redis詳細解析主從複製、哨兵和叢集

推薦學習:
一、主從複製
1. 主從同步的用處
通過持久化功能,redis 保證了即使在伺服器重新啟動的情況下也不會丟失資料,因為持久化會把記憶體中的資料儲存到硬碟上,重新啟動會從硬碟上載入資料,但是由於資料是儲存在一臺伺服器上的,如果這臺伺服器出現硬碟故障等問題,也會導致資料丟失。為了避免單點故障,通常的做法是將資料庫複製多個副本以部署在不同的伺服器上,這樣即使有一臺伺服器出現故障,其他伺服器依然可以繼續提供服務。為此,redis 提供了複製 replication 功能,可以實現當一臺資料庫中的資料更新後,自動將更新的資料同步到其他資料庫上。
在複製的概念中,資料庫分為兩類,一類是主資料庫 master,另一類是從資料庫 slave。主資料庫可以進行讀寫操作,當寫操做導致資料變化時自動將資料同步給從資料庫,而從資料庫一般是唯讀的,並接收主資料庫同步過來的資料。一個主資料庫可以擁有多個從資料庫,而一個從資料庫只能擁有一個主資料庫。
2. 主從同步原理
2.1 原理詳解
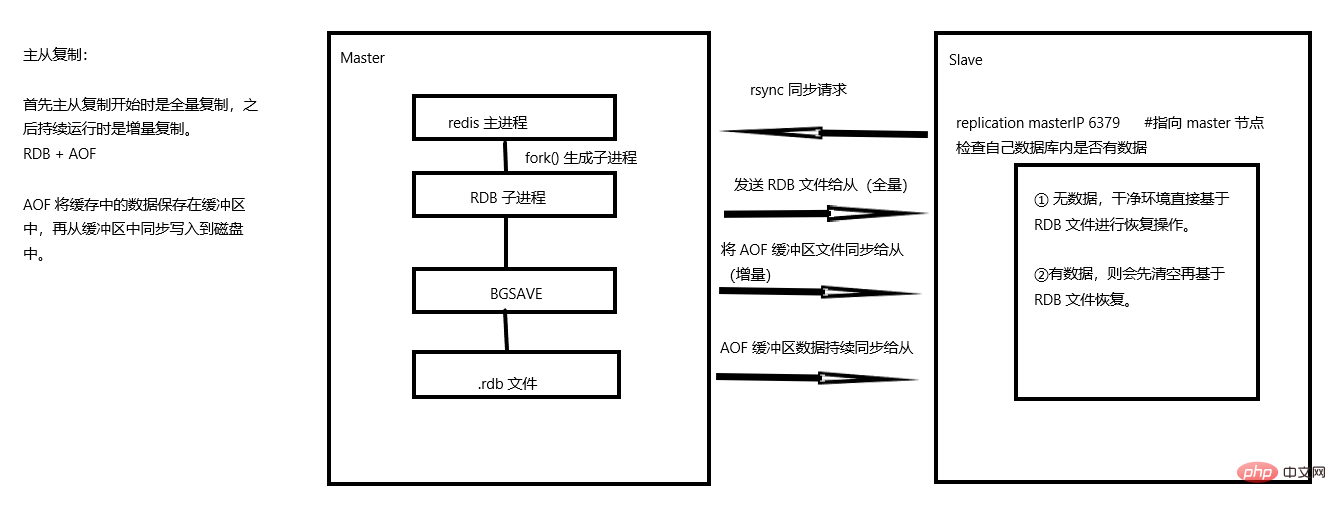
若啟動一個 Slave 機器程序,則它會向 Master 機器傳送一個
sync_command命令,請求同步連線。無論是第一次連線還是重新連線,Master 機器都會啟動一個後臺程序,將資料快照(RDB)儲存到資料檔案中(.rdb檔案),同時 Master 還會記錄修改資料的所有命令並快取在資料檔案中。
後臺程序完成快取操作之後,Master 機器就會向 Slave 機器傳送資料檔案,Slave 端機器將資料檔案儲存到硬碟上,然後將其載入到記憶體中,接著 Master 機器就會將修改資料的所有操作一併行送給 Slave 端機器。若 Slave 出現故障導致宕機,則恢復正常後會自動重新連線。
Master 機器收到 Slave 端機器的連線後,將其完整的資料檔案傳送給 Slave 端機器,如果 Master 同時收到多個 Slave發來的同步請求則 Master 會在後臺啟動一個程序以儲存資料檔案,然後將其傳送給所有的 Slave 端機器,確保所有的 Slave 端機器都正常。
RDB 做全量同步,AOF 做增量同步
2.2 理論精簡

slave -> master 傳送 sync command 申請同步 master 主程序 -> 呼叫 fork() 函數 派生 RDB 子程序進行持久化 -> 生成 RDB 檔案 將 RDB 檔案推播給 slaves(完成全量同步)#增量同步:使用到了 AOF 持久化(機制:將快取資料儲存到緩衝中),所以主從節點均需要開啟 AOF增量同步是通過 AOF 功能將快取中的資料 append(追加)到緩衝中來進行 master 緩衝 -> slave 緩衝的同步 在持續性的執行過程中,也是增量持續同步的過程
2.3 最終精簡版
slave -> master 傳送 syncmaster 使用 RDB 生成 .rdb 檔案(全量同步)傳送給 slaves master 使用 AOF 將緩衝區資料同步給 slaves 緩衝區資料(增量)
二、哨兵模式
1. 哨兵的作用
哨兵的出現主要是解決了主從複製出現故障時需要人為干預的問題
哨兵模式主要功能:
叢集監控:負責監控 redismaster 和 slave 程序是否正常工作 訊息通知:如果某個 redis 範例有故障,那麼哨兵負責傳送訊息作為報警通知給管理員 故障轉移:如果 master node 掛掉了,會自動轉移到 slave node 上 設定中心:如果故障轉移發生了,通知 client 使用者端新的 master 地址
使用一個或者多個哨兵 sentinel 範例組成的系統,對 redis 節點進行監控,在主節點出現故障的情況下,能將從節點中的一個升級為主節點,進行故障轉移,保證系統的可用性。
2. 哨兵原理
2.1 原理詳解
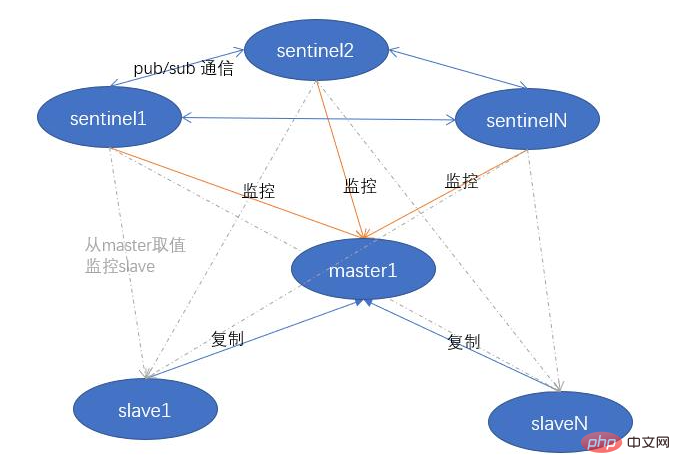
首先主節點的資訊是設定在哨兵
sentinel的組態檔中。哨兵節點會和設定的主節點建立起兩條連線命令連線和訂閱連線
PS:redis 釋出訂閱(pub/sub)是一種訊息通訊模式:傳送者(pub)傳送消 息,訂閱者 (sub)接收訊息。哨兵會通過命令連線每 10s 傳送一次 INFO 命令,通過 INFO 命令,主節點會返回自己的 run_id 和自己的從節點資訊。
哨兵會對這些從節點也建立兩條連線命令連線和訂閱連線。
哨兵通過命令連線向從節點傳送 INFO 命令,獲取到他的一些資訊:
run id(redis 伺服器 id) role(職能) 從伺服器的複製偏移量 offset 其他
通過命令連線向伺服器的
sentinel:hello頻道傳送一條訊息,內容包括自己的 IP、埠、run id、設定(後續投票的時候會用到)等。通過訂閱連線對伺服器的
sentinel:hello頻道做了監聽,所有向該頻道傳送的哨兵的訊息都能被接受到。解析監聽到的訊息,進行分析提取,就可以知道還有那些別的哨兵服務節點也在監聽這些主從節點了,更新結構體將這些哨兵節點記錄下來。
向觀察到的其他的哨兵節點建立命令連線(此時沒有訂閱連線)。
2.2 原理精簡
3 個哨兵 3 個 redis
- 三個哨兵之間建立命令連線,週期檢測 「隊友」 狀態
- 哨兵會向 master 節點(己在組態檔中指定)傳送兩條連線,分別是命令連線和訂閱連線(為了週期性獲取 master 節點的資料)
- 哨兵向 master 週期性傳送 info 命令,master(活著的情況下)會返回
redis-cli info replication master節點的資訊 + 從節點位置 - 哨兵通過 master 返回的資訊,再向 slaves 節點傳送 info 命令,slaves 返回資料,從而哨兵叢集就可以獲取到 redis 所有叢集資訊
- 哨兵會向伺服器傳送命令連線,建立自己的 hello 頻道,哨兵會向這個 hello 頻道建立訂閱,用於哨兵之間的訊息共用
2.3 思路
- 3 個哨兵互相監聽,使用 ping 互相檢測存活
- 3 個哨兵分別向資料節點 master 傳送命令連線和訂閱連線(info 命令)獲取資料節點資訊(包含主從節點)3 個哨兵再向其他從節點傳送 info ,用於獲取從節點詳細資訊
- 3 個哨兵之間通過 hello 頻道進行訊息共用
3. 哨兵模式下的故障遷移
① 主觀下線
哨兵節點會每秒一次的頻率向建立了命令連線的範例傳送 PING 命令,如果在down-after-milliseconds毫秒內沒有做出有效響應包括PONG/LOADING/MASTERDOWN以外的響應,哨兵就會將該範例在本結構體中的狀態標記為SRI_S_DOWN主觀下線。② 客觀下線
當一個哨兵節點發現主節點處於主觀下線狀態是,會向其他的哨兵節點發出詢問,該節點是不是已經主觀下線了。如果超過設定引數quorum個節點認為是主觀下線時,該哨兵節點就會將自己維護的結構體中該主節點標記為SRIO DOWN客觀下線詢問命令SENTINEL is-master-down-by-addr。③ master 選舉
在認為主節點客觀下線的情況下,哨兵節點節點間會發起一次選舉,命令為SENTINEL is-master-down-by-addr,只是 runid 這次會將自己的 runid 帶進去,希望接受者將自己設定為主節點。如果超過半數以上的節點返回將該節點標記為 leader 的情況下,會有該 leader 對故障進行遷移。④ 故障轉移
####在從節點中挑選出新的主節點通訊正常 優先順序排序 優先順序相同時選擇 offset 最大的###將該節點設定成新的主節點SLAVEOF no one,並確保在後續的INGO命令時 該節點返回狀態為master ###將其他的從節點設定成從新的主節點複製,SLAVEOF命令###將舊的主節點變成新的主節點的從節點PS:優缺點#優點:高可用,哨兵模式是基於主從模式的,所有主從模式的優點,哨兵模式都具有有;主從可以自動切換,系統更健壯,可用性更高#缺點:redis 比較難支援線上擴容,在群集容量達到上限時線上擴容會變得很複雜
三、叢集
1. redis 叢集的含義
主節點負責讀寫請求和叢集資訊的維護,從節點只進行主節點資料和狀態資訊的複製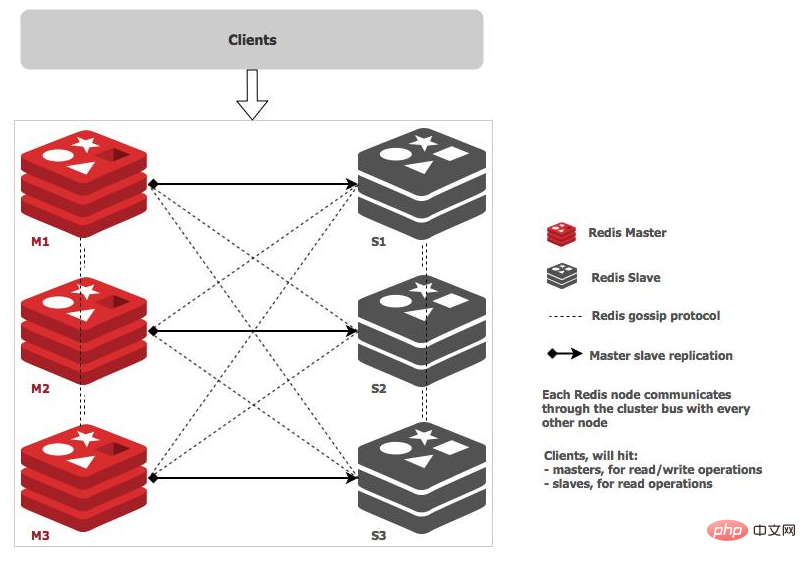
redis 的哨兵模式基本已經可以實現高可用、讀寫分離,但是在這種模式每臺 redis 伺服器都儲存相同的資料,很浪費記憶體資源,所以在 redis3.0 上加入了 Cluster 群集模式,實現了 redis 的分散式儲存,也就是說每臺 redis 節點儲存著不同的內容。根據官方推薦,叢集部署至少要 3 臺以上的 master 節點,最好使用 3 主 3 從六個節點的模式。
Cluster 群集由多個 redis 伺服器組成的分散式網路服務群集,群集之中有多個 master 主節點,每一個主節點都可讀可寫,節點之間會相互通訊,兩兩相連,redis 群集無中心節點。
2. redis 叢集的特點
- 在 redis-Cluster 群集中,可以給每個一個主節點新增從節點,主節點和從節點直接尊循主從模型的特性,當使用者需要處理更多讀請求的時候,新增從節點可以擴充套件系統的讀效能
- redis-cluster 的故障轉移:redis 群集的主機節點內建了類似
redis sentinel的節點故障檢測和自動故障轉移功能,當群集中的某個主節點下線時,群集中的其他線上主節點會注意到這一點,並且對已經下線的主節點進行故障轉移 - 叢集進行故障轉移的方法和
redis sentinel進行故障轉移的方法基本一樣,不同的是,在叢集裡面,故障轉移是由叢集中其他線上的主節點負責進行的,所以群集不必另外使用redis sentinel
四、分散式鎖
https://www.zhihu.com/question/300767410/answer/1749442787
如果在一個分散式系統中,我們從資料庫中讀取一個資料,然後修改儲存,這種情況很容易遇到並行問題。因為讀取和更新儲存不是一個原子操作,在並行時就會導致資料的不正確。這種場景其實並不少見,比如電商秒殺活動,庫存數量的更新就會遇到。如果是單機應用,直接使用本地鎖就可以避免。如果是分散式應用,本地鎖派不上用場,這時就需要引入分散式鎖來解決。由此可見分散式鎖的目的其實很簡單,就是為了保證多臺伺服器在執行某一段程式碼時保證只有一臺伺服器執行。
簡單來說:
現在的業務應用通常都是微服務架構,這也意味著一個應用會部署多個程序,那麼多個程序如果需要修改資料庫中的同一行記錄時,為了避免操作亂序導致資料錯誤,此時就需要引入分散式鎖解決問題。
為了保證分散式鎖的可用性,至少要確保鎖的實現要同時滿足以下幾點:
- 互斥性。在任何時刻,保證只有一個使用者端持有鎖。
- 不能出現死鎖。如果在一個使用者端持有鎖的期間,這個使用者端崩潰了,也要保證後續的其他使用者端可以上鎖。
- 保證上鎖和解鎖都是同一個使用者端。
一般來說,實現分散式鎖的方式有以下幾種:
- 使用 MySQL,基於唯一索引。
- 使用 ZooKeeper,基於臨時有序節點。
- 使用 Redis,基於 setnx 命令。
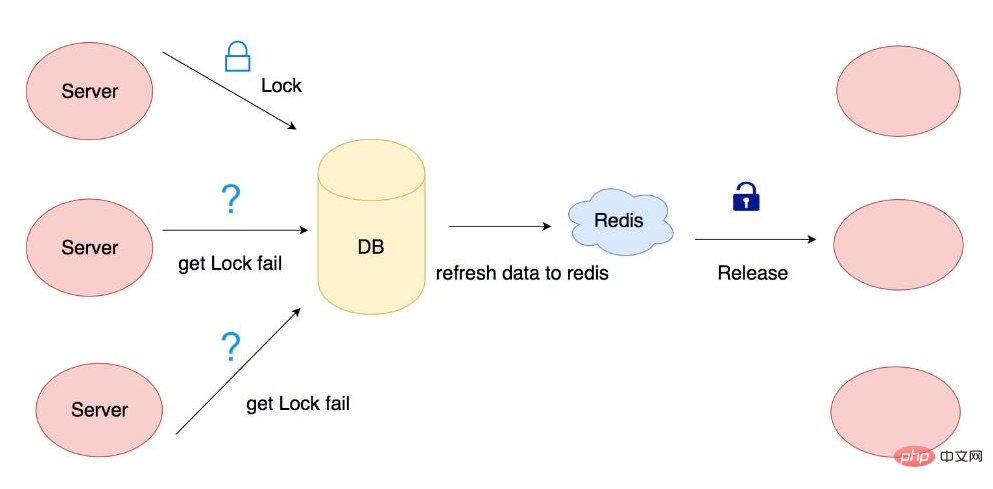
對 redis 來說注意三點,對 key 的加鎖,如果請求未完成對快要過期的 key 的續期,請求完成後 key 的解鎖。防止並行環境下被讀取的一個 key 可能被多個請求修改,造成無效操作,資源浪費的情況。
五、redis 總結
redis 可以做為 mysql 的前置快取資料庫,redis 與 mysql 對接的方式需要設定執行緒池,需要定義後端 mysql 的位置( IP + port +sock 檔案的位置)
redis 基礎功能:用於記憶體/快取的快速儲存(讀取)
實現的方式:
預設將資料儲存在記憶體/快取中 具有豐富的資料型別:string list hash set && order set 等 重要資料持久化的功能,持久化的方式:AOF RDB
單執行緒模式 -> 速度快的原因之一:Epoll + I/O 複用(cluster 中的 slots 雜湊槽可以充當資料讀、取的索引)
- redis 中的演演算法:
LRU:淘汰策略1) 快取中的資料進行隨機淘汰2) 快取中被設定了過期時間的資料進行隨機淘汰3) 快取中被設定了過期時間的資料,進行惰性刪除(僅當存取到的資料過期了,才會刪除)4) 當資料持續儲存過程中記憶體將滿,會在設定了過期時間的資料中進行近期淘汰 令牌桶 + 漏桶演演算法:限流 Raft:選舉機制,用於選舉新的主節點
- redis 快取高熱資料的機制
高熱資料:命中次數高的資料 指定提高快取內資料的命中數,最直接的可以刷指令碼,存取這些資料
六、系統優化
1. 單例伺服器,伺服器本身優化
硬體資源選擇(系統五大資源)
- 磁碟 固態盤 SCSI(硬體磁碟陣列)
- 伺服器記憶體條選擇(本地伺服器和雲伺服器)
- CPU 核數選擇
- 網路網路卡(本地伺服器和雲伺服器),需要考慮負載壓力下的網路流量 QPS
- 伺服器選型(麒麟、曉龍、浪潮英信、華為、華三、戴爾(型別:刀片、塔式、機櫃))
以上需要計算費用成本,還需要考慮到該伺服器上的服務在執行時消耗的效能比例(需要預留給系統一部分資源)
服務本身環境的選擇
作業系統選擇
Linux 發行版:centos ubuntu redhat server debian alphon mac SUSE(PS:虛擬化 KVM XEN FUFE)基於作業系統,依賴環境。選擇最小化安裝還是指定作業系統版本的安裝 + 指定核心版本。軟體是否有依賴(例如:tomcat 需要 JDK,編譯需要 gcc gcc-c++ pcre …)
軟體資源優化
五大負載+核心優化(TCP協定相關、佇列相關、路由轉發、重定向、埠、檔案開啟數、系統的軟硬限制等)
2. 單例伺服器應用服務本身優化
以 redis 為例
首先從啟動讀取的恢復檔案來看,基於AOF需要開啟 AOF功能(RDB 預設)
- RDB 中 save M N 觸發週期的選擇判定,這會影響到磁碟資源的使用
- AOF 中選擇合適的 syncwrite 同步寫入磁碟的策略
everysecond
使用過程中,需要考慮到的是記憶體的使用量( OOM )
- 記憶體淘汰策略:惰性淘汰+定期刪除,禁止淘汰+定期刪除。根據情況選擇合適的淘汰策略(組態檔中定義)。
持久化方向
持久化的功能在保證資料完整性的同時,依然會持續性的對磁碟產生儲存壓力(壓力來源於 AOF 和 RDB 生成的資料檔案,AOF 和 RDB 的紀錄檔檔案)。
- 資料/紀錄檔檔案的定期歸檔
- 紀錄檔檔案的分割(儲存在紀錄檔中心)
- 共用儲存
NFS GFS fastDFS
redis主程序
- 可以使用兩個 redis 主程序配合實現備份冗餘,提高抗高並行的能力
推薦學習:
以上就是redis詳細解析主從複製、哨兵和叢集的詳細內容,更多請關注TW511.COM其它相關文章!