Meta AI(前身為 Facebook AI,雖然已改名三個月時間,但說到 Meta 很多人還是無法第一時間反應過來)近日詳細介紹了「首個高效能自我監督機器學習演演算法」—— ,該演演算法可以應用於語音、影象和文字。

自我監督學習演演算法 —— 是一種機器通過直接觀察環境進行學習的演演算法,而不通過由人工標記過的影象、文字、音訊和其他資料來源來學習,這種演演算法能夠大大推動人工智慧的發展。
從人類自身學習的角度來看,我們日常都在使用視覺和聽覺等感官知覺來了解和學習身邊的事物,但目前市面上普遍存在的自我監督學習演演算法通常只能針對某一個單獨的領域(如:僅限影象、語音和文字中的一種,而不能用於所有情景),這一點也正是 data2vec 和其他自我監督演演算法最大的不同之處。
data2vec 提供一個能夠用於語音、影象和文字的單一自我監督演演算法 —— 這意味著它不依賴於人工標記的資料集,而且還能夠跨語音、影象和文字使用。除了這個優勢以外,data2vec 與以前的演演算法相比,還具備經過簡化的訓練方式,並且在演演算法速度和準確性上還能夠與特定模式的對手相匹配或略勝一籌。
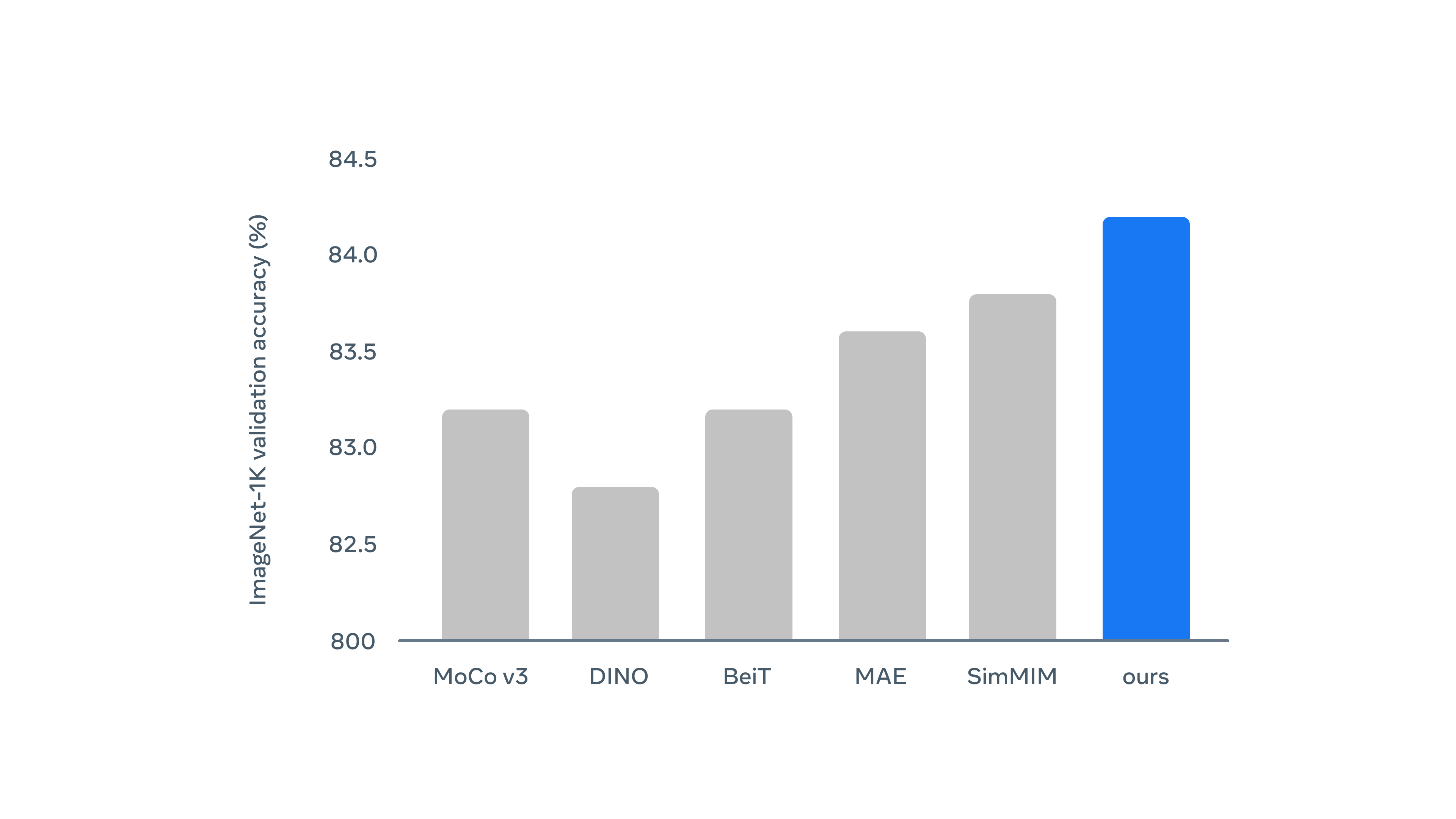
Meta AI 為了證明這個演演算法的可行性,在流行的 ImageNet 計算機視覺基準上對 data2vec 進行了測試,結果顯示它在流行的模型大小上比現有的方法表現更好。
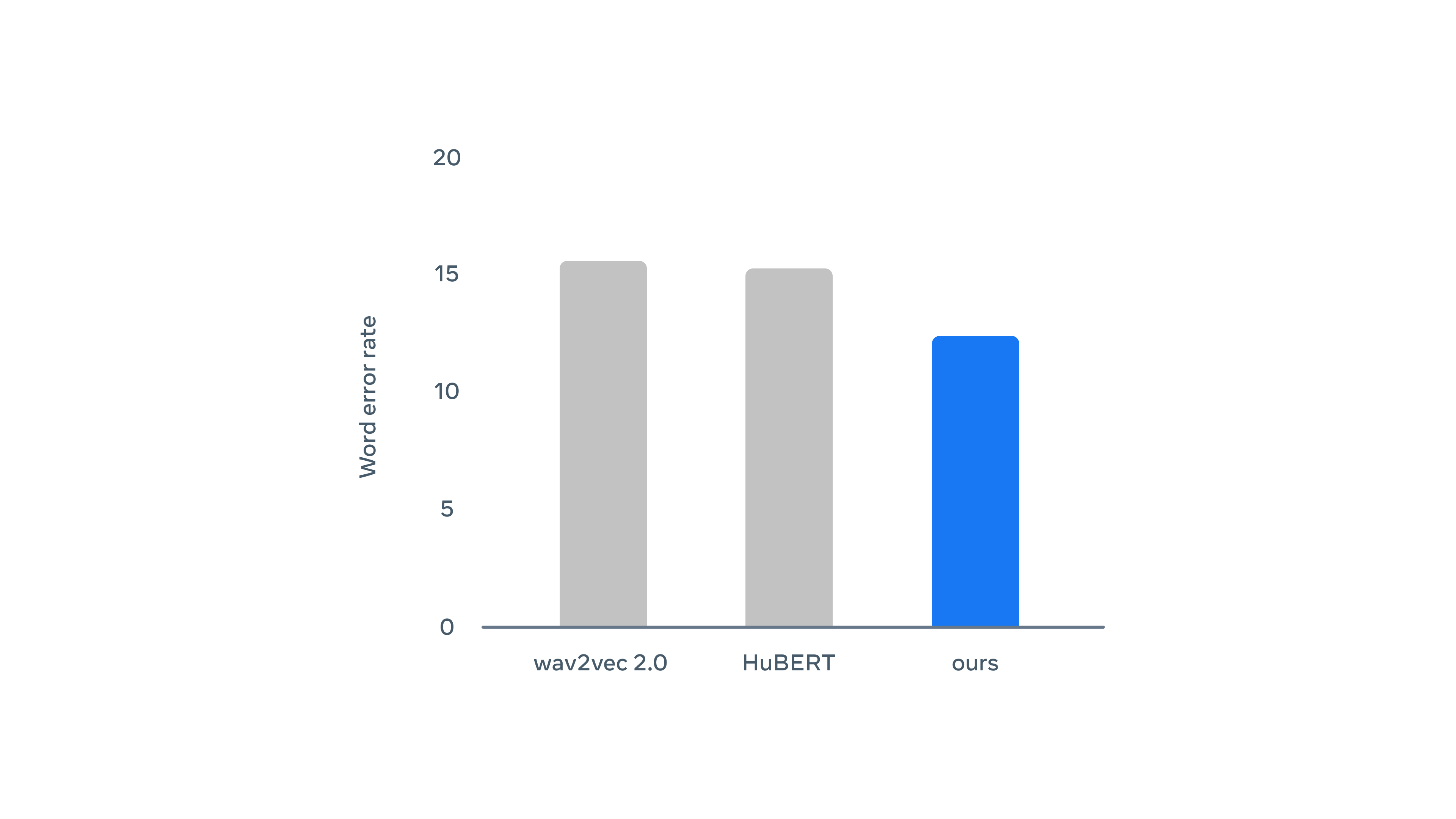
而在語音方面,data2vec 的表現則優於 wav2vec 2.0 和 HuBERT(錯誤率越低越好),他們兩個是 Meta AI 所開發的另兩個語音自我監督演演算法。
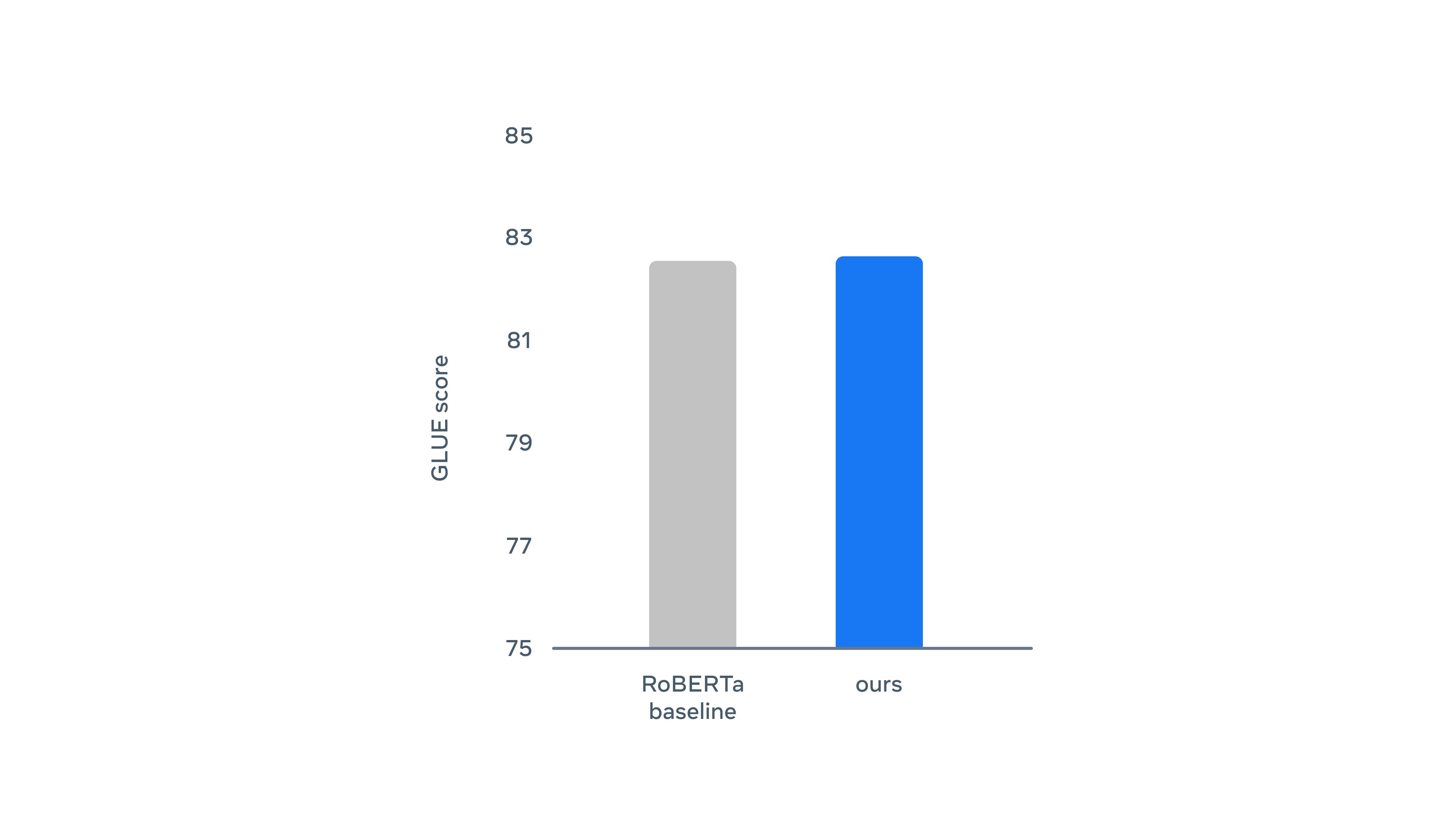
對於文字的處理,經過 GLUE 基準套件測試,它的表現與 RoBERTa 基本一致。
Meta AI 指出,Data2vec 的誕生表明,同樣的自我監督演演算法可以在不同的模式中很好地工作 —— 而且往往比現有的單一最佳演演算法更好。這為更普遍的自我監督學習鋪平了道路,使我們更接近人工智慧可以使用視訊、文字和聲音來學習這個複雜世界的願景。
詳細介紹 data2vec 的論文可從 Meta AI ,與此同時他們還在 GitHub 上釋出了 data2vec 的原始碼和預訓練模型,該演演算法沒有建立單獨的倉庫,而是位於 倉庫之下,演演算法採用 MIT 許可。