
分享嘉賓:周勁鬆 網易數帆
編輯整理:王賢才 碧桂園
出品平臺:DataFunTalk
導讀:這次分享的主題是網易內部孵化的資料湖專案Arctic。在分析了部分現有開源資料湖專案後,網易數帆有數團隊結合自身需求,孵化了Arctic。本次分享的內容包括五大方面:
- 什麼是資料湖?
- 網易需要的資料湖
- Arctic核心原理
- 現有成果
- 總結與規劃
01 什麼是資料湖
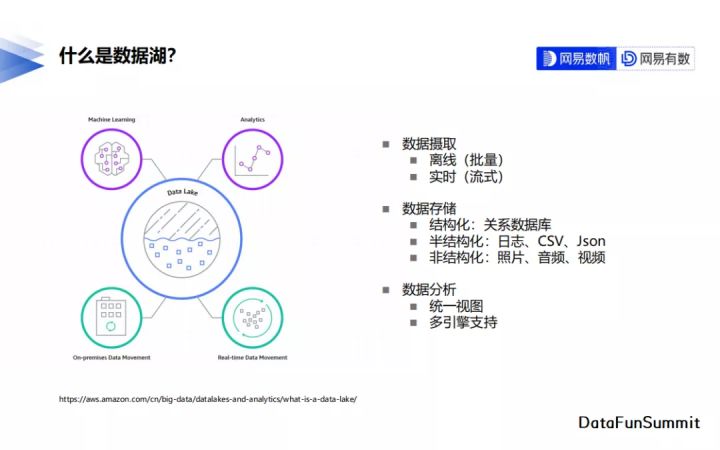
我們從資料攝取、資料儲存和資料分析三個方面來描述資料湖的特性。
資料攝取就是資料寫入,資料湖既可以支援批次的資料寫入,也可以支援流式的資料寫入。
從資料儲存上來說,相較於數倉只能儲存結構化的資料,我們希望資料湖既能儲存結構化的資料,比如關係型資料庫中的資料,也支援儲存半結構化的資料,比如應用系統的業務紀錄檔,同時還能儲存非結構化的資料,比如照片、音訊或者視訊資料。但是現在實際的使用情況下,儲存結構化與半結構化的需求比非結構化的需求更多一些。
從資料分析的角度上來說,資料湖更強調儲存。在計算上,儘量利用不同計算引擎的特點去處理不同的需求,為了支援不同的計算引擎,資料湖一般會提供統一的結構去描述其中的資料。下圖是亞馬遜的一個資料湖產品圖,它支援實時的或者定時的把一些資料寫到資料湖裡面,在資料湖上完成資料分析以及機器學習相關的應用。
傳統資料湖更強調其靈活性,而在資料治理上普遍功能較弱。為了彌補資料湖在資料治理上的不足,湧現出了一批完善資料湖資料治理的專案,比較出名的有三個,我們稱之為資料湖三劍客。它們分別是:Delta Lake、Apache Hudi、Apache Iceberg。

Delta Lake:從功能上來講,支援事務隔離,支援同時對資料進行讀寫,有資料多版本的概念。Delta Lake在流批一體上,除了支援傳統的批次寫入,還可以通過Spark Streaming寫入實時資料,也可以從表裡讀出實時資料,但是現在還無法實時更新/刪除資料。表結構修改方面,它只支援新增欄位。
Apache Hudi:很好地彌補了Delta Lake在實時更新和刪除資料上的不足,同時這也成為了它最大的特點。但是我們在調研時Apache Hudi和spark還是強繫結的關係,雖然社群已經發起適配Apache Flink的討論,但對現有的程式碼改動較大,等待其開發完並能投入生產還需要不少時間。另外Hudi引入了額外的索引開銷(Bloom Filter或者HBase)進行資料組織,雖然提升了資料合併的效能,但卻也帶來了額外的計算、運維開銷。
Apache Iceberg:是三者中最年輕,也是程式碼最簡潔的一個,但與Delta Lake一樣,其在資料實時寫入與讀取的支援上還不完善。
經過分析,三款資料湖產品都有自己的特點,但是都不能完全滿足我們對資料湖的需求。
02 網易需要什麼樣的資料湖
為了描述網易對資料湖的需求,先來介紹下網易資料開發的現狀。
以網易雲音樂的一個資料開發過程為例,雲音樂的資料主要來自兩方面,一個是業務埋點紀錄檔,另一個是資料庫裡的Binlog紀錄檔。開發模式就是較為標準的Lambda架構,離線鏈路通過Spark在HDFS上做T+1的批次計算;如果對資料實時性有較高要求的場景,則通過Flink在Kafka上做實時鏈路的建設,資料應用時再結合批次計算和實時計算的結果。
Lambda架構最大的問題就是流和批的重複建設,不僅造成了雙倍的成本投入,實際開發過程中還極容易出現流批口徑不一致,導致最後資料品質不高的結果。
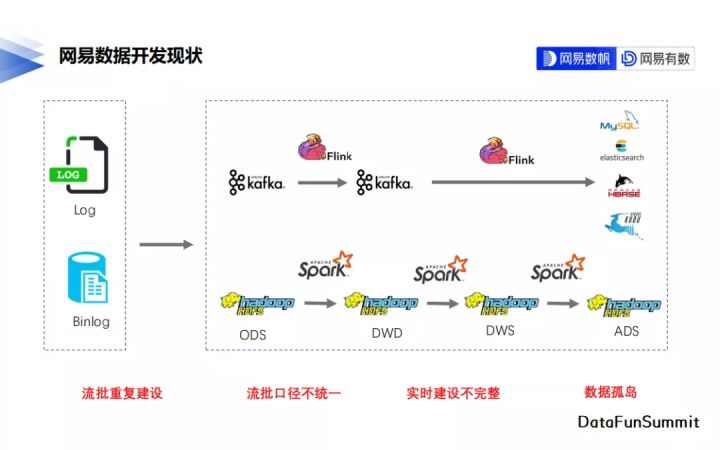
基於這樣的開發現狀,網易對資料湖的最重要需求是什麼呢?
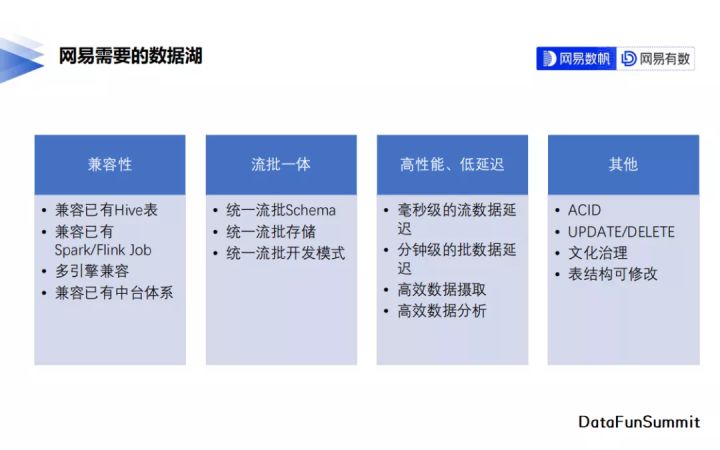
- 首先流批一體是我們的核心需求,新的開發模式要能夠同時支援實時、批次的資料寫入、讀取,能方便地在其上用Flink實現實時資料開發,也能通過Spark實現批次的資料加工,不僅能存放只有追加的紀錄檔資料,也能儲存有變更需求的Binlog資料。我們計劃按照三個層級逐級推進流批一體,首先是統一流批的表後設資料,接下來統一流批的儲存方式,最後統一流批的開發模式。
- 另外一個重要的需求是相容性,新的資料湖方案要能相容已有的Hive表,無需把已有的Hive資料重新遷移到資料湖上,也不用對已有的資料開發任務進行重新的編寫來適應新的資料湖特性。與原有系統的相容性很大程度決定了新系統能否得到很好的推廣。
- 除以上兩點外,還有高效能、低延遲,以及支援ACID、表結構變更、檔案治理等常規的資料湖能力。
03 Arctic核心原理
為了滿足上面提到的需求,網易內部孵化了流批一體的實時資料湖專案——Arctic。
1. Arctic架構
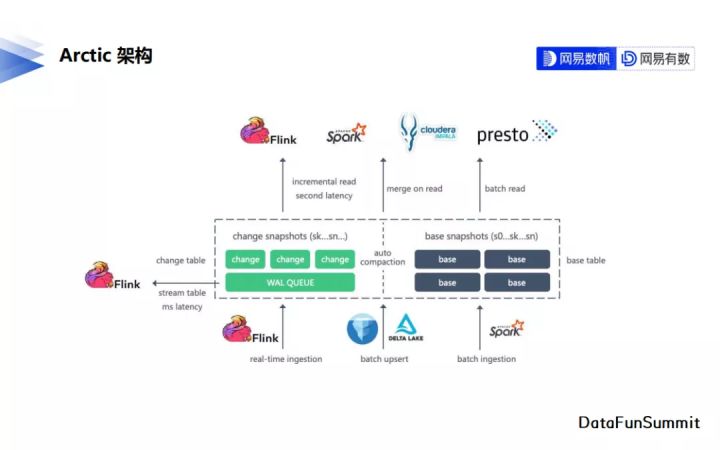
上圖是Arctic現有的架構,中間虛線部分為Arctic的核心模組,虛線以外的部分則是對接的一些計算引擎。
Arctic表內部分成了兩個表空間,一個是base表空間,一個是change表空間,base表空間儲存表的基礎資料,或者也叫存量資料。change表空間儲存表的變更資料,在進行查詢時將change表的資料合併入base表後返回給使用者,以得到實時變更之後的資料,這個過程我們叫它Merge-On-Read。
隨著資料不斷寫入,change資料越來越多,Merge-On-Read的效能必將大大下降。Arctic內部通過自動的合併過程將堆積的change資料合併到base表中,以提升Merge-On-Read的效能。
現階段Arctic整合了Apache Flink完成對實時資料的寫入和讀取,整合了Apache Spark完成對存量資料的寫入與讀取,整合了Impala與Presto完成資料分析。
2. 異構儲存
根據需求的不同,base表與change表選擇了不同的儲存方案。源於對歷史Hive表的相容需求,base表仍然選擇使用Hive進行管理。change表是新增的內容,我們選擇了Apache Iceberg對其進行資料管理,主要依賴了其多版本的機制與靈活的檔案管理方式。對於有毫秒級實時消費的場景,我們還會在Iceberg的change表之上使用Apache Kafka構建一塊毫秒級的change資料分發管道。
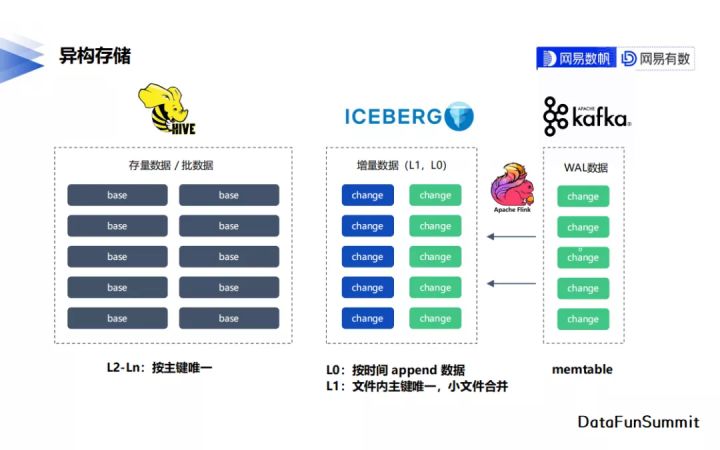
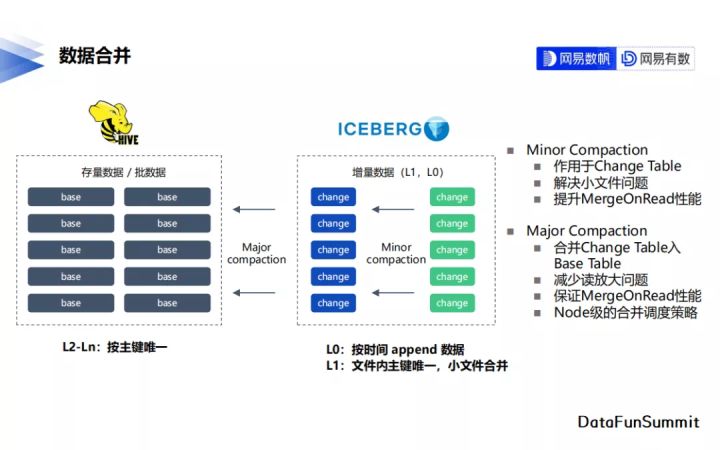
3. 資料合併
檔案合併方面,我們拆分出主要合併change表的Minor Compaction,與合併change表到base表的Major Compaction過程。合併不僅解決了前面提到的讀放大問題,也負責實時寫入場景下的小檔案治理問題。
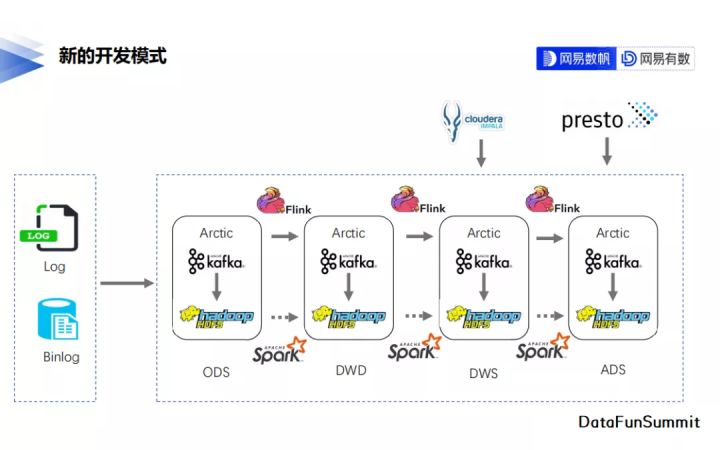
04 現有成果
下圖為Arctic在雲音樂落地之後新的開發模式。Arctic統一了實時與離線操作的表物件,支援同時使用Flink與Spark對錶完成實時與離線的資料開發。新的開發模式很好地解決了Lambda架構下schema不一致的問題,同時也加速了離線鏈路向實時鏈路升級的速度。
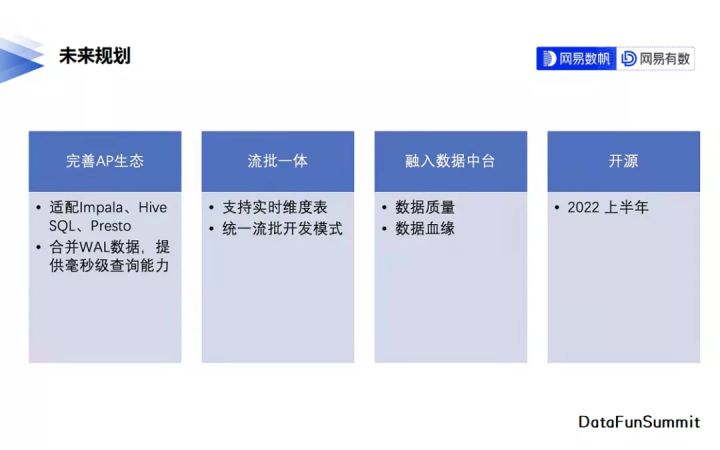
05 未來規劃
現階段Arctic對Presto、Impala等AP引擎的整合還不夠完善,後續我們會花更多的時間與精力優化Arctic在AP場景下的查詢效能。同時針對資料延遲要求特別高的場景,我們會考慮將Kafka中毫秒級的資料納入Merge-On-Read的範圍內。
另外,流批一體仍然會是我們繼續探索的主要方向。Arctic現階段解決了後設資料與表資料的流批一體,下一階段是資料開發上的流批一體探索。
在周邊生態完善方面Arctic將融入資料中臺的資料品質、資料血緣等系統。
Arctic計劃於2022上半年開源。
今天的分享就到這裡,謝謝大家。
分享嘉賓:
