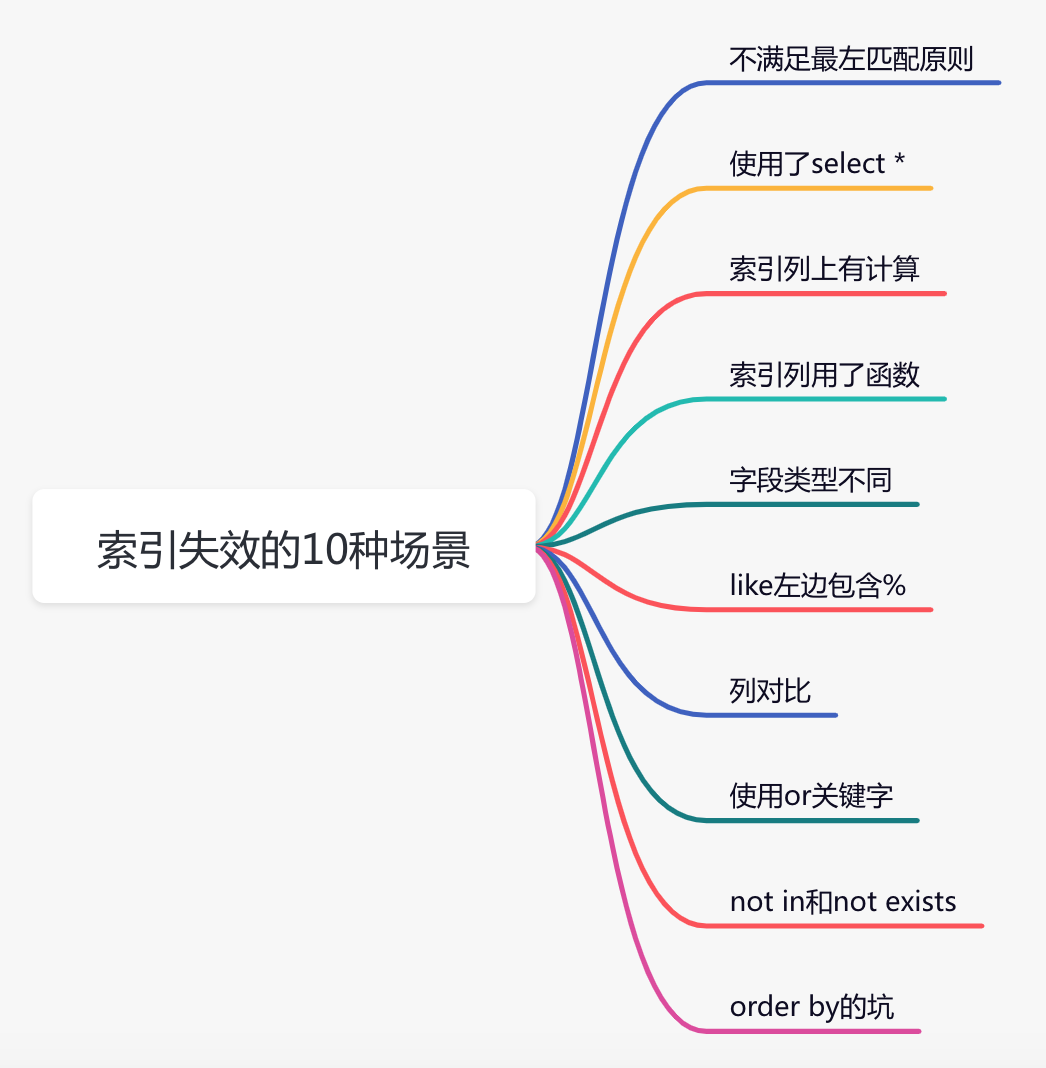
聊聊索引失效的10種場景,巨坑
前言
我之前寫的一篇文章《聊聊sql優化的15個小技巧》,自發表之後,在全網廣受好評,被很多大佬轉載過,說明了這類文章的價值。
今天我接著上一期資料庫的話題,更進一步聊聊索引的相關問題,因為索引是大家都比較關心的公共話題,確實有很多坑。
不知道你在實際工作中,有沒有遇到過下面的這兩種情況:
- 明明在某個欄位上加了索引,但實際上並沒有生效。
- 索引有時候生效了,有時候沒有生效。
最近無意間獲得一份BAT大廠大佬寫的刷題筆記,一下子打通了我的任督二脈,越來越覺得演演算法沒有想象中那麼難了。
今天就跟大家一起聊聊,mysql資料庫索引失效的10種場景,給曾經踩過坑,或者即將要踩坑的朋友們一個參考。
1. 準備工作
所謂空口無憑,如果我直接把索引失效的這些場景丟出來,可能沒有任何說服力。
所以,我決定建表和造資料,給大家一步步演示效果,儘量做到有理有據。
我相信,如果大家耐心的看完這篇文章,一定會有很多收穫的。
1.1 建立user表
建立一張user表,表中包含:id、code、age、name和height欄位。
CREATE TABLE `user` (
`id` int NOT NULL AUTO_INCREMENT,
`code` varchar(20) COLLATE utf8mb4_bin DEFAULT NULL,
`age` int DEFAULT '0',
`name` varchar(30) COLLATE utf8mb4_bin DEFAULT NULL,
`height` int DEFAULT '0',
`address` varchar(30) COLLATE utf8mb4_bin DEFAULT NULL,
PRIMARY KEY (`id`),
KEY `idx_code_age_name` (`code`,`age`,`name`),
KEY `idx_height` (`height`)
) ENGINE=InnoDB AUTO_INCREMENT=4 DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_bin
此外,還建立了三個索引:
id: 資料庫的主鍵idx_code_age_name: 由code、age和name三個欄位組成的聯合索引。idx_height:普通索引
1.2 插入資料
為了方便給大家做演示,我特意向user表中插入了3條資料:
INSERT INTO sue.user (id, code, age, name, height) VALUES (1, '101', 21, '周星馳', 175,'香港');
INSERT INTO sue.user (id, code, age, name, height) VALUES (2, '102', 18, '周杰倫', 173,'臺灣');
INSERT INTO sue.user (id, code, age, name, height) VALUES (3, '103', 23, '蘇三', 174,'成都');
周星馳和周杰倫是我偶像,在這裡自戀了一次,把他們和我放到一起了。哈哈哈。
1.3 檢視資料庫版本
為了防止以後出現不必要的誤會,在這裡有必要查一下當前資料庫的版本。不說版本就直接給結論,是耍流氓,哈哈哈。
select version();
查出當前的mysql版本號為:8.0.21
1.4 檢視執行計劃
在mysql中,如果你想檢視某條sql語句是否使用了索引,或者已建好的索引是否失效,可以通過explain關鍵字,檢視該sql語句的執行計劃,來判斷索引使用情況。
例如:
explain select * from user where id=1;
執行結果:

從圖中可以看出,由於id欄位是主鍵,該sql語句用到了主鍵索引。
當然,如果你想更深入的瞭解explain關鍵字的用法,可以看看我的另一篇文章《explain | 索引優化的這把絕世好劍,你真的會用嗎?》,裡面更為詳細的介紹。
2. 不滿足最左匹配原則
之前我已經給code、age和name這3個欄位建好聯合索引:idx_code_age_name。
該索引欄位的順序是:
- code
- age
- name
如果在使用聯合索引時,沒注意最左字首原則,很有可能導致索引失效喔,不信我們一起往下看。
2.1 哪些情況索引有效?
先看看哪些情況下,能走索引。
explain select * from user
where code='101';
explain select * from user
where code='101' and age=21
explain select * from user
where code='101' and age=21 and name='周星馳';
執行結果:

上面三種情況,sql都能正常走索引。
其實還有一種比較特殊的場景:
explain select * from user
where code = '101' and name='周星馳';
執行結果:

查詢條件原本的順序是:code、age、name,但這裡只有code和name中間斷層了,掉了age欄位,這種情況也能走code欄位上的索引。
看到這裡,不知道聰明的你,有沒有發現這樣一個規律:
這4條sql中都有code欄位,它是索引欄位中的第一個欄位,也就是最左邊的欄位。只要有這個欄位在,該sql已經就能走索引。
這就是我們所說的最左匹配原則。
2.2 哪些情況索引失效?
前面我已經介紹過,建立了聯合索引後,在查詢條件中有哪些情況索引是有效的。
接下來,我們重點看看哪些情況下索引會失效。
explain select * from user
where age=21;
explain select * from user
where name='周星馳';
explain select * from user
where age=21 and name='周星馳';
執行結果:

從圖中看出這3種情況下索引確實失效了。
說明以上3種情況不滿足最左匹配原則,說白了是因為查詢條件中,沒有包含給定欄位最左邊的索引欄位,即欄位code。
3. 使用了select *
在《阿里巴巴開發手冊》中明確說過,查詢sql中禁止使用select * 。
那麼,你知道為什麼嗎?
廢話不多說,按照國際慣例先上一條sql:
explain
select * from user where name='蘇三';
執行結果:

在該sql中用了select *,從執行結果看,走了全表掃描,沒有用到任何索引,查詢效率是非常低的。
如果查詢的時候,只查我們真正需要的列,而不查所有列,結果會怎麼樣?
非常快速的將上面的sql改成只查了code和name列,太easy了:
explain
select code,name from user
where name='蘇三';
執行結果:

從圖中執行結果不難看出,該sql語句這次走了全索引掃描,比全表掃描效率更高。
其實這裡用到了:覆蓋索引。
如果select語句中的查詢列,都是索引列,那麼這些列被稱為覆蓋索引。這種情況下,查詢的相關欄位都能走索引,索引查詢效率相對來說更高一些。
而使用select *查詢所有列的資料,大概率會查詢非索引列的資料,非索引列不會走索引,查詢效率非常低。
4. 索引列上有計算
介紹本章節內容前,先跟大家一起回顧一下,根據id查詢資料的sql語句:
explain select * from user where id=1;
執行結果:
從圖中可以看出,由於id欄位是主鍵,該sql語句用到了主鍵索引。
但如果id列上面有計算,比如:
explain select * from user where id+1=2;
執行結果:

從上圖中的執行結果,能夠非常清楚的看出,該id欄位的主鍵索引,在有計算的情況下失效了。
5. 索引列用了函數
有時候我們在某條sql語句的查詢條件中,需要使用函數,比如:擷取某個欄位的長度。
假如現在有個需求:想查出所有身高是17開頭的人,如果sql語句寫成這樣:
explain select * from user where height=17;
該sql語句確實用到了普通索引:

但該sql語句肯定是有問題的,因為它只能查出身高正好等於17的,但對於174這種情況,它沒辦法查出來。
為了滿足上面的要求,我們需要把sql語句稍稍改造了一下:
explain select * from user where SUBSTR(height,1,2)=17;
這時需要用到SUBSTR函數,用它擷取了height欄位的前面兩位字元,從第一個字元開始。
執行結果:

你有沒有發現,在使用該函數之後,該sql語句竟然走了全表掃描,索引失效了。
6. 欄位型別不同
在sql語句中因為欄位型別不同,而導致索引失效的問題,很容易遇到,可能是我們日常工作中最容易忽略的問題。
到底怎麼回事呢?
請大家注意觀察一下t_user表中的code欄位,它是varchar字元型別的。
在sql語句中查詢資料時,查詢條件我們可以寫成這樣:
explain
select * from user where code="101";
執行結果:

從上圖中看到,該code欄位走了索引。
溫馨提醒一下,查詢字元欄位時,用雙引號
「和單引號'都可以。
但如果你在寫sql時,不小心把引號弄掉了,把sql語句變成了:
explain
select * from user where code=101;
執行結果:

你會驚奇的發現,該sql語句竟然變成了全表掃描。因為少寫了引號,這種小小的失誤,竟然讓code欄位上的索引失效了。
這時你心裡可能有一萬個為什麼,其中有一個肯定是:為什麼索引會失效呢?
答:因為code欄位的型別是varchar,而傳參的型別是int,兩種型別不同。
此外,還有一個有趣的現象,如果int型別的height欄位,在查詢時加了引號條件,卻還可以走索引:
explain select * from user
where height='175';
執行結果:

從圖中看出該sql語句確實走了索引。int型別的引數,不管在查詢時加沒加引號,都能走索引。
這是變魔術嗎?這不科學呀。
答:mysql發現如果是int型別欄位作為查詢條件時,它會自動將該欄位的傳參進行隱式轉換,把字串轉換成int型別。
mysql會把上面列子中的字串175,轉換成數位175,所以仍然能走索引。
接下來,看一個更有趣的sql語句:
select 1 + '1';
它的執行結果是2,還是11呢?
好吧,不賣關子了,直接公佈答案執行結果是2。
mysql自動把字串1,轉換成了int型別的1,然後變成了:1+1=2。
但如果你確實想拼接字串該怎麼辦?
答:可以使用concat關鍵字。
具體拼接sql如下:
select concat(1,'1');
接下來,關鍵問題來了:為什麼字串型別的欄位,傳入了int型別的引數時索引會失效呢?
答:根據mysql官網上解釋,字串’1’、’ 1 '、'1a’都能轉換成int型別的1,也就是說可能會出現多個字串,對應一個int型別引數的情況。那麼,mysql怎麼知道該把int型別的1轉換成哪種字串,用哪個索引快速查值?
感興趣的小夥伴可以再看看官方檔案:https://dev.mysql.com/doc/refman/8.0/en/type-conversion.html
7. like左邊包含%
模糊查詢,在我們日常的工作中,使用頻率還是比較高的。
比如現在有個需求:想查詢姓李的同學有哪些?
使用like語句可以很快的實現:
select * from user where name like '李%';
但如果like用的不好,就可能會出現效能問題,因為有時候它的索引會失效。
不信,我們一起往下看。
目前like查詢主要有三種情況:
- like ‘%a’
- like ‘a%’
- like ‘%a%’
假如現在有個需求:想查出所有code是10開頭的使用者。
這個需求太簡單了吧,sql語句如下:
explain select * from user
where code like '10%';
執行結果:

圖中看出這種%在10右邊時走了索引。
而如果把需求改了:想出現出所有code是1結尾的使用者。
查詢sql語句改為:
explain select * from user
where code like '%1';
執行結果:

從圖中看出這種%在1左邊時,code欄位上索引失效了,該sql變成了全表掃描。
此外,如果出現以下sql:
explain select * from user
where code like '%1%';
該sql語句的索引也會失效。
下面用一句話總結一下規律:當like語句中的%,出現在查詢條件的右邊時,索引會失效。
那麼,為什麼會出現這種現象呢?
答:其實很好理解,索引就像字典中的目錄。一般目錄是按字母或者拼音從小到大,從左到右排序,是有順序的。
我們在查目錄時,通常會先從左邊第一個字母進行匹對,如果相同,再匹對左邊第二個字母,如果再相同匹對其他的字母,以此類推。
通過這種方式我們能快速鎖定一個具體的目錄,或者縮小目錄的範圍。
但如果你硬要跟目錄的設計反著來,先從字典目錄右邊匹配第一個字母,這畫面你可以自行腦補一下,你眼中可能只剩下絕望了,哈哈。
8. 列對比
上面的內容都是常規需求,接下來,來點不一樣的。
假如我們現在有這樣一個需求:過濾出表中某兩列值相同的記錄。比如user表中id欄位和height欄位,查詢出這兩個欄位中值相同的記錄。
這個需求很簡單,sql可以這樣寫:
explain select * from user
where id=height
執行結果:

意不意外,驚不驚喜?索引失效了。
為什麼會出現這種結果?
id欄位本身是有主鍵索引的,同時height欄位也建了普通索引的,並且兩個欄位都是int型別,型別是一樣的。
但如果把兩個單獨建了索引的列,用來做列對比時索引會失效。
感興趣的朋友可以找我私聊。
9. 使用or關鍵字
我們平時在寫查詢sql時,使用or關鍵字的場景非常多,但如果你稍不注意,就可能讓已有的索引失效。
不信一起往下面看。
某天你遇到這樣一個需求:想查一下id=1或者height=175的使用者。
你三下五除二就把sql寫好了:
explain select * from user
where id=1 or height='175';
執行結果:

沒錯,這次確實走了索引,恭喜被你蒙對了,因為剛好id和height欄位都建了索引。
但接下來的一個夜黑風高的晚上,需求改了:除了前面的查詢條件之後,還想加一個address=‘成都’。
這還不簡單,sql走起:
explain select * from user
where id=1 or height='175' or address='成都';
執行結果:

結果悲劇了,之前的索引都失效了。
你可能一臉懵逼,為什麼?我做了什麼?
答:因為你最後加的address欄位沒有加索引,從而導致其他欄位的索引都失效了。
注意:如果使用了
or關鍵字,那麼它前面和後面的欄位都要加索引,不然所有的索引都會失效,這是一個大坑。
10. not in和not exists
在我們日常工作中用得也比較多的,還有範圍查詢,常見的有:
- in
- exists
- not in
- not exists
- between and
今天重點聊聊前面四種。
10.1 in關鍵字
假如我們想查出height在某些範圍之內的使用者,這時sql語句可以這樣寫:
explain select * from user
where height in (173,174,175,176);
執行結果:

從圖中可以看出,sql語句中用in關鍵字是走了索引的。
10.2 exists關鍵字
有時候使用in關鍵字時效能不好,這時就能用exists關鍵字優化sql了,該關鍵字能達到in關鍵字相同的效果:
explain select * from user t1
where exists (select 1 from user t2 where t2.height=173 and t1.id=t2.id)
執行結果:

從圖中可以看出,用exists關鍵字同樣走了索引。
10.3 not in關鍵字
上面演示的兩個例子是正向的範圍,即在某些範圍之內。
那麼反向的範圍,即不在某些範圍之內,能走索引不?
話不多說,先看看使用not in的情況:
explain select * from user
where height not in (173,174,175,176);
執行結果:

你沒看錯,索引失效了。
看如果現在需求改了:想查一下id不等於1、2、3的使用者有哪些,這時sql語句可以改成這樣:
explain select * from user
where id not in (173,174,175,176);
執行結果:

你可能會驚奇的發現,主鍵欄位中使用not in關鍵字查詢資料範圍,任然可以走索引。而普通索引欄位使用了not in關鍵字查詢資料範圍,索引會失效。
10.4 not exists關鍵字
除此之外,如果sql語句中使用not exists時,索引也會失效。具體sql語句如下:
explain select * from user t1
where not exists (select 1 from user t2 where t2.height=173 and t1.id=t2.id)
執行結果:

從圖中看出sql語句中使用not exists關鍵後,t1表走了全表掃描,並沒有走索引。
11. order by的坑
在sql語句中,對查詢結果進行排序是非常常見的需求,一般情況下我們用關鍵字:order by就能搞定。
但我始終覺得order by挺難用的,它跟where或者limit關鍵字有很多千絲萬縷的聯絡,一不小心就會出問題。
Let go
11.1 哪些情況走索引?
首先當然要溫柔一點,一起看看order by的哪些情況可以走索引。
我之前說過,在code、age和name這3個欄位上,已經建了聯合索引:idx_code_age_name。
11.1.1 滿足最左匹配原則
order by後面的條件,也要遵循聯合索引的最左匹配原則。具體有以下sql:
explain select * from user
order by code limit 100;
explain select * from user
order by code,age limit 100;
explain select * from user
order by code,age,name limit 100;
執行結果:

從圖中看出這3條sql都能夠正常走索引。
除了遵循最左匹配原則之外,有個非常關鍵的地方是,後面還是加了limit關鍵字,如果不加它索引會失效。
11.1.2 配合where一起使用
order by還能配合where一起遵循最左匹配原則。
explain select * from user
where code='101'
order by age;
執行結果:

code是聯合索引的第一個欄位,在where中使用了,而age是聯合索引的第二個欄位,在order by中接著使用。
假如中間斷層了,sql語句變成這樣,執行結果會是什麼呢?
explain select * from user
where code='101'
order by name;
執行結果:

雖說name是聯合索引的第三個欄位,但根據最左匹配原則,該sql語句依然能走索引,因為最左邊的第一個欄位code,在where中使用了。只不過order by的時候,排序效率比較低,需要走一次filesort排序罷了。
11.1.3 相同的排序
order by後面如果包含了聯合索引的多個排序欄位,只要它們的排序規律是相同的(要麼同時升序,要麼同時降序),也可以走索引。
具體sql如下:
explain select * from user
order by code desc,age desc limit 100;
執行結果:

該範例中order by後面的code和age欄位都用了降序,所以依然走了索引。
11.1.4 兩者都有
如果某個聯合索引欄位,在where和order by中都有,結果會怎麼樣?
explain select * from user
where code='101'
order by code, name;
執行結果:

code欄位在where和order by中都有,對於這種情況,從圖中的結果看出,還是能走了索引的。
11.2 哪些情況不走索引?
前面介紹的都是正面的用法,是為了讓大家更容易接受下面反面的用法。
好了,接下來,重點聊聊order by的哪些情況下不走索引?
11.2.1 沒加where或limit
如果order by語句中沒有加where或limit關鍵字,該sql語句將不會走索引。
explain select * from user
order by code, name;
執行結果:

從圖中看出索引真的失效了。
11.2.2 對不同的索引做order by
前面介紹的基本都是聯合索引,這一個索引的情況。但如果對多個索引進行order by,結果會怎麼樣呢?
explain select * from user
order by code, height limit 100;
執行結果:
從圖中看出索引也失效了。
11.2.3 不滿足最左匹配原則
前面已經介紹過,order by如果滿足最左匹配原則,還是會走索引。下面看看,不滿足最左匹配原則的情況:
explain select * from user
order by name limit 100;
執行結果:

name欄位是聯合索引的第三個欄位,從圖中看出如果order by不滿足最左匹配原則,確實不會走索引。
11.2.4 不同的排序
前面已經介紹過,如果order by後面有一個聯合索引的多個欄位,它們具有相同排序規則,那麼會走索引。
但如果它們有不同的排序規則呢?
explain select * from user
order by code asc,age desc limit 100;
執行結果:

從圖中看出,儘管order by後面的code和age欄位遵循了最左匹配原則,但由於一個欄位是用的升序,另一個欄位用的降序,最終會導致索引失效。
最近無意間獲得一份BAT大廠大佬寫的刷題筆記,一下子打通了我的任督二脈,越來越覺得演演算法沒有想象中那麼難了。
好了今天分享的內容就先到這裡,我們下期再見。