2022 年 3 月 25 日,騰訊聯合英偉達開發的 TensorRT 外掛自動生成工具 TPAT 正式宣佈開源。
TensorRT 是當前應用最廣的 GPU 推理框架,但由於支援的運算元數量有限,使用者面臨手寫外掛以支援運算元的痛點。TPAT 能夠支援開放神經網路交換 (ONNX) 格式所有的運算元,端到端生成 TensorRT 外掛,在解放人力成本的同時,效能對比手寫毫不遜色。
TPAT Github 地址:
背景
TensorRT 是當今最快的 GPU 推理引擎,可以讓深度學習模型在 GPU 上實現低延遲、高吞吐量的部署,支援 Caffe,TensorFlow,Mxnet,Pytorch 等主流深度學習框架,由英偉達開發維護。業界幾乎所有 GPU 推理業務都在使用TensorRT。
但是 TensorRT 也存在缺陷,即它的部署流程比較繁瑣,因此演演算法工程師提供的模型需要交由系統工程師來部署上線,非常耗時耗力。在傳統的 TensorRT 工作流裡,手寫外掛往往是最耗時的一部分。

TensorRT 手寫運算元外掛難點
⦁ TensorRT 官方只支援很有限的常用運算元(Conv/FC/BN/Relu…),對於不支援的運算元,需要使用者手寫外掛來實現;
⦁ 外掛的編寫需要 GPU 和 cuda 知識,英偉達的工程師也通常需要 1~2 周時間來編寫一個運算元實現;模型中如果包含多個不支援運算元,就需要更多時間來逐個編寫和偵錯外掛。
TPAT 概覽
TPAT 實現了 TensorRT 外掛的全自動生成,TensorRT 的部署和上線能基本流程化不再需要人工參與。手寫外掛的步驟將由 TPAT 代替,TPAT 全自動生成一個運算元外掛耗時僅需要 30-60 分鐘的時間(該時間用於搜尋運算元的高效能 CUDA Kernel),TensorRT 會因此成為一個真正端到端的推理框架。

TPAT 亮點
⦁ 覆蓋度:支援 onnx/tensorflow/pyTorch 所有的運算元
⦁ 全自動:端到端全自動生成使用者指定的 TensorRT Plugin
⦁ 高效能:大部分運算元上效能超越手寫 Plugin
架構設計
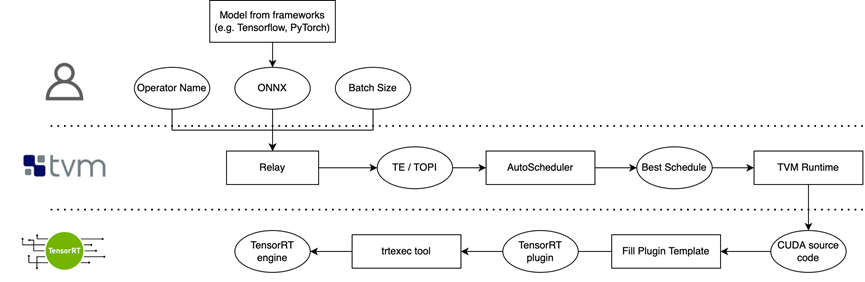
TPAT 接受使用者輸入的 ONNX-Model,指定需要生成 TensorRT Plugin 的運算元和 batch size,基於 TVM 深度學習編譯器,對固定形狀的運算元進行 AutoTune,自動生成高效能的 CUDA Kernel. 將 CUDA Kernel 和 Runtime 必要的引數填充進 TensorRT Plugin 模板,生成動態連結庫,可以直接載入到 TensorRT 執行。
TPAT 部分運算元效能資料
使用 TPAT 自動生成 TensorRT-7.2 不支援的運算元,並且用 TPAT 優化 TensorRT-7.2 原生實現效能較差的運算元;
對比手寫 Plugin

優化 TensorRT 原生運算元

對內部業務模型裡的部分運算元進行了測試,TPAT 的效能幾乎全面超越 CUDA 工程師手寫,並且端到端的設計能夠大幅減少人力投入;對於 TensorRT 原生的運算元實現,TPAT 的表現也並不遜色,AutoTune 的特點能夠優化 TensorRT 裡表現不那麼好的原生運算元實現。
TPAT 開源
後續 TPAT 的開源計劃:
- 對於運算元的多精度進行支援,包括 Float16,Int8.
- 利用 TPAT 進行子圖的優化
- 對於動態形狀的支援
附:TPAT 使用案例
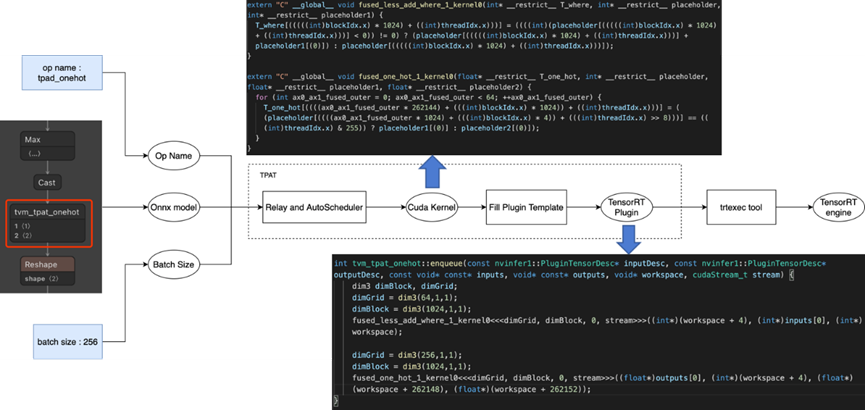
使用 TPAT 支援 Onehot 運算元(TensorRT-7.2.2.3)
- 輸入包括了 onehot 運算元的 ONNX_Model、Onehot 運算元的名字、batch_size
- TPAT藉助 TVM的Relay 和 AutoScheduler 元件,生成高效能的 CUDA Kernel;
- 經過模板填充後直接生成可用的 onehot 運算元 Plugin 的動態連結庫。