讀完搞懂MySQL持久化和回滾(圖文詳解)

redo log
事務的支援是資料庫區分檔案系統的重要特徵之一,事務的四大特性:
- 原子性:所有的操作要麼都做,要麼都不做,不可分割。
- 一致性:資料庫從一種狀態變成另一種狀態的的結果最終是一致的,比如A給B轉賬500,A最終少了500,B最終多了500,但是A+B的值始終沒變。
- 隔離性:事務和事務之前相互隔離,互不干擾。
- 永續性:事務一旦提交,它對資料的變更是永久性的。
本篇文章主要說說永續性相關的知識。
當我們在事務中更新一條記錄的時候,比如:
update user set age=11 where user_id=1;
它的流程大概是這樣的:
- 先判斷user_id這條資料所在的頁是否在記憶體裡,如果不在的話,先從資料庫讀取到,然後載入到記憶體中
- 修改記憶體中的age為11
- 寫入redo log,並且redo log處於prepare狀態
- 寫入binlog
- 提交事務,redo log變成commit狀態
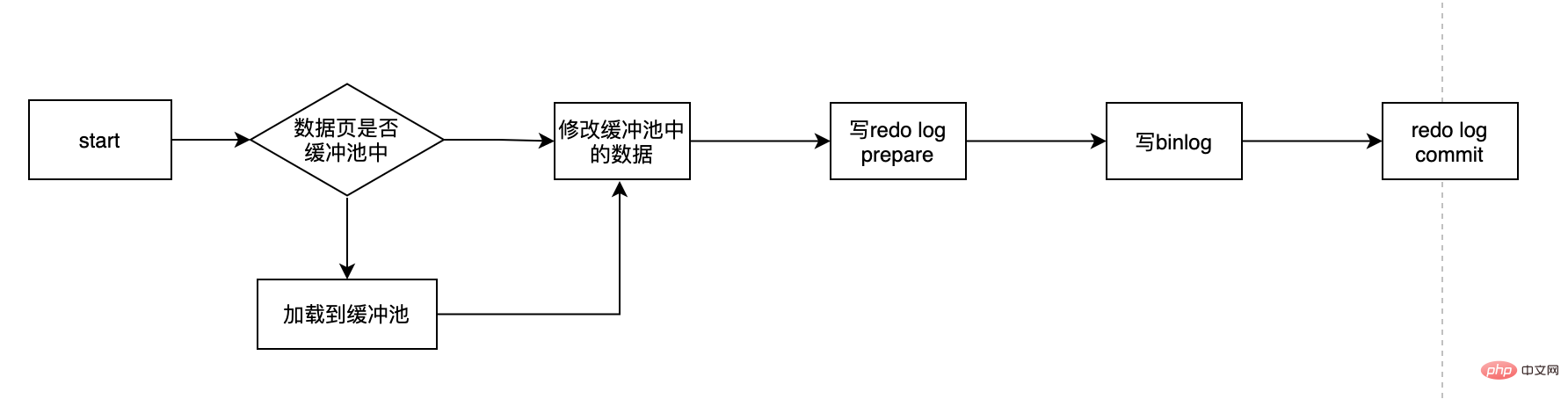
這裡面有幾個關鍵的點:redo log是什麼?為什麼需要redo log?prepare狀態的redo log是什麼?redo log和binlog是否可以只選其一...?帶著這一系列的問題,我們來揭開redo log的面紗。
為什麼要先更新記憶體資料,不直接更新磁碟資料?
我們為什麼不每次更新資料的時候,直接更新對應的磁碟資料?首先我們知道磁碟IO是緩慢的,記憶體是快速的,兩者的速度不是一個量級的,那麼針對緩慢的磁碟IO,出現了索引,通過索引哪怕資料成百上千萬我們依然可以在磁碟上很快速的找我們的資料,這就是索引的作用。但是索引也需要維護,並不是一成不變的,當我們插入一條新資料A的時候,由於這條資料要插入在已存在的資料B之後,那麼就要移動B資料,讓出一個位置給A,這個有一定的開銷。
更糟糕的是,本來要插入的頁已經滿了,那麼就要申請一個新的頁,然後挪一部分資料過去,這叫做頁的分裂,這個開銷更大。如果我們的sql變更是直接修改磁碟的資料,恰巧正好出現上面的問題,那麼此時的效率就會很低,嚴重的話會造成超時,這也是上面更新的過程為什麼先要載入對應的資料頁到記憶體中,然後先更新記憶體中的資料的原因。對於mysql來說,所有的變更都必須先更新緩衝池中的資料,然後緩衝池中的髒頁會以一定的頻率被刷入磁碟(checkPoint機制),通過緩衝池來優化CPU和磁碟之間的鴻溝,這樣就可以保證整體的效能不會下降太快。
為什麼需要redo log?
緩衝池可以幫助我們消除CPU和磁碟之間的鴻溝,checkpoint機制可以保證資料的最終落盤,然而由於checkpoint並不是每次變更的時候就觸發的,而是master執行緒隔一段時間去處理的。所以最壞的情況就是剛寫完緩衝池,資料庫宕機了,那麼這段資料就是丟失的,無法恢復。這樣的話就不滿足ACID中的D,為了解決這種情況下的持久化問題,InnoDB引擎的事務採用了WAL技術(Write-Ahead Logging),這種技術的思想就是先寫紀錄檔,再寫磁碟,只有紀錄檔寫入成功,才算事務提交成功,這裡的紀錄檔就是redo log。當發生宕機且資料未刷到磁碟的時候,可以通過redo log來恢復,保證ACID中的D,這就是redo log的作用。
redo log是如何實現的?
redo log的寫入並不是直接寫入磁碟的,redo log也有緩衝區的,叫做redo log buffer(重做紀錄檔緩衝),InnoDB引擎會在寫redo log的時候先寫redo log buffer,然後也是以一定的頻率刷入到真正的redo log中,redo log buffer一般不需要特別大,它只是一個臨時的容器,master執行緒會每秒將redo log buffer刷到redo log檔案中,因此我們只要保證redo log buffer能夠存下1s內的事務變更的資料量即可,以mysql5.7.23為例,這個預設是16M。
mysql> show variables like '%innodb_log_buffer_size%'; +------------------------+----------+ | Variable_name | Value | +------------------------+----------+ | innodb_log_buffer_size | 16777216 | +------------------------+----------+
16M的buffer足夠應對大部分應用了,buffer同步到redo log的策略主要有如下幾個:
- master執行緒每秒將buffer刷到到redo log中
- 每個事務提交的時候會將buffer刷到redo log中
- 當buffer剩餘空間小於1/2時,會被刷到redo log中
需要注意的是redo log buffer刷到redo log的過程並不是真正的刷到磁碟中去了,只是刷入到os cache中去,這是現代作業系統為了提高檔案寫入的效率做的一個優化,真正的寫入會交給系統自己來決定(比如os cache足夠大了)。那麼對於InnoDB來說就存在一個問題,如果交給系統來fsync,同樣如果系統宕機,那麼資料也丟失了(雖然整個系統宕機的概率還是比較小的)。針對這種情況,InnoDB給出innodb_flush_log_at_trx_commit策略,讓使用者自己決定使用哪個。
mysql> show variables like 'innodb_flush_log_at_trx_commit'; +--------------------------------+-------+ | Variable_name | Value | +--------------------------------+-------+ | innodb_flush_log_at_trx_commit | 1 | +--------------------------------+-------+
- 0:表示事務提交後,不進行fsync,而是由master每隔1s進行一次重做紀錄檔的fysnc
- 1:預設值,每次事務提交的時候同步進行fsync
- 2:寫入os cache後,交給作業系統自己決定什麼時候fsync
從3種刷入策略來說:
2肯定是效率最高的,但是隻要作業系統發生宕機,那麼就會丟失os cache中的資料,這種情況下無法滿足ACID中的D
0的話,是一種折中的做法,它的IO效率理論是高於1的,低於2的,它的資料安全性理論是要低於1的,高於2的,這種策略也有丟失資料的風險,也無法保證D。
1是預設值,可以保證D,資料絕對不會丟失,但是效率最差的。個人建議使用預設值,雖然作業系統宕機的概率理論小於資料庫宕機的概率,但是一般既然使用了事務,那麼資料的安全應該是相對來說更重要些。
redo log是對頁的物理修改,第x頁的第x位置修改成xx,比如:
page(2,4),offset 64,value 2
在InnoDB引擎中,redo log都是以512位元組為單位進行儲存的,每個儲存的單位我們稱之為redo log block(重做紀錄檔塊),若一個頁中儲存的紀錄檔量大於512位元組,那麼就需要邏輯上切割成多個block進行儲存。
一個redo log block是由紀錄檔頭、紀錄檔體、紀錄檔尾組成。紀錄檔頭佔用12位元組,紀錄檔尾佔用8位元組,所以一個block真正能儲存的資料就是512-12-8=492位元組。
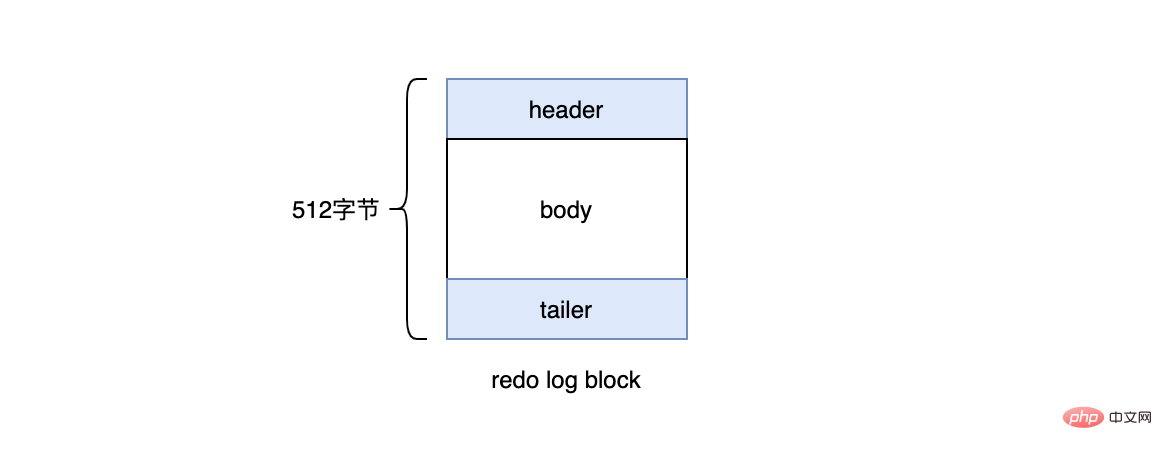
多個redo log block組成了我們的redo log。
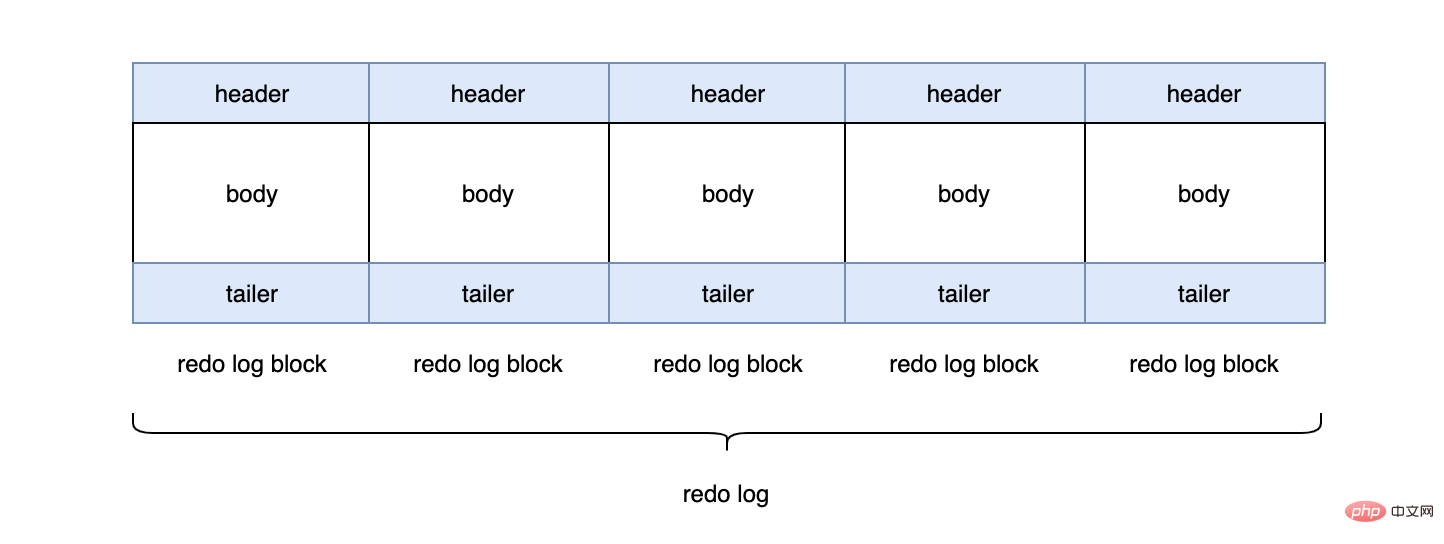
每個redo log預設大小為48M:
mysql> show variables like 'innodb_log_file_size'; +----------------------+----------+ | Variable_name | Value | +----------------------+----------+ | innodb_log_file_size | 50331648 | +----------------------+----------+
InnoDB預設2個redo log組成一個log組,真正工作的就是這個log組。
mysql> show variables like 'innodb_log_files_in_group'; +---------------------------+-------+ | Variable_name | Value | +---------------------------+-------+ | innodb_log_files_in_group | 2 | +---------------------------+-------+ #ib_logfile0 #ib_logfile1
當ib_logfile0寫完之後,會寫ib_logfile1,當ib_logfile1寫完之後,會重新寫ib_logfile0...,就這樣一直不停的迴圈寫。
為什麼一個block設計成512位元組?
這個和磁碟的磁區有關,機械磁碟預設的磁區就是512位元組,如果你要寫入的資料大於512位元組,那麼要寫入的磁區肯定不止一個,這時就要涉及到碟片的轉動,找到下一個磁區,假設現在需要寫入兩個磁區A和B,如果磁區A寫入成功,而磁區B寫入失敗,那麼就會出現非原子性的寫入,而如果每次只寫入和磁區的大小一樣的512位元組,那麼每次的寫入都是原子性的。
為什麼要兩段式提交?
從上文我們知道,事務的提交要先寫redo log(prepare),再寫binlog,最後再提交(commit)。這裡為什麼要有個prepare的動作?redo log直接commit狀態不行嗎?假設redo log直接提交,在寫binlog的時候,發生了crash,這時binlog就沒有對應的資料,那麼所有依靠binlog來恢復資料的slave,就沒有對應的資料,導致主從不一致。
所以需要通過兩段式(2pc)提交來保證redo log和binlog的一致性是非常有必要的。具體的步驟是:處於prepare狀態的redo log,會記錄2PC的XID,binlog寫入後也會記錄2PC的XID,同時會在redo log上打上commit標識。
redo log和bin log是否可以只需要其中一個?
不可以。redo log本身大小是固定的,在寫滿之後,會重頭開始寫,會覆蓋老資料,因為redo log無法儲存所有資料,所以在主從模式下,想要通過redo log來同步資料給從庫是行不通的。那麼binlog是一定需要的,binlog是mysql的server層產生的,和儲存引擎無關,binglog又叫歸檔紀錄檔,當一個binlog file寫滿之後,會寫入到一個新的binlog file中。
所以我們是不是隻需要binlog就行了?redo log可以不需要?當然也不行,redo log的作用是提供crash-safe的能力,首先對於一個資料的修改,是先修改緩衝池中的資料頁的,這時修改的資料並沒有真正的落盤,這主要是因為磁碟的離散讀寫能力效率低,真正落盤的工作交給master執行緒定期來處理,好處就是master可以一次性把多個修改一起寫入磁碟。
那麼此時就有一個問題,當事務commit之後,資料在緩衝區的髒頁中,還沒來的及刷入磁碟,此時資料庫發生了崩潰,那麼這條commit的資料即使在資料庫恢復後,也無法還原,並不能滿足ACID中的D,然後就有了redo log,從流程來看,一個事務的提交必須保證redo log的寫入成功,只有redo log寫入成功才算事務提交成功,redo log大部分情況是順序寫的磁碟,所以它的效率要高很多。當commit後發生crash的情況下,我們可以通過redo log來恢復資料,這也是為什麼需要redo log的原因。
但是事務的提交也需要binlog的寫入成功,那為什麼不可以通過binlog來恢復未落盤的資料?這是因為binlog不知道哪些資料落盤了,所以不知道哪些資料需要恢復。對於redo log而言,在資料落盤後對應的redo log中的資料會被刪除,那麼在資料庫重新啟動後,只要把redo log中剩下的資料都恢復就行了。
crash後是如何恢復的?
通過兩段式提交我們知道redo log和binlog在各個階段會被打上prepare或者commit的標識,同時還會記錄事務的XID,有了這些資料,在資料庫重新啟動的時候,會先去redo log裡檢查所有的事務,如果redo log的事務處於commit狀態,那麼說明在commit後發生了crash,此時直接把redo log的資料恢復就行了,如果redo log是prepare狀態,那麼說明commit之前發生了crash,此時binlog的狀態決定了當前事務的狀態,如果binlog中有對應的XID,說明binlog已經寫入成功,只是沒來的及提交,此時再次執行commit就行了,如果binlog中找不到對應的XID,說明binlog沒寫入成功就crash了,那麼此時應該執行回滾。
undo log
redo log是事務永續性的保證,undo log是事務原子性的保證。在事務中更新資料的前置操作其實是要先寫入一個undo log中的,所以它的流程大致如下:

什麼情況下會生成undo log?
undo log的作用就是mvcc(多版本控制)和回滾,我們這裡主要說回滾,當我們在事務裡insert、update、delete某些資料的時候,就會產生對應的undo log,當我們執行回滾時,通過undo log就可以回到事務開始的樣子。需要注意的是回滾並不是修改的物理頁,而是邏輯的恢復到最初的樣子,比如一個資料A,在事務裡被你修改成B,但是此時有另一個事務已經把它修改成了C,如果回滾直接修改資料頁把資料改成A,那麼C就被覆蓋了。
對於InnoDB引擎來說,每個行記錄除了記錄本身的資料之外,還有幾個隱藏的列:
- DB_ROW_ID:如果沒有為表顯式的定義主鍵,並且表中也沒有定義唯一索引,那麼InnoDB會自動為表新增一個row_id的隱藏列作為主鍵。
- DB_TRX_ID:每個事務都會分配一個事務ID,當對某條記錄發生變更時,就會將這個事務的事務ID寫入trx_id中。
- DB_ROLL_PTR:回滾指標,本質上就是指向 undo log 的指標。

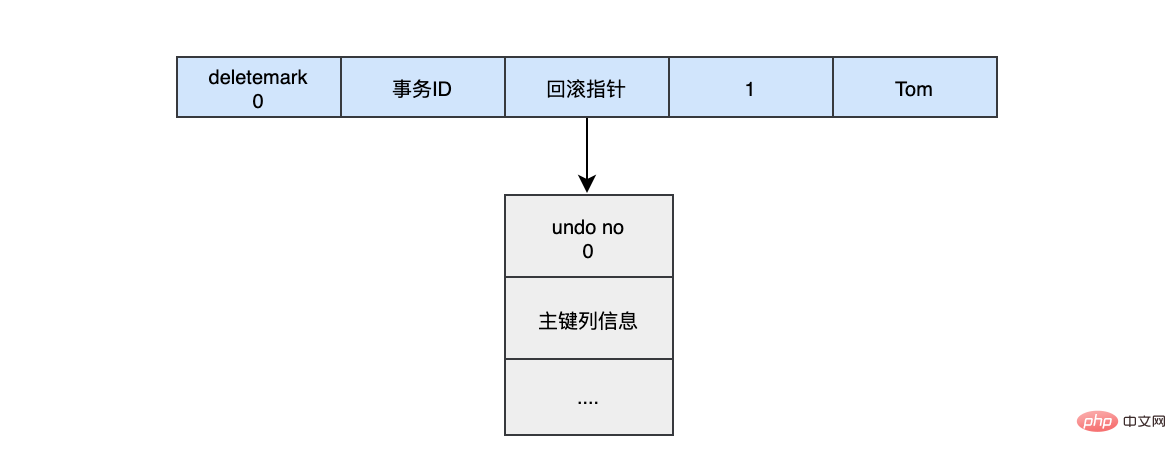
當我們執行INSERT時:
begin;
INSERT INTO user (name) VALUES ("tom")插入的資料都會生一條insert undo log,並且資料的回滾指標會指向它。undo log會記錄undo log的序號、插入主鍵的列和值...,那麼在進行rollback的時候,通過主鍵直接把對應的資料刪除即可。
對於更新的操作會產生update undo log,並且會分更新主鍵的和不更新的主鍵的,假設現在執行:
UPDATE user SET name="Sun" WHERE id=1;
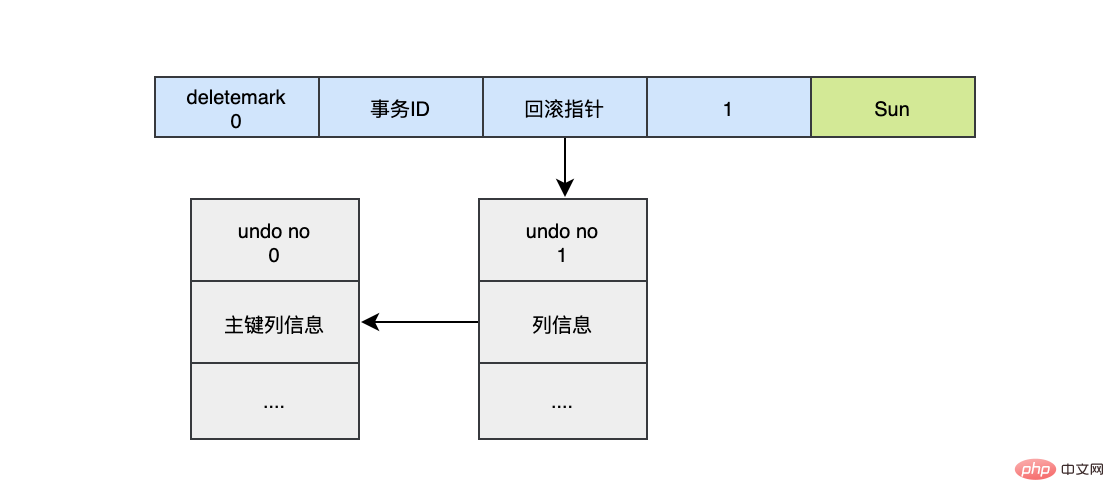
這時會把老的記錄寫入新的undo log,讓回滾指標指向新的undo log,它的undo no是1,並且新的undo log會指向老的undo log(undo no=0)。
假設現在執行:
UPDATE user SET id=2 WHERE id=1;
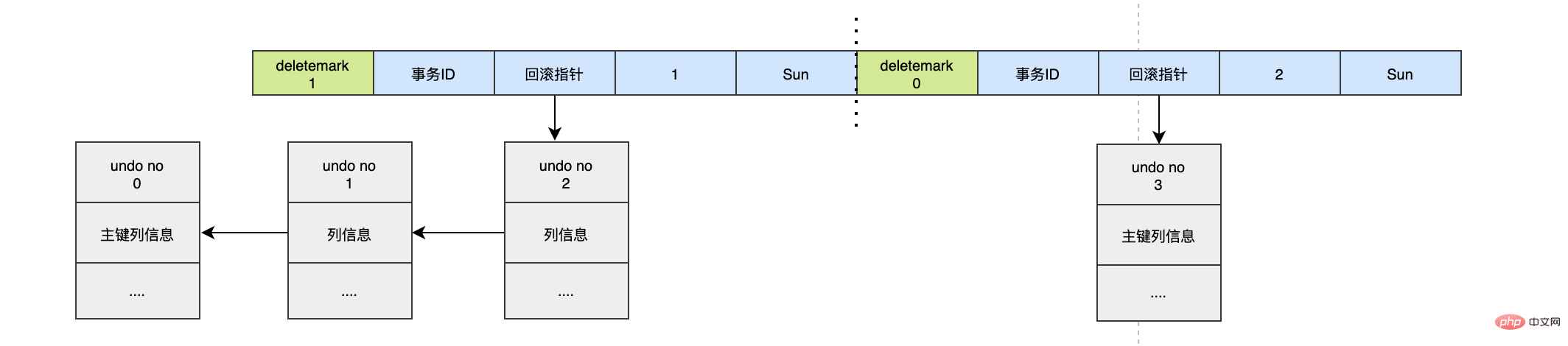
對於更新主鍵的操作,會先把原來的資料deletemark標識開啟,這時並沒有真正的刪除資料,真正的刪除會交給清理執行緒去判斷,然後在後面插入一條新的資料,新的資料也會產生undo log,並且undo log的序號會遞增。
可以發現每次對資料的變更都會產生一個undo log,當一條記錄被變更多次時,那麼就會產生多條undo log,undo log記錄的是變更前的紀錄檔,並且每個undo log的序號是遞增的,那麼當要回滾的時候,按照序號依次向前推,就可以找到我們的原始資料了。
undo log是如何回滾的?
以上面的例子來說,假設執行rollback,那麼對應的流程應該是這樣:
- 通過undo no=3的紀錄檔把id=2的資料刪除
- 通過undo no=2的紀錄檔把id=1的資料的deletemark還原成0
- 通過undo no=1的紀錄檔把id=1的資料的name還原成Tom
- 通過undo no=0的紀錄檔把id=1的資料刪除
undo log存在什麼地方?
InnoDB對undo log的管理採用段的方式,也就是回滾段,每個回滾段記錄了1024個undo log segment,InnoDB引擎預設支援128個回滾段
mysql> show variables like 'innodb_undo_logs'; +------------------+-------+ | Variable_name | Value | +------------------+-------+ | innodb_undo_logs | 128 | +------------------+-------+
那麼能支援的最大並行事務就是128*1024。每個undo log segment就像維護一個有1024個元素的陣列。
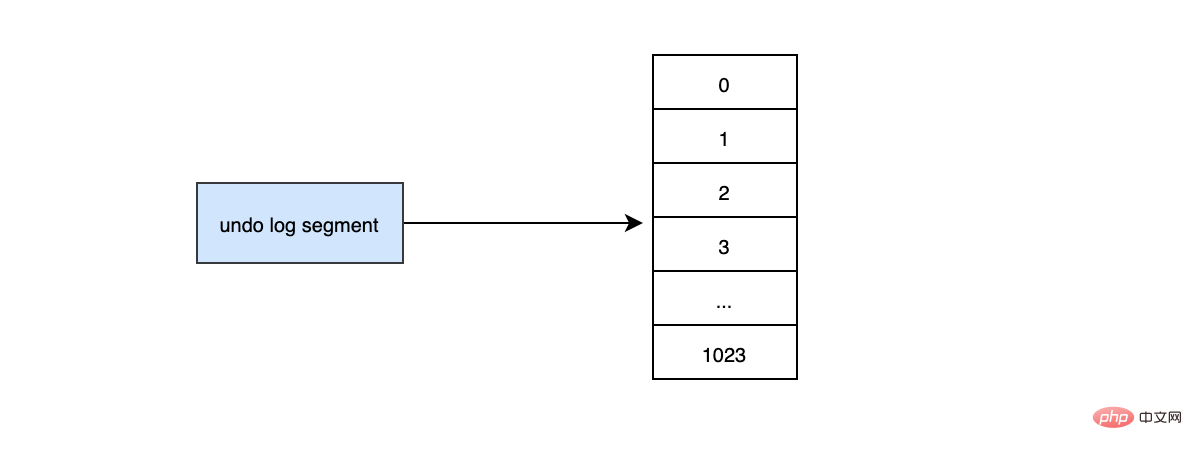
當我們開啟個事務需要寫undo log的時候,就得先去undo log segment中去找到一個空閒的位置,當有空位的時候,就會去申請undo頁,最後會在這個申請到的undo頁中進行undo log的寫入。我們知道mysql預設一頁的大小是16k。
mysql> show variables like '%innodb_page_size%'; +------------------+-------+ | Variable_name | Value | +------------------+-------+ | innodb_page_size | 16384 | +------------------+-------+
那麼為一個事務就分配一個頁,其實是非常浪費的(除非你的事物非常長),假設你的應用的TPS為1000,那麼1s就需要1000個頁,大概需要16M的儲存,1分鐘大概需要1G的儲存...,如果照這樣下去除非mysql清理的非常勤快,否則隨著時間的推移,磁碟空間會增長的非常快,而且很多空間都是浪費的。
於是undo頁就被設計的可以重用了,當事務提交時,並不會立刻刪除undo頁,因為重用,這個undo頁它可能不乾淨了,所以這個undo頁可能混雜著其他事務的undo log。undo log在commit後,會被放到一個連結串列中,然後判斷undo頁的使用空間是否小於3/4,如果小於3/4的話,則表示當前的undo頁可以被重用,那麼它就不會被回收,其他事務的undo log可以記錄在當前undo頁的後面。由於undo log是離散的,所以清理對應的磁碟空間時,效率不是那麼高。
推薦學習:
以上就是讀完搞懂MySQL持久化和回滾(圖文詳解)的詳細內容,更多請關注TW511.COM其它相關文章!