【專案總結】瑪嘉環境物聯網平臺(大三學生獨立完成的真實企業外包專案)/網脈通用物聯網平臺/網脈鐵塔監測系統
前言
寫這篇文章的目的主要是對過去做過的專案做一個整理,梳理專案中遇到問題和我當時的解決方案,回顧我做專案的過程,總結經驗和教訓,以便在來年找實習時有一個較好的思路去展示我做過的專案。
在本文只梳理設計和實踐過程中遇到的問題和解決方案,就不具體介紹專案的功能了,如果對專案功能感興趣的可以看我上傳的視訊【專案演示】網脈鐵塔監測物聯網平臺。
一、概述
1.背景
瑪嘉環境物聯網平臺,是一個當地一個做環保器材企業的真實外包專案,由學院的老師接手。最開始是一個研究生在做的,不過做了三個多月,企業不太滿意,暑假時候研究生因為學制的原因到另外一個學校學習,簡單來說就是「跑路」了,留下一個爛攤子。
在大二暑假,我和另外幾個同學被叫到老師辦公室,讓我們接手這個專案,一開始以為還算簡單,費費勁應該也能做,但是直到接手研究生的專案原始碼後我忽然覺得專案難度驟升,因為他使用了Jeecg低程式碼開發平臺。對於低程式碼平臺這種東西,大家可能會覺得匪夷所思,認為低程式碼平臺就是給不會開發的人用的,這怎麼會難度驟升呢?其實不然,現在的低程式碼平臺很多都無法做到這種特殊需求的客製化化開發,一般低程式碼平臺解決的都是那種表單型別開發,直白點就是平常的crud。
可是我們並不是crud啊!
在克服了無數的困難後,我最終把專案完成並部署上線投入使用,現在進入維護階段。
網脈通用物聯網平臺
受到低程式碼的啟發,我針對瑪嘉環境物聯網平臺進行通用化改造,試圖從物聯網領域的工作模式中抽象出一套模型,力求做到人人皆可通過該平臺獲取自己客製化化的物聯網服務。
經過探索和開發,最終也完成部分。當時以為做到了通用化,但是後來在一次和物電老師(負責瑪嘉環境物聯網平臺的硬體開發和設計的老師,一個非常好的,也真正有實力的老師)的交談中,我才發現,由於自身對於物聯網認知的侷限性,並沒有真正達到當初的目標。當時我才意識到,設計一個通用化物聯網平臺,最大的難點在於沒有一個確定的業界統一的標準,這之中有歷史原因,也有利益關係。當各個嵌入式裝置都有統一的協定,那麼物聯網裝置便能像手機接入網際網路這般容易。所謂物聯網,無非就是再現一個網際網路罷了。
網脈鐵塔監測物聯網平臺
該平臺是為了參加服創省賽而寫的版本,不過基本上也就是網脈通用物聯網的別稱,因為之前設計通用物聯網時本就是試圖設計一個通用的物聯網模型,讓所有人,不限行業、不限規模地接入平臺,獲取客製化化服務。或許對於真正的通用化還有些距離,不過對於這種賽題還是綽綽有餘,我幾乎不費吹灰之力就將原來的平臺改造成賽題所要求的平臺(幾乎就是換了個名字),當然也根據賽題要求對通用化物聯網平臺做了一定的功能補充。
2.三者的關係
三者同出一脈,前者是企業要求的產物,後兩者是根據我自己的想法對其的改造,想做出點不一樣的東西,最後也確實做出了點東西。
二、設計中遇到的問題與思考
背景
在思考下述問題時,我們必須得結合當時的背景,否則所提的一切設計都是在耍流氓!
如果從當時的視角來看,我面臨以下幾個問題:
1.專案上手需要時間,就算我也要好久
- Jeecg的技術棧並未完全瞭解,難以上手。比如我沒學過vue那套,redis平常也沒用過;其他同學更不用說了,大抵要學上好久
- 設定專案環境都花了一個晚上(主要之前沒學過前端,node.js這種環境都配了好久)
2.專案設計堪憂
- 整個UI設計堪憂,同時與業務相關的頁面也就那麼兩三個
- 匯入sql檔案,好傢伙,43個表,後來我細細梳理後發現,真正與業務相關的表只有2個!!!其他都是jeecg自帶的…
- 專案規範方面有點隨意,可能是因為以為只有自己看,沒想到有人接手,好在他在關鍵步驟有註釋
- 表設計(時序資料庫)顯然沒有考慮到未來的變動,比如在設計資料儲存時就直接固定六個欄位表示(感測量1-6)(這個還是我看原始碼發現的,專案中還用了反射去寫入實體資料類)
3.專案需求不明確
- 甲方無法專業表述需求,不過這也是外包的通病了
- 甲方需求時刻都在變,時不時加新的需求
- 我們只能從甲方天馬行空的想象中,確定實際可行的方案,並給出原型以供其參考
4.留的檔案很亂,沒有真正意義上的設計檔案
5.時間緊,任務重
甲方的客戶也很急,因為之前開發已經耗費了三個月,甲方希望能先儘快上線系統,滿足基本功能即可
1.如何確定需求?
在真實需求溝通中,我發現了兩點:
永遠不要低估甲方的想象力,他們提出的需求往往特別天馬行空,兩個字——離譜!
永遠不要高估甲方能給的建議,他們對於原型的修改往往提不出有效的建議,一般都是「這裡換個顏色,圖示大一點」,對於專案本質的東西,他們連理解都理解不了,又如何提出有效的建議呢?
那麼,如何去設計出他們想要的專案呢?
我一直在思考這個問題,從我這次的專案經歷來看,我覺得可以分為以下幾步:
1.假想你是甲方
永遠不要站在設計者的角度去溝通專案需求,假想你就是這家企業的老闆,我想開發一個專案讓公司達到某方面的效果。
2.抓住甲方真正想要的東西
甲方在描述他的需求時,往往會給一個範例,或者其他網站,就比如我在溝通需求過程中他們就給了一個之前的老網站(也是一個外包專案,不過介面風格一看就是上個世紀的)。記住不要糾結於甲方描述出的圖畫,因為甲方很多時候也不知道自己想要什麼。他們只會對做出來的東西說一句——「誒,這個好,我想要這個功能」。
這就好像我們去理髮,其實我們往往不知道自己要理什麼髮型,然後我可能就隨便說了一個我印象裡的明星髮型,因為我看他很帥,可我們真的是想要這個髮型嗎?我們只不過想變帥而已,那這個頭型真的可以讓自己變帥嗎?不一定吧。所以真正作為設計師的我們就需要揣測他的意圖,不要在意他所描述的東西,但要抓住他為什麼要描述這種圖畫,揣測他的意圖,理解他的重點。
要了解甲方真正在意哪個點,他想要這些功能的目的,抓住這些點,多去問一些問題確認。
3.根據這些點,以甲方的視角去設計專案,給甲方描述一下你的方案並解釋為什麼
根據之前得到的重點,揣測甲方的意圖,然後從他的角度出發,憑藉你的專業能力,給他描述一下你的設計。
如果你真正get到了甲方的意圖和重點,那麼你可以發揮你的專業知識,提出切實可行的設計方案,並向他解釋你為什麼這麼設計。
4.轉化為需求,和甲方確認
如果甲方覺得不可以,你要明白他不滿意的地方在哪,針對其進行修改;如果方案得到甲方同意,那麼將其轉化為確定需求,和甲方確認。
一定要列出需求清單,不然甲方真的會反覆變需求(別問我為什麼,因為說多了都是淚啊)
2.如何接手這個設計堪憂的專案?
如何接手這個專案呢?這留給我們一個非常大的難題。
當時給我們有兩條路:
1.沿用之前專案
此時甲方也很急,所以希望快速上線,沿用之前的專案好處在於:
理論上可以快速上線,因為我們也不確定新開發一個系統能不能趕得上專案週期。
當然也有很多壞處:
如此糟糕的設計完全滿足不了需求,沿用之前的設計只是權宜之計,未來開發只會舉步維艱;
留下的技術棧我們需要時間學習,對於我而言也至少需要一週時間;
缺少相應設計檔案,很多東西都要讀原始碼。
2.重開一個專案,選用自己熟悉的技術棧,根據使用者需求重新設計編寫
這種方案好處在於技術棧都是自己熟悉的,也更容易駕馭專案,然後可以完全脫開之前專案的設計,重寫一個系統,後期功能開發也會更容易。
但是對於當時那種情況來說,我們並不能確定開發週期,而且當時所組的團隊彼此不熟悉(對我來說還好,因為都是實驗室成員,而作為實驗室負責人的我都認識,也大概瞭解他們的技術方向),這點是個很大的挑戰。
很多時候,計算機領域就是這樣,我們不斷地做選擇題,而這種選擇題並不像我們考試那般有一個明確的答案,選擇往往是多樣的,每個選擇都有它的優劣,你甚至根本無法確認選擇的優勢劣勢以及數量,我們只能憑藉當時的情景去做出自己認為的最優選擇。
當時我選擇了沿用之前的技術棧,但設計肯定不能沿用,必須重構!徹底重構!
3.如何進行資料建模?
如何進行資料建模,這是個非常大的問題,我將其拆分成幾個子問題
①物聯網情境下如何儲存資料?
我們知道物聯網產生的資料往往具有以下特點:
- 海量性
- 關聯性
- 時效性
如果用傳統的關係型資料庫mysql顯然無法很好的滿足需求。
其實不應該這麼去說,因為這樣會有一種先入為主的觀念。我們應該這麼講——在現有的資料庫產品中,mysql肯定不是儲存這種資料的最佳選擇。
根據調研收集資料,以及老師提供的資料庫推薦中,我找到了一個較為合適的資料庫產品——TDengine。它是一款針對物聯網場景進行開發的國產開源時序資料庫產品,或者說平臺(因為整合了很多資料庫沒有的功能),他對時序資料做了專門的優化,同時減去了一些傳統資料庫中不必要的功能(比如事務),因此效能在同類產品中算是前列,更重要的是它的檔案豐富,很好上手。
②如何根據自身需求在TDengine上進行資料建模?
TDengine的設計比較特殊,有普通表和超級表的概念。對於一般資料的儲存,他建議是一個資料採集點一張表,用超級表進行統一管理,這樣有很多好處,比如避開事務問題,最大程度的保證單個資料採集點的插入和查詢的效能是最優的等等。
以上描述的是TDengine檔案中描述的最常用的資料建設計——多列模型
TDengine 支援多列模型,只要物理量是一個資料採集點同時採集的(時間戳一致),這些量就可以作為不同列放在一張超級表裡。
除此之外,官方檔案還提到了另一種極限的設計方式——單列模型
但還有一種極限的設計,單列模型,每個採集的物理量都單獨建表,因此每種型別的物理量都單獨建立一超級表。比如電流、電壓、相位,就建三張超級表。
接下來我們看一下我當時的需求:
從和客戶的交談中,我發現客戶的期望是想做出一個可以線上管理他們的環保裝置,他們給出的老的系統也是這麼做的。
這也可能是之前研究生設計固定的六個欄位儲存的原因,可能當時的甲方認為最多不超過六個。
但是我也發現了,他們的裝置並不固定,幾乎所有的裝置感測器都是外購的,也就是說他們並沒有獨立的生產能力;所有的硬體設施也是臨時挑選,這就意味著他們後期很可能再次更換裝置感測器,而且型別和數量並不固定。
總的來說,當時的情況有以下幾點:
- 一臺裝置的感測器型別和數量不固定
- 每個感測器所包含的感測量不固定,比如溫溼度感測器能測溫度和溼度兩個感測量
- 每臺裝置還有開關量這種概念(這個一開始沒說清楚,導致設計並未考慮到,當然後期做了補救)
如果設計者是你,你會如何設計?
我們來捋一捋單列模型和多列模型的優缺點:
多列模型
就是把一臺裝置的所有感測量儲存在一張表,或者把同一個感測器的感測量儲存在一張表裡。如果是前者,會陷入到研究生的那種設計中,我到底該設計幾個欄位,是六個嗎?你真的能確定甲方不會加到六個以上嗎?(實際上現在他們已經加到了16個,很慶幸當初沒沿用之前的設計);如果是後者,你要確定多少個超級表呢?每加一個感測器型別就加一個嗎?你確定加的完嗎?尤其是在裝置感測器還都確定的情況下。
當然這也有好處,就是它的儲存空間小,速度也快(同一時間上傳的資料只需寫入一次即可)。
單列模型
每個感測量一張表,我只需要建立固定的八張不同型別的表即可。優點是靈活,能很好滿足使用者的情景,缺點是效率低。
綜合下來,我選擇了單列模型去進行資料建模,因為單列模型不僅很好滿足使用者需求,同時公司規模不大,註定不可能有過多(10000以上)的裝置接入系統。與其去追求那可忽略不計的效能,不如選擇切實可行的設計方案來極大提升系統的靈活性。
③如何抽象出物聯網裝置的通用模型?
以下所講大概率不全面,以下設計都是根據我接觸到的裝置來說的。
我們先梳理一下現實中的物理模型是怎麼樣的
以我的甲方舉例,他們所做的是對環保裝置加裝各種感測器,比如汙水處理可能會有流量,溫溼度,光氧這種,同時利用繼電器進行裝置控制,其物理模型如下:
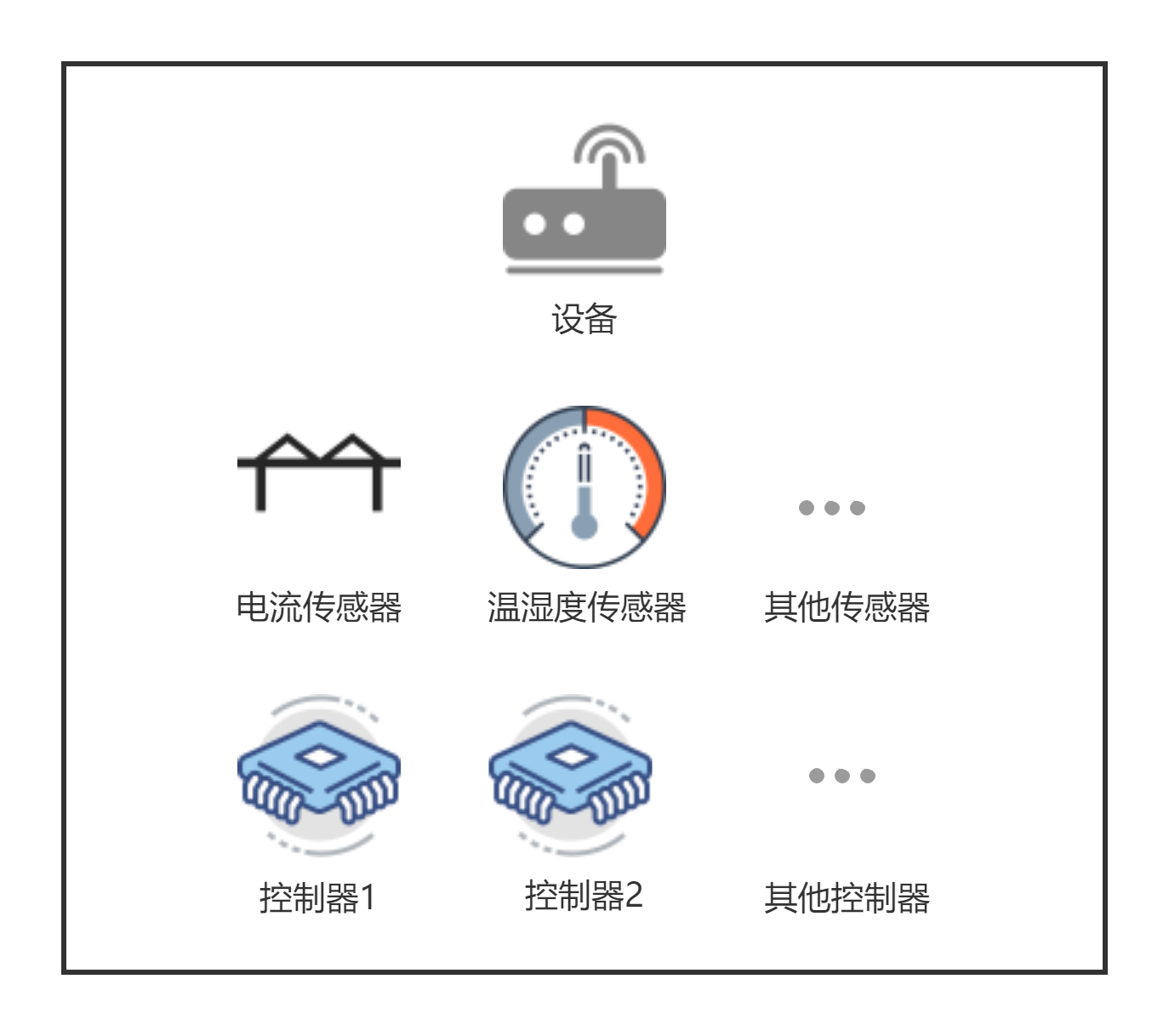
其實上圖已經有了建模的味道,現實中的所表現出的往往會更復雜,更難尋找規律。
首先我們明確一臺裝置有哪些東西:
感測器(資料收集器)
這裡的感測器並不一定是我們嚴格意義上的感測器,這裡的感測器更貼切的叫法應該叫資料收集器,用於收集各種資料,比如電流感測器,溫溼度感測器,gps定位等等。
控制器
控制器是可以對裝置進行控制的裝置,目前我接觸的一般是繼電器控制(甲方採用的方案),肯定還有其他控制裝置的裝置,所以我把它叫做控制器而不叫做繼電器。
根據物理模型,我們轉化為我們需要的資料模型。
首先設計出的資料模型需要符合以下幾點:
- 能夠靈活設定,比如感測量、感測器、控制器的數量、含義等資訊可以自定義
- 對於普通使用者而言不能暴露太多複雜度
- 對於開發人員而言可以靈活設定裝置實現高度可自定義
於是我設計出以下資料模型:
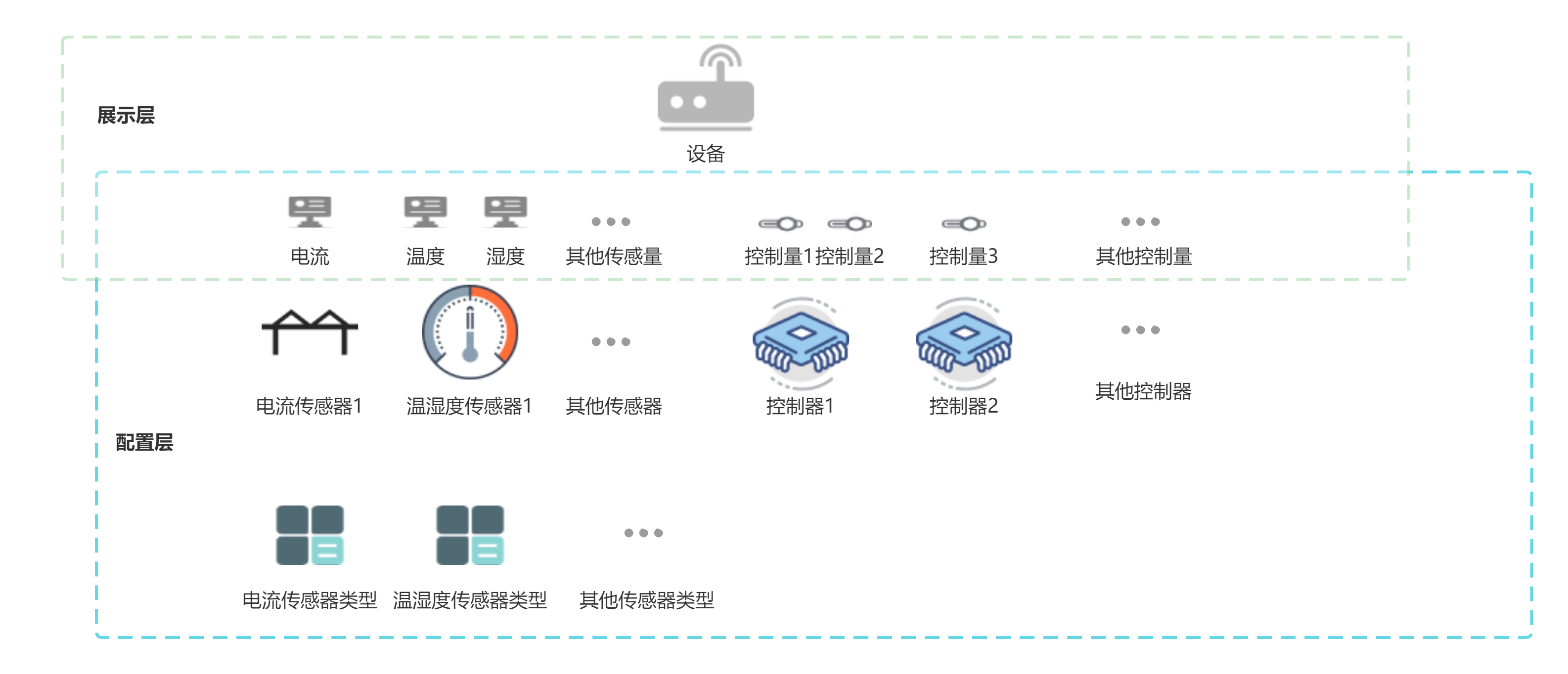
先統一解釋一下各個概念:
裝置:這裡的裝置和物理意義上的裝置相似,是一種虛擬裝置,你可以把你監控的裝置當做一臺裝置,比如生產機床;也可以是某些非常規意義上的裝置,比如你可以把一個房間當做一臺裝置。這裡的裝置更準確的說是一種虛擬的集合,它可能賦予了特定的現實意義,或者僅僅是為了方便管理某些感測器和控制器。
感測量:感測器測出來的資料量。比如溫溼度感測器測出來的溫度、溼度等,一般用於表示裝置的某種資訊。
感測器(資料收集器):這裡的感測器並不一定是我們嚴格意義上的感測器,這裡的感測器更貼切的叫法應該叫資料收集器,用於收集各種資料,比如電流感測器,溫溼度感測器,gps定位等等。感測器除了需要自定一些基本資訊外,最重要的是需要繫結感測量,這樣感測器上傳的資料才能儲存到對應的感測量中。
控制器:控制器是可以對裝置進行控制的裝置,目前我接觸的一般是繼電器控制(甲方採用的方案),肯定還有其他控制裝置的裝置,所以我把它叫做控制器而不叫做繼電器。
感測器型別:為了進一步抽象的產物,比如定義某個型號的感測器為某種型別(因為一個型號的感測器可以有同一種解析方式,同樣的感測量繫結規則),感測器型別可以自定義
感測量型別:為了進一步抽象的產物,主要規定了感測量的儲存方式、單位等。比如溫度就是一個感測量型別,這種型別可以自定義。
上述設計中,我抽象出了很多概念,比如感測器型別、感測量、控制量、感測器型別、感測量型別。這些東西一方面是為了更好地抽離物聯網領域的各個元素,建立出一個統一模型;另一方面是為了方便將展示層和設定層分離開來,在給使用者展示時,使用者肯定不想了解這個溫度是從哪個感測器測出來,他們只想看到這臺裝置的這些指標,比如溫度、溼度;同時他們並不想知道這些控制量(比如裝置開關、風扇檔速)是由繼電器控制的還是由其他裝置控制的,他們只想知道這些控制量可以控制裝置,至於如何控制這不關使用者的事情。
抽離這些元素可以更好的展示裝置資訊,既能兼顧開發人員對裝置模型的自由設定,又能對普通使用者遮蔽部分複雜性。
④如何進行資料庫表設計?
設計思路有了,那麼具體實施就相對容易了。
首先我們有兩個資料庫(資料量不大的情況下,暫時不考慮分庫分表情況),一個是mysql資料庫,一個是TDengine資料庫。
mysql資料庫主要儲存業務資料,可以建立如下表:裝置資訊表、感測量表、感測器表、感測量型別表、感測器型別表、控制器表、控制量表
TDengine資料庫主要儲存時序資料,對應到此場景中就是感測量的值,我們可以根據值的型別確定幾個超級表,然後每新增一個感測量時就根據其資料型別(float、int、string這種)來建立對應的普通表,每次寫入資料時,寫入其感測量表即可。
4.如何與裝置通訊?
①裝置如何與系統連線
這其實是物聯網一個非常大的問題,在這裡我們採用了業界已有的解決方案。
首先是MQTT協定,
MQTT(訊息佇列遙測傳輸)是ISO 標準(ISO/IEC PRF 20922)下基於釋出/訂閱正規化的訊息協定。它工作在TCP/IP協定族上,是為硬體效能低下的遠端裝置以及網路狀況糟糕的情況下而設計的釋出/訂閱型訊息協定,為此,它需要一個訊息中介軟體 。
MQTT是一個基於使用者端-伺服器的訊息釋出/訂閱傳輸協定。MQTT協定是輕量、簡單、開放和易於實現的,這些特點使它適用範圍非常廣泛。在很多情況下,包括受限的環境中,如:機器與機器(M2M)通訊和物聯網(IoT)。其在,通過衛星鏈路通訊感測器、偶爾撥號的醫療裝置、智慧家居、及一些小型化裝置中已廣泛使用。
然後我們採用了開源物聯網 MQTT 訊息伺服器EMQ X
EMQ X (Erlang/Enterprise/Elastic MQTT Broker) 是基於 Erlang/OTP
平臺開發的開源物聯網 MQTT 訊息伺服器。Erlang/OTP是出色的軟實時 (Soft-Realtime)、低延時 (Low-Latency)、分散式
(Distributed)的語言平臺。MQTT 是輕量的 (Lightweight)、釋出訂閱模式 (PubSub) 的物聯網訊息協定。
EMQ X 設計目標是實現高可靠,並支援承載海量物聯網終端的MQTT連線,支援在海量物聯網裝置間低延時訊息路由:
- 穩定承載大規模的 MQTT 使用者端連線,單伺服器節點支援50萬到100萬連線。
- 分散式節點叢集,快速低延時的訊息路由,單叢集支援1000萬規模的路由。 訊息伺服器內擴充套件,支援客製化多種認證方式、高效儲存訊息到後端資料庫。
- 完整物聯網協定支援,MQTT、MQTT-SN、CoAP、LwM2M、WebSocket 或私有協定支援。
至於平臺與EMQ X訊息伺服器的連線我們採用MQTT使用者端 eclipse paho去實現。
大致如下:
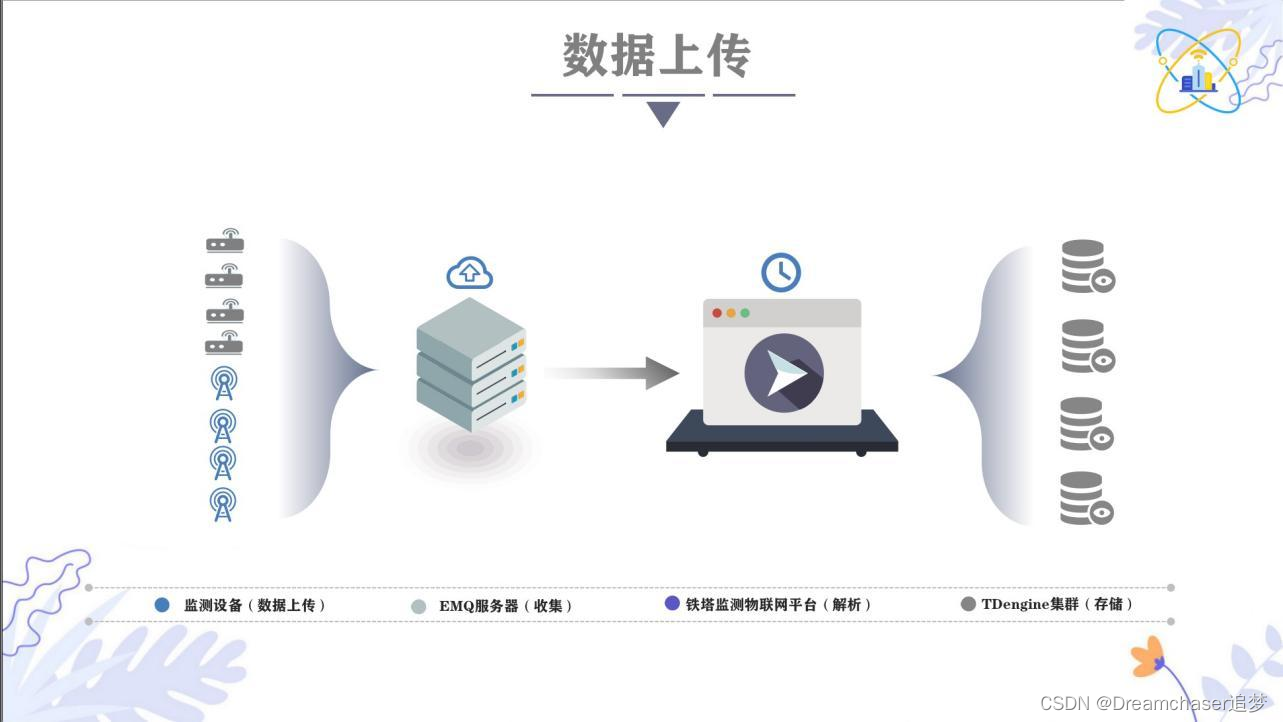
這裡我們僅僅是採用直接連線的方式,主要原因是我當時剛接觸這東西,不太瞭解。其實更優的方案應該是EMQ服務將訊息傳送到訊息中介軟體中,比如RabbitMQ,然後再由系統接收,這樣可以提高系統吞吐量。當然了,在直接連線的時候也用了SpringBoot的監聽器實現了非同步處理,效能也還過得去。
②如何判斷裝置狀態
這裡最優的設計應該是直接利用EMQ X的裝置下線功能的,不過當時由於EMQ伺服器是由物電老師負責的,我不清楚它的功能,所以自己想了個簡單巧妙的方法來判斷裝置狀態:
在每次解析資料後,系統會將資料刷入對應的redis快取(實時資料)中,設定這個快取生命時長為五分鐘。每次前端獲取實時資料都會去這個快取裡取。
如果五分鐘內裝置沒有更新資料(包括gps)時,該快取就失效了,此時如果前端發來請求獲取裝置資料再去快取裡找就找不到了,與此同時會更新裝置狀態,傳送離線訊息。
這種方法雖然巧妙,但是有個問題,離線訊息傳送不及時。
③如何解析完全不一致的裝置資料
裝置可以連線了,也可以判斷裝置狀態了,那麼我們如何解析資料呢?
或許這個問題比較抽象,我們再具體一點,
比如現在有以下感測器:
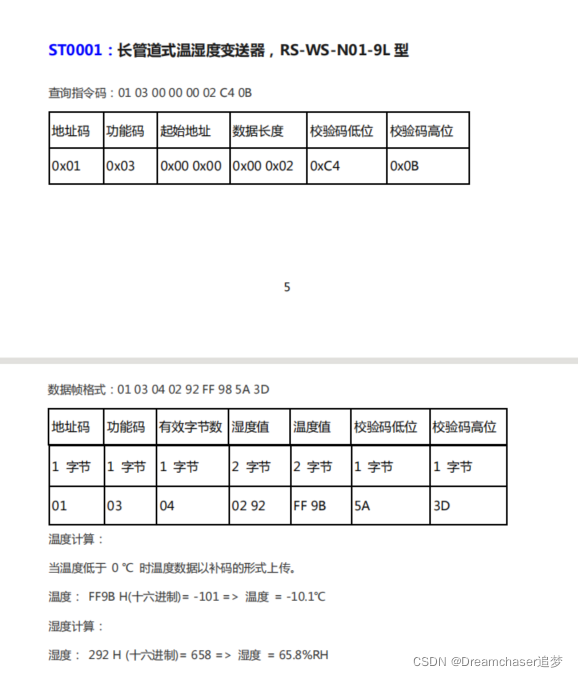
別急,還有這種:
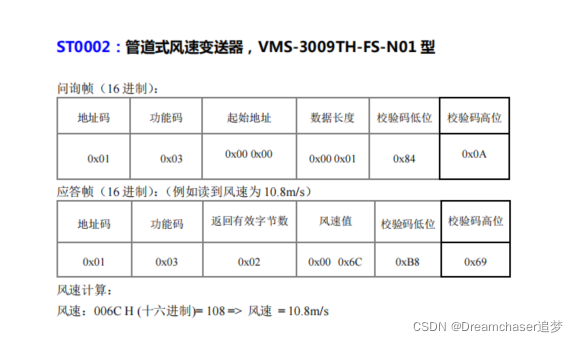
你以為完了嗎?還有呢:

其實這就是我一開始面對的情況——解析格式複雜多樣,種類不確定。
面對上述情況你會如何解決?
你可能會想到以下幾種方案:
- 每個感測器型別寫一套解析程式碼
反問:你確定寫的完嗎? - 對上述的解析方式進行抽象,寫出通用的解析程式碼
反問:你確定你能高度概括如此異構的解析方式? - 對每種方式進行分析,進行歸納彙總,寫出幾種通用的解析程式碼
反問:系統如何識別感測器資料該用哪種解析方式?
其實我選擇的是第三種,那麼問題來了,系統如何識別感測器資料該用哪種解析方式?
當時我使用了一個之前設計中常用的手法——抽離不確定性。我抽離出一個概念——解析規則。
解析規則,顧名思義,就是規定了如何解析資料。它是一串字串,用事先規定好的語言去確定一套解析規則,讓程式看到這串字串就知道如何去解析資料。
舉個例子,在我之前展示的溫溼度感測器和風速感測器中,它們資料解析規則很像,比如起始地址都是0x00 0x00,每個感測量的資料長度都是0x00 0x01,其規定的含義也類似,那麼我們完全可以將其歸為一類(實際上和老師溝通後確實是的,這類感測器都有類似的格式)。那麼我們可以定義以下解析規則:
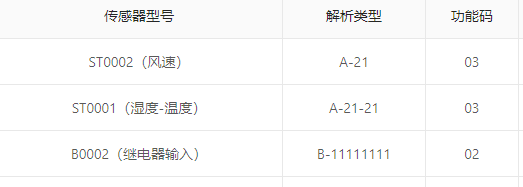
A–通用模擬量(Analog)
每個分隔符之間的數位表示一個感測量的解析方式,第一位表示長度,第二位表示精度。例如A-21-21,兩個「-21」表示有2個感測器資料,其中的「2」表示有2個位元組,「1」表示精度(除以10^1)
對於後一種繼電器資料我們可以另外再定義一種解析規則:
B–通用開關量(Binary)
格式後面跟一串二進位制數位,0表示該位無效,1表示該位有效
B-00001111,表示低4位元有效
B-0000110100001111
這種解析規則的好處就在於它是完全可以窮舉完的,這也意味著我們完全可以事先編寫幾套固定的解析程式碼,然後在設定感測器型別時把解析規則設定。
④如何做到反向控制
有了之前mqtt連線的基礎,那麼我們很容易設計出反向控制的方案。
我們只需規定一個事件,當使用者點選了控制量的開關,那麼系統就會向EMQ訊息伺服器傳送一條訊息,然後訂閱該訊息的裝置便會接收到訊息,此時裝置做出相應的變化。
比如,我點選了裝置溫控開關(一個控制量),那麼系統就會向EMQ伺服器釋出對應的訊息事件,由於我們是用繼電器實現的,那麼我們需要傳送對應訊息內容就是控制串的16位元crc冗餘校驗碼。在EMQ伺服器接受到訊息後會轉發給對應的裝置,裝置做出響應。
事實上,實踐遇到的問題會更復雜,這個會在工程實踐中講。這也從側面看出設計只是理論上的,那些所謂完美的設計在實踐中也會出現各種各樣的問題。
5.如何設計物聯網領域的通用解決方案
在瑪嘉環境物聯網平臺設計之初,我便考慮到了各種可能的情況,比如裝置感測器不固定,型號不固定等等,而我也根據當時的物理模型抽象出一套較為通用的物聯網模型。
根據這套模型,我實現了企業的需求,同時系統本身就具有一種通用性,這種通用性不僅體現在低程式碼開發平臺jeecg,更體現在專案之初的各種通用性設計。
至此,只要符合接入規則的裝置便能通過簡單設定接入平臺,此時我們可以提供諸如檢視裝置狀態,檢視裝置歷史資料,對裝置進行反向控制等基本服務。
有了這些後,我萌生了一個大膽的想法——能不能開發一個適用於物聯網的通用平臺,和那些低程式碼平臺做的事情一樣,提供一些通用物聯網服務,讓任何人,不限行業、不限規模地接入平臺,獲取到客製化化的物聯網服務呢?
於是我開發了第二個版本——通用物聯網平臺。
①裝置服務
該版本最重要的功能就是可以提供各種客製化化的服務,比如裝置資源預約服務,針對的就是諸如停車場、圖書館這種需要資源預約的場景;又比如資料預測服務,可以根據已有的歷史資料預測未來的資料變化,適用於鐵塔監測、裝置監測這種需要預測未來的場景;再比如自動報警服務…
最重要的是這些服務本身可以自由設定,效果圖如下:
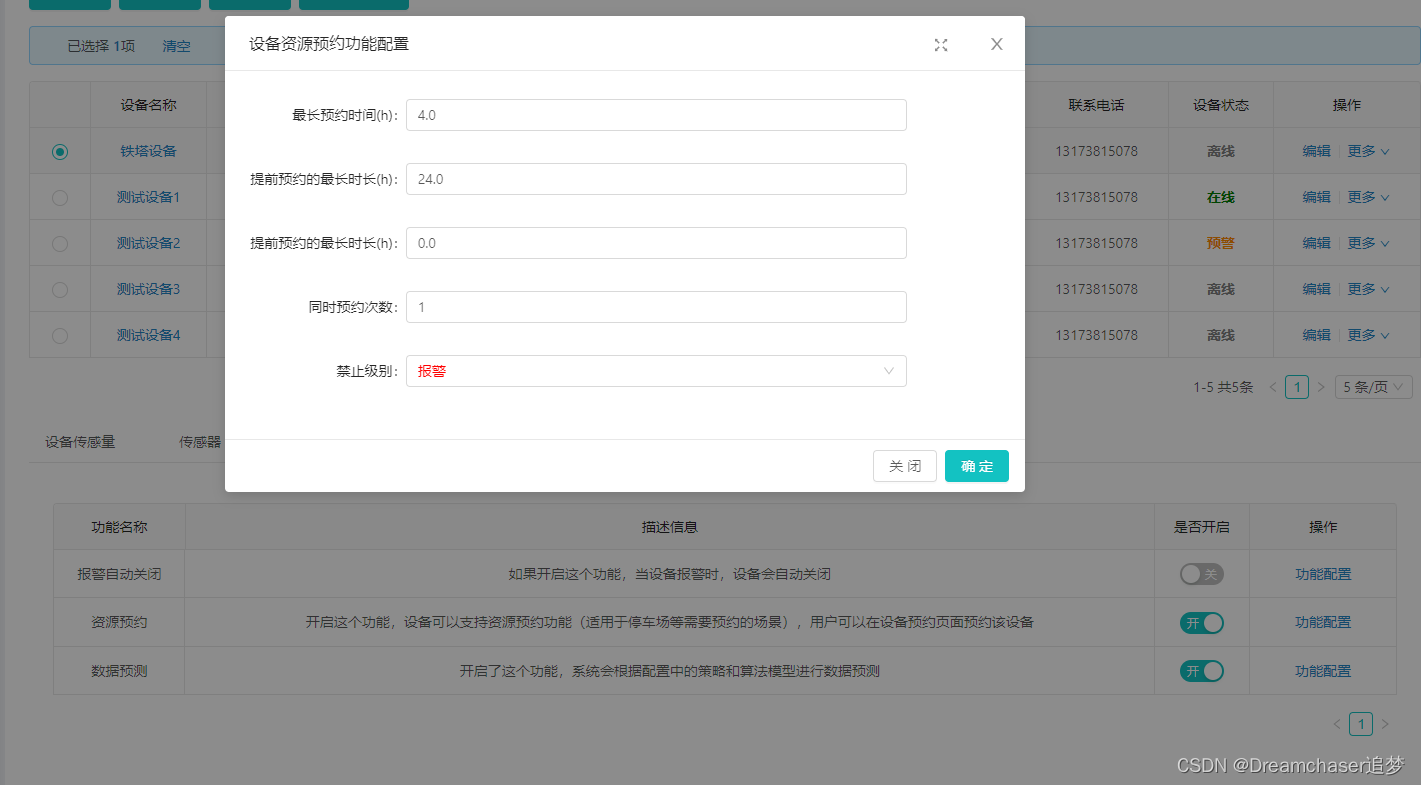
這樣就實現客製化化的服務需求,不同行業的人可以根據自己需要設定獲取自己想要的服務。
②多種運營模式
我們可以設想一下,這樣做就相當於在各種物聯網平臺上又做了一層抽象,構建出一套通用的物聯網模型。如果有企業或者個人想要監控裝置,獲取對應的物聯網服務,只需接入平臺即可(事實上,這種需求很多,比如一些製造業就需要資訊化,而他們最想做的事情就是監控自己的裝置,而他們又不想單獨開發一個平臺,那麼接入已有的平臺便是最好的選擇)
我們可以設定企業賬號,個人賬號,管理自己的裝置,為不同使用者提供不同的服務。
但是,一個令人沮喪的訊息是——阿里雲Iot實際上也就在做類似的事情,這也是我將其寫的差不多的時候才發現的
三、工程實踐中遇到的問題
1.團隊問題
①技術水平技術不一
團隊成員技術水平不一,當初在接到任務時,也分了工,比如我負責整個專案的設計和把控專案進度,以及後端的核心資料解析,其他人負責諸如前端開發,後端業務等等。
但是問題也隨之出現了,正如我之前擔心的那樣,團隊成員工程實踐能力差距太大了,我佈置一個任務,有時一週都沒個解決方案,或者呈現出的東西離我想要的效果差距很大。
②溝通成本
再加上一個很麻煩的問題——溝通成本,每次佈置任務都需要開會花時間講清楚。他們也會遇到很多問題,有時候就來問我,原本我是想分化問題來減輕負擔,但往往問題又拋回給我,我如果一一解答,那還不如我自己去做。
③自身水平受限
當時我很多問題也並沒有明確的解決思路,往往能給的建議也很有限,以我當時的技術水平,無法做到統籌全域性。因為很多問題我自己都需要一一去探尋,並沒有一個明確的解決思路。
眼看著企業那邊不斷催促,老師也不斷問我們這邊的專案狀況,我最終在完成自身的任務的情況下,去著手解決其他問題,嘗試最快滿足企業基本需求。
最終專案部署上線並逐步更新迭代,逐漸演變成個人專案。
2.部署問題小記
在遇到一些問題時,我習慣把解決問題的過程記錄下來,方便後面回顧總結,以下是當時部署遇到的問題小記:
安裝寶塔面板,連結phpmyadmin後分別報502和403的錯誤,發現是因為php沒下,後來又因為php版本過高重新下了個低版本的,後來又報錯,原因是phpmyadmin版本過低,最後將兩者重新安裝到最新版本後使用正常
執行sql檔案發現因為開發時用的是mysql8,而生成環境用的是mysql5.7,sql無法執行,改了一下sql最終執行成功
前端找不到依賴,折騰兩三小時後通過下載淘寶的cnpm,並執行cnpm install解決
後端打成jar包出現問題,折騰了一會後加了個SpringBoot的打包外掛(一開始jar包找不到,發現是版本沒配),打包後發現報包已損壞的資訊,然後根據網上做的去弄結果還是不行,折騰了好久發現按照檔案說的打包方式就可以了,之前是因為多模組的專案只打包了子模組,後面幾次是因為上傳沒有上傳完整就開始java -jar執行了
執行後發現後臺報錯,連線出問題,原因是生產環境的設定有問題,修改後並且同時修改了環境(包括redis和mysql的設定)
後來又報錯說沒有QRTZ_LOCKS這個表,一開始以為真沒有然後又執行了一遍sql檔案,發現是有的,但是是小寫,我就懷疑是不是mysql5是區分大小寫的(開發環境中的mysql8是不區分的),在網上搜尋證實了我的猜測,最終改了mysql的組態檔解決問題
按照步驟設定Nginx後發現網站無法存取,我嘗試不復制dist資料夾而是複製資料夾裡的檔案,還是不可以,搜了之後發現問題在於寶塔面板沒有繫結相對應的域名,繫結後可以正常存取
但是前後端都部署後發現前端頁面雖然可以正常存取,但是驗證碼404,說明前端存取後端失敗,仔細檢查後端執行的紀錄檔檔案發現能夠正常執行,一開始我懷疑後端路徑出問題了,所以開啟相應的埠存取,雖然報404,但是說明後端已經部署上去了。接著我懷疑是前端設定的問題,仔細檢查發現並沒什麼問題,然後開始上網找資料,嘗試著將localhost改成了對應的ip地址,驚奇的發現可以存取了!(按理來說localhost應該也可以的才對,因為我部署前後端都是在一臺伺服器上的,而且mysql的路徑也是localhost)
原因還沒深究,總之弄完已經晚上10點了…
後記
前後端雖然打通,但是外網存取後端報404,包括前端存取後端的swagger檔案也是如此,我嘗試修改前端裡的檔案,把後臺介面的地址改為127.0.0.1,即自己存取自己,居然可以存取了。這說明存取127.0.0.1是可以存取後端,後端沒有問題,但是外網存取不行
這裡我估計是被防火牆攔截掉了,攔截掉也好,反正也是單機部署,省事,就這樣了。
3.前端依賴匯入問題
前端匯入依賴依舊沒有匯入完整,試遍了網上很多很多方法,包括刪了重新安裝,更改倉庫,用npm、yarn亦或者cnpm,重灌vue,這些都沒用,出現各種問題。仔細檢視前端執行的提示,發現它缺少依賴,我試著匯入相應的依賴,可是還有另外一些依賴沒匯入。於是我開始檢視package.json裡的dependencys,發現這些依賴都來自於devDependency,於是乎我就懷疑yarn install時並沒有把這些依賴安裝進去。但是根據百度得到的資訊來看yarn install是可以把所有依賴都匯入的。偶然間我發現了npm的設定production會導致這個原因,檢視自己的設定確實是true,所以應該是因為這個原因導致yarn並沒有將devDependency依賴匯入。解決 npm 無法安裝 devDependencies 下的依賴包的問題 - dkvirus的個人空間 - OSCHINA - 中文開源技術交流社群,於是更改後可以正常執行。不過引入sanding業務檔案後發現依然報錯,估計是因為有些依賴也沒匯入
原來學長還有一些檔案放在其他地方…
4.多資料來源切換問題
這個問題的背景是這樣的:
因為平臺涉及到TDengine和mysql兩個資料庫,所以在業務處理中難免會操作這兩個資料庫。因為mysql和TDengine都是服務JDBC規範的,所以當時採取的解決方案是用dynamic-datasource-spring-boot-starter的多資料庫源的啟動器來控制多個資料來源。
一開始用的還算正常,當時用了jeecg的Java增強功能實現感測量增加,業務邏輯要求操作mysql庫和TDengine,這時,問題就出現了。
以下是當時的問題記錄:
操作了同一個資料庫源,
估計是增強時已經有資料注入,這時再用@DS可能會有一些問題
但是業務需要在增加感測量的時候建立相應的TDengine的表
解決方法有兩個:
1.繼續用線上開發,利用增強Java方式繼續開發,不過資料來源切換是個問題,需要另外寫jdbc來解決
2.生成程式碼,自己去寫業務,這樣可以解決問題,但是在頻繁的需求變動下,這種方式不方便,而有些效果程式碼生成器無法幫你生成
兩種都試了,但是最後還是用第一種開發下去
一開始遇到無法獲取資料來源的問題,原本打算自己去建立,但是想著專案裡已經有這個資料庫連線池了,只是無法獲取到。於是我開始看mybatisplus的相關原始碼,最終發現動態資料來源被註冊到了容器中,名字為dataSource
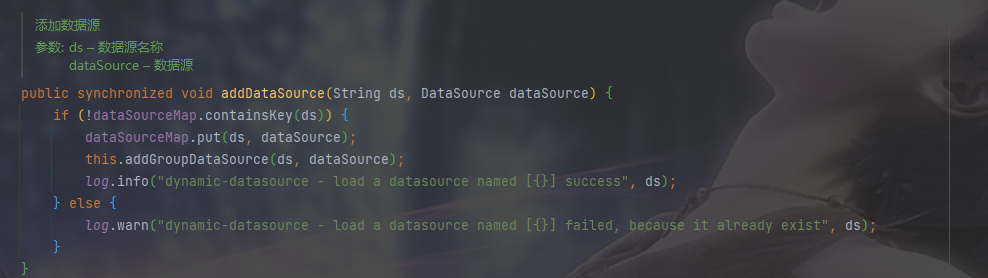
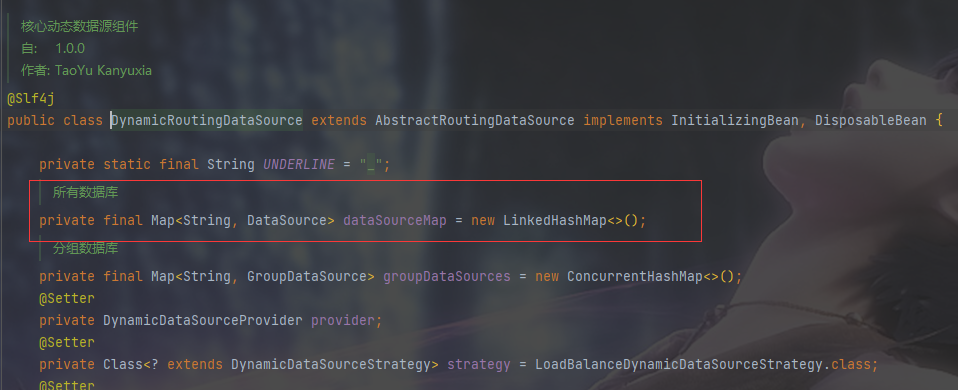
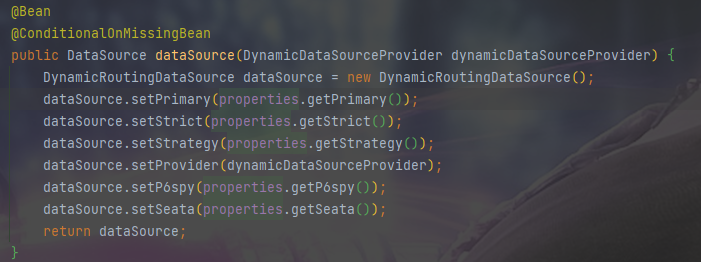
最後通過獲取這個DataSource獲取TDengine的資料庫連線池,然後根據此封裝了個工具類
最終順利通過測試,不過由於jeecg並沒有提供批次刪除的Java增強,所以批次刪除感測量的時候,TDengine資料庫將不會清除這些表
總結一下問題:問題出在多資料來源切換,在一個方法中使用多個資料來源無法使用dynamic-datasource-spring-boot-starter,需要另外編寫JDBC程式碼去運算元據庫,不過單獨為此去建立資料來源顯然不太合適,因為在容器中已經存在了相應的資料庫連線池,問題在於我怎麼獲取到它。通過閱讀原始碼發現,動態資料來源被註冊到了容器中,名字為dataSource,最後通過根據名稱注入來獲取到了這個物件。
現在去看檔案,發現其實是有資料庫源切換的功能的,不過檔案要收費!!!
5.redis快取問題
當時想著對熱點資料比如裝置實時資料、裝置資訊等進行快取,這個操作雖然提高了系統效能,但是與此同時引入了快取一致性問題。當某些業務操作涉及增刪改時,需要同時修改快取和資料庫,否則業務資料則會不一致。為此我特意封裝了redis的快取操作類來方便編碼。
6.mybatis拼接sql語句問題
拼接高階查詢出現問題,試了各種方法,不斷偵錯,把拼接的sql去TDengine裡執行,甚至想自己寫jdbc,不過我突然想到#和$的區別,為了防止sql注入,#是通過jdbc的preparedStatement來實現的,如果把拼接的sql條件放進去會多個「,而且容易造成sql注入的字元會被跳脫。
mybatis $和#問題,之前感覺差不多,無非就是是否預編譯的問題,但隨著做專案後發現兩者大有不同。對於$沒有預編譯(對應jdbc中Statement),是直接以執行的,適合用於自定義sql語句。而#它幫我們做了處理,比如對於字串、時間等資料型別加了"‘"單引號。雖然真正寫過jdbc的程式碼,也深知其麻煩,也瞭解它一些坑,但是用了封裝後的工具,雖然這些麻煩已經看不見了,但是因為自己不瞭解mybatis的處理,也會踩一些坑。
7.redis使用map的問題
原先想著map可以集中管理,統計也方便,但是後來發現使用map不能單獨設定鍵值的有效時間,這就導致很多原本應該失效的資料依然存在。所以最後統一都改成用字首的方式。
8.裝置定位出錯
當時出現這個bug是產品上線後,然後企業那邊發訊息過來說有裝置定位到了非洲,當時我在上課也沒注意,下課後上線去看發現一切正常,這就很詭異了。
後來發現,我在部署偵錯的時候往往沒有任何問題,但是在過了幾天後,問題出現了——部分裝置定位到了非洲,而這個問題也不是一直存在,往往忽隱忽現。
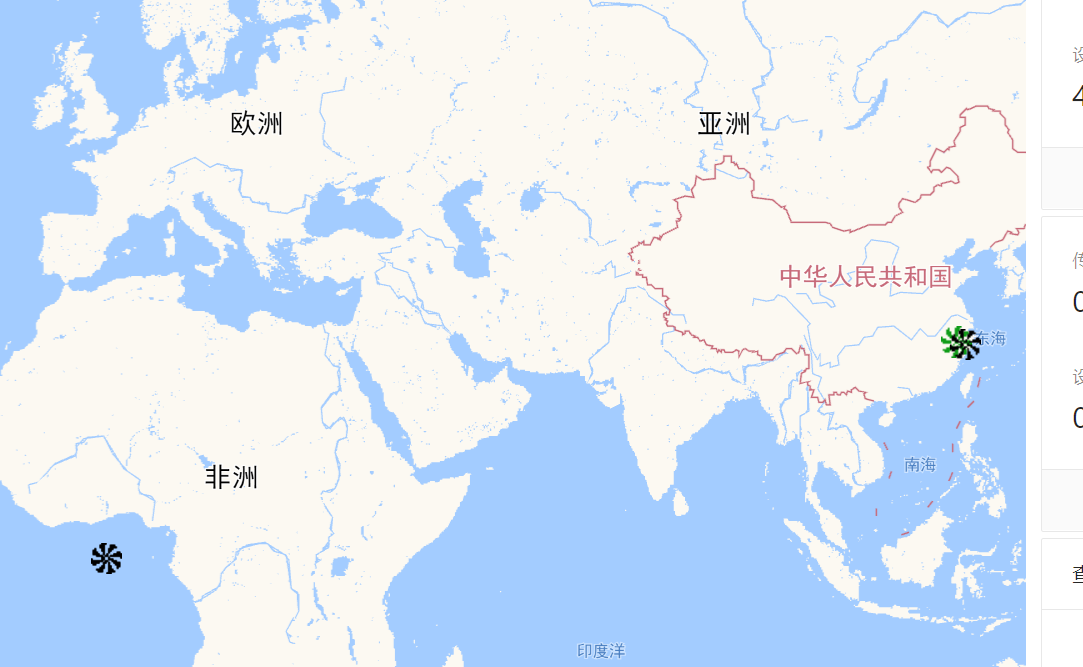
而我們知道改bug的前提是復現bug,而這bug跟個幽靈似的,令人頭疼。
當時我也對另一個現象很好奇,為什麼gps異常的裝置都會定位在非洲,於是我開始搜尋,最後發現這個地方確實有些特殊——在火星座標系中,GPS(0,0)正是這個點。
同時我還發現一個現象,異常的裝置都是下線狀態,於是我開始了猜測,是不是因為裝置被關時上傳了個(0,0)座標?
為了驗證這種猜測,我開始檢索伺服器的紀錄檔,發現裝置確實上傳了(0,0)座標。
好了,問題找到了,是因為裝置誤上傳了(0,0)座標,可這貌似也不是軟體層面上的問題啊!
沒辦法,問題還是要解決的,於是我對(0,0)座標做了特殊的處理——不理它。
其實後面又出現了同樣的問題,排查發現,它上傳的(0,0)座標並不一定是(0,0),而可能是(0.000,0.000)。
我當時的心情是這樣的

於是我又對邏輯做了修改,將解析字串先統一轉化成浮點數,然後再比較,最後才解決了問題。
9.vue非同步資料props傳值問題
以下是當時的問題記錄:
由於是非同步資料,所以資料一開始是預設值,但是等非同步資料來了之後就會有值,但是當你把非同步資料放在data物件的子屬性的子屬性時便會失效(響應式)。
此時我犯了一個錯誤,便是指標賦值,其實props也是把物件參照傳了過去,如果物件屬性會變,那麼它也會變(實際上就是參照誤用)。解決方案就是把父物件給他或者建立一個物件,其屬性便是真正的資料,而我們把該物件參照傳遞即可
監聽問題,正常情況下,如果一個屬性原本存在,直接重新賦值是可以監聽到的。但是如果物件沒有該屬性,而你想手動通過自己去設定來增加新的屬性值,這種情況下vue是監聽不到的!!!

現在回過去看這個問題,其實涉及vue響應式的原理,由於當時是邊學vue邊做的專案,所以很多地方都是磕磕碰碰的,尤其是非同步處理這塊,我因為它糾結了好久。
10.前端伺服器資料更新問題
當我更新了一個版本上線時,企業那邊看到的依舊是老的版本,網上查詢相關博文才發現是因為瀏覽器有快取機制。
解決方案一個是修改nignx設定,設定快取策略為不快取
#解決前端快取問題
location = /index.html {
add_header Cache-Control "no-cache, no-store";
}
想要既能快取又能在部署時沒有問題,需要給靜態檔名新增hash值。在webpack中,有些設定能讓我們實現持久化快取。
11.vue資料延遲更新問題
寫程式碼的時候發現資料並沒有更新,檢索後最終發現問題在於沒使用vue.nextTick方法,想當然以為資料會實時改變
Vue.nextTick(callback) 使用原理:
原因是,Vue是非同步執行dom更新的,一旦觀察到資料變化,Vue就會開啟一個佇列,然後把在同一個事件迴圈 (event loop) 當中觀察到資料變化的 watcher 推播進這個佇列。如果這個watcher被觸發多次,只會被推播到佇列一次。這種緩衝行為可以有效的去掉重複資料造成的不必要的計算和DOm操作。而在下一個事件迴圈時,Vue會清空佇列,並進行必要的DOM更新。
當你設定 vm.someData = ‘new value’,DOM 並不會馬上更新,而是在非同步佇列被清除,也就是下一個事件迴圈開始時執行更新時才會進行必要的DOM更新。如果此時你想要根據更新的 DOM 狀態去做某些事情,就會出現問題。。為了在資料變化之後等待 Vue 完成更新 DOM ,可以在資料變化之後立即使用 Vue.nextTick(callback) 。這樣回撥函數在 DOM 更新完成後就會呼叫。
注:在dom操作都要加一層nextTick
上述問題也是因為不熟悉vue原理導致的,想當然的以為資料會實時改變。
12.vue使用echarts問題
在vue中使用echarts時出現了以下異常——echarts.js:3066 Uncaught Error: setOption should not be called during main process
經過多番檢索最終解決,以下是當時的問題記錄:
跟vue一起用時出現了這個問題,解決了,就是不要讓echart範例變成vue的響應式物件:
data() {
return {
id: 'chart-xxxxx',
instance: null,
};
},
mounted() {
this.instance = Object.freeze({ chart: echart.init(document.getElementById(this.id)) });
},
tips: 超大物件放入vue 的data前最好freeze下,不然可能出現把整個頁面卡住的效能問題,當然,你得明白自己在幹啥
經測試,宣告並初始化賦值option後,修改option屬性,呼叫setOption方法就會報錯。
目前解決的方案就是將其宣告在元件內,只宣告一次,每次都是重新初始化一個新的option。
如下面這樣
option={
title: {
text: this.title,
left: '1%'
}
}
13.前端非同步載入順序
這個是當時js的多執行緒的非同步操作不太會用記下的,當然最後解決了,去學習了下js的相關知識。
14.vue封裝echarts問題
在用vue封裝echarts的過程中遇到了很多問題,其中一個就是非同步資料安裝問題,當資料還沒到達時,圖表便已經安裝。這個問題我也嘗試了很多思路。最終在vue-echarts官方檔案中找到了答案。
它的方案和我之前寫的類似,主動向外提供渲染方法,當資料到達時再主動呼叫更新。但由於我並不清楚echarts的原理,呼叫setOption方法時發現圖表並沒有進行渲染,當我放在圖表mounted方法裡,圖表渲染,不過是資料到達前的圖表,其也沒進行更新。
事實上,不怕你們笑話,我到現在也沒找到vue封裝echarts的最佳實踐,網上的資料貌似也沒給出一個明確的實踐方案。目前專案中封裝的圖表也是經過很多偵錯最終做出來的,但自問也沒有覺得十分優雅,這個問題待我深入理解了vue的原理並熟悉了echarts的使用後,再去研究一下吧。
15.byte和int轉化問題
在寫裝置反向控制時,需要封裝一個轉16為crc校驗碼的方法,其中就踩了byte和int轉化的坑(好吧,是我自己沒注意…)
int轉byte要注意位數的擷取,byte是8bit,int是32bit,強轉要注意後8位元。
byte轉int要注意高位補1的規則,常常要和0xFF進行&操作,即將高位清0。
16.嵌入式裝置單執行緒傳輸問題
當我寫完反向控制功能後,進行測試,可以成功控制。不過隨著測試增多,我也發現,部分命令下發後裝置並無反應。和老師溝通後才發現了問題所在——裝置控制器(繼電器)是單執行緒,有時候我通過平臺的對裝置下發控制命令,此時裝置可能在上傳自身資訊,所以此時發的訊息就被丟棄了。
為了避免這種情況,同時考慮到使用者實際使用情況,我選擇在間隔1s發2-3次命令(因為傳送的命令實際上是裝置的狀態,相同命令即時多次被接收,也不會變更裝置狀態)。不過這樣也有問題,就是如果使用者短時間內開關,開關狀態可能就不是最近一次的狀態。為了避免這種情況,我選擇在前端加相應提示,限制使用者短時間內多次開關裝置。
總結
總之,在做這個專案過程我遇到了很多困難和挑戰,但是經過不斷思考探索,最終也得到了較好的解決,這個過程極大地鍛鍊了我的專案設計能力和工程實踐能力,從這次專案中我也得到了不少有價值的經驗教訓。我個人對於這次經歷還是挺滿意的。
上述專案總結其實也有一些值得大家思考的地方,寫此文的目的不僅是為了自己的總結,也是給同在路上的人一個參考,提供一個思路。
後記
願大家以夢為馬,不負青春韶華。
與君共勉!