歸納總結Python常用模組大全

推薦學習:
一、時間模組time() 與 datetime()
time()模組中的重要函數

time()模組時間格式轉換
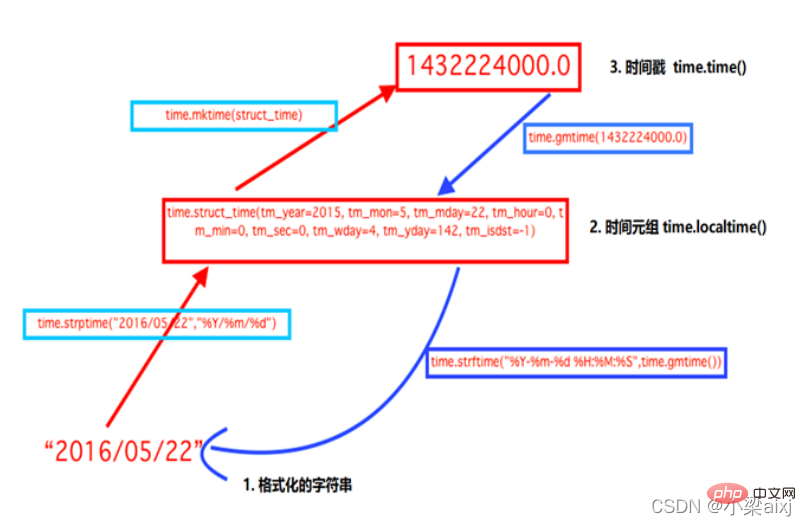
time()模組時間轉換
時間戳 1970年1月1日之後的秒, 即:time.time()
格式化的字串 2014-11-11 11:11, 即:time.strftime(’%Y-%m-%d’)
結構化時間 元組包含了:年、日、星期等… time.struct_time 即:time.localtime()
import time print(time.time()) # 時間戳:1511166937.2178104 print(time.strftime('%Y-%m-%d')) # 格式化的字串: 2017-11-20 print(time.localtime()) # 結構化時間(元組): (tm_year=2017, tm_mon=11...) print(time.gmtime()) # 將時間轉換成utc格式的元組格式: (tm_year=2017, tm_mon=11...) #1. 將結構化時間轉換成時間戳: 1511167004.0 print(time.mktime(time.localtime()))#2. 將格字串時間轉換成結構化時間 元組: (tm_year=2017, tm_mon=11...) print(time.strptime('2014-11-11', '%Y-%m-%d'))#3. 結構化時間(元組) 轉換成 字串時間 :2017-11-20 print(time.strftime('%Y-%m-%d', time.localtime())) # 預設當前時間#4. 將結構化時間(元組) 轉換成英文字串時間 : Mon Nov 20 16:51:28 2017 print(time.asctime(time.localtime()))
#5. 將時間戳轉成 英文字串時間 : Mon Nov 20 16:51:28 2017 print(time.ctime(time.time()))
ctime和asctime區別
1)ctime傳入的是以秒計時的時間戳轉換成格式化時間
2)asctime傳入的是時間元組轉換成格式化時間
import time t1 = time.time() print(t1) #1483495728.4734166 print(time.ctime(t1)) #Wed Jan 4 10:08:48 2017 t2 = time.localtime() print(t2) #time.struct_time(tm_year=2017, tm_mon=1, tm_mday=4, tm_hour=10, print(time.asctime(t2)) #Wed Jan 4 10:08:48 2017
datetime獲取時間
import datetime
#1、datetime.datetime獲取當前時間
print(datetime.datetime.now())
#2、獲取三天後的時間
print(datetime.datetime.now()+datetime.timedelta(+3))
#3、獲取三天前的時間
print(datetime.datetime.now()+datetime.timedelta(-3))
#4、獲取三個小時後的時間
print(datetime.datetime.now()+datetime.timedelta(hours=3))
#5、獲取三分鐘以前的時間
print(datetime.datetime.now()+datetime.timedelta(minutes = -3))
import datetime
print(datetime.datetime.now()) #2017-08-18
11:25:52.618873
print(datetime.datetime.now().date()) #2017-08-18
print(datetime.datetime.now().strftime("%Y-%m-%d %H-%M-%S"))
#2017-08-18 11-25-52datetime時間轉換
#1、datetime物件與str轉化
# datetime.datetime.now().strftime("%Y-%m-%d %H:%M:%S")
'2018-03-09 10:08:50'
# datetime.datetime.strptime('2016-02-22',"%Y-%m-%d")
datetime.datetime(2016, 2, 22, 0, 0)#2、datetime物件轉時間元組 # datetime.datetime.now().timetuple() time.struct_time(tm_year=2018, tm_mon=3, tm_mday=9,
#3、時間戳轉換成datetime物件 # datetime.datetime.fromtimestamp(1520561646.8906238) datetime.datetime(2018, 3, 9, 10, 14, 6, 890624)
本地時間與utc時間相互轉換
# 本地時間與utc時間相互轉換
import time
import datetime
def utc2local(utc_st):
''' 作用:將UTC時間裝換成本地時間
:param utc_st: 傳入的是utc時間(datatime物件)
:return: 返回的是本地時間 datetime 物件
'''
now_stamp = time.time()
local_time = datetime.datetime.fromtimestamp(now_stamp)
utc_time = datetime.datetime.utcfromtimestamp(now_stamp)
offset = local_time - utc_time
local_st = utc_st + offset
return local_st
def local2utc(local_st):
''' 作用:將本地時間轉換成UTC時間
:param local_st: 傳入的是本地時間(datatime物件)
:return: 返回的是utc時間 datetime 物件
'''
time_struct = time.mktime(local_st.timetuple())
utc_st = datetime.datetime.utcfromtimestamp(time_struct)
return utc_st
utc_time = datetime.datetime.utcfromtimestamp(time.time())
# utc_time = datetime.datetime(2018, 5, 6, 5, 57, 9, 511870) # 比北京時間
晚了8個小時
local_time = datetime.datetime.now()
# local_time = datetime.datetime(2018, 5, 6, 13, 59, 27, 120771) # 北京本地時間
utc_to_local = utc2local(utc_time)
local_to_utc = local2utc(local_time)
print utc_to_local # 2018-05-06 14:02:30.650270 已經轉換成了北京本地時間
print local_to_utc # 2018-05-06 06:02:30 轉換成北京當地時間django的timezone時間與本地時間轉換
# django的timezone時間與本地時間轉換 from django.utils import timezone from datetime import datetime utc_time = timezone.now() local_time = datetime.now() #1、utc時間裝換成本地時間 utc_to_local = timezone.localtime(timezone.now())
#2、本地時間裝utc時間 local_to_utc = timezone.make_aware(datetime.now(), timezone.get_current_timezone())
Python計算兩個日期之間天數
import datetime d1 = datetime.datetime(2018,10,31) # 第一個日期 d2 = datetime.datetime(2019,2,2) # 第二個日期 interval = d2 - d1 # 兩日期差距 print(interval.days) # 具體的天數
二、random()模組
random()模組常用函數
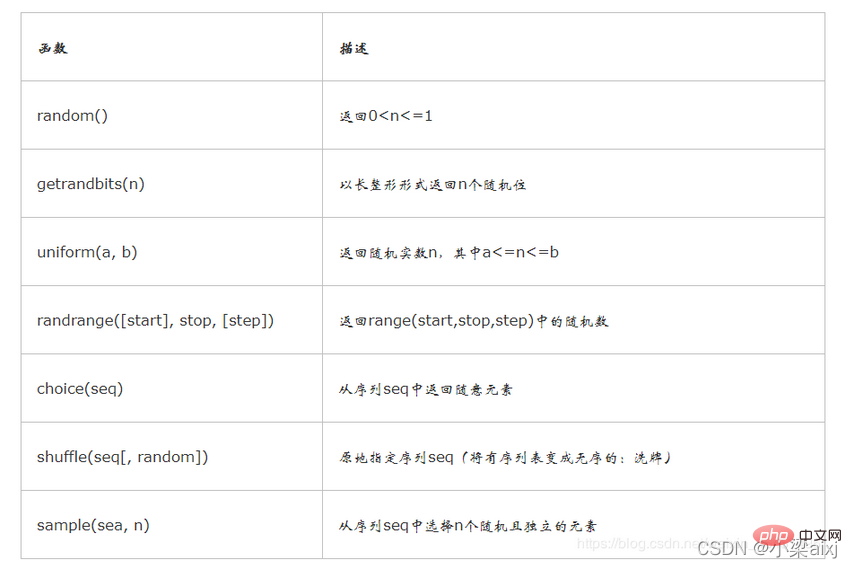
random常用函數舉例
import random #⒈ 隨機整數: print(random.randint(0,99)) # 隨機選取0-99之間的整數 print(random.randrange(0, 101, 2)) # 隨機選取0-101之間的偶數
#⒉ 隨機浮點數: print(random.random()) # 0.972654134347 print(random.uniform(1, 10)) # 4.14709813772
#⒊ 隨機字元:
print(random.choice('abcdefg')) # c
print(random.sample('abcdefghij',3)) # ['j', 'f', 'c']使用random實現四位驗證碼
1.使用for迴圈實現
#使用for迴圈實現
import random
checkcode = ''
for i in range(4):
current = random.randrange(0,4)
if current == i:
tmp = chr(random.randint(65,90)) #65,90表示所有大寫字母
else:
tmp = random.randint(0,9)
checkcode += str(tmp)
print(checkcode) #執行結果: 851K2.使用random.sample實現
import random import string str_source = string.ascii_letters + string.digits str_list = random.sample(str_source,7) #['i', 'Q', 'U', 'u', 'A', '0', '9'] print(str_list) str_final = ''.join(str_list) #iQUuA09 print(str_final) # 執行結果: jkFU2Ed
三、os模組
os模組常用方法
import os #1 當前工作目錄,即當前python指令碼工作的目錄路徑 print(os.getcwd()) # C:\Users\admin\PycharmProjects\s14\Day5\test4
#2 當前指令碼工作目錄;相當於shell下cd
os.chdir("C:\\Users\\admin\\PycharmProjects\\s14")
os.chdir(r"C:\Users\admin\PycharmProjects\s14")
print(os.getcwd()) # C:\Users\admin\PycharmProjects\s14#3 返回當前目錄: ('.')
print(os.curdir) # ('.')#4 獲取當前目錄的父目錄字串名:('..')
print(os.pardir) # ('..')#5 可生成多層遞迴目錄 os.makedirs(r'C:\aaa\bbb') # 可以發現在C槽建立了資料夾/aaa/bbb
#6 若目錄為空,則刪除,並遞迴到上一級目錄,如若也為空,則刪除,依此類推 os.removedirs(r'C:\aaa\bbb') # 刪除所有空目錄
#7 生成單級目錄;相當於shell中mkdir dirname os.mkdir(r'C:\bbb') # 僅能建立單個目錄
#8 刪除單級空目錄,若目錄不為空則無法刪除,報錯;相當於shell中rmdir dirname os.rmdir(r'C:\aaa') # 僅刪除指定的一個空目錄
#9 列出指定目錄下的所有檔案和子目錄,包括隱藏檔案,並以列表方式列印 print(os.listdir(r"C:\Users\admin\PycharmProjects\s14"))
#10 刪除一個檔案 os.remove(r'C:\bbb\test.txt') # 指定刪除test.txt檔案
#11 重新命名檔案/目錄 os.rename(r'C:\bbb\test.txt',r'C:\bbb\test00.bak')
#12 獲取檔案/目錄資訊 print(os.stat(r'C:\bbb\test.txt'))
#13 輸出作業系統特定的路徑分隔符,win下為"\\",Linux下為"/" print(os.sep) # \
#14 輸出當前平臺使用的行終止符,win下為"\r\n",Linux下為"\n" print(os.linesep)
#15 輸出用於分割檔案路徑的字串 print(os.pathsep) # ; (分號)
#16 輸出字串指示當前使用平臺。win->'nt'; Linux->'posix' print(os.name) # nt
#17 執行shell命令,直接顯示
os.system("bash command")#18 獲取系統環境變數
print(os.environ) # environ({'OS': 'Windows_NT', 'PUBLIC': ………….#19 返回path規範化的絕對路徑 print(os.path.abspath(r'C:/bbb/test.txt')) # C:\bbb\test.txt
#20 將path分割成目錄和檔名二元組返回
print(os.path.split(r'C:/bbb/ccc')) # ('C:/bbb', 'ccc')#21 返回path的目錄。其實就是os.path.split(path)的第一個元素 print(os.path.dirname(r'C:/bbb/ccc')) # C:/bbb
#22 返回path最後的檔名。如何path以/或\結尾,那麼就會返回空值。即 os.path.split(path)的第二個元素 print(os.path.basename(r'C:/bbb/ccc/ddd')) # ddd
#23 如果path存在,返回True;如果path不存在,返回False print(os.path.exists(r'C:/bbb/ccc/')) # True
#24 如果path是絕對路徑,返回True # True print(os.path.isabs(r"C:\Users\admin\PycharmProjects\s14\Day5\test4"))
#25 如果path是一個存在的檔案,返回True。否則返回False print(os.path.isfile(r'C:/bbb/ccc/test2.txt')) # True
#26 如果path是一個存在的目錄,則返回True。否則返回False print(os.path.isdir(r'C:/bbb/ccc')) # True
#28 返回path所指向的檔案或者目錄的最後存取時間 print(os.path.getatime(r'C:/bbb/ccc/test2.txt')) # 1483509254.9647143
#29 返回path所指向的檔案或者目錄的最後修改時間 print(os.path.getmtime(r'C:/bbb/ccc/test2.txt')) # 1483510068.746478
#30 無論linux還是windows,拼接出檔案路徑 put_filename = '%s%s%s'%(self.home,os. path.sep, filename) #C:\Users\admin\PycharmProjects\s14\day10select版FTP\home
os命令建立資料夾: C:/aaa/bbb/ccc/ddd並寫入檔案file1.txt
import os
os.makedirs('C:/aaa/bbb/ccc/ddd',exist_ok=True) # exist_ok=True:如果存
在當前資料夾不報錯
path = os.path.join('C:/aaa/bbb/ccc','ddd',)
f_path = os.path.join(path,'file.txt')
with open(f_path,'w',encoding='utf8') as f:
f.write('are you ok!!')將其他目錄的絕對路徑動態的新增到pyhton的環境變數中
import os,sys print(os.path.dirname( os.path.dirname( os.path.abspath(__file__) ) )) BASE_DIR = os.path.dirname( os.path.dirname( os.path.abspath(__file__) ) ) sys.path.append(BASE_DIR) # 程式碼解釋: # 要想匯入其他目錄中的函數,其實就是將其他目錄的絕對路徑動態的新增到 pyhton的環境變數中,這樣python直譯器就能夠在執行時找到匯入的模組而不報 錯: # 然後呼叫sys模組sys.path.append(BASE_DIR)就可以將這條路徑新增到python 環境變數中
os.popen獲取指令碼執行結果
1.data.py
data = {'name':'aaa'}
import json
print json.dumps(data)2.get_data.py
#! /usr/bin/env python
# -*- coding: utf-8 -*-
import os,json
ret = os.popen('python data.py')
data = ret.read().strip()
ret.close()
data = json.loads(data)
print data # {'name':'aaa'}四、sys模組
1、 sys基本方法
sys.argv 返回執行指令碼傳入的引數 sys.exit(n) 退出程式,正常退出時exit(0) sys.version 獲取Python解釋程式的版本資訊 sys.maxint 最大的Int值 sys.path 返回模組的搜尋路徑,初始化時使用PYTHONPATH環境變數的值 sys.platform 返回作業系統平臺名稱 sys.stdout.write(‘please:’) val = sys.stdin.readline()[:-1]
2、使用sys返回執行指令碼引數
import sys # C:\Users\tom\PycharmProjects\s14Review\day01> python test01.py 1 2 3 print(sys.argv) # 列印所有引數 ['test01.py', '1', '2', '3'] print(sys.argv[1:]) # 獲取索引 1 往後的所有引數 ['1', '2', '3']
tarfile用於將資料夾歸檔成 .tar的檔案
tarfile使用
import tarfile
# 將資料夾Day1和Day2歸檔成your.rar並且在歸檔資料夾中Day1和Day2分別變成
bbs2.zip和ccdb.zip的壓縮檔案
tar = tarfile.open('your.tar','w')
tar.add(r'C:\Users\admin\PycharmProjects\s14\Day1', arcname='bbs2.zip')
tar.add(r'C:\Users\admin\PycharmProjects\s14\Day2', arcname='cmdb.zip')
tar.close()# 將剛剛的歸檔檔案your.tar進行解壓解壓的內容是bbs2.zip和cmdb.zip壓縮檔案
而不是變成原有的資料夾
tar = tarfile.open('your.tar','r')
tar.extractall() # 可設定解壓地址
tar.close()shutil 建立壓縮包,複製,移動檔案
注 : shutil 對壓縮包的處理是呼叫 ZipFile 和 TarFile 兩個模組來進行的 作用: shutil 建立壓縮包並返回檔案路徑(如:zip、tar),並且可以複製檔案,移動檔案
shutil使用
import shutil
#1 copyfileobj() 將檔案test11.txt中的內容複製到test22.txt檔案中
f1 = open("test11.txt",encoding="utf-8")
f2 = open("test22.txt",'w',encoding="utf-8")
shutil.copyfileobj(f1,f2)#2 copyfile() 直接指定檔名就可進行復制
shutil.copyfile("test11.txt",'test33.txt')#3 shutil.copymode(src, dst) 僅拷貝許可權。內容、組、使用者均不變
#4 shutil.copystat(src, dst) 拷貝狀態的資訊,包括:mode bits, atime, mtime,
flags
shutil.copystat('test11.txt','test44.txt')#5 遞迴的去拷貝目錄中的所有目錄和檔案,這裡的test_dir是一個資料夾,包含多
級資料夾和檔案
shutil.copytree("test_dir","new_test_dir")#6 遞迴的去刪除目錄中的所有目錄和檔案,這裡的test_dir是一個資料夾,包含多
級資料夾和檔案
shutil.rmtree("test_dir")#7 shutil.move(src, dst) 遞迴的去移動檔案
shutil.move('os_test.py',r'C:\\')#8 shutil.make_archive(base_name, format,...) 建立壓縮包並返回檔案路徑,例 如:zip、tar ' ' '
- base_name: 壓縮包的檔名,也可以是壓縮包的路徑。只是檔名時,則儲存至當前目錄,否則儲存至指定路徑,
如:www =>儲存至當前路徑
如:/Users/wupeiqi/www =>儲存至/Users/wupeiqi/ - format: 壓縮包種類,「zip」, 「tar」, 「bztar」,「gztar」
- root_dir: 要壓縮的資料夾路徑(預設當前目錄)
- owner: 使用者,預設當前使用者
- group: 組,預設當前組
- logger: 用於記錄紀錄檔,通常是logging.Logger物件
’ ’ ’
#將C:\Users\admin\PycharmProjects\s14\Day4 的資料夾壓縮成 testaa.zip
shutil.make_archive("testaa","zip",r"C:\Users\admin\PycharmProjects
\s14\Day4")zipfile將檔案或資料夾進行壓縮
zipfile使用
import zipfile
#將檔案main.py和test11.py壓縮成day5.zip的壓縮檔案
z = zipfile.ZipFile('day5.zip', 'w')
z.write('main.py')
z.write("test11.txt")
z.close()#將剛剛壓縮的day5.zip檔案進行解壓成原檔案
z = zipfile.ZipFile('day5.zip', 'r')
z.extractall()
z.close()五、shelve 模組
作用:shelve模組是一個簡單的k,v將記憶體資料通過檔案持久化的模組,可以持久化任何pickle可支援的python資料格式
shelve持久化
import shelve
import datetime
#1 首先使用shelve將.py中定義的字典列表等讀取到指定檔案shelve_test中,其
實我們可不必關心在檔案中是怎樣儲存的
d = shelve.open('shelve_test') #開啟一個檔案
info = {"age":22,"job":"it"}
name = ["alex","rain","test"]
d["name"] = name #持久化列表
d["info"] = info
d["date"] = datetime.datetime.now()
d.close()#2 在這裡我們可以將剛剛讀取到 shelve_test檔案中的內容從新獲取出來
d = shelve.open('shelve_test') # 開啟一個檔案
print(d.get("name")) # ['alex', 'rain', 'test']
print(d.get("info")) # {'job': 'it', 'age': 22}
print(d.get("date")) # 2017-11-20 17:54:21.223410json和pickle序列化
1、json序列化
序列化 (json.dumps) :是將記憶體中的物件儲存到硬碟,變成字串
反序列化(json.loads) : 將剛剛儲存在硬碟中的記憶體物件從新載入到記憶體中
json.dumps( data,ensure_ascii=False, indent=4)
json序列化
#json序列化程式碼
import json
info = {
'name':"tom",
"age" :"100"
}
f = open("test.txt",'w')
# print(json.dumps(info))
f.write(json.dumps(info))
f.close()json反序列化
#json反序列化程式碼
import json
f = open("test.txt","r")
data = json.loads(f.read())
f.close()
print(data["age"])2、pickle序列化
python的pickle模組實現了python的所有資料序列和反序列化。基本上功能使用和JSON模組沒有太大區別,方法也同樣是dumps/dump和loads/load
與JSON不同的是pickle不是用於多種語言間的資料傳輸,它僅作為python物件的持久化或者python程式間進行互相傳輸物件的方法,因此它支援了python所有的資料型別。
pickle序列化
#pickle序列化程式碼
import pickle
info = {
'name':"tom",
"age" :"100"
}
f = open("test.txt",'wb')
f.write(pickle.dumps(info))
f.close()pickle反序列化
#pickle反序列化程式碼
import pickle
f = open("test.txt","rb")
data = pickle.loads(f.read())
f.close()
print(data["age"])3、解決JSON不可以序列化datetime型別
解決json無法序列化時間格式
import json,datetime
class JsonCustomEncoder(json.JSONEncoder):
def default(self, field):
if isinstance(field, datetime.datetime):
return field.strftime('%Y-%m-%d %H:%M:%S')
elif isinstance(field, datetime.date):
return field.strftime('%Y-%m-%d')
else:
return json.JSONEncoder.default(self, field)
t = datetime.datetime.now()
print(type(t),t)
f = open('ttt','w') #指定將內容寫入到ttt檔案中
f.write(json.dumps(t,cls=JsonCustomEncoder)) #使用時候只要在json.dumps
增加個cls引數即可4、JSON和pickle模組的區別
JSON只能處理基本資料型別。pickle能處理所有Python的資料型別。
JSON用於各種語言之間的字元轉換。pickle用於Python程式物件的持久化或者Python程式間物件網路傳輸,但不同版本的Python序列化可能還有差異
hashlib 模組
1、用於加密相關的操作,代替了md5模組和sha模組,主要提供 SHA1, SHA224, SHA256, SHA384, SHA512 ,MD5 演演算法
五種簡單加密方式
import hashlib
#1 ######## md5 ########
# 目的:實現對b"HelloIt's me" 這句話進行md5加密
m = hashlib.md5() # 1)生成一個md5加密物件
m.update(b"Hello") # 2)使用m對 b"Hello" 加密
m.update(b"It's me") # 3) 使用m對 b"It's me"加密
print(m.hexdigest()) # 4) 最終加密結果就是對b"HelloIt's me"加密的md5
值:5ddeb47b2f925ad0bf249c52e342728a#2 ######## sha1 ######## hash = hashlib.sha1() hash.update(b'admin') print(hash.hexdigest())
#3 ######## sha256 ######## hash = hashlib.sha256() hash.update(b'admin') print(hash.hexdigest())
#4 ######## sha384 ######## hash = hashlib.sha384() hash.update(b'admin') print(hash.hexdigest())
#5 ######## sha512 ######## hash = hashlib.sha512() hash.update(b'admin') print(hash.hexdigest())
2、以上加密演演算法雖然依然非常厲害,但時候存在缺陷,即:通過撞庫可以反解。所以,有必要對加密演演算法中新增自定義key再來做加密。
hmac新增自定義key加密
######### hmac ######## import hmac h = hmac.new(b"123456","真實要傳的內容".encode(encoding="utf-8")) print(h.digest()) print(h.hexdigest()) # 注:hmac是一種雙重加密方法,前面是加密的內容,後面才是真實要傳的資料 資訊
六、subprocess 模組
1、subprocess原理以及常用的封裝函數
- 執行python的時候,我們都是在建立並執行一個程序。像Linux程序那樣,一個程序可以fork一個子程序,並讓這個子程序exec另外一個程式
- 在Python中,我們通過標準庫中的subprocess包來fork一個子程序,並執行一個外部的程式。
- subprocess包中定義有數個建立子程序的函數,這些函數分別以不同的方式建立子程序,所以我們可以根據需要來從中選取一個使用
- 另外subprocess還提供了一些管理標準流(standard stream)和管道(pipe)的工具,從而在程序間使用文字通訊。
subprocess常用函數
#1、返回執行狀態:0 執行成功
retcode = subprocess.call(['ping', 'www.baidu.com', '-c5'])
#2、返回執行狀態:0 執行成功,否則拋異常
subprocess.check_call(["ls", "-l"])
#3、執行結果為元組:第1個元素是執行狀態,第2個是命令結果
>>> ret = subprocess.getstatusoutput('pwd')
>>> ret
(0, '/test01')#4、返回結果為 字串 型別
>>> ret = subprocess.getoutput('ls -a')
>>> ret
'.\n..\ntest.py'#5、返回結果為’bytes’型別
>>> res=subprocess.check_output(['ls','-l'])
>>> res.decode('utf8')
'總用量 4\n-rwxrwxrwx. 1 root root 334 11月 21 09:02 test.py\n'將dos格式檔案轉換成unix格式
subprocess.check_output(['chmod', '+x', filepath]) subprocess.check_output(['dos2unix', filepath])
2、subprocess.Popen()
實際上,上面的幾個函數都是基於Popen()的封裝(wrapper),這些封裝的目的在於讓我們容易使用子程序
當我們想要更個性化我們的需求的時候,就要轉向Popen類,該類生成的物件用來代表子程序
與上面的封裝不同,Popen物件建立後,主程式不會自動等待子程序完成。我們必須呼叫物件的wait()方法,父程序才會等待 (也就是阻塞block)
從執行結果中看到,父程序在開啟子程序之後並沒有等待child的完成,而是直接執行print。
chil
#1、先列印'parent process'不等待child的完成
import subprocess
child = subprocess.Popen(['ping','-c','4','www.baidu.com'])
print('parent process')#2、後列印'parent process'等待child的完成
import subprocess
child = subprocess.Popen('ping -c4 www.baidu.com',shell=True)
child.wait()
print('parent process')child.poll() # 檢查子程序狀態
child.kill() # 終止子程序
child.send_signal() # 向子程序傳送訊號
child.terminate() # 終止子程序3、subprocess.PIPE 將多個子程序的輸入和輸出連線在一起
subprocess.PIPE實際上為文字流提供一個快取區。child1的stdout將文字輸出到快取區,隨後child2的stdin從該PIPE中將文字讀取走
child2的輸出文字也被存放在PIPE中,直到communicate()方法從PIPE中讀取出PIPE中的文字。
注意:communicate()是Popen物件的一個方法,該方法會阻塞父程序,直到子程序完成
分步執行cat /etc/passwd | grep root命
import subprocess #下面執行命令等價於: cat /etc/passwd | grep root child1 = subprocess.Popen(["cat","/etc/passwd"], stdout=subprocess.PIPE) child2 = subprocess.Popen(["grep","root"],stdin=child1.stdout, stdout=subprocess.PIPE) out = child2.communicate() #返回執行結果是元組 print(out) #執行結果: (b'root:x:0:0:root:/root:/bin/bash\noperator:x:11:0:operator:/root: /sbin/nologin\n', None)
獲取ping命令執行結果
import subprocess
list_tmp = []
def main():
p = subprocess.Popen(['ping', 'www.baidu.com', '-c5'], stdin = subprocess.PIPE, stdout = subprocess.PIPE)
while subprocess.Popen.poll(p) == None:
r = p.stdout.readline().strip().decode('utf-8')
if r:
# print(r)
v = p.stdout.read().strip().decode('utf-8')
list_tmp.append(v)
main()
print(list_tmp[0])七、re模組
常用正規表示式符號
⒈萬用字元( . )
作用:點(.)可以匹配除換行符以外的任意一個字串
例如:‘.ython’ 可以匹配‘aython’ ‘bython’ 等等,但只能匹配一個字串
⒉跳脫字元( \ )
作用:可以將其他有特殊意義的字串以原本意思表示
例如:‘python.org’ 因為字串中有一個特殊意義的字串(.)所以如果想將其按照普通意義就必須使用這樣表示: ‘python.org’ 這樣就只會匹配‘python.org’ 了
注:如果想對反斜線(\)自身跳脫可以使用雙反斜線(\)這樣就表示 ’\’
⒊字元集
作用:使用中括號來括住字串來建立字元集,字元集可匹配他包括的任意字串
①‘[pj]ython’ 只能夠匹配‘python’ ‘jython’
② ‘[a-z]’ 能夠(按字母順序)匹配a-z任意一個字元
③‘[a-zA-Z0-9]’ 能匹配任意一個大小寫字母和數位
④‘[^abc]’ 可以匹配任意除a,b和c 之外的字串
⒋管道符
作用:一次性匹配多個字串
例如:’python|perl’ 可以匹配字串‘python’ 和 ‘perl’
⒌可選項和重複子模式(在子模式後面加上問號?)
作用:在子模式後面加上問號,他就變成可選項,出現或者不出現在匹配字串中都是合法的
例如:r’(aa)?(bb)?ccddee’ 只能匹配下面幾種情況
‘aabbccddee’
‘aaccddee’
‘bbccddee’
‘ccddee’
⒍字串的開始和結尾
① ‘w+’ 匹配以w開通的字串
② ‘^http’ 匹配以’http’ 開頭的字串
③‘ $com’ 匹配以‘com’結尾的字串
7.最常用的匹配方法
\d 匹配任何十進位制數;它相當於類 [0-9]。
\D 匹配任何非數位字元;它相當於類 [^0-9]。
\s 匹配任何空白字元;它相當於類 [ fv]。
\S 匹配任何非空白字元;它相當於類 [^ fv]。
\w 匹配任何字母數位字元;它相當於類 [a-zA-Z0-9_]。
\W 匹配任何非字母數位字元;它相當於類 [^a-zA-Z0-9_]。
\w* 匹配所有字母字元
\w+ 至少匹配一個字元
re模組更詳細表示式符號
- ‘.’ 預設匹配除\n之外的任意一個字元,若指定flag DOTALL,則匹配任意字元,包括換行
- ‘^’ 匹配字元開頭,若指定flags MULTILINE,這種也可以匹配上(r"^a","\nabc\neee",flags=re.MULTILINE)
匹配字元結尾,或e.search("foo",「bfoo\nsdfsf」,flags=re.MULTILINE).group()也可
- '’ 匹配號前的字元0次或多次,re.findall(「ab*」,「cabb3abcbbac」) 結果為[‘abb’, ‘ab’, ‘a’]
- ‘+’ 匹配前一個字元1次或多次,re.findall(「ab+」,「ab+cd+abb+bba」) 結果[‘ab’, ‘abb’]
- ‘?’ 匹配前一個字元1次或0次
- ‘{m}’ 匹配前一個字元m次
- ‘{n,m}’ 匹配前一個字元n到m次,re.findall(「ab{1,3}」,「abb abc abbcbbb」) 結果’abb’, ‘ab’, ‘abb’]
- ‘|’ 匹配|左或|右的字元,re.search(「abc|ABC」,「ABCBabcCD」).group() 結果’ABC’
- ‘(…)’ 分組匹配,re.search("(abc){2}a(123|456)c", 「abcabca456c」).group() 結果 abcabca456c
- ‘\A’ 只從字元開頭匹配,re.search("\Aabc",「alexabc」) 是匹配不到的
- ‘\Z’ 匹配字元結尾,同$
- ‘\d’ 匹配數位0-9
- ‘\D’ 匹配非數位
- ‘\w’ 匹配[A-Za-z0-9]
- ‘\W’ 匹配非[A-Za-z0-9]
- ‘s’ 匹配空白字元、\t、\n、\r , re.search("\s+",「ab\tc1\n3」).group() 結果 ‘\t’
- \b 匹配一個單詞邊界,也就是指單詞和空格間的位置,如,「er\b」可以匹配「never」中的「er」,但不能匹配「verb」中的「er」
- \B 匹配非單詞邊界。「er\B」能匹配「verb」中的「er」,但不能匹配「never」中的「er」
re模組常用函數*

⒈ re.compile(pattern[, flags])
1)把一個正規表示式pattern編譯成正則物件,以便可以用正則物件的match和search方法
2)用了re.compile以後,正則物件會得到保留,這樣在需要多次運用這個正則物件的時候,效率會有較大的提升
re.compile使用
import re
mobile_re = re.compile(r'^(13[0-9]|15[012356789]|17[678]|18[0-9]|14[57])
[0-9]{8}$')
ret = re.match(mobile_re,'18538762511')
print(ret) # <_sre.SRE_Match object; span=(0, 11),
match='18538652511'>⒉ search(pattern, string[, flags]) 和 match(pattern, string[, flags])
1)match :只從字串的開始與正規表示式匹配,匹配成功返回matchobject,否則返回none;
2)search :將字串的所有字串嘗試與正規表示式匹配,如果所有的字串都沒有匹配成功,返回none,否則返回matchobject;
match與search使用比較
import re
a =re.match('www.bai', 'www.baidu.com')
b = re.match('bai', 'www.baidu.com')
print(a.group()) # www.bai
print(b) # None
# 無論有多少個匹配的只會匹配一個
c = re.search('bai', 'www.baidubaidu.com')
print(c) # <_sre.SRE_Match object; span=(4, 7),
match='bai'>
print(c.group()) # bai⒊ split(pattern, string[, maxsplit=0])
作用:將字串以指定分割方式,格式化成列表
import re
text = 'aa 1bb###2cc3ddd'
print(re.split('\W+', text)) # ['aa', '1bb', '2cc3ddd']
print(re.split('\W', text)) # ['aa', '1bb', '', '', '2cc3ddd']
print(re.split('\d', text)) # ['aa ', 'bb###', 'cc', 'ddd']
print(re.split('#', text)) # ['aa 1bb', '', '', '2cc3ddd']
print(re.split('#+', text)) # ['aa 1bb', '2cc3ddd']⒋ findall(pattern, string)
作用:正規表示式 re.findall 方法能夠以列表的形式返回能匹配的子串
import re
p = re.compile(r'\d+')
print(p.findall('one1two2three3four4')) # ['1', '2', '3', '4']
print(re.findall('o','one1two2three3four4')) # ['o', 'o', 'o']
print(re.findall('\w+', 'he.llo, wo#rld!')) # ['he', 'llo', 'wo', 'rld']⒌ sub(pat, repl, string[, count=0])
1)替換,將string裡匹配pattern的部分,用repl替換掉,最多替換count次然後返回替換後的字串
2)如果string裡沒有可以匹配pattern的串,將被原封不動地返回
3)repl可以是一個字串,也可以是一個函數
4) 如果repl是個字串,則其中的反斜杆會被處理過,比如 \n 會被轉成換行符,反斜杆加數位會被替換成相應的組,比如 \6 表示pattern匹配到的第6個組的內容
import re
test="Hi, nice to meet you where are you from?"
print(re.sub(r'\s','-',test)) # Hi,-nice-to-meet-you-where-are-you-from?
print(re.sub(r'\s','-',test,5)) # Hi,-nice-to-meet-you-where are you from?
print(re.sub('o','**',test)) # Hi, nice t** meet y**u where are y**u fr**m?⒍ escape(string)
1) re.escape(pattern) 可以對字串中所有可能被解釋為正則運運算元的字元進行跳脫的應用函數。
2) 如果字串很長且包含很多特殊技字元,而你又不想輸入一大堆反斜槓,或者字串來自於使用者(比如通過raw_input函數獲取輸入的內容),
且要用作正規表示式的一部分的時候,可以用這個函數
import re
print(re.escape('www.python.org'))re模組中的匹配物件和組 group()
1)group方法返回模式中與給定組匹配的字串,如果沒有給定匹配組號,預設為組0
2)m.group() == m.group(0) == 所有匹配的字元
group(0)與group(1)區別比較
import re
a = "123abc321efg456"
print(re.search("([0-9]*)([a-z]*)([0-9]*)",a).group(0)) # 123abc321
print(re.search("([0-9]*)([a-z]*)([0-9]*)",a).groups()) # ('123', 'abc', '321')
print(re.search("([0-9]*)([a-z]*)([0-9]*)",a).group(1)) # 123
print(re.search("([0-9]*)([a-z]*)([0-9]*)",a).group(2)) # abc
print(re.search("([0-9]*)([a-z]*)([0-9]*)",a).group(3)) # 321import re
m = re.match('(..).*(..)(..)','123456789')
print(m.group(0)) # 123456789
print(m.group(1)) # 12
print(m.group(2)) # 67
print(m.group(3)) # 89group()匹配之返回匹配索引
import re
m = re.match('www\.(.*)\..*','www.baidu.com')
print(m.group(1)) # baidu
print(m.start(1)) # 4
print(m.end(1)) # 9
print(m.span(1)) # (4, 9)group()匹配ip,狀態以元組返回
import re
test = 'dsfdf 22 g2323 GigabitEthernet0/3 10.1.8.1 YES NVRAM up
eee'
# print(re.match('(\w.*\d)\s+(\d{1,3}\.\d{1,3}\.\d{1,3}\.\d{1,3})\s+YES\s+NVRAM
\s+(\w+)\s+(\w+)\s*', test).groups())
ret = re.search( r'(\w*\/\d+).*\s(\d{1,3}\.\d{1,3}\.\d{1,3}\.\d{1,3}).*(\s+up\s+)',test
).groups()
print(ret) # 執行結果: ('GigabitEthernet0/3', '10.1.8.1', ' up ')
#1. (\w*\d+\/\d+) 匹配結果為:GigabitEthernet0/3
#1.1 \w*: 匹配所有字母數位
#1.2 /\d+:匹配所有斜槓開頭後根數位 (比如:/3 )
#2. (\d{1,3}\.\d{1,3}\.\d{1,3}\.\d{1,3}) 匹配結果為:10.1.8.1
#3. \s+up\s+ 匹配結果為: up 這個單詞,前後都為空格re模組其他知識點
re匹配忽略大小寫,匹配換行
import re
#匹配時忽略大小寫
print(re.search("[a-z]+","abcdA").group()) #abcd
print(re.search("[a-z]+","abcdA",flags=re.I).group()) #abcdA
#連同換行符一起匹配:
#'.'預設匹配除\n之外的任意一個字元,若指定flag DOTALL,則匹配任意字元,包
括換行
print(re.search(r".+","\naaa\nbbb\nccc").group()) #aaa
print(re.search(r".+","\naaa\nbbb\nccc",flags=re.S))
#<_sre.SRE_Match object; span=(0, 12), match='\naaa\nbbb\nccc'>
print(re.search(r".+","\naaa\nbbb\nccc",flags=re.S).group())
aaa
bbb
ccc計算器用到的幾個知識點
- init_l=[i for i in re.split(’(-\d+.\d)’,expression) if i]
a. 按照類似負數的字串分割成列表
b. -\d+.\d是為了可以匹配浮點數(比如:3.14)
c. (if i)是為了去除列表中的空元素
d. 分割結果:[’-1’, ‘-2’, ‘*((’, ‘-60’, ‘+30+(’, - re.search(’[+-*/(]$’,expression_l[-1])
a. 匹配expression_l列表最後一個元素是 +,-,*,/,( 這五個符號就是負數 - new_l=[i for i in re.split(’([+-*/()])’,exp) if i]
a. 將字串按照+,-,*,/,(,)切分成列表(不是正真的負數就切分) - print(re.split(’([+-])’,’-1+2-3*(22+3)’)) #按照加號或者減號分割成列表
執行結果: [’’, ‘-’, ‘1’, ‘+’, ‘2’, ‘-’, '3(2*2’, ‘+’, ‘3)’]
推薦學習:
以上就是歸納總結Python常用模組大全的詳細內容,更多請關注TW511.COM其它相關文章!