手把手帶你搞懂Redis高可用叢集

推薦學習:
幾種 Redis 高可用性的解決方案。包括:「主從模式」、「哨兵機制」以及「哨兵叢集」。
- 「主從模式」具有讀寫分離,分擔讀壓力、資料備份,提供多個副本等優點。
- 「哨兵機制」在主節點故障後能自動將從節點提升成主節點,不需要人工干預操作就能恢復服務可用。
- 「哨兵叢集」解決單點故障以及單機哨兵產生「誤判」問題。
Redis 從最簡單的單機版,經過資料持久化、主從多副本、哨兵叢集,通過這麼一番的優化,不管是效能還是穩定性,都越來越高。
但是隨著時間的發展,公司業務體量迎來了爆炸性增長,此時的架構模型,還能夠承擔這麼大的流量嗎?
比如有這麼一個需求:要用 Redis 儲存 5000 萬個鍵值對,每個鍵值對大約是 512B,為了能快速部署並對外提供服務,我們採用雲主機來執行 Redis 範例,那麼,該如何選擇雲主機的記憶體容量呢?
通過計算,這些鍵值對所佔的記憶體空間大約是 25GB(5000 萬 *512B)。
想到的第一個方案就是:選擇一臺 32GB 記憶體的雲主機來部署 Redis。因為 32GB 的記憶體能儲存所有資料,而且還留有 7GB,可以保證系統的正常執行。
同時,還採用 RDB 對資料做持久化,以確保 Redis 範例故障後,還能從 RDB 恢復資料。
但是,在使用的過程中會發現,Redis 的響應有時會非常慢。通過 INFO命令 檢視 Redis 的latest_fork_usec指標值(表示最近一次 fork 的耗時),結果發現這個指標值特別高。
這跟 Redis 的持久化機制有關係。
在使用 RDB 進行持久化時,Redis 會 fork 子程序來完成,fork 操作的用時和 Redis 的資料量是正相關的,而 fork 在執行時會阻塞主執行緒。資料量越大,fork 操作造成的主執行緒阻塞的時間越長。
所以,在使用 RDB 對 25GB 的資料進行持久化時,資料量較大,後臺執行的子程序在 fork 建立時阻塞了主執行緒,於是就導致 Redis 響應變慢了。
顯然這個方案是不可行的,我們必須要尋找其他的方案。
如何儲存更多資料?
為了儲存大量資料,我們一般有兩種方法:「縱向擴充套件」和「橫向擴充套件」:
- 縱向擴充套件:升級單個 Redis 範例的資源設定,包括增加記憶體容量、增加磁碟容量、使用更高設定的 CPU;
- 橫向擴充套件:橫向增加當前 Redis 範例的個數。
首先,「縱向擴充套件」的好處是,實施起來簡單、直接。不過,這個方案也面臨兩個潛在的問題。
- 第一個問題是,當使用 RDB 對資料進行持久化時,如果資料量增加,需要的記憶體也會增加,主執行緒
fork子程序時就可能會阻塞。 - 第二個問題:縱向擴充套件會受到硬體和成本的限制。 這很容易理解,畢竟,把記憶體從 32GB 擴充套件到 64GB 還算容易,但是,要想擴充到 1TB,就會面臨硬體容量和成本上的限制了。
與「縱向擴充套件」相比,「橫向擴充套件」是一個擴充套件性更好的方案。這是因為,要想儲存更多的資料,採用這種方案的話,只用增加 Redis 的範例個數就行了,不用擔心單個範例的硬體和成本限制。
Redis 叢集就是基於「橫向擴充套件」實現的 ,通過啟動多個 Redis 範例組成一個叢集,然後按照一定的規則,把收到的資料劃分成多份,每一份用一個範例來儲存。
Redis 叢集
Redis 叢集是一種分散式資料庫方案,叢集通過分片(sharding,也可以叫切片)來進行資料共用,並提供複製和故障轉移功能。
回到我們剛剛的場景中,如果把 25GB 的資料平均分成 5 份(當然,也可以不做均分),使用 5 個範例來儲存,每個範例只需要儲存 5GB 資料。如下圖所示:
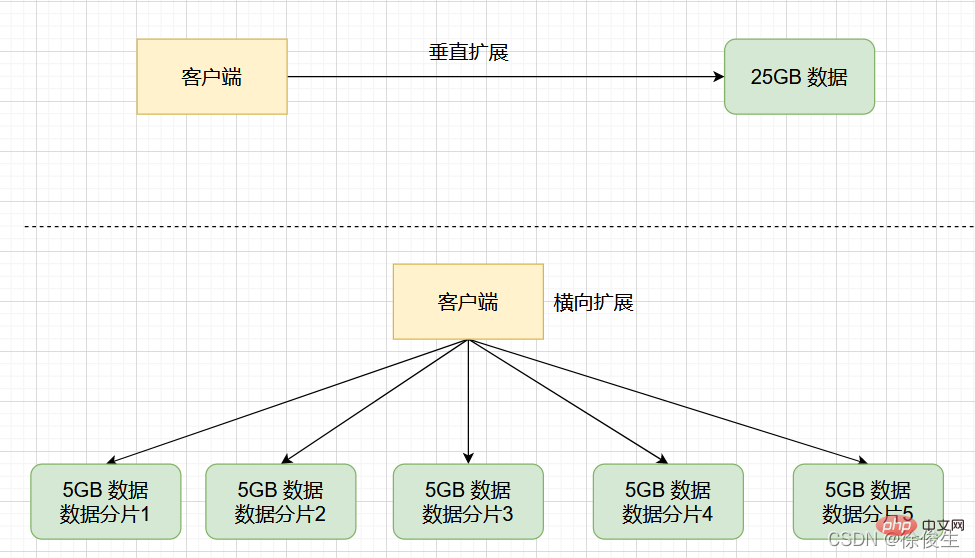
那麼,在切片叢集中,範例在為 5GB 資料生成 RDB 時,資料量就小了很多,fork 子程序一般不會給主執行緒帶來較長時間的阻塞。
採用多個範例儲存資料切片後,我們既能儲存 25GB 資料,又避免了 fork 子程序阻塞主執行緒而導致的響應突然變慢。
在實際應用 Redis 時,隨著業務規模的擴充套件,儲存大量資料的情況通常是無法避免的。而 Redis 叢集,就是一個非常好的解決方案。
下面我們開始研究如何搭建一個 Redis 叢集?
搭建 Redis 叢集
一個 Redis 叢集通常由多個節點組成,在剛開始的時候,每個節點都是相互獨立地,節點之間沒有任何關聯。要組建一個可以工作的叢集,我們必須將各個獨立的節點連線起來,構成一個包含多節點的叢集。
我們可以通過 CLUSTER MEET 命令,將各個節點連線起來:
CLUSTER MEET <ip> <port>
- ip:待加入叢集的節點 ip
- port:待加入叢集的節點 port
命令說明:通過向一個節點 A 傳送 CLUSTER MEET 命令,可以讓接收命令的節點 A 將另一個節點 B 新增到節點 A 所在的叢集中。
這麼說有點抽象,下面看一個例子。
假設現在有三個獨立的節點 127.0.0.1:7001、 127.0.0.1:7002、 127.0.0.1:7003。
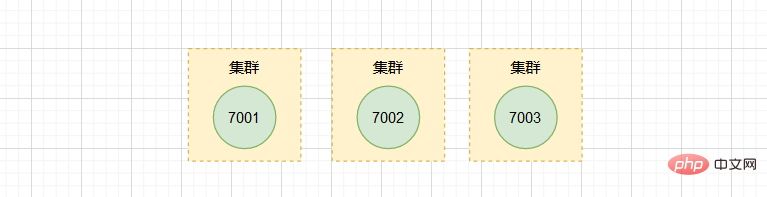
我們首先使用使用者端連上節點 7001:
$ redis-cli -c -p 7001
然後向節點 7001 傳送命令,將節點 7002 新增到 7001 所在的叢集裡:
127.0.0.1:7001> CLUSTER MEET 127.0.0.1 7002
同樣的,我們向 7003 傳送命令,也新增到 7001 和 7002 所在的叢集。
127.0.0.1:7001> CLUSTER MEET 127.0.0.1 7003
通過
CLUSTER NODES命令可以檢視叢集中的節點資訊。
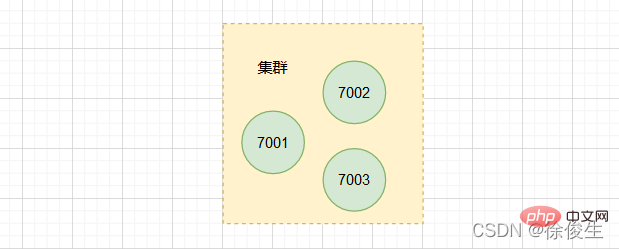
現在叢集中已經包含 7001、 7002 和 7003 三個節點。不過,在使用單個範例的時候,資料存在哪兒,使用者端存取哪兒,都是非常明確的。但是,切片叢集不可避免地涉及到多個範例的分散式管理問題。
要想把切片叢集用起來,我們就需要解決兩大問題:
- 資料切片後,在多個範例之間如何分佈?
- 使用者端怎麼確定想要存取的資料在哪個範例上?
接下來,我們就一個個地解決。
資料切片和範例的對應分佈關係
在切片叢集中,資料需要分佈在不同範例上,那麼,資料和範例之間如何對應呢?
這就和接下來要講的 Redis Cluster 方案有關了。不過,我們要先弄明白切片叢集和 Redis Cluster 的聯絡與區別。
在 Redis 3.0 之前,官方並沒有針對切片叢集提供具體的方案。從 3.0 開始,官方提供了一個名為
Redis Cluster的方案,用於實現切片叢集。
實際上,切片叢集是一種儲存大量資料的通用機制,這個機制可以有不同的實現方案。 Redis Cluster 方案中就規定了資料和範例的對應規則。
具體來說, Redis Cluster 方案採用 雜湊槽(Hash Slot),來處理資料和範例之間的對映關係。
雜湊槽與 Redis 範例對映
在 Redis Cluster 方案中,一個切片叢集共有 16384 個雜湊槽(2^14),這些雜湊槽類似於資料分割區,每個鍵值對都會根據它的 key,被對映到一個雜湊槽中。
在上面我們分析的,通過 CLUSTER MEET 命令將 7001、7002、7003 三個節點連線到同一個叢集裡面,但是這個叢集目前是處於下線狀態的,因為叢集中的三個節點沒有分配任何槽。
那麼,這些雜湊槽又是如何被對映到具體的 Redis 範例上的呢?
我們可以使用 CLUSTER MEET 命令手動建立範例間的連線,形成叢集,再使用CLUSTER ADDSLOTS 命令,指定每個範例上的雜湊槽個數。
CLUSTER ADDSLOTS <slot> [slot ...]
Redis5.0 提供
CLUSTER CREATE命令建立叢集,使用該命令,Redis 會自動把這些槽平均分佈在叢集範例上。
舉個例子,我們通過以下命令,給 7001、7002、7003 三個節點分別指派槽。
將槽 0 ~ 槽5000 指派給 給 7001 :
127.0.0.1:7001> CLUSTER ADDSLOTS 0 1 2 3 4 ... 5000
將槽 5001 ~ 槽10000 指派給 給 7002 :
127.0.0.1:7002> CLUSTER ADDSLOTS 5001 5002 5003 5004 ... 10000
將槽 10001~ 槽 16383 指派給 給 7003 :
127.0.0.1:7003> CLUSTER ADDSLOTS 10001 10002 10003 10004 ... 16383
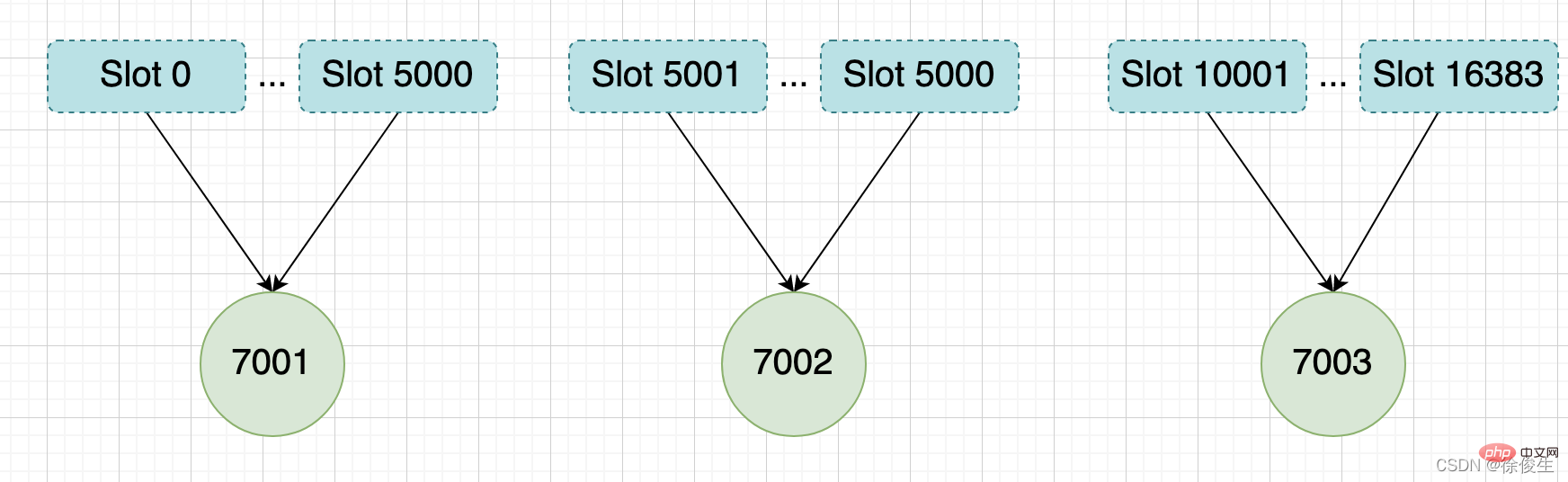
當三個 CLUSTER ADDSLOTS 命令都執行完畢之後,資料庫中的 16384 個槽都已經被指派給了對應的節點,此時叢集進入上線狀態。
通過雜湊槽,切片叢集就實現了資料到雜湊槽、雜湊槽再到範例的分配。
但是,即使範例有了雜湊槽的對映資訊,使用者端又是怎麼知道要存取的資料在哪個範例上呢?
使用者端如何定位資料?
一般來說,使用者端和叢集範例建立連線後,範例就會把雜湊槽的分配資訊發給使用者端。但是,在叢集剛剛建立的時候,每個範例只知道自己被分配了哪些雜湊槽,是不知道其他範例擁有的雜湊槽資訊的。
那麼,使用者端是如何可以在存取任何一個範例時,就能獲得所有的雜湊槽資訊呢?
Redis 範例會把自己的雜湊槽資訊發給和它相連線的其它範例,來完成雜湊槽分配資訊的擴散。當範例之間相互連線後,每個範例就有所有雜湊槽的對映關係了。
使用者端收到雜湊槽資訊後,會把雜湊槽資訊快取在本地。當用戶端請求鍵值對時,會先計算鍵所對應的雜湊槽,然後就可以給相應的範例傳送請求了。
當用戶端向節點請求鍵值對時,接收命令的節點會計算出命令要處理的資料庫鍵屬於哪個槽,並檢查這個槽是否指派給了自己:
- 如果鍵所在的槽剛好指派給了當前節點,那麼節點會直接執行這個命令;
- 如果沒有指派給當前節點,那麼節點會向用戶端返回一個
MOVED錯誤,然後重定向(redirect)到正確的節點,並再次傳送之前待執行的命令。
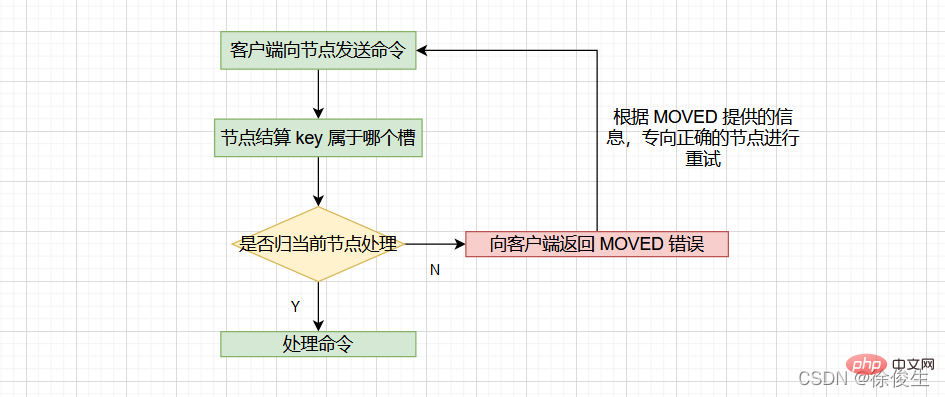
計算鍵屬於哪個槽
節點通過以下演演算法來定義 key 屬於哪個槽:
crc16(key,keylen) & 0x3FFF;
- crc16:用於計算 key 的 CRC-16 校驗和
- 0x3FFF:換算成 10 進位制是 16383
- & 0x3FFF:用於計算出一個介於 0~16383 之間的整數作為 key 的槽號。
通過
CLUSTER KEYSLOT <KEY>命令可以檢視 key 屬於哪個槽。
判斷槽是否由當前節點負責處理
當節點計算出 key 所屬的 槽 i 之後,節點會判斷 槽 i 是否被指派了自己。那麼如何判斷呢?
每個節點會維護一個 「slots陣列」,節點通過檢查 slots[i] ,判斷 槽 i 是否由自己負責:
- 如果說
slots[i]對應的節點是當前節點的話,那麼說明槽 i由當前節點負責,節點可以執行使用者端傳送的命令; - 如果說
slots[i]對應的不是當前節點,節點會根據slots[i]所指向的節點向用戶端返回MOVED錯誤,指引使用者端轉到正確的節點。
MOVED 錯誤
格式:
MOVED <slot> <ip>:<port>
- slot:鍵所在的槽
- ip:負責處理槽 slot 節點的 ip
- port:負責處理槽 slot 節點的 port
比如:MOVED 10086 127.0.0.1:7002,表示,使用者端請求的鍵值對所在的雜湊槽 10086,實際是在 127.0.0.1:7002 這個範例上。
通過返回的 MOVED 命令,就相當於把雜湊槽所在的新範例的資訊告訴給使用者端了。
這樣一來,使用者端就可以直接和 7002 連線,並行送操作請求了。
同時,使用者端還會更新本地快取,將該槽與 Redis 範例對應關係更新正確。
叢集模式的
redis-cli使用者端在接收到MOVED錯誤時,並不會列印出MOVED錯誤,而是根據MOVED錯誤自動進行節點轉向,並列印出轉向資訊,所以我們是看不見節點返回的MOVED錯誤的。而使用單機模式的redis-cli使用者端可以列印MOVED錯誤。
其實,Redis 告知使用者端重定向存取新範例分兩種情況:MOVED 和 ASK 。下面我們分析下 ASK 重定向命令的使用方法。
重新分片
在叢集中,範例和雜湊槽的對應關係並不是一成不變的,最常見的變化有兩個:
- 在叢集中,範例有新增或刪除,Redis 需要重新分配雜湊槽;
- 為了負載均衡,Redis 需要把雜湊槽在所有範例上重新分佈一遍。
重新分片可以線上進行,也就是說,重新分片的過程中,叢集不需要下線。
舉個例子,上面提到,我們組成了 7001、7002、7003 三個節點的叢集,我們可以向這個叢集新增一個新節點127.0.0.1:7004。
$ redis-cli -c -p 7001 127.0.0.1:7001> CLUSTER MEET 127.0.0.1 7004 OK
然後通過重新分片,將原本指派給節點 7003 的槽 15001 ~ 槽 16383 改為指派給 7004。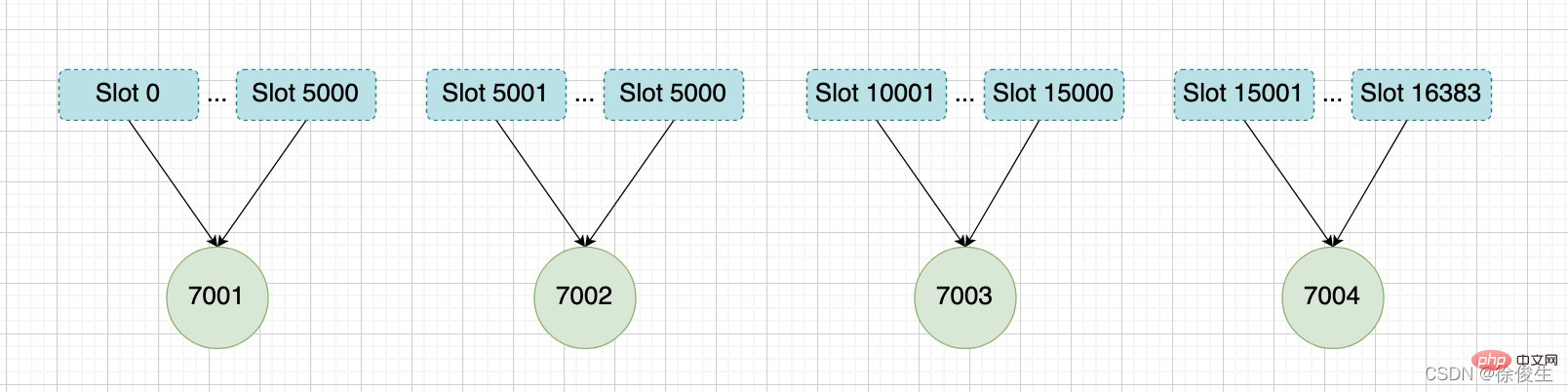
在重新分片的期間,源節點向目標節點遷移槽的過程中,可能會出現這樣一種情況:如果某個槽的資料比較多,部分遷移到新範例,還有一部分沒有遷移咋辦?
在這種遷移部分完成的情況下,使用者端就會收到一條 ASK 報錯資訊。
ASK 錯誤
如果使用者端向目標節點傳送一個與資料庫鍵有關的命令,並且這個命令要處理的鍵正好屬於被遷移的槽時:
- 源節點會先在自己的資料庫裡查詢指定的鍵,如果找到的話,直接執行命令;
- 相反,如果源節點沒有找到,那麼這個鍵就有可能已經遷移到了目標節點,源節點就會向用戶端傳送一個
ASK錯誤,指引使用者端轉向目標節點,並再次傳送之前要執行的命令。
看起來好像有點複雜,我們舉個例子來解釋一下。
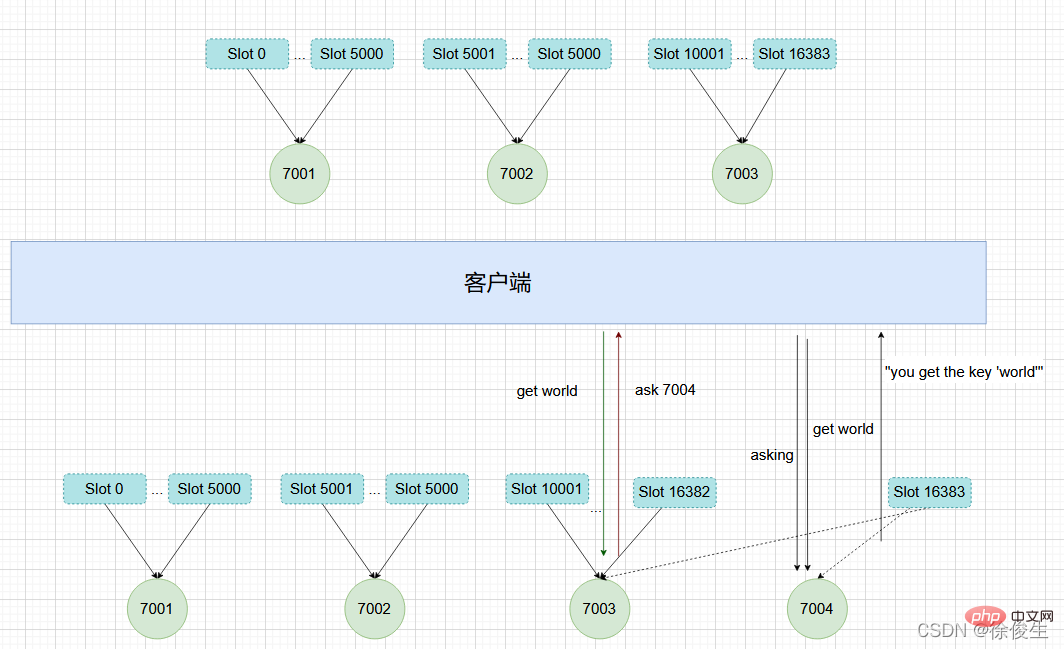
如上圖所示,節點 7003 正在向 7004 遷移 槽 16383,這個槽包含 hello 和 world,其中鍵 hello 還留在節點 7003,而 world 已經遷移到 7004。
我們向節點 7003 傳送關於 hello 的命令 這個命令會直接執行:
127.0.0.1:7003> GET "hello" "you get the key 'hello'"
如果我們向節點 7003 傳送 world 那麼使用者端就會被重定向到 7004:
127.0.0.1:7003> GET "world" -> (error) ASK 16383 127.0.0.1:7004
使用者端在接收到 ASK 錯誤之後,先傳送一個 ASKING 命令,然後在傳送 GET "world" 命令。
ASKING命令用於開啟節點的ASKING標識,開啟之後才可以執行命令。
ASK 和 MOVED 的區別
ASK 錯誤和 MOVED 錯誤都會導致使用者端重定向,它們的區別在於:
- MOVED 錯誤代表槽的負責權已經從一個節點轉移到了另一個節點:在使用者端收到關於
槽 i的MOVED錯誤之後,使用者端每次遇到關於槽 i的命令請求時,都可以直接將命令請求傳送至MOVED錯誤指向的節點,因為該節點就是目前負責槽 i的節點。 - 而 ASK 只是兩個節點遷移槽的過程中的一種臨時措施:在使用者端收到關於
槽 i的ASK錯誤之後,使用者端只會在接下來的一次命令請求中將關於槽 i的命令請求傳送到ASK錯誤指向的節點,但是 ,如果使用者端再次請求槽 i中的資料,它還是會給原來負責槽 i的節點傳送請求。
這也就是說,ASK 命令的作用只是讓使用者端能給新範例傳送一次請求,而且也不會更新使用者端快取的雜湊槽分配資訊。而不像 MOVED 命令那樣,會更改本地快取,讓後續所有命令都發往新範例。
我們現在知道了 Redis 叢集的實現原理。下面我們再來分析下,Redis 叢集如何實現高可用的呢?
複製與故障轉移
Redis 叢集中的節點也是分為主節點和從節點。
- 主節點用於處理槽
- 從節點用於複製主節點,如果被複制的主節點下線,可以代替主節點繼續提供服務。
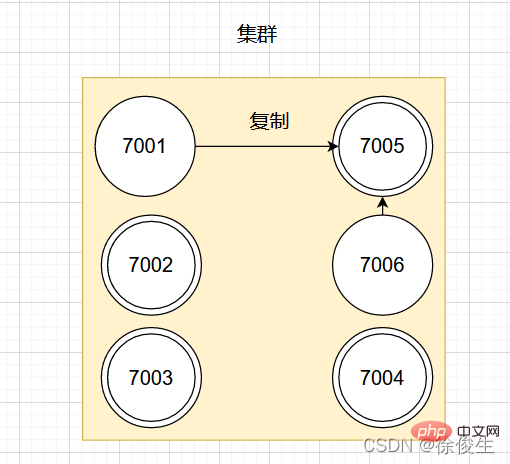
舉個例子,對於包含 7001 ~ 7004 的四個主節點的叢集,可以新增兩個節點:7005、7006。並將這兩個節點設定為 7001 的從節點。
設定從節點命令:
CLUSTER REPLICATE <node_id>
如圖:
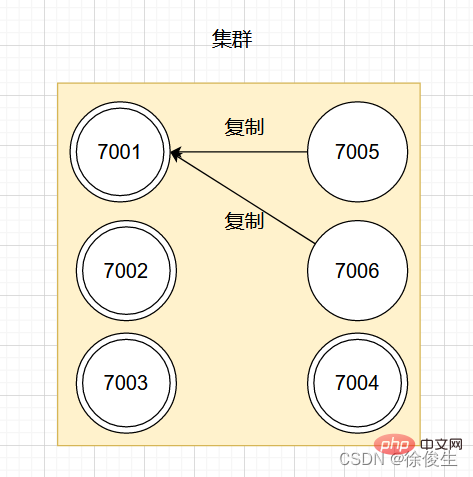
如果此時,主節點 7001 下線,那麼叢集中剩餘正常工作的主節點將在 7001 的兩個從節點中選出一個作為新的主節點。
例如,節點 7005 被選中,那麼原來由節點 7001 負責處理的槽會交給節點 7005 處理。而節點 7006 會改為複製新主節點 7005。如果後續 7001 重新上線,那麼它將成為 7005 的從節點。如下圖所示:
故障檢測
叢集中每個節點會定期向其他節點傳送 PING 訊息,來檢測對方是否線上。如果接收訊息的一方沒有在規定時間內返回 PONG 訊息,那麼接收訊息的一方就會被傳送方標記為「疑似下線」。
叢集中的各個節點會通過互相發訊息的方式來交換各節點的狀態資訊。
節點的三種狀態:
- 線上狀態
- 疑似下線狀態 PFAIL
- 已下線狀態 FAIL
一個節點認為某個節點失聯了並不代表所有的節點都認為它失聯了。在一個叢集中,半數以上負責處理槽的主節點都認定了某個主節點下線了,叢集才認為該節點需要進行主從切換。
Redis 叢集節點採用 Gossip 協定來廣播自己的狀態以及自己對整個叢集認知的改變。比如一個節點發現某個節點失聯了 (PFail),它會將這條資訊向整個叢集廣播,其它節點也就可以收到這點失聯資訊。
我們都知道,哨兵機制可以通過監控、自動切換主庫、通知使用者端實現故障自動切換。那麼 Redis Cluster 又是如何實現故障自動轉移呢?
故障轉移
當一個從節點發現自己正在複製的主節點進入了「已下線」狀態時,從節點將開始對下線主節點進行故障切換。
故障轉移的執行步驟:
- 在複製下線主節點的所有從節點裡,選中一個從節點
- 被選中的從節點執行
SLAVEOF no one命令,成為主節點 - 新的主節點會復原所有對已下線主節點的槽指派,將這些槽全部指派給自己
- 新的主節點向叢集廣播一條
PONG訊息,讓叢集中其他節點知道,該節點已經由從節點變為主節點,且已經接管了原主節點負責的槽 - 新的主節點開始接收自己負責處理槽有關的命令請求,故障轉移完成。
選主
這個選主方法和哨兵的很相似,兩者都是基於 Raft演演算法 的領頭演演算法實現的。流程如下:
- 叢集的設定紀元是一個自增計數器,初始值為0;
- 當叢集裡的某個節點開始一次故障轉移操作時,叢集設定紀元加 1;
- 對於每個設定紀元,叢集裡每個負責處理槽的主節點都有一次投票的機會,第一個向主節點要求投票的從節點將獲得主節點的投票;
- 當從節點發現自己複製的主節點進入「已下線」狀態時,會向叢集廣播一條訊息,要求收到這條訊息,並且具有投票權的主節點為自己投票;
- 如果一個主節點具有投票權,且尚未投票給其他從節點,那麼該主節點會返回一條訊息給要求投票的從節點,表示支援從節點成為新的主節點;
- 每個參與選舉的從節點會計算獲得了多少主節點的支援;
- 如果叢集中有 N 個具有投票權的主節點,當一個從節點收到的支援票
大於等於 N/2 + 1時,該從節點就會當選為新的主節點; - 如果在一個設定紀元裡沒有從節點收集到足夠多的票數,那麼叢集會進入一個新的設定紀元,並再次進行選主。
訊息
叢集中的各個節點通過傳送和接收訊息來進行通訊,我們把傳送訊息的節點稱為傳送者,接收訊息的稱為接收者。
節點傳送的訊息主要有五種:
- MEET 訊息
- PING 訊息
- PONG 訊息
- FAIL 訊息
- PUBLISH 訊息
叢集中的各個節點通過 Gossip 協定交換不同節點的狀態資訊, Gossip 是由 MEET、PING、PONG 三種訊息組成。
傳送者每次傳送 MEET、PING、PONG 訊息時,都會從自己已知的節點列表中隨機選出兩個節點(可以是主節點或者從節點)一併行送給接收者。
接收者收到 MEET、PING、PONG 訊息時,根據自身是否認識這兩個節點來進行不同的處理:
- 如果被選中的節點不存在接收著已知的節點列表,說明是第一次接觸,接收者會根據選擇節點的 ip和埠號進行通訊;
- 如果已經存在,說明之前已經完成了通訊,然後會更新原有選中節點的資訊。
推薦學習:
以上就是手把手帶你搞懂Redis高可用叢集的詳細內容,更多請關注TW511.COM其它相關文章!