6_Makefile與GCC
第六章 Makefile與GCC
6.1 交叉編譯器
6.1.1 什麼是交叉編譯
簡單地說,我們在PC機上編譯程式時,這些程式是在PC機上執行的。我們想讓一個程式在ARM板子上執行,怎麼辦?
ARM板效能越來越強,可以認為ARM板就相當於一臺PC,當然可以在ARM板上安裝開發工具,比如安裝ARM版本的GCC,這樣就可以在ARM板上編譯程式,在ARM板上直接執行這個程式。
但是,有些ARM板效能弱,或者即使它的效能很強也強不過PC機,所以更多時候我們是在PC機上開發、編譯程式,再把這個程式下載到ARM板上去執行。
這就引入一個問題:
1) 我們使用工具比如說gcc編譯出的程式是給PC機用的,這程式裡的指令是X86指令。
2)那麼能否使用同一套工具給ARM板編譯程式?
顯示不行,因為X86的指令肯定不能在ARM板子上執行。所以我們需要使用另一套工具:交叉編譯工具鏈。
為何叫「交叉」?
首先,我們是在PC機上使用這套工具鏈來編譯程式;
然後再把程式下載到ARM板執行;
如果程式不對,需要回到PC機修改程式、編譯程式,再把程式下載到ARM板上執行、驗證。如此重複。
在這個過程中,我們一會在PC上寫程式、編譯程式,一會在ARM板上執行、驗證,中間來來回回不斷重複,所以稱之為「交叉」。對於所用的工具鏈,它是在PC機上給ARM板編譯程式,稱之為「交叉工具鏈」。
有很多種交叉工具鏈,舉例如下:
1) Ubuntu平臺:交叉工具鏈有arm-linux-gcc編譯器
2) Windows 平臺:利用ADS(ARM開發環境),使用armcc編譯器。
3) Windows平臺:利用cygwin環境,執行arm-elf-gcc編譯器。
6.1.2 為什麼需要使用交叉編譯
1) 因為有些目的平臺上不允許或不能夠安裝所需要的編譯器,而我們又需要這個編譯器的某些功能;
2) 因為有些目的平臺上的資源貧乏,無法執行我們所需要編譯器;
3) 因為目的平臺還沒有建立,連作業系統都沒有,根本談不上執行什麼編譯器。
6.1.3 驗證範例
下面這個例子,我們準備原始檔main.c,然後我們採用gcc編譯後可執行程式放在目標板上執行看看是否能執行起來,如下:
main.c
01 #include <stdio.h>
02
03 int main()
04 {
05 printf("100ask\n");
06 return 0;
07 }
在虛擬機器器編譯執行:
$ gcc main.c –o 100ask
$ ./100ask
100ask
$
在上面的執行結果,沒有任問題,然後我們將這個可執行程式放到目標板上,如下:
$ chmod 777 100ask
$ ./100ask
./100ask: line 1: syntax error: unexpected 「(」
$
報錯無法執行。說明為X86平臺製作的可執行檔案,不能在其他架構平臺上執行。交叉編譯就是為了解決這個問題。
為了方便實驗,我們在Ubuntu中使用gcc來做實驗,如果想使用交叉編譯,參考章節《第二章1.2 安裝SDK、設定工具鏈》,安裝好工具鏈,設定好環境變數後,將所有的gcc替換為arm-linux- gcc就可以完成交叉編譯。
其中:
gcc是在x86架構指令用的。
arm-linux- gcc是RSIC(精簡指令集)ARM架構上面使用。
他們會把源程式編譯出不同的組合指令然後生成不同平臺的可執行檔案。
6.2 gcc編譯器1_gcc常用選項__gcc編譯過程詳解
6.2.1 gcc編譯過程詳解
一個C/C++檔案要經過預處理(preprocessing)、編譯(compilation)、組合(assembly)和連線(linking)等4步才能生成可執行檔案,編譯流程圖如下。
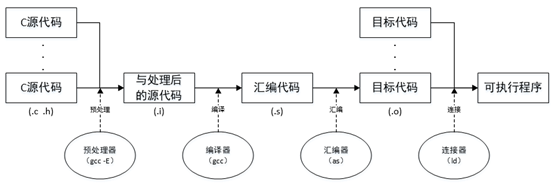
6.1.2.1 預處理:
C/C++原始檔中,以「#」開頭的命令被稱為預處理命令,如包含命令「#include」、宏定義命令「#define」、條件編譯命令「#if」、「#ifdef」等。預處理就是將要包含(include)的檔案插入原檔案中、將宏定義展開、根據條件編譯命令選擇要使用的程式碼,最後將這些東西輸出到一個「.i」檔案中等待進一步處理。
6.1.2.2 編譯:
對預處理後的原始碼進行詞法和語法分析,生成目標系統的組合程式碼檔案,字尾名為「.s」。
6.1.2.3 組合:
對組合程式碼進行優化,生成目的碼檔案,字尾名為「.o」。
6.1.2.4 連結:
解析目的碼中的外部參照,將多個目的碼檔案連線為一個可執行檔案。
編譯器利用這4個步驟中的一個或多個來處理輸入檔案,原始檔的字尾名錶示原始檔所用的語言,字尾名控制著編譯器的預設動作
| 字尾名 | 語言種類 | 後期操作 |
|---|---|---|
| .c | C源程式 | 預處理、編譯、組合 |
| .C | C++源程式 | 預處理、編譯、組合 |
| .cc | C++源程式 | 預處理、編譯、組合 |
| .cxx | C++源程式 | 預處理、編譯、組合 |
| .m | Objective-C源程式 | 預處理、編譯、組合 |
| .i | 預處理後的C檔案 | 編譯、組合 |
| .ii | 預處理後的C++檔案 | 編譯、組合 |
| .s | 組合語言源程式 | 組合 |
| .S | 組合語言源程式 | 預處理、組合 |
| .h | 前處理器檔案 | 通常不出現在命令列上 |
其他字尾名的檔案被傳遞給聯結器(linker),通常包括:
.o:目標檔案(Object file,OBJ檔案)
.a:歸檔庫檔案(Archive file)
在編譯過程中,除非使用了「-c」,「-S」或「-E」選項(或者編譯錯誤阻止了完整的過程),否則最後的步驟總是連線。在連線階段中,所有對應於源程式的.o檔案,「-l」選項指定的庫檔案,無法識別的檔名(包括指定的「.o」目標檔案和「.a」庫檔案)按命令列中的順序傳遞給聯結器。
6.2.2 gcc命令
gcc命令格式是:
gcc [選項] 檔案列表
gcc命令用於實現c程式編譯的全過程。檔案列表引數指定了gcc的輸入檔案,選項用於客製化gcc的行為。gcc根據選項的規則將輸入檔案編譯生成適當的輸出檔案。
gcc的選項非常多,常用的選項,它們大致可以分為以下幾類 。並且使用一個例子來描述這些選項,建立一個mian.c原始檔,程式碼為如下:
main.c:
01 #include <stdio.h>
02
03 #define HUNDRED 100
04
05 int main()
06 {
07 printf("%d ask\n",HUNDRED);
08 return 0;
09 }
註明: 程式碼目錄在裸機Git倉庫 NoosProgramProject/ (6_Makefile與GCC/001_gcc_01001_gcc_01)資料夾下。
6.2.2.1 過程控制選項
過程控制選項用於控制gcc的編譯過程。無過程控制選項時,gcc將預設執行全部編譯過程,產生可執行程式碼。常用的過程控制選項有:
(1)預處理選項(-E)
C/C++原始檔中,以「#」開頭的命令被稱為預處理命令,如包含命令「#include」、宏定義命令「#define」、條件編譯命令「#if」、「#ifdef」等。預處理就是將要包含(include)的檔案插入原檔案中、將宏定義展開、根據條件編譯命令選擇要使用的程式碼,最後將這些東西輸出到一個「.i」檔案中等待進一步處理。使用例子如下:
$ gcc -E main.c -o main.i
執行結果,生成main.i,main.i的內容(由於標頭檔案展開內容過多,我將擷取部分關鍵程式碼):
extern int ftrylockfile (FILE *__stream) __attribute__ ((__nothrow__ , __leaf__)) ;
extern void funlockfile (FILE *__stream) __attribute__ ((__nothrow__ , __leaf__));
# 942 "/usr/include/stdio.h" 3 4
# 2 "main.c" 2
# 5 "main.c"
int main()
{
printf("%d ask\n",100);
return 0;
}
你會發現標頭檔案被展開和printf函數中呼叫HUNDRED這個宏被展開。
(2)編譯選項(-S)
編譯就是把C/C++程式碼(比如上述的「.i」檔案)「翻譯」成組合程式碼。使用例子如下:
$ gcc -S main.c -o main.s
執行結果,生成main.s,main.s的內容:
1 .file "main.c"
2 .text
3 .section .rodata
4 .LC0:
5 .string "%d ask\n"
6 .text
7 .globl main
8 .type main, @function
9 main:
10 .LFB0:
11 .cfi_startproc
12 pushq %rbp
13 .cfi_def_cfa_offset 16
14 .cfi_offset 6, -16
15 movq %rsp, %rbp
16 .cfi_def_cfa_register 6
17 movl $100, %esi
18 leaq .LC0(%rip), %rdi
19 movl $0, %eax
20 call printf@PLT
21 movl $0, %eax
22 popq %rbp
23 .cfi_def_cfa 7, 8
24 ret
25 .cfi_endproc
26 .LFE0:
27 .size main, .-main
28 .ident "GCC: (Ubuntu 7.5.0-3ubuntu1~18.04) 7.5.0"
29 .section .note.GNU-stack,"",@progbits
(3)組合選項(-c)
組合就是將上述的「.s」檔案組合程式碼翻譯成符合一定格式的機器程式碼,在Linux系統上一般表現為ELF目標檔案(OBJ檔案)
$ gcc -c main.c -o main.o
執行結果,生成main.o(將原始檔轉為一定格式的機器程式碼)。
6.2.2.2 輸出選項
輸出選項用於指定gcc的輸出特性等,常用的選項有:
(1)輸出目標選項(-o filename)
-o選項指定生成檔案的檔名為filename。使用例子如下
$ gcc main.c -o main
執行結果,生成可執行程式main,如下:
$ ls
main.c main
$ ./main
$ 100 ask
其中,如果無此選項時使用預設的檔名,各編譯階段有各自的預設檔名,可執行檔案的預設名為a.out。使用例子如下:
$ gcc main.c
執行結果,生成可執行檔案a.out,如下:
$ ls
a.out main.c
$ ./a.out
$ 100 ask
(2)輸出所有警告選項(-Wall)
顯示所有的警告資訊,而不是隻顯示預設型別的警告。建議使用。我們見上面的main.c稍微修改一下,b此節程式碼目錄在裸機Git倉庫 NoosProgramProject/(6_Makefile與GCC/001_gcc_02)資料夾下,如下:
main.c:
01 #include <stdio.h>
02
03 #define HUNDRED 100
04
05 int main()
06 {
07 int a = 0;
08 printf("%d ask\n",HUNDRED);
09 return 0;
10 }
編譯不新增-Wall選項編譯,沒有任何警告資訊,編譯結果如下:
$ gcc main.c -o main.c
編譯新增-Wall選項編譯,現實所有警告資訊,編譯結果如下:
$ gcc main.c -Wall -o main.c
main.c: In function ‘main’:
main.c:7:6: warning: unused variable ‘a’ [-Wunused-variable]
int a=0;
^
6.2.2.3 標頭檔案選項
標頭檔案選項(-Idirname)
將dirname目錄加入到標頭檔案搜尋目錄列表中。當gcc在預設的路徑中沒有找到標頭檔案時,就到本選項指定的目錄中去找。在上面的例子中建立一個目錄,然後建立一個標頭檔案test.h。然後main.c裡面增加#include「test.h」,程式碼目錄在裸機Git倉庫 NoosProgramProject/(6_Makefile與GCC/001_gcc_03) 資料夾下,使用例子如下:
$ tree
.
├── inc
│ └── test.h
└── main.c
1 directory, 2 files
$
test.h:
01 #ifndef __TEST_H
02 #define __TEST_H
03 /*
04 code
05 */
06 #endif
執行結果,這樣就可以參照指定檔案下的目錄的標頭檔案,如下:
$ gcc main.c -I inc -o main
如果不新增標頭檔案選項,編譯執行結果,如下:
$ gcc main.c -o main
main.c:2:18: fatal error: test.h: No such file or directory
compilation terminated.
會產生錯誤提示,無法找到test.h標頭檔案。
6.2.2.3 連結庫選項
(詳細使用方法檢視下一節:gcc編譯器2_深入講解連結過程)
1) 新增庫檔案搜尋目錄(-Ldirname)
將dirname目錄加入到庫檔案的搜尋目錄列表中。
2) 載入庫名選項(-lname)
載入名為libname.a或libname.so的函數庫。例如:-lm表示連結名為libm.so的函數庫。
3) 靜態庫選項(-static)
使用靜態庫。注意:在命令列中,靜態庫夾在的庫必須位於呼叫該庫的目標檔案之後。
6.2.2.4 程式碼優化選項
gcc提供幾種不同級別的程式碼優化方案,分別是0,1,2,3和s級,用-Olevel選項表示。預設0級,即不進行優化。典型的優化選項:
(1)-O :基本優化,使程式碼執行的更快。
(2)-O2:勝讀優化,產生儘可能小和快的程式碼。如無特殊要求,不建議使用O2以上的優化。
(3)-Os:生成最小的可執行檔案,適合用於嵌入式軟體。
6.2.2.5 偵錯選項
程式碼目錄在**git倉庫(6_Makefile與GCC/001_gcc_02)**資料夾下
gcc支援數種偵錯選項:
-g 產生能被GDB偵錯程式使用的偵錯資訊。
偵錯例子如下,首先需要編譯,操作步驟如下:
$ gcc main.c -g -o main
GDB偵錯範例:
(1)run命令
偵錯執行,使用run命令開始執行被偵錯的程式,run命令的格式:
run [執行引數]
$ gdb -q main <---進入偵錯程式
Reading symbols from output...done.
(gdb) run <---開始執行程式
Starting program: /home/100ask/makefile/
100 ask
[Inferior 1 (process 7425) exited normally]
(gdb)
(2)list命令
列出原始碼,使用list命令來檢視源程式以及行號資訊,list命令的格式:
list [行號]
(gdb) list 1 <---列出地一行附近的原始碼,每次10行
#include <stdio.h>
#define HUNDRED 100
int main()
{
int a = 100;
printf("%d ask\n",HUNDRED);
return 0;
(gdb) <Enter> <---按Enter鍵,列出下10行原始碼
}
(gdb)
(3)設定斷點
1)break命令,設定斷點命令,break命令的格式: break <行號> | <函數名>
(gdb) break 7
Breakpoint 1 at 0x40052e: file main.c, line 7.
(gdb)
2)info break命令,查 看斷點命令:
(gdb) info break
Num Type Disp Enb Address What
1 breakpoint keep y 0x000000000040052e in main at main.c:7
(gdb)
3)delete breakpoint命令,刪除斷點命令, delete breakpoint命令的格式: delete breakpoint <斷點號>
(gdb) delete breakpoint 1
(gdb) info break
No breakpoints or watchpoints.
(gdb)
(4)跟蹤執行結果
1)print命令,顯示變數的值,print命令的格式:print[/格式] <表示式>
2)display命令,設定自動現實命令,display命令的格式: display <表示式>
3)step和 next命令,單步執行命令,step和next命令的格式:step <行號> 或 next <行號>
4)continue命令,繼續執行命令。
(gdb) break 7
Breakpoint 1 at 0x40052e: file main.c, line 7.
(gdb) break 9
Breakpoint 2 at 0x400535: file main.c, line 9.
(gdb) run
Starting program:/home/100ask/makefile/
Breakpoint 1, main () at main.c:7
7 int a = 100;
(gdb) continue
Continuing.
Breakpoint 2, main () at main.c:9
9 printf("%d ask\n",HUNDRED);
(gdb) print a
$1 = 100
(gdb)
6.2.3 編譯錯誤警告
在寫程式碼的時候,其實應該養成一個好的習慣就是任何的警告錯誤,我們都不要錯過,
編譯錯誤必然是要解決的,因為會導致生成目標檔案。但是警告可能往往會被人忽略,但是有時候,編譯警告會導致執行結果不是你想要的內容。接下來我們來簡單分析一下gcc的編譯警告如何處理,例子如下:
main.c
01 #include <stdio.h>
02 #include "hander.h"
03
04 int main()
05 {
06 float a = 0.0;
07 int b = a;
08 char c = 'a'
09
10 printf("100ask: \n",a);
11
12 return 0;
13 }
上面檔案中有三處錯誤:
第2行:包含了一個不存在的標頭檔案。
第8行:語句後面沒有加分號。
第10行:書寫格式錯誤,變數a沒有對應的輸出格式。
我們對上面的檔案進行編譯,還記得上面我們講的編譯警告選項嗎?我們在編譯的時候加上它(-Wall),如下:
$ gcc main.c -Wall -o output
main.c: In function ‘main’:
main.c:2:20: fatal error: hander.h: No such file or directory
compilation terminated.
錯誤警告資訊分析:在展開第二行的hander.h標頭檔案的時候,產生編譯錯誤,沒有hander.h檔案或者目錄。接著我們把hander.h標頭檔案去掉,在編譯一次:
$ gcc -Wall main.c -o output
main.c: In function ‘main’:
main.c:10:2: error: expected ‘,’ or ‘;’ before ‘printf’
printf("100ask: \n",a);
^
main.c:8:7: warning: unused variable ‘c’ [-Wunused-variable]
char c = 'a'
^
main.c:7:6: warning: unused variable ‘b’ [-Wunused-variable]
int b = a;
^
錯誤警告資訊分析:有一個錯誤和兩個警告。一個錯誤是指第10行prntf之前缺少分號。兩個警告是指第7行和第8行的變數沒有使用。那麼我繼續解決錯誤資訊和警告,將兩個警告的變數刪除和printf前新增分號,然後繼續編譯,如下:
$ gcc -Wall main.c -o output
main.c: In function ‘main’:
main.c:8:9: warning: too many arguments for format [-Wformat-extra-args]
printf("100ask: \n",a);
^
錯誤警告資訊分析:還是有警告資訊,該警告指的是printf中的格式引數太多,也就是沒有新增變數a的輸出格式,繼續解決錯誤資訊和警告,新增變數a的輸出格式,然後繼續編譯,如下:
$ gcc -Wall main.c -o output
$ tree
.
├── main.c
└── output
最終編譯成功,輸出目標檔案。
6.3 gcc編譯器2_深入講解連結過程
你會發現,可執行檔案檔案會比原始碼大了。這是因為編譯的最後一步連結會解析程式碼中的外部應用。然後將組合生成的OBJ檔案,系統庫的OBJ檔案,庫檔案連結起來。它們全部連結生成最後的可執行檔案,從而使可執行檔案比原始碼大。我們用一個例子來說明上面描述,程式碼使用**(程式碼目錄在裸機Git倉庫 NoosProgramProject/(6_Makefile與GCC/001_gcc_01)資料夾下)**如下:
$ gcc main.c -c
$ gcc -o output main.o
$ gcc -o output_static main.o --static
$ ls -alh
drwxrwxr-x 2 tym tym 4.0K 2月 20 07:27 .
drwxrwxr-x 6 tym tym 4.0K 2月 20 07:25 ..
-rw-rw-r-- 1 tym tym 96 2月 20 07:25 main.c
-rw-rw-r-- 1 tym tym 1.5K 2月 20 07:26 main.o
-rwxrwxr-x 1 tym tym 8.5K 2月 20 07:27 output
-rwxrwxr-x 1 tym tym 892K 2月 20 07:27 output_static
從上面的例子可以看出output_static比output大很多。
6.3.1 動態連結庫和靜態連結庫使用例程
靜態庫和動態庫,是根據連結時期的不同來劃分。
靜態庫:在連結階段被連結的,所以生成的可執行檔案就不受庫的影響,即使庫被刪除,程式依然可以成功執行。連結靜態庫從某種意義上來說是一種複製貼上,被連結後庫就直接嵌入可執行程式中了,這樣系統空間有很大的浪費,而且一旦發現系統中有bug,就必須一一把連結該庫的程式找出來,然後重新編譯,十分麻煩。靜態庫是不是一無是處了呢?不是的,如果程式碼在其他系統上執行,且沒有相應的庫時,解決辦法就是使用靜態庫。而且由於動態庫是在程式執行的時候被連結,因此動態庫的執行速度比較慢。
動態庫:是在程式執行的時候被連結的。程式執行完,庫仍需保留在系統上,以供程式執行時呼叫。而動態庫剛好彌補了這個缺陷,因為動態庫是在程式執行時被連結的,所以磁碟上只需保留一份副本,一次節約了空間,如果發現bug或者是要升級,只要用新的庫把原來的替換掉就可以了。
下面我們建立三個檔案main.c,add.c,add.h,講解靜態庫連結和動態庫連結,如下:
main.c:
#include <stdio.h>
#include "add.h"
int main(int argc, char *argv[])
{
printf("%d\n",add(10, 10));
printf("%d\n",add(20, 20));
return 0;
}
add.c:
#include "add.h"
int add(int a, int b)
{
return a + b;
}
add.h:
#ifndef __ADD_H
#define __ADD_H
int add(int a, int b);
#endif
**註明:**程式碼目錄在裸機Git倉庫 NoosProgramProject/(6_Makefile與GCC/001_gcc_04)資料夾下。
6.3.1.1 靜態庫連結
靜態庫名字一般為「libxxx.a」。利用靜態庫編譯生成的可執行檔案比較大,因為整個函數庫的所有資料都被整合進了可執行檔案中。
優點:
1.不需要外部函數庫支援。
2.載入速度快。
缺點:
1.靜態庫升級,程式需要重新編譯。
2.多個程式呼叫相同庫,靜態庫會重複調入記憶體,造成記憶體的浪費。
靜態庫的製作,如下:
$ gcc add.c -o add.o -c
$ ar -rc libadd.a add.o
靜態庫的使用,例子如下:
$ gcc main.c -o output -ladd -L.
執行結果:
$ ./output
20
40
6.3.1.2 動態庫連結
動態庫名字一般為「libxxx.so」,又稱共用庫。動態庫在編譯的時候沒有被編譯進可執行檔案,所以可執行檔案比較小。需要動態申請並呼叫相應的庫才能執行。
**優點:**多個程式可以使用同一個動態庫,節省記憶體。
**缺點:**載入速度慢。
動態庫的製作,如下:
$ gcc -shared -fPIC lib.c -o libtest.so
$ sudo cp libtest.so /usr/lib/
動態庫的使用,如下:
$ gcc main.c -L. -ltest -o output
執行結果:
$ ./output
20
40
6.4 Makefile的引入及規則
6.4.1 為什麼需要Makefile?
在上一章節對GCC編譯器描述,以及如何進行C源程式編譯。在上一章節的例子中,我們都是在終端執行gcc命令來完成原始檔的編譯。感覺挺方便的,這是因為工程中的原始檔只有一兩個,在終端直接執行編譯命令,確實快捷方便。但是現在一些專案工程中的原始檔不計其數,其按型別、功能、模組分別放在若干個目錄中,如果仍然使用在終端輸入若干條命令,那顯然不切實際,開發效率極低。程式設計師肯定不會被這些繁瑣的事情,影響自己的開發進度。如果我們能夠編寫一個管理編譯這些檔案的工具,使用這個工具來描述這些原始檔的編譯,如何重新編譯。為此「make」工具就此誕生。並且由Makefile負責管理整個編譯流程,Makefile定義了一系列的規則來指定哪些檔案需要先編譯,哪些檔案需要後編譯,哪些檔案需要重新編譯,甚至於進行更復雜的功能操作,因為 Makefile就像一個Shell指令碼一樣,也可以執行作業系統的命令,極大的提高了軟體開發的效率。
6.4.2 Makefile的引入
Makefile的引入是為了簡化我們編譯流程,提高我們的開發進度。下面我們用一個例子來說明Makefile如何簡化我們的編譯流程。我們建立一個工程內容分別main.c,sub.c,sub.h,add.c,add.h五個檔案。sub.c負責計算兩個數減法運算,add.c負責計算兩個數加法運算,然後編譯出可執行檔案。其原始檔內容如下:
main.c:
#include <stdio.h>
#include "add.h"
#include "sub.h"
int main()
{
printf("100 ask, add:%d\n", add(10, 10));
printf("100 ask, sub:%d\n", sub(20, 10));
return 0;
}
add.c:
#include "add.h"
int add(int a, int b)
{
return a + b;
}
add.h:
#ifndef __ADD_H
#define __ADD_H
int add(int a, int b);
#endif
sub.c:
#include "sub.h"
int sub(int a, int b)
{
return a - b;
}
sub.h:
#ifndef __SUB_H
#define __SUB_H
int sub(int a, int b);
#endif
程式碼目錄在裸機Git倉庫 NoosProgramProject/(6_Makefile與GCC/001_Makefile_01)資料夾下。
我們使用gcc對上面工程進行編譯及生成可執行程式,在終端輸入如下命令,如下:
$ gcc main.c sub.c add.c -o ouput
$ ls
add.c add.h main.c output sub.c sub.h
$ ./output
100 ask, add:20
100 ask, sub:10
上面的命令是通過gcc編譯器對 main.c sub.c add.c這三個檔案進行編譯,及生成可執行程式output,並執行可執行檔案產生結果。
從上面的例子看起來比較簡單,一條命令完成三個源程式的編譯併產生結果,這是因為目前只有三個原始檔,如果有上千個原始檔,或者存在依賴檔案的修改,你執行上面那條命令,將會重新編譯,你會發現一天的工作都是等待漫長的編譯。這樣消耗的時間是非常恐怖的。我們肯定想哪個檔案被修改了,只編譯這個被修改的檔案即可。其它沒有修改的檔案就不需要再次重新編譯了,為此我們改變我們的編譯方法,使用命令如下:
$ gcc -c main.c
$ gcc -c sub.c
$ gcc -c add.c
$ gcc main.o sub.o add.o -o output
我們將上面一條命令變成了四條,分別編譯成原始檔的目標檔案,最後再將所有的目標檔案連結成可執行檔案。雖然這個增加了命令,但是可以解決,當其中一個原始檔的內容發生了變化,我們只需要修改單獨重新生成對應的目標檔案,然後重新連結成可知執行檔案,不用全部重新編譯。假如我們修改了add.c檔案,只需要重新編譯生成add.c的目標檔案,然後再將所有的.o檔案連結成可執行檔案,如下:
$ gcc -c add.c
$ gcc main.o sub.o add.o -o output
這樣的方式雖然可以節省時間,但是仍然存在幾個問題,如下:
1)如果原始檔的數目很多,那麼我們需要花費大量的時間,敲命令執行。
2)如果原始檔的數目很多,然後修改了很多檔案,後面發現忘記修改了什麼。
3)如果標頭檔案的內容修改,替換,更換目錄,所有依賴於這個標頭檔案的原始檔全部需要重新編譯。
這些問題我們不可能一個一個去找和排查,所有引入Makefile,正可以解決上述問題。我們對上面的問題整理,編寫Makefile,如下:
Makefile:
output: main.o add.o sub.o
gcc -o output main.o add.o sub.o
main.o: main.c
gcc -c main.c
add.o: add.c
gcc -c add.c
sub.o: sub.c
gcc -c sub.c
clean:
rm *.o output
Makefile編寫好後只需要執行make命令,就可以自動幫助我們編譯工程。注意,make命令必須要在Makefile的當前目錄執行,如下:
$ ls
add.c add.h main.c Makefile sub.c sub.h
$ make
gcc -c main.c
gcc -c add.c
gcc -c sub.c
gcc -o output main.o add.o sub.o
$ ls
add.c add.h add.o main.c main.o Makefile output sub.c sub.h sub.o
通過make命令就可以生成相對應的目標檔案.o和可執行檔案。如果我們在此使用make命令編譯,如下:
$ make
make: 'output' is up to date.
再次使用make編譯器會返回,可執行程式為最新的結果,我們依舊修改一下add.c,然後在編譯,如下:
$ make
gcc -c add.c
gcc -o output main.o add.o sub.o
會發現,它自動只重新編譯生成我們修改原始檔的目標檔案.c和可執行檔案。
通過上述例子,Makefile的引入,將我們上面的三個問題解決了,它可以幫助我們快速的編譯,只更新修改過的檔案,這樣在一個很龐大的工程中,只有第一次編譯時間比較長,第二次開始大大縮短編譯時間,節省了我們的開發週期。不過上面的Makefile仍然有問題,就是工程中的原始檔不斷增加,如果按照上面的寫法,你會發現,Makefile會越來越臃腫。下面我們講解如何解決這個臃腫的問題。
6.4.3 Makefile的規則
6.4.3.1 命名規則:
一般來說將Makefile命名為Makefile或makefile都可以,當很多原始檔的名字是小些,所以一般使用Makefile。Makefile也可以為其他名字,比如makefile.linux,但你需用make的引數(-f or --file)制定對應的檔案,範例如下:
make -f makefile.linux
6.4.3.2 基本語法規則:
目標(target):依賴(prerequisites)
[Tab]命令(command)
1)target:需要生成的目標檔案
2)prerequisites:生成該target所依賴的一些檔案
3)command:生成該目標需要執行的命令
三者的關係:target依賴於 prerequisites中的檔案,其生成規則定義在command中。
舉例,比如我們平時要編譯一個檔案:
$ gcc main.c -o main
換成Makefile的書寫格式:
01 main:main.c
02 gcc main.c -o main
**注意:Makefile檔案裡的命令必須要使用Tab。**不能使用空格。
6.4.3.3 目標生成規則:
目標生成:
1)檢查規則中的依賴檔案是否存在。
2)若依賴檔案不存在,則尋找是否有規則用來生成該依賴檔案。
目標生成流程,如下:
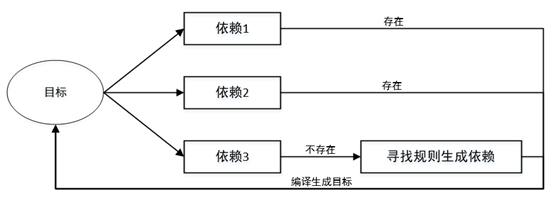
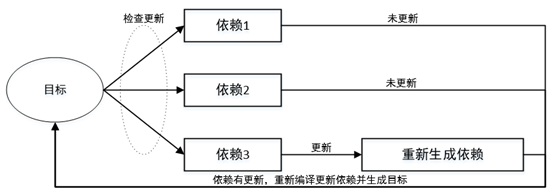
目標更新:
1)檢查目標的所有依賴,任何一個依賴有更新時,就要重新生成目標。
2)目標檔案比依賴檔案更新時間晚,則需要更新。
目標更新流程,如下:
我們使用上面的例子,Makefile內容如下:
output: main.o add.o sub.o
gcc -o output main.o add.o sub.o
main.o: main.c
gcc -c main.c
add.o: add.c
gcc -c add.c
sub.o: sub.c
gcc -c sub.c
clean:
rm *.o output
編譯執行:
$ make
gcc -c main.c
gcc -c add.c
gcc -c sub.c
gcc -o output main.o add.o sub.o
make命令會檢測尋找目標的依賴是否存在,不存在,則會尋找生成依賴的命令。當我們修改某一個檔案時,比如之修改add.c檔案,然後重新make,如下:
$ make
gcc -c add.c
gcc -o output main.o add.o sub.o
會發現make命令,會檢查更新。然後只編譯更新的軟體。
6.5 Makefile的語法
6.5.1 變數的定義及取值
Makefile也支援變數定義,變數的定義也讓的我們的Makefile更加簡化,可複用。
**變數的定義:**一般採用大寫字母,賦值方式像C語言的賦值方式一樣,如下:
DIR = ./100ask/
**變數取值:**使用括號將變數括起來再加美元符,如下:
FOO = $(DIR)
變數可讓Makefile簡化可複用,上面個的Makefile檔案,內容如下:
output: main.o add.o sub.o
gcc -o output main.o add.o sub.o
main.o: main.c
gcc -c main.c
add.o: add.c
gcc -c add.c
sub.o: sub.c
gcc -c sub.c
clean:
rm *.o output
我們可以將其優化,如下:
#Makefile變數定義
OBJ = main.o add.o sub.o
output: $(OBJ)
gcc -o output $(OBJ)
main.o: main.c
gcc -c main.c
add.o: add.c
gcc -c add.c
sub.o: sub.c
gcc -c sub.c
clean:
rm $(OBJ) output
我們分析一下上面簡化過的Makefile,第一行是註釋,Makefile的註釋採用‘#’,而且不支援像C語言中的多行註釋。第二行我們定義了變數OBJ,並賦值字串」main.o,add.o,sub.o「。其中第三,四,十三行,使用這個變數。這樣用到用一個字串的地方直接呼叫這個變數,無需重複寫一大段字串。
Makefile除了使用‘=’進行賦值,還有其他賦值方式,比如‘:=’和‘?=’,接下來我們來對比一下這幾種的區別:
6.5.2.1 賦值符‘=’
我們使用一個例子來說明賦值符‘=’的用法。Makefile內容如下:
01 PARA = 100
02 CURPARA = $(PARA)
03 PARA = ask
04
05 print:
06 @echo $(CURPARA)
分析程式碼:第一行定義變數PARA,並賦值為「100」,第二行定義變數CURPARA,並賦值參照變數PARA,此時CURPARA的值和PARA的值是一樣的,第三行,將變數PARA的變數修改為「ask」。第六行輸出CURPARA的值,echo前面增加@符號,代表執行此條命令,不會在終端列印出來。
通過命令「make print」執行Makefile,如下:
$ make print
ask
從結果上看,變數CURPARA的值並不是「100」。其值為PARA最後一次賦值的值。說明,賦值符「=」,可以藉助另外一個變數,可以將變數的真實值推到後面去定義。也就是變數的真實值取決於它所參照的變數的最後一次有效值。
其實可以理解為在C語言中,定義一個指標變數指向一個變數的地址。如下:
01 int a = 10;
02 int *b = &a;
03 a=20;
6.5.2.2 賦值符‘:=’
我們使用一個例子來說明賦值符‘:=’的用法。Makefile內容如下:
01 PARA = 100
02 CURPARA := $(PARA)
03 PARA = ask
04
05 print:
06 @echo $(CURPARA)
程式碼分析:我們見上面的Makefile的第二行的「=」替換成「:=」,重新編譯,如下:
$ make print
100
$
從結果上看,變數CURPARA的值為「100」。「=」和「:=」的區別就在這裡,「:=」只取第一次被賦值的值。
6.5.2.3 賦值符‘?=’
我們兩個Makefile來說明賦值符‘?=’的用法。如下:
第一個Makefile:
PARA = 100
PARA ?= ask
print:
@echo $(PARA)
編譯結果:
$ make print
100
$
第二個Makefile:
PARA ?= ask
print:
@echo $(PARA)
編譯結果:
$ make print
ask
$
上面的例子說明,如果變數 PARA 前面沒有被賦值,那麼此變數就是「ask」,如果前面已經賦過值了,那麼就使用前面賦的值。
6.5.2.4 賦值符‘+=’
Makefile 中的變數是字串,有時候我們需要給前面已經定義好的變數新增一些字串進去,此時就要使用到符號「+=」,比如如下:
01 OBJ = main.o add.o
02 OBJ += sub.o
這樣的結果是OBJ的值為:」main.o,add.o,sub.o「。說明「+=」用作與變數的追加。
6.5.2 系統自帶變數
系統自定義了一些變數,通常都是大寫,比如CC,PWD,CLFAG等等,有些有預設值,有些沒有,比如以下幾種,如下:
1)CPPFLAGS:前處理器需要的選項,如:-l
2)CFLAGS:編譯的時候使用的引數,-Wall -g -c
3)LDFLAGS:連結庫使用的選項,-L -l
其中:預設值可以被修改,比如CC預設值是cc,但可以修改為gcc:CC=gcc
使用的例子,如下:
01 OBJ = main.o add.o sub.o
02 output: $(OBJ)
03 gcc -o output $(OBJ)
04 main.o: main.c
05 gcc -c main.c
06 add.o: add.c
07 gcc -c add.c
08 sub.o: sub.c
09 gcc -c sub.c
10
11 clean:
12 rm $(OBJ) output
使用系統自帶變數,如下:
01 CC = gcc
02 OBJ = main.o add.o sub.o
03 output: $(OBJ)
04 $(CC) -o output $(OBJ)
05 main.o: main.c
06 $(CC) -c main.c
07 add.o: add.c
08 $(CC) -c add.c
09 sub.o: sub.c
10 $(CC) -c sub.c
11
12 clean:
13 rm $(OBJ) output
在上面例子中,系統變數CC不改變預設值,也同樣可以編譯,修改的目的是為了明確使用gcc編譯。
6.5.3 自動變數
Makefile的語法提供一些自動變數,這些變數可以讓我們更加快速的完成Makefile的編寫,其中自動變數只能在規則中的命令使用,常用的自動變數如下:
1)$@:規則中的目標
2)$<:規則中的第一個依賴檔案
3)$^:規則中的所有依賴檔案
我們上面的例子繼續完善,修改為採用自動變數的格式,如下:
01 CC = gcc
02 OBJ = main.o add.o sub.o
03 output: $(OBJ)
04 $(CC) -o $@ $^
05 main.o: main.c
06 $(CC) -c $<
07 add.o: add.c
08 $(CC) -c $<
09 sub.o: sub.c
10 $(CC) -c $<
11
12 clean:
13 rm $(OBJ) output
其中:第4行 表 示 變 量 O B J 的 值 , 即 m a i n . o a d d . o s u b . o , 第 四 , 第 六 , 第 八 行 的 ^表示變數OBJ的值,即main.o add.o sub.o,第四,第六,第八行的 表示變量OBJ的值,即main.oadd.osub.o,第四,第六,第八行的<分別表示main.c add.c sub.c。$@表示output。
6.5.4 模式規則
模式規則實在目標及依賴中使用%來匹配對應的檔案,我們依舊使用上面的例子,採用模式規則格式,如下:
01 CC = gcc
02 OBJ = main.o add.o sub.o
03 output: $(OBJ)
04 $(CC) -o $@ $^
05 %.o: %.c
06 $(CC) -c $<
07
08 clean:
09 rm $(OBJ) output
其中:第五行%.o: %.表示如下。
1.main.o由main.c生成
2.add.o 由 add.c生成
3.sub.o 由 sub.c生成
6.5.5 偽目標
所謂偽目標就是這樣一個目標,它不代表一個真正的檔名,在執行make時可以指定這個目標來執行其所在規則定義的命令,有時我們將一個偽目標成為標籤。那麼到底什麼是偽目標呢?我們依舊通過上面的例子來說明偽目標是什麼。
我們執行make命令,然後在執行在執行命令make clean,如下:
$make
gcc -c main.c
gcc -c add.c
gcc -c sub.c
gcc -o output main.o add.o sub.o
$make clean
rm *.o output
是不是發現沒啥問題,接著我們做個手腳,在Makefile目錄下建立一個clean的檔案,然後依舊執行make和make clean,如下:
$touch clean
$make
gcc -c main.c
gcc -c add.c
gcc -c sub.c
gcc -o output main.o add.o sub.o
$make clean
make: 'clean' is up to date.
為什麼clean下的命令沒有被執行?這是因為Makefile中定義的只執行命令的目標與工作目錄下的實際檔案出現名字衝突。而Makefile中clean目標沒有任何依賴檔案,所以目標被認為是最新的而不去執行規則所定義的命令。所以rm命令不會被執行。偽目標就是為了解決這個問題,我們在clean前面增加.PHONY:clean,如下:
01 CC = gcc
02 OBJ = main.o add.o sub.o
03 output: $(OBJ)
04 $(CC) -o $@ $^
05 %.o: %.c
06 $(CC) -c $<
07
08 .PHONY:clean
09 clean:
10 rm $(OBJ) output
執行結果:
$make
gcc -c main.c
gcc -c add.c
gcc -c sub.c
gcc -o output main.o add.o sub.o
$make clean
rm *.o output
通過增加了偽目標之後,就是執行rm命令了。當一個目標被宣告為偽目標後,make在執行規則時不會去試圖去查詢隱含規則來建立它。這樣就提高了make的執行效率,也不用擔心由於目標和檔名重名了。
偽目標的兩大好處:
1.避免只執行命令的目標和工作目錄下的實際檔案出現名字衝突。
2.提高執行Makefile時的效率
6.5.6 Makefile函數
Makefile提供了大量的函數,其中我們經常使用的函數主要有兩個(wildcard,patsubst)。注意,Makefile中所有的函數必須要有返回值。建立一個資料夾src,在裡下面建立兩個檔案,100.c,ask.c。如下:
.
├── Makefile
└── src
├── 100.c
└── ask.c
**註明:**程式碼目錄在裸機Git倉庫 NoosProgramProject/(6_Makefile與GCC/001_Makefile_02)資料夾下。
6.5.6.1 wildcard函數
用於查詢指定目錄下指定型別的檔案,函數引數:目錄+檔案型別,如下:
$(wildcard 指定檔案型別)
其中,指定檔案型別,如果不寫路徑,則預設為當前目錄查詢,例子如下:
01 SRC = $(wildcard ./src/*.c)
02
03 print:
04 @echo $(SRC)
執行命令make,結果如下:
$ make
./src/ask.c ./src/100.c
其中,這條規則表示:找到目錄./src下所有字尾為.c的檔案,並賦值給變數SRC。命令執行完,SRC變數的值:./src/ask.c ./src/100.c
6.5.6.2 patsubst函數
用於匹配替換。函數引數:原模式+目標模式+檔案列表,如下:
$( patsubst 原模式, 目標模式, 檔案列表)
其中,從檔案列表中查詢出符合原模式檔案型別的檔案,然後一一替換成目標模式。舉例:將./src目錄下的.c結尾的檔案,替換成.o檔案,並賦值給obj。如下:
SRC = $(wildcard ./src/*.c)
OBJ = $(patsubst %.c, %.o, $(SRC))
print:
@echo $(OBJ)
執行命令make,結果如下:
$ make
./src/ask.o ./src/100.o
其中,這條規則表示:把變數中所有字尾為.c的檔案替換為.o。 命令執行完,OBJ變數的值:./src/ask.o ./src/100.o
6.6 Makefile範例
在上面的例子中,我們都是把標頭檔案,原始檔放在同一個檔案裡面,這樣不好用於維護,所以我們將其分類,把它變得更加規範一下,把所有的標頭檔案放在資料夾:inc,把所有的原始檔放在資料夾:src。(**程式碼目錄在裸機Git倉庫 NoosProgramProject/(6_Makefile與GCC/001_Makefile_03)資料夾下)。**如下:
$ tree
.
├── inc
│ ├── add.h
│ └── sub.h
├── Makefile
└── src
├── add.c
├── main.c
└── sub.c
其中Makefile的內容如下:
01 SOURCE = $(wildcard ./src/*.c)
02 OBJECT = $(patsubst %.c, %.o, $(SOURCE))
03
04 INCLUEDS = -I ./inc
05
06 TARGET = 100ask
07 CC = gcc
08 CFLAGS = -Wall -g
09
10 $(TARGET): $(OBJECT)
11 @mkdir -p output/
12 $(CC) $^ $(CFLAGES) -o output/$(TARGET)
13
14 %.o: %.c
15 $(CC) $(INCLUEDS) $(CFLAGES) -c $< -o $@
16
17 .PHONY:clean
18 clean:
19 @rm -rf $(OBJECT) output/
分析:
行1:獲取當前目錄下src所有.c檔案,並賦值給變數SOURCE。
行2:將./src目錄下的.c結尾的檔案,替換成.o檔案,並賦值給變數OBJECT。
行4:通過-I選項指明標頭檔案的目錄,並賦值給變數INCLUDES。
行6:最終目標檔案的名字100ask,賦值給TARGET。
行7:替換CC的預設之cc,改為gcc。
行8:將顯示所有的警告資訊選項和gdb偵錯選項賦值給變數CFLAGS。
行11:建立目錄output,並且不再終端現實該條命令。
行12:編譯生成可執行程式100ask,並將可執行程式生成到output目錄
行15:將原始檔生成對應的目標檔案。
行17:偽目標,避免當前目錄有同名的clean檔案。
行19:用與執行命令make clean時執行的命令,刪除編譯過程生成的檔案。
最後編譯的結果,如下:
$ make
gcc -I ./inc -c src/main.c -o src/main.o
gcc -I ./inc -c src/add.c -o src/add.o
gcc -I ./inc -c src/sub.c -o src/sub.o
gcc src/main.o src/add.o src/sub.o -o output/100ask
$tree
.
├── inc
│ ├── add.h
│ └── sub.h
├── Makefile
├── output
│ └── 100ask
└── src
├── add.c
├── add.o
├── main.c
├── main.o
├── sub.c
└── sub.o
上面的Makefile檔案算是比較完善了,不過專案開發中,程式碼需要不斷的迭代,那麼必須要有東西來記錄它的變化,所以還需要對最終的可執行檔案新增版本號,如下:
01 VERSION = 1.0.0
02 SOURCE = $(wildcard ./src/*.c)
03 OBJECT = $(patsubst %.c, %.o, $(SOURCE))
04
05 INCLUEDS = -I ./inc
06
07 TARGET = 100ask
08 CC = gcc
09 CFLAGS = -Wall -g
10
11 $(TARGET): $(OBJECT)
12 @mkdir -p output/
13 $(CC) $^ $(CFLAGES) -o output/$(TARGET)_$(VERSION)
14
15 %.o: %.c
16 $(CC) $(INCLUEDS) $(CFLAGES) -c $< -o $@
17
18 .PHONY:clean
19 clean:
20 @rm -rf $(OBJECT) output/
分析:
行1:將版本號賦值給變數VERSION。
行13:生成可執行檔案的字尾新增版本號。
編譯結果:
$ tree
.
├── inc
│ ├── add.h
│ └── sub.h
├── Makefile
├── output
│ └── 100ask_1.0.0
└── src
├── add.c
├── add.o
├── main.c
├── main.o
├── sub.c
└── sub.o