牛B程式設計師在「建立索引」時都會注意啥?
小夥伴想精準查詢自己想看的MySQL文章?喏 → MySQL專欄目錄 | 點選這裡
不得不說,如何建立索引已經是我們開發人員必須掌握的技能之一了。在設計系統資料表時,你可能會根據具體業務需求,給對應的某個表欄位新增
普通索引或唯一索引;也可能根據最左字首原則、索引下推特性和覆蓋索引,將多個列揉成一個聯合索引來使用。
當同事問我一些建立索引的經驗時,作為一個久經沙場的老程式設計師,我建議儘量讓每條SQL中的where、group by、order by條件都能最大化使用索引。當然,在寫多讀少和讀多寫少的不同場景下使用方式也不盡相同。我們在保證SQL執行效率的同時,還要關注到資料庫對索引檔案的維護成本,從容應對那些常見又很惹人煩的場景諸如:模糊查詢、大文字檢索、超大分頁等。
今天想和大家聊一聊我們在建立索引時需要關注哪方面的問題,避免一手好牌打得稀爛。
專用車票
一、明確索引的優缺點
知己知彼,百戰不殆。想正確的使用索引,首先我們要知道索引的特性以及他的優缺點。
1-1、優點
- 索引大大減小了伺服器需要
掃描的資料量(資料頁) - 索引可以幫助伺服器
避免排序和臨時表 - 索引可以將
隨機I/O變成順序I/O
1-2、缺點
- 雖然索引大大提高了查詢速度,同時卻會
降低更新表的速度,如對錶進行INSERT、UPDATE和DELETE。因為更新表時,MySQL不僅要儲存資料,還要儲存索引檔案。 - 建立索引會佔用磁碟空間的索引檔案。一般情況這個問題不算嚴重,但如果你在一個大表上建立了多種組合索引,且伴隨大量資料量插入,索引檔案大小也會快速膨脹。
- 如果某個資料列包含許多重複的內容,為它建立索引就沒有太大的實際效果。
- 對於非常小的表,大部分情況下簡單的全表掃描更高效;
- 只需為最經常查詢和最經常排序的資料列建立索引。(MySQL裡同一個資料表裡的索引總數上限為16個)

索引的目的是提高查詢效率,和我們在圖書館借書一樣:需先定位到分類區 → 書架 → 書 → 章節 →頁數。圖書館可以看做資料庫,如果將所有資料亂放,相信一天你也找不到你想要的那篇《葵花寶典》。換位思考,其實伺服器也很累,對它好點~
其實索引的本質都是通過不斷地縮小想要獲取資料的範圍來篩選出最終想要的結果,同時把隨機的事件變成順序的事件,也就是說,有了這種索引機制,我們可以高效鎖定某資料的同時,還可以快速定位範圍以及排序工作。
一般應用系統中的讀寫比例會在10:1 ~ 15:1甚至更高,而插入操作和更新刪除操作(我們成為DML操作)很少在效能上出問題,多隻是在事務處理方面。在生產環境中,我們遇到更多的效能問題還是出現在一些複雜的查詢SQL中。因此,對查詢語句的索引優化顯然是重中之重。
說到索引,我們一定要了解他的資料結構以及他的儲存和查詢方式。拿MysQL來說,InnoDB、MyISAM、Memory每個儲存引擎的都有所不同。
二叉排序樹 → 二叉平衡樹 → B-Tree(B樹) → B+Tree(B+樹)
對於MySQL最常用的InnoDB引擎,資料結構為B+Tree,選用B+樹是經歷了漫長的演化(如上),想了解詳細過程的同學可以參考《曾經,我以為我很懂MySQL索引》 ,這裡不再贅述。
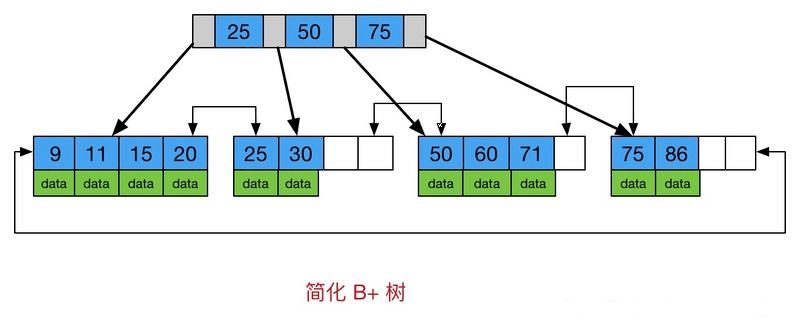
需要說明的是,B+Tree的特性是N叉樹+有序儲存。B+樹的葉子節點間按順序建立了鏈指標,加強了區間存取性,所以B+樹對索引對範圍查詢和排序有天然的優勢。
二、開發中建立索引時要注意哪些(經驗之談)
咱們本文的範例我們構造一張簡單的LOL英雄資訊表,如下:
mysql> select * from t_lol;
+----+--------------+--------------+-------+
| id | hero_title | hero_name | price |
+----+--------------+--------------+-------+
| 1 | 刀鋒之影 | 泰隆 | 6300 |
| 2 | 迅捷斥候 | 提莫 | 6300 |
| 3 | 光輝女郎 | 拉克絲 | 1350 |
| 4 | 發條魔靈 | 奧莉安娜 | 6300 |
| 5 | 至高之拳 | 李青 | 6300 |
| 6 | 無極劍聖 | 易 | 450 |
| 7 | 疾風劍豪 | 亞索 | 6300 |
| 8 | 女槍 | 好運 | 1350 |
+----+--------------+--------------+-------+
8 rows in set (0.00 sec)
2-1、儘量構造覆蓋索引
比如你建立了hero_name,price 的索引 idx_name_price(hero_name,price),查詢資料時使用這種姿勢:
SELECT * from t_lol where hero_name = '亞索' and price = 6300;
由於該索引中只存有hero_name、price和主鍵列,命中索引後,select *的其他欄位怎麼辦呢?資料庫還必須回到聚集索引中通過主鍵查詢其他列資料,這就是回表,這也是你背的那條:少用select * 的原因,他會使SQL錯失對覆蓋索引的使用。
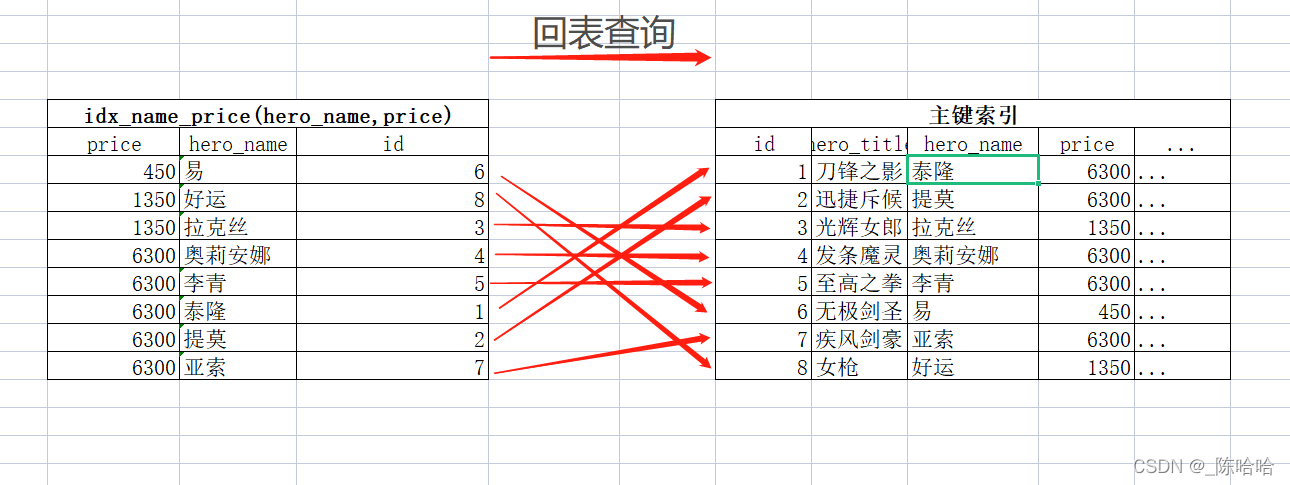
我們通過EXPLAIN檢查一下SQL執行情況,發現雖然使用上了索引,但確實未達到覆蓋索引,發生了回表。當資料量很大時,回表耗時可能會達到覆蓋索引的十倍以上。
mysql> EXPLAIN SELECT * from t_lol where hero_name = '亞索' and price = 6300;
+----+-------------+-------+------------+------+--------------------------+----------------+---------+-------------+------+----------+-------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+-------+------------+------+--------------------------+----------------+---------+-------------+------+----------+-------+
| 1 | SIMPLE | t_lol | NULL | ref | idx_price,idx_name_price | idx_name_price | 136 | const,const | 1 | 100.00 | NULL |
+----+-------------+-------+------------+------+--------------------------+----------------+---------+-------------+------+----------+-------+
1 row in set, 1 warning (0.00 sec)
而如果只查select hero_name,price兩列,或再加上主鍵id這列,都可以使用上覆蓋索引不用再回表。即key=idx_name_price;Extra=Using index;
mysql> EXPLAIN SELECT hero_name,price from t_lol where hero_name = '亞索' and price = 6300;
+----+-------------+-------+------------+------+--------------------------+----------------+---------+-------------+------+----------+-------------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+-------+------------+------+--------------------------+----------------+---------+-------------+------+----------+-------------+
| 1 | SIMPLE | t_lol | NULL | ref | idx_price,idx_name_price | idx_name_price | 136 | const,const | 1 | 100.00 | Using index |
+----+-------------+-------+------------+------+--------------------------+----------------+---------+-------------+------+----------+-------------+
1 row in set, 1 warning (0.00 sec)
2-2、建立複用性強的索引
還是這張t_lol表,如果增加一個高頻介面,通過價格(price)查詢英雄綽號(hero_title),那我們建立的idx_name_price(hero_name,price)索引還能用麼?
mysql> explain select * from t_lol where price =6300;
+----+-------------+-------+------------+------+---------------+------+---------+------+------+----------+-------------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+-------+------------+------+---------------+------+---------+------+------+----------+-------------+
| 1 | SIMPLE | t_lol | NULL | ALL | idx_price | NULL | NULL | NULL | 8 | 62.50 | Using where |
+----+-------------+-------+------------+------+---------------+------+---------+------+------+----------+-------------+
1 row in set, 1 warning (0.00 sec)
key=NULL;Extra=Using where;顯然是沒有用上索引idx_name_price(hero_name,price),因為在MySQL中索引履行最左字首原則。這個最左字首可以是聯合索引的最左X個欄位,也可以是字串索引的最左Y個字元。
最左字首原則
B+樹的節點儲存索引順序是從左向右儲存(說明一下,這個左到右只是說邏輯上的單向有序,並不是左邊和右邊。。別犟),在匹配的時候自然也要滿足從左向右匹配;
通常我們在建立聯合索引的時候,也就是對多個欄位建立索引,相信建立過索引的同學們會發現,無論是Oracle還是 MySQL 都會讓我們選擇索引的順序,比如我們想在a,b,c三個欄位上建立一個聯合索引,我們可以選擇自己想要的優先順序,a、b、c,或者是b、a、c 或者是c、a、b等順序。 為什麼資料庫會讓我們選擇欄位的順序呢?不都是三個欄位的聯合索引麼?這裡就引出了資料庫索引的最左字首原理。
在我們開發中經常會遇到明明這個欄位建了聯合索引,但是SQL查詢該欄位時卻不會使用索引的問題。比如索引abc_index:(a,b,c)是a,b,c三個欄位的聯合索引,下列sql執行時都無法命中索引abc_index的;
select * from table where c = '1';
select * from table where b ='1' and c ='2';
以下三種情況卻會走索引:
select * from table where a = '1';
select * from table where a = '1' and b = '2';
select * from table where a = '1' and b = '2' and c='3';
從上面兩個例子大家是否闊以看出點眉目?
是的,索引abc_index:(a,b,c),只會在(a)、(a,b)、(a,b,c) 三種型別的查詢中使用。其實這裡說的有一點歧義,其實(a,c)也會走,但是隻走a欄位索引,不會走c欄位。
另外還有一個特殊情況說明下,下面這種型別的也只會有 a與b 走索引,c不會走。
select * from table where a = '1' and b > '2' and c='3';
像上面這種型別的sql語句,在a、b走完索引後,c已經是無序了,所以c就沒法走索引,優化器會認為還不如全表掃描c欄位來的快。
最左字首:顧名思義,就是最左優先,上例中我們建立了a_b_c多列索引,相當於建立了(a)單列索引,(a,b)組合索引以及(a,b,c)組合索引。
因此,在建立多列索引時,要根據業務需求,where子句中使用最頻繁的一列放在最左邊。
我們明白最左字首原則後發現,根本無法做到讓每個請求都最大化利用到索引,總不能一個介面就加一個索引吧?
mysql> select * from t_lol;
+----+--------------+--------------+-------+
| id | hero_title | hero_name | price |
+----+--------------+--------------+-------+
| 1 | 刀鋒之影 | 泰隆 | 6300 |
| 2 | 迅捷斥候 | 提莫 | 6300 |
| 3 | 光輝女郎 | 拉克絲 | 1350 |
| 4 | 發條魔靈 | 奧莉安娜 | 6300 |
| 5 | 至高之拳 | 李青 | 6300 |
| 6 | 無極劍聖 | 易 | 450
| 7 | 疾風劍豪 | 亞索 | 6300 |
| 8 | 女槍 | 好運 | 1350 |
+----+--------------+--------------+-------+
8 rows in set (0.00 sec)
回到我們上面提到的問題,如果有一個高頻介面:通過價格(price)查詢英雄綽號(hero_title),那我豈不是還要新建一個單獨的index(price)索引?
其實這裡引出了一個問題,在建立聯合索引的時候,如何安排索在引內的欄位順序? 也就是索引的複用能力。
因為可以支援最左字首,所以當已經有了idx_name_price(hero_name,price)這個聯合索引後,一般就不需要單獨在hero_name上建立索引了。但單獨查price時是無法使用該聯合索引的,那麼如果要使用該索引還能滿足通過price列查詢的需求。怎麼辦?正如你所想的,修改索引列順序。
因此,第一原則是,如果通過調整順序,可第以少維護一個索引,那麼這個順序往往就是需要優先考慮採用的。
所以你應該知道,這段開頭的問題裡,我們既要為高頻請求建立(price,hero_name)這個聯合索引,並用這個索引支援根據price查詢hero_title的需求。 那麼我們只需將聯合索引順序修改為 idx_name_price(price,hero_name)即可。

2-3、索引不是越多越好
很顯然,我們在文章前面提到的索引缺點處就做出了說明,索引是把雙刃劍,提高查詢效率的同時還需要使用資料庫中大量資源去維護他。越來越大的索引檔案、越來越慢的DML操作都是需要考慮的後果。
因此我們在建立索引時需要根據實際場景的需求,是讀多寫少還是讀少寫多?資料量建立索引的必要性?索引的硬傷?等。
有同學問我資料量少時(幾十條?)建立索引和不建立索引查詢效率和維護成本上會有多少區別?
搞得我一時不知道怎麼回答。。作為一名老程式設計師,建議大家把眼光放長遠些,別在這種問題上花太多時間研究。只能說是,如果有業務會使用到,建議都按照我們開發時建立索引的規範來建立,後續總會用得上。資料少索引維護成本也可以忽略不計,別留坑就行。
2-4、使用索引的一些暖心建議
1、索引不會包含有null值的列
只要列中包含有null值都將不會被包含在索引中,複合索引中只要有一列含有null值,那麼這一列對於此複合索引就是無效的。所以我們在資料庫設計時建議不要讓欄位的預設值為null。
2、使用短索引
對串列進行索引,如果可能應該指定一個字首長度。例如,如果有一個char(255)的列,如果在前10個或20個字元內,多數值是惟一的,那麼就不要對整個列進行索引。短索引不僅可以提高查詢速度而且可以節省磁碟空間和I/O操作。
3、索引列排序
查詢只使用一個索引,因此如果where子句中已經使用了索引的話,那麼order by中的列是不會使用索引的。因此資料庫預設排序可以符合要求的情況下不要使用排序操作;儘量不要包含多個列的排序,如果需要最好給這些列建立複合索引。
4、like語句操作
一般情況下不推薦使用like操作,如果非使用不可,如何使用也是一個問題。like %陳% 不會使用索引而like 陳%可以使用索引。
5、不要在列上進行運算
這將導致索引失效而進行全表掃描,例如
SELECT * FROM table_name WHERE YEAR(column_name)<2017;
6、不使用not in和<>這類非集操作
這不屬於支援的範圍查詢條件,不會使用索引。
總結
在我們實際操作索引前,建議根據實際需求,結合搜尋引擎索引特性,先設計好每張表的索引型別和結構,儘量避免邊寫邊改。資料量劇增後再想修改索引是很麻煩的,需要很長的修改時間,且修改時會鎖表。對了,千萬不要隨意修改線上庫的索引,別問我為什麼,一個字:疼~~
快過年了,過年得有過年得態度,有啥事兒,明年再說吧~~
