Python資料異常值檢測和處理(範例詳解)

推薦學習:
1 什麼是異常值?
在機器學習中,異常檢測和處理是一個比較小的分支,或者說,是機器學習的一個副產物,因為在一般的預測問題中,模型通常是對整體樣本資料結構的一種表達方式,這種表達方式通常抓住的是整體樣本一般性的性質,而那些在這些性質上表現完全與整體樣本不一致的點,我們就稱其為異常點,通常異常點在預測問題中是不受開發者歡迎的,因為預測問題通產關注的是整體樣本的性質,而異常點的生成機制與整體樣本完全不一致,如果演演算法對異常點敏感,那麼生成的模型並不能對整體樣本有一個較好的表達,從而預測也會不準確。 從另一方面來說,異常點在某些場景下反而令分析者感到極大興趣,如疾病預測,通常健康人的身體指標在某些維度上是相似,如果一個人的身體指標出現了異常,那麼他的身體情況在某些方面肯定發生了改變,當然這種改變並不一定是由疾病引起(通常被稱為噪音點),但異常的發生和檢測是疾病預測一個重要起始點。相似的場景也可以應用到信用欺詐,網路攻擊等等。
2 異常值的檢測方法
一般異常值的檢測方法有基於統計的方法,基於聚類的方法,以及一些專門檢測異常值的方法等,下面對這些方法進行相關的介紹。
1. 簡單統計
如果使用pandas,我們可以直接使用describe()來觀察資料的統計性描述(只是粗略的觀察一些統計量),不過統計資料為連續型的,如下:
df.describe()
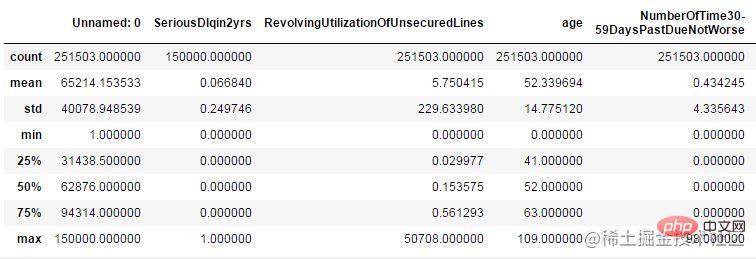
或者簡單使用散點圖也能很清晰的觀察到異常值的存在。如下所示:
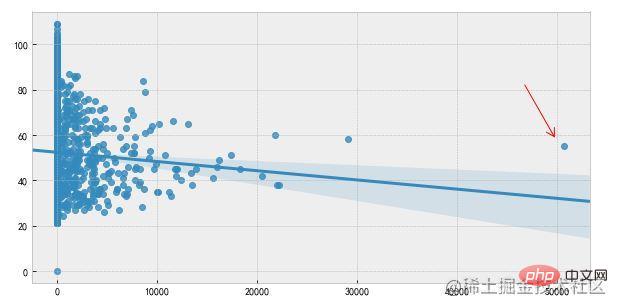
2. 3∂原則
這個原則有個條件:資料需要服從正態分佈。在3∂原則下,異常值如超過3倍標準差,那麼可以將其視為異常值。正負3∂的概率是99.7%,那麼距離平均值3∂之外的值出現的概率為P(|x-u| > 3∂) <= 0.003,屬於極個別的小概率事件。如果資料不服從正態分佈,也可以用遠離平均值的多少倍標準差來描述。
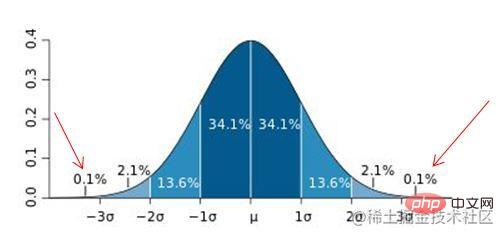
紅色箭頭所指就是異常值。
3. 箱型圖
這種方法是利用箱型圖的四分位距(IQR)對異常值進行檢測,也叫Tukey‘s test。箱型圖的定義如下:
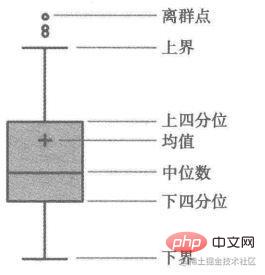
四分位距(IQR)就是上四分位與下四分位的差值。而我們通過IQR的1.5倍為標準,規定:超過上四分位+1.5倍IQR距離,或者下四分位-1.5倍IQR距離的點為異常值。下面是Python中的程式碼實現,主要使用了numpy的percentile方法。
Percentile = np.percentile(df['length'],[0,25,50,75,100]) IQR = Percentile[3] - Percentile[1] UpLimit = Percentile[3]+ageIQR*1.5 DownLimit = Percentile[1]-ageIQR*1.5
也可以使用seaborn的視覺化方法boxplot來實現:
f,ax=plt.subplots(figsize=(10,8)) sns.boxplot(y='length',data=df,ax=ax) plt.show()
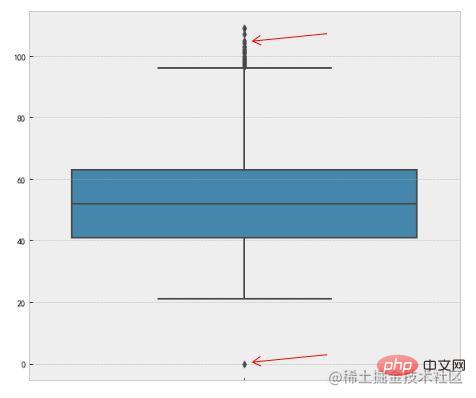
紅色箭頭所指就是異常值。
以上是常用到的判斷異常值的簡單方法。下面來介紹一些較為複雜的檢測異常值演演算法,由於涉及內容較多,僅介紹核心思想,感興趣的朋友可自行深入研究。
4. 基於模型檢測
這種方法一般會構建一個概率分佈模型,並計算物件符合該模型的概率,把具有低概率的物件視為異常點。如果模型是簇的集合,則異常是不顯著屬於任何簇的物件;如果模型是迴歸時,異常是相對遠離預測值的物件。
離群點的概率定義:離群點是一個物件,關於資料的概率分佈模型,它具有低概率。這種情況的前提是必須知道資料集服從什麼分佈,如果估計錯誤就造成了重尾分佈。
比如特徵工程中的RobustScaler方法,在做資料特徵值縮放的時候,它會利用資料特徵的分位數分佈,將資料根據分位數劃分為多段,只取中間段來做縮放,比如只取25%分位數到75%分位數的資料做縮放。這樣減小了異常資料的影響。
優缺點:(1)有堅實的統計學理論基礎,當存在充分的資料和所用的檢驗型別的知識時,這些檢驗可能非常有效;(2)對於多後設資料,可用的選擇少一些,並且對於高維資料,這些檢測可能性很差。
5. 基於近鄰度的離群點檢測
統計方法是利用資料的分佈來觀察異常值,一些方法甚至需要一些分佈條件,而在實際中資料的分佈很難達到一些假設條件,在使用上有一定的侷限性。
確定資料集的有意義的鄰近性度量比確定它的統計分佈更容易。這種方法比統計學方法更一般、更容易使用,因為一個物件的離群點得分由到它的k-最近鄰(KNN)的距離給定。
需要注意的是:離群點得分對k的取值高度敏感。如果k太小,則少量的鄰近離群點可能導致較低的離群點得分;如果K太大,則點數少於k的簇中所有的物件可能都成了離群點。為了使該方案對於k的選取更具有魯棒性,可以使用k個最近鄰的平均距離。
優缺點:(1)簡單;(2)缺點:基於鄰近度的方法需要O(m2)時間,巨量資料集不適用;(3)該方法對引數的選擇也是敏感的;(4)不能處理具有不同密度區域的資料集,因為它使用全域性閾值,不能考慮這種密度的變化。
5. 基於密度的離群點檢測
從基於密度的觀點來說,離群點是在低密度區域中的物件。基於密度的離群點檢測與基於鄰近度的離群點檢測密切相關,因為密度通常用鄰近度定義。一種常用的定義密度的方法是,定義密度為到k個最近鄰的平均距離的倒數。如果該距離小,則密度高,反之亦然。另一種密度定義是使用DBSCAN聚類演演算法使用的密度定義,即一個物件周圍的密度等於該物件指定距離d內物件的個數。
優缺點:(1)給出了物件是離群點的定量度量,並且即使資料具有不同的區域也能夠很好的處理;(2)與基於距離的方法一樣,這些方法必然具有O(m2)的時間複雜度。對於低維資料使用特定的資料結構可以達到O(mlogm);(3)引數選擇是困難的。雖然LOF演演算法通過觀察不同的k值,然後取得最大離群點得分來處理該問題,但是,仍然需要選擇這些值的上下界。
6. 基於聚類的方法來做異常點檢測
基於聚類的離群點:一個物件是基於聚類的離群點,如果該物件不強屬於任何簇,那麼該物件屬於離群點。
離群點對初始聚類的影響:如果通過聚類檢測離群點,則由於離群點影響聚類,存在一個問題:結構是否有效。這也是k-means演演算法的缺點,對離群點敏感。為了處理該問題,可以使用如下方法:物件聚類,刪除離群點,物件再次聚類(這個不能保證產生最優結果)。
優缺點:(1)基於線性和接近線性複雜度(k均值)的聚類技術來發現離群點可能是高度有效的;(2)簇的定義通常是離群點的補,因此可能同時發現簇和離群點;(3)產生的離群點集和它們的得分可能非常依賴所用的簇的個數和資料中離群點的存在性;(4)聚類演演算法產生的簇的品質對該演演算法產生的離群點的品質影響非常大。
7. 專門的離群點檢測
其實以上說到聚類方法的本意是是無監督分類,並不是為了尋找離群點的,只是恰好它的功能可以實現離群點的檢測,算是一個衍生的功能。
除了以上提及的方法,還有兩個專門用於檢測異常點的方法比較常用:One Class SVM和Isolation Forest,詳細內容不進行深入研究。
3 異常值的處理方法
檢測到了異常值,我們需要對其進行一定的處理。而一般異常值的處理方法可大致分為以下幾種:
- 刪除含有異常值的記錄:直接將含有異常值的記錄刪除;
- 視為缺失值:將異常值視為缺失值,利用缺失值處理的方法進行處理;
- 平均值修正:可用前後兩個觀測值的平均值修正該異常值;
- 不處理:直接在具有異常值的資料集上進行資料探勘;
是否要刪除異常值可根據實際情況考慮。因為一些模型對異常值不很敏感,即使有異常值也不影響模型效果,但是一些模型比如邏輯迴歸LR對異常值很敏感,如果不進行處理,可能會出現過擬合等非常差的效果。
4 異常值總結
以上是對異常值檢測和處理方法的彙總。
通過一些檢測方法我們可以找到異常值,但所得結果並不是絕對正確的,具體情況還需自己根據業務的理解加以判斷。同樣,對於異常值如何處理,是該刪除,修正,還是不處理也需結合實際情況考慮,沒有固定的。
推薦學習:
以上就是Python資料異常值檢測和處理(範例詳解)的詳細內容,更多請關注TW511.COM其它相關文章!