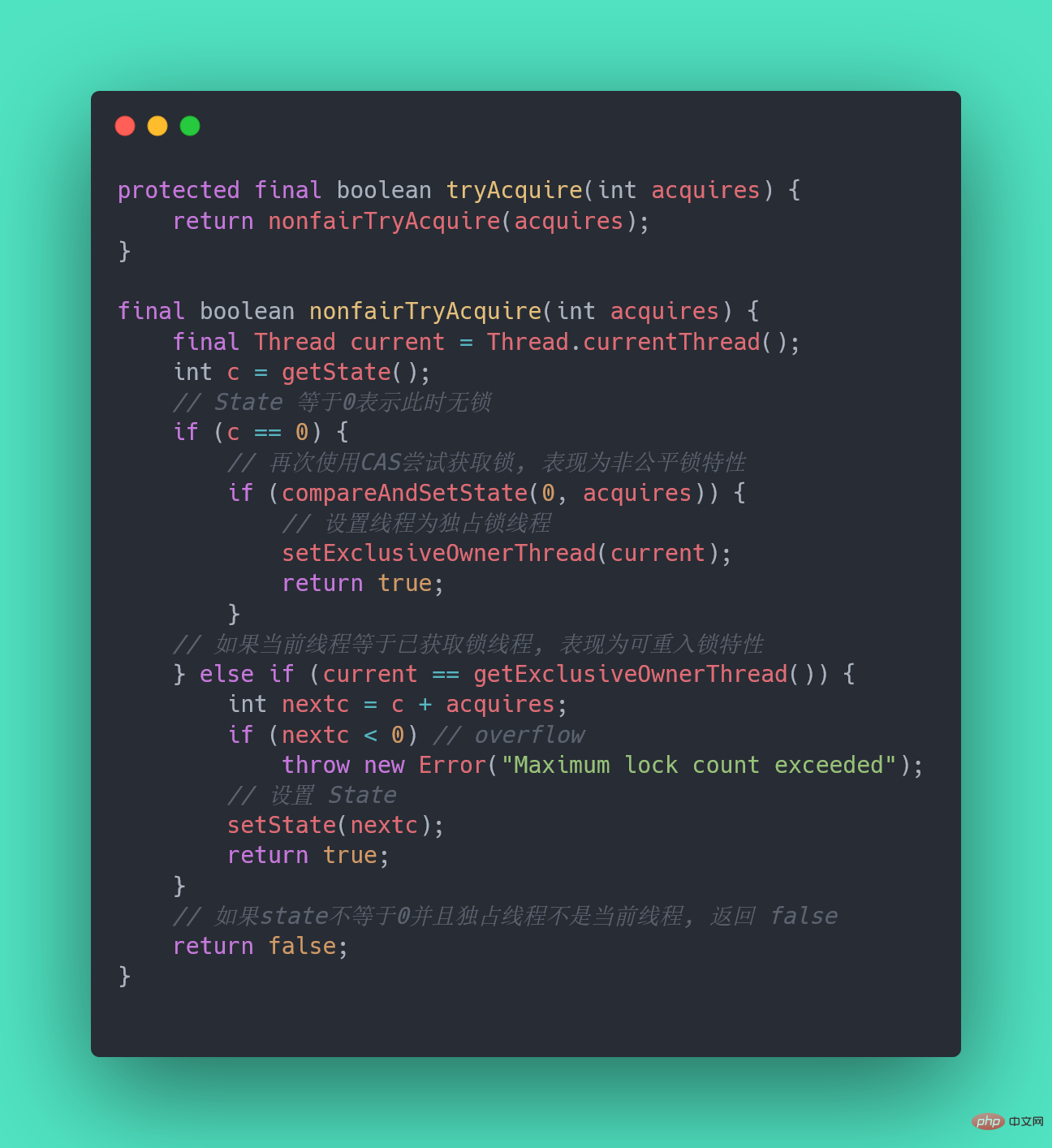
相對來說,非公平鎖會有更好的效能,因為它的吞吐量比較大。當然,非公平鎖讓獲取鎖的時間變得更加不確定,可能會導致在阻塞佇列中的執行緒長期處於飢餓狀態。
32.CAS呢?CAS瞭解多少?
CAS叫做CompareAndSwap,⽐較並交換,主要是通過處理器的指令來保證操作的原⼦性的。
CAS 指令包含 3 個引數:共用變數的記憶體地址 A、預期的值 B 和共用變數的新值 C。
只有當記憶體中地址 A 處的值等於 B 時,才能將記憶體中地址 A 處的值更新為新值 C。作為一條 CPU 指令,CAS 指令本身是能夠保證原子性的 。
33.CAS 有什麼問題?如何解決?
CAS的經典三大問題:
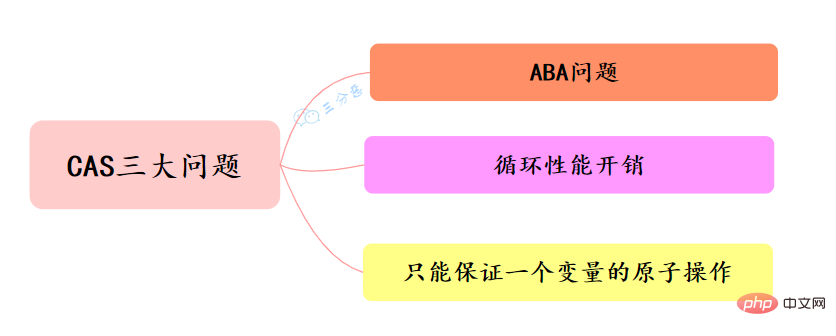
ABA 問題
並行環境下,假設初始條件是A,去修改資料時,發現是A就會執行修改。但是看到的雖然是A,中間可能發生了A變B,B又變回A的情況。此時A已經非彼A,資料即使成功修改,也可能有問題。
怎麼解決ABA問題?
- 加版本號
每次修改變數,都在這個變數的版本號上加1,這樣,剛剛A->B->A,雖然A的值沒變,但是它的版本號已經變了,再判斷版本號就會發現此時的A已經被改過了。參考樂觀鎖的版本號,這種做法可以給資料帶上了一種實效性的檢驗。
Java提供了AtomicStampReference類,它的compareAndSet方法首先檢查當前的物件參照值是否等於預期參照,並且當前印戳(Stamp)標誌是否等於預期標誌,如果全部相等,則以原子方式將參照值和印戳標誌的值更新為給定的更新值。
迴圈效能開銷
自旋CAS,如果一直迴圈執行,一直不成功,會給CPU帶來非常大的執行開銷。
怎麼解決迴圈效能開銷問題?
在Java中,很多使用自旋CAS的地方,會有一個自旋次數的限制,超過一定次數,就停止自旋。
只能保證一個變數的原子操作
CAS 保證的是對一個變數執行操作的原子性,如果對多個變數操作時,CAS 目前無法直接保證操作的原子性的。
怎麼解決只能保證一個變數的原子操作問題?
- 可以考慮改用鎖來保證操作的原子性
- 可以考慮合併多個變數,將多個變數封裝成一個物件,通過AtomicReference來保證原子性。
34.Java有哪些保證原子性的方法?如何保證多執行緒下i++ 結果正確?
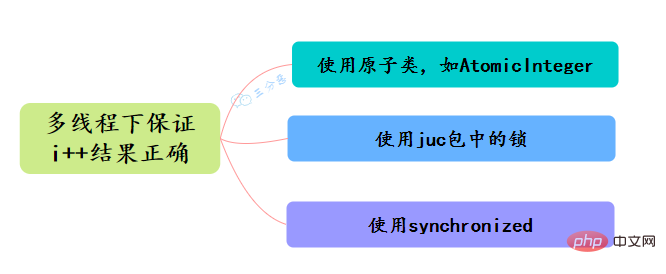
- 使用迴圈原子類,例如AtomicInteger,實現i++原子操作
- 使用juc包下的鎖,如ReentrantLock ,對i++操作加鎖lock.lock()來實現原子性
- 使用synchronized,對i++操作加鎖
35.原子操作類瞭解多少?
當程式更新一個變數時,如果多執行緒同時更新這個變數,可能得到期望之外的值,比如變數i=1,A執行緒更新i+1,B執行緒也更新i+1,經過兩個執行緒操作之後可能i不等於3,而是等於2。因為A和B執行緒在更新變數i的時候拿到的i都是1,這就是執行緒不安全的更新操作,一般我們會使用synchronized來解決這個問題,synchronized會保證多執行緒不會同時更新變數i。
其實除此之外,還有更輕量級的選擇,Java從JDK 1.5開始提供了java.util.concurrent.atomic包,這個包中的原子操作類提供了一種用法簡單、效能高效、執行緒安全地更新一個變數的方式。
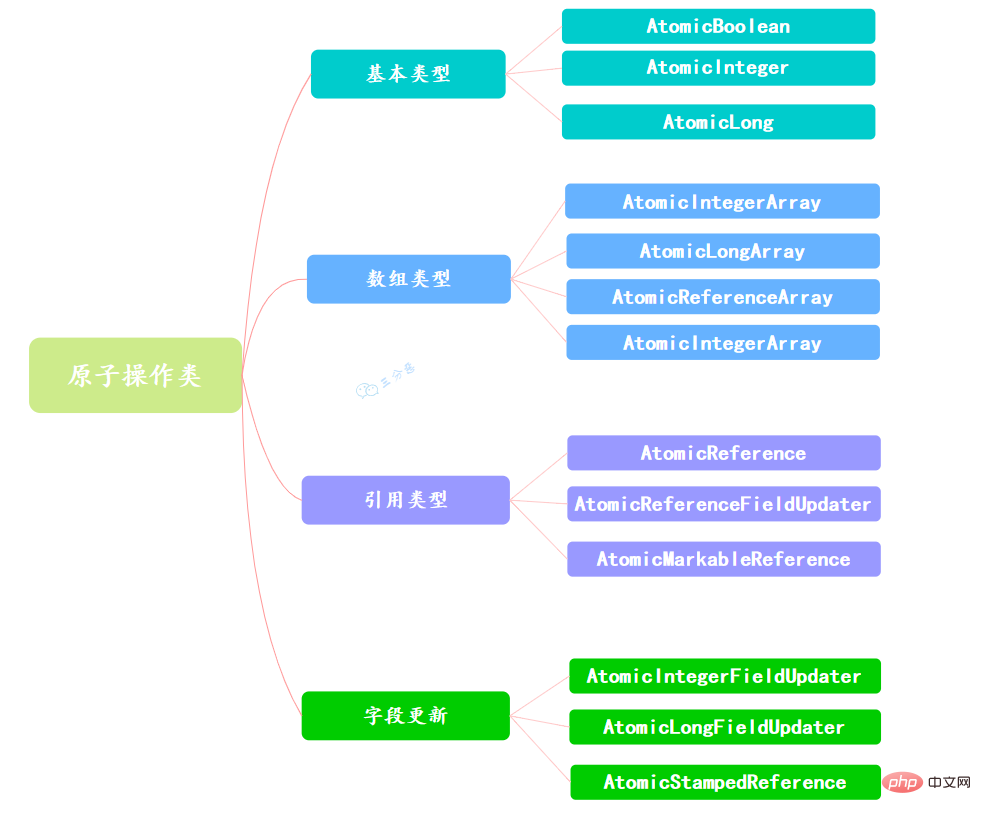
因為變數的型別有很多種,所以在Atomic包裡一共提供了13個類,屬於4種型別的原子更新方式,分別是原子更新基本型別、原子更新陣列、原子更新參照和原子更新屬性(欄位)。
Atomic包裡的類基本都是使用Unsafe實現的包裝類。
使用原子的方式更新基本型別,Atomic包提供了以下3個類:
AtomicBoolean:原子更新布林型別。
AtomicInteger:原子更新整型。
AtomicLong:原子更新長整型。
通過原子的方式更新陣列裡的某個元素,Atomic包提供了以下4個類:
AtomicIntegerArray:原子更新整型陣列裡的元素。
AtomicLongArray:原子更新長整型陣列裡的元素。
AtomicReferenceArray:原子更新參照型別陣列裡的元素。
AtomicIntegerArray類主要是提供原子的方式更新陣列裡的整型
原子更新基本型別的AtomicInteger,只能更新一個變數,如果要原子更新多個變數,就需要使用這個原子更新參照型別提供的類。Atomic包提供了以下3個類:
AtomicReference:原子更新參照型別。
AtomicReferenceFieldUpdater:原子更新參照型別裡的欄位。
AtomicMarkableReference:原子更新帶有標記位的參照型別。可以原子更新一個布林型別的標記位和參照型別。構造方法是AtomicMarkableReference(V initialRef,boolean initialMark)。
如果需原子地更新某個類裡的某個欄位時,就需要使用原子更新欄位類,Atomic包提供了以下3個類進行原子欄位更新:
- AtomicIntegerFieldUpdater:原子更新整型的欄位的更新器。
- AtomicLongFieldUpdater:原子更新長整型欄位的更新器。
- AtomicStampedReference:原子更新帶有版本號的參照型別。該類將整數值與參照關聯起來,可用於原子的更新資料和資料的版本號,可以解決使用CAS進行原子更新時可能出現的 ABA問題。
36.AtomicInteger 的原理?
一句話概括:使用CAS實現。
以AtomicInteger的新增方法為例:
public final int getAndIncrement() {
return unsafe.getAndAddInt(this, valueOffset, 1);
}通過Unsafe類的範例來進行新增操作,來看看具體的CAS操作:
public final int getAndAddInt(Object var1, long var2, int var4) {
int var5;
do {
var5 = this.getIntVolatile(var1, var2);
} while(!this.compareAndSwapInt(var1, var2, var5, var5 + var4));
return var5;
}compareAndSwapInt 是一個native方法,基於CAS來操作int型別變數。其它的原子操作類基本都是大同小異。
37.執行緒死鎖瞭解嗎?該如何避免?
死鎖是指兩個或兩個以上的執行緒在執行過程中,因爭奪資源而造成的互相等待的現象,在無外力作用的情況下,這些執行緒會一直相互等待而無法繼續執行下去。
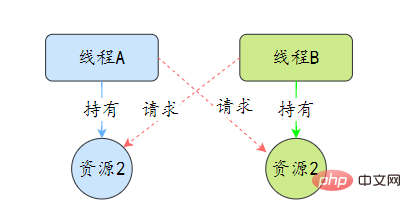
那麼為什麼會產生死鎖呢? 死鎖的產生必須具備以下四個條件:
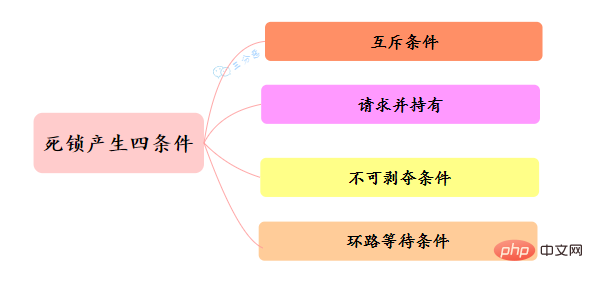
- 互斥條件:指執行緒對己經獲取到的資源進行它性使用,即該資源同時只由一個執行緒佔用。如果此時還有其它執行緒請求獲取獲取該資源,則請求者只能等待,直至佔有資源的執行緒釋放該資源。
- 請求並持有條件:指一個 執行緒己經持有了至少一個資源,但又提出了新的資源請求,而新資源己被其它執行緒佔有,所以當前執行緒會被阻塞,但阻塞 的同時並不釋放自己已經獲取的資源。
- 不可剝奪條件:指執行緒獲取到的資源在自己使用完之前不能被其它執行緒搶佔,只有在自己使用完畢後才由自己釋放該資源。
- 環路等待條件:指在發生死鎖時,必然存在一個執行緒——資源的環形鏈,即執行緒集合 {T0,T1,T2,…… ,Tn} 中 T0 正在等待一 T1 佔用的資源,Tl1正在等待 T2用的資源,…… Tn 在等待己被 T0佔用的資源。
該如何避免死鎖呢?答案是至少破壞死鎖發生的一個條件。
其中,互斥這個條件我們沒有辦法破壞,因為用鎖為的就是互斥。不過其他三個條件都是有辦法破壞掉的,到底如何做呢?
對於「請求並持有」這個條件,可以一次性請求所有的資源。
對於「不可剝奪」這個條件,佔用部分資源的執行緒進一步申請其他資源時,如果申請不到,可以主動釋放它佔有的資源,這樣不可搶佔這個條件就破壞掉了。
對於「環路等待」這個條件,可以靠按序申請資源來預防。所謂按序申請,是指資源是有線性順序的,申請的時候可以先申請資源序號小的,再申請資源序號大的,這樣線性化後就不存在環路了。
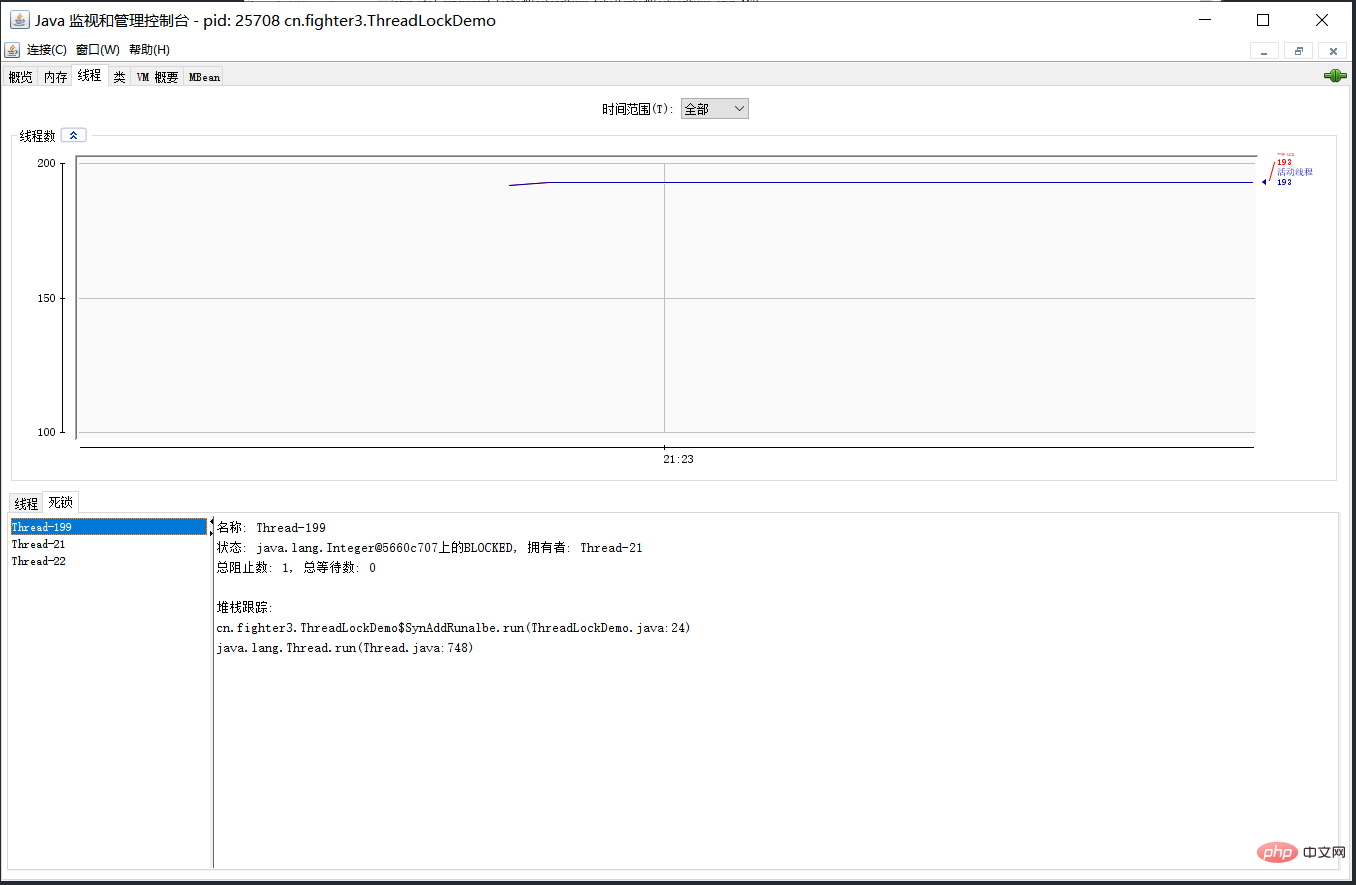
38.那死鎖問題怎麼排查呢?
可以使用jdk自帶的命令列工具排查:
- 使用jps查詢執行的Java程序:jps -l
- 使用jstack檢視執行緒堆疊資訊:jstack -l 程序id
基本就可以看到死鎖的資訊。
還可以利用圖形化工具,比如JConsole。出現執行緒死鎖以後,點選JConsole執行緒面板的檢測到死鎖按鈕,將會看到執行緒的死鎖資訊。
39.CountDownLatch(倒計數器)瞭解嗎?
CountDownLatch,倒計數器,有兩個常見的應用場景[18]:
場景1:協調子執行緒結束動作:等待所有子執行緒執行結束
CountDownLatch允許一個或多個執行緒等待其他執行緒完成操作。
例如,我們很多人喜歡玩的王者榮耀,開黑的時候,得等所有人都上線之後,才能開打。
![王者榮耀等待玩家確認-來源參考[18]](https://s3.ap-northeast-1.wasabisys.com/img.tw511.com/202203/e6d0fa993edec812cec62a596151c219-49d4qjxodnwbz.png)
CountDownLatch模仿這個場景(參考[18]):
建立大喬、蘭陵王、安其拉、哪吒和鎧等五個玩家,主執行緒必須在他們都完成確認後,才可以繼續執行。
在這段程式碼中,new CountDownLatch(5)使用者建立初始的latch數量,各玩家通過countDownLatch.countDown()完成狀態確認,主執行緒通過countDownLatch.await()等待。
public static void main(String[] args) throws InterruptedException {
CountDownLatch countDownLatch = new CountDownLatch(5);
Thread 大喬 = new Thread(countDownLatch::countDown);
Thread 蘭陵王 = new Thread(countDownLatch::countDown);
Thread 安其拉 = new Thread(countDownLatch::countDown);
Thread 哪吒 = new Thread(countDownLatch::countDown);
Thread 鎧 = new Thread(() -> {
try {
// 稍等,上個衛生間,馬上到...
Thread.sleep(1500);
countDownLatch.countDown();
} catch (InterruptedException ignored) {}
});
大喬.start();
蘭陵王.start();
安其拉.start();
哪吒.start();
鎧.start();
countDownLatch.await();
System.out.println("所有玩家已經就位!");
}場景2. 協調子執行緒開始動作:統一各執行緒動作開始的時機
王者遊戲中也有類似的場景,遊戲開始時,各玩家的初始狀態必須一致。不能有的玩家都出完裝了,有的才降生。
所以大家得一塊出生,在
![王者榮耀-來源參考[18]](https://s3.ap-northeast-1.wasabisys.com/img.tw511.com/202203/e4c766e2207c7e595356f530af8ccbe9-50co5aiupuscr.png)
在這個場景中,仍然用五個執行緒代表大喬、蘭陵王、安其拉、哪吒和鎧等五個玩家。需要注意的是,各玩家雖然都呼叫了start()執行緒,但是它們在執行時都在等待countDownLatch的訊號,在訊號未收到前,它們不會往下執行。
public static void main(String[] args) throws InterruptedException {
CountDownLatch countDownLatch = new CountDownLatch(1);
Thread 大喬 = new Thread(() -> waitToFight(countDownLatch));
Thread 蘭陵王 = new Thread(() -> waitToFight(countDownLatch));
Thread 安其拉 = new Thread(() -> waitToFight(countDownLatch));
Thread 哪吒 = new Thread(() -> waitToFight(countDownLatch));
Thread 鎧 = new Thread(() -> waitToFight(countDownLatch));
大喬.start();
蘭陵王.start();
安其拉.start();
哪吒.start();
鎧.start();
Thread.sleep(1000);
countDownLatch.countDown();
System.out.println("敵方還有5秒達到戰場,全軍出擊!");
}
private static void waitToFight(CountDownLatch countDownLatch) {
try {
countDownLatch.await(); // 在此等待訊號再繼續
System.out.println("收到,發起進攻!");
} catch (InterruptedException e) {
e.printStackTrace();
}
}CountDownLatch的核心方法也不多:
await():等待latch降為0;boolean await(long timeout, TimeUnit unit):等待latch降為0,但是可以設定超時時間。比如有玩家超時未確認,那就重新匹配,總不能為了某個玩家等到天荒地老。countDown():latch數量減1;getCount():獲取當前的latch數量。
40.CyclicBarrier(同步屏障)瞭解嗎?
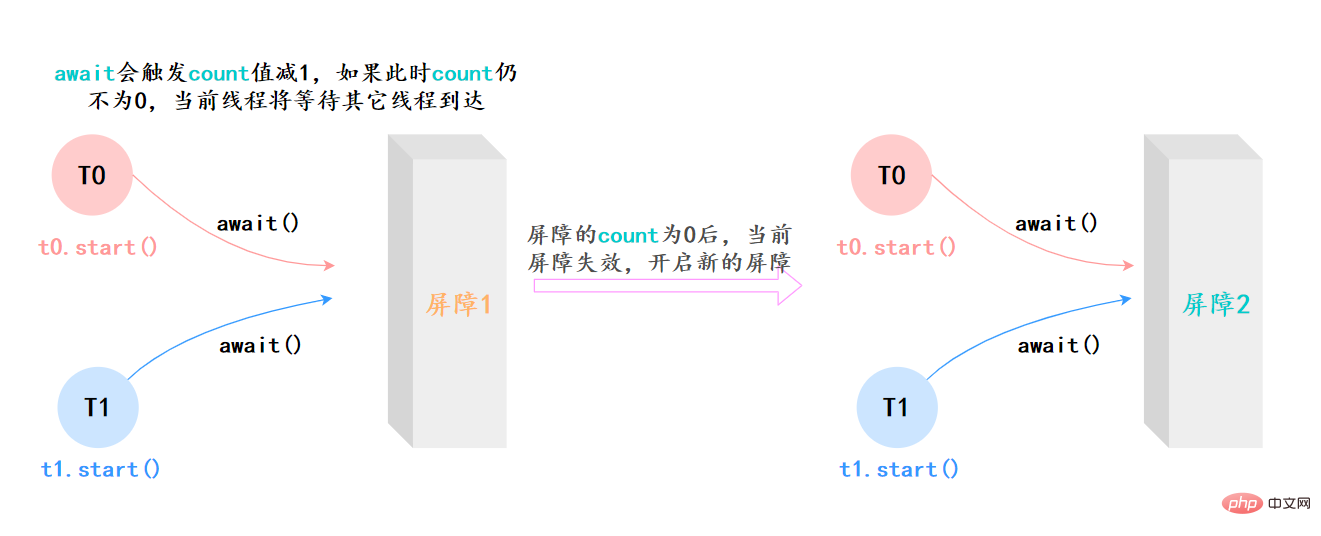
CyclicBarrier的字面意思是可迴圈使用(Cyclic)的屏障(Barrier)。它要做的事情是,讓一 組執行緒到達一個屏障(也可以叫同步點)時被阻塞,直到最後一個執行緒到達屏障時,屏障才會開門,所有被屏障攔截的執行緒才會繼續執行。
它和CountDownLatch類似,都可以協調多執行緒的結束動作,在它們結束後都可以執行特定動作,但是為什麼要有CyclicBarrier,自然是它有和CountDownLatch不同的地方。
不知道你聽沒聽過一個新人UP主小約翰可汗,小約翰生平有兩大恨——「想結衣結衣不依,迷愛理愛理不理。」我們來還原一下事情的經過:小約翰在親政後認識了新垣結衣,於是決定第一次選妃,向結衣表白,等待迴應。然而新垣結衣迴應嫁給了星野源,小約翰傷心欲絕,發誓生平不娶,突然發現了鈴木愛理,於是小約翰決定第二次選妃,求愛理搭理,等待迴應。

我們拿程式碼模擬這一場景,發現CountDownLatch無能為力了,因為CountDownLatch的使用是一次性的,無法重複利用,而這裡等待了兩次。此時,我們用CyclicBarrier就可以實現,因為它可以重複利用。

執行結果:

CyclicBarrier最最核心的方法,仍然是await():
- 如果當前執行緒不是第一個到達屏障的話,它將會進入等待,直到其他執行緒都到達,除非發生被中斷、屏障被拆除、屏障被重設等情況;
上面的例子抽象一下,本質上它的流程就是這樣就是這樣:
41.CyclicBarrier和CountDownLatch有什麼區別?
兩者最核心的區別[18]:
- CountDownLatch是一次性的,而CyclicBarrier則可以多次設定屏障,實現重複利用;
- CountDownLatch中的各個子執行緒不可以等待其他執行緒,只能完成自己的任務;而CyclicBarrier中的各個執行緒可以等待其他執行緒
它們區別用一個表格整理:
| CyclicBarrier | CountDownLatch |
|---|---|
| CyclicBarrier是可重用的,其中的執行緒會等待所有的執行緒完成任務。屆時,屏障將被拆除,並可以選擇性地做一些特定的動作。 | CountDownLatch是一次性的,不同的執行緒在同一個計數器上工作,直到計數器為0. |
| CyclicBarrier面向的是執行緒數 | CountDownLatch面向的是任務數 |
| 在使用CyclicBarrier時,你必須在構造中指定參與共同作業的執行緒數,這些執行緒必須呼叫await()方法 | 使用CountDownLatch時,則必須要指定任務數,至於這些任務由哪些執行緒完成無關緊要 |
| CyclicBarrier可以在所有的執行緒釋放後重新使用 | CountDownLatch在計數器為0時不能再使用 |
| 在CyclicBarrier中,如果某個執行緒遇到了中斷、超時等問題時,則處於await的執行緒都會出現問題 | 在CountDownLatch中,如果某個執行緒出現問題,其他執行緒不受影響 |
42.Semaphore(號誌)瞭解嗎?
Semaphore(號誌)是用來控制同時存取特定資源的執行緒數量,它通過協調各個執行緒,以保證合理的使用公共資源。
聽起來似乎很抽象,現在汽車多了,開車出門在外的一個老大難問題就是停車 。停車場的車位是有限的,只能允許若干車輛停泊,如果停車場還有空位,那麼顯示牌顯示的就是綠燈和剩餘的車位,車輛就可以駛入;如果停車場沒位了,那麼顯示牌顯示的就是綠燈和數位0,車輛就得等待。如果滿了的停車場有車離開,那麼顯示牌就又變綠,顯示空車位數量,等待的車輛就能進停車場。

我們把這個例子類比一下,車輛就是執行緒,進入停車場就是執行緒在執行,離開停車場就是執行緒執行完畢,看見紅燈就表示執行緒被阻塞,不能執行,Semaphore的本質就是協調多個執行緒對共用資源的獲取。
![Semaphore許可獲取-來源參考[18]](https://s3.ap-northeast-1.wasabisys.com/img.tw511.com/202203/57a99d1fe2032fae83a4eeb49f0b3d97-56zcxnvprko2k.png)
我們再來看一個Semaphore的用途:它可以用於做流量控制,特別是公用資源有限的應用場景,比如資料庫連線。
假如有一個需求,要讀取幾萬個檔案的資料,因為都是IO密集型任務,我們可以啟動幾十個執行緒並行地讀取,但是如果讀到記憶體後,還需要儲存到資料庫中,而資料庫的連線數只有10個,這時我們必須控制只有10個執行緒同時獲取資料庫連線儲存資料,否則會報錯無法獲取資料庫連線。這個時候,就可以使用Semaphore來做流量控制,如下:
public class SemaphoreTest {
private static final int THREAD_COUNT = 30;
private static ExecutorService threadPool = Executors.newFixedThreadPool(THREAD_COUNT);
private static Semaphore s = new Semaphore(10);
public static void main(String[] args) {
for (int i = 0; i < THREAD_COUNT; i++) {
threadPool.execute(new Runnable() {
@Override
public void run() {
try {
s.acquire();
System.out.println("save data");
s.release();
} catch (InterruptedException e) {
}
}
});
}
threadPool.shutdown();
}}在程式碼中,雖然有30個執行緒在執行,但是隻允許10個並行執行。Semaphore的構造方法Semaphore(int permits)接受一個整型的數位,表示可用的許可證數量。Semaphore(10)表示允許10個執行緒獲取許可證,也就是最大並行數是10。Semaphore的用法也很簡單,首先執行緒使用 Semaphore的acquire()方法獲取一個許可證,使用完之後呼叫release()方法歸還許可證。還可以用tryAcquire()方法嘗試獲取許可證。
43.Exchanger 瞭解嗎?
Exchanger(交換者)是一個用於執行緒間共同作業的工具類。Exchanger用於進行執行緒間的資料交換。它提供一個同步點,在這個同步點,兩個執行緒可以交換彼此的資料。
![英雄交換獵物-來源參考[18]](https://s3.ap-northeast-1.wasabisys.com/img.tw511.com/202203/a99f1f171b5f8c414e2981e6a7d5189a-57svpck0brdba.png)
這兩個執行緒通過 exchange方法交換資料,如果第一個執行緒先執行exchange()方法,它會一直等待第二個執行緒也執行exchange方法,當兩個執行緒都到達同步點時,這兩個執行緒就可以交換資料,將本執行緒生產出來的資料傳遞給對方。
Exchanger可以用於遺傳演演算法,遺傳演演算法裡需要選出兩個人作為交配物件,這時候會交換兩人的資料,並使用交叉規則得出2個交配結果。Exchanger也可以用於校對工作,比如我們需要將紙製銀行流水通過人工的方式錄入成電子銀行流水,為了避免錯誤,採用AB崗兩人進行錄入,錄入到Excel之後,系統需要載入這兩個Excel,並對兩個Excel資料進行校對,看看是否錄入一致。
public class ExchangerTest {
private static final Exchanger<String> exgr = new Exchanger<String>();
private static ExecutorService threadPool = Executors.newFixedThreadPool(2);
public static void main(String[] args) {
threadPool.execute(new Runnable() {
@Override
public void run() {
try {
String A = "銀行流水A"; // A錄入銀行流水資料
exgr.exchange(A);
} catch (InterruptedException e) {
}
}
});
threadPool.execute(new Runnable() {
@Override
public void run() {
try {
String B = "銀行流水B"; // B錄入銀行流水資料
String A = exgr.exchange("B");
System.out.println("A和B資料是否一致:" + A.equals(B) + ",A錄入的是:"
+ A + ",B錄入是:" + B);
} catch (InterruptedException e) {
}
}
});
threadPool.shutdown();
}}假如兩個執行緒有一個沒有執行exchange()方法,則會一直等待,如果擔心有特殊情況發生,避免一直等待,可以使用exchange(V x, long timeOut, TimeUnit unit)設定最大等待時長
44.什麼是執行緒池?
執行緒池: 簡單理解,它就是一個管理執行緒的池子。
- 它幫我們管理執行緒,避免增加建立執行緒和銷燬執行緒的資源損耗。因為執行緒其實也是一個物件,建立一個物件,需要經過類載入過程,銷燬一個物件,需要走GC垃圾回收流程,都是需要資源開銷的。
- 提高響應速度。 如果任務到達了,相對於從執行緒池拿執行緒,重新去建立一條執行緒執行,速度肯定慢很多。
- 重複利用。 執行緒用完,再放回池子,可以達到重複利用的效果,節省資源。
45.能說說工作中執行緒池的應用嗎?
之前我們有一個和第三方對接的需求,需要向第三方推播資料,引入了多執行緒來提升資料推播的效率,其中用到了執行緒池來管理執行緒。
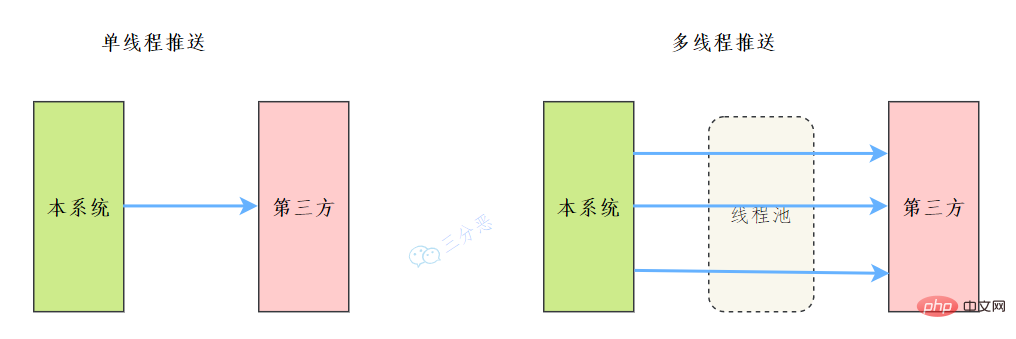
主要程式碼如下:

完整可執行程式碼地址:https://gitee.com/fighter3/thread-demo.git
執行緒池的引數如下:
corePoolSize:執行緒核心引數選擇了CPU數×2
maximumPoolSize:最大執行緒數選擇了和核心執行緒數相同
keepAliveTime:非核心閒置執行緒存活時間直接置為0
unit:非核心執行緒保持存活的時間選擇了 TimeUnit.SECONDS 秒
workQueue:執行緒池等待佇列,使用 LinkedBlockingQueue阻塞佇列
同時還用了synchronized 來加鎖,保證資料不會被重複推播:
synchronized (PushProcessServiceImpl.class) {}ps:這個例子只是簡單地進行了資料推播,實際上還可以結合其他的業務,像什麼資料淨化啊、資料統計啊,都可以套用。
46.能簡單說一下執行緒池的工作流程嗎?
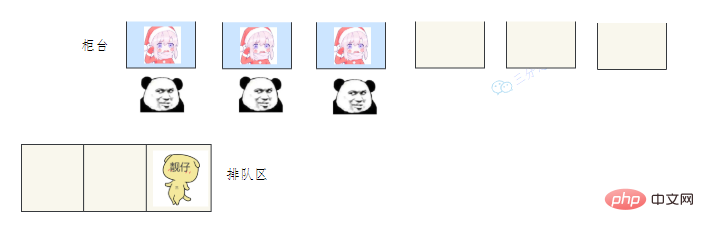
用一個通俗的比喻:
有一個營業廳,總共有六個視窗,現在開放了三個視窗,現在有三個視窗坐著三個營業員小姐姐在營業。
老三去辦業務,可能會遇到什麼情況呢?
- 老三發現有空間的在營業的視窗,直接去找小姐姐辦理業務。

- 老三發現沒有空閒的視窗,就在排隊區排隊等。
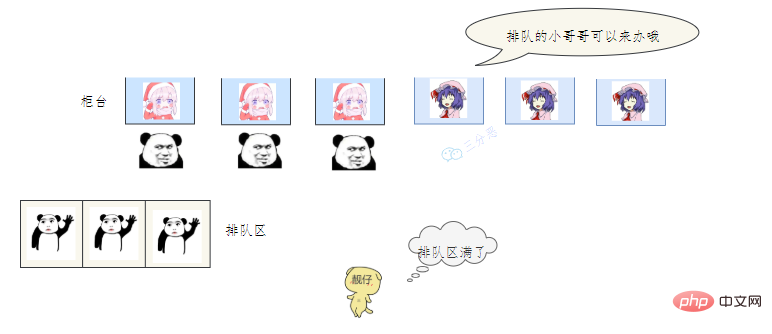
- 老三發現沒有空閒的視窗,等待區也滿了,蚌埠住了,經理一看,就讓休息的小姐姐趕緊回來上班,等待區號靠前的趕緊去新視窗辦,老三去排隊區排隊。小姐姐比較辛苦,假如一段時間發現他們可以不用接著營業,經理就讓她們接著休息。
- 老三一看,六個視窗都滿了,等待區也沒位置了。老三急了,要鬧,經理趕緊出來了,經理該怎麼辦呢?
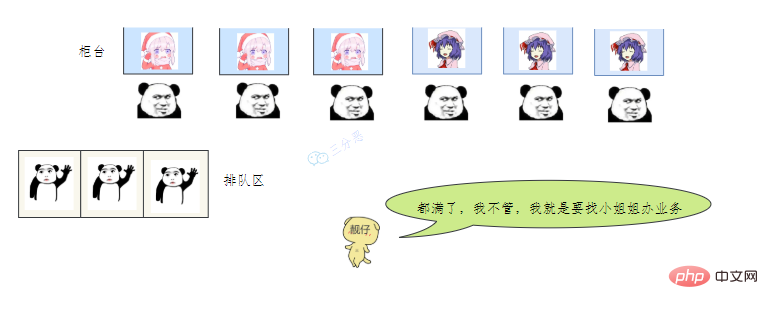
我們銀行系統已經癱瘓
誰叫你來辦的你找誰去
看你比較急,去隊里加個塞
今天沒辦法,不行你看改一天
上面的這個流程幾乎就跟 JDK 執行緒池的大致流程類似,
- 營業中的 3個視窗對應核心執行緒池數:corePoolSize
- 總的營業視窗數6對應:maximumPoolSize
- 開啟的臨時視窗在多少時間內無人辦理則關閉對應:unit
- 排隊區就是等待佇列:workQueue
- 無法辦理的時候銀行給出的解決方法對應:RejectedExecutionHandler
- threadFactory 該引數在 JDK 中是 執行緒工廠,用來建立執行緒物件,一般不會動。
所以我們執行緒池的工作流程也比較好理解了:
- 執行緒池剛建立時,裡面沒有一個執行緒。任務佇列是作為引數傳進來的。不過,就算佇列裡面有任務,執行緒池也不會馬上執行它們。
- 當呼叫 execute() 方法新增一個任務時,執行緒池會做如下判斷:
- 如果正在執行的執行緒數量小於 corePoolSize,那麼馬上建立執行緒執行這個任務;
- 如果正在執行的執行緒數量大於或等於 corePoolSize,那麼將這個任務放入佇列;
- 如果這時候佇列滿了,而且正在執行的執行緒數量小於 maximumPoolSize,那麼還是要建立非核心執行緒立刻執行這個任務;
- 如果佇列滿了,而且正在執行的執行緒數量大於或等於 maximumPoolSize,那麼執行緒池會根據拒絕策略來對應處理。
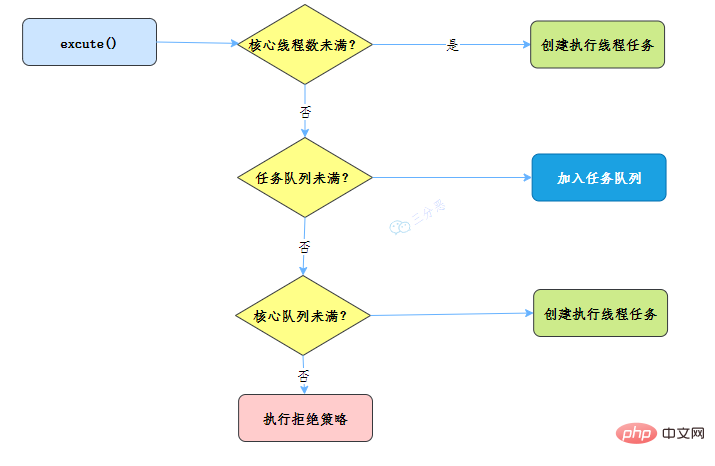
當一個執行緒完成任務時,它會從佇列中取下一個任務來執行。
當一個執行緒無事可做,超過一定的時間(keepAliveTime)時,執行緒池會判斷,如果當前執行的執行緒數大於 corePoolSize,那麼這個執行緒就被停掉。所以執行緒池的所有任務完成後,它最終會收縮到 corePoolSize 的大小。
47.執行緒池主要引數有哪些?
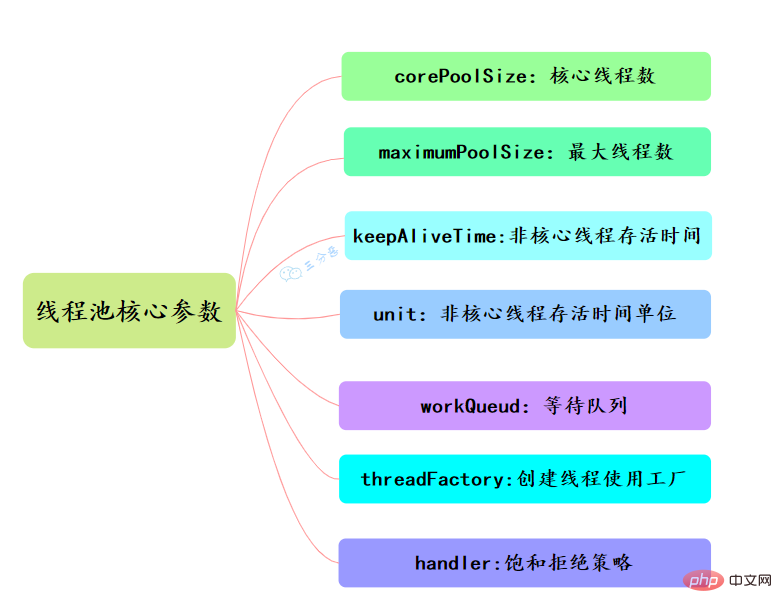
執行緒池有七大引數,需要重點關注corePoolSize、maximumPoolSize、workQueue、handler這四個。
- corePoolSize
此值是用來初始化執行緒池中核心執行緒數,當執行緒池中執行緒池數< corePoolSize時,系統預設是新增一個任務才建立一個執行緒池。當執行緒數 = corePoolSize時,新任務會追加到workQueue中。
- maximumPoolSize
maximumPoolSize表示允許的最大執行緒數 = (非核心執行緒數+核心執行緒數),當BlockingQueue也滿了,但執行緒池中匯流排程數 < maximumPoolSize時候就會再次建立新的執行緒。
- keepAliveTime
非核心執行緒 =(maximumPoolSize - corePoolSize ) ,非核心執行緒閒置下來不幹活最多存活時間。
- unit
執行緒池中非核心執行緒保持存活的時間的單位
- TimeUnit.DAYS; 天
- TimeUnit.HOURS; 小時
- TimeUnit.MINUTES; 分鐘
- TimeUnit.SECONDS; 秒
- TimeUnit.MILLISECONDS; 毫秒
- TimeUnit.MICROSECONDS; 微秒
- TimeUnit.NANOSECONDS; 納秒
- workQueue
執行緒池等待佇列,維護著等待執行的Runnable物件。當執行當執行緒數= corePoolSize時,新的任務會被新增到workQueue中,如果workQueue也滿了則嘗試用非核心執行緒執行任務,等待佇列應該儘量用有界的。
- threadFactory
建立一個新執行緒時使用的工廠,可以用來設定執行緒名、是否為daemon執行緒等等。
- handler
corePoolSize、workQueue、maximumPoolSize都不可用的時候執行的飽和策略。
48.執行緒池的拒絕策略有哪些?
類比前面的例子,無法辦理業務時的處理方式,幫助記憶:
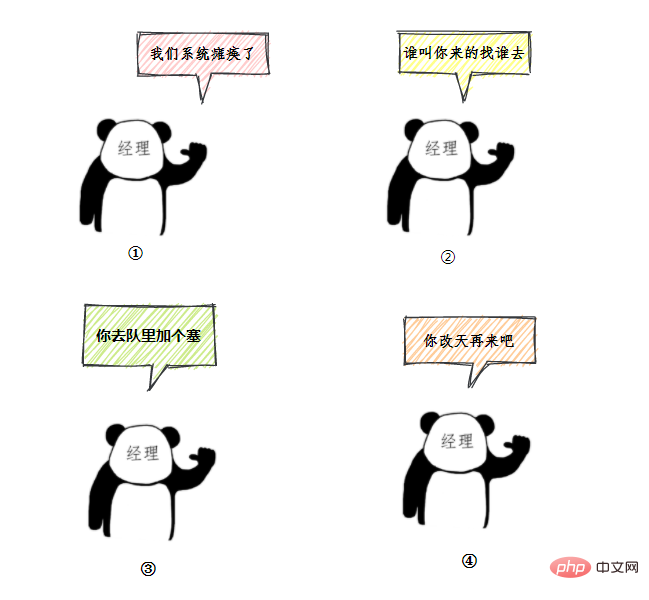
- AbortPolicy :直接丟擲異常,預設使用此策略
- CallerRunsPolicy:用呼叫者所在的執行緒來執行任務
- DiscardOldestPolicy:丟棄阻塞佇列裡最老的任務,也就是佇列裡靠前的任務
- DiscardPolicy :當前任務直接丟棄
想實現自己的拒絕策略,實現RejectedExecutionHandler介面即可。
49.執行緒池有哪幾種工作佇列?
常用的阻塞佇列主要有以下幾種:
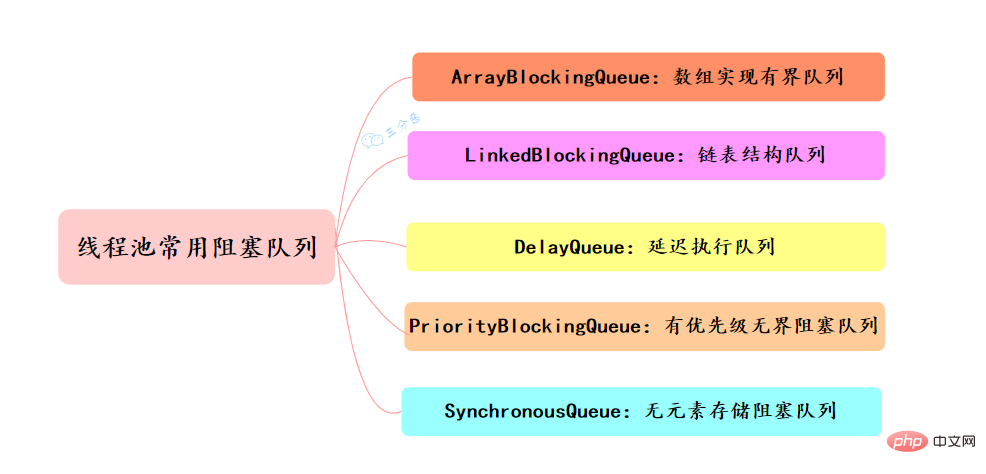
- ArrayBlockingQueue:ArrayBlockingQueue(有界佇列)是一個用陣列實現的有界阻塞佇列,按FIFO排序量。
- LinkedBlockingQueue:LinkedBlockingQueue(可設定容量佇列)是基於連結串列結構的阻塞佇列,按FIFO排序任務,容量可以選擇進行設定,不設定的話,將是一個無邊界的阻塞佇列,最大長度為Integer.MAX_VALUE,吞吐量通常要高於ArrayBlockingQuene;newFixedThreadPool執行緒池使用了這個佇列
- DelayQueue:DelayQueue(延遲佇列)是一個任務定時週期的延遲執行的佇列。根據指定的執行時間從小到大排序,否則根據插入到佇列的先後排序。newScheduledThreadPool執行緒池使用了這個佇列。
- PriorityBlockingQueue:PriorityBlockingQueue(優先順序佇列)是具有優先順序的無界阻塞佇列
- SynchronousQueue:SynchronousQueue(同步佇列)是一個不儲存元素的阻塞佇列,每個插入操作必須等到另一個執行緒呼叫移除操作,否則插入操作一直處於阻塞狀態,吞吐量通常要高於LinkedBlockingQuene,newCachedThreadPool執行緒池使用了這個佇列。
50.執行緒池提交execute和submit有什麼區別?
- execute 用於提交不需要返回值的任務
threadsPool.execute(new Runnable() {
@Override public void run() {
// TODO Auto-generated method stub }
});- submit()方法用於提交需要返回值的任務。執行緒池會返回一個future型別的物件,通過這個 future物件可以判斷任務是否執行成功,並且可以通過future的get()方法來獲取返回值
Future<Object> future = executor.submit(harReturnValuetask); try { Object s = future.get(); } catch (InterruptedException e) {
// 處理中斷異常 } catch (ExecutionException e) {
// 處理無法執行任務異常 } finally {
// 關閉執行緒池 executor.shutdown();}51.執行緒池怎麼關閉知道嗎?
可以通過呼叫執行緒池的shutdown或shutdownNow方法來關閉執行緒池。它們的原理是遍歷執行緒池中的工作執行緒,然後逐個呼叫執行緒的interrupt方法來中斷執行緒,所以無法響應中斷的任務可能永遠無法終止。
shutdown() 將執行緒池狀態置為shutdown,並不會立即停止:
- 停止接收外部submit的任務
- 內部正在跑的任務和佇列裡等待的任務,會執行完
- 等到第二步完成後,才真正停止
shutdownNow() 將執行緒池狀態置為stop。一般會立即停止,事實上不一定:
- 和shutdown()一樣,先停止接收外部提交的任務
- 忽略佇列裡等待的任務
- 嘗試將正在跑的任務interrupt中斷
- 返回未執行的任務列表
shutdown 和shutdownnow簡單來說區別如下:
- shutdownNow()能立即停止執行緒池,正在跑的和正在等待的任務都停下了。這樣做立即生效,但是風險也比較大。
- shutdown()只是關閉了提交通道,用submit()是無效的;而內部的任務該怎麼跑還是怎麼跑,跑完再徹底停止執行緒池。
52.執行緒池的執行緒數應該怎麼設定?
執行緒在Java中屬於稀缺資源,執行緒池不是越大越好也不是越小越好。任務分為計算密集型、IO密集型、混合型。
- 計算密集型:大部分都在用CPU跟記憶體,加密,邏輯操作業務處理等。
- IO密集型:資料庫連結,網路通訊傳輸等。

一般的經驗,不同型別執行緒池的引數設定:
- 計算密集型一般推薦執行緒池不要過大,一般是CPU數 + 1,+1是因為可能存在頁缺失(就是可能存在有些資料在硬碟中需要多來一個執行緒將資料讀入記憶體)。如果執行緒池數太大,可能會頻繁的 進行執行緒上下文切換跟任務排程。獲得當前CPU核心數程式碼如下:
Runtime.getRuntime().availableProcessors();
- IO密集型:執行緒數適當大一點,機器的Cpu核心數*2。
- 混合型:可以考慮根絕情況將它拆分成CPU密集型和IO密集型任務,如果執行時間相差不大,拆分可以提升吞吐量,反之沒有必要。
當然,實際應用中沒有固定的公式,需要結合測試和監控來進行調整。
53.有哪幾種常見的執行緒池?
面試常問,主要有四種,都是通過工具類Excutors建立出來的,需要注意,阿里巴巴《Java開發手冊》裡禁止使用這種方式來建立執行緒池。
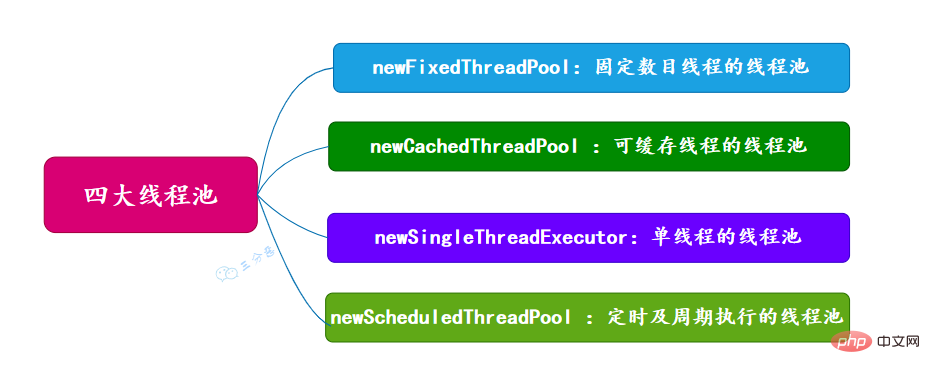
newFixedThreadPool (固定數目執行緒的執行緒池)
newCachedThreadPool (可快取執行緒的執行緒池)
newSingleThreadExecutor (單執行緒的執行緒池)
newScheduledThreadPool (定時及週期執行的執行緒池)
54.能說一下四種常見執行緒池的原理嗎?
前三種執行緒池的構造直接呼叫ThreadPoolExecutor的構造方法。
newSingleThreadExecutor
public static ExecutorService newSingleThreadExecutor(ThreadFactory threadFactory) {
return new FinalizableDelegatedExecutorService
(new ThreadPoolExecutor(1, 1,
0L, TimeUnit.MILLISECONDS,
new LinkedBlockingQueue<Runnable>(),
threadFactory));
}執行緒池特點
- 核心執行緒數為1
- 最大執行緒數也為1
- 阻塞佇列是無界佇列LinkedBlockingQueue,可能會導致OOM
- keepAliveTime為0
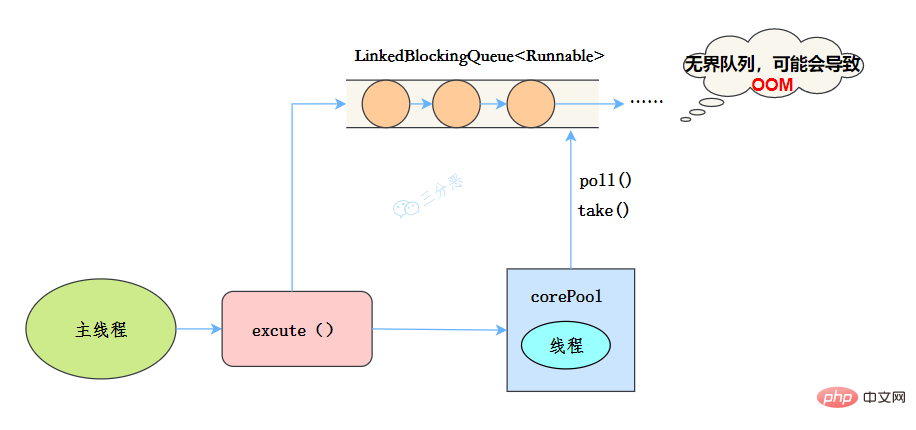
工作流程:
- 提交任務
- 執行緒池是否有一條執行緒在,如果沒有,新建執行緒執行任務
- 如果有,將任務加到阻塞佇列
- 當前的唯一執行緒,從佇列取任務,執行完一個,再繼續取,一個執行緒執行任務。
適用場景
適用於序列執行任務的場景,一個任務一個任務地執行。
newFixedThreadPool
public static ExecutorService newFixedThreadPool(int nThreads, ThreadFactory threadFactory) {
return new ThreadPoolExecutor(nThreads, nThreads,
0L, TimeUnit.MILLISECONDS,
new LinkedBlockingQueue<Runnable>(),
threadFactory);
}執行緒池特點:
- 核心執行緒數和最大執行緒數大小一樣
- 沒有所謂的非空閒時間,即keepAliveTime為0
- 阻塞佇列為無界佇列LinkedBlockingQueue,可能會導致OOM
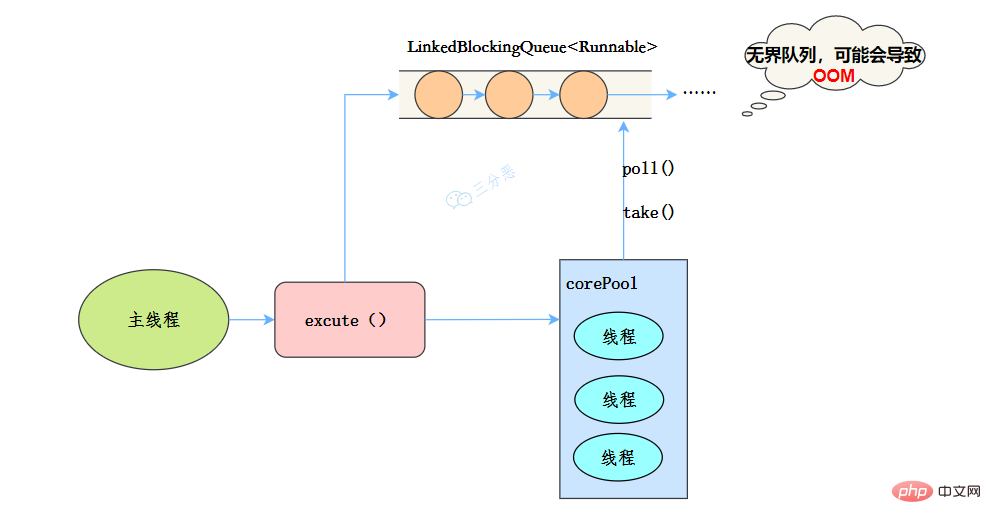
工作流程:
- 提交任務
- 如果執行緒數少於核心執行緒,建立核心執行緒執行任務
- 如果執行緒數等於核心執行緒,把任務新增到LinkedBlockingQueue阻塞佇列
- 如果執行緒執行完任務,去阻塞佇列取任務,繼續執行。
使用場景
FixedThreadPool 適用於處理CPU密集型的任務,確保CPU在長期被工作執行緒使用的情況下,儘可能的少的分配執行緒,即適用執行長期的任務。
newCachedThreadPool
public static ExecutorService newCachedThreadPool(ThreadFactory threadFactory) {
return new ThreadPoolExecutor(0, Integer.MAX_VALUE,
60L, TimeUnit.SECONDS,
new SynchronousQueue<Runnable>(),
threadFactory);
}執行緒池特點:
- 核心執行緒數為0
- 最大執行緒數為Integer.MAX_VALUE,即無限大,可能會因為無限建立執行緒,導致OOM
- 阻塞佇列是SynchronousQueue
- 非核心執行緒空閒存活時間為60秒
當提交任務的速度大於處理任務的速度時,每次提交一個任務,就必然會建立一個執行緒。極端情況下會建立過多的執行緒,耗盡 CPU 和記憶體資源。由於空閒 60 秒的執行緒會被終止,長時間保持空閒的 CachedThreadPool 不會佔用任何資源。
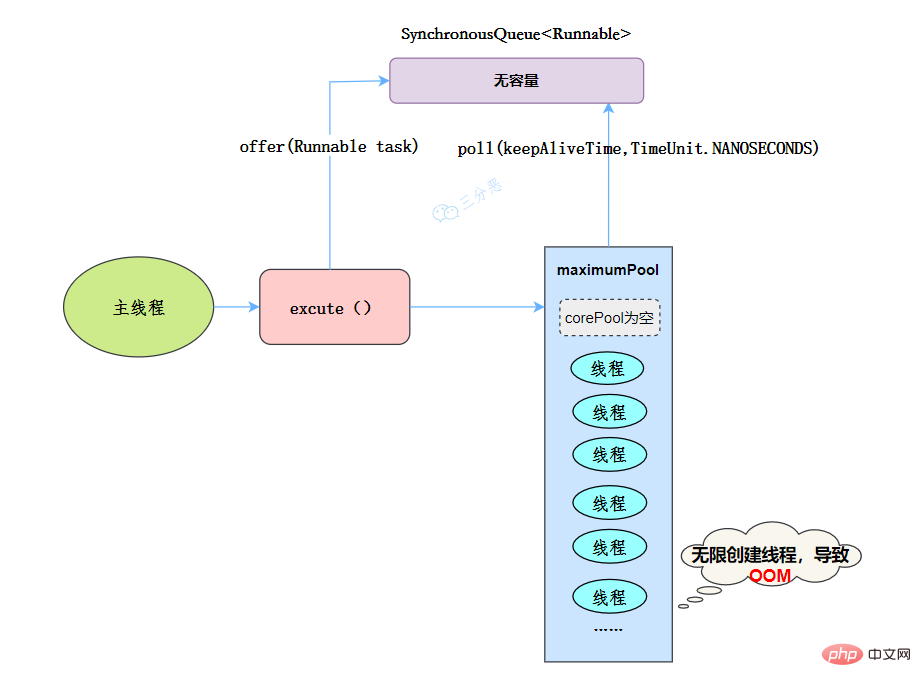
工作流程:
- 提交任務
- 因為沒有核心執行緒,所以任務直接加到SynchronousQueue佇列。
- 判斷是否有空閒執行緒,如果有,就去取出任務執行。
- 如果沒有空閒執行緒,就新建一個執行緒執行。
- 執行完任務的執行緒,還可以存活60秒,如果在這期間,接到任務,可以繼續活下去;否則,被銷燬。
適用場景
用於並行執行大量短期的小任務。
newScheduledThreadPool
public ScheduledThreadPoolExecutor(int corePoolSize) {
super(corePoolSize, Integer.MAX_VALUE, 0, NANOSECONDS,
new DelayedWorkQueue());
}執行緒池特點
- 最大執行緒數為Integer.MAX_VALUE,也有OOM的風險
- 阻塞佇列是DelayedWorkQueue
- keepAliveTime為0
- scheduleAtFixedRate() :按某種速率週期執行
- scheduleWithFixedDelay():在某個延遲後執行
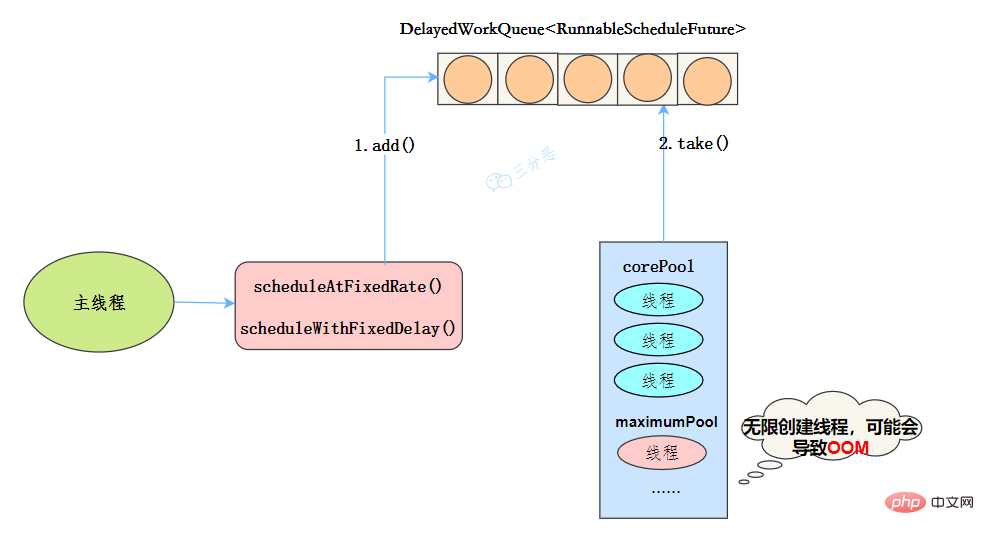
工作機制
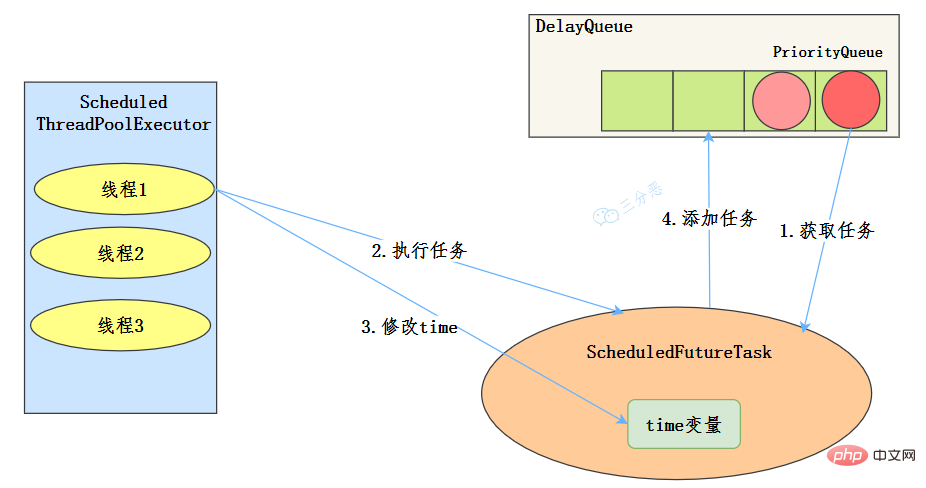
- 執行緒從DelayQueue中獲取已到期的ScheduledFutureTask(DelayQueue.take())。到期任務是指ScheduledFutureTask的time大於等於當前時間。
- 執行緒執行這個ScheduledFutureTask。
- 執行緒修改ScheduledFutureTask的time變數為下次將要被執行的時間。
- 執行緒把這個修改time之後的ScheduledFutureTask放回DelayQueue中(DelayQueue.add())。
使用場景
週期性執行任務的場景,需要限制執行緒數量的場景
使用無界佇列的執行緒池會導致什麼問題嗎?
例如newFixedThreadPool使用了無界的阻塞佇列LinkedBlockingQueue,如果執行緒獲取一個任務後,任務的執行時間比較長,會導致佇列的任務越積越多,導致機器記憶體使用不停飆升,最終導致OOM。
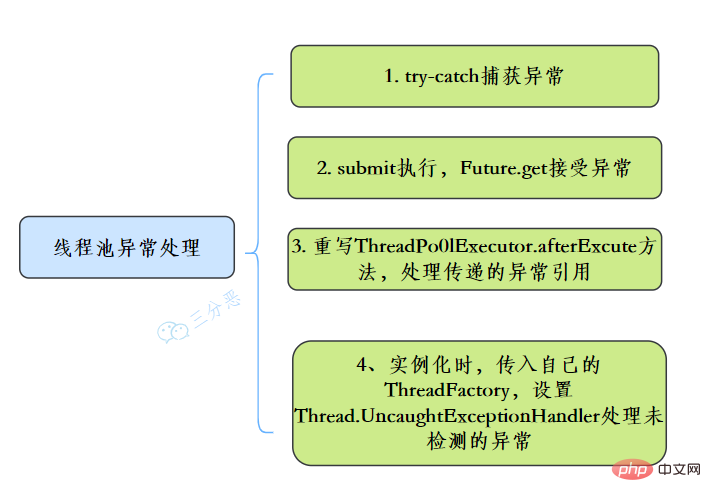
55.執行緒池異常怎麼處理知道嗎?
在使用執行緒池處理任務的時候,任務程式碼可能丟擲RuntimeException,丟擲異常後,執行緒池可能捕獲它,也可能建立一個新的執行緒來代替異常的執行緒,我們可能無法感知任務出現了異常,因此我們需要考慮執行緒池異常情況。
常見的例外處理方式:
56.能說一下執行緒池有幾種狀態嗎?
執行緒池有這幾個狀態:RUNNING,SHUTDOWN,STOP,TIDYING,TERMINATED。
//執行緒池狀態 private static final int RUNNING = -1 << COUNT_BITS; private static final int SHUTDOWN = 0 << COUNT_BITS; private static final int STOP = 1 << COUNT_BITS; private static final int TIDYING = 2 << COUNT_BITS; private static final int TERMINATED = 3 << COUNT_BITS;
執行緒池各個狀態切換圖:
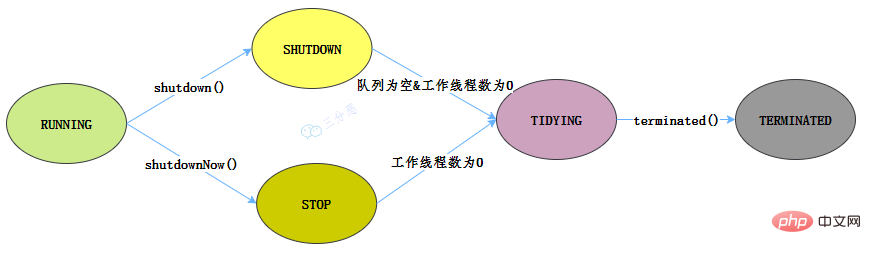
RUNNING
- 該狀態的執行緒池會接收新任務,並處理阻塞佇列中的任務;
- 呼叫執行緒池的shutdown()方法,可以切換到SHUTDOWN狀態;
- 呼叫執行緒池的shutdownNow()方法,可以切換到STOP狀態;
SHUTDOWN
- 該狀態的執行緒池不會接收新任務,但會處理阻塞佇列中的任務;
- 佇列為空,並且執行緒池中執行的任務也為空,進入TIDYING狀態;
STOP
- 該狀態的執行緒不會接收新任務,也不會處理阻塞佇列中的任務,而且會中斷正在執行的任務;
- 執行緒池中執行的任務為空,進入TIDYING狀態;
TIDYING
- 該狀態表明所有的任務已經執行終止,記錄的任務數量為0。
- terminated()執行完畢,進入TERMINATED狀態
TERMINATED
- 該狀態表示執行緒池徹底終止
57.執行緒池如何實現引數的動態修改?
執行緒池提供了幾個 setter方法來設定執行緒池的引數。
![JDK 執行緒池參數設定介面來源參考[7]](https://s3.ap-northeast-1.wasabisys.com/img.tw511.com/202203/6094178ce7a357b1c3eb573fc35e4d09-785fs32wnzg0s.png)
這裡主要有兩個思路:
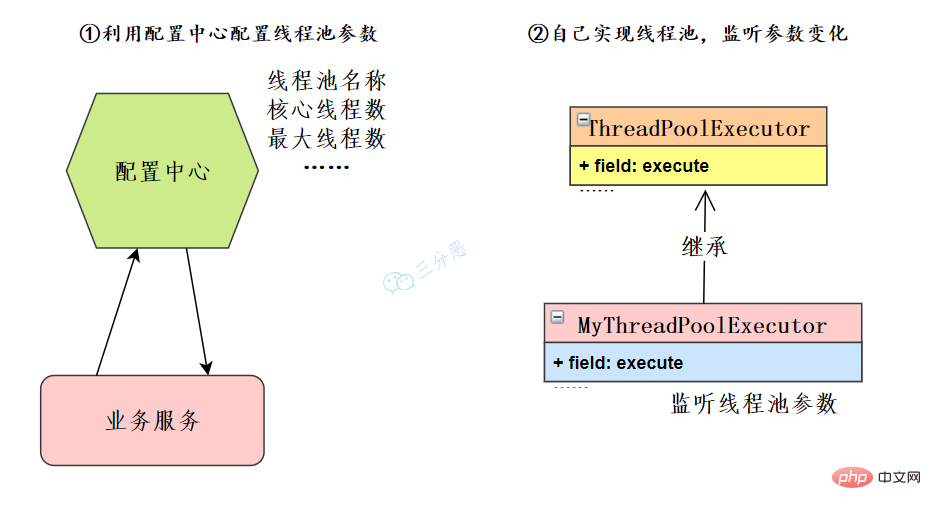
在我們微服務的架構下,可以利用設定中心如Nacos、Apollo等等,也可以自己開發設定中心。業務服務讀取執行緒池設定,獲取相應的執行緒池範例來修改執行緒池的引數。
如果限制了設定中心的使用,也可以自己去擴充套件ThreadPoolExecutor,重寫方法,監聽執行緒池引數變化,來動態修改執行緒池引數。
執行緒池調優瞭解嗎?
執行緒池設定沒有固定的公式,通常事前會對執行緒池進行一定評估,常見的評估方案如下:
![執行緒池評估方案 來源參考[7]](https://s3.ap-northeast-1.wasabisys.com/img.tw511.com/202203/b8171ba02ccd61fc1cad003f65eae9c1-804g0n513c5sk.png)
上線之前也要進行充分的測試,上線之後要建立完善的執行緒池監控機制。
事中結合監控告警機制,分析執行緒池的問題,或者可優化點,結合執行緒池動態引數設定機制來調整設定。
事後要注意仔細觀察,隨時調整。
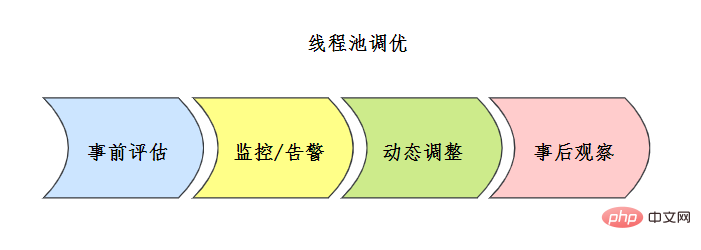
具體的調優案例可以檢視參考[7]美團技術部落格。
58.你能設計實現一個執行緒池嗎?
這道題在阿里的面試中出現頻率比較高
執行緒池實現原理可以檢視 要是以前有人這麼講執行緒池,我早就該明白了! ,當然,我們自己實現, 只需要抓住執行緒池的核心流程-參考[6]:
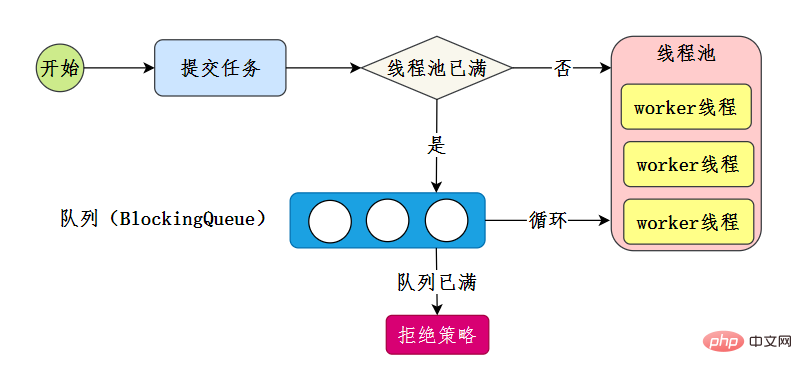
我們自己的實現就是完成這個核心流程:
- 執行緒池中有N個工作執行緒
- 把任務提交給執行緒池執行
- 如果執行緒池已滿,把任務放入佇列
- 最後當有空閒時,獲取佇列中任務來執行
實現程式碼[6]:

這樣,一個實現了執行緒池主要流程的類就完成了。
59.單機執行緒池執行斷電了應該怎麼處理?
我們可以對正在處理和阻塞佇列的任務做事務管理或者對阻塞佇列中的任務持久化處理,並且當斷電或者系統崩潰,操作無法繼續下去的時候,可以通過回溯紀錄檔的方式來複原正在處理的已經執行成功的操作。然後重新執行整個阻塞佇列。
也就是說,對阻塞佇列持久化;正在處理任務事務控制;斷電之後正在處理任務的回滾,通過紀錄檔恢復該次操作;伺服器重新啟動後阻塞佇列中的資料再載入。
並行容器和框架
關於一些並行容器,可以去看看 面渣逆襲:Java集合連環三十問 ,裡面有CopyOnWriteList和ConcurrentHashMap這兩種執行緒安全容器類的問答。。
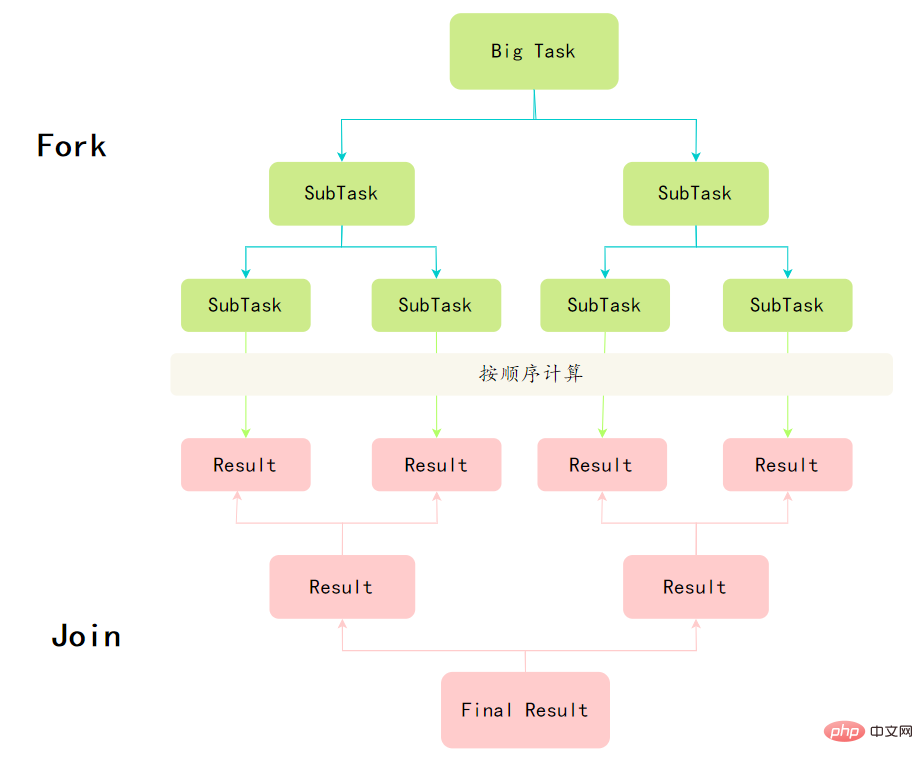
60.Fork/Join框架了解嗎?
Fork/Join框架是Java7提供的一個用於並行執行任務的框架,是一個把大任務分割成若干個小任務,最終彙總每個小任務結果後得到大任務結果的框架。
要想掌握Fork/Join框架,首先需要理解兩個點,分而治之和工作竊取演演算法。
分而治之
Fork/Join框架的定義,其實就體現了分治思想:將一個規模為N的問題分解為K個規模較小的子問題,這些子問題相互獨立且與原問題性質相同。求出子問題的解,就可得到原問題的解。
工作竊取演演算法
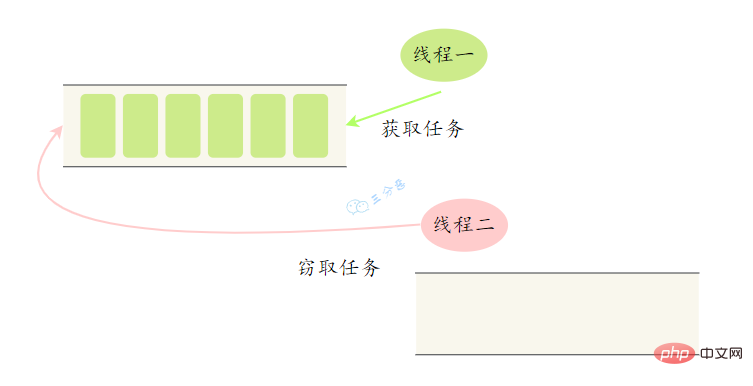
大任務拆成了若干個小任務,把這些小任務放到不同的佇列裡,各自建立單獨執行緒來執行佇列裡的任務。
那麼問題來了,有的執行緒幹活塊,有的執行緒幹活慢。幹完活的執行緒不能讓它空下來,得讓它去幫沒幹完活的執行緒幹活。它去其它執行緒的佇列裡竊取一個任務來執行,這就是所謂的工作竊取。
工作竊取發生的時候,它們會存取同一個佇列,為了減少竊取任務執行緒和被竊取任務執行緒之間的競爭,通常任務會使用雙端佇列,被竊取任務執行緒永遠從雙端佇列的頭部拿,而竊取任務的執行緒永遠從雙端佇列的尾部拿任務執行。
看一個Fork/Join框架應用的例子,計算1~n之間的和:1+2+3+…+n
- 設定一個分割閾值,任務大於閾值就拆分任務
- 任務有結果,所以需要繼承RecursiveTask
public class CountTask extends RecursiveTask<Integer> {
private static final int THRESHOLD = 16; // 閾值
private int start;
private int end;
public CountTask(int start, int end) {
this.start = start;
this.end = end;
}
@Override
protected Integer compute() {
int sum = 0;
// 如果任務足夠小就計算任務
boolean canCompute = (end - start) <= THRESHOLD;
if (canCompute) {
for (int i = start; i <= end; i++) {
sum += i;
}
} else {
// 如果任務大於閾值,就分裂成兩個子任務計算
int middle = (start + end) / 2;
CountTask leftTask = new CountTask(start, middle);
CountTask rightTask = new CountTask(middle + 1, end);
// 執行子任務
leftTask.fork();
rightTask.fork(); // 等待子任務執行完,並得到其結果
int leftResult = leftTask.join();
int rightResult = rightTask.join(); // 合併子任務
sum = leftResult + rightResult;
}
return sum;
}
public static void main(String[] args) {
ForkJoinPool forkJoinPool = new ForkJoinPool(); // 生成一個計算任務,負責計算1+2+3+4
CountTask task = new CountTask(1, 100); // 執行一個任務
Future<Integer> result = forkJoinPool.submit(task);
try {
System.out.println(result.get());
} catch (InterruptedException e) {
} catch (ExecutionException e) {
}
}
}ForkJoinTask與一般Task的主要區別在於它需要實現compute方法,在這個方法裡,首先需要判斷任務是否足夠小,如果足夠小就直接執行任務。如果比較大,就必須分割成兩個子任務,每個子任務在呼叫fork方法時,又會進compute方法,看看當前子任務是否需要繼續分割成子任務,如果不需要繼續分割,則執行當前子任務並返回結果。使用join方法會等待子任務執行完並得到其結果。
推薦學習:《》
以上就是歸納整理Java並行知識點的詳細內容,更多請關注TW511.COM其它相關文章!