歸納整理Redis的六種底層資料結構

推薦學習:
1、簡單動態字串(SDS)
Redis 雖然是用 C 語言寫的,但Redis沒有直接使用C語言傳統的字串表示(以空字元 ‘\0’ 結尾的字元陣列),二是自己構建了一種名為簡單動態字串(simple dynamic string,SDS)的抽象型別,並將 SDS 作為 Redis的預設字串表示。
在Redis裡面,C字串只會作為字串字面量(string literal)用在一些無須對字串值進行修改的地方,比如列印紀錄檔。
SDS 的定義:
struct sdshdr{
//記錄buf陣列中已使用位元組的數量
//等於 SDS 所儲存字串的長度
int len;
//記錄 buf 陣列中未使用位元組的數量
int free;
//位元組陣列,用於儲存字串
char buf[];}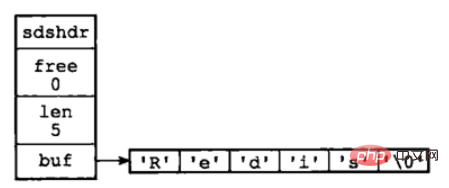
① free 屬性的值為 0,表示這個SDS沒有分配任何未使用的空間。
② len 屬性的值為 5,表示這個SDS儲存了一個五位元組長的字串。
③ buf 屬性是一個char 型別的陣列,陣列前五個位元組分別儲存了 ‘R’、‘e’、
‘d’、‘i’、‘s’ 五個字元,而最後一個位元組則儲存了空字元 ‘\0’ 。
(SDS遵循C字串以空字元結尾的慣例,儲存空字元的 1 位元組空間不計算在SDS的 len屬性裡面,並且為空字元分配額外的 1 位元組空間,以及新增空字元到字串末尾等操作,都是由SDS 函數自動完成的,所有這個空字元對於SDS的使用者來說是完全透明的。遵循空字元結尾這一慣例的好處是,SDS可以直接重用C字串函數庫裡面的函數。)
SDS 與 C 字浮串的區別:
(1)常數複雜度獲取字串長度
因為 C 字串並不記錄自身的長度資訊, 所以為了獲取一個 C 字串的長度, 程式必須遍歷整個字串, 對遇到的每個字元進行計數, 直到遇到代表字串結尾的空字元為止, 這個操作的複雜度為 O(N) 。
和 C 字串不同, 因為 SDS 在 len 屬性中記錄了 SDS 本身的長度, 所以獲取一個 SDS 長度的複雜度僅為 O(1) 。
(2)杜絕緩衝區溢位
我們知道在 C 語言中使用 strcat 函數來進行兩個字串的拼接,一旦沒有分配足夠長度的記憶體空間,就會造成緩衝區溢位。而對於 SDS 資料型別,在進行字元修改的時候,會首先根據記錄的 len 屬性檢查記憶體空間是否滿足需求,如果不滿足,會進行相應的空間擴充套件,然後在進行修改操作,所以不會出現緩衝區溢位。
(3)減少修改字串的記憶體重新分配次數
C語言由於不記錄字串的長度,所以如果要修改字串,必須要重新分配記憶體(先釋放再申請),因為如果沒有重新分配,字串長度增大時會造成記憶體緩衝區溢位,字串長度減小時會造成記憶體洩露。
而對於SDS,由於len屬性和free屬性的存在,對於修改字串SDS實現了空間預分配和惰性空間釋放兩種策略:
1、空間預分配:對字串進行空間擴充套件的時候,擴充套件的記憶體比實際需要的多,這樣可以減少連續執行字串增長操作所需的記憶體重分配次數。
2、惰性空間釋放:對字串進行縮短操作時,程式不立即使用記憶體重新分配來回收縮短後多餘的位元組,而是使用 free 屬性將這些位元組的數量記錄下來,等待後續使用。(當然SDS也提供了相應的API,當我們有需要時,也可以手動釋放這些未使用的空間)。
(4)二進位制安全
因為C字串以空字元作為字串結束的標識,而對於一些二進位制檔案(如圖片等),內容可能包括空字串,因此C字串無法正確存取;而所有 SDS 的API 都是以處理二進位制的方式來處理 buf 裡面的元素,並且 SDS 不是以空字串來判斷是否結束,而是以 len 屬性表示的長度來判斷字串是否結束。
(5)相容部分 C 字串函數
雖然 SDS 的 API 都是二進位制安全的, 但它們一樣遵循 C 字串以空字元結尾的慣例: 這些 API 總會將 SDS 儲存的資料的末尾設定為空字元, 並且總會在為 buf 陣列分配空間時多分配一個位元組來容納這個空字元, 這是為了讓那些儲存文字資料的 SDS 可以重用一部分 <string.h> 庫定義的函數。
(6)總結
2、連結串列
作為一種常用資料結構,連結串列內建在很多高階的程式語言裡面,因為Redis使用的 C 語言並沒有內建這種資料結構,所以 Redis 構建了自己的連結串列結構。
每個連結串列節點使用一個 adlist.h/listNode 結構來表示:
typedef struct listNode {
// 前置節點
struct listNode *prev;
// 後置節點
struct listNode *next;
// 節點的值
void *value;} listNode;多個 listNode 可以通過 prev 和 next 指標組成雙端連結串列, 如圖 3-1 所示。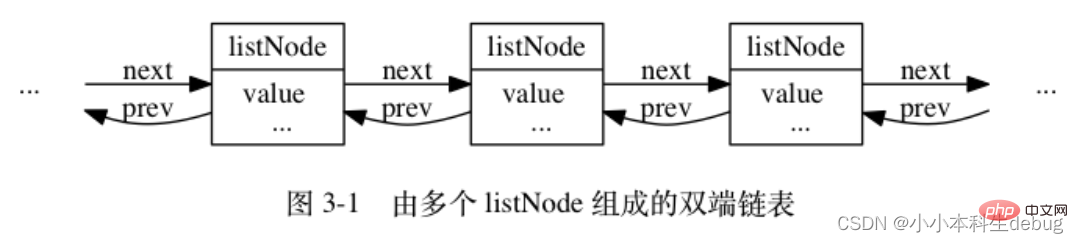
雖然僅僅使用多個 listNode 結構就可以組成連結串列, 但使用 adlist.h/list 來持有連結串列的話, 操作起來會更方便:
typedef struct list {
// 表頭節點
listNode *head;
// 表尾節點
listNode *tail;
// 連結串列所包含的節點數量
unsigned long len;
// 節點值複製函數
void *(*dup)(void *ptr);
// 節點值釋放函數
void (*free)(void *ptr);
// 節點值對比函數
int (*match)(void *ptr, void *key);} list;list 結構為連結串列提供了表頭指標 head 、表尾指標 tail , 以及連結串列長度計數器 len , 而 dup 、 free 和 match 成員則是用於實現多型連結串列所需的型別特定函數:
① dup 函數用於複製連結串列節點所儲存的值;
② free 函數用於釋放連結串列節點所儲存的值;
③ match 函數則用於對比連結串列節點所儲存的值和另一個輸入值是否相等。
圖 3-2 是由一個 list 結構和三個 listNode 結構組成的連結串列: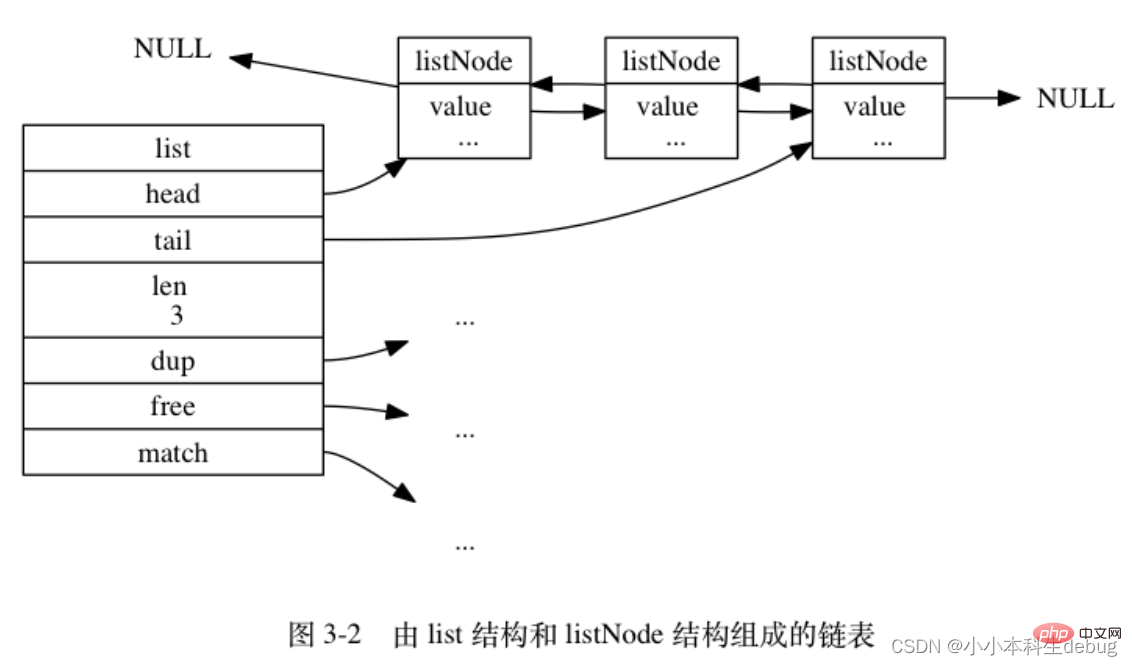
Redis 的連結串列實現的特性可以總結如下:
①雙端: 連結串列節點帶有 prev 和 next 指標, 獲取某個節點的前置節點和後置節點的複雜度都是 O(1) 。
②無環: 表頭節點的 prev 指標和表尾節點的 next 指標都指向 NULL , 對連結串列的存取以 NULL 為終點。
③帶表頭指標和表尾指標: 通過 list 結構的 head 指標和 tail 指標, 程式獲取連結串列的表頭節點和表尾節點的複雜度為 O(1) 。
④帶連結串列長度計數器: 程式使用 list 結構的 len 屬性來對 list 持有的連結串列節點進行計數, 程式獲取連結串列中節點數量的複雜度為 O(1) 。
⑤多型: 連結串列節點使用 void* 指標來儲存節點值, 並且可以通過 list 結構的 dup 、 free 、 match 三個屬性為節點值設定型別特定函數, 所以連結串列可以用於儲存各種不同型別的值。
3、字典
字典又稱為符號表或者關聯陣列、或對映(map),是一種用於儲存鍵值對的抽象資料結構。字典中的每一個鍵 key 都是唯一的,通過 key 可以對值來進行查詢或修改。C 語言中沒有內建這種資料結構的實現,所以字典依然是 Redis 自己構建的。
Redis 的字典使用雜湊表作為底層實現, 一個雜湊表裡面可以有多個雜湊表節點, 而每個雜湊表節點就儲存了字典中的一個鍵值對。
雜湊表
Redis 字典所使用的雜湊表由 dict.h/dictht 結構定義:
typedef struct dictht {
// 雜湊表陣列
dictEntry **table;
// 雜湊表大小
unsigned long size;
// 雜湊表大小掩碼,用於計算索引值
// 總是等於 size - 1
unsigned long sizemask;
// 該雜湊表已有節點的數量
unsigned long used;} dictht;圖 4-1 展示了一個大小為 4 的空雜湊表 (沒有包含任何鍵值對)。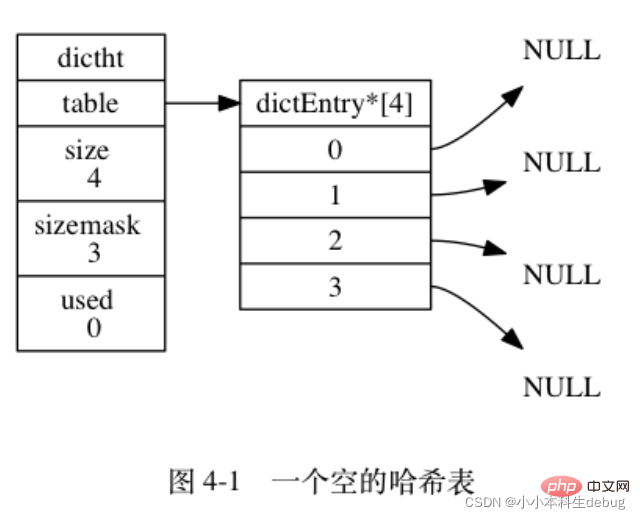
雜湊表節點
雜湊表節點使用 dictEntry 結構表示, 每個 dictEntry 結構都儲存著一個鍵值對:
typedef struct dictEntry {
// 鍵
void *key;
// 值
union {
void *val;
uint64_t u64;
int64_t s64;
} v;
// 指向下個雜湊表節點,形成連結串列
struct dictEntry *next;} dictEntry;key 用來儲存鍵,val 屬性用來儲存值,值可以是一個指標,也可以是uint64_t 整數,也可以是 int64_t 整數。
注意這裡還有一個指向下一個雜湊表節點的指標,我們知道雜湊表最大的問題是存在雜湊衝突,如何解決雜湊衝突,有開放地址法和鏈地址法。這裡採用的便是鏈地址法,通過 next 這個指標可以將多個雜湊值相同的鍵值對連線在一起,用來解決雜湊衝突。
(因為 dictEntry 節點組成的連結串列沒有指向連結串列表尾的指標, 所以為了速度考慮, 程式總是將新節點新增到連結串列的表頭位置(複雜度為 O(1)), 排在其他已有節點的前面。)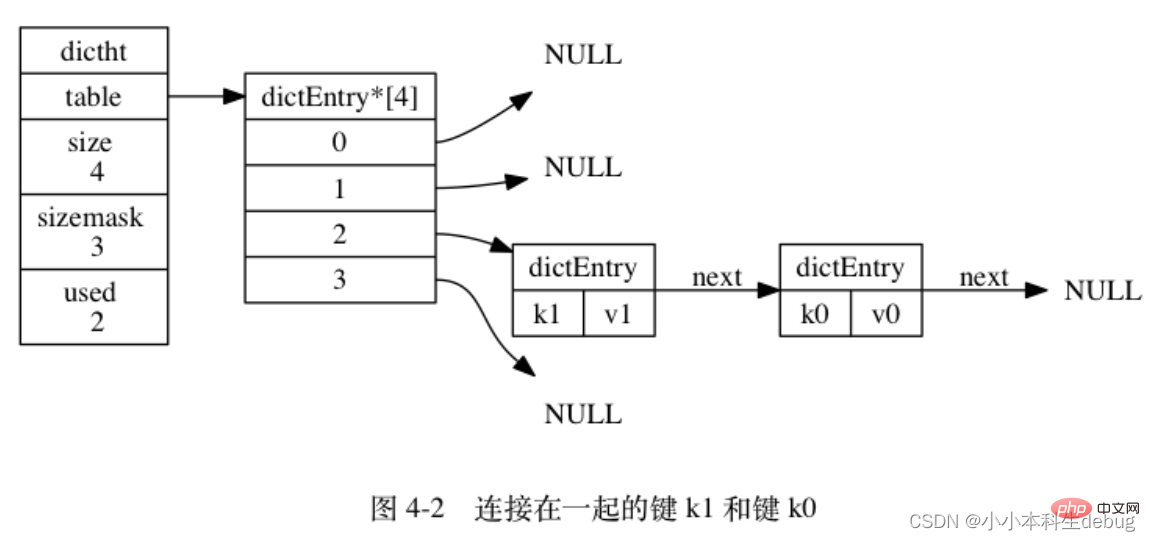
字典
Redis 中的字典由 dict.h/dict 結構表示:
typedef struct dict {
// 型別特定函數
dictType *type;
// 私有資料
void *privdata;
// 雜湊表
dictht ht[2];
// rehash 索引
// 當 rehash 不在進行時,值為 -1
int rehashidx;
/* rehashing not in progress if rehashidx == -1 */} dict;type 屬性和 privdata 屬性是針對不同型別的鍵值對, 為建立多型字典而設定的:
● type 屬性是一個指向 dictType 結構的指標, 每個 dictType 結構儲存了一簇用於操作特定型別鍵值對的函數, Redis 會為用途不同的字典設定不同的型別特定函數。
● 而 privdata 屬性則儲存了需要傳給那些型別特定函數的可選引數。
typedef struct dictType {
// 計算雜湊值的函數
unsigned int (*hashFunction)(const void *key);
// 複製鍵的函數
void *(*keyDup)(void *privdata, const void *key);
// 複製值的函數
void *(*valDup)(void *privdata, const void *obj);
// 對比鍵的函數
int (*keyCompare)(void *privdata, const void *key1, const void *key2);
// 銷燬鍵的函數
void (*keyDestructor)(void *privdata, void *key);
// 銷燬值的函數
void (*valDestructor)(void *privdata, void *obj);} dictType;ht 屬性是一個包含兩個項的陣列, 陣列中的每個項都是一個 dictht 雜湊表, 一般情況下, 字典只使用 ht[0] 雜湊表, ht[1] 雜湊表只會在對 ht[0] 雜湊表進行 rehash 時使用。
除了 ht[1] 之外, 另一個和 rehash 有關的屬性就是 rehashidx : 它記錄了 rehash 目前的進度, 如果目前沒有在進行 rehash , 那麼它的值為 -1 。
圖 4-3 展示了一個普通狀態下(沒有進行 rehash)的字典: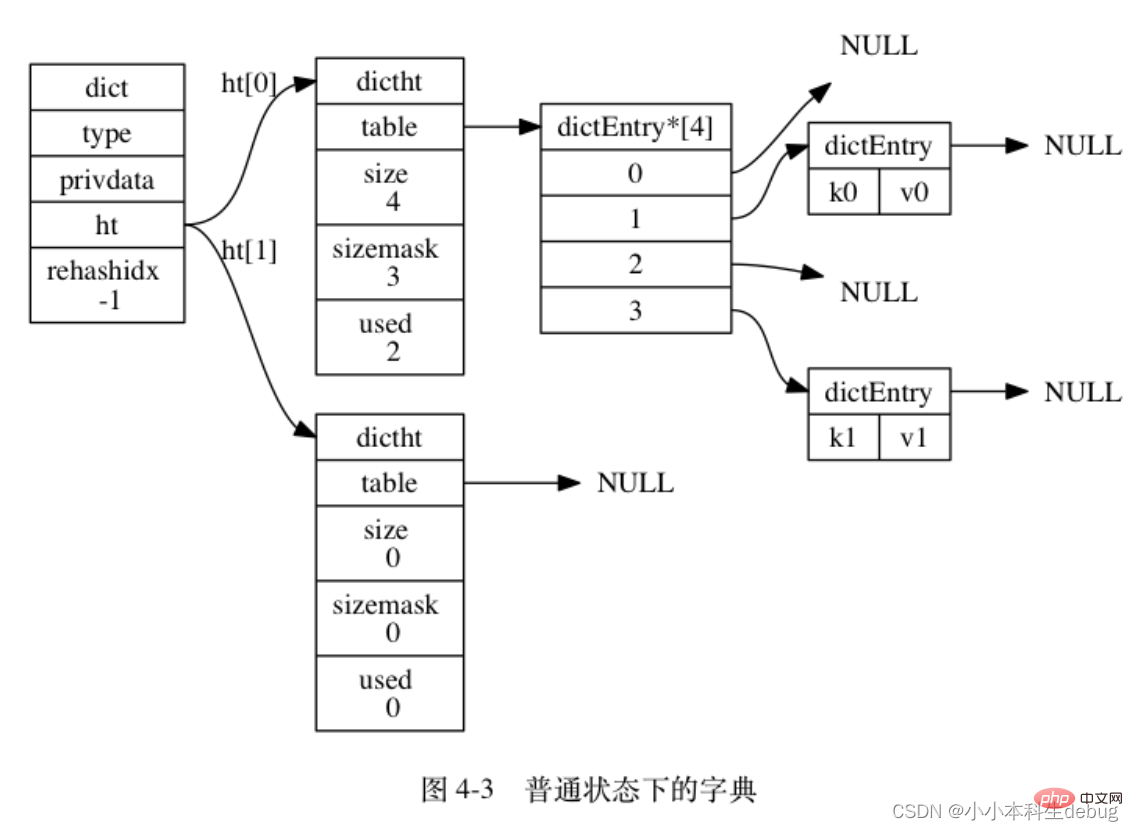
① 雜湊演演算法:Redis計算雜湊值和索引值方法如下:
# 使用字典設定的雜湊函數,計算鍵 key 的雜湊值 hash = dict->type->hashFunction(key);# 使用雜湊表的 sizemask 屬性和雜湊值,計算出索引值 # 根據情況不同, ht[x] 可以是 ht[0] 或者 ht[1]index = hash & dict->ht[x].sizemask;
②解決雜湊衝突:這個問題上面我們介紹了,方法是鏈地址法。通過字典裡面的 *next 指標指向下一個具有相同索引值的雜湊表節點。
③擴容和收縮(rehash):當雜湊表儲存的鍵值對太多或者太少時,就要通過 rerehash(重新雜湊)來對雜湊表進行相應的擴充套件或者收縮。具體步驟:
1、為字典的 ht[1] 雜湊表分配空間, 這個雜湊表的空間大小取決於要執行的操作, 以及 ht[0] 當前包含的鍵值對數量 (也即是 ht[0].used 屬性的值)
● 如果執行的是擴充套件操作, 那麼 ht[1] 的大小為第一個大於等於 ht[0].used * 2n; (也就是每次擴充套件都是根據原雜湊表已使用的空間擴大一倍建立另一個雜湊表)
● 如果執行的是收縮操作, 每次收縮是根據已使用空間縮小一倍建立一個新的雜湊表。
2、將儲存在 ht[0] 中的所有鍵值對 rehash 到 ht[1] 上面: rehash 指的是重新計算鍵的雜湊值和索引值, 然後將鍵值對放置到 ht[1] 雜湊表的指定位置上。
3、當 ht[0] 包含的所有鍵值對都遷移到了 ht[1] 之後 (ht[0] 變為空表), 釋放 ht[0] , 將 ht[1] 設定為 ht[0] , 並在 ht[1] 新建立一個空白雜湊表, 為下一次 rehash 做準備。
④觸發擴容與收縮的條件:
1、伺服器目前沒有執行 BGSAVE 命令或者 BGREWRITEAOF 命令,並且負載因子大於等於1。
2、伺服器目前正在執行 BGSAVE 命令或者 BGREWRITEAOF 命令,並且負載因子大於等於5。
ps:負載因子 = 雜湊表已儲存節點數量 / 雜湊表大小。
3、另一方面, 當雜湊表的負載因子小於 0.1 時, 程式自動開始對雜湊表執行收縮操作。
⑤漸近式 rehash
什麼叫漸進式 rehash?也就是說擴容和收縮操作不是一次性、集中式完成的,而是分多次、漸進式完成的。如果儲存在Redis中的鍵值對只有幾個幾十個,那麼 rehash 操作可以瞬間完成,但是如果鍵值對有幾百萬,幾千萬甚至幾億,那麼要一次性的進行 rehash,勢必會造成Redis一段時間內不能進行別的操作。所以Redis採用漸進式 rehash,這樣在進行漸進式rehash期間,字典的刪除查詢更新等操作可能會在兩個雜湊表上進行,第一個雜湊表沒有找到,就會去第二個雜湊表上進行查詢。但是進行增加操作,一定是在新的雜湊表上進行的。
4、跳躍表
跳躍表(skiplist)是一種有序資料結構,它通過在每個節點中維持多個指向其它節點的指標,從而達到快速存取節點的目的。
具有如下性質:
1、由很多層結構組成;
2、每一層都是一個有序的連結串列,排列順序為由高層到底層,都至少包含兩個連結串列節點,分別是前面的head節點和後面的nil節點;
3、最底層的連結串列包含了所有的元素;
4、如果一個元素出現在某一層的連結串列中,那麼在該層之下的連結串列也全都會出現(上一層的元素是當前層的元素的子集);
5、連結串列中的每個節點都包含兩個指標,一個指向同一層的下一個連結串列節點,另一個指向下一層的同一個連結串列節點;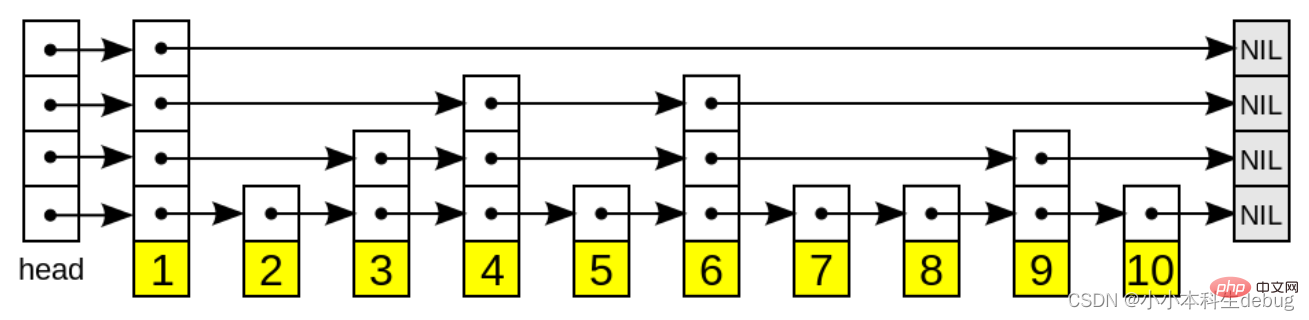
和連結串列、字典等資料結構被廣泛地應用在 Redis 內部不同, Redis 只在兩個地方用到了跳躍表, 一個是實現有序集合鍵, 另一個是在叢集節點中用作內部資料結構, 除此之外, 跳躍表在 Redis 裡面沒有其他用途。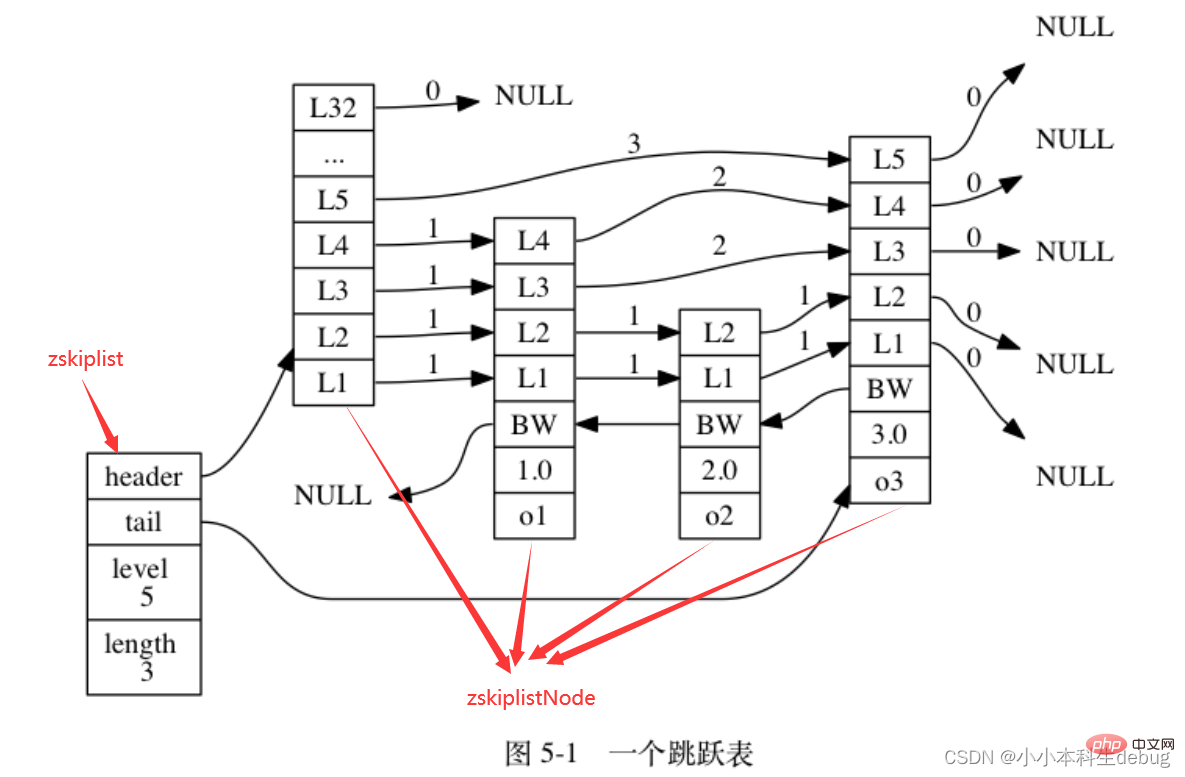
跳躍表節點(zskiplistNode)
該結構包含以下屬性:
①層(level):節點中用 L1 、 L2 、 L3 等字樣標記節點的各個層, L1 代表第一層, L2 代表第二層,以此類推。每個層都帶有兩個屬性:前進指標和跨度。前進指標用於存取位於表尾方向的其他節點,而跨度則記錄了前進指標所指向節點和當前節點的距離。在上面的圖片中,連線上帶有數位的箭頭就代表前進指標,而那個數位就是跨度。當程式從表頭向表尾進行遍歷時,存取會沿著層的前進指標進行。
每次建立一個新跳躍表節點的時候, 程式都根據冪次定律 (power law,越大的數出現的概率越小) 隨機生成一個介於 1 和 32 之間的值作為 level 陣列的大小, 這個大小就是層的「高度」。(所以說表頭節點的高度就是32)
②後退(backward)指標:節點中用 BW 字樣標記節點的後退指標,它指向位於當前節點的前一個節點。後退指標在程式從表尾向表頭遍歷時使用。
③分值(score):各個節點中的 1.0 、 2.0 和 3.0 是節點所儲存的分值。在跳躍表中,節點按各自所儲存的分值從小到大排列。
④成員物件(obj):各個節點中的 o1 、 o2 和 o3 是節點所儲存的成員物件。
注意表頭節點和其他節點的構造是一樣的: 表頭節點也有後退指標、分值和成員物件, 不過表頭節點的這些屬性都不會被用到, 所以圖中省略了這些部分, 只顯示了表頭節點的各個層。
跳躍表(zskiplist)
① header :指向跳躍表的表頭節點。
② tail :指向跳躍表的表尾節點。
③ level :記錄目前跳躍表內,層數最大的那個節點的層數(表頭節點的層數不計算在內)。
④ length :記錄跳躍表的長度,也即是,跳躍表目前包含節點的數量(表頭節點不計算在內)。
5、整數集合
整數集合(intset)是集合鍵的底層實現之一,當一個集合只包含整數值元素,並且這個集合的元素數量不多時,Redis就會使用集合作為集合鍵的底層實現。
整數集合(intset)是Redis用於儲存整數值的集合抽象資料型別,它可以儲存型別為int16_t、int32_t 或者int64_t 的整數值,並且保證集合中不會出現重複元素。
每個 intset.h/intset 結構表示一個整數集合:
typedef struct intset {
// 編碼方式
uint32_t encoding;
// 集合包含的元素數量
uint32_t length;
// 儲存元素的陣列
int8_t contents[];} intset;整數集合的每個元素都是 contents 陣列的一個資料項,它們按照從小到大的順序排列,並且不包含任何重複項。
length 屬性記錄了 contents 陣列的大小。
需要注意的是雖然 contents 陣列宣告為 int8_t 型別,但是實際上contents 陣列並不儲存任何 int8_t 型別的值,其真正型別有 encoding 來決定。
① 升級(encoding int16_t -> int32_t -> int64_t)
當我們新增的元素型別比原集合元素型別的長度要大時,需要對整數集合進行升級,才能將新元素放入整數集合中。具體步驟:
1、根據新元素型別,擴充套件整數集合底層陣列的大小,併為新元素分配空間。
2、將底層陣列現有的所有元素都轉成與新元素相同型別的元素,並將轉換後的元素放到正確的位置,放置過程中,維持整個元素順序都是有序的。
3、將新元素新增到整數集合中(保證有序)。
升級能極大地節省記憶體。
② 降級
整數集合不支援降級操作,一旦對陣列進行了升級,編碼就會一直保持升級後的狀態。
6、壓縮列表
壓縮列表(ziplist)是列表鍵和雜湊鍵的底層實現之一。
當一個列表鍵只包含少量列表項, 並且每個列表項要麼就是小整數值, 要麼就是長度比較短的字串, 那麼 Redis 就會使用壓縮列表來做列表鍵的底層實現。
因為雜湊鍵裡面包含的所有鍵和值都是小整數值或者短字串。
壓縮列表是 Redis 為了節約記憶體而開發的, 由一系列特殊編碼的連續記憶體塊組成的順序型(sequential)資料結構。
一個壓縮列表可以包含任意多個節點(entry), 每個節點可以儲存一個位元組陣列或者一個整數值。
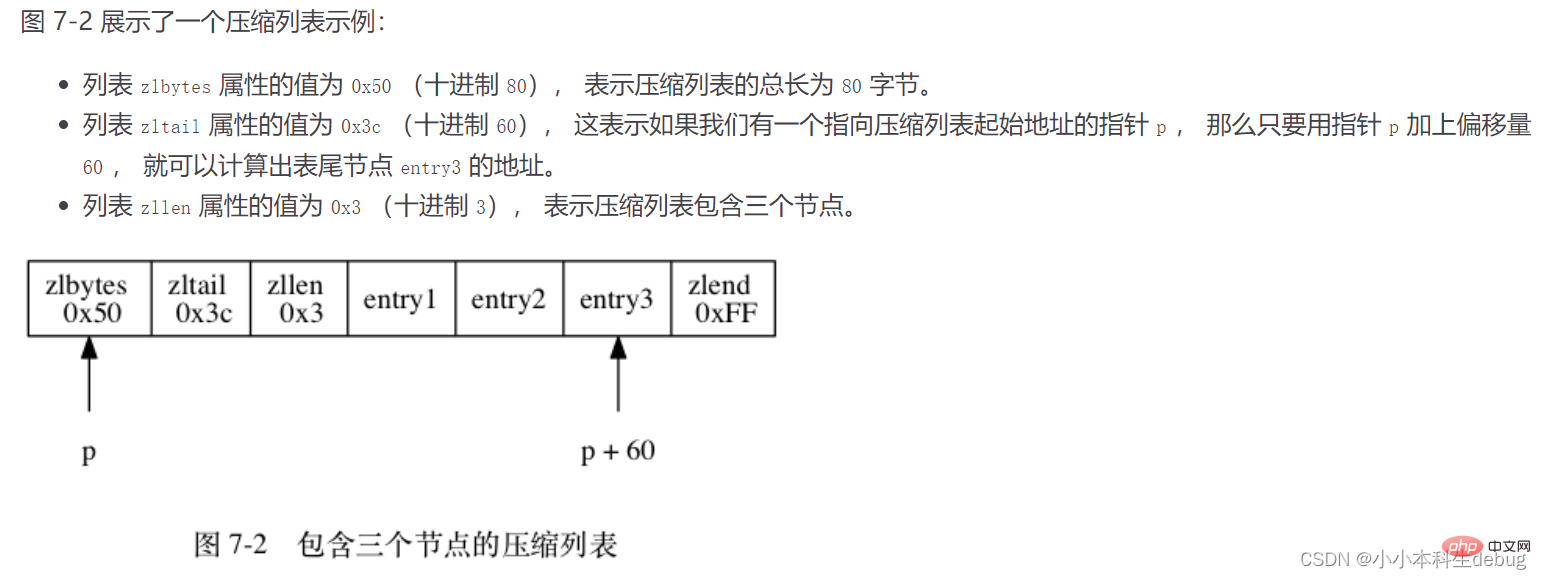
每個壓縮列表節點都由 previous_entry_length 、 encoding 、 content 三個部分組成
① previous_entry_ength:記錄壓縮列表前一個位元組的長度。previous_entry_ength 的長度可能是1個位元組或者是5個位元組。如果上一個節點的長度小於254,則該節點只需要一個位元組就可以表示前一個節點的長度了。如果前一個節點的長度大於等於254,則屬性的第一個位元組為254,後面用四個位元組表示當前節點前一個節點的長度。利用此原理即當前節點位置減去上一個節點的長度即得到上一個節點的起始位置,壓縮列表可以從尾部向頭部遍歷。這麼做很有效地減少了記憶體的浪費。
② encoding:節點的encoding儲存的是節點的content的內容型別以及長度,encoding型別一共有兩種,一種位元組陣列一種是整數,encoding區域長度為1位元組、2位元組或者5位元組長。
③ content:content區域用於儲存節點的內容,節點內容型別和長度由encoding決定。
連鎖更新問題
連鎖更新在最壞情況下需要對壓縮列表執行 N 次空間重分配操作, 而每次空間重分配的最壞複雜度為 O(N) , 所以連鎖更新的最壞複雜度為 O(N^2) 。
要注意的是, 儘管連鎖更新的複雜度較高, 但它真正造成效能問題的機率是很低的
推薦學習:
以上就是歸納整理Redis的六種底層資料結構的詳細內容,更多請關注TW511.COM其它相關文章!