詳細解析Redis記憶體滿了怎麼去優化

推薦學習:
Redis記憶體滿了怎麼辦?怎麼優化記憶體?
MySQL裡有2000w資料,redis中只存20w的資料,如何保證redis中的資料都是熱點資料
redis記憶體資料集大小上升到一定大小的時候,就會施行資料淘汰策略。
Redis主要消耗什麼物理資源?
記憶體。
Redis的記憶體用完了會發生什麼?
如果達到設定的上限,Redis的寫命令會返回錯誤資訊(但是讀命令還可以正常返回。)或者你可以設定記憶體淘汰機制,當Redis達到記憶體上限時會沖刷掉舊的內容。
談談快取資料的淘汰機制
Redis 快取有哪些淘汰策略?
- 不進行資料淘汰的策略,只有 noeviction 這一種。
會進行淘汰的 7 種策略,我們可以再進一步根據淘汰候選資料集的範圍把它們分成兩類:
- 在設定了過期時間的資料中進行淘汰,包括 volatile-random、volatile-ttl、volatile-lru、volatile-lfu四種。
- 在所有資料範圍內進行淘汰,包括 allkeys-lru、allkeys-random、allkeys-lfu三種。
| 策略 | 規則 |
|---|---|
| volatile-ttl | 在篩選時,會針對設定了過期時間的鍵值對,根據過期時間的先後進行刪除,越早過期的越先被刪除。 |
| volatile-random | 在設定了過期時間的鍵值對中,進行隨機刪除。 |
| volatile-lru | 使用 LRU 演演算法篩選設定了過期時間的鍵值對 |
| volatile-lfu | 使用 LFU 演演算法選擇設定了過期時間的鍵值對 |
| 策略 | 規則 |
|---|---|
| allkeys-random | 從所有鍵值對中隨機選擇並刪除資料; |
| allkeys-lru | 使用 LRU 演演算法在所有資料中進行篩選 |
| vallkeys-lfu | 使用 LFU 演演算法在所有資料中進行篩選 |
談談LRU演演算法
是按照最近最少使用的原則來篩選資料,最不常用的資料會被篩選出來,而最近頻繁使用的資料會留在快取中。
那具體是怎麼篩選的呢?LRU 會把所有的資料組織成一個連結串列,連結串列的頭和尾分別表示 MRU 端和 LRU 端,分別代表最近最常使用的資料和最近最不常用的資料。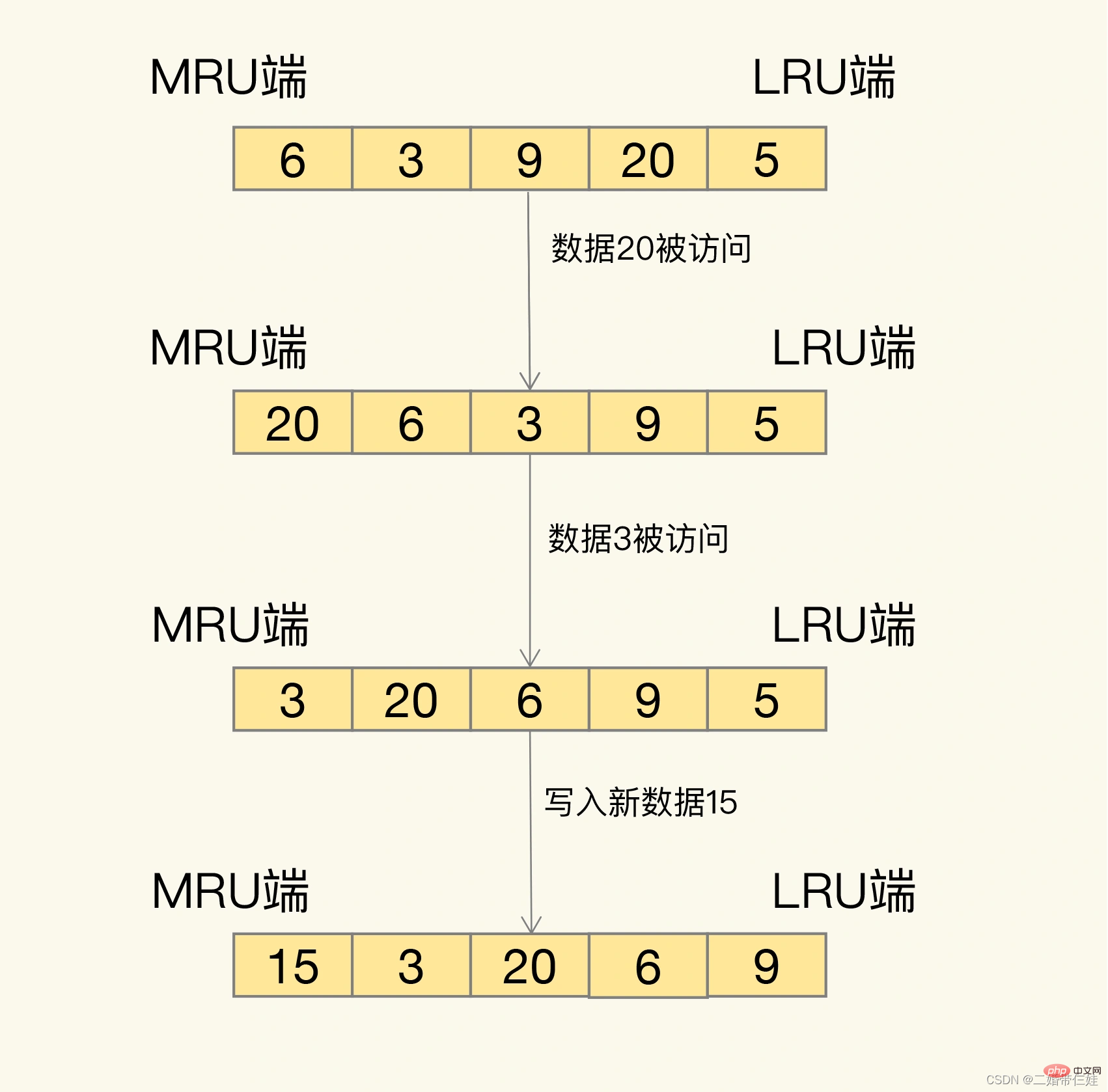
LRU 演演算法背後的想法非常樸素:它認為剛剛被存取的資料,肯定還會被再次存取,所以就把它放在 MRU 端;長久不存取的資料,肯定就不會再被存取了,所以就讓它逐漸後移到 LRU 端,在快取滿時,就優先刪除它。
問題:LRU 演演算法在實際實現時,需要用連結串列管理所有的快取資料,這會帶來額外的空間開銷。而且,當有資料被存取時,需要在連結串列上把該資料移動到 MRU 端,如果有大量資料被存取,就會帶來很多連結串列移動操作,會很耗時,進而會降低 Redis 快取效能。
解決:
在 Redis 中,LRU 演演算法被做了簡化,以減輕資料淘汰對快取效能的影響。具體來說,Redis 預設會記錄每個資料的最近一次存取的時間戳(由鍵值對資料結構 RedisObject 中的 lru 欄位記錄)。然後,Redis 在決定淘汰的資料時,第一次會隨機選出 N 個資料,把它們作為一個候選集合。接下來,Redis 會比較這 N 個資料的 lru 欄位,把 lru 欄位值最小的資料從快取中淘汰出去。
當需要再次淘汰資料時,Redis 需要挑選資料進入第一次淘汰時建立的候選集合。這兒的挑選標準是:能進入候選集合的資料的 lru 欄位值必須小於候選集合中最小的 lru 值。當有新資料進入候選資料集後,如果候選資料集中的資料個數達到了 maxmemory-samples,Redis 就把候選資料集中 lru 欄位值最小的資料淘汰出去。
使用建議:
- 優先使用 allkeys-lru 策略。這樣,可以充分利用 LRU 這一經典快取演演算法的優勢,把最近最常存取的資料留在快取中,提升應用的存取效能。如果你的業務資料中有明顯的冷熱資料區分,我建議你使用 allkeys-lru 策略。
- 如果業務應用中的資料存取頻率相差不大,沒有明顯的冷熱資料區分,建議使用 allkeys-random 策略,隨機選擇淘汰的資料就行。
- 如果你的業務中有置頂的需求,比如置頂新聞、置頂視訊,那麼,可以使用 volatile-lru 策略,同時不給這些置頂資料設定過期時間。這樣一來,這些需要置頂的資料一直不會被刪除,而其他資料會在過期時根據 LRU 規則進行篩選。
如何處理被淘汰的資料?
一旦被淘汰的資料選定後,如果這個資料是乾淨資料,那麼我們就直接刪除;如果這個資料是髒資料,我們需要把它寫回資料庫。
那怎麼判斷一個資料到底是乾淨的還是髒的呢?
- 乾淨資料和髒資料的區別就在於,和最初從後端資料庫裡讀取時的值相比,有沒有被修改過。乾淨資料一直沒有被修改,所以後端資料庫裡的資料也是最新值。在替換時,它可以被直接刪除。
- 而髒資料就是曾經被修改過的,已經和後端資料庫中儲存的資料不一致了。此時,如果不把髒資料寫回到資料庫中,這個資料的最新值就丟失了,就會影響應用的正常使用。
即使淘汰的資料是髒資料,Redis 也不會把它們寫回資料庫。所以,我們在使用 Redis 快取時,如果資料被修改了,需要在資料修改時就將它寫回資料庫。否則,這個髒資料被淘汰時,會被 Redis 刪除,而資料庫裡也沒有最新的資料了。
Redis怎麼優化記憶體?
1、控制key的數量:當使用Redis儲存大量資料時,通常會存在大量鍵,過多的鍵同樣會消耗大量記憶體。Redis本質是一個資料結構伺服器,它為我們提供多種資料結構,如hash,list,set,zset 等結構。使用Redis時不要進入一個誤區,大量使用get/set這樣的API,把Redis當成Memcached使用。對於儲存相同的資料內容利用Redis的資料結構降低外層鍵的數量,也可以節省大量記憶體。
2、縮減鍵值物件,降低Redis記憶體使用最直接的方式就是縮減鍵(key)和值(value)的長度。
- key長度:如在設計鍵時,在完整描述業務情況下,鍵值越短越好。
- value長度:值物件縮減比較複雜,常見需求是把業務物件序列化成二進位制陣列放入Redis。首先應該在業務上精簡業務物件,去掉不必要的屬性避免儲存無效資料。其次在序列化工具選擇上,應該選擇更高效的序列化工具來降低位元組陣列大小。
3、編碼優化。Redis對外提供了string,list,hash,set,zet等型別,但是Redis內部針對不同型別存在編碼的概念,所謂編碼就是具體使用哪種底層資料結構來實現。編碼不同將直接影響資料的記憶體佔用和讀寫效率。
- 1、redisObject物件
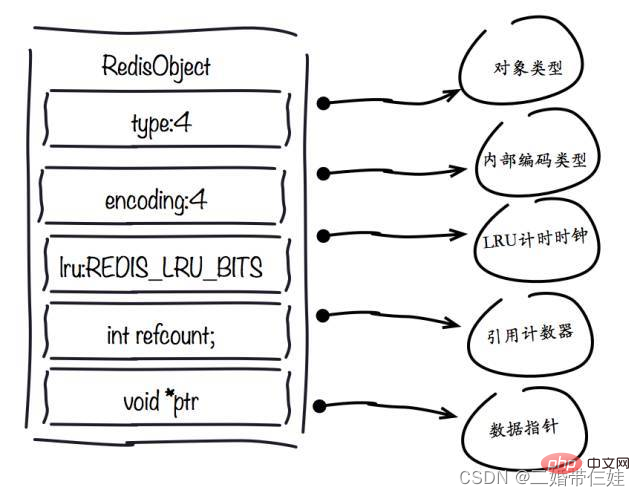
type欄位:
利用集合型別資料,因為通常情況下很多小的Key-Value可以用更緊湊的方式存放到一起。儘可能使用雜湊表(hashes),雜湊表(是說雜湊表裡面儲存的數少)使用的記憶體非常小,所以你應該儘可能的將你的資料模型抽象到一個雜湊表裡面。比如你的web系統中有一個使用者物件,不要為這個使用者的名稱,姓氏,郵箱,密碼設定單獨的key,而是應該把這個使用者的所有資訊儲存到一張雜湊表裡面。
encoding欄位:
採用不同的編碼實現記憶體佔用存在明顯差異
lru欄位:
開發提示:可以使用scan + object idletime 命令批次查詢哪些鍵長時間未被存取,找出長時間不存取的鍵進行清理降低記憶體佔用。
refcount欄位:
當物件為整數且範圍在[0-9999]時,Redis可以使用共用物件的方式來節省記憶體。
ptr欄位 :
開發提示:高並行寫入場景中,在條件允許的情況下建議字串長度控制在39位元組以內,減少建立redisObject記憶體分配次數從而提高效能。
- 2、縮減鍵值物件
降低Redis記憶體使用最直接的方式就是縮減鍵(key)和值(value)的長度。
可以使用通用壓縮演演算法壓縮json,xml後再存入Redis,從而降低記憶體佔用
- 3、共用物件池
物件共用池指Redis內部維護[0-9999]的整數物件池。建立大量的整數型別redisObject存在記憶體開銷,每個redisObject內部結構至少佔16位元組,甚至超過了整數自身空間消耗。所以Redis記憶體維護一個[0-9999]的整數物件池,用於節約記憶體。 除了整數值物件,其他型別如list,hash,set,zset內部元素也可以使用整數物件池。因此開發中在滿足需求的前提下,儘量使用整數物件以節省記憶體。
當設定maxmemory並啟用LRU相關淘汰策略如:volatile-lru,allkeys-lru時,Redis禁止使用共用物件池。
為什麼開啟maxmemory和LRU淘汰策略後物件池無效?
LRU演演算法需要獲取物件最後被存取時間,以便淘汰最長未存取資料,每個物件最後存取時間儲存在redisObject物件的lru欄位。物件共用意味著多個參照共用同一個redisObject,這時lru欄位也會被共用,導致無法獲取每個物件的最後存取時間。如果沒有設定maxmemory,直到記憶體被用盡Redis也不會觸發記憶體回收,所以共用物件池可以正常工作。
綜上所述,共用物件池與maxmemory+LRU策略衝突,使用時需要注意。
為什麼只有整數物件池?
首先整數物件池複用的機率最大,其次物件共用的一個關鍵操作就是判斷相等性,Redis之所以只有整數物件池,是因為整數比較演演算法時間複雜度為O(1),只保留一萬個整數為了防止物件池浪費。如果是字串判斷相等性,時間複雜度變為O(n),特別是長字串更消耗效能(浮點數在Redis內部使用字串儲存)。對於更復雜的資料結構如hash,list等,相等性判斷需要O(n2)。對於單執行緒的Redis來說,這樣的開銷顯然不合理,因此Redis只保留整數共用物件池。
- 4、字串優化
Redis沒有采用原生C語言的字串型別而是自己實現了字串結構,內部簡單動態字串,簡稱SDS。
字串結構:
- 特點:
O(1)時間複雜度獲取:字串長度,已用長度,未用長度。
可用於儲存位元組陣列,支援安全的二進位制資料儲存。
內部實現空間預分配機制,降低記憶體再分配次數。
惰性刪除機制,字串縮減後的空間不釋放,作為預分配空間保留。
預分配機制:
- 開發提示:儘量減少字串頻繁修改操作如append,setrange, 改為直接使用set修改字串,降低預分配帶來的記憶體浪費和記憶體碎片化。
字串重構:基於hash型別的二級編碼方式。
- 二級編碼怎麼用?
二級編碼方法中採用的 ID 長度是有講究的。
涉及到一個問題–Hash 型別底層結構小於設定值時使用壓縮列表,大於設定值時使用雜湊表。
一旦從壓縮列表轉為了雜湊表,Hash 型別會一直用雜湊表進行儲存,而不會再轉回壓縮列表。
在節省記憶體空間方面,雜湊表就沒有壓縮列表那麼高效。為能充分使用壓縮列表的精簡記憶體佈局,一般要控制儲存在 Hash 中的元素個數。
- 5.編碼優化
使用壓縮列表ziplist編碼的hash型別依然比使用hashtable編碼的集合節省大量記憶體。
- 6.控制key的數量
開發提示:使用ziplist+hash優化keys後,如果想使用超時刪除功能,開發人員可以儲存每個物件寫入的時間,再通過定時任務使用hscan命令掃描資料,找出hash內超時的資料項刪除即可。
當Redis記憶體不足時,首先考慮的問題不是加機器做水平擴充套件,應該先嚐試做記憶體優化。當遇到瓶頸時,再去考慮水平擴充套件。即使對於叢集化方案,垂直層面優化也同樣重要,避免不必要的資源浪費和叢集化後的管理成本。
推薦學習:
以上就是詳細解析Redis記憶體滿了怎麼去優化的詳細內容,更多請關注TW511.COM其它相關文章!