一起分析MySQL的高可用架構技術

背景說明
隨著資訊科技的發展,企業越來越依賴於資訊化管理,各業務應用的資料資訊,主要儲存在資料庫中,企業對這些資料存取的連續性要求越來越高,為了避免因為資料的中斷導致各種損失,資料庫的高可用已成了企業資訊化建設的重中之中。同時,對於電信、金融、能源、軍工等等涉及國計民生的行業或領域的關鍵業務對於關鍵資料儲存都需要高可用,必須保證資料系統7×24小時全天候執行,防止資料丟失、資料損壞。程式設計學習資料點選領取
高可用架構介紹
高可用架構對於網際網路服務基本是標配,無論是應用服務還是資料庫服務都需要做到高可用。對於一個系統而言,可能包含很多模組,比如前端應用,快取,資料庫,搜尋,訊息佇列等,每個模組都需要做到高可用,才能保證整個系統的高可用。對於資料庫服務而言,高可用可能更復雜,對使用者的服務可用,不僅僅是能存取,還需要有正確性保證,因此資料庫的高可用需要更加認證對待。
MySQL高可用架構分類
- MySQL實現高可用之MMM
- MySQL實現高可用之MHA
- MySQL實現高可用之主從架構
- MySQL實現高可用之Cluster模式
MMM的技術分析
MMM(Master-Master replication manager for MySQL)是一套支援雙主故障切換和雙主日常管理的指令碼程式。
MMM使用Perl語言開發,主要用來監控和管理MySQL Master-Master(雙主)複製,雖然叫做雙主複製,但是業務上同一時刻只允許對一個主進行寫入,另一臺備選主上提供部分讀服務,以加速在主主切換時刻備選主的預熱
MMM的監控端是會提供多個虛擬ip(vip),包括一個可寫的vip,多個可讀的vip,通過監管的管理,這些ip會繫結在可用的mysql上,當某一臺mysql宕機時,會將vip遷移到其他mysql。
MMM這套指令碼程式一方面實現了故障切換的功能,另一方面其內部附加的工具指令碼也可以實現多個slave的read負載均衡。
這個套件也能基於標準的主從設定的任意數量的從伺服器進行讀負載均衡,所以你可以用它來在一組居於複製的伺服器啟動虛擬ip,除此之外,它還有實現資料備份、節點之間重新同步功能的指令碼。
MMM的基礎元件分析
- mmm_mond:監控程序,負責所有的監控工作,決定和處理所有節點角色活動。因此,指令碼需要在監管上執行。
- mmm_agentd:執行在每個msql伺服器上的代理程序,完成監控的探針工作和執行簡單的遠端服務設定。此指令碼需要在被監管機上執行。
- mmm_control:一個簡單的指令碼,提供管理mmm_mond進行的命令。
MMM實現基本實現原理
MMM提供了自動和手動兩種方式移除一組伺服器中複製延遲較高的伺服器的虛擬ip,同時它還可以備份資料,實現兩節點之間的資料同步等。
MySQL本身沒有提供replication failover的解決方案,通過MMM方案能實現伺服器的故障轉移,從而實現mysql的高可用。
MMM的使用場景
由於MMM無法完全的保證資料一致性,所以MMM適用於對資料的一致性要求不是很高,但是又想最大程度的保證業務可用性的場景。
對於那些對資料的一致性要求很高的業務,非常不建議採用MMM這種高可用架構。
- MMM專案來自 Google:code.google.com/p/mysql-mas…
- 官方網站為:mysql-mmm.org
MHA簡介
MHA(Master High Availability)目前在MySQL高可用方面是一個相對成熟的解決方案,它由日本DeNA公司的youshimaton(現就職於Facebook公司)開發,是一套優秀的作為MySQL高可用性環境下故障切換和主從提升的高可用軟體。在MySQL故障切換過程中,MHA能做到在0~30秒之內自動完成資料庫的故障切換操作,並且在進行故障切換的過程中,MHA能在最大程度上保證資料的一致性,以達到真正意義上的高可用。
MHA是一款開源的MySQL高可用程式,MHA在監控到master節點故障時,會自動提升其中擁有最新資料的slave節點成為新的master節點。
MHA會獲取其他節點的額外資訊來避免一致性方面的問題,也就是MHA會獲取其他從節點中的資料資訊,並將資訊發給最接近主節點的從節點,這樣主節點故障時會提升此從節點為主節點,而此從節點擁有其他從節點所有的資料資訊。
MHA還提供了master節點的線上切換功能,即按需切換master/slave節點。
MHA的基礎元件
MHA由兩部分組成:MHA Manager(管理節點)和MHA Node(資料節點)。
MHA Manager可以單獨部署在獨立的機器上管理多個master-slave叢集,也可以部署在一臺slave節點上。
MHA的實現原理
- MHA Node執行在每臺MySQL伺服器上,MHA Manager會定時探測叢集中的master節點,當master出現故障時,它可以自動將最新資料的slave提升為新的master,然後將所有其他的slave重新指向新的master。整個故障轉移過程對應用程式完全透明。
- 在MHA自動故障切換過程中,MHA試圖從宕機的主伺服器上儲存二進位制紀錄檔,最大程度的保證資料的不丟失,但這並不總是可行的。
- 例如,如果主伺服器硬體故障或無法通過ssh存取,MHA沒法儲存二進位制紀錄檔,只進行故障轉移而丟失了最新的資料。使用MySQL 5.5的半同步複製,可以降低資料丟失的風險。
- MHA可以與半同步複製結合起來,如果只有一個slave已經收到了最新的二進位制紀錄檔,MHA可以將最新的二進位制紀錄檔應用於其他所有的slave伺服器上,因此可以保證所有節點的資料一致性。
MHA的使用場景
目前MHA主要支援一主多從的架構。
要搭建MHA,要求一個複製叢集中必須最少有三臺資料庫伺服器,一主二從,即一臺充當master,一臺充當備用master,另外一臺充當從庫。
因為至少需要三臺伺服器,出於機器成本的考慮,淘寶也在該基礎上進行了改造,目前淘寶TMHA已經支援一主一從。
從程式碼層面看,MHA就是一套Perl指令碼,那麼相信以阿里系的技術實力,將MHA改成支援一主一從也並非難事。
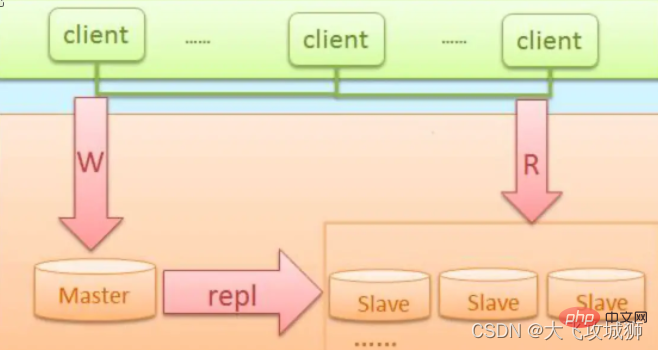
MySQL主從架構
此種架構,一般初創企業比較常用,也便於後面步步的擴充套件
此架構特點
- 成本低,佈署快速、方便
- 讀寫分離
- 還能通過及時增加從庫來減少讀庫壓力
- 主庫單點故障
- 資料一致性問題(同步延遲造成)
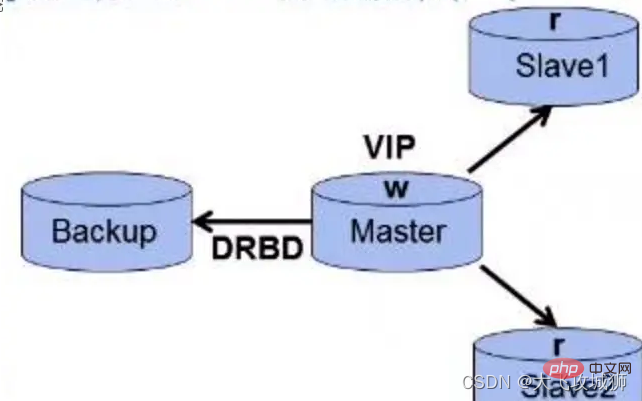
- 高可用軟體可使用Heartbeat,全面負責VIP、資料與DRBD服務的管理
- 主故障後可自動快速切換,並且從庫仍然能通過VIP與新主庫進行資料同步
- 從庫也支援讀寫分離,可使用中介軟體或程式實現
MySQL Cluster概述
MySQL Cluster技術在分散式系統中為MySQL提供了冗餘特性,增強了安全性,可以的提高系統的可靠性和資料的有效性。MySQL叢集需要一組計算機,每臺計算機可以理解為一個節點,這些節點的功能各不相同。MySQL Cluster按照功能來分,可以分為三種節點:管理節點、資料節點和SQL節點。叢集中的某臺計算機可以是某一個節點,也可以是兩種或者三種節點的集合,這些節點組合在一起,為應用提供具有高可靠性、高效能的Cluster資料管理;
目前企業資料量越來越大,所以對MySQL的要求進一步提高,以前的大部分高可用方案通常存在一定的缺陷,例如MySQL Replication方案,Master是否存活檢測需要一定的時間,如果需要主從切換也需要一定的時間,因此高可用很大的程度上依賴於監控軟體和自動化管理工具。隨著MySQL Cluster的不斷髮展,終於在效能和高可用上得到了很大的提高;
MySQL Cluster基本概念
MySQL Cluster簡單地講是一種MySQL叢集的技術,是由一組計算機構成,每臺計算機可以存放一個或者多個節點,其中包括MySQL伺服器,DNB Cluster的資料節點,管理其他節點,以及專門的資料存取程式,這些節點組合在一起,就可以為應用提高可高效能、高可用性和可縮放性的Cluster資料管理;
MySQL Cluster的存取過程大致是這樣的,應用通常使用一定的負載均衡演演算法將對資料存取分散到不同的SQL節點,SQL節點對資料節點進行資料存取並從資料節點返回資料結果,管理節點僅僅只是對SQL節點和資料節點進行設定管理;
理解MySQL Cluster節點
MySQL Cluster按照節點型別可以分為3種型別的節點,分別是管理節點、SQL節點、資料節點,所有的這些節點構成了一個完整的MySQL叢集體系,事實上,資料儲存在NDB儲存伺服器的儲存引擎中,表結構則儲存在MySQL伺服器中,應用程式通過MySQL伺服器存取資料,而叢集管理伺服器則通過管理工具ndb_mgmd來管理NDB儲存伺服器;
【1.管理節點】
管理節點主要是用來對其他的節點進行管理。通常通過設定config.ini檔案來設定叢集中有多少需要維護的副本、設定每個資料節點上為資料和索引分配多少記憶體、IP地址、以及在每個資料節點上儲存資料的磁碟路徑;
管理節點通常管理Cluster組態檔和Cluster紀錄檔。Cluster中的每個節點從管理伺服器檢索設定資訊,並請求確定管理伺服器所在位置的方式。如果節點內出現新的事件的時候,節點將這類事件的資訊傳輸到管理伺服器,將這類資訊寫入到Cluster紀錄檔中;
一般在MySQL Cluster體系中至少需要一個管理節點,另外值得注意的是,因為資料節點和SQL節點在啟動之前需要讀取Cluster的設定資訊,所以通常管理節點是最先啟動的;
【2.SQL節點】
SQL節點簡單地講就是mysqld伺服器,應用不能直接存取資料節點,只能通過SQL節點存取資料節點來返回資料。任何一個SQL節點都是連線到所有的儲存節點的,所以當人任何一個儲存節點發生故障的時候,SQL節點都可以把請求轉移到另一個儲存節點執行。通常來講,SQL節點越多越好,SQL節點越多,分配到每個SQL節點的負載就越小,系統的整體效能就越好;
【3.資料節點】
資料節點用來存放Cluster裡面的資料,MySQL Cluster在各個資料節點之間複製資料,任何一個節點發生了故障,始終會有另外的資料節點儲存資料;
通常這3種不同邏輯的節點可以分佈在不同的計算機上面,叢集最少有3臺計算機,為了保證能夠正常維護叢集服務,通常將管理節點放在一個單獨的主機上;
推薦學習:
以上就是一起分析MySQL的高可用架構技術的詳細內容,更多請關注TW511.COM其它相關文章!