Redis深入學習之詳解持久化原理
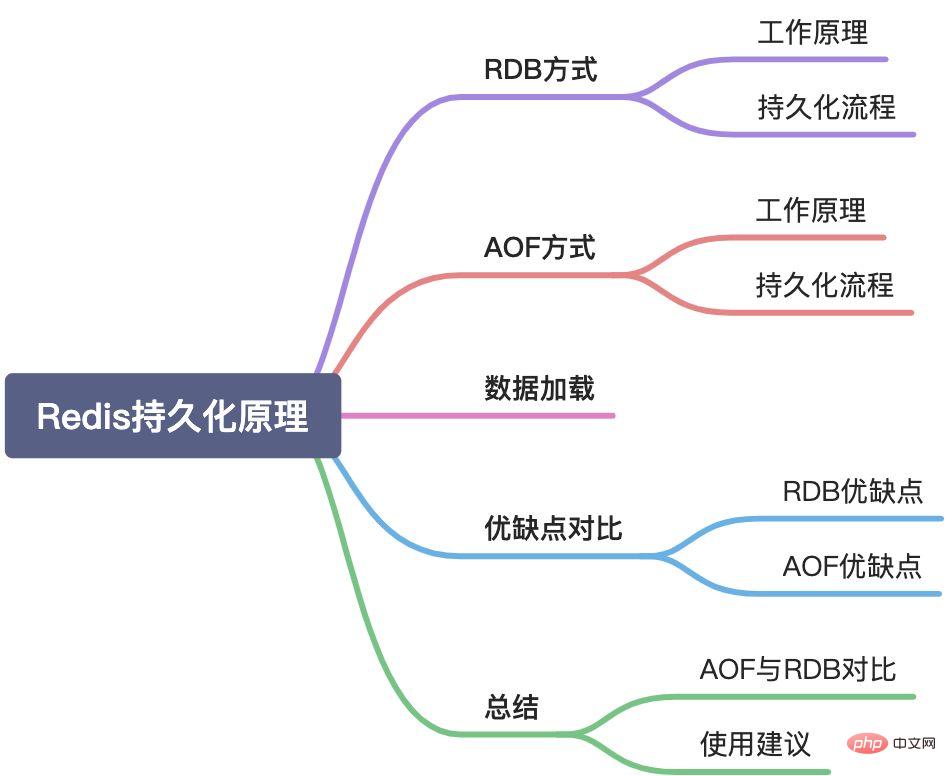
本文將從以下幾個方面介紹Redis持久化機制:
 ## 寫在前面
## 寫在前面
本文從整體上詳細介紹Redis的兩種持久化方式,包含工作原理、持久化流程及實踐策略,以及背後的一些理論知識。上一篇文章僅介紹了RDB持久化,但是Redis持久化是一個整體,單獨介紹不成體系,故重新整理。【相關推薦:Redis視訊教學】
Redis是一個記憶體資料庫,所有的資料將儲存在記憶體中,這與傳統的MySQL、Oracle、SqlServer等關係型資料庫直接把資料儲存到硬碟相比,Redis的讀寫效率非常高。但是儲存在記憶體中也有一個很大的缺陷,一旦斷電或者宕機,記憶體資料庫中的內容將會全部丟失。為了彌補這一缺陷,Redis提供了把記憶體資料持久化到硬碟檔案,以及通過備份檔案來恢復資料的功能,即Redis持久化機制。
Redis支援兩種方式的持久化:RDB快照和AOF。
RDB持久化
RDB快照用官方的話來說:RDB持久化方案是按照指定時間間隔對你的資料集生成的時間點快照(point-to-time snapshot)。它以緊縮的二進位制檔案儲存Redis資料庫某一時刻所有資料物件的記憶體快照,可用於Redis的資料備份、轉移與恢復。到目前為止,仍是官方的預設支援方案。
RDB工作原理
既然說RDB是Redis中資料集的時間點快照,那我們先簡單瞭解一下Redis內的資料物件在記憶體中是如何儲存與組織的。
預設情況下,Redis中有16個資料庫,編號從0-15,每個Redis資料庫使用一個redisDb物件來表示,redisDb使用hashtable儲存K-V物件。為方便理解,我以其中一個db為例繪製Redis內部資料的儲存結構示意圖。

時間點快照也就是某一時刻Redis內每個DB中每個資料物件的狀態,先假設在這一時刻所有的資料物件不再改變,我們就可以按照上圖中的資料結構關係,把這些資料物件依次讀取出來並寫入到檔案中,以此實現Redis的持久化。然後,當Redis重新啟動時按照規則讀取這個檔案中的內容,再寫入到Redis記憶體即可恢復至持久化時的狀態。
當然,這個前提時我們上面的假設成立,否則面對一個時刻變化的資料集,我們無從下手。我們知道Redis中使用者端命令處理是單執行緒模型,如果把持久化作為一個命令處理,那資料集肯定時處於靜止狀態。另外,作業系統提供的fork()函數建立的子程序可獲得與父程序一致的記憶體資料,相當於獲取了記憶體資料副本;fork完成後,父程序該幹嘛幹嘛,持久化狀態的工作交給子程序就行了。
很顯然,第一種情況不可取,持久化備份會導致短時間內Redis服務不可用,這對於高HA的系統來講是無法容忍的。所以,第二種方式是RDB持久化的主要實踐方式。由於fork子程序後,父程序資料一直在變化,子程序並不與父程序同步,RDB持久化必然無法保證實時性;RDB持久化完成後發生斷電或宕機,會導致部分資料丟失;備份頻率決定了丟失資料量的大小,提高備份頻率,意味著fork過程消耗較多的CPU資源,也會導致較大的磁碟I/O。
持久化流程
在Redis內完成RDB持久化的方法有rdbSave和rdbSaveBackground兩個函數方法(原始碼檔案rdb.c中),先簡單說下兩者差別:
- rdbSave:是同步執行的,方法呼叫後就會立刻啟動持久化流程。由於Redis是單執行緒模型,持久化過程中會阻塞,Redis無法對外提供服務;
- rdbSaveBackground:是後臺(非同步)執行的,該方法會fork出子程序,真正的持久化過程是在子程序中執行的(呼叫rdbSave),主程序會繼續提供服務;
RDB持久化的觸發必然離不開以上兩個方法,觸發的方式分為手動和自動。手動觸發容易理解,是指我們通過Redis使用者端人為的對Redis伺服器端發起持久化備份指令,然後Redis伺服器端開始執行持久化流程,這裡的指令有save和bgsave。自動觸發是Redis根據自身執行要求,在滿足預設條件時自動觸發的持久化流程,自動觸發的場景有如下幾個(摘自這篇文章):
- serverCron中
save m n設定規則自動觸發; - 從節點全量複製時,主節點傳送rdb檔案給從節點完成複製操作,主節點會出發bgsave;
- 執行
debug reload命令重新載入redis時; - 預設情況下(未開啟AOF)執行shutdown命令時,自動執行bgsave;
結合原始碼及參考文章,我整理了RDB持久化流程來幫助大家有個整體的瞭解,然後再從一些細節進行說明。
從上圖可以知道:
- 自動觸發的RDB持久化是通過rdbSaveBackground以子程序方式執行的持久化策略;
- 手動觸發是以使用者端命令方式觸發的,包含save和bgsave兩個命令,其中save命令是在Redis的命令處理執行緒以阻塞的方式呼叫
rdbSave方法完成的。
自動觸發流程是一個完整的鏈路,涵蓋了rdbSaveBackground、rdbSave等,接下來我以serverCron為例分析一下整個流程。
save規則及檢查
serverCron是Redis內的一個週期性函數,每隔100毫秒執行一次,它的其中一項工作就是:根據組態檔中save規則來判斷當前需要進行自動持久化流程,如果滿足條件則嘗試開始持久化。瞭解一下這部分的實現。
在redisServer中有幾個與RDB持久化有關的欄位,我從程式碼中摘出來,中英文對照著看下:
struct redisServer {
/* 省略其他欄位 */
/* RDB persistence */
long long dirty; /* Changes to DB from the last save
* 上次持久化後修改key的次數 */
struct saveparam *saveparams; /* Save points array for RDB,
* 對應組態檔多個save引數 */
int saveparamslen; /* Number of saving points,
* save引數的數量 */
time_t lastsave; /* Unix time of last successful save
* 上次持久化時間*/
/* 省略其他欄位 */
}
/* 對應redis.conf中的save引數 */
struct saveparam {
time_t seconds; /* 統計時間範圍 */
int changes; /* 資料修改次數 */
};saveparams對應redis.conf下的save規則,save引數是Redis觸發自動備份的觸發策略,seconds為統計時間(單位:秒), changes為在統計時間內發生寫入的次數。save m n的意思是:m秒內有n條寫入就觸發一次快照,即備份一次。save引數可以設定多組,滿足在不同條件的備份要求。如果需要關閉RDB的自動備份策略,可以使用save ""。以下為幾種設定的說明:
# 表示900秒(15分鐘)內至少有1個key的值發生變化,則執行 save 900 1 # 表示300秒(5分鐘)內至少有1個key的值發生變化,則執行 save 300 10 # 表示60秒(1分鐘)內至少有10000個key的值發生變化,則執行 save 60 10000 # 該設定將會關閉RDB方式的持久化 save ""
serverCron對RDB save規則的檢測程式碼如下所示:
int serverCron(struct aeEventLoop *eventLoop, long long id, void *clientData) {
/* 省略其他邏輯 */
/* 如果使用者請求進行AOF檔案重寫時,Redis正在執行RDB持久化,Redis會安排在RDB持久化完成後執行AOF檔案重寫,
* 如果aof_rewrite_scheduled為true,說明需要執行使用者的請求 */
/* Check if a background saving or AOF rewrite in progress terminated. */
if (hasActiveChildProcess() || ldbPendingChildren())
{
run_with_period(1000) receiveChildInfo();
checkChildrenDone();
} else {
/* 後臺無 saving/rewrite 子程序才會進行,逐個檢查每個save規則*/
for (j = 0; j < server.saveparamslen; j++) {
struct saveparam *sp = server.saveparams+j;
/* 檢查規則有幾個:滿足修改次數,滿足統計週期,達到重試時間間隔或者上次持久化完成*/
if (server.dirty >= sp->changes
&& server.unixtime-server.lastsave > sp->seconds
&&(server.unixtime-server.lastbgsave_try > CONFIG_BGSAVE_RETRY_DELAY || server.lastbgsave_status == C_OK))
{
serverLog(LL_NOTICE,"%d changes in %d seconds. Saving...", sp->changes, (int)sp->seconds);
rdbSaveInfo rsi, *rsiptr;
rsiptr = rdbPopulateSaveInfo(&rsi);
/* 執行bgsave過程 */
rdbSaveBackground(server.rdb_filename,rsiptr);
break;
}
}
/* 省略:Trigger an AOF rewrite if needed. */
}
/* 省略其他邏輯 */
}如果沒有後臺的RDB持久化或AOF重寫程序,serverCron會根據以上設定及狀態判斷是否需要執行持久化操作,判斷依據就是看lastsave、dirty是否滿足saveparams陣列中的其中一個條件。如果有一個條件匹配,則呼叫rdbSaveBackground方法,執行非同步持久化流程。
rdbSaveBackground
rdbSaveBackground是RDB持久化的輔助性方法,主要工作是fork子程序,然後根據呼叫方(父程序或者子程序)不同,有兩種不同的執行邏輯。
- 如果呼叫方是父程序,則fork出子程序,儲存子程序資訊後直接返回。
- 如果呼叫方是子程序則呼叫rdbSave執行RDB持久化邏輯,持久化完成後退出子程序。
int rdbSaveBackground(char *filename, rdbSaveInfo *rsi) {
pid_t childpid;
if (hasActiveChildProcess()) return C_ERR;
server.dirty_before_bgsave = server.dirty;
server.lastbgsave_try = time(NULL);
// fork子程序
if ((childpid = redisFork(CHILD_TYPE_RDB)) == 0) {
int retval;
/* Child 子程序:修改程序標題 */
redisSetProcTitle("redis-rdb-bgsave");
redisSetCpuAffinity(server.bgsave_cpulist);
// 執行rdb持久化
retval = rdbSave(filename,rsi);
if (retval == C_OK) {
sendChildCOWInfo(CHILD_TYPE_RDB, 1, "RDB");
}
// 持久化完成後,退出子程序
exitFromChild((retval == C_OK) ? 0 : 1);
} else {
/* Parent 父程序:記錄fork子程序的時間等資訊*/
if (childpid == -1) {
server.lastbgsave_status = C_ERR;
serverLog(LL_WARNING,"Can't save in background: fork: %s",
strerror(errno));
return C_ERR;
}
serverLog(LL_NOTICE,"Background saving started by pid %ld",(long) childpid);
// 記錄子程序開始的時間、型別等。
server.rdb_save_time_start = time(NULL);
server.rdb_child_type = RDB_CHILD_TYPE_DISK;
return C_OK;
}
return C_OK; /* unreached */
}rdbSave是真正執行持久化的方法,它在執行時存在大量的I/O、計算操作,耗時、CPU佔用較大,在Redis的單執行緒模型中持久化過程會持續佔用執行緒資源,進而導致Redis無法提供其他服務。為了解決這一問題Redis在rdbSaveBackground中fork出子程序,由子程序完成持久化工作,避免了佔用父程序過多的資源。
需要注意的是,如果父程序記憶體佔用過大,fork過程會比較耗時,在這個過程中父程序無法對外提供服務;另外,需要綜合考慮計算機記憶體使用量,fork子程序後會佔用雙倍的記憶體資源,需要確保記憶體夠用。通過info stats命令檢視latest_fork_usec選項,可以獲取最近一個fork以操作的耗時。
rdbSave
Redis的rdbSave函數是真正進行RDB持久化的函數,流程、細節賊多,整體流程可以總結為:建立並開啟臨時檔案、Redis記憶體資料寫入臨時檔案、臨時檔案寫入磁碟、臨時檔案重新命名為正式RDB檔案、更新持久化狀態資訊(dirty、lastsave)。其中「Redis記憶體資料寫入臨時檔案」最為核心和複雜,寫入過程直接體現了RDB檔案的檔案格式,本著一圖勝千言的理念,我按照原始碼流程繪製了下圖。
補充說明一下,上圖右下角「遍歷當前資料庫的鍵值對並寫入」這個環節會根據不同型別的Redis資料型別及底層資料結構採用不同的格式寫入到RDB檔案中,不再展開了。我覺得大家對整個過程有個直觀的理解就好,這對於我們理解Redis內部的運作機制大有裨益。
AOF持久化
上一節我們知道RDB是一種時間點(point-to-time)快照,適合資料備份及災難恢復,由於工作原理的「先天性缺陷」無法保證實時性持久化,這對於快取丟失零容忍的系統來說是個硬傷,於是就有了AOF。
AOF工作原理
AOF是Append Only File的縮寫,它是Redis的完全持久化策略,從1.1版本開始支援;這裡的file儲存的是引起Redis資料修改的命令集合(比如:set/hset/del等),這些集合按照Redis Server的處理順序追加到檔案中。當重新啟動Redis時,Redis就可以從頭讀取AOF中的指令並重放,進而恢復關閉前的資料狀態。
AOF持久化預設是關閉的,修改redis.conf以下資訊並重新啟動,即可開啟AOF持久化功能。
# no-關閉,yes-開啟,預設no appendonly yes appendfilename appendonly.aof
AOF本質是為了持久化,持久化物件是Redis內每一個key的狀態,持久化的目的是為了在Reids發生故障重新啟動後能夠恢復至重新啟動前或故障前的狀態。相比於RDB,AOF採取的策略是按照執行順序持久化每一條能夠引起Redis中物件狀態變更的命令,命令是有序的、有選擇的。把aof檔案轉移至任何一臺Redis Server,從頭到尾按序重放這些命令即可恢復如初。舉個例子:
首先執行指令set number 0,然後隨機呼叫incr number、get number 各5次,最後再執行一次get number ,我們得到的結果肯定是5。
因為在這個過程中,能夠引起number狀態變更的只有set/incr型別的指令,並且它們執行的先後順序是已知的,無論執行多少次get都不會影響number的狀態。所以,保留所有set/incr命令並持久化至aof檔案即可。按照aof的設計原理,aof檔案中的內容應該是這樣的(這裡是假設,實際為RESP協定):
set number 0 incr number incr number incr number incr number incr number
最本質的原理用「命令重放」四個字就可以概括。但是,考慮實際生產環境的複雜性及作業系統等方面的限制,Redis所要考慮的工作要比這個例子複雜的多:
- Redis Server啟動後,aof檔案一直在追加命令,檔案會越來越大。檔案越大,Redis重新啟動後恢復耗時越久;檔案太大,轉移工作就越難;不加管理,可能撐爆硬碟。很顯然,需要在合適的時機對檔案進行精簡。例子中的5條incr指令很明顯的可以替換為為一條
set命令,存在很大的壓縮空間。 - 眾所周知,檔案I/O是作業系統效能的短板,為了提高效率,檔案系統設計了一套複雜的快取機制,Redis操作命令的追加操作只是把資料寫入了緩衝區(aof_buf),從緩衝區到寫入物理檔案在效能與安全之間權衡會有不同的選擇。
- 檔案壓縮即意味著重寫,重寫時即可依據已有的aof檔案做命令整合,也可以先根據當前Redis內資料的狀態做快照,再把儲存快照過程中的新增的命令做追加。
- aof備份後的檔案是為了恢復資料,結合aof檔案的格式、完整性等因素,Redis也要設計一套完整的方案做支援。
持久化流程
從流程上來看,AOF的工作原理可以概括為幾個步驟:命令追加(append)、檔案寫入與同步(fsync)、檔案重寫(rewrite)、重新啟動載入(load),接下來依次瞭解每個步驟的細節及背後的設計哲學。
命令追加
當 AOF 持久化功能處於開啟狀態時,Redis 在執行完一個寫命令之後,會以協定格式(也就是RESP,即 Redis 使用者端和伺服器互動的通訊協定 )把被執行的寫命令追加到 Redis 伺服器端維護的 AOF 緩衝區末尾。對AOF檔案只有單執行緒的追加操作,沒有seek等複雜的操作,即使斷電或宕機也不存在檔案損壞風險。另外,使用文字協定好處多多:
- 文字協定有很好的相容性;
- 文字協定就是使用者端的請求命令,不需要二次處理,節省了儲存及載入時的處理開銷;
- 文字協定具有可讀性,方便檢視、修改等處理。
AOF緩衝區型別為Redis自主設計的資料結構sds,Redis會根據命令的型別採用不同的方法(catAppendOnlyGenericCommand、catAppendOnlyExpireAtCommand等)對命令內容進行處理,最後寫入緩衝區。
需要注意的是:如果命令追加時正在進行AOF重寫,這些命令還會追加到重寫緩衝區(aof_rewrite_buffer)。
檔案寫入與同步
AOF檔案的寫入與同步離不開作業系統的支援,開始介紹之前,我們需要補充一下Linux I/O緩衝區相關知識。硬碟I/O效能較差,檔案讀寫速度遠遠比不上CPU的處理速度,如果每次檔案寫入都等待資料寫入硬碟,會整體拉低作業系統的效能。為了解決這個問題,作業系統提供了延遲寫(delayed write)機制來提高硬碟的I/O效能。
傳統的UNIX實現在核心中設有緩衝區快取記憶體或頁面快取記憶體,大多數磁碟I/O都通過緩衝進行。 當將資料寫入檔案時,核心通常先將該資料複製到其中一個緩衝區中,如果該緩衝區尚未寫滿,則並不將其排入輸出佇列,而是等待其寫滿或者當核心需要重用該緩衝區以便存放其他磁碟塊資料時, 再將該緩衝排入到輸出佇列,然後待其到達隊首時,才進行實際的I/O操作。這種輸出方式就被稱為延遲寫。
延遲寫減少了磁碟讀寫次數,但是卻降低了檔案內容的更新速度,使得欲寫到檔案中的資料在一段時間內並沒有寫到磁碟上。當系統發生故障時,這種延遲可能造成檔案更新內容的丟失。為了保證磁碟上實際檔案系統與緩衝區快取記憶體中內容的一致性,UNIX系統提供了sync、fsync和fdatasync三個函數為強制寫入硬碟提供支援。
Redis每次事件輪訓結束前(beforeSleep)都會呼叫函數flushAppendOnlyFile,flushAppendOnlyFile會把AOF緩衝區(aof_buf)中的資料寫入核心緩衝區,並且根據appendfsync設定來決定採用何種策略把核心緩衝區中的資料寫入磁碟,即呼叫fsync()。該設定有三個可選項always、no、everysec,具體說明如下:
- always:每次都呼叫
fsync(),是安全性最高、效能最差的一種策略。 - no:不會呼叫
fsync()。效能最好,安全性最差。 - everysec:僅在滿足同步條件時呼叫
fsync()。這是官方建議的同步策略,也是預設設定,做到兼顧效能和資料安全性,理論上只有在系統突然宕機的情況下丟失1秒的資料。
注意:上面介紹的策略受設定項no-appendfsync-on-rewrite的影響,它的作用是告知Redis:AOF檔案重寫期間是否禁止呼叫fsync(),預設是no。
如果appendfsync設定為always或everysec,後臺正在進行的BGSAVE或者BGREWRITEAOF消耗過多的磁碟I/O,在某些Linux系統設定下,Redis對fsync()的呼叫可能阻塞很長時間。然而這個問題還沒有修復,因為即使是在不同的執行緒中執行fsync(),同步寫入操作也會被阻塞。
為了緩解此問題,可以使用該選項,以防止在進行BGSAVE或BGREWRITEAOF時在主程序中呼叫fsync()。
- 設定為
yes意味著,如果子程序正在進行BGSAVE或BGREWRITEAOF,AOF的持久化能力就與appendfsync設定為no有著相同的效果。最糟糕的情況下,這可能會導致30秒的快取資料丟失。 - 如果你的系統有上面描述的延遲問題,就把這個選項設定為
yes,否則保持為no。
檔案重寫
如前面提到的,Redis長時間執行,命令不斷寫入AOF,檔案會越來越大,不加控制可能影響宿主機的安全。
為了解決AOF檔案體積問題,Redis引入了AOF檔案重寫功能,它會根據Redis內資料物件的最新狀態生成新的AOF檔案,新舊檔案對應的資料狀態一致,但是新檔案會具有較小的體積。重寫既減少了AOF檔案對磁碟空間的佔用,又可以提高Redis重新啟動時資料恢復的速度。還是下面這個例子,舊檔案中的6條命令等同於新檔案中的1條命令,壓縮效果顯而易見。
我們說,AOF檔案太大時會觸發AOF檔案重寫,那到底是多大呢?有哪些情況會觸發重寫操作呢?
**
與RDB方式一樣,AOF檔案重寫既可以手動觸發,也會自動觸發。手動觸發直接呼叫bgrewriteaof命令,如果當時無子程序執行會立刻執行,否則安排在子程序結束後執行。自動觸發由Redis的週期性方法serverCron檢查在滿足一定條件時觸發。先了解兩個設定項:
- auto-aof-rewrite-percentage:代表當前AOF檔案大小(aof_current_size)和上一次重寫後AOF檔案大小(aof_base_size)相比,增長的比例。
- auto-aof-rewrite-min-size:表示執行
BGREWRITEAOF時AOF檔案佔用空間最小值,預設為64MB;
Redis啟動時把aof_base_size初始化為當時aof檔案的大小,Redis執行過程中,當AOF檔案重寫操作完成時,會對其進行更新;aof_current_size為serverCron執行時AOF檔案的實時大小。當滿足以下兩個條件時,AOF檔案重寫就會觸發:
增長比例:(aof_current_size - aof_base_size) / aof_base_size > auto-aof-rewrite-percentage 檔案大小:aof_current_size > auto-aof-rewrite-min-size
手動觸發與自動觸發的程式碼如下,同樣在週期性方法serverCron中:
int serverCron(struct aeEventLoop *eventLoop, long long id, void *clientData) {
/* 省略其他邏輯 */
/* 如果使用者請求進行AOF檔案重寫時,Redis正在執行RDB持久化,Redis會安排在RDB持久化完成後執行AOF檔案重寫,
* 如果aof_rewrite_scheduled為true,說明需要執行使用者的請求 */
if (!hasActiveChildProcess() &&
server.aof_rewrite_scheduled)
{
rewriteAppendOnlyFileBackground();
}
/* Check if a background saving or AOF rewrite in progress terminated. */
if (hasActiveChildProcess() || ldbPendingChildren())
{
run_with_period(1000) receiveChildInfo();
checkChildrenDone();
} else {
/* 省略rdb持久化條件檢查 */
/* AOF重寫條件檢查:aof開啟、無子程序執行、增長百分比已設定、當前檔案大小超過閾值 */
if (server.aof_state == AOF_ON &&
!hasActiveChildProcess() &&
server.aof_rewrite_perc &&
server.aof_current_size > server.aof_rewrite_min_size)
{
long long base = server.aof_rewrite_base_size ?
server.aof_rewrite_base_size : 1;
/* 計算增長百分比 */
long long growth = (server.aof_current_size*100/base) - 100;
if (growth >= server.aof_rewrite_perc) {
serverLog(LL_NOTICE,"Starting automatic rewriting of AOF on %lld%% growth",growth);
rewriteAppendOnlyFileBackground();
}
}
}
/**/
}AOF檔案重寫的流程是什麼?聽說Redis支援混合持久化,對AOF檔案重寫有什麼影響?
從4.0版本開始,Redis在AOF模式中引入了混合持久化方案,即:純AOF方式、RDB+AOF方式,這一策略由設定引數aof-use-rdb-preamble(使用RDB作為AOF檔案的前半段)控制,預設關閉(no),設定為yes可開啟。所以,在AOF重寫過程中檔案的寫入會有兩種不同的方式。當aof-use-rdb-preamble的值是:
- no:按照AOF格式寫入命令,與4.0前版本無差別;
- yes:先按照RDB格式寫入資料狀態,然後把重寫期間AOF緩衝區的內容以AOF格式寫入,檔案前半部分為RDB格式,後半部分為AOF格式。
結合原始碼(6.0版本,原始碼太多這裡不貼出,可參考aof.c)及參考資料,繪製AOF重寫(BGREWRITEAOF)流程圖:
結合上圖,總結一下AOF檔案重寫的流程:
- rewriteAppendOnlyFileBackground開始執行,檢查是否有正在進行的AOF重寫或RDB持久化子程序:如果有,則退出該流程;如果沒有,則繼續建立接下來父子程序間資料傳輸的通訊管道。執行fork()操作,成功後父子程序分別執行不同的流程。
父程序:
- 記錄子程序資訊(pid)、時間戳等;
- 繼續響應其他使用者端請求;
- 收集AOF重寫期間的命令,追加至aof_rewrite_buffer;
- 等待並向子程序同步aof_rewrite_buffer的內容;
子程序:
- 修改當前程序名稱,建立重寫所需的臨時檔案,呼叫rewriteAppendOnlyFile函數;
- 根據
aof-use-rdb-preamble設定,以RDB或AOF方式寫入前半部分,並同步至硬碟; - 從父程序接收增量AOF命令,以AOF方式寫入後半部分,並同步至硬碟;
- 重新命名AOF檔案,子程序退出。
資料載入
Redis啟動後通過loadDataFromDisk函數執行資料載入工作。這裡需要注意,雖然持久化方式可以選擇AOF、RDB或者兩者兼用,但是資料載入時必須做出選擇,兩種方式各自載入一遍就亂套了。
理論上,AOF持久化比RDB具有更好的實時性,當開啟了AOF持久化方式,Redis在資料載入時優先考慮AOF方式。而且,Redis 4.0版本後AOF支援了混合持久化,載入AOF檔案需要考慮版本相容性。Redis資料載入流程如下圖所示:
在AOF方式下,開啟混合持久化機制生成的檔案是「RDB頭+AOF尾」,未開啟時生成的檔案全部為AOF格式。考慮兩種檔案格式的相容性,如果Redis發現AOF檔案為RDB頭,會使用RDB資料載入的方法讀取並恢復前半部分;然後再使用AOF方式讀取並恢復後半部分。由於AOF格式儲存的資料為RESP協定命令,Redis採用偽使用者端執行命令的方式來恢復資料。
如果在AOF命令追加過程中發生宕機,由於延遲寫的技術特點,AOF的RESP命令可能不完整(被截斷)。遇到這種情況時,Redis會按照設定項aof-load-truncated執行不同的處理策略。這個設定是告訴Redis啟動時讀取aof檔案,如果發現檔案被截斷(不完整)時該如何處理:
- yes:則儘可能多的載入資料,並以紀錄檔的方式通知使用者;
- no:則以系統錯誤的方式崩潰,並禁止啟動,需要使用者修復檔案後再重新啟動。
總結
Redis提供了兩種持久化的選擇:RDB支援以特定的實踐間隔為資料集生成時間點快照;AOF把Redis Server收到的每條寫指令持久化到紀錄檔中,待Redis重新啟動時通過重放命令恢復資料。紀錄檔格式為RESP協定,對紀錄檔檔案只做append操作,無失真壞風險。並且當AOF檔案過大時可以自動重寫壓縮檔案。
當然,如果你不需要對資料進行持久化,也可以禁用Redis的持久化功能,但是大多數情況並非如此。實際上,我們時有可能同時使用RDB和AOF兩種方式的,最重要的就是我們要理解兩者的區別,以便合理使用。
RDB vs AOF
RDB優點
- RDB是一個緊湊壓縮的二進位制檔案,代表Redis在某一個時間點上的資料快照,非常適合用於備份、全量複製等場景。
- RDB對災難恢復、資料遷移非常友好,RDB檔案可以轉移至任何需要的地方並重新載入。
- RDB是Redis資料的記憶體快照,資料恢復速度較快,相比於AOF的命令重放有著更高的效能。
RDB缺點
- RDB方式無法做到實時或秒級持久化。因為持久化過程是通過fork子程序後由子程序完成的,子程序的記憶體只是在fork操作那一時刻父程序的資料快照,而fork操作後父程序持續對外服務,內部資料時刻變更,子程序的資料不再更新,兩者始終存在差異,所以無法做到實時性。
- RDB持久化過程中的fork操作,會導致記憶體佔用加倍,而且父程序資料越多,fork過程越長。
- Redis請求高並行可能會頻繁命中save規則,導致fork操作及持久化備份的頻率不可控;
- RDB檔案有檔案格式要求,不同版本的Redis會對檔案格式進行調整,存在老版本無法相容新版本的問題。
AOF優點
- AOF持久化有更好的實時性,我們可以選擇三種不同的方式(appendfsync):no、every second、always,every second作為預設的策略具有最好的效能,極端情況下可能會丟失一秒的資料。
- AOF檔案只有append操作,無複雜的seek等檔案操作,沒有損壞風險。即使最後寫入資料被截斷,也很容易使用
redis-check-aof工具修復; - 當AOF檔案變大時,Redis可在後臺自動重寫。重寫過程中舊檔案會持續寫入,重寫完成後新檔案將變得更小,並且重寫過程中的增量命令也會append到新檔案。
- AOF檔案以已於理解與解析的方式包含了對Redis中資料的所有操作命令。即使不小心錯誤的清除了所有資料,只要沒有對AOF檔案重寫,我們就可以通過移除最後一條命令找回所有資料。
- AOF已經支援混合持久化,檔案大小可以有效控制,並提高了資料載入時的效率。
AOF缺點
- 對於相同的資料集合,AOF檔案通常會比RDB檔案大;
- 在特定的fsync策略下,AOF會比RDB略慢。一般來講,fsync_every_second的效能仍然很高,fsync_no的效能與RDB相當。但是在巨大的寫壓力下,RDB更能提供最大的低延時保障。
- 在AOF上,Redis曾經遇到一些幾乎不可能在RDB上遇到的罕見bug。一些特殊的指令(如BRPOPLPUSH)導致重新載入的資料與持久化之前不一致,Redis官方曾經在相同的條件下進行測試,但是無法復現問題。
使用建議
對RDB和AOF兩種持久化方式的工作原理、執行流程及優缺點了解後,我們來思考下,實際場景中應該怎麼權衡利弊,合理的使用兩種持久化方式。如果僅僅是使用Redis作為快取工具,所有資料可以根據持久化資料庫進行重建,則可關閉持久化功能,做好預熱、快取穿透、擊穿、雪崩之類的防護工作即可。
一般情況下,Redis會承擔更多的工作,如分散式鎖、排行榜、註冊中心等,持久化功能在災難恢復、資料遷移方面將發揮較大的作用。建議遵循幾個原則:
- 不要把Redis作為資料庫,所有資料儘可能可由應用服務自動重建。
- 使用4.0以上版本Redis,使用AOF+RDB混合持久化功能。
- 合理規劃Redis最大佔用記憶體,防止AOF重寫或save過程中資源不足。
- 避免單機部署多範例。
- 生產環境多為叢集化部署,可在slave開啟持久化能力,讓master更好的對外提供寫服務。
- 備份檔案應自動上傳至異地機房或雲端儲存,做好災難備份。
關於fork()
通過上面的分析,我們都知道RDB的快照、AOF的重寫都需要fork,這是一個重量級操作,會對Redis造成阻塞。因此為了不影響Redis主程序響應,我們需要儘可能降低阻塞。
- 降低fork的頻率,比如可以手動來觸發RDB生成快照、與AOF重寫;
- 控制Redis最大使用記憶體,防止fork耗時過長;
- 使用更高效能的硬體;
- 合理設定Linux的記憶體分配策略,避免因為實體記憶體不足導致fork失敗。
更多程式設計相關知識,請存取:!!
以上就是Redis深入學習之詳解持久化原理的詳細內容,更多請關注TW511.COM其它相關文章!