面試真題總結:Faster Rcnn,目標檢測,折積,梯度消失,Adam演演算法
目標檢測可以分為兩大類,分別是什麼,他們的優缺點是什麼呢?
答案:目標檢測演演算法分為單階段和雙階段兩大類。單階段目標驗測演演算法(one-stage),代表演演算法有 yolo 系列,SSD 系列;直接對影象進行計算生成檢測結果,檢測速度快,但檢測精度低。雙階段目標驗測演演算法(two-stage),代表演演算法 RCNN 系列;先對影象提取候選框,然後基於候選區域做二次修正得到檢測點結果,檢測精度較高,但檢測速度較慢。【單階段偏應用,因為在精度沒有差很多的情況下,速度很快,就會選擇單階段目標檢測演演算法;雙階段偏比賽,只注重精度高低,速度不考慮】
Faster Rcnn,為什麼設定RPN這個層?RPN如果沒有的話,他會對大目標更好還是對小目標更好?問的是roi這一層呢?
答案:RPN的作用是生成合適的region proposals。網路結構分為一個折積層和一個兩分支的網路,其中一個分支是softmax分類網路,另一個用於bbox迴歸。具體的步驟是:生成anchors -> softmax分類器提取 positive anchors -> 對positive anchors進行bbox 迴歸 -> Proposal Layer綜合所有 positive anchors及其偏移量用來生成更精確的proposals。RPN最終就是在原圖尺度上,設定了密密麻麻的候選Anchor。然後用cnn去找出其中的positive anchors並對它進行迴歸,使得框的大小和位置更準確。生成anchor的過程:特徵圖上每個點都配備k個anchor,然後對每個anchor要做二分類和四個值的迴歸。
目標檢測預測的時候為什麼都會用到NMS?
NMS,一句話概括就是去除重複的檢測框。非極大值抑制,顧名思義就是抑制不是極大值的元素,在目標檢測中,就是提取置信度高的目標檢測框,而抑制置信度低的誤檢框。使用深度學習模型會檢測出很多目標框,具體數量由anchor數量決定,其中有很多重複的框定位到同一個目標,nms用來去除這些重複的框,獲得真正的目標框。
NMS程式碼實現:
import numpy as np
def NMS(dects,threshhold):
"""
input:
detcs:二維陣列(n_samples,5),5列:x1,y1,x2,y2,score
threshhold: IOU閾值
"""
x1=dects[:,0]
y1=dects[:,1]
x2=dects[:,2]
y2=dects[:,3]
score=dects[:,4]
ndects=dects.shape[0]#box的數量
area=(x2-x1+1)*(y2-y1+1)
order=score.argsort()[::-1] #score從大到小排列的indexs,一維陣列
keep=[] #儲存符合條件的index
suppressed=np.array([0]*ndects) #初始化為0,若大於threshhold,變為1,表示被抑制
for _i in range(ndects):
i=order[_i] #從得分最高的開始遍歷
if suppressed[i]==1:
continue
keep.append(i)
for _j in range(i+1,ndects):
j=order[_j]
if suppressed[j]==1: #若已經被抑制,跳過
continue
xx1=np.max(x1[i],x1[j])#求兩個box的交集面積interface
yy1=np.max(y1[i],y1j])
xx2=np.min(x2[i],x2[j])
yy2=np.min(y2[i],y2[j])
w=np.max(0,xx2-xx1+1)
h=np.max(0,yy2-yy1+1)
interface=w*h
overlap=interface/(area[i]+area[j]-interface) #計算IOU(交/並)
if overlap>=threshhold:#IOU若大於閾值,則抑制
suppressed[j]=1
return keep
【dects自己隨便設定個陣列測試即可】
折積網路里的感受野是什麼意思?
在折積神經網路CNN中,決定某一層輸出結果中一個元素所對應的輸入層的區域大小,被稱作感受野。用數學的語言感受野就是CNN中的某一層輸出結果的一個元素對應輸入層的一個對映。再通俗點的解釋是,feature map上的一個點對應輸入圖上的區域。
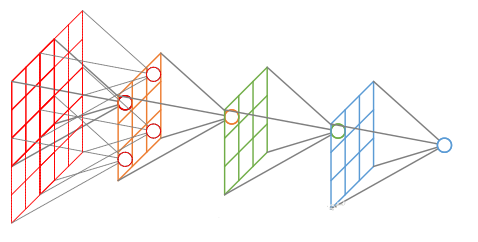
你都知道什麼啟用函數?
https://blog.csdn.net/weixin_46112766/article/details/109255872
梯度消失有什麼辦法規避麼?如何確定是否出現梯度爆炸?
首先我們要知道什麼情況屬於發生了梯度消失現象,如:模型無法從訓練資料中獲得更新(如低損失);模型不穩定,導致更新過程中的損失出現顯著變化;訓練過程中,模型損失變成 NaN。
解決辦法:
-
重新設計網路模型
梯度爆炸可以通過重新設計層數更少的網路來解決。使用更小的批尺寸
(batchsize)對網路訓練也有好處。另外也許是學習率(learning rate)過大導致的問題,減小學習率。 -
使用 ReLU 啟用函數
梯度爆炸的發生可能是因為啟用函數,如之前很流行的Sigmoid和Tanh函數。使用ReLU啟用函數可以減少梯度爆炸。採用ReLU啟用函數是最適合隱藏層的,是目前使用最多的啟用函數。
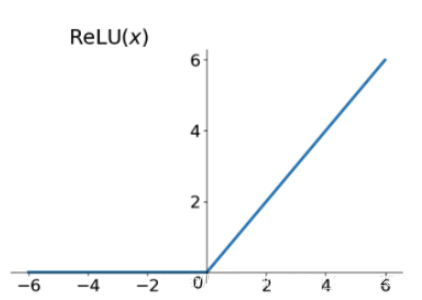
relu函數的導數在正數部分是恆等於1的,因此在深層網路中使用relu啟用函數就不會導致梯度消失和爆炸的問題。relu的主要貢獻在於解決了梯度消失、爆炸的問題計算方便,計算速度快,加速了網路的訓練同時也存在一些缺點:由於負數部分恆為0,會導致一些神經元無法啟用(可通過設定小學習率部分解決)輸出不是以0為中心的
-
使用leaky relu
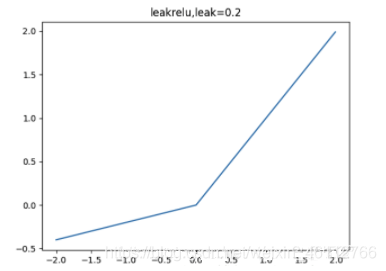
leak relu就是為了解決relu的0區間帶來的影響,而且包含了relu的所有優點,其數學表達為: l e a k y r e l u = m a x ( k ∗ x , x ) leaky relu = max(k*x,x) leakyrelu=max(k∗x,x);其中k是leaky係數,一般選擇0.01或者0.02,或者通過學習而來。
-
使用elu啟用函數
解決relu的0區間帶來的影響,其數學表達為:
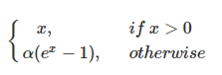
使用elu相對於leaky relu,計算更消耗時間一些。
-
使用梯度截斷(Gradient Clipping)
梯度剪下這個方案主要是針對梯度爆炸提出的,其思想是設定一個梯度剪下閾值,然後更新梯度的時候,如果梯度超過這個閾值,那麼就將其強制限制在這個範圍之內。這可以防止梯度爆炸。
-
使用權重正則化(Weight Regularization)
如果梯度爆炸仍然存在,可以嘗試另一種方法,即檢查網路權重的大小,並懲罰產生較大權重值的損失函數。該過程被稱為權重正則化,通常使用的是 L1 懲罰項(權重絕對值)或 L2 懲罰項(權重平方)。比如在tensorflow中,若搭建網路的時候已經設定了正則化引數,則呼叫以下程式碼可以直接計算出正則損失:
regularization_loss = tf.add_n(tf.losses.get_regularization_losses(scope='my_resnet_50'))正則化是通過對網路權重做正則限制過擬合,仔細看正則項在損失函數的形式: L o s s = ( y − W T x ) 2 + α ∣ ∣ W ∣ ∣ 2 Loss = (y-W^Tx)^2+\alpha||W||^2 Loss=(y−WTx)2+α∣∣W∣∣2,其中,α 是指正則項係數,如果發生梯度爆炸,權值的範數就會變的非常大,通過正則化項,可以部分限制梯度爆炸的發生。
事實上,在深度神經網路中,往往是梯度消失出現的更多一些。
-
預訓練加finetunning
其基本思想是每次訓練一層隱藏層節點,將上一層隱藏層的輸出作為輸入,而本層隱節點的輸出作為下一層隱節點的輸入,這就是逐層預訓練。在預訓練完成後,再對整個網路進行「微調」(fine-tunning)。Hinton在訓練深度信念網路(Deep Belief Networks中,使用了這個方法,在各層預訓練完成後,再利用BP演演算法對整個網路進行訓練。此思想相當於是先尋找區域性最優,然後整合起來尋找全域性最優,此方法有一定的好處,但是目前應用的不是很多了。現在基本都是直接拿imagenet的預訓練模型直接進行finetunning。
-
批次歸一化
Batchnorm具有加速網路收斂速度,提升訓練穩定性的效果,Batchnorm本質上是解決反向傳播過程中的梯度問題。batchnorm全名是batch normalization,簡稱BN,即批規範化,通過規範化操作將輸出訊號x規範化保證網路的穩定性。
-
殘差結構
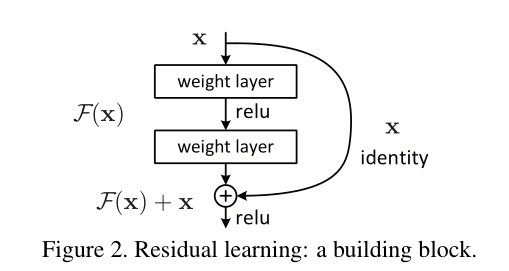
殘差網路的出現導致了image net比賽的終結,自從殘差提出後,幾乎所有的深度網路都離不開殘差的身影,相比較之前的幾層,幾十層的深度網路,殘差可以很輕鬆的構建幾百層,一千多層的網路而不用擔心梯度消失過快的問題,原因就在於殘差的捷徑(shortcut)部分,殘差網路通過加入 shortcut connections,變得更加容易被優化。包含一個 shortcut connection 的幾層網路被稱為一個殘差塊(residual block),如下圖:
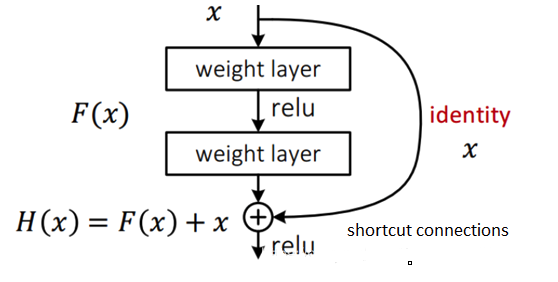
Adam演演算法你瞭解了麼?
Adam是對隨機梯度下降演演算法的擴充套件,Adam使用動量和自適應學習率來加快收斂速度。隨機梯度下降保持一個單一的學習速率(稱為alpha),用於所有的權重更新,並且在訓練過程中學習速率不會改變。每一個網路權重(引數)都保持一個學習速率,並隨著學習的展開而單獨地進行調整。Adam方法則是從梯度的第一次和第二次矩的預算來計算不同引數的自適應學習速率。
解釋下梯度下降?
https://blog.csdn.net/weixin_46112766/article/details/112308601
softmax的函數一般用在哪裡?怎麼計算的,softmax的函數輸出的結果是個標量還是個向量?
softmax函數一般用在分類任務的最後一層,進行一個概率化的輸出。結果是一個向量,具體計算請看啟用函數篇文章。
損失函數的意思是什麼?
https://blog.csdn.net/weixin_46112766/article/details/111314068
資料量是多少? 多少張(2000張),資料輸入的時候大小大概多大,即影象大小多大?是320*320還是224#224?你有沒有測過你的影格率是多少,多少毫秒一張影象,那你的主幹網路用的是什麼?
參考答案:資料量1-2w張左右,影格率20-30之間比較好,主幹網路就是一些常見的經典網路。
此題目是開放性題目,根據自己的專案情況回答即可。
大概講下deepsort的流程是什麼?指標是多少?
deepsort通過yolo等網路進行檢測,然後檢測出來的物體再通過卡爾曼濾波進行位置修正,最後匈牙利演演算法對前後幀的框進行匹配。
具體的deepsort,只執行 yolo 檢測, 速率大概為 11-13 fps, 新增 deep_sort 多目標追蹤後, 速率大概為 11.5 fps (顯示卡 GTX1060.)
fps:每秒鐘能傳輸多少幀
機器學習瞭解麼?瞭解哪些機器學習演演算法?
線性迴歸,kmeans,svm,神經網路,後面的深度學習折積神經網路,迴圈神經網路等。
Faster-RCNN的結構是什麼?
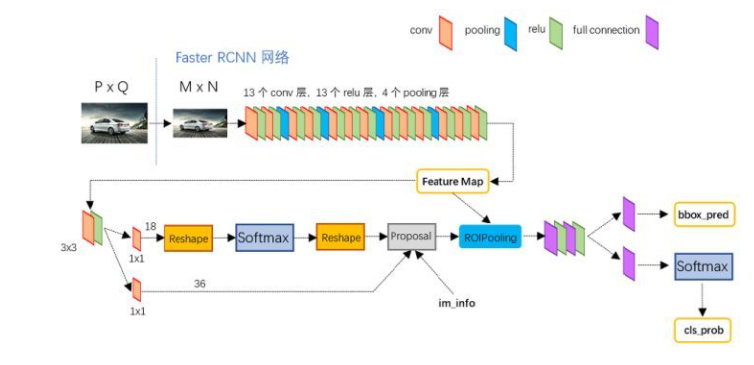
首先,Faster RCNN主要分為四個部分:折積層(backbone)、Region Proposal Networks、roi pooling和最後的分類迴歸網路。
折積層就是一般的分類模型,比如VGG-16和ResNet-101。在圖片輸入到折積層之前,會先resize到一定的尺寸,然後利用折積層提取特徵圖。
RPN網路用於生成region proposals。該層通過softmax判斷anchors屬於positive或者negative,再利用bounding box regression修正anchors獲得精確的proposals。
Roi Pooling收集輸入的feature maps和proposals,綜合這些資訊後提取proposal feature maps,送入後續全連線層判定目標類別。
最後的分類迴歸模組利用proposal feature maps計算proposal的類別,同時再次bounding box regression獲得檢測框最終的精確位置。迴歸的損失函數是smooth L1 loss,分類的損失函數是交叉熵損失。
anchor(就是檢測出來的那個框)是怎麼生成的?在每個網格上是怎麼生成的?
Faster rcnn中Anchor生成過程:Faster R-CNN中的Anchor有3種不同的尺度128×128,256×256,512×512 ,3種形狀也就是不同的長寬比W:H=1:1,1:2,2:1,這樣Feature Map中的點就可以組合出來9個不同形狀不同尺度的Anchor Box。
Faster R-CNN進行Anchor Box生成的Feature Map是原圖下取樣16倍得到的,這樣不同的長寬比實際上是將面積為16×16的區域,拉伸為不同的形狀,如下圖:
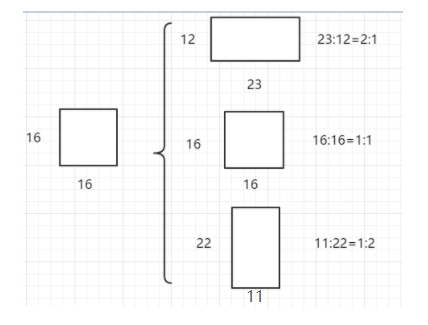
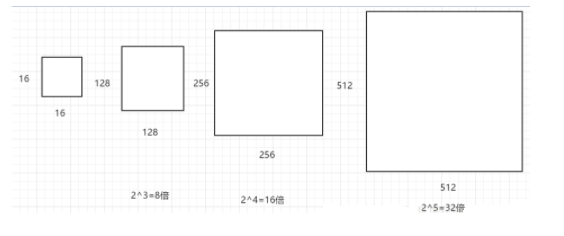
不同的ratio生成的邊框的面積是相同的,具有相同的大小。三種不同的面積(尺度),實際上是將上述面積為16×16的區域進行放大或者縮小。128×128是16×16放大8倍;256×256是放大16倍;512×512則是放大32倍。如下圖:
Yolo Anchor:YOLO v2,v3的Anchor Box 的大小和形狀是通過對訓練資料的聚類得到的。
採用標準的k-means方法。官方的 V2,V3的Anchor
anchors = 0.57273, 0.677385, 1.87446, 2.06253, 3.33843, 5.47434, 7.88282, 3.52778, 9.77052, 9.16828 (yolo v2)
anchors = 10,13, 16,30, 33,23, 30,61, 62,45, 59,119, 116,90, 156,198, 373,326 (yolo v3)
需要注意的是 anchor計算的尺度問題。
yolo v2的是相對最後一個Feature Map (13×13)來的,yolo v3則是相對於原始輸入影象的416×416的。
這也是在計算目標檢測中,邊框計算中需要注意的問題,就是計算的邊框究竟在相對於那個尺度得出的。
在一個 14*14的特徵圖上面,你認為有多少anchor?在哪裡生成?
答案:一個特徵圖上生成anchor數量的計算公式:【h * w * k】
w:影象的寬 h:影象的高 k:anchors的數量
此題的答案為: 14 ∗ 14 ∗ 9 14*14*9 14∗14∗9,每個畫素點生成k個anchor
畫素點在特徵圖上是怎麼反應的呢?那14*14的特徵圖上有多少個畫素點呢?
參照感受野得答案回答即可。
Resnet18網路結構下取樣的strides是多少?他有多少個下取樣層?
下取樣的步長是2
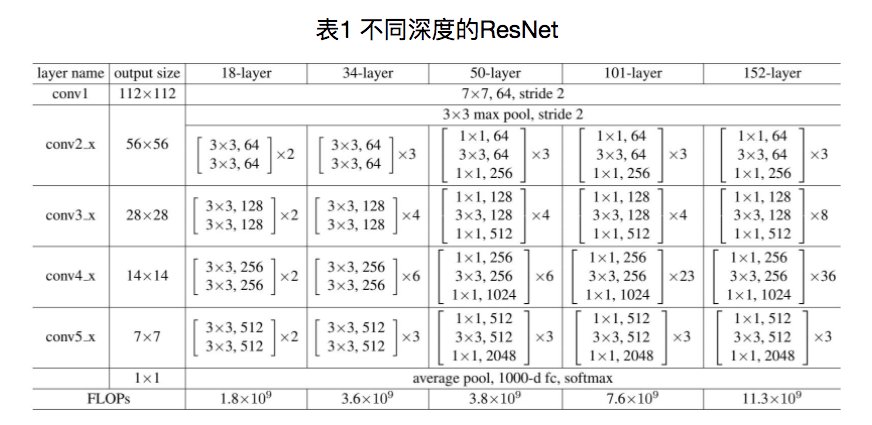
resnet18進行5次折積下取樣
Resnet18的bottlenets是什麼結構?Resnet的殘差結構是什麼?他有幾個階段?(有幾個塊兒)一般常用的有哪些Resnet?
殘差結構如圖所示:
折積實現的兩種方式:
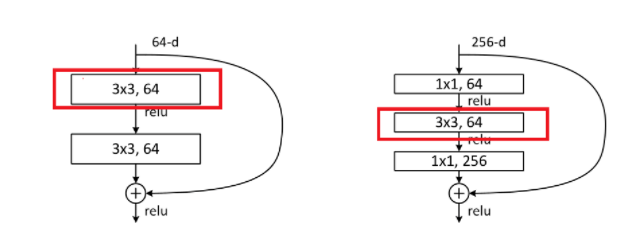
除了resnet18,還有resnet50/101/152
Faster-RCNN這樣的演演算法在兩個階段計算損失有多少個?兩個階段分別是什麼損失?
PRN階段會有迴歸box的loss和判斷前景和後景的loss。第二階段同樣會有精修box座標的loss和真正的分類loss
Faster-RCNN裡面,在做框迴歸的時候,有個迴歸的loss,為什麼不直接用框的座標直接計算loss?
無論是在RPN還是RoIHead中,迴歸結果都不是bounding box的座標,而是相對(正樣本anchor、RoI)中心點座標的位移和長寬比。為方便敘述,一般把兩者分別稱之為offset和scale。直觀地看,直接回歸bounding box的座標更方便,免去了傳參(RPN中需要傳入anchor,RoIHead中需要傳入RoI)與座標計算。但是,如果迴歸的是座標,那麼在計算損失時,大尺寸bbox的座標誤差佔的比重可能就會比小尺寸bbox之間的座標誤差大得多,從而使得模型更偏向於學習大bbox,從而導致小目標的檢測效果不佳。
在選anchor計算的時候,在迴歸框的時候,不是迴歸的座標,迴歸的是個差值,但實際上他在做偏值的時候,而是在偏值上乘個均值在除了個方差,這是為什麼呢?
為了對資料進行標註化處理
mask r-cnn的網路結構以及和Faster-RCNN的區別?
(多了一個網路分支)這兩個網路主要的區別在於mask rcnn在faster-rcnn的網路基礎上增加了一個分支進行mask的檢測。
ROI-align的實現原理?ROI-pooling 的區別?
在常見的兩級檢測框架(比如Fast-RCNN,Faster-RCNN,RFCN)中,ROI Pooling 的作用是根據預選框的位置座標在特徵圖中將相應區域池化為固定尺寸的特徵圖,以便進行後續的分類和包圍框迴歸操作。由於預選框的位置通常是由模型迴歸得到的,一般來講是浮點數,而池化後的特徵圖要求尺寸固定。故ROI Pooling這一操作存在兩次量化的過程。
- 將候選框邊界量化為整數點座標值。
- 將量化後的邊界區域平均分割成 k x k 個單元(bin),對每一個單元的邊界進行量化。
為了解決ROI Pooling的上述缺點,作者提出了ROI Align這一改進的方法。ROI Align的思路很簡單:取消量化操作,使用雙線性內插的方法獲得座標為浮點數的畫素點上的影象數值,從而將整個特徵聚集過程轉化為一個連續的操作。
BN層他在做前向和推理的時候有什麼區別?
https://www.jiqizhixin.com/articles/2021-01-06-6
mmask r-cnn在做評測時候 用的什麼評測指標?用什麼方法評測的?
主要是用了mAP進行效能指標的計算,即通過計算PR曲線的面積來衡量模型效能。
Focal loss 的思想介紹下?
針對樣本不平衡的情況下,使用Focal Loss作為損失函數,加強對於hard example的訓練!從而一定程度上解決樣本不平衡問題!它的核心思想就是:整體縮放Loss,易分類樣本縮放的比難分類樣本更多,從而損失函數中就凸顯了難分類樣本的權重,使得模型在訓練時更專注於難分類的樣本。
跟蹤演演算法介紹下?
deepsort演演算法是先用yolo進行每一幀的object的檢測然後通過卡爾曼濾波進行位置精修,最後配合匈牙利演演算法進行前後兩幀object的匹配。
臉部辨識是分類問題還是非分類問題?這種分類問題和常規的分類問題的區別在哪裡?
臉部辨識是分類問題,只不過人臉的這種分類,需要先檢測到人臉位置。對於人臉的多分類問題。有多少分類,取決於所處理問題的人臉庫大小,人臉庫中有多少目標人臉,就需要機器進行相應數量的細分類。如果想要機器認出每個他看到的人,則有多少人,人臉就可以分為多少類,而這些類別之間的區別是非常細微的。由此可見臉部辨識問題的難度。更不要提,這件事還要受到光照,角度,人臉部的裝飾物等各種因素的影響。比如在人臉的二分類問題中的Triplet loss是一個學習臉部辨識折積網路引數的好方法,他可以講臉部辨識當成一個二分類的方法。(如果問到Triplet loss相關的知識點和含義具體可參照課程和臉部辨識的檔案講述即可)
常用的臉部辨識的loss有哪些?
https://blog.csdn.net/intflojx/article/details/82378520
臉部辨識loss論文和知識點彙總,建議有時間可以看看:
含公式推導:https://zhuanlan.zhihu.com/p/64314762
loss上下姊妹篇:
上:https://zhuanlan.zhihu.com/p/34404607
下:https://zhuanlan.zhihu.com/p/34436551?refer=DCF-tracking
ps://zhuanlan.zhihu.com/p/64314762](https://zhuanlan.zhihu.com/p/64314762)
loss上下姊妹篇:
上:https://zhuanlan.zhihu.com/p/34404607
下:https://zhuanlan.zhihu.com/p/34436551?refer=DCF-tracking
focal loss(解決正負、難易樣本問題,用一句目標檢測)原理:https://zhuanlan.zhihu.com/p/80594704
作者根據朋友、學生及自己的面試經驗,整理成冊,名為《名企AI面經100篇:揭開三個月薪資翻倍的祕訣》,現免費分享給大家,祝大家早日進入心儀的公司!
注:可以掃碼領取,新增時備註:領取面經100篇
