【轉】BAT機器學習面試1000題系列(1~50)
BAT機器學習面試1000題系列
整理:July、元超、立娜、德偉、賈茹、王劍、AntZ、孟瑩等眾人。本系列大部分題目來源於公開網路,取之分享,用之分享,且在撰寫答案過程中若參照他人解析則必註明原作者及來源連結。另,不少答案得到寒小陽、管博士、張雨石、王贇、褚博士等七月線上名師審校。
說明:本系列作為國內首個AI題庫,首發於七月線上實驗室公眾號上:julyedulab,並部分更新於本部落格上,且已於17年雙十二當天上線七月線上官網、七月線上Android APP、七月線上iPhone APP,後本文暫停更新和維護,另外的近3000道題都已更新到七月線上APP或七月線上官網題庫板塊上,歡迎天天刷題。另,可以轉載,註明來源連結即可。
前言
July我又回來了。
之前本部落格整理過數千道微軟等公司的面試題,側重資料結構、演演算法、海量資料處理,詳見:微軟面試100題系列,今17年,近期和團隊整理BAT機器學習面試1000題系列,側重機器學習、深度學習。我們將通過這個系列索引絕大部分機器學習和深度學習的筆試面試題、知識點,它將更是一個足夠龐大的機器學習和深度學習面試庫/知識庫,通俗成體系且循序漸進。
此外,有四點得強調下:
- 雖然本系列主要是機器學習、深度學習相關的考題,其他型別的題不多,但不代表應聘機器學習或深度學習的崗位時,公司或面試官就只問這兩項,雖說是做資料或AI相關,但基本的語言(比如Python)、編碼coding能力(對於開發,編碼coding能力怎麼強調都不過分,比如最簡單的手寫快速排序、手寫二分查詢)、資料結構、演演算法、電腦架構、作業系統、概率統計等等也必須掌握。對於資料結構和演演算法,一者 重點推薦前面說的微軟面試100題系列(後來這個系列整理成了新書《程式設計之法:面試和演演算法心得》),二者 多刷leetcode,看1000道題不如實際動手刷100道。
- 本系列會盡量讓考察同一個部分(比如同是模型/演演算法相關的)、同一個方向(比如同是屬於最佳化的演演算法)的題整理到一塊,為的是讓大家做到舉一反三、構建完整知識體系,在準備筆試面試的過程中,通過懂一題懂一片。
- 本系列每一道題的答案都會確保邏輯清晰、通俗易懂(當你學習某個知識點感覺學不懂時,十有八九不是你不夠聰明,十有八九是你所看的資料不夠通俗、不夠易懂),如有更好意見,歡迎在評論下共同探討。
- 關於如何學習機器學習,最推薦機器學習集訓營系列。從Python基礎、資料分析、爬蟲,到資料視覺化、spark巨量資料,最後實戰機器學習、深度學習等一應俱全。
另,本系列會長久更新,直到上千道、甚至數千道題,歡迎各位於評論下留言分享你在自己筆試面試中遇到的題,或你在網上看到或收藏的題,共同分享幫助全球更多人,thanks。
限於篇幅,完整版可以掃碼領取,新增時備註:領取面經100篇

BAT機器學習面試1000題系列
1 請簡要介紹下SVM,機器學習 ML模型 易SVM,全稱是support vector machine,中文名叫支援向量機。SVM是一個面向資料的分類演演算法,它的目標是為確定一個分類超平面,從而將不同的資料分隔開。
擴充套件:這裡有篇文章詳盡介紹了SVM的原理、推導,《
支援向量機通俗導論(理解SVM的三層境界)》。此外,這裡有個視訊也是關於SVM的推導:《純白板手推SVM》
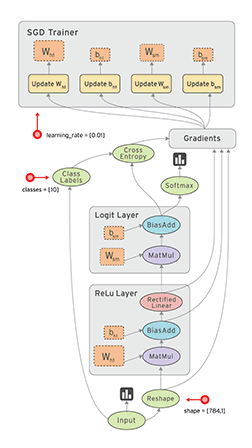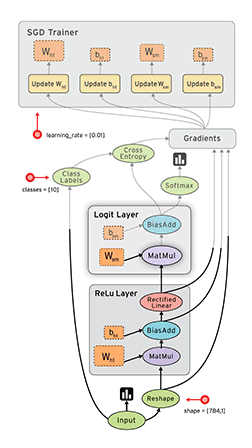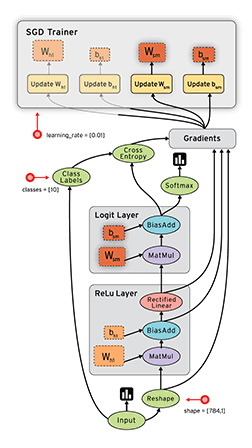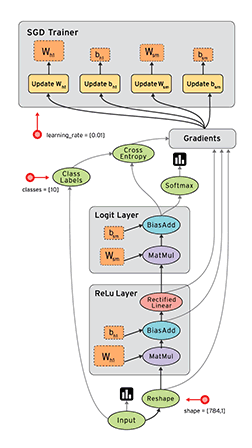
2 請簡要介紹下tensorflow的計算圖,深度學習 DL框架 中
@寒小陽&AntZ:Tensorflow是一個通過計算圖的形式來表述計算的程式設計系統,計算圖也叫資料流圖,可以把計算圖看做是一種有向圖,Tensorflow中的每一個節點都是計算圖上的一個Tensor, 也就是張量,而節點之間的邊描述了計算之間的依賴關係(定義時)和數學操作(運算時)。如下兩圖表示:
a=x*y; b=a+z; c=tf.reduce_sum(b);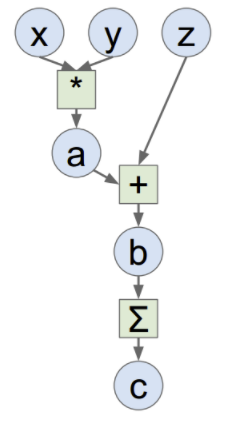
3 在k-means或kNN,我們常用歐氏距離來計算最近的鄰居之間的距離,有時也用曼哈頓距離,請對比下這兩種距離的差別。機器學習 ML模型 中
歐氏距離,最常見的兩點之間或多點之間的距離表示法,又稱之為歐幾里得度量,它定義於歐幾里得空間中,如點 x = (x1,...,xn) 和 y = (y1,...,yn) 之間的距離為: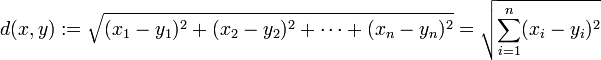
歐氏距離雖然很有用,但也有明顯的缺點。它將樣品的不同屬性(即各指標或各變數量綱)之間的差別等同看待,這一點有時不能滿足實際要求。例如,在教育研究中,經常遇到對人的分析和判別,個體的不同屬性對於區分個體有著不同的重要性。因此,歐氏距離適用於向量各分量的度量標準統一的情況。
- 曼哈頓距離,我們可以定義曼哈頓距離的正式意義為L1-距離或城市區塊距離,也就是在歐幾里得空間的固定直角座標系上兩點所形成的線段對軸產生的投影的距離總和。例如在平面上,座標(x1, y1)的點P1與座標(x2, y2)的點P2的曼哈頓距離為:
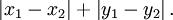 ,要注意的是,曼哈頓距離依賴座標系統的轉度,而非系統在座標軸上的平移或對映。當座標軸變動時,點間的距離就會不同。
,要注意的是,曼哈頓距離依賴座標系統的轉度,而非系統在座標軸上的平移或對映。當座標軸變動時,點間的距離就會不同。
通俗來講,想象你在曼哈頓要從一個十字路口開車到另外一個十字路口,駕駛距離是兩點間的直線距離嗎?顯然不是,除非你能穿越大樓。而實際駕駛距離就是這個「曼哈頓距離」,這也是曼哈頓距離名稱的來源, 同時,曼哈頓距離也稱為城市街區距離(City Block distance)。
曼哈頓距離和歐式距離一般用途不同,無相互替代性。另,關於各種距離的比較參看《從K近鄰演演算法、距離度量談到KD樹、SIFT+BBF演演算法》。
4 CNN的折積核是單層的還是多層的?深度學習 DL模型 中
@AntZ:折積運算的定義和理解可以看下這篇文章《CNN筆記:通俗理解折積神經網路》,連結:http://blog.csdn.net/v_july_v/article/details/51812459,在CNN中,折積計算屬於離散折積, 本來需要折積核的權重矩陣旋轉180度, 但我們並不需要旋轉前的權重矩陣形式, 故直接用旋轉後權重矩陣作為折積核表達, 這樣的好處就離散折積運算變成了矩陣點積運算。
一般而言,深度折積網路是一層又一層的。層的本質是特徵圖, 存貯輸入資料或其中間表示值。一組折積核則是聯絡前後兩層的網路參數列達體, 訓練的目標就是每個折積核的權重引陣列。
描述網路模型中某層的厚度,通常用名詞通道channel數或者特徵圖feature map數。不過人們更習慣把作為資料輸入的前層的厚度稱之為通道數(比如RGB三色圖層稱為輸入通道數為3),把作為折積輸出的後層的厚度稱之為特徵圖數。
折積核(filter)一般是3D多層的,除了面積引數, 比如3x3之外, 還有厚度引數H(2D的視為厚度1). 還有一個屬性是折積核的個數N。
折積核的厚度H, 一般等於前層厚度M(輸入通道數或feature map數). 特殊情況M > H。
折積核的個數N, 一般等於後層厚度(後層feature maps數,因為相等所以也用N表示)。
折積核通常從屬於後層,為後層提供了各種檢視前層特徵的視角,這個視角是自動形成的。
折積核厚度等於1時為2D折積,也就是平面對應點分別相乘然後把結果加起來,相當於點積運算. 各種2D折積動圖可以看這裡https://github.com/vdumoulin/conv_arithmetic
折積核厚度大於1時為3D折積(depth-wise),每片平面分別求2D折積,然後把每片折積結果加起來,作為3D折積結果;1x1折積屬於3D折積的一個特例(point-wise),有厚度無面積, 直接把每層單個點相乘再相加。
歸納之,折積的意思就是把一個區域,不管是一維線段,二維方陣,還是三維長方塊,全部按照折積核的維度形狀,從輸入挖出同樣維度形狀, 對應逐點相乘後求和,濃縮成一個標量值也就是降到零維度,作為輸出到一個特徵圖的一個點的值. 這個很像漁夫收網。
可以比喻一群漁夫坐一個漁船撒網打魚,魚塘是多層水域,每層魚兒不同。
船每次移位一個stride到一個地方,每個漁夫撒一網,得到收穫,然後換一個距離stride再撒,如此重複直到遍歷魚塘。
A漁夫盯著魚的品種,遍歷魚塘後該漁夫描繪了魚塘的魚品種分佈;
B漁夫盯著魚的重量,遍歷魚塘後該漁夫描繪了魚塘的魚重量分佈;
還有N-2個漁夫,各自興趣各幹各的;
最後得到N個特徵圖,描述了魚塘的一切!
2D折積表示漁夫的網就是帶一圈浮標的漁網,只打上面一層水體的魚;
3D折積表示漁夫的網是多層巢狀的漁網,上中下層水體的魚兒都跑不掉;
1x1折積可以視為每次移位stride,甩鉤釣魚代替了撒網;
下面解釋一下特殊情況的 M > H:
實際上,除了輸入資料的通道數比較少之外,中間層的feature map數很多,這樣中間層算折積會累死計算機(魚塘太深,每層魚都打,需要的魚網太重了)。所以很多深度折積網路把全部通道/特徵圖劃分一下,每個折積核只看其中一部分(漁夫A的漁網只打撈深水段,漁夫B的漁網只打撈淺水段)。這樣整個深度網路架構是橫向開始分道揚鑣了,到最後才又融合。這樣看來,很多網路模型的架構不完全是突發奇想,而是是被引數計算量逼得。特別是現在需要在移動裝置上進行AI應用計算(也叫推斷), 模型引數規模必須更小, 所以出現很多減少握手規模的折積形式, 現在主流網路架構大都如此。比如AlexNet: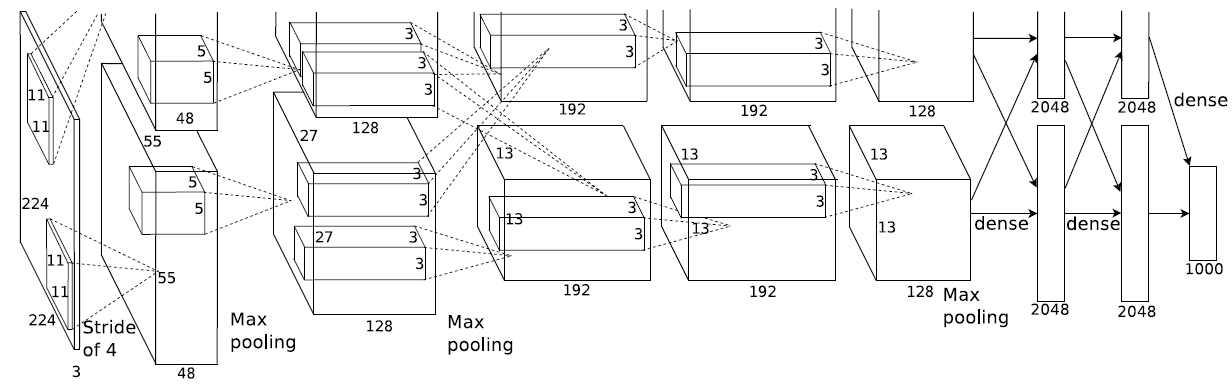
另,附百度2015校招機器學習筆試題:http://www.itmian4.com/thread-7042-1-1.html
5關於LR。機器學習 ML模型 難
@rickjin:把LR從頭到腳都給講一遍。建模,現場數學推導,每種解法的原理,正則化,LR和maxent模型啥關係,lr為啥比線性迴歸好。有不少會背答案的人,問邏輯細節就糊塗了。原理都會? 那就問工程,並行化怎麼做,有幾種並行化方式,讀過哪些開源的實現。還會,那就準備收了吧,順便逼問LR模型發展歷史。
另外,這兩篇文章可以做下參考:Logistic Regression 的前世今生(理論篇)、機器學習演演算法與Python實踐之(七)邏輯迴歸(Logistic Regression)。
6 overfitting怎麼解決?機器學習 ML基礎 中
dropout、regularization、batch normalizatin
@AntZ: overfitting就是過擬合, 其直觀的表現如下圖所示,隨著訓練過程的進行,模型複雜度增加,在training data上的error漸漸減小,但是在驗證集上的error卻反而漸漸增大——因為訓練出來的網路過擬合了訓練集, 對訓練集外的資料卻不work, 這稱之為泛化(generalization)效能不好。泛化效能是訓練的效果評價中的首要目標,沒有良好的泛化,就等於南轅北轍, 一切都是無用功。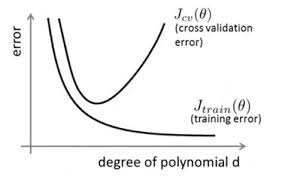
過擬合是泛化的反面,好比鄉下快活的劉姥姥進了大觀園會各種不適應,但受過良好教育的林黛玉進賈府就不會大驚小怪。實際訓練中, 降低過擬合的辦法一般如下:
正則化(Regularization)
L2正則化:目標函數中增加所有權重w引數的平方之和, 逼迫所有w儘可能趨向零但不為零. 因為過擬合的時候, 擬合函數需要顧忌每一個點, 最終形成的擬合函數波動很大, 在某些很小的區間裡, 函數值的變化很劇烈, 也就是某些w非常大. 為此, L2正則化的加入就懲罰了權重變大的趨勢.
L1正則化:目標函數中增加所有權重w引數的絕對值之和, 逼迫更多w為零(也就是變稀疏. L2因為其導數也趨0, 奔向零的速度不如L1給力了). 大家對稀疏規則化趨之若鶩的一個關鍵原因在於它能實現特徵的自動選擇。一般來說,xi的大部分元素(也就是特徵)都是和最終的輸出yi沒有關係或者不提供任何資訊的,在最小化目標函數的時候考慮xi這些額外的特徵,雖然可以獲得更小的訓練誤差,但在預測新的樣本時,這些沒用的特徵權重反而會被考慮,從而干擾了對正確yi的預測。稀疏規則化運算元的引入就是為了完成特徵自動選擇的光榮使命,它會學習地去掉這些無用的特徵,也就是把這些特徵對應的權重置為0。
隨機失活(dropout)
在訓練的執行的時候,讓神經元以超引數p的概率被啟用(也就是1-p的概率被設定為0), 每個w因此隨機參與, 使得任意w都不是不可或缺的, 效果類似於數量巨大的模型整合。
逐層歸一化(batch normalization)
這個方法給每層的輸出都做一次歸一化(網路上相當於加了一個線性變換層), 使得下一層的輸入接近高斯分佈. 這個方法相當於下一層的w訓練時避免了其輸入以偏概全, 因而泛化效果非常好.
提前終止(early stopping)
理論上可能的區域性極小值數量隨引數的數量呈指數增長, 到達某個精確的最小值是不良泛化的一個來源. 實踐表明, 追求細粒度極小值具有較高的泛化誤差。這是直觀的,因為我們通常會希望我們的誤差函數是平滑的, 精確的最小值處所見相應誤差曲面具有高度不規則性, 而我們的泛化要求減少精確度去獲得平滑最小值, 所以很多訓練方法都提出了提前終止策略. 典型的方法是根據交叉叉驗證提前終止: 若每次訓練前, 將訓練資料劃分為若干份, 取一份為測試集, 其他為訓練集, 每次訓練完立即拿此次選中的測試集自測. 因為每份都有一次機會當測試集, 所以此方法稱之為交叉驗證. 交叉驗證的錯誤率最小時可以認為泛化效能最好, 這時候訓練錯誤率雖然還在繼續下降, 但也得終止繼續訓練了.
7 LR和SVM的聯絡與區別。機器學習 ML模型 中
@朝陽在望,聯絡:
1、LR和SVM都可以處理分類問題,且一般都用於處理線性二分類問題(在改進的情況下可以處理多分類問題)
2、兩個方法都可以增加不同的正則化項,如l1、l2等等。所以在很多實驗中,兩種演演算法的結果是很接近的。
區別:
1、LR是引數模型,SVM是非引數模型。
2、從目標函數來看,區別在於邏輯迴歸採用的是logistical loss,SVM採用的是hinge loss,這兩個損失函數的目的都是增加對分類影響較大的資料點的權重,減少與分類關係較小的資料點的權重。
3、SVM的處理方法是隻考慮support vectors,也就是和分類最相關的少數點,去學習分類器。而邏輯迴歸通過非線性對映,大大減小了離分類平面較遠的點的權重,相對提升了與分類最相關的資料點的權重。
4、邏輯迴歸相對來說模型更簡單,好理解,特別是大規模線性分類時比較方便。而SVM的理解和優化相對來說複雜一些,SVM轉化為對偶問題後,分類只需要計算與少數幾個支援向量的距離,這個在進行復雜核函數計算時優勢很明顯,能夠大大簡化模型和計算。
5、logic 能做的 svm能做,但可能在準確率上有問題,svm能做的logic有的做不了。
來源:http://blog.csdn.net/timcompp/article/details/62237986
8 說說你知道的核函數。機器學習 ML基礎 易
通常人們會從一些常用的核函數中選擇(根據問題和資料的不同,選擇不同的引數,實際上就是得到了不同的核函數),例如:
- 多項式核,顯然剛才我們舉的例子是這裡多項式核的一個特例(R = 1,d = 2)。雖然比較麻煩,而且沒有必要,不過這個核所對應的對映實際上是可以寫出來的,該空間的維度是
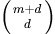 ,其中
,其中 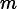 是原始空間的維度。
是原始空間的維度。 - 高斯核
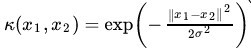 ,這個核就是最開始提到過的會將原始空間對映為無窮維空間的那個傢伙。不過,如果
,這個核就是最開始提到過的會將原始空間對映為無窮維空間的那個傢伙。不過,如果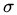 選得很大的話,高次特徵上的權重實際上衰減得非常快,所以實際上(數值上近似一下)相當於一個低維的子空間;反過來,如果選得很小,則可以將任意的資料對映為線性可分——當然,這並不一定是好事,因為隨之而來的可能是非常嚴重的過擬合問題。不過,總的來說,通過調控引數,高斯核實際上具有相當高的靈活性,也是使用最廣泛的核函數之一。下圖所示的例子便是把低維線性不可分的資料通過高斯核函數對映到了高維空間:
選得很大的話,高次特徵上的權重實際上衰減得非常快,所以實際上(數值上近似一下)相當於一個低維的子空間;反過來,如果選得很小,則可以將任意的資料對映為線性可分——當然,這並不一定是好事,因為隨之而來的可能是非常嚴重的過擬合問題。不過,總的來說,通過調控引數,高斯核實際上具有相當高的靈活性,也是使用最廣泛的核函數之一。下圖所示的例子便是把低維線性不可分的資料通過高斯核函數對映到了高維空間: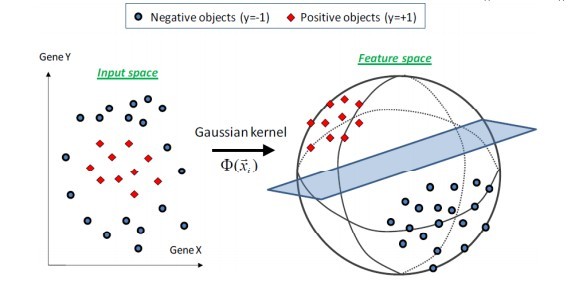
- 線性核
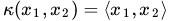 ,這實際上就是原始空間中的內積。這個核存在的主要目的是使得「對映後空間中的問題」和「對映前空間中的問題」兩者在形式上統一起來了(意思是說,咱們有的時候,寫程式碼,或寫公式的時候,只要寫個模板或通用表示式,然後再代入不同的核,便可以了,於此,便在形式上統一了起來,不用再分別寫一個線性的,和一個非線性的)。
,這實際上就是原始空間中的內積。這個核存在的主要目的是使得「對映後空間中的問題」和「對映前空間中的問題」兩者在形式上統一起來了(意思是說,咱們有的時候,寫程式碼,或寫公式的時候,只要寫個模板或通用表示式,然後再代入不同的核,便可以了,於此,便在形式上統一了起來,不用再分別寫一個線性的,和一個非線性的)。
9 LR與線性迴歸的區別與聯絡。機器學習 ML模型 中等
@AntZ: LR工業上一般指Logistic Regression(邏輯迴歸)而不是Linear Regression(線性迴歸). LR線上性迴歸的實數範圍輸出值上施加sigmoid函數將值收斂到0~1範圍, 其目標函數也因此從差平方和函數變為對數損失函數, 以提供最佳化所需導數(sigmoid函數是softmax函數的二元特例, 其導數均為函數值的f*(1-f)形式)。請注意, LR往往是解決二元0/1分類問題的, 只是它和線性迴歸耦合太緊, 不自覺也冠了個迴歸的名字(馬甲無處不在). 若要求多元分類,就要把sigmoid換成大名鼎鼎的softmax了。
@nishizhen:個人感覺邏輯迴歸和線性迴歸首先都是廣義的線性迴歸,
其次經典線性模型的優化目標函數是最小二乘,而邏輯迴歸則是似然函數,
另外線性迴歸在整個實數域範圍內進行預測,敏感度一致,而分類範圍,需要在[0,1]。邏輯迴歸就是一種減小預測範圍,將預測值限定為[0,1]間的一種迴歸模型,因而對於這類問題來說,邏輯迴歸的魯棒性比線性迴歸的要好。
@乖乖癩皮狗:邏輯迴歸的模型本質上是一個線性迴歸模型,邏輯迴歸都是以線性迴歸為理論支援的。但線性迴歸模型無法做到sigmoid的非線性形式,sigmoid可以輕鬆處理0/1分類問題。
10 請問(決策樹、Random Forest、Booting、Adaboot)GBDT和XGBoost的區別是什麼?機器學習 ML模型 難
@AntZ
整合學習的整合物件是學習器. Bagging和Boosting屬於整合學習的兩類方法. Bagging方法有放回地取樣同數量樣本訓練每個學習器, 然後再一起整合(簡單投票); Boosting方法使用全部樣本(可調權重)依次訓練每個學習器, 迭代整合(平滑加權).
決策樹屬於最常用的學習器, 其學習過程是從根建立樹, 也就是如何決策葉子節點分裂. ID3/C4.5決策樹用資訊熵計算最優分裂, CART決策樹用基尼指數計算最優分裂, xgboost決策樹使用二階泰勒展開係數計算最優分裂.
下面所提到的學習器都是決策樹:
Bagging方法:
學習器間不存在強依賴關係, 學習器可並行訓練生成, 整合方式一般為投票;
Random Forest屬於Bagging的代表, 放回抽樣, 每個學習器隨機選擇部分特徵去優化;
Boosting方法:
學習器之間存在強依賴關係、必須序列生成, 整合方式為加權和;
Adaboost屬於Boosting, 採用指數損失函數替代原本分類任務的0/1損失函數;
GBDT屬於Boosting的優秀代表, 對函數殘差近似值進行梯度下降, 用CART迴歸樹做學習器, 整合為迴歸模型;
xgboost屬於Boosting的集大成者, 對函數殘差近似值進行梯度下降, 迭代時利用了二階梯度資訊, 整合模型可分類也可迴歸. 由於它可在特徵粒度上平行計算, 結構風險和工程實現都做了很多優化, 泛化, 效能和擴充套件性都比GBDT要好。
關於決策樹,這裡有篇《決策樹演演算法》。而隨機森林Random Forest是一個包含多個決策樹的分類器。至於AdaBoost,則是英文"Adaptive Boosting"(自適應增強)的縮寫,關於AdaBoost可以看下這篇文章《Adaboost 演演算法的原理與推導》。GBDT(Gradient Boosting Decision Tree),即梯度上升決策樹演演算法,相當於融合決策樹和梯度上升boosting演演算法。
@Xijun LI:xgboost類似於gbdt的優化版,不論是精度還是效率上都有了提升。與gbdt相比,具體的優點有:
1.損失函數是用泰勒展式二項逼近,而不是像gbdt裡的就是一階導數
2.對樹的結構進行了正則化約束,防止模型過度複雜,降低了過擬合的可能性
3.節點分裂的方式不同,gbdt是用的gini係數,xgboost是經過優化推導後的
更多詳見:https://xijunlee.github.io/2017/06/03/%E9%9B%86%E6%88%90%E5%AD%A6%E4%B9%A0%E6%80%BB%E7%BB%93/
11 為什麼xgboost要用泰勒展開,優勢在哪裡?機器學習 ML模型 難
@AntZ:xgboost使用了一階和二階偏導, 二階導數有利於梯度下降的更快更準. 使用泰勒展開取得函數做自變數的二階導數形式, 可以在不選定損失函數具體形式的情況下, 僅僅依靠輸入資料的值就可以進行葉子分裂優化計算, 本質上也就把損失函數的選取和模型演演算法優化/引數選擇分開了. 這種去耦合增加了xgboost的適用性, 使得它按需選取損失函數, 可以用於分類, 也可以用於迴歸。
12 xgboost如何尋找最優特徵?是又放回還是無放回的呢?機器學習 ML模型 難
@AntZ:xgboost在訓練的過程中給出各個特徵的增益評分,最大增益的特徵會被選出來作為分裂依據, 從而記憶了每個特徵對在模型訓練時的重要性 -- 從根到葉子中間節點涉及某特徵的次數作為該特徵重要性排序.
xgboost屬於boosting整合學習方法, 樣本是不放回的, 因而每輪計算樣本不重複. 另一方面, xgboost支援子取樣, 也就是每輪計算可以不使用全部樣本, 以減少過擬合. 進一步地, xgboost 還有列取樣, 每輪計算按百分比隨機取樣一部分特徵, 既提高計算速度又減少過擬合。
13 談談判別式模型和生成式模型?機器學習 ML基礎 易
判別方法:由資料直接學習決策函數 Y = f(X),或者由條件分佈概率 P(Y|X)作為預測模型,即判別模型。
生成方法:由資料學習聯合概率密度分佈函數 P(X,Y),然後求出條件概率分佈P(Y|X)作為預測的模型,即生成模型。
由生成模型可以得到判別模型,但由判別模型得不到生成模型。
常見的判別模型有:K近鄰、SVM、決策樹、感知機、線性判別分析(LDA)、線性迴歸、傳統的神經網路、邏輯斯蒂迴歸、boosting、條件隨機場
常見的生成模型有:樸素貝葉斯、隱馬爾可夫模型、高斯混合模型、檔案主題生成模型(LDA)、限制玻爾茲曼機L1和L2的區別。機器學習 ML基礎 易
L1範數(L1 norm)是指向量中各個元素絕對值之和,也有個美稱叫「稀疏規則運算元」(Lasso regularization)。
比如 向量A=[1,-1,3], 那麼A的L1範數為 |1|+|-1|+|3|.
簡單總結一下就是:
L1範數: 為x向量各個元素絕對值之和。
L2範數: 為x向量各個元素平方和的1/2次方,L2範數又稱Euclidean範數或者Frobenius範數
Lp範數: 為x向量各個元素絕對值p次方和的1/p次方.
在支援向量機學習過程中,L1範數實際是一種對於成本函數求解最優的過程,因此,L1範數正則化通過向成本函數中新增L1範數,使得學習得到的結果滿足稀疏化,從而方便人類提取特徵。
L1範數可以使權值稀疏,方便特徵提取。
L2範數可以防止過擬合,提升模型的泛化能力。
@AntZ: L1和L2的差別,為什麼一個讓絕對值最小,一個讓平方最小,會有那麼大的差別呢?看導數一個是1一個是w便知, 在靠進零附近, L1以勻速下降到零, 而L2則完全停下來了. 這說明L1是將不重要的特徵(或者說, 重要性不在一個數量級上)儘快剔除, L2則是把特徵貢獻儘量壓縮最小但不至於為零. 兩者一起作用, 就是把重要性在一個數量級(重要性最高的)的那些特徵一起平等共事(簡言之, 不養閒人也不要超人)。
14 L1和L2正則先驗分別服從什麼分佈。機器學習 ML基礎 易
@齊同學:面試中遇到的,L1和L2正則先驗分別服從什麼分佈,L1是拉普拉斯分佈,L2是高斯分佈。
@AntZ: 先驗就是優化的起跑線, 有先驗的好處就是可以在較小的資料集中有良好的泛化效能,當然這是在先驗分佈是接近真實分佈的情況下得到的了,從資訊理論的角度看,向系統加入了正確先驗這個資訊,肯定會提高系統的效能。
對引數引入高斯正態先驗分佈相當於L2正則化, 這個大家都熟悉: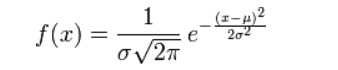
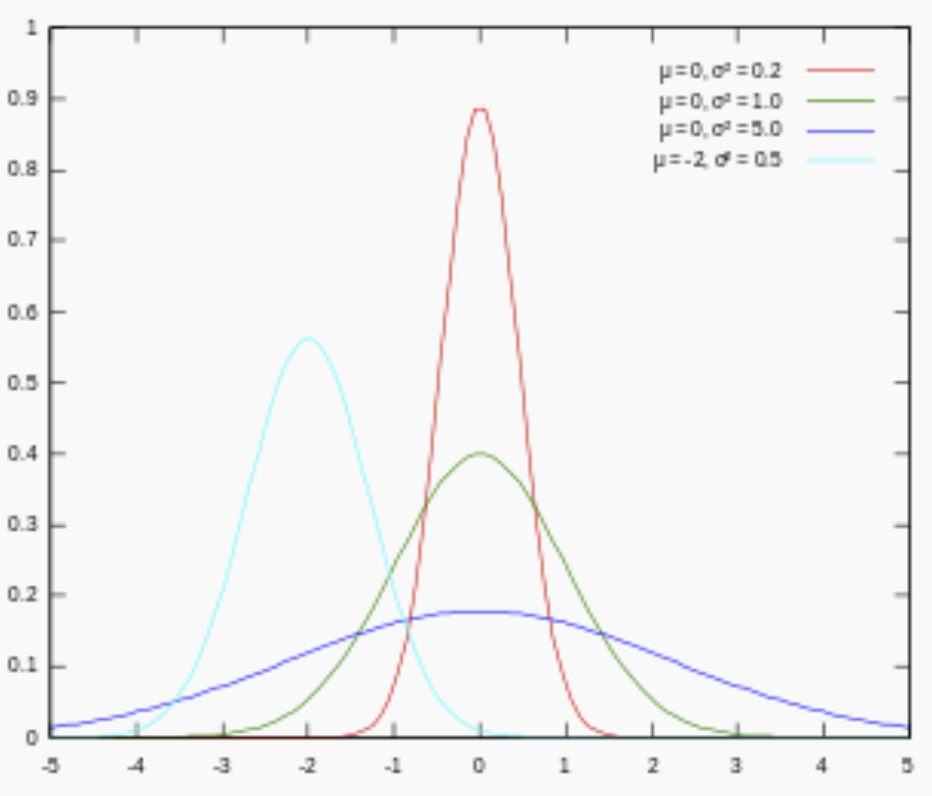
對引數引入拉普拉斯先驗等價於 L1正則化, 如下圖: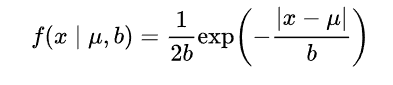
從上面兩圖可以看出, L2先驗趨向零周圍, L1先驗趨向零本身。
15 CNN最成功的應用是在CV,那為什麼NLP和Speech的很多問題也可以用CNN解出來?為什麼AlphaGo裡也用了CNN?這幾個不相關的問題的相似性在哪裡?CNN通過什麼手段抓住了這個共性?深度學習 DL應用 難
@許韓,來源:https://zhuanlan.zhihu.com/p/25005808
Deep Learning -Yann LeCun, Yoshua Bengio & Geoffrey Hinton
Learn TensorFlow and deep learning, without a Ph.D.
The Unreasonable Effectiveness of Deep Learning -LeCun 16 NIPS Keynote
以上幾個不相關問題的相關性在於,都存在區域性與整體的關係,由低層次的特徵經過組合,組成高層次的特徵,並且得到不同特徵之間的空間相關性。如下圖:低層次的直線/曲線等特徵,組合成為不同的形狀,最後得到汽車的表示。
CNN抓住此共性的手段主要有四個:區域性連線/權值共用/池化操作/多層次結構。
區域性連線使網路可以提取資料的區域性特徵;權值共用大大降低了網路的訓練難度,一個Filter只提取一個特徵,在整個圖片(或者語音/文字) 中進行折積;池化操作與多層次結構一起,實現了資料的降維,將低層次的區域性特徵組合成為較高層次的特徵,從而對整個圖片進行表示。如下圖: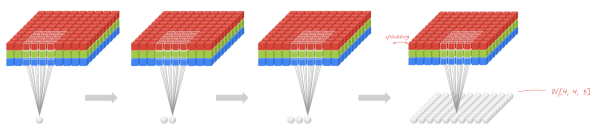
上圖中,如果每一個點的處理使用相同的Filter,則為全折積,如果使用不同的Filter,則為Local-Conv。
另,關於CNN,這裡有篇文章《 CNN筆記:通俗理解折積神經網路》。
16 說一下Adaboost,權值更新公式。當弱分類器是Gm時,每個樣本的的權重是w1,w2...,請寫出最終的決策公式。機器學習 ML模型 難
給定一個訓練資料集T={(x1,y1), (x2,y2)…(xN,yN)},其中範例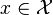 ,而範例空間
,而範例空間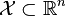 ,yi屬於標記集合{-1,+1},Adaboost的目的就是從訓練資料中學習一系列弱分類器或基本分類器,然後將這些弱分類器組合成一個強分類器。
,yi屬於標記集合{-1,+1},Adaboost的目的就是從訓練資料中學習一系列弱分類器或基本分類器,然後將這些弱分類器組合成一個強分類器。
Adaboost的演演算法流程如下:
- 步驟1. 首先,初始化訓練資料的權值分佈。每一個訓練樣本最開始時都被賦予相同的權值:1/N。
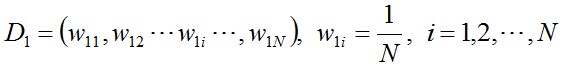
- 步驟2. 進行多輪迭代,用m = 1,2, ..., M表示迭代的第多少輪
a. 使用具有權值分佈Dm的訓練資料集學習,得到基本分類器(選取讓誤差率最低的閾值來設計基本分類器):
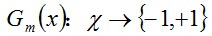
b. 計算Gm(x)在訓練資料集上的分類誤差率
由上述式子可知,Gm(x)在訓練資料集上的 誤差率em就是被Gm(x)誤分類樣本的權值之和。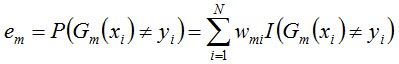
c. 計算Gm(x)的係數,am表示Gm(x)在最終分類器中的重要程度(目的:得到基本分類器在最終分類器中所佔的權重):
由上述式子可知,em <= 1/2時,am >= 0,且am隨著em的減小而增大,意味著分類誤差率越小的基本分類器在最終分類器中的作用越大。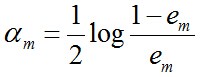
d. 更新訓練資料集的權值分佈(目的:得到樣本的新的權值分佈),用於下一輪迭代
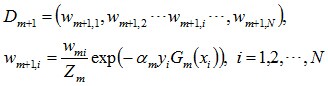
使得被基本分類器Gm(x)誤分類樣本的權值增大,而被正確分類樣本的權值減小。就這樣,通過這樣的方式,AdaBoost方法能「重點關注」或「聚焦於」那些較難分的樣本上。
其中,Zm是規範化因子,使得Dm+1成為一個概率分佈:
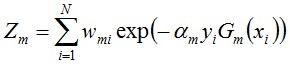
- 步驟3. 組合各個弱分類器
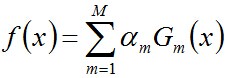
從而得到最終分類器,如下:
更多請檢視此文:《Adaboost 演演算法的原理與推導》。
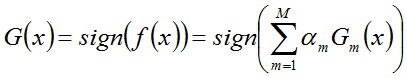
17 LSTM結構推導,為什麼比RNN好?深度學習 DL模型 難
推導forget gate,input gate,cell state, hidden information等的變化;因為LSTM有進有出且當前的cell informaton是通過input gate控制之後疊加的,RNN是疊乘,因此LSTM可以防止梯度消失或者爆炸
經常在網上搜尋東西的朋友知道,當你不小心輸入一個不存在的單詞時,搜尋引擎會提示你是不是要輸入某一個正確的單詞,比如當你在Google中輸入「Julw」時,系統會猜測你的意圖:是不是要搜尋「July」,如下圖所示:
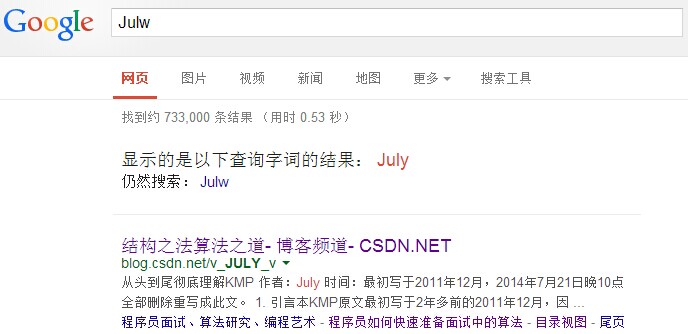
這叫做拼寫檢查。根據谷歌一員工寫的文章顯示,Google的拼寫檢查基於貝葉斯方法。請說說的你的理解,具體Google是怎麼利用貝葉斯方法,實現"拼寫檢查"的功能。機器學習 ML應用 難
使用者輸入一個單詞時,可能拼寫正確,也可能拼寫錯誤。如果把拼寫正確的情況記做c(代表correct),拼寫錯誤的情況記做w(代表wrong),那麼"拼寫檢查"要做的事情就是:在發生w的情況下,試圖推斷出c。換言之:已知w,然後在若干個備選方案中,找出可能性最大的那個c,也就是求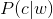 的最大值。
的最大值。
而根據貝葉斯定理,有:
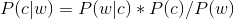
由於對於所有備選的c來說,對應的都是同一個w,所以它們的P(w)是相同的,因此我們只要最大化
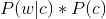
即可。其中:
- P(c)表示某個正確的詞的出現"概率",它可以用"頻率"代替。如果我們有一個足夠大的文字型檔,那麼這個文字型檔中每個單詞的出現頻率,就相當於它的發生概率。某個詞的出現頻率越高,P(c)就越大。比如在你輸入一個錯誤的詞「Julw」時,系統更傾向於去猜測你可能想輸入的詞是「July」,而不是「Jult」,因為「July」更常見。
- P(w|c)表示在試圖拼寫c的情況下,出現拼寫錯誤w的概率。為了簡化問題,假定兩個單詞在字形上越接近,就有越可能拼錯,P(w|c)就越大。舉例來說,相差一個字母的拼法,就比相差兩個字母的拼法,發生概率更高。你想拼寫單詞July,那麼錯誤拼成Julw(相差一個字母)的可能性,就比拼成Jullw高(相差兩個字母)。值得一提的是,一般把這種問題稱為「編輯距離」,參見部落格中的這篇文章。
所以,我們比較所有拼寫相近的詞在文字型檔中的出現頻率,再從中挑出出現頻率最高的一個,即是使用者最想輸入的那個詞。具體的計算過程及此方法的缺陷請參見這裡。
18 為什麼樸素貝葉斯如此「樸素」?機器學習 ML模型 易
因為它假定所有的特徵在資料集中的作用是同樣重要和獨立的。正如我們所知,這個假設在現實世界中是很不真實的,因此,說樸素貝葉斯真的很「樸素」。
@AntZ: 樸素貝葉斯模型(Naive Bayesian Model)的樸素(Naive)的含義是"很簡單很天真"地假設樣本特徵彼此獨立. 這個假設現實中基本上不存在, 但特徵相關性很小的實際情況還是很多的, 所以這個模型仍然能夠工作得很好。
19 請大致對比下plsa和LDA的區別。機器學習 ML模型 中等
- pLSA中,主題分佈和詞分佈確定後,以一定的概率(
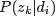 、
、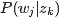 )分別選取具體的主題和詞項,生成好檔案。而後根據生成好的檔案反推其主題分佈、詞分佈時,最終用EM演演算法(極大似然估計思想)求解出了兩個未知但固定的引數的值:
)分別選取具體的主題和詞項,生成好檔案。而後根據生成好的檔案反推其主題分佈、詞分佈時,最終用EM演演算法(極大似然估計思想)求解出了兩個未知但固定的引數的值: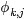 (由轉換而來)和
(由轉換而來)和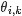 (由轉換而來)。
(由轉換而來)。
- 檔案d產生主題z的概率,主題z產生單詞w的概率都是兩個固定的值。
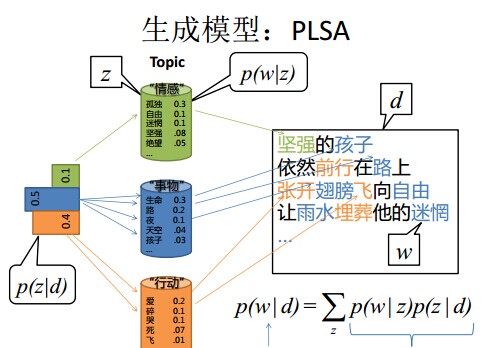
- 舉個檔案d產生主題z的例子。給定一篇檔案d,主題分佈是一定的,比如{ P(zi|d), i = 1,2,3 }可能就是{0.4,0.5,0.1},表示z1、z2、z3,這3個主題被檔案d選中的概率都是個固定的值:P(z1|d) = 0.4、P(z2|d) = 0.5、P(z3|d) = 0.1,如下圖所示(圖擷取自沈博PPT上):
- 檔案d產生主題z的概率,主題z產生單詞w的概率都是兩個固定的值。
- 但在貝葉斯框架下的LDA中,我們不再認為主題分佈(各個主題在檔案中出現的概率分佈)和詞分佈(各個詞語在某個主題下出現的概率分佈)是唯一確定的(而是隨機變數),而是有很多種可能。但一篇檔案總得對應一個主題分佈和一個詞分佈吧,怎麼辦呢?LDA為它們弄了兩個Dirichlet先驗引數,這個Dirichlet先驗為某篇檔案隨機抽取出某個主題分佈和詞分佈。
- 檔案d產生主題z(準確的說,其實是Dirichlet先驗為檔案d生成主題分佈Θ,然後根據主題分佈Θ產生主題z)的概率,主題z產生單詞w的概率都不再是某兩個確定的值,而是隨機變數。
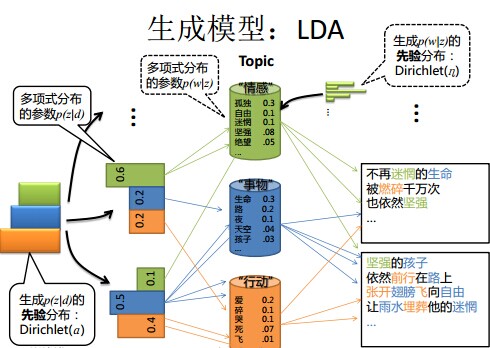
- 還是再次舉下檔案d具體產生主題z的例子。給定一篇檔案d,現在有多個主題z1、z2、z3,它們的主題分佈{ P(zi|d), i = 1,2,3 }可能是{0.4,0.5,0.1},也可能是{0.2,0.2,0.6},即這些主題被d選中的概率都不再認為是確定的值,可能是P(z1|d) = 0.4、P(z2|d) = 0.5、P(z3|d) = 0.1,也有可能是P(z1|d) = 0.2、P(z2|d) = 0.2、P(z3|d) = 0.6等等,而主題分佈到底是哪個取值集合我們不確定(為什麼?這就是貝葉斯派的核心思想,把未知引數當作是隨機變數,不再認為是某一個確定的值),但其先驗分佈是dirichlet 分佈,所以可以從無窮多個主題分佈中按照dirichlet 先驗隨機抽取出某個主題分佈出來。如下圖所示(圖擷取自沈博PPT上):
- 檔案d產生主題z(準確的說,其實是Dirichlet先驗為檔案d生成主題分佈Θ,然後根據主題分佈Θ產生主題z)的概率,主題z產生單詞w的概率都不再是某兩個確定的值,而是隨機變數。
換言之,LDA在pLSA的基礎上給這兩引數(、)加了兩個先驗分佈的引數(貝葉斯化):一個主題分佈的先驗分佈Dirichlet分佈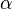 ,和一個詞語分佈的先驗分佈Dirichlet分佈
,和一個詞語分佈的先驗分佈Dirichlet分佈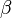 。
。
綜上,LDA真的只是pLSA的貝葉斯版本,檔案生成後,兩者都要根據檔案去推斷其主題分佈和詞語分佈,只是用的引數推斷方法不同,在pLSA中用極大似然估計的思想去推斷兩未知的固定引數,而LDA則把這兩引數弄成隨機變數,且加入dirichlet先驗。
更多請參見:《通俗理解LDA主題模型》。
20 請簡要說說EM演演算法。機器學習 ML模型 中等
@tornadomeet,本題解析來源:http://www.cnblogs.com/tornadomeet/p/3395593.html
有時候因為樣本的產生和隱含變數有關(隱含變數是不能觀察的),而求模型的引數時一般採用最大似然估計,由於含有了隱含變數,所以對似然函數引數求導是求不出來的,這時可以採用EM演演算法來求模型的引數的(對應模型引數個數可能有多個),EM演演算法一般分為2步:
E步:選取一組引數,求出在該引數下隱含變數的條件概率值;
M步:結合E步求出的隱含變數條件概率,求出似然函數下界函數(本質上是某個期望函數)的最大值。
重複上面2步直至收斂。
公式如下所示:
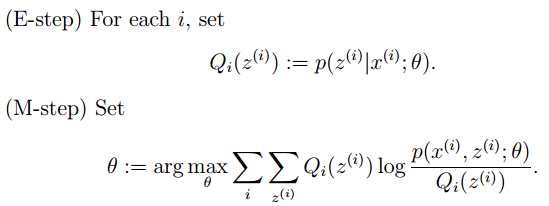
M步公式中下界函數的推導過程:
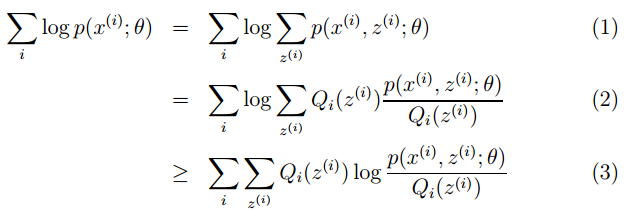
EM演演算法一個常見的例子就是GMM模型,每個樣本都有可能由k個高斯產生,只不過由每個高斯產生的概率不同而已,因此每個樣本都有對應的高斯分佈(k箇中的某一個),此時的隱含變數就是每個樣本對應的某個高斯分佈。
GMM的E步公式如下(計算每個樣本對應每個高斯的概率):
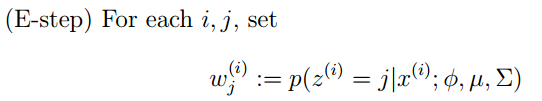
更具體的計算公式為:
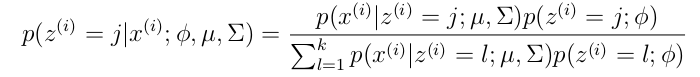
M步公式如下(計算每個高斯的比重,均值,方差這3個引數):

21 KNN中的K如何選取的?機器學習 ML模型 易
關於什麼是KNN,可以檢視此文:《從K近鄰演演算法、距離度量談到KD樹、SIFT+BBF演演算法》。KNN中的K值選取對K近鄰演演算法的結果會產生重大影響。如李航博士的一書「統計學習方法」上所說:
- 如果選擇較小的K值,就相當於用較小的領域中的訓練範例進行預測,「學習」近似誤差會減小,只有與輸入範例較近或相似的訓練範例才會對預測結果起作用,與此同時帶來的問題是「學習」的估計誤差會增大,換句話說,K值的減小就意味著整體模型變得複雜,容易發生過擬合;
- 如果選擇較大的K值,就相當於用較大領域中的訓練範例進行預測,其優點是可以減少學習的估計誤差,但缺點是學習的近似誤差會增大。這時候,與輸入範例較遠(不相似的)訓練範例也會對預測器作用,使預測發生錯誤,且K值的增大就意味著整體的模型變得簡單。
- K=N,則完全不足取,因為此時無論輸入範例是什麼,都只是簡單的預測它屬於在訓練範例中最多的累,模型過於簡單,忽略了訓練範例中大量有用資訊。
在實際應用中,K值一般取一個比較小的數值,例如採用交叉驗證法(簡單來說,就是一部分樣本做訓練集,一部分做測試集)來選擇最優的K值。
22 防止過擬合的方法。機器學習 ML基礎 易
過擬合的原因是演演算法的學習能力過強;一些假設條件(如樣本獨立同分布)可能是不成立的;訓練樣本過少不能對整個空間進行分佈估計。
處理方法:
- 早停止:如在訓練中多次迭代後發現模型效能沒有顯著提高就停止訓練
- 資料集擴增:原有資料增加、原有資料加隨機噪聲、重取樣
- 正則化
- 交叉驗證
- 特徵選擇/特徵降維
- 建立一個驗證集是最基本的防止過擬合的方法。我們最終訓練得到的模型目標是要在驗證集上面有好的表現,而不訓練集。
- 正則化可以限制模型的複雜度。
23 機器學習中,為何要經常對資料做歸一化。機器學習 ML基礎 中等
@zhanlijun,本題解析來源:http://www.cnblogs.com/LBSer/p/4440590.html
機器學習模型被網際網路行業廣泛應用,如排序(參見:排序學習實踐)、推薦、反作弊、定位(參見:基於樸素貝葉斯的定位演演算法)等。一般做機器學習應用的時候大部分時間是花費在特徵處理上,其中很關鍵的一步就是對特徵資料進行歸一化,為什麼要歸一化呢?很多同學並未搞清楚,維基百科給出的解釋:1)歸一化後加快了梯度下降求最優解的速度;2)歸一化有可能提高精度。下面再簡單擴充套件解釋下這兩點。
1 歸一化為什麼能提高梯度下降法求解最優解的速度?
斯坦福機器學習視訊做了很好的解釋:https://class.coursera.org/ml-003/lecture/21
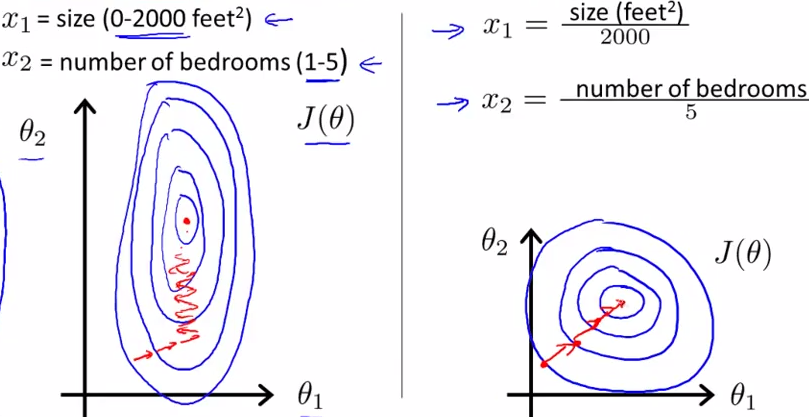
如下圖所示,藍色的圈圈圖代表的是兩個特徵的等高線。其中左圖兩個特徵X1和X2的區間相差非常大,X1區間是[0,2000],X2區間是[1,5],其所形成的等高線非常尖。當使用梯度下降法尋求最優解時,很有可能走「之字型」路線(垂直等高線走),從而導致需要迭代很多次才能收斂;
而右圖對兩個原始特徵進行了歸一化,其對應的等高線顯得很圓,在梯度下降進行求解時能較快的收斂。
因此如果機器學習模型使用梯度下降法求最優解時,歸一化往往非常有必要,否則很難收斂甚至不能收斂。
2 歸一化有可能提高精度
一些分類器需要計算樣本之間的距離(如歐氏距離),例如KNN。如果一個特徵值域範圍非常大,那麼距離計算就主要取決於這個特徵,從而與實際情況相悖(比如這時實際情況是值域範圍小的特徵更重要)。
3 歸一化的型別
1)線性歸一化
這種歸一化方法比較適用在數值比較集中的情況。這種方法有個缺陷,如果max和min不穩定,很容易使得歸一化結果不穩定,使得後續使用效果也不穩定。實際使用中可以用經驗常數值來替代max和min。
2)標準差標準化
經過處理的資料符合標準正態分佈,即均值為0,標準差為1,其轉化函數為:
其中μ為所有樣本資料的均值,σ為所有樣本資料的標準差。
3)非線性歸一化
經常用在資料分化比較大的場景,有些數值很大,有些很小。通過一些數學函數,將原始值進行對映。該方法包括 log、指數,正切等。需要根據資料分佈的情況,決定非線性函數的曲線,比如log(V, 2)還是log(V, 10)等。
談談深度學習中的歸一化問題。深度學習 DL基礎 易
詳情參見此視訊:《深度學習中的歸一化》。
24 哪些機器學習演演算法不需要做歸一化處理?機器學習 ML基礎 易
概率模型不需要歸一化,因為它們不關心變數的值,而是關心變數的分佈和變數之間的條件概率,如決策樹、rf。而像adaboost、svm、lr、KNN、KMeans之類的最佳化問題就需要歸一化。
@管博士:我理解歸一化和標準化主要是為了使計算更方便 比如兩個變數的量綱不同 可能一個的數值遠大於另一個那麼他們同時作為變數的時候 可能會造成數值計算的問題,比如說求矩陣的逆可能很不精確 或者梯度下降法的收斂比較困難,還有如果需要計算歐式距離的話可能 量綱也需要調整 所以我估計lr 和 knn 保準話一下應該有好處。至於其他的演演算法 我也覺得如果變數量綱差距很大的話 先標準化一下會有好處。
@寒小陽:一般我習慣說樹形模型,這裡說的概率模型可能是差不多的意思。
25 對於樹形結構為什麼不需要歸一化?機器學習 ML基礎 易
答:數值縮放,不影響分裂點位置。因為第一步都是按照特徵值進行排序的,排序的順序不變,那麼所屬的分支以及分裂點就不會有不同。對於線性模型,比如說LR,我有兩個特徵,一個是(0,1)的,一個是(0,10000)的,這樣運用梯度下降時候,損失等高線是一個橢圓的形狀,這樣我想迭代到最優點,就需要很多次迭代,但是如果進行了歸一化,那麼等高線就是圓形的,那麼SGD就會往原點迭代,需要的迭代次數較少。
另外,注意樹模型是不能進行梯度下降的,因為樹模型是階躍的,階躍點是不可導的,並且求導沒意義,所以樹模型(迴歸樹)尋找最優點事通過尋找最優分裂點完成的。
26 資料歸一化(或者標準化,注意歸一化和標準化不同)的原因。機器學習 ML基礎 易
@我愛大泡泡,來源:http://blog.csdn.net/woaidapaopao/article/details/77806273
要強調:能不歸一化最好不歸一化,之所以進行資料歸一化是因為各維度的量綱不相同。而且需要看情況進行歸一化。
- 有些模型在各維度進行了不均勻的伸縮後,最優解與原來不等價(如SVM)需要歸一化。
- 有些模型伸縮有與原來等價,如:LR則不用歸一化,但是實際中往往通過迭代求解模型引數,如果目標函數太扁(想象一下很扁的高斯模型)迭代演演算法會發生不收斂的情況,所以最壞進行資料歸一化。
補充:其實本質是由於loss函數不同造成的,SVM用了尤拉距離,如果一個特徵很大就會把其他的維度dominated。而LR可以通過權重調整使得損失函數不變。
27 請簡要說說一個完整機器學習專案的流程。機器學習 ML應用 中
@寒小陽、龍心塵
1 抽象成數學問題
明確問題是進行機器學習的第一步。機器學習的訓練過程通常都是一件非常耗時的事情,胡亂嘗試時間成本是非常高的。
這裡的抽象成數學問題,指的我們明確我們可以獲得什麼樣的資料,目標是一個分類還是迴歸或者是聚類的問題,如果都不是的話,如果劃歸為其中的某類問題。
2 獲取資料
資料決定了機器學習結果的上限,而演演算法只是儘可能逼近這個上限。
資料要有代表性,否則必然會過擬合。
而且對於分類問題,資料偏斜不能過於嚴重,不同類別的資料數量不要有數個數量級的差距。
而且還要對資料的量級有一個評估,多少個樣本,多少個特徵,可以估算出其對記憶體的消耗程度,判斷訓練過程中記憶體是否能夠放得下。如果放不下就得考慮改進演演算法或者使用一些降維的技巧了。如果資料量實在太大,那就要考慮分散式了。
3 特徵預處理與特徵選擇
良好的資料要能夠提取出良好的特徵才能真正發揮效力。
特徵預處理、資料淨化是很關鍵的步驟,往往能夠使得演演算法的效果和效能得到顯著提高。歸一化、離散化、因子化、缺失值處理、去除共線性等,資料探勘過程中很多時間就花在它們上面。這些工作簡單可複製,收益穩定可預期,是機器學習的基礎必備步驟。
篩選出顯著特徵、摒棄非顯著特徵,需要機器學習工程師反覆理解業務。這對很多結果有決定性的影響。特徵選擇好了,非常簡單的演演算法也能得出良好、穩定的結果。這需要運用特徵有效性分析的相關技術,如相關係數、卡方檢驗、平均互資訊、條件熵、後驗概率、邏輯迴歸權重等方法。
4 訓練模型與調優
直到這一步才用到我們上面說的演演算法進行訓練。現在很多演演算法都能夠封裝成黑盒供人使用。但是真正考驗水平的是調整這些演演算法的(超)引數,使得結果變得更加優良。這需要我們對演演算法的原理有深入的理解。理解越深入,就越能發現問題的癥結,提出良好的調優方案。
5 模型診斷
如何確定模型調優的方向與思路呢?這就需要對模型進行診斷的技術。
過擬合、欠擬合 判斷是模型診斷中至關重要的一步。常見的方法如交叉驗證,繪製學習曲線等。過擬合的基本調優思路是增加資料量,降低模型複雜度。欠擬合的基本調優思路是提高特徵數量和品質,增加模型複雜度。
誤差分析 也是機器學習至關重要的步驟。通過觀察誤差樣本,全面分析誤差產生誤差的原因:是引數的問題還是演演算法選擇的問題,是特徵的問題還是資料本身的問題……
診斷後的模型需要進行調優,調優後的新模型需要重新進行診斷,這是一個反覆迭代不斷逼近的過程,需要不斷地嘗試, 進而達到最優狀態。
6 模型融合
一般來說,模型融合後都能使得效果有一定提升。而且效果很好。
工程上,主要提升演演算法準確度的方法是分別在模型的前端(特徵清洗和預處理,不同的取樣模式)與後端(模型融合)上下功夫。因為他們比較標準可複製,效果比較穩定。而直接調參的工作不會很多,畢竟大量資料訓練起來太慢了,而且效果難以保證。
7 上線執行
這一部分內容主要跟工程實現的相關性比較大。工程上是結果導向,模型線上上執行的效果直接決定模型的成敗。 不單純包括其準確程度、誤差等情況,還包括其執行的速度(時間複雜度)、資源消耗程度(空間複雜度)、穩定性是否可接受。
這些工作流程主要是工程實踐上總結出的一些經驗。並不是每個專案都包含完整的一個流程。這裡的部分只是一個指導性的說明,只有大家自己多實踐,多積累專案經驗,才會有自己更深刻的認識。
故,基於此,七月線上每一期ML演演算法班都特此增加特徵工程、模型調優等相關課。比如,這裡有個公開課視訊《特徵處理與特徵選擇》。
28 邏輯斯特迴歸為什麼要對特徵進行離散化。機器學習 ML模型 中等
@嚴林,本題解析來源:https://www.zhihu.com/question/31989952
在工業界,很少直接將連續值作為邏輯迴歸模型的特徵輸入,而是將連續特徵離散化為一系列0、1特徵交給邏輯迴歸模型,這樣做的優勢有以下幾點:
0. 離散特徵的增加和減少都很容易,易於模型的快速迭代;
1. 稀疏向量內積乘法運算速度快,計算結果方便儲存,容易擴充套件;
2. 離散化後的特徵對異常資料有很強的魯棒性:比如一個特徵是年齡>30是1,否則0。如果特徵沒有離散化,一個異常資料「年齡300歲」會給模型造成很大的干擾;
3. 邏輯迴歸屬於廣義線性模型,表達能力受限;單變數離散化為N個後,每個變數有單獨的權重,相當於為模型引入了非線性,能夠提升模型表達能力,加大擬合;
4. 離散化後可以進行特徵交叉,由M+N個變數變為M*N個變數,進一步引入非線性,提升表達能力;
5. 特徵離散化後,模型會更穩定,比如如果對使用者年齡離散化,20-30作為一個區間,不會因為一個使用者年齡長了一歲就變成一個完全不同的人。當然處於區間相鄰處的樣本會剛好相反,所以怎麼劃分割區間是門學問;
6. 特徵離散化以後,起到了簡化了邏輯迴歸模型的作用,降低了模型過擬合的風險。
李沐曾經說過:模型是使用離散特徵還是連續特徵,其實是一個「海量離散特徵+簡單模型」 同 「少量連續特徵+複雜模型」的權衡。既可以離散化用線性模型,也可以用連續特徵加深度學習。就看是喜歡折騰特徵還是折騰模型了。通常來說,前者容易,而且可以n個人一起並行做,有成功經驗;後者目前看很贊,能走多遠還須拭目以待。
29 new 和 malloc的區別。程式設計開發 C/C++ 易
@Sommer_Xia,來源:http://blog.csdn.net/shymi1991/article/details/39432775
1. malloc與free是C++/C語言的標準庫函數,new/delete是C++的運運算元。它們都可用於申請動態記憶體和釋放記憶體。
2. 對於非內部資料型別的物件而言,光用maloc/free無法滿足動態物件的要求。物件在建立的同時要自動執行建構函式,物件在消亡之前要自動執行解構函式。由於malloc/free是庫函數而不是運運算元,不在編譯器控制許可權之內,不能夠把執行建構函式和解構函式的任務強加於malloc/free。
3. 因此C++語言需要一個能完成動態記憶體分配和初始化工作的運運算元new,以一個能完成清理與釋放記憶體工作的運運算元delete。注意new/delete不是庫函數。
4. C++程式經常要呼叫C函數,而C程式只能用malloc/free管理動態記憶體
30 hash 衝突及解決辦法。資料結構/演演算法 中等
@Sommer_Xia,來源:http://blog.csdn.net/shymi1991/article/details/39432775
關鍵字值不同的元素可能會映象到雜湊表的同一地址上就會發生雜湊衝突。解決辦法:
1)開放定址法:當衝突發生時,使用某種探查(亦稱探測)技術在雜湊表中形成一個探查(測)序列。沿此序列逐個單元地查詢,直到找到給定 的關鍵字,或者碰到一個開放的地址(即該地址單元為空)為止(若要插入,在探查到開放的地址,則可將待插入的新結點存人該地址單元)。查詢時探查到開放的 地址則表明表中無待查的關鍵字,即查詢失敗。
2) 再雜湊法:同時構造多個不同的雜湊函數。
3)鏈地址法:將所有雜湊地址為i的元素構成一個稱為同義詞鏈的單連結串列,並將單連結串列的頭指標存在雜湊表的第i個單元中,因而查詢、插入和刪除主要在同義詞鏈中進行。鏈地址法適用於經常進行插入和刪除的情況。
4)建立公共溢位區:將雜湊表分為基本表和溢位表兩部分,凡是和基本表發生衝突的元素,一律填入溢位表。
31 下列哪個不屬於CRF模型對於HMM和MEMM模型的優勢(B ) 機器學習 ML模型 中等
A. 特徵靈活 B. 速度快 C. 可容納較多上下文資訊 D. 全域性最優
首先,CRF,HMM(隱馬模型),MEMM(最大熵隱馬模型)都常用來做序列標註的建模.
隱馬模型一個最大的缺點就是由於其輸出獨立性假設,導致其不能考慮上下文的特徵,限制了特徵的選擇
最大熵隱馬模型則解決了隱馬的問題,可以任意選擇特徵,但由於其在每一節點都要進行歸一化,所以只能找到區域性的最優值,同時也帶來了標記偏見的問題,即凡是訓練語料中未出現的情況全都忽略掉
條件隨機場則很好的解決了這一問題,他並不在每一個節點進行歸一化,而是所有特徵進行全域性歸一化,因此可以求得全域性的最優值。
此外《機器學習工程師第八期》裡有講概率圖模型。
32 什麼是熵。機器學習 ML基礎 易
從名字上來看,熵給人一種很玄乎,不知道是啥的感覺。其實,熵的定義很簡單,即用來表示隨機變數的不確定性。之所以給人玄乎的感覺,大概是因為為何要取這樣的名字,以及怎麼用。
熵的概念最早起源於物理學,用於度量一個熱力學系統的無序程度。在資訊理論裡面,熵是對不確定性的測量。
熵的引入
事實上,熵的英文原文為entropy,最初由德國物理學家魯道夫·克勞修斯提出,其表示式為:
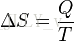
它表示一個繫系統在不受外部干擾時,其內部最穩定的狀態。後來一中國學者翻譯entropy時,考慮到entropy是能量Q跟溫度T的商,且跟火有關,便把entropy形象的翻譯成「熵」。
我們知道,任何粒子的常態都是隨機運動,也就是"無序運動",如果讓粒子呈現"有序化",必須耗費能量。所以,溫度(熱能)可以被看作"有序化"的一種度量,而"熵"可以看作是"無序化"的度量。
如果沒有外部能量輸入,封閉系統趨向越來越混亂(熵越來越大)。比如,如果房間無人打掃,不可能越來越乾淨(有序化),只可能越來越亂(無序化)。而要讓一個系統變得更有序,必須有外部能量的輸入。
1948年,夏農Claude E. Shannon引入資訊(熵),將其定義為離散隨機事件的出現概率。一個系統越是有序,資訊熵就越低;反之,一個系統越是混亂,資訊熵就越高。所以說,資訊熵可以被認為是系統有序化程度的一個度量。
更多請檢視《最大熵模型中的數學推導》。
33 熵、聯合熵、條件熵、相對熵、互資訊的定義。機器學習 ML基礎 中等
為了更好的理解,需要了解的概率必備知識有:
- 大寫字母X表示隨機變數,小寫字母x表示隨機變數X的某個具體的取值;
- P(X)表示隨機變數X的概率分佈,P(X,Y)表示隨機變數X、Y的聯合概率分佈,P(Y|X)表示已知隨機變數X的情況下隨機變數Y的條件概率分佈;
- p(X = x)表示隨機變數X取某個具體值的概率,簡記為p(x);
- p(X = x, Y = y) 表示聯合概率,簡記為p(x,y),p(Y = y|X = x)表示條件概率,簡記為p(y|x),且有:p(x,y) = p(x) * p(y|x)。
熵:如果一個隨機變數X的可能取值為X = {x1, x2,…, xk},其概率分佈為P(X = xi) = pi(i = 1,2, ..., n),則隨機變數X的熵定義為:
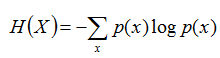
把最前面的負號放到最後,便成了:
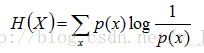
上面兩個熵的公式,無論用哪個都行,而且兩者等價,一個意思(這兩個公式在下文中都會用到)。
聯合熵:兩個隨機變數X,Y的聯合分佈,可以形成聯合熵Joint Entropy,用H(X,Y)表示。
條件熵:在隨機變數X發生的前提下,隨機變數Y發生所新帶來的熵定義為Y的條件熵,用H(Y|X)表示,用來衡量在已知隨機變數X的條件下隨機變數Y的不確定性。
且有此式子成立:H(Y|X) = H(X,Y) – H(X),整個式子表示(X,Y)發生所包含的熵減去X單獨發生包含的熵。至於怎麼得來的請看推導:
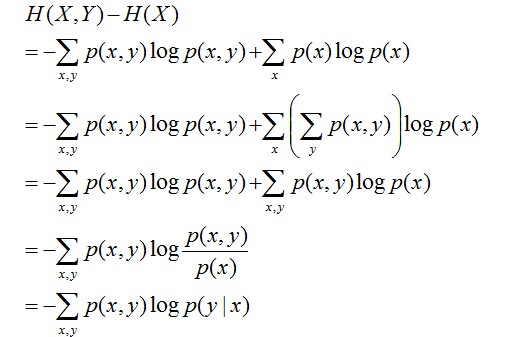
簡單解釋下上面的推導過程。整個式子共6行,其中
- 第二行推到第三行的依據是邊緣分佈p(x)等於聯合分佈p(x,y)的和;
- 第三行推到第四行的依據是把公因子logp(x)乘進去,然後把x,y寫在一起;
- 第四行推到第五行的依據是:因為兩個sigma都有p(x,y),故提取公因子p(x,y)放到外邊,然後把裡邊的-(log p(x,y) - log p(x))寫成- log (p(x,y)/p(x) ) ;
- 第五行推到第六行的依據是:p(x,y) = p(x) * p(y|x),故p(x,y) / p(x) = p(y|x)。
相對熵:又稱互熵,交叉熵,鑑別資訊,Kullback熵,Kullback-Leible散度等。設p(x)、q(x)是X中取值的兩個概率分佈,則p對q的相對熵是:
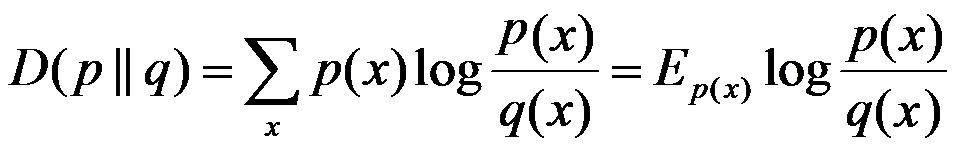
在一定程度上,相對熵可以度量兩個隨機變數的「距離」,且有D(p||q) ≠D(q||p)。另外,值得一提的是,D(p||q)是必然大於等於0的。
互資訊:兩個隨機變數X,Y的互資訊定義為X,Y的聯合分佈和各自獨立分佈乘積的相對熵,用I(X,Y)表示:
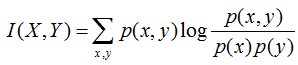
且有I(X,Y)=D(P(X,Y) || P(X)P(Y))。下面,咱們來計算下H(Y)-I(X,Y)的結果,如下:
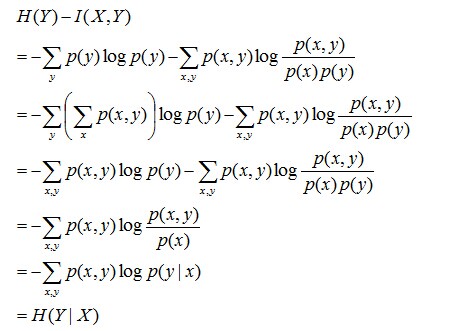
通過上面的計算過程,我們發現竟然有H(Y)-I(X,Y) = H(Y|X)。故通過條件熵的定義,有:H(Y|X) = H(X,Y) - H(X),而根據互資訊定義展開得到H(Y|X) = H(Y) - I(X,Y),把前者跟後者結合起來,便有I(X,Y)= H(X) + H(Y) - H(X,Y),此結論被多數文獻作為互資訊的定義。更多請檢視《最大熵模型中的數學推導》。
34 什麼是最大熵。機器學習 ML基礎 易
熵是隨機變數不確定性的度量,不確定性越大,熵值越大;若隨機變數退化成定值,熵為0。如果沒有外界干擾,隨機變數總是趨向於無序,在經過足夠時間的穩定演化,它應該能夠達到的最大程度的熵。
為了準確的估計隨機變數的狀態,我們一般習慣性最大化熵,認為在所有可能的概率模型(分佈)的集合中,熵最大的模型是最好的模型。換言之,在已知部分知識的前提下,關於未知分佈最合理的推斷就是符合已知知識最不確定或最隨機的推斷,其原則是承認已知事物(知識),且對未知事物不做任何假設,沒有任何偏見。
例如,投擲一個骰子,如果問"每個面朝上的概率分別是多少",你會說是等概率,即各點出現的概率均為1/6。因為對這個"一無所知"的色子,什麼都不確定,而假定它每一個朝上概率均等則是最合理的做法。從投資的角度來看,這是風險最小的做法,而從資訊理論的角度講,就是保留了最大的不確定性,也就是說讓熵達到最大。
3.1 無偏原則
下面再舉個大多數有關最大熵模型的文章中都喜歡舉的一個例子。
例如,一篇文章中出現了「學習」這個詞,那這個詞是主語、謂語、還是賓語呢?換言之,已知「學習」可能是動詞,也可能是名詞,故「學習」可以被標為主語、謂語、賓語、定語等等。
- 令x1表示「學習」被標為名詞, x2表示「學習」被標為動詞。
- 令y1表示「學習」被標為主語, y2表示被標為謂語, y3表示賓語, y4表示定語。
且這些概率值加起來的和必為1,即 ![]() ,
,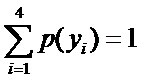 , 則根據無偏原則,認為這個分佈中取各個值的概率是相等的,故得到:
, 則根據無偏原則,認為這個分佈中取各個值的概率是相等的,故得到:
因為沒有任何的先驗知識,所以這種判斷是合理的。如果有了一定的先驗知識呢?
即進一步,若已知:「學習」被標為定語的可能性很小,只有0.05,即![]() ,剩下的依然根據無偏原則,可得:
,剩下的依然根據無偏原則,可得:
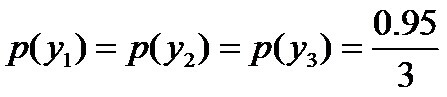
再進一步,當「學習」被標作名詞x1的時候,它被標作謂語y2的概率為0.95,即![]() ,此時仍然需要堅持無偏見原則,使得概率分佈儘量平均。但怎麼樣才能得到儘量無偏見的分佈?
,此時仍然需要堅持無偏見原則,使得概率分佈儘量平均。但怎麼樣才能得到儘量無偏見的分佈?
實踐經驗和理論計算都告訴我們,在完全無約束狀態下,均勻分佈等價於熵最大(有約束的情況下,不一定是概率相等的均勻分佈。 比如,給定均值和方差,熵最大的分佈就變成了正態分佈 )。
於是,問題便轉化為了:計算X和Y的分佈,使得H(Y|X)達到最大值,並且滿足下述條件:
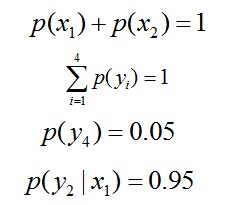
因此,也就引出了最大熵模型的本質,它要解決的問題就是已知X,計算Y的概率,且儘可能讓Y的概率最大(實踐中,X可能是某單詞的上下文資訊,Y是該單詞翻譯成me,I,us、we的各自概率),從而根據已有資訊,儘可能最準確的推測未知資訊,這就是最大熵模型所要解決的問題。
相當於已知X,計算Y的最大可能的概率,轉換成公式,便是要最大化下述式子H(Y|X):
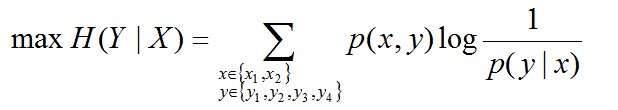
且滿足以下4個約束條件:
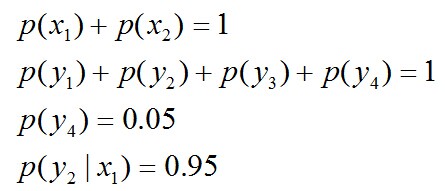
簡單說下有監督學習和無監督學習的區別。機器學習 ML基礎 易
有監督學習:對具有標記的訓練樣本進行學習,以儘可能對訓練樣本集外的資料進行分類預測。(LR,SVM,BP,RF,GBDT)
無監督學習:對未標記的樣本進行訓練學習,比發現這些樣本中的結構知識。(KMeans,DL)
35 瞭解正則化麼。機器學習 ML基礎 易
正則化是針對過擬合而提出的,以為在求解模型最優的是一般優化最小的經驗風險,現在在該經驗風險上加入模型複雜度這一項(正則化項是模型引數向量的範數),並使用一個rate比率來權衡模型複雜度與以往經驗風險的權重,如果模型複雜度越高,結構化的經驗風險會越大,現在的目標就變為了結構經驗風險的最佳化,可以防止模型訓練過度複雜,有效的降低過擬合的風險。
奧卡姆剃刀原理,能夠很好的解釋已知資料並且十分簡單才是最好的模型。
36 協方差和相關性有什麼區別?機器學習 ML基礎 易
相關性是協方差的標準化格式。協方差本身很難做比較。例如:如果我們計算工資($)和年齡(歲)的協方差,因為這兩個變數有不同的度量,所以我們會得到不能做比較的不同的協方差。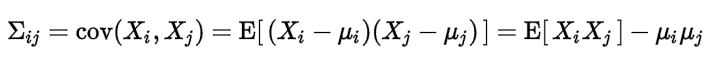
為了解決這個問題,我們計算相關性來得到一個介於-1和1之間的值,就可以忽略它們各自不同的度量。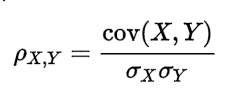
37 線性分類器與非線性分類器的區別以及優劣。機器學習 ML基礎 易
@偉祺,線性和非線性是針對,模型引數和輸入特徵來講的;比如輸入x,模型y=ax+ax^2那麼就是非線性模型,如果輸入是x和X^2則模型是線性的。
線性分類器可解釋性好,計算複雜度較低,不足之處是模型的擬合效果相對弱些。
非線性分類器效果擬合能力較強,不足之處是資料量不足容易過擬合、計算複雜度高、可解釋性不好。
常見的線性分類器有:LR,貝葉斯分類,單層感知機、線性迴歸
常見的非線性分類器:決策樹、RF、GBDT、多層感知機
SVM兩種都有(看線性核還是高斯核)
38 資料的邏輯儲存結構(如陣列,佇列,樹等)對於軟體開發具有十分重要的影響,試對你所瞭解的各種儲存結構從執行速度、儲存效率和適用場合等方面進行簡要地分析。 資料結構/演演算法 中等
| 執行速度 | 儲存效率 | 適用場合 | ||
| 陣列 | 快 | 高 | 比較適合進行查詢操作,還有像類似於矩陣等的操作 | |
| 連結串列 | 較快 | 較高 | 比較適合增刪改頻繁操作,動態的分配記憶體 | |
| 佇列 | 較快 | 較高 | 比較適合進行任務類等的排程 | |
| 棧 | 一般 | 較高 | 比較適合遞迴類程式的改寫 | |
| 二元樹(樹) | 較快 | 一般 | 一切具有層次關係的問題都可用樹來描述 | |
| 圖 | 一般 | 一般 | 除了像最小生成樹、最短路徑、拓撲排序等經典用途。還被用於像神經網路等人工智慧領域等等。 | |
39 什麼是分散式資料庫?計算機基礎 資料庫 易
分散式資料庫系統是在集中式資料庫系統成熟技術的基礎上發展起來的,但不是簡單地把集中式資料庫分散地實現,它具有自己的性質和特徵。集中式資料庫系統的許多概念和技術,如資料獨立性、資料共用和減少冗餘度、並行控制、完整性、安全性和恢復等在分散式資料庫系統中都有了不同的、更加豐富的內容。
具體來說,叢集檔案系統是指執行在多臺計算機之上,之間通過某種方式相互通訊從而將叢集內所有儲存空間資源整合、虛擬化並對外提供檔案存取服務的檔案系統。其與NTFS、EXT等本地檔案系統的目的不同,前者是為了擴充套件性,後者執行在單機環境,純粹管理塊和檔案之間的對映以及檔案屬性。
叢集檔案系統分為多類,按照對儲存空間的存取方式,可分為共用儲存型叢集檔案系統和分散式叢集檔案系統,前者是多臺計算機識別到同樣的儲存空間,並相互協調共同管理其上的檔案,又被稱為共用檔案系統;後者則是每臺計算機各自提供自己的儲存空間,並各自協調管理所有計算機節點中的檔案。Veritas的VxFS/VCS,昆騰Stornext,中科藍鯨BWFS,EMC的MPFS,屬於共用儲存型叢集檔案系統。而HDFS、Gluster、Ceph、Swift等網際網路常用的大規模叢集檔案系統無一例外都屬於分散式叢集檔案系統。分散式叢集檔案系統可延伸性更強,目前已知最大可延伸至10K節點。
按照後設資料的管理方式,可分為對稱式叢集檔案系統和非對稱式叢集檔案系統。前者每個節點的角色均等,共同管理檔案後設資料,節點間通過高速網路進行資訊同步和互斥鎖等操作,典型代表是Veritas的VCS。而非對稱式叢集檔案系統中,有專門的一個或者多個節點負責管理後設資料,其他節點需要頻繁與後設資料節點通訊以獲取最新的後設資料比如目錄列表檔案屬性等等,後者典型代表比如HDFS、GFS、BWFS、Stornext等。對於叢集檔案系統,其可以是分散式+對稱式、分散式+非對稱式、共用式+對稱式、共用式+非對稱式,兩兩任意組合。
按照檔案存取方式來分類,叢集檔案系統可分為序列存取式和並行存取式,後者又被俗稱為並行檔案系統。
序列存取是指使用者端只能從叢集中的某個節點來存取叢集內的檔案資源,而並行存取則是指使用者端可以直接從叢集中任意一個或者多個節點同時收發資料,做到並行資料存取,加快速度。
HDFS、GFS、pNFS等叢集檔案系統,都支援並行存取,需要安裝專用使用者端,傳統的NFS/CIFS使用者端不支援並行存取。
40 簡單說說貝葉斯定理。機器學習 ML模型 易
在引出貝葉斯定理之前,先學習幾個定義:
- 條件概率(又稱後驗概率)就是事件A在另外一個事件B已經發生條件下的發生概率。條件概率表示為P(A|B),讀作「在B條件下A的概率」。
比如,在同一個樣本空間Ω中的事件或者子集A與B,如果隨機從Ω中選出的一個元素屬於B,那麼這個隨機選擇的元素還屬於A的概率就定義為在B的前提下A的條件概率,所以:P(A|B) = |A∩B|/|B|,接著分子、分母都除以|Ω|得到
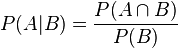
- 聯合概率表示兩個事件共同發生的概率。A與B的聯合概率表示為
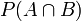 或者
或者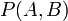 。
。 - 邊緣概率(又稱先驗概率)是某個事件發生的概率。邊緣概率是這樣得到的:在聯合概率中,把最終結果中那些不需要的事件通過合併成它們的全概率,而消去它們(對離散隨機變數用求和得全概率,對連續隨機變數用積分得全概率),這稱為邊緣化(marginalization),比如A的邊緣概率表示為P(A),B的邊緣概率表示為P(B)。
接著,考慮一個問題:P(A|B)是在B發生的情況下A發生的可能性。
- 首先,事件B發生之前,我們對事件A的發生有一個基本的概率判斷,稱為A的先驗概率,用P(A)表示;
- 其次,事件B發生之後,我們對事件A的發生概率重新評估,稱為A的後驗概率,用P(A|B)表示;
- 類似的,事件A發生之前,我們對事件B的發生有一個基本的概率判斷,稱為B的先驗概率,用P(B)表示;
- 同樣,事件A發生之後,我們對事件B的發生概率重新評估,稱為B的後驗概率,用P(B|A)表示。
貝葉斯定理便是基於下述貝葉斯公式:
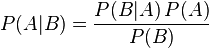
上述公式的推導其實非常簡單,就是從條件概率推出。
根據條件概率的定義,在事件B發生的條件下事件A發生的概率是
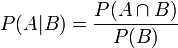
同樣地,在事件A發生的條件下事件B發生的概率
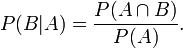
整理與合併上述兩個方程式,便可以得到:
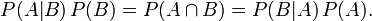
接著,上式兩邊同除以P(B),若P(B)是非零的,我們便可以得到貝葉斯定理的公式表示式:

所以,貝葉斯公式可以直接根據條件概率的定義直接推出。即因為P(A,B) = P(A)P(B|A) = P(B)P(A|B),所以P(A|B) = P(A)P(B|A) / P(B)。更多請參見此文:《從貝葉斯方法談到貝葉斯網路》。
41 #include和#include「filename.h」有什麼區別?計算機基礎 編譯原理 易
用 #include 格式來參照標準庫的標頭檔案(編譯器將從標準庫目錄開始搜尋)。
用 #include 「filename.h」 格式來參照非標準庫的標頭檔案(編譯器將從使用者的工作目錄開始搜尋)。
42 某超市研究銷售紀錄資料後發現,買啤酒的人很大概率也會購買尿布,這種屬於資料探勘的哪類問題?(A) 資料探勘 DM模型 易
A. 關聯規則發現 B. 聚類
C. 分類 D. 自然語言處理
43 將原始資料進行整合、變換、維度規約、數值規約是在以下哪個步驟的任務?(C) 資料探勘 DM基礎 易
A. 頻繁模式挖掘 B. 分類和預測 C. 資料預處理 D. 資料流挖掘
44 下面哪種不屬於資料預處理的方法? (D) 資料探勘 DM基礎 易
A變數代換 B離散化 C 聚集 D 估計遺漏值
45 什麼是KDD? (A) 資料探勘 DM基礎 易
A. 資料探勘與知識發現 B. 領域知識發現
C. 檔案知識發現 D. 動態知識發現
46 當不知道資料所帶標籤時,可以使用哪種技術促使帶同類標籤的資料與帶其他標籤的資料相分離?(B) 資料探勘 DM模型 易
A. 分類 B. 聚類 C. 關聯分析 D. 隱馬爾可夫鏈
47 建立一個模型,通過這個模型根據已知的變數值來預測其他某個變數值屬於資料探勘的哪一類任務?(C) 資料探勘 DM基礎 易
A. 根據內容檢索 B. 建模描述
C. 預測建模 D. 尋找模式和規則
48 以下哪種方法不屬於特徵選擇的標準方法: (D) 資料探勘 DM基礎 易
A嵌入 B 過濾 C 包裝 D 抽樣
49 請用python編寫函數find_string,從文字中搜尋並列印內容,要求支援萬用字元星號和問號。Python Python語言 易
例子:
>>>find_string('hello\nworld\n','wor')
['wor']
>>>find_string('hello\nworld\n','l*d')
['ld']
>>>find_string('hello\nworld\n','o.')
['or']
答案
def find_string(str,pat):
import re
return re.findall(pat,str,re.I)
50 說下紅黑樹的五個性質。資料結構 樹 易
紅黑樹,一種二叉查詢樹,但在每個結點上增加一個儲存位表示結點的顏色,可以是Red或Black。
通過對任何一條從根到葉子的路徑上各個結點著色方式的限制,紅黑樹確保沒有一條路徑會比其他路徑長出倆倍,因而是接近平衡的。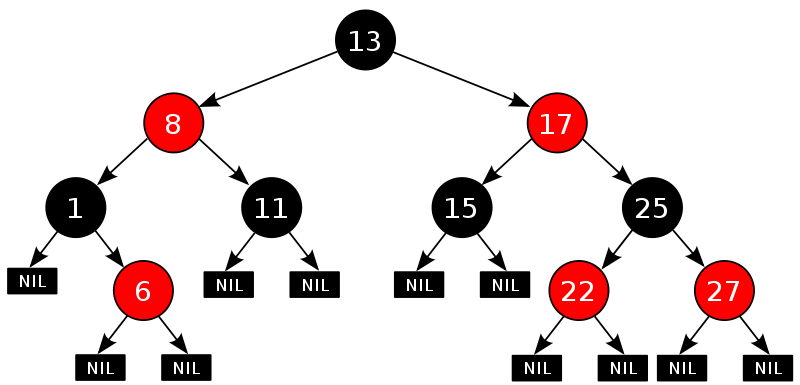
紅黑樹,作為一棵二叉查詢樹,滿足二叉查詢樹的一般性質。下面,來了解下 二叉查詢樹的一般性質。
二叉查詢樹,也稱有序二元樹(ordered binary tree),或已排序二元樹(sorted binary tree),是指一棵空樹或者具有下列性質的二元樹:
若任意節點的左子樹不空,則左子樹上所有結點的值均小於它的根結點的值;
若任意節點的右子樹不空,則右子樹上所有結點的值均大於它的根結點的值;
任意節點的左、右子樹也分別為二叉查詢樹。
沒有鍵值相等的節點(no duplicate nodes)。
因為一棵由n個結點隨機構造的二叉查詢樹的高度為lgn,所以順理成章,二叉查詢樹的一般操作的執行時間為O(lgn)。但二叉查詢樹若退化成了一棵具有n個結點的線性鏈後,則這些操作最壞情況執行時間為O(n)。
紅黑樹雖然本質上是一棵二叉查詢樹,但它在二叉查詢樹的基礎上增加了著色和相關的性質使得紅黑樹相對平衡,從而保證了紅黑樹的查詢、插入、刪除的時間複雜度最壞為O(log n)。
但它是如何保證一棵n個結點的紅黑樹的高度始終保持在logn的呢?這就引出了紅黑樹的5個性質:
每個結點要麼是紅的要麼是黑的。
根結點是黑的。
每個葉結點(葉結點即指樹尾端NIL指標或NULL結點)都是黑的。
如果一個結點是紅的,那麼它的兩個兒子都是黑的。
對於任意結點而言,其到葉結點樹尾端NIL指標的每條路徑都包含相同數目的黑結點。
正是紅黑樹的這5條性質,使一棵n個結點的紅黑樹始終保持了logn的高度,從而也就解釋了上面所說的「紅黑樹的查詢、插入、刪除的時間複雜度最壞為O(log n)」這一結論成立的原因。更多請參見此文:《教你初步瞭解紅黑樹》。
後記
熟悉我的朋友可能已經知道,我個人從 2010 年開始在CSDN寫部落格,寫了十年,如今接近1700萬PV,創業做「七月線上」則已五年,五年已30多萬學員。這五年經歷且看過很多的人和事,比如我們的機器學習集訓營幫助了超過1000人就業、轉型、提升,他們就業後有的同學會分享面經,當看到那一篇篇透露著面經作者本人的那股努力、那股不服輸的勁的面經的時候,則讓我倍感勵志。比如「雙非渣本三年 100 次面試經歷精選:從最初 iOS 前端到轉型面機器學習」 這篇面經,便讓我印象非常深刻。在佩服主人公毅力和意志的同時,也對他願意分享對眾多人有著非常重要參考價值和借鑑意義的成功經驗倍感欣慰。
當然,類似的面經遠遠不止於此,後來我們整理出了100篇面經,彙總成冊為《名企AI面經100 篇:揭開三個月薪資翻倍的祕訣》,這 100 篇面經分為機器學習、深度學習、 CV、NLP、推薦系統、金融風控、計算廣告、資料探勘/資料分析八大方向。分享面經的作者各種背景都有,比如
- 科班,或非科班;
- 985、211,或雙非院校;
- 研究生或本科,甚至大專;
- 學生,或在職;
- 至於傳統IT轉型 AI 的就更多了,有從 Java、PHP、C、C++等偏後端服務轉型的,也有從 Android、iOS、前端等偏使用者端開發轉型的,當然也有資料分析、巨量資料方向等轉型的。
但令人振奮的是,他們都轉型成功了,而且他們中的很多人都通過集訓營/就業班三個月到半年的學習,成功實現薪資翻倍——這些成功的經驗就更值得借鑑了。
就業部的同事特地將這些寶貴的經驗整理出來,希望可以幫到更多人。
限於篇幅,完整版可以掃碼領取,新增時備註:領取面經100篇