範例詳解Python元組

推薦學習:
引言——在Python中,通過資料結構來儲存專案中重要的資料資訊。Python語言內建了多種資料結構,例如列表,元組,字典和集合等。本堂課我們來講一講Python中舉足輕重的一巨量資料結構——元組。
在Python中,我們可以將元組看作一種特殊的列表。它與列表唯一的不同在於:元組內的資料元素不能發生改變【這個不變——不但不能改變其中的資料項,而且也不能新增和刪除資料項!】。當我們需要建立一組不可改變的資料時,通常是將這些資料放進元組中~
1.元組的 建立 && 存取
(1)元組的建立:
在Python中,建立元組的基本形式是以小括號「()」將資料元素括起來,各個元素之間用逗號「,」隔開。
如下:
tuple1 = ('xiaoming', 'xiaohong', 18, 21)
tuple2 = (1, 2, 3, 4, 5)
# 而且——是可以建立空元組哦!
tuple3 = ()
# 小注意——如果你建立的元組只包含一個元素時,也不要忘記在元素後面加上逗號。讓其識別為一個元組:
tuple4 = (22, )(2)存取:
元組和字串以及列表類似,索引都是從0開始,並且可以進行擷取和組合等操作。
如下:
tuple1 = ('xiaoming', 'xiaohong', 18, 21)
tuple2 = (1, 2, 3, 4, 5)
# 顯示元組中索引為1的元素的值
print("tuple1[1]:", tuple1[0])
# 顯示元組中索引從1到3的元素的值
print("tuple2[1:3]:", tuple2[1:3])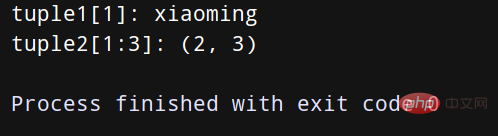
2.元組的 修改 && 刪除
(1)元組的修改:
雖然在開頭就說元組不可變,但是它還是有個被支援的騷操作——元組之間進行連線組合:
tuple1 = ('xiaoming', 'xiaohong', 18, 21)
tuple2 = (1, 2, 3, 4, 5)
tuple_new = tuple1 + tuple2
print(tuple_new)
(1)元組的刪除:
雖然元組不可變,但是卻可以通過del語句刪除整個元組。
如下:
tuple1 = ('xiaoming', 'xiaohong', 18, 21)
print(tuple1) # 正常列印tuple1
del tuple1
print(tuple1) # 因為上面刪除了tuple1,所以再列印會報錯哦!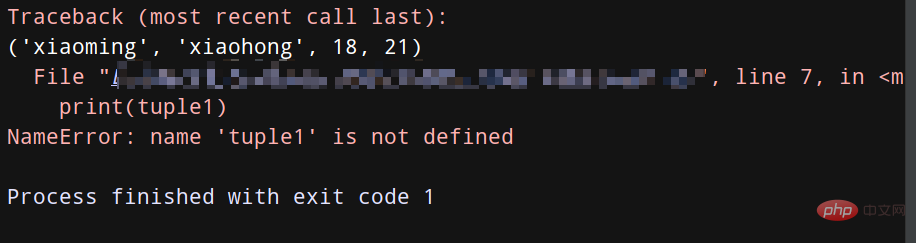
3.元組的內建方法
元組是不可變,但是我們可以通過使用內建方法來操作元組。常用的內建方法如下:
- len(tuple):計算元組元素個數;
- max(tuple):返回元組中元素的最大值;
- min(tuple):返回元組中元素的最小值;
- tuple(seq):將列表轉換為元組。
其實更多時候,我們是將元組先轉換為列表,操作之後再轉換為元組(因為列表具有很多方法~)。
4.將序列分解為單獨的變數
(1)
Python允許將一個包含N個元素的元組或序列分別為N個單獨的變數。這是因為Python語法允許任何序列/可迭代物件通過簡單的賦值操作分解為單獨的變數,唯一的要求是變數的總數和結構要與序列相吻合。
如下:
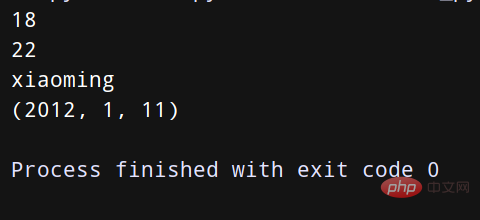
tuple1 = (18, 22) x, y = tuple1 print(x) print(y) tuple2 = ['xiaoming', 33, 19.8, (2012, 1, 11)] name, age, level, date = tuple2 print(name) print(date)
如果要分解未知或任意長度的可迭代物件,上述分解操作豈不直接很nice!通常在這類可迭代物件中會有一些已知的元件或模式(例如:元素1之後的所有內容都是電話號碼),利用「*」星號表示式分解可迭代物件後,使得開發者能輕鬆利用這些模式,而無須在可迭代物件中做複雜操作就能得到相關的元素。
在Python中,星號表示式在迭代一個變長的元組序列時十分有用。如下演示分解一個待標記元組序列的過程。
records = [
('AAA', 1, 2),
('BBB', 'hello'),
('CCC', 5, 3)
]
def do_foo(x, y):
print('AAA', x, y)
def do_bar(s):
print('BBB', s)
for tag, *args in records:
if tag == 'AAA':
do_foo(*args)
elif tag == 'BBB':
do_bar(*args)
line = 'guan:ijing234://wef:678d:guan'
uname, *fields, homedir, sh = line.split(':')
print(uname)
print(*fields)
print(homedir)
print(sh)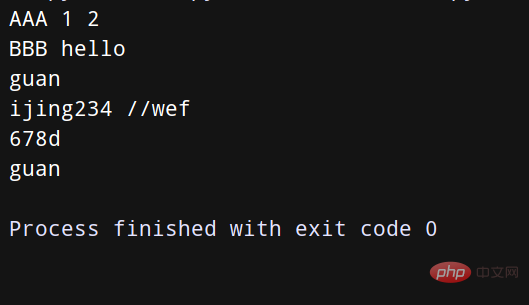
(2)
在Python中迭代處理列表或元組等序列時,有時需要統計最後幾項記錄以實現歷史記錄統計功能。
使用內建的deque實現:
from _collections import deque q = deque(maxlen=3) q.append(1) q.append(2) q.append(3) print(q) q.append(4) print(q)
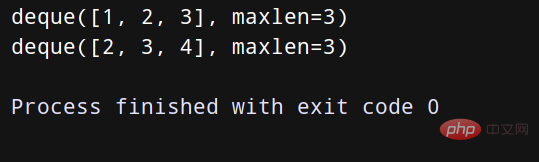
如下——演示了將序列中的最後幾項作為歷史記錄的過程。
from _collections import deque
def search(lines, pattern, history=5):
previous_lines = deque(maxlen=history)
for line in lines:
if pattern in line:
yield line, previous_lines
previous_lines.append(line)
# Example use on a file
if __name__ == '__main__':
with open('123.txt') as f:
for line, prevlines in search(f, 'python', 5):
for pline in prevlines: # 包含python的行
print(pline) # print (pline, end='')
# 列印最後檢查過的N行文字
print(line) # print (pline, end='')123.txt:
pythonpythonpythonpythonpythonpythonpython python python
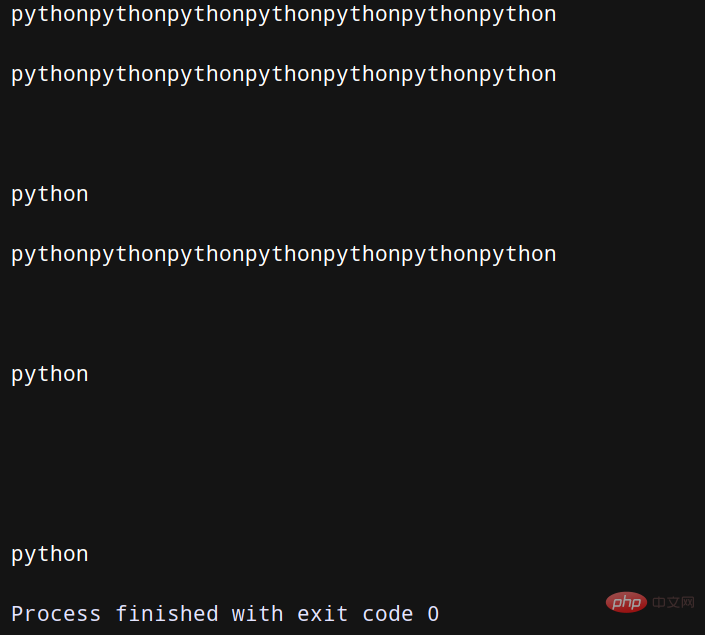
在上述程式碼中,對一系列文字行實現了簡單的文字匹配操作,當發現有合適的匹配時,就輸出當前的匹配行以及最後檢查過的N行文字。使用deque(maxlen=N)建立了一個固定長度的佇列。當有新記錄加入而使得佇列變成已滿狀態時,會自動移除最老的那條記錄。當編寫搜尋某項記錄的程式碼時,通常會用到含有yield關鍵字的生成器函數,它能夠將處理搜尋過程的程式碼和使用搜尋結果的程式碼成功解耦開來。
5.實現優先順序佇列
使用內建模組heapq可以實現一個簡單的優先順序佇列。
如下——演示了實現一個簡單的優先順序佇列的過程。
import heapq
class PriorityQueue:
def __init__(self):
self._queue = []
self._index = 0
def push(self, item, priority):
heapq.heappush(self._queue, (-priority, self._index, item))
self._index += 1
def pop(self):
return heapq.heappop(self._queue)[-1]
class Item:
def __init__(self, name):
self.name = name
def __repr__(self):
return 'Item({!r})'.format(self.name)
q = PriorityQueue()
q.push(Item('AAA'), 1)
q.push(Item('BBB'), 4)
q.push(Item('CCC'), 5)
q.push(Item('DDD'), 1)
print(q.pop())
print(q.pop())
print(q.pop())在上述程式碼中,利用heapq模組實現了一個簡單的優先順序佇列,第一次執行pop()操作時返回的元素具有最高的優先順序。
擁有相同優先順序的兩個元素(foo和grok)返回的順序,同插入到佇列時的順序相同。
函數heapq.heappush()和heapq.heappop()分別實現了列表_queue中元素的插入和移除操作,並且保證列表中的第一個元素的優先順序最低。
函數heappop()總是返回「最小」的元素,並且因為push和pop操作的複雜度都是O(log2N),其中N代表堆中元素的數量,因此就算N的值很大,這些操作的效率也非常高。
上述程式碼中的佇列以元組 (-priority, index, item)的形式組成,priority取負值是為了讓佇列能夠按元素的優先順序從高到底排列。這和正常的堆排列順序相反,一般情況下,堆是按從小到大的順序進行排序的。變數index的作用是將具有相同優先順序的元素以適當的順序排列,通過維護一個不斷遞增的索引,元素將以它們加入佇列時的順序排列。但是當index在對具有相同優先順序的元素間進行比較操作,同樣扮演一個重要的角色。
在Python中,如果以元組(priority, item)的形式儲存元素,只要它們的優先順序不同,它們就可以進行比較。但是如果兩個元組的優先順序相同,在進行比較操作時會失敗。這時可以考慮引入一個額外的索引值,以(priority, index, item)的方式建立元組,因為沒有哪兩個元組會有相同的index值,所以這樣就可以完全避免上述問題。一旦比較操作的結果可以確定,Python就不會再去比較剩下的元組元素了。
如下——演示了實現一個簡單的優先順序佇列的過程:
import heapq
class PriorityQueue:
def __init__(self):
self._queue = []
self._index = 0
def push(self, item, priority):
heapq.heappush(self._queue, (-priority, self._index, item))
self._index += 1
def pop(self):
return heapq.heappop(self._queue)[-1]
class Item:
def __init__(self, name):
self.name = name
def __repr__(self):
return 'Item({!r})'.format(self.name)
# ①
a = Item('AAA')
b = Item('BBB')
#a < b 錯誤
a = (1, Item('AAA'))
b = (5, Item('BBB'))
print(a < b)
c = (1, Item('CCC'))
#② a < c 錯誤
# ③
a = (1, 0, Item('AAA'))
b = (5, 1, Item('BBB'))
c = (1, 2, Item('CCC'))
print(a < b)
# ④
print(a < c)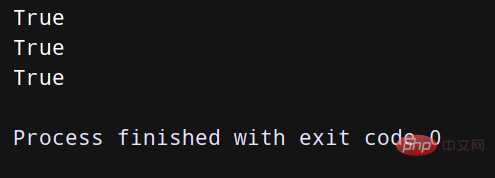
在上述程式碼中,因為在1-2中沒有新增所以,所以當兩個元組的優先順序相同時會出錯;而在3-4中新增了索引,這樣就不會出錯了!
推薦學習:
以上就是範例詳解Python元組的詳細內容,更多請關注TW511.COM其它相關文章!