一、背景
Firestorm自2021年11月上線開源 0.1.0 版本後,該專案受到了業界的廣泛關注。 Firestorm是為了加速分散式計算引擎能上雲的重要元件,同時也能解決在大Shuffle場景下,計算任務由於Shuffle過程異常而導致的任務失敗。(更詳細的背景可以參考此文:[)
目前Firestorm迎來了0.2.0 版本的正式釋出,而Firestorm也成為了第一個支援混合儲存的開源Remote Shuffle Service 方案。本文將重點介紹 Firestorm 0.2.0 版本的最新特性及效能分析。
二、版本新特性—支援混合儲存
什麼是混合儲存
在Firestorm初始版本中,Shuffle資料只能儲存在Shuffle Server的本地盤,或者分散式儲存系統。而混合儲存則充分利用了Shuffle Server的記憶體資源,並結合本地檔案和分散式儲存系統,使得Shuffle資料能儲存在多個媒介中。
為什麼需要混合儲存
在實際的生產過程中,由於Shuffle資料的塊大小不一致,小的只有幾KB,甚至幾十Byte,**而大的能達到256MB以上。這樣的場景下,對於HDFS這樣的分散式儲存非常不友好,大量的小資料塊的寫入會導致叢集響應過慢,嚴重影響計算任務的效率。**雖然使用Shuffle Server
磁碟能很好的緩解該問題,但隨之而來的問題是,Shuffle Server必須具備大量的磁碟空間來承載PB級別的Shuffle資料,這樣的繫結不利於現在的雲原生的大環境。同時,在Shuffle資料寫入過程中,必須要等待資料都寫入儲存後,才能進行下一步,在儲存繁忙時,對於計算任務的效能有較大的影響。為了解決上述提到的問題,基於記憶體,本地檔案和分散式儲存相結合的混合儲存的方案就油然而生了。
混合儲存實現原理
以Spark為例,先看下基於單一儲存的方案是如何對Shuffle資料進行讀寫的:
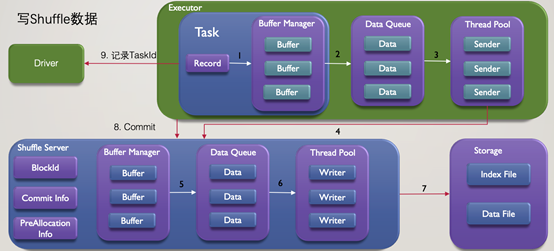
在上圖寫的過程中,Shuffle資料在經過步驟1,2,3的計算,快取等操作,在步驟4傳送到了Shuffle Server側,再經過步驟5,6的快取,資料聚合等操作,最終通過步驟7寫入儲存媒介。所有任務結束後,會傳送Commit命令給Shuffle Server,如果是最後一個任務,則必須等待相關資料都寫入儲存後,才能完成,而Commit操作後等待寫入儲存的過程對於任務的整體效能影響較大。
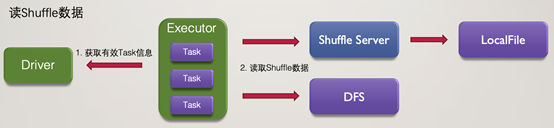
在寫入完成後,讀取過程則較為簡單,基於儲存媒介,選擇從Shuffle Server讀取或直接從分散式儲存讀取。 瞭解完之前的方案後,再來看下混合儲存是如何實現:
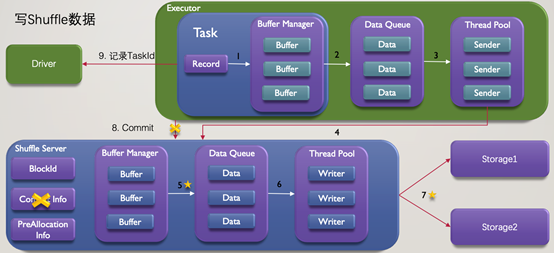
相比之前,有3個主要的變化:
1.首先,步驟5的Flush方案進行了優化: 之前的Flush方案是,每個Shuffle Partition資料達到閾值或整個快取空間達到閾值,則將這部分資料寫入儲存媒介,而現在則設定了快取空間的上下水位,到達上水位則進行Flush操作,直至快取空間到達低水位。同時,在Flush資料選擇上,優先選擇資料量多的Partition。通過上水位的控制,保證了在Flush過程中,快取依然有足夠的空間接受新的資料,而通過下水位及Flush資料的選擇,保障了資料量較少的Shuffle資料能駐留在記憶體,降低儲存寫入小檔案的概率。
2.其次,對步驟7進行了重構: 支援基於寫入資料塊大小對儲存媒介進行選擇,如,大於32MB的資料塊寫入分散式儲存,而其它的則寫入本地儲存。這樣的策略是為了更好匹配分散式儲存的寫入模式,達到更好的寫入效能。同時,也觀察到在實際任務執行過程中,巨量資料塊的數量雖然佔比不高,如,30%,但是,巨量資料塊的資料總量佔比更高,如,70%。基於這樣的儲存方案,可以降低對於本地盤容量的依賴,便於Firestorm在各種環境下進行部署,甚至雲上部署。
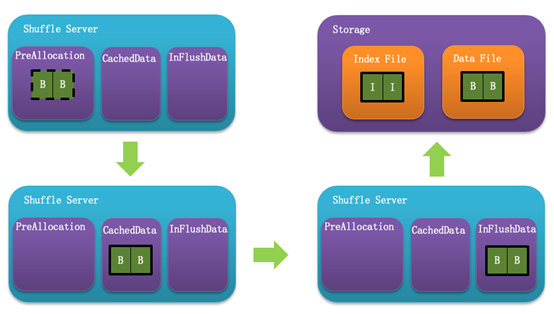
3.最後,去除了步驟8的Commit操作: Commit操作存在的意義在於讀取資料時保證資料都能被讀取到。由於記憶體也作為了混合儲存的一部分,且Shuffle Server側在儲存媒介正常的情況下能保證Shuffle資料要麼在記憶體中,要麼在儲存媒介中,那麼Commit操作也失去了存在的意義。從下圖可以看到,BufferManager包含多個Buffer,每個Buffer儲存了單個Partition的Shuffle資料,且儲存CachedData中。當BufferManager達到高水位時,CachedData的資料會轉移到InFlushData,直到儲存寫入完成,同時,CachedData還能接收新的Shuffle資料。這樣的策略保證了Shuffle資料未寫入儲存前也不會丟失。
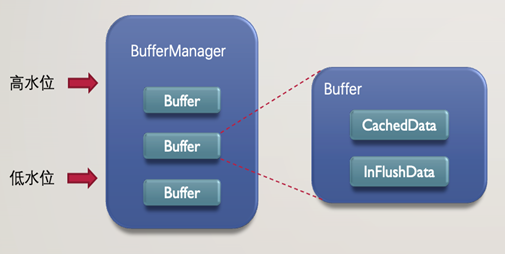
下圖則展示了資料在Shuffle Server的記憶體區域中是如何流轉的,寫入前先申請記憶體空間並佔據PreAllocation區域,接收到資料後記憶體使用轉移到CachedData區域,在Flush後進一步移動到InFlushData區域,最後寫入儲存中,並清理掉記憶體空間。
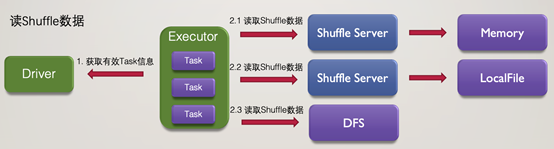
瞭解了寫入過程,再看讀取過程的變化則更容易了,相比之前的單一儲存的讀取方案,基於混合儲存方案讀取時,會按序從Shuffle Server Memory, Shuffle Server本地儲存及分散式儲存讀取Shuffle資料。
混合儲存的優勢
上文已經介紹了混合儲存解決的問題及相關實現,這裡再做下總結,引入混合儲存可以帶來如下收益: 1.基於寫入資料塊大小選擇儲存媒介,提升DFS的寫入效能 2.降低對於Shuffle Server本地磁碟容量的依賴,在雲原生環境下,更容易部署 3.降低寫入Shuffle Server本地磁碟的資料量,當採用SSD作為本地儲存時,增加SSD使用壽命,降低儲存成本 4.引入記憶體作為儲存,提升計算任務效能
混合儲存的使用方式
由於記憶體的Flush策略進行了變更,Shuffle Server引入的相關設定如下:
#基於rss.server.buffer.capacity值的低水位百分比
rss.server.memory.shuffle.lowWaterMark.percentage 25.0
#基於rss.server.buffer.capacity值的高水位百分比
rss.server.memory.shuffle.highWaterMark.percentage 75.0
目前支援的混合儲存型別有:
Shuffle Server端:
注意:由於使用了本地檔案和HDFS混合儲存,需要增加rss.server.flush.cold.storage.threshold.size該設定,設定單次寫入資料量閾值,大於該值將寫入HDFS,其餘的寫入本地檔案
rss.storage.type MEMORY_LOCALFILE_HDFS
rss.storage.basePath /path1,/path2
rss.server.hdfs.base.path hdfs://ip:port/path
rss.server.flush.cold.storage.threshold.size 32m
Spark Client端:
spark.rss.storage.type MEMORY_LOCALFILE_HDFS
spark.rss.base.path hdfs://ip:port/path
支援資料過濾
在讀取Shuffle資料的過程中,會先讀取所有的後設資料資訊,如,BlockId,TaskId,Length等,再基於後設資料資訊讀取Shuffle資料。由於分散式計算任務的Shuffle資料會產生冗餘,如,Spark的推測執行等。為了減少資料的無效讀取,更合理的利用系統資源,增加了讀取Shuffle資料時的過濾功能。優化的場景如下: 1.Spark AQE 需要讀取指定的上游資料 2.Spark 推測執行產生的冗餘資料 3.混合儲存場景下,資料已從記憶體讀取,又被寫入儲存而產生的冗餘資料
其它特性
除了上述的主要特性,版本還有如下改動:
1.新增對於Spark版本的支援,目前已能支援,Spark2.3, Spark2.4, Spark3.0, Spark3.1
2.優化Shuffle資料讀取策略,改為先讀取Index檔案,再讀取Data檔案
3.新增GRPC相關指標 4.修復已知缺陷
三、版本效能測試
由於新版本在儲存架構上有了較大的變動,以下是效能測試的相關資訊
測試環境
硬體環境
1.每臺伺服器為 176 cores,256G記憶體,4T * 12 HDD,網路頻寬 10GB/s
2.Hadoop Yarn叢集:1 * ResourceManager + 6 * NodeManager, 4T * 10 HDD 寫臨時資料
3.Firestorm叢集:1 * Coordinator + 6 * Shuffle Server,
4.T * 10 HDD 寫Shuffle資料
軟體環境
1.Hadoop版本2.8.5
2.Spark版本
3. 2.4.Spark相關設定:
spark.executor.instances 100
spark.executor.cores 4
spark.executor.memory 9g
spark.executor.memoryOverhead 1024
spark.shuffle.manager org.apache.spark.shuffle.RssShuffleManager
spark.rss.storage.type MEMORY_LOCALFILE
4.Firestorm Shuffle Server相關設定:
rss.storage.type MEMORY_LOCALFILE rss.server.buffer.capacity 50g
測試場景:
TPC-DS 基於1TB資料量的TPC-DS,對Spark原生Shuffle,Firestorm 0.1.0,Firestorm 0.2.0進行了對比效能測試,以下是相關測試結果:
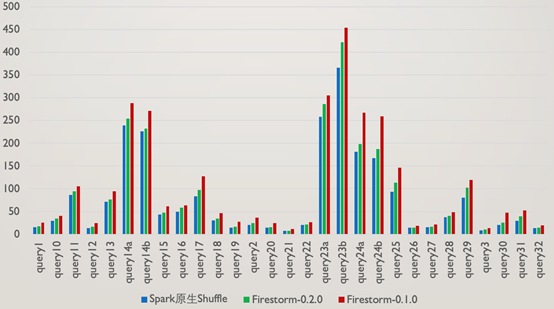
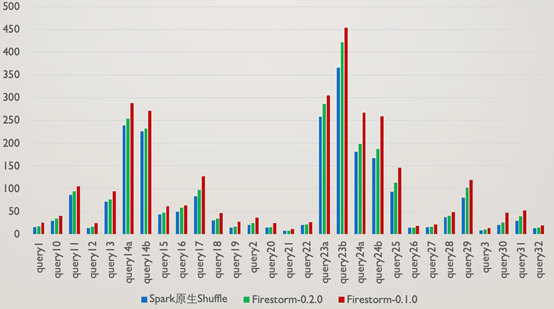
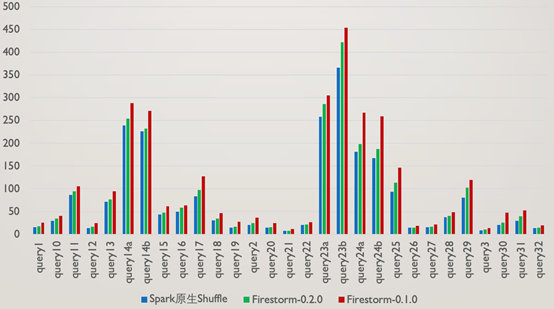
從測試結果可以看到,Firestorm0.2.0版本比上一個版本有了30%左右的提升,但對於Spark原生Shuffle並無任何優勢,這個結果是符合預期的,原因有如下幾點:
1.即使是1TB的TPC-DS測試,query的Shuffle資料量普遍較小,使得磁碟可以忽略由於隨機讀寫而產生的效能下降
2.由於考慮到高並行場景下的網路連線數過多問題,每個Executor和Shuffle Server之間僅存在一個RPC連線,序列傳送資料的模式降低了效能
3.使用者端在傳送完資料後,會每隔一定時間檢查傳送成功與否,這個間隔時間也增加了任務執行的效能損耗
從效能角度看,Firestorm的優勢主要在於減少了儲存隨機讀寫帶來的效能損耗,由於RPC在實現上更多的考慮穩定性及高並行場景,相比原生Shuffle方案有額外的效能開銷,最終導致了在沒有磁碟隨機IO的場景下,Firestorm效能不如原生Shuffle。 **但是,在磁碟有隨機IO的場景下,Firestorm還是具備效能優勢的,**為了驗證這個結論,將10塊HDD降低為2塊HDD,選取Shuffle資料量較多的query23a進行測試,測試結果如下:
可以很明顯的看到,當HDD數量從10下降到2以後,對於原生Spark的Shuffle Read效能影響嚴重,讀取時間上升了5倍,而對於Firestorm來說,由於隨機讀寫問題不突出,Shuffle Read效能基本沒有損耗。 測試場景: TeraSort 基於1TB資料集,對原生Spark Shuffle,Firestorm 進行效能對比測試,結果如下:
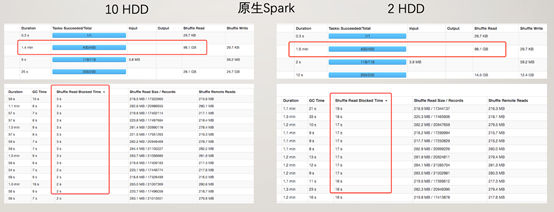
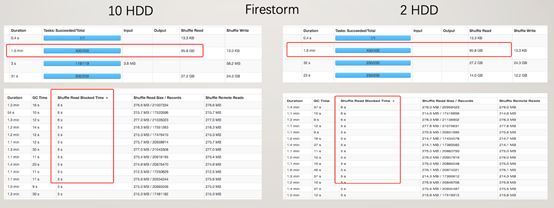
由於Shuffle資料量在500GB,從測試結果可以明顯看出即使擁有10塊HDD,原生Spark的磁碟隨機讀取造成的Shuffle Read效能下降還是非常明顯的。而Firestorm不管是哪個版本,在Shuffle Read的效能上遠優於原生Spark。對於Firestorm-0.2.0版本,由於混合儲存的存在,Commit操作不再需要,可以看到已經不需要在最後個任務完成後等待Shuffle資料寫入儲存了。
四、總結
本文介紹了Firestorm 0.2.0版本對於儲存側的一系列改進,其中最為重要的是引入了混合儲存功能,利用了記憶體,本地磁碟,遠端儲存等資源更合理的分配儲存策略。除了提高了效能,還降低了對本地磁碟的依賴,能更好的在雲原生的環境下進行部署使用。
附上開源地址,歡迎共建: