嵌入式軟體開發工程師面指南_總結
嵌入式軟體開發工程師面指南
- 一、C語言
- 1.1、區域性變數能否和全域性變數重名
- 1.2、如何用C編寫死迴圈
- 1.2、new和malloc
- 1.3、static的用法(定義和用途)(必考)
- 1.4、const的用法(定義與用途)(必考)
- 1.5、const常數和#define的區別(編譯階段、安全性、記憶體佔用等)
- 1.6、volatile作用和用法
- 1.7、變數的作用域(全域性變數和區域性變數)
- 1.8、sizeof與strlen(字串,陣列)
- 1.9、與或非,互斥或。運運算元優先順序
- 1.10、遞迴函數與回撥函數的區別是什麼?
- 1.11、問什麼要用回撥函數呢?
- 1.12、const關鍵字的作用
- 1.13、系統呼叫和函數呼叫的區別
- 1.14、段錯誤發生的原因
- 1.15、段錯誤發生的原因
- 1.16、什麼時候會造成記憶體洩露
- 1.17、什麼是大小端模式
- 1.18、全域性變數可以宣告定義在標頭檔案中?
- 1.19、C語言中各種資料型別與"0"的比較詳解
- 1.20、c語言中什麼是位元欄
- 1.21、簡述什麼是地址傳遞和值傳遞,並簡述兩者的區別
- 1.21、c語言中呼叫函數如何返回多個值?
- 1.22、函數中能否返回一個區域性變數地址
- 1.23、棧的特點是什麼
- 1.24、c語言中用了#define,作用範圍是從哪到哪
- 1.25、c語言中定義常數有幾種方式
- 1.26、程式的區域性變數存在於哪裡,全域性變數存在於哪裡,動態申請資料存在於哪裡。
- 1.27、do……while和while有什麼區別?
- 二、Linux
- 三、資料結構
- 四、程序與執行緒
- 4.1、什麼是程序、執行緒、有什麼區別
- 4.2、多程序與多執行緒的優缺點
- 4.3、什麼時候用程序、什麼時候用執行緒
- 4.4、父程序、子程序
- 4.5、Fork的作用是什麼?
- 4.6、fork和vfork的區別
- 4.7、程序的開銷比執行緒大在了哪裡?
- 4.8、什麼是阻塞,什麼是非阻塞
- 4.9、同步和互斥
- 4.10、申請互斥鎖的過程
- 4.11、建立守護行程的步驟
- 4.12、指出靜態庫和共用庫的區別
- 4.13、什麼是 I/O 多路複用?
- 1.14、進執行緒的區別
- 1.15、一個程式中最多建立多少個執行緒
- 1.16、檔案io中的檔案描述符
- 1.17、執行緒中的同步應該怎麼實現
- 1.18、程序間通訊訊息佇列的機制
- 1.19、什麼是程序池
- 1.20、程序之間通訊的途徑有哪些?
- 1.21、產生死鎖的原因是什麼?
- 1.22、程序和執行緒有什麼區別?
- 五、網路程式設計
- 六、C++
- 七、Qt
- 八、ARM體系結構
- 九、系統移植
- 十、驅動
- 十一、Python
- 十二、微控制器
- 十三、雜項
- 跳轉:嵌入式軟體開發工程師面指南_總結
個人網站入口:http://www.baiziqing.cn/
一、C語言
1.1、區域性變數能否和全域性變數重名
能,區域性會遮蔽全域性。
1.2、如何用C編寫死迴圈
while(1){}或者for( ; ; )
1.2、new和malloc
1)、new和delete是c++的關鍵字,不需要標頭檔案,需要編譯器支援;malloc和free是c/c++的庫函數、需要帶標頭檔案stdlin.h
2)、使用new操作符申請記憶體分配時,無需指定記憶體塊的大小,編譯器會根據型別資訊自行計算;而malloc則需要支援本地所分配的大小。
3)、new操作符記憶體分配成功時,返回的是物件型別的指標;而malloc記憶體分配成功則返回void。
1.3、static的用法(定義和用途)(必考)
static 限制作用域
在C語言中,關鍵字static有三個明顯的作用:
1)、用static修飾區域性變數:使其變為靜態儲存方式,那麼這個區域性變數執行完成時不會被釋放,繼續保留在記憶體中。
2)、用static修飾全域性變數:使其在本檔案內部有效,而其他檔案不可以被參照或連結該變數。
3)、用static修飾函數:使函數只在本檔案內部有效,對其他檔案不可見,這樣的函數又叫靜態函數;使用靜態函數的好處,不用擔心與其他檔案的同名函數產生干擾,也是對函數本身保護的一種機制。
1.4、const的用法(定義與用途)(必考)
const主要用來修飾變數、函數形參和類成員函數:
1)、用const修飾常數:定義時就初始化,以後不能修改。
2)、用const修飾形參:func(const int a){ };該函數在函數內不能改變。
3)、用const修飾成員函數:該函數對成員變數只能進行唯讀操作,就是不能修改成員變數的數值。
下面的宣告都是什麼意思?
const int a;
int const a;
const int *a;
int * const a;
int const * a const;
第一和第二作業是一樣的,a是常整型數。
第三個意味著a是一個指向常整型數的指標。(整型數不可修改,但指標可以)
第四個意思是a是一個指向整型數的常數的指標。(指標指向的整型數是可以修改的,但指標是不可修改的)
第五個意味著a是一個指向整型數的常指標。(指標指向的整型數是不可修改的,同時指標也是不可修改的)
[scode type=「blue」]
結論和記憶方法: ***
(1)const 在 *前面,就表示const作用於p所指向的量。所以這時候p所指向的是個常數。
(2)const 在 *後面,表示p本身是常數,但是p指向的不一定是常數。
(3)*在const中間,表示p本身是常數,p指向的也是個常數。
[/scode]
1.5、const常數和#define的區別(編譯階段、安全性、記憶體佔用等)
用#define max 100;定義的常數沒有型別(不就行型別安全檢查,可能會引數意想不到的錯誤)所給出的是一個立即數,編譯器只是把所定義的常數值與所在的常數名字聯絡起來,define所定義的宏變數在預處理階段的時候進行替換,在程式中使用到該常數的地方都要進行拷貝替換。
用const int max = 255;定義的常數有型別(編譯時會進行型別檢查)名字,儲存在靜態區域中,在編譯時確定其值。在程式執行過程中const變數只有一個拷貝,而#define所定義的宏變數卻有多個拷貝,所以宏定義在程式執行過程中所消耗的記憶體比const變數的大很多。
1.6、volatile作用和用法
一個定義為volatile的變數是說這變數可能被意想不到的地改變,這樣不會假設這個變數的值了。
以下幾種情況都會用到volatile:
1)、並行裝置的硬體記憶體。
2)、一箇中斷服務子程式會存取到的非自動變數。
3)、多執行緒應用中被幾個任務共用的變數。
1.7、變數的作用域(全域性變數和區域性變數)
全域性變數:
在所以函數體外部定義,程式所在的部分(甚至其他檔案中的程式碼)都可以使用。
全域性變數不受作用域的影響(也就是全域性變數的生命週期一直到程式的結束)。
區域性變數:
出現在一個作用域內,它們是侷限於一個函數的。
區域性變數經常被稱為自動變數,它們進入作用域時自動生成,離開作用域時自動消失。
關鍵字auto可以顯式說明這個問題,但是區域性變數預設為auto。所以沒有必要宣告auto。
區域性變數可以和全域性變數重名,在區域性變數作用域範圍內,全域性變數失效,採用的是區域性變數的值。
1.8、sizeof與strlen(字串,陣列)
1)、如果是陣列:
#include<stdio.h>
int main()
{
int a[5]={1,2,3,4,5};
printf(「sizeof 陣列名=%d\n」,sizeof(a));
printf(「sizeof *陣列名=%d\n」,sizeof(*a));
}
執行結果:
sizeof 陣列名=20
sizeof *陣列名=4
2)、如果是指標,sizeof只會檢測到指標的型別,指標都是佔用4位元組的空間(32位元機)。
sizeof是什麼?是一個操作符,也是關鍵字,就不是一個函數,這和strlen()不同,strlen()是一個函數。
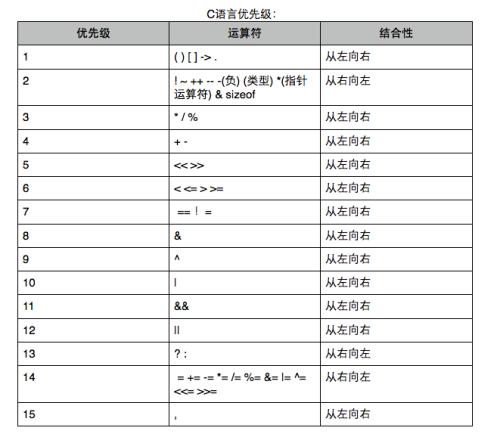
1.9、與或非,互斥或。運運算元優先順序
1.10、遞迴函數與回撥函數的區別是什麼?
答:回撥是一個函數把非當前函數當做引數傳遞到自身內部來呼叫;而遞迴是自己呼叫自己。
1.11、問什麼要用回撥函數呢?
答:我們對回撥函數的使用無非是對函數指標的應用,函數指標的概念本身很簡單,但是把函數指標應用於回撥函數就體現了一種解決問題的策略,一種設計系統的思想。
1.12、const關鍵字的作用
const是一個修飾符,被修飾的物件或者變數是不可修改的,也就是說const可讀不可改
1.13、系統呼叫和函數呼叫的區別
系統呼叫是最底層的應用,是面向硬體的。而庫函數的呼叫是面向開發的,相當於應用程式的API(即預先定義好的函數)介面;
1.14、段錯誤發生的原因
段錯誤 是指存取的記憶體超過了系統給程式分配的記憶體空間。
原因:
- 存取不存在的記憶體空間
- 存取唯讀的記憶體空間
- 存取系統保護的記憶體空間
- 棧溢位
1.15、段錯誤發生的原因
1.16、什麼時候會造成記憶體洩露
常見的記憶體洩露
(1)記憶體分配未成功,卻使用了它
(2)記憶體分配成功,但尚未初始化就參照它
(3)記憶體分配成功且初始化,但操作越過了記憶體的邊界
(4)忘記釋放記憶體,造成記憶體漏失
(5)釋放了記憶體卻繼續使用它
1.17、什麼是大小端模式
高位元組對應高地址(大端模式)、高位元組對應低地址(小端模式)
1.18、全域性變數可以宣告定義在標頭檔案中?
注意標頭檔案中不可以放變數的定義!!!一般情況下標頭檔案中只放變數的宣告,因為標頭檔案要被其他檔案包含(即#include),如果把定義放到標頭檔案的話,就不能避免多次定義變數,C++不允許多次定義變數,一個程式中對指定變數的定義只有一次,宣告可以無數次。
1.19、C語言中各種資料型別與"0"的比較詳解
1.19.1、int型別資料和0比較
1.19.1、int型別資料和0比較
if(a == 0)或者 if(a != 0)
1.19.2、float型別與0比較
const float N=0.0001;
if( (a>=N) && (a<=N)
不建議寫成:
if(a == 0)或者 if(a != 0)
1.19.3、bool型別與0比較
建議寫成:if(a)或者 if(!a)
1.19.4、指標型別與0比較
if(p == NULL) 或者 if(p != NULL)
1.20、c語言中什麼是位元欄
位元欄(bit-field)是以位為單位來定義結構體(或聯合體)中的成員變數所佔的空間。含有位元欄的結構體(聯合體)稱為位元欄結構。採用位元欄結構既能夠節省空間,又方便於操作。
1.21、簡述什麼是地址傳遞和值傳遞,並簡述兩者的區別
值傳遞只是將變數的內容複製一份而已,函數進行操作的其實是另一個變數,只是另一個變數的值和傳遞的變數值是相同的。
而地址傳遞是直接把變數的地址傳遞給函數,這時函數是直接對原來的變數進行操作的。所以值會變化。
1.21、c語言中呼叫函數如何返回多個值?
通過使用指標,在函數呼叫時,傳遞帶有地址的引數,並使用指標更改其值;這樣,修改後的值就會變成原始引數。
1.22、函數中能否返回一個區域性變數地址
一般的來說,函數是可以返回區域性變數的。 區域性變數的作用域只在函數內部,在函數返回後,區域性變數的記憶體已經釋放了。
1.23、棧的特點是什麼
棧的特點是先進後出表。棧是一種只能在一端進行插入和刪除操作的特殊線性表。它按照先進後出的原則儲存資料,先進入的資料被壓入棧底,最後的資料在棧頂,需要讀資料的時候從棧頂開始彈出資料。
1.24、c語言中用了#define,作用範圍是從哪到哪
define只在當前檔案有效,如果是在標頭檔案中定義的,則參照改標頭檔案的檔案都有效
1.25、c語言中定義常數有幾種方式
定義常數PI的兩種方式:
#define Pi 3.1415926f;
const float pi 3.1415926f;
1.26、程式的區域性變數存在於哪裡,全域性變數存在於哪裡,動態申請資料存在於哪裡。
程式的區域性變數存在於棧區;全域性變數存在於靜態區;動態申請資料存在於堆區。
1.27、do……while和while有什麼區別?
do…while是先回圈再判斷,while是先判斷再回圈。
二、Linux
2.1、 Linux核心的組成部分
Linux核心主要由五個子系統組成:程序排程,記憶體管理,虛擬檔案系統,網路介面,程序間通訊。
2.2、Linux系統的組成部分
Linux系統一般有4個主要部分:核心、shell、檔案系統和應用程式。
2.3、系統呼叫與普通函數呼叫的區別
1)、系統呼叫:
- 使用INT和IRET指令,核心和應用程核態,從而可以使用特權指令操控裝置
- 依賴於核心,不保證移植性
- 在使用者空間和核心上下文環境間切換
- 是作業系統的一個入口點
2)、普通函數呼叫:
- 使用CALL和RET指令,呼叫時沒有堆
- 平臺移植性好
- 屬於過程呼叫,呼叫開銷較小
- 一個普通功能函數的呼叫
2.4、核心態,使用者態的區別
核心態,作業系統在核心態執行——執行作業系統程式
使用者態,應用程式只能在使用者態執行——執行使用者程式
2.5、bootloader、核心、根檔案的關係
啟動順序:bootloader->linux kernel->rootfile->app
2.6 、Bootloader啟動的兩個階段:
Stage1:組合語言
Stage2:c語言
2.7、linux下檢查記憶體狀態的命令
檢視程序:top
檢視記憶體:free
cat /proc/meminfo
vmstat
2.8、一個程式從開始執行到結束的完整過程(四個過程)
預處理(Pre-Processing)、編譯(Compiling)、組合(Assembling)、連結(Linking)
2.9、什麼是堆,棧,記憶體漏失和記憶體溢位?
棧由系統操作,程式設計師不可以操作。
所以記憶體漏失是指堆記憶體的洩漏。
堆記憶體是指程式從堆中分配的,大小任意的,使用完後必須顯式釋放的記憶體。應用程式一般使用malloc,new等函數從堆中分配到一塊記憶體,使用完後,程式必須負責相應的呼叫free或delete釋放該記憶體塊,否則,這塊記憶體就不能被再次使用。
記憶體溢位:你要求分配的記憶體超出了系統能給你的,系統不能滿足需求,於是產生溢位。
記憶體越界:向系統申請了一塊記憶體,而在使用記憶體時,超出了申請的範圍(常見的有使用定大小陣列時發生記憶體越界)
記憶體溢位問題是 C 語言或者 C++ 語言所固有的缺陷,它們既不檢查陣列邊界,又不檢查型別可靠性(type-safety)。
2.10、死鎖的原因、條件
產生死鎖的原因主要是:
1)、因為系統資源不足。
2)、程序執行推進的順序不合適。
3)、資源分配不當等。
2.11、硬連結與軟連結
1)、硬連結
硬連結只能參照同一檔案系統中的檔案。它參照的是檔案在檔案系統中的物理索引(也稱為inode)。當您移動或刪除原始檔案時,硬連結不會被破壞,因為它所參照的是檔案的物理資料而不是檔案在檔案結構中的位置。
硬連結的檔案不需要使用者有存取原始檔案的許可權,也不會顯示原始檔案的位置,這樣有助於檔案的安全。如果您刪除的檔案有相應的硬連結,那麼這個檔案依然會保留,直到所有對它的參照都被刪除。
2)、軟連結
軟連線,其實就是新建立一個檔案,這個檔案就是專門用來指向別的檔案的(那就和windows 下的快捷方式的那個檔案有很接近的意味)。
軟連線產生的是一個新的檔案,但這個檔案的作用就是專門指向某個檔案的,刪了這個軟連線檔案,那就等於不需要這個連線,和原來的存在的實體原檔案沒有任何關係,但刪除原來的檔案,則相應的軟連線不可用。
2.12、中斷和異常的區別
內中斷:同步中斷(異常)是由cpu內部的電訊號產生的中斷,其特點為當前執行的指令結束後才轉而產生中斷,由於有cpu主動產生,其執行點必然是可控的。
外中斷:非同步中斷是由cpu的外設產生的電訊號引起的中斷,其發生的時間點不可預期。
2.13、中斷怎麼發生,中斷處理流程
請求中斷→響應中斷→關閉中斷→保留斷點→中斷源識別→保護現場→中斷服務子程式→恢復現場→中斷返回。
2.14、linux下編譯優化選項
加:-o
2.15、linux命令
1)、改變檔案屬性的命令:chmod (chmod 777 /etc/squid 執行命令後,sq
就被修改為777(可讀可寫可執行))
2)、查詢檔案中匹配字串的命令:grep
3)、查詢當前目錄:pwd
4)、刪除目錄:rm -rf 目錄名
5)、刪除檔案:rm 檔名
6)、建立目錄(資料夾):mkdir
7)、建立檔案:touch
8)、vi和vim 檔名也可以建立
9)、解壓:tar -xzvf 壓縮包
打包:tar -cvzf 目錄(資料夾)
10)、檢視程序對應的埠號
1、先檢視程序pid
ps -ef | grep 程序名
2、通過pid檢視佔用埠
netstat -nap | grep 程序pid
2.16、硬實時系統和軟實時系統
軟實時系統:
Windows、Linux系統通常為軟實時,當然有修補程式可以將核心做成硬實時的系統的。
硬實時系統:
對時間要求很高,限定時間內不管做沒做完必須返回。
VxWorks,uCOS,FreeRTOS,WinCE,RT-thread等實時系統;
三、資料結構
3.1、十大排序
我想對於每一個經歷過秋招的小夥伴們來說,十大排序基本都被問過(快速排序、歸併排序、堆排序、氣泡排序、插入排序、選擇排序、希爾排序、桶排序、基數排序)。
對這十大排序的考察主要有兩點:
1、考察時間複雜度、空間複雜度、穩定與否。
2、手寫某種排序。
第一點:對於時間複雜度的考察,可能會考察插入排序的平均複雜度是多少?最壞和最好複雜度又是多少?有時候也會從別的角度來對你進行考察,直接會問你瞭解到的的排序中哪些排序是穩定的?哪些不是穩定的?
第二點:快速排序手寫次數絕對佔據第一名,因為現在企業招聘基本都是有程式碼要求的,有時候面試官可能也拿不準讓你寫什麼演演算法題,「算了,寫個快排吧」,快排的頻率就是就是這樣被拉高的;第二高頻率的應該就是歸併排序了。在筆者秋招過程中,手寫過5次歸併,3次快排。因為歸併是剛好比快排難度大一點,但也不是那種特別難的排序方法。對於女生來說,讓手寫的排序一般是氣泡排序、快速排序、歸併排序,對於男生同學而言,要求手寫的排序一般有快速排序、歸併排序以及堆排序。
十大排序中考察最多的就是氣泡排序、快速排序、歸併排序、堆排序以及可能會出現的桶排序和基數排序了,其餘排序出現的概率稍小一點。
3.2、演演算法
嵌入式考察演演算法大多都是雙向連結串列、二元樹、字串翻轉和複製這些普通題目。刷題可以在LeetCode、牛客網、杭電OJ等。
十種常見排序演演算法可以分為兩大類:
非線性時間比較類排序:通過比較來決定元素間的相對次序,由於其時間複雜度不能突破O(nlogn),因此稱為非線性時間比較類排序。
線性時間非比較類排序:不通過比較來決定元素間的相對次序,它可以突破基於比較排序的時間下界,以線性時間執行,因此稱為線性時間非比較類排序。
3.3、佇列和棧的區別有什麼?
棧:
棧(stack)又名堆疊,線性表。僅允許在表的一端進行插入和刪除運算。這一端為棧頂,另一端為棧底,先進後出。
佇列:
佇列是一種特殊的線性表,特殊之處在於它只允許在表的前端(front)進行刪除操作,而在表的後端(rear)進行插入操作,和棧一樣,佇列是一種操作受限制的線性表。進行插入操作的端稱為隊尾,進行刪除操作的端稱為隊頭。
3.4、順序表和連結串列他們的特點?
線性表儲存資料,需要預先申請一塊儲存空間,然後將資料按照次序逐一儲存,資料之間緊密貼合,不留一絲空隙,
連結串列的儲存方式與順序表截然相反,什麼時候儲存資料,什麼時候才申請儲存空間,資料之間的邏輯關係依靠每個資料元素攜帶的指標維持
3.5、什麼是完全二元樹
如果二元樹中除去最後一層節點為滿二元樹,且最後一層的結點依次從左到右分佈,則此二元樹被稱為完全二元樹。
3.6、什麼是二元樹
樹有很多種, 每個節點最多隻能有兩個子節點的叫二元樹
二元樹的子節點分為左節點和右節點
3.7、七大查詢演演算法
順序查詢
二分查詢
插值查詢
斐波那契查詢
樹表查詢
分塊查詢
雜湊查詢
3.8、十大排序排序演演算法
(1)氣泡排序;
(2)選擇排序;
(3)插入排序;
(4)希爾排序;
(5)歸併排序;
(6)快速排序;
(7)基數排序;
(8)堆排序;
(9)計數排序;
(10)桶排序;
3.8、怎樣判斷一個演演算法的優劣?
時間複雜度
空間複雜度
3.9、"演演算法"的基本特徵有哪些?
一個演演算法應該具有以下五個重要的特徵:
1,有窮性(Finiteness)
2,確切性(Definiteness)
3,輸入項(Input)
4,輸入項(Input)
5,可行性(Effectiveness)
3.10、什麼是雜湊表
根據關鍵碼值而直接進行存取的資料結構
3.11、如何判斷單連結串列是否存在環
方法一、窮舉遍歷
方法二、雜湊錶快取
方法三、快慢指標
方法四、Set集合大小變化
3.12、刪除連結串列中倒數第n個節點
要刪除倒數第n個節點,我們就要找到其前面一個節點,也就是倒數第n+1個節點,找到這個節點就可以進行刪除;
定義兩個指標,p和cur,cur指標向前走,走了n+1步之後,p指標開始走,當cur指標走到連結串列結尾的時候,p指標剛好走到倒數第n+1個節點處。
3.13、迴圈佇列有什麼用
為充分利用向量空間,克服"假溢位"現象的方法是:將向量空間想象為一個首尾相接的圓環,並稱這種向量為迴圈向量。
四、程序與執行緒
4.1、什麼是程序、執行緒、有什麼區別
程序是資源(CPU、記憶體等)分配的基本單位,執行緒是CPU排程和分配的基本單位(程式執行的最小單位)。
同一時間,如果CPU是單核,只有一個程序在執行,所謂的並行執行,也是順序執行,只不過由於切換太快,誤以為這些程序同步執行。多核CPU可以同一時間點多個程序在執行。
4.2、多程序與多執行緒的優缺點
1)、一個程序死了不影響其他程序,一個執行緒奔潰很可能影響1到它本身所處在的執行緒。
2)、建立多程序的系統花銷大於建立多執行緒。
3)、多程序通訊因為需要跨域程序邊界,不適合大量的資料傳送,適合小資料或者密集的資料傳送。多執行緒無需跨域程序邊界,適合各執行緒間的大量傳送。並且多執行緒跨域共用同一程序的共用記憶體和變數。
4.3、什麼時候用程序、什麼時候用執行緒
程序間通訊:
(1)、有名管道、無名管道;(2)、訊號;(3)、共用記憶體;(4)、訊息佇列;(5)、號誌;(6)、socket
執行緒通訊(鎖):
(1)、號誌;(2)、讀寫鎖;(3)、條件變數;(4)、互斥鎖;(5)、自旋鎖
4.4、父程序、子程序
父程序呼叫fork()以後,克隆出一個子程序,子程序和父程序擁有相同內容的程式碼段、資料段和使用者堆疊。
父程序和子程序誰先執行不一定,看CPU。所以我們一般會設定父程序等待子程序執行完畢。
4.5、Fork的作用是什麼?
在Linux下產生新的程序的系統呼叫就是fork函數
4.6、fork和vfork的區別
- fork ():子程序拷貝父程序的資料段,程式碼段
vfork( ):子程序與父程序共用資料段 - fork ()父子程序的執行次序不確定
vfork 保證子程序先執行,在呼叫exec 或exit 之前與父程序資料是共用的,在它呼叫exec
或exit 之後父程序才可能被排程執行。
4.7、程序的開銷比執行緒大在了哪裡?
- 建立程序需要為程序劃分出一塊完整的記憶體空間,有大量的初始化操作,比如要把記憶體分段(堆疊、正文區等)。
- 建立執行緒則簡單得多,只需要確定 PC 指標 和暫存器 的值,並且給執行緒分配一個棧 用於執行程式,同一個程序的多個執行緒間可以複用堆疊 。
- 因此,建立程序比建立執行緒慢,而且程序的記憶體開銷更大。
4.8、什麼是阻塞,什麼是非阻塞
阻塞呼叫是指呼叫結果返回之前,當前執行緒會被掛起。呼叫執行緒只有在得到結果之後才會返回。
非阻塞呼叫指在不能立刻得到結果之前,該呼叫不會阻塞當前執行緒。
4.9、同步和互斥
互斥 :是指散步在不同任務之間的若干程式片斷,當某個任務執行其中一個程式片段時,其它任務就不能執行它們之中的任一程式片段,只能等到該任務執行完這個程式片段後才可以執行。
同步 :是指散佈在不同任務之間的若干程式片斷,它們的執行必須嚴格按照規定的某種先後次序來執行,這種先後次序依賴於要完成的特定的任務。
4.10、申請互斥鎖的過程
/*標頭檔案*/
#include <pthread.h>
1)初始化互斥鎖
int pthread_mutex_init(pthread_mutex_t *mutex, const pthread_mutexattr_t *attr);
2)上鎖
int pthread_mutex_lock(pthread_mutex_t *mutex);
3)解鎖
int pthread_mutex_unlock(pthread_mutex_t * mutex);
4)銷燬互斥鎖
int pthread_mutex_destroy(pthread_mutex_t *mutex);
4.11、建立守護行程的步驟
- 建立子程序,父程序退出
- 子程序下建立新的對談
- 設定當前目錄為根目錄
- 設定檔案許可權掩碼
- 退出檔案描述符
4.12、指出靜態庫和共用庫的區別
靜態庫編譯時程式較大,可以獨立執行。
動態庫編譯時程式交小,不可獨立執行。
4.13、什麼是 I/O 多路複用?
I/O 通常指網路 I/O,多路指多個 Socket 連結,複用指作業系統進行運算排程的最小單位執行緒 。整體意思也就是多個網路 I/O 複用一個或少量的執行緒來處理 Socket。
I/O 多路服用有多種實現模式:select、 poll、 epoll、 kqueue
1.14、進執行緒的區別
執行緒依賴於程序,同一程序的多個執行緒共用這一程序的資源。 所以程序間的切換會比執行緒更加的耗時。
1.15、一個程式中最多建立多少個執行緒
一個執行緒的棧要預留1M的記憶體空間,而一個程序中可用的記憶體空間只有2G,所以理論上一個程序中最多可以開2048個執行緒,但是記憶體當然不可能完全拿來作執行緒的棧,所以實際數目要比這個值要小。
1.16、檔案io中的檔案描述符
對於Linux而言,所有對裝置或檔案的操作都是通過檔案描述符進行的。
1.17、執行緒中的同步應該怎麼實現
當使用多個執行緒來存取同一個資料時,非常容易出現執行緒安全問題(比如多個執行緒都在操作同一資料導致資料不一致),所以我們用同步機制來解決這些問題。
1.18、程序間通訊訊息佇列的機制
訊息佇列與命名管道有許多類似之處,但少了在開啟和關閉管道時的複雜性。但使用訊息佇列並未解決我們在使用命名管道時遇到的問題,比如管道滿時的阻塞問題。
與命名管道相比,訊息佇列的優勢在於,它獨立於傳送和接收程序而存在,這消除了在同步命名管道的開啟和關閉時可能產生的一些困難。
1.19、什麼是程序池
程序池的作用是在多個使用者端並行請求時提高伺服器的處理效率。
1.20、程序之間通訊的途徑有哪些?
程序間通訊方式有:管道,訊號,號誌,訊息佇列,共用記憶體,通訊端共六種。
1.21、產生死鎖的原因是什麼?
系統資源有限。
程序推進順序不合理。
1.22、程序和執行緒有什麼區別?
程序是資源分配的最小單位。
執行緒是程式執行的最小單位,
五、網路程式設計
5.1、TCP、UDP的區別
TCP --> 傳輸控制協定,提供物件導向連線、可靠的位元組流服務。當用戶端和伺服器交換資料前,必須先在雙方之間建立一個TCP連線、之後才能傳輸資料。
UDP --> 使用者資料包協定,是一個簡單的面向資料包的運算層協定。UDP不提供可靠性,它是把應用程式傳給IP層的資料包傳送出去,但是並不能保證它們能到達目的地。
| TCP | <–> | UDP |
|---|---|---|
| TCP是面向連線 | UDP面向無連線 | |
| UDP程式結構簡單 | ||
| TCP是面向位元組流 | UDP是基於資料包 | |
| TCP保證資料正確性 | UDP可能丟包 | |
| TCP保證資料順序到達 | UDP不保證資料到達 |
4.5、TCP、UDP的優缺點
TCP優點:可靠穩定
TCP的可靠體現在TCP在傳輸資料之前,會有三次握手來建立連線,而且在資料傳遞時,有確認、視窗、重傳、阻塞控制機制,在資料傳完之後,還會斷開來連線用來節約系統資源。
TCP缺點:慢、效率低、佔用系統資源高、容易被攻擊
在傳遞資料之前要建立連線,這會消耗時間,而且在資料傳遞時,確認機制、重傳機制、阻塞機制等會消耗大量時間,而且每臺裝置上維護所有的傳遞連線。
UDP優點:快,比TCP稍安全
UDP沒有TCP擁有各種機制,是一種無狀態的傳輸協定,所以傳輸資料非常快,沒有TCP整型機制,被攻擊的機會就少一些,但也是無法避免被攻擊。
UDP缺點:不可靠、不穩定
因為沒有TCP的這些機制,UDP在傳輸資料時,如果網路品質不好,就會容易丟包,造成資料的缺失。
4.5、TCP、UDP適用場景
TCP:傳輸一些對訊號完整性,訊號品質有要求的資訊。
UDP:對網路通訊品質要求不高時,要求網路通訊速度要快的場景。
4.5、TCP為什麼是可靠連線
因為TCP傳輸的資料滿足3大條件,不丟失,不重複,按順序到達。
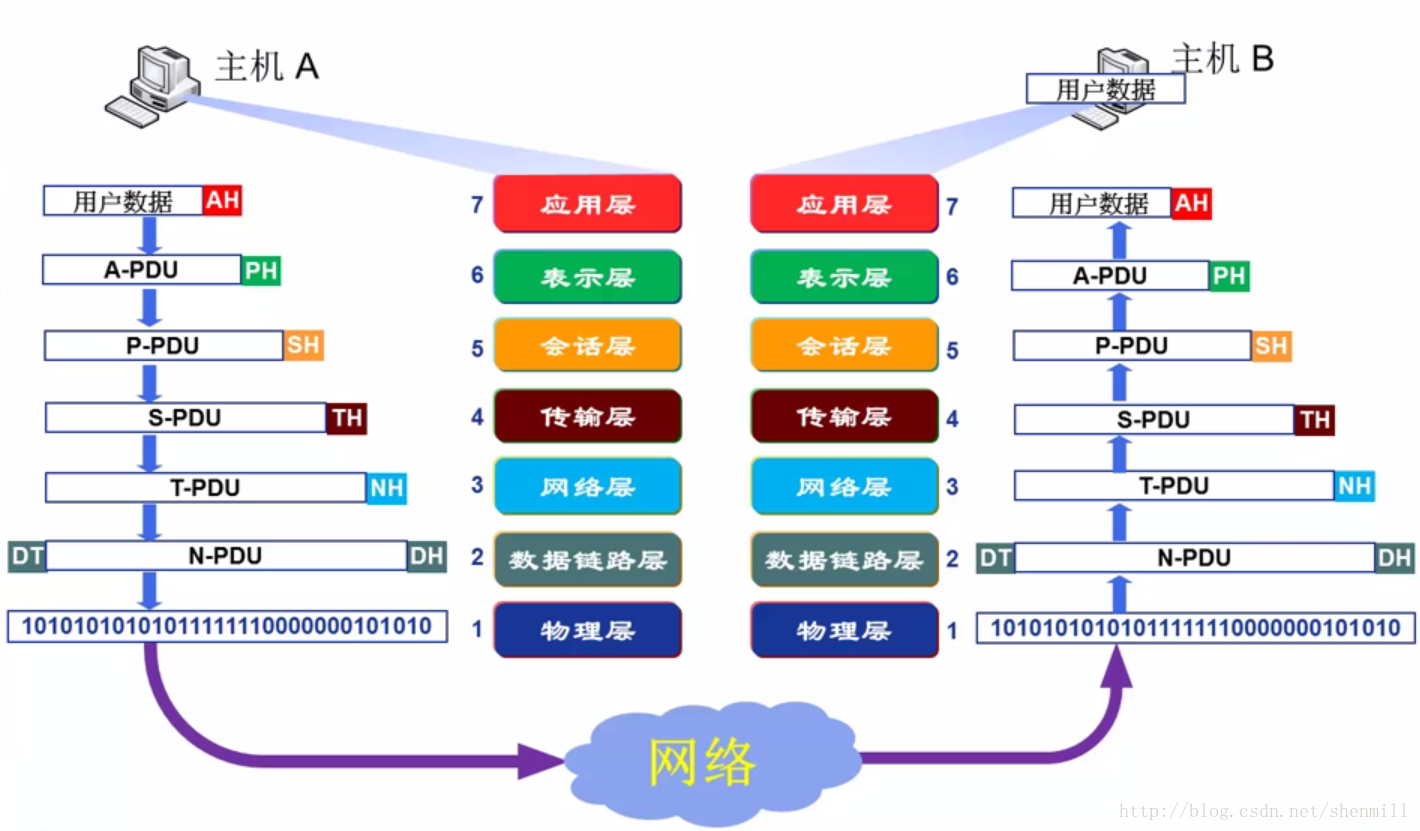
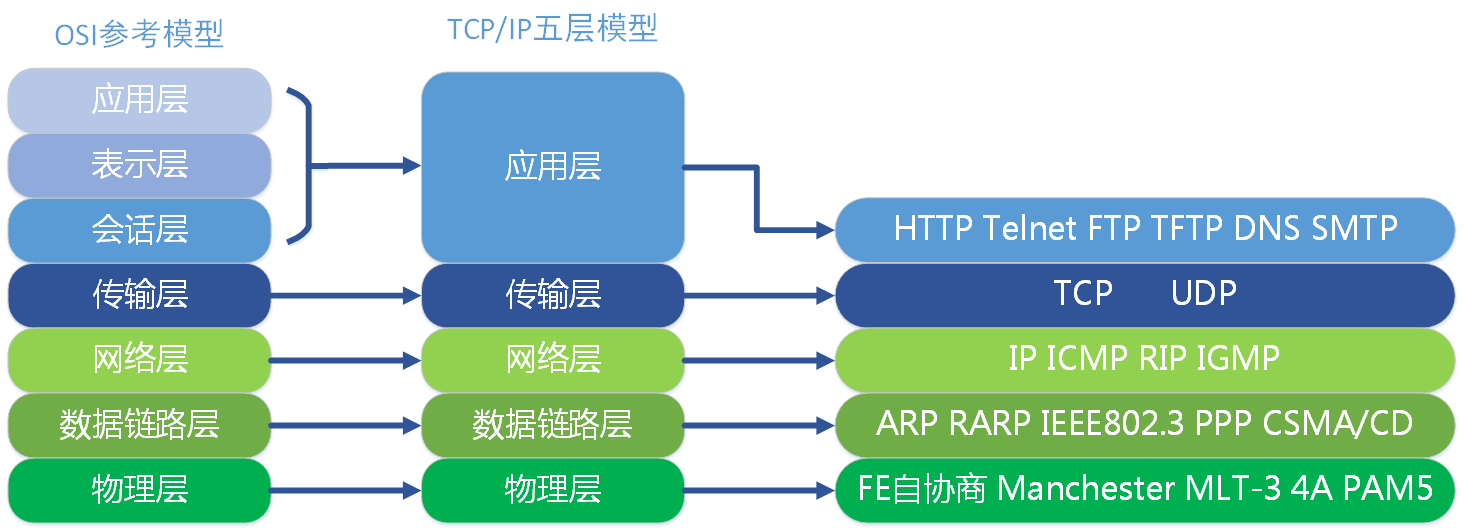
5.6、OSI典型網路模型 ★★★
5.7、三次握手、四次揮手
1)、三次握手過程
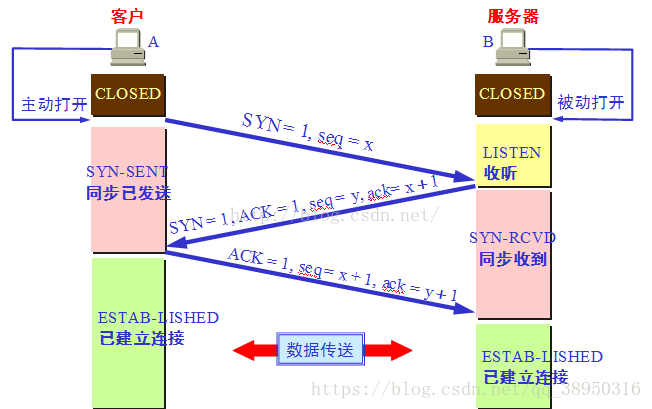
- 第一次握手:建立連線時,使用者端傳送syn包(syn=x)到伺服器,並進入SYN_SENT狀態,等待伺服器確認;SYN:同步序列編號(Synchronize Sequence Numbers)。
- 第二次握手:伺服器收到syn包,必須確認客戶的SYN(ack=x+1),同時自己也傳送一個SYN包(syn=y),即SYN+ACK包,此時伺服器進入SYN_RECV狀態;
- 第三次握手:使用者端收到伺服器的SYN+ACK包,向伺服器傳送確認包ACK(ack=y+1),此包傳送完畢,使用者端和伺服器進入ESTABLISHED(TCP連線成功)狀態,完成三次握手。
TCP/IP建立連線是三次握手過程:
第一次:建立連線時,使用者端向伺服器傳送連線請求,進入SYN_END狀態,並等待伺服器確認。
第二次:伺服器收到使用者端連線請求,並向用戶端傳送允許連線應答,進入SYN_RECV狀態。
第三次:使用者端收到伺服器允許連線應答,並向伺服器傳送確認連線,此時使用者端和伺服器進入通訊狀態,三次握手完成。
2)、四次揮手過程
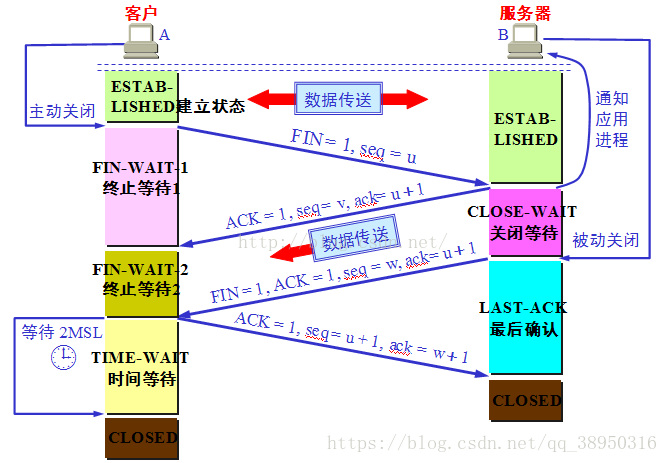
- 1.使用者端程序發出連線釋放報文,並且停止傳送資料。釋放資料包文首部,FIN=1,其序列號為seq=u(等於前面已經傳送過來的資料的最後一個位元組的序號加1),此時,使用者端進入FIN-WAIT-1(終止等待1)狀態。 TCP規定,FIN報文段即使不攜帶資料,也要消耗一個序號。
- 2.伺服器收到連線釋放報文,發出確認報文,ACK=1,ack=u+1,並且帶上自己的序列號seq=v,此時,伺服器端就進入了CLOSE-WAIT(關閉等待)狀態。TCP伺服器通知高層的應用程序,使用者端向伺服器的方向就釋放了,這時候處於半關閉狀態,即使用者端已經沒有資料要傳送了,但是伺服器若傳送資料,使用者端依然要接受。這個狀態還要持續一段時間,也就是整個CLOSE-WAIT狀態持續的時間。
- 3.使用者端收到伺服器的確認請求後,此時,使用者端就進入FIN-WAIT-2(終止等待2)狀態,等待伺服器傳送連線釋放報文(在這之前還需要接受伺服器傳送的最後的資料)。
- 4.伺服器將最後的資料傳送完畢後,就向用戶端傳送連線釋放報文,FIN=1,ack=u+1,由於在半關閉狀態,伺服器很可能又傳送了一些資料,假定此時的序列號為seq=w,此時,伺服器就進入了LAST-ACK(最後確認)狀態,等待使用者端的確認。
[collapse status=「false」 title=「常見面試題:」]
【問題1】為什麼連線的時候是三次握手,關閉的時候卻是四次握手? ★★★
答:三次握手時,伺服器同時把ACK和SYN放在一起傳送到了使用者端那裡。
四次揮手時,當收到對方的 FIN 報文時,僅僅表示對方不再傳送資料了但是還能接收資料,己方是否現在關閉傳送資料通道,需要上層應用來決定,因此,己方 ACK 和 FIN 一般都會分開傳送。
【問題2】為什麼使用者端最後還要等待2MSL?
答:使用者端需要保證最後一次傳送的ACK報文到伺服器,如果伺服器未收到,可以請求使用者端重發,這樣使用者端還有時間再發,重新啟動2MSL計時。
【問題3】為什麼不能用兩次握手進行連線?
答:3次握手完成兩個重要的功能,既要雙方做好傳送資料的準備工作(雙方都知道彼此已準備好),也要允許雙方就初始序列號進行協商,這個序列號在握手過程中被傳送和確認。
【問題4】如果已經建立了連線,但是使用者端突然出現故障了怎麼辦?
TCP還設有一個保活計時器,顯然,使用者端如果出現故障,伺服器不能一直等下去,白白浪費資源。伺服器每收到一次使用者端的請求後都會重新復位這個計時器,時間通常是設定為2小時,若兩小時還沒有收到使用者端的任何資料,伺服器就會傳送一個探測報文段,以後每隔75秒鐘傳送一次。若一連傳送10個探測報文仍然沒反應,伺服器就認為使用者端出了故障,接著就關閉連線。
[/collapse]
5.8、常見網路協定
TCP/IP協定
NetBEUI
IPX/SPX協定
5.9、處理粘包問題
解決粘包問題: 就是轉換成傳送資料和接收資料的格式,
傳送資料: 傳送資料,先傳送資料的長度,然後在傳送真實資料的位元組數;
接收資料: 接收真實資料的長度,然後在安置位元組長度接收資料;
5.10、ip地址分了多少類
A類:0 ~ 127.255.255.255
B類:128 ~ 191.255.255.255
C類:192 ~ 223.255.255.255
D類:224 ~ 239.255.255.255
E類:240 ~ 255.255.255.255
六、C++
最喜歡問的莫過於strlen與sizeof的區別、explicit關鍵字、mutable關鍵字、指標和參照、public、protected、private三者在繼承情況下的一些存取許可權、菱形繼承、友元函數等。這些隨便一本基礎的C++書籍都會講到。
6.1、構造和解構的作用
建構函式只是起初始化值的作用,但範例化一個物件的時候,可以通過範例去傳遞引數,從主函數傳遞到其他的函數裡面,這樣就使其他的函數裡面有值了。
解構函式與建構函式的作用相反,用於復原物件的一些特殊任務處理,可以是釋放物件分配的記憶體空間
特點:解構函式與建構函式同名,但該函數前面加~。 解構函式沒有引數,也沒有返回值,而且不能過載
6.2、繼承是做什麼的?
繼承是指一個物件直接使用另一物件的屬性和方法
6.3、多型是做什麼?
多型首先是建立在繼承的基礎上的,先有繼承才能有多型。多型是指不同的子類在繼承父類別後分別都重寫覆蓋了父類別的方法,即父類別同一個方法,在繼承的子類中表現出不同的形式。
6.4、物件導向中的物件指的是什麼?
就是範例化了的類。類是屬性和方法的封裝。物件是 這個類的具體實現。
6.5、類和物件的關係是什麼?
物件是類範例化出來的,物件中含有類的屬性,類是物件的抽象。
6.6、類的關鍵詞用什麼
class
6.7、如果想要在類的外部存取類
C public的類成員
可以作為虛擬函式的是普通函數,解構函式。
6.8、友元有哪些呢?
友元函數就是以friend開頭的一種破壞類的封裝性的一種用法
友元類的私有和保護成員在類外不可以使用
6.9、繼承的作用是什麼?
繼承是指在已存在的類的基礎上擴充套件產生新的類。
意義:繼承是物件導向程式設計的三大特徵(封裝、繼承和多型)之一
6.10、組合和繼承的區別是什麼?
組合和繼承是物件導向中兩種程式碼複用的方式。組合是指在新類中建立原有類的物件,重複利用已有類的功能。繼承是物件導向的主要特性之一,它允許設計人員根據其他類的實現來定義一個類的實現。
6.11、多型指的是什麼?
多型首先是建立在繼承的基礎上的,先有繼承才能有多型。多型是指不同的子類在繼承父類別後分別都重寫覆蓋了父類別的方法,即父類別同一個方法,在繼承的子類中表現出不同的形式。多型成立的另一個條件是在建立子類時候必須使用父類別new子類的方式。
6.12、什麼是抽象類,抽象類怎麼使用?
抽象類是特殊的類,只是不能被範例化;除此以外,具有類的其他特性;重要的是抽象類可以包括抽象方法,這是普通類所不能的。
如果預計要建立元件的多個版本,則建立抽象類。抽象類提供簡單的方法來控制元件版本。
如果建立的功能將在大範圍的全異物件間使用,則使用介面。如果要設計小而簡練的功能塊,則使用介面。
如果要設計大的功能單元,則使用抽象類.如果要在元件的所有實現間提供通用的已實現功能,則使用抽象類。
抽象類主要用於關係密切的物件;而介面適合為不相關的類提供通用功能。
6.13、malloc 和 new的區別?
malloc/free是標準庫函數,new/delete是C++運運算元
malloc失敗返回空,new失敗拋異常
new/delete會呼叫構造、解構函式,malloc/free不會,所以他們無法滿足動態物件的要求。
new返回有型別的指標,malloc返回無型別的指標
6.14、深拷貝和淺拷貝的區別是什麼?
淺拷貝(shallowCopy)只是增加了一個指標指向已存在的記憶體地址,
深拷貝(deepCopy)是增加了一個指標並且申請了一個新的記憶體,使這個增加的指標指向這個新的記憶體,使用深拷貝的情況下,釋放記憶體的時候不會因為出現淺拷貝時釋放同一個記憶體的錯誤。
七、Qt
八、ARM體系結構
8.1、講一講馮諾依曼和哈佛體系的區別
哈佛結構:
程式和資料分開獨立放在不同的記憶體塊中, 彼此完全分離的結構稱為哈佛結構。譬如 大部分的單(MCS51、 ARM9等)均採用哈佛結構。
馮·諾伊曼結構:
程式和資料都放在記憶體中,且不彼此分離 的結構稱為馮諾依曼結構。譬如Intel的 CPU均採用馮諾依曼結構。
8.2、什麼是ARM體系架構
ARM體系結構包含有:
(1)結構
- 不同ARM體系採用不同指令集
- 哈佛結構是將資料與指令分開儲存並行
- 馮諾依曼結構是混合儲存的
(2)ARM工作模式
User 、FIQ、IRQ、System、Supervisor、Abort、Undef
(3)暫存器
ARM有37個暫存器
(4)ARM指令機器碼
8.3、什麼的異常
正常工作之外的流程都叫異常
九、系統移植
9.1、什麼是裝置樹
裝置樹:用樹型結構描述裝置節點
十、驅動
10.1、什麼是驅動?
控制硬體的軟體
驅動是專門為系統編寫的組態檔,沒有驅動電腦便無法正常執行,簡單來說,驅動是連線電腦和其他硬體的必備程式。
十一、Python
十二、微控制器
12.1、 IO口工作方式(學過STM32的人應該很熟悉)
上拉輸入、下拉輸入、推輓輸出、開漏輸出。
12.2、請說明匯流排介面USRT、I2C、USB的異同點
串/並、速度、全/半雙工、匯流排拓撲等。
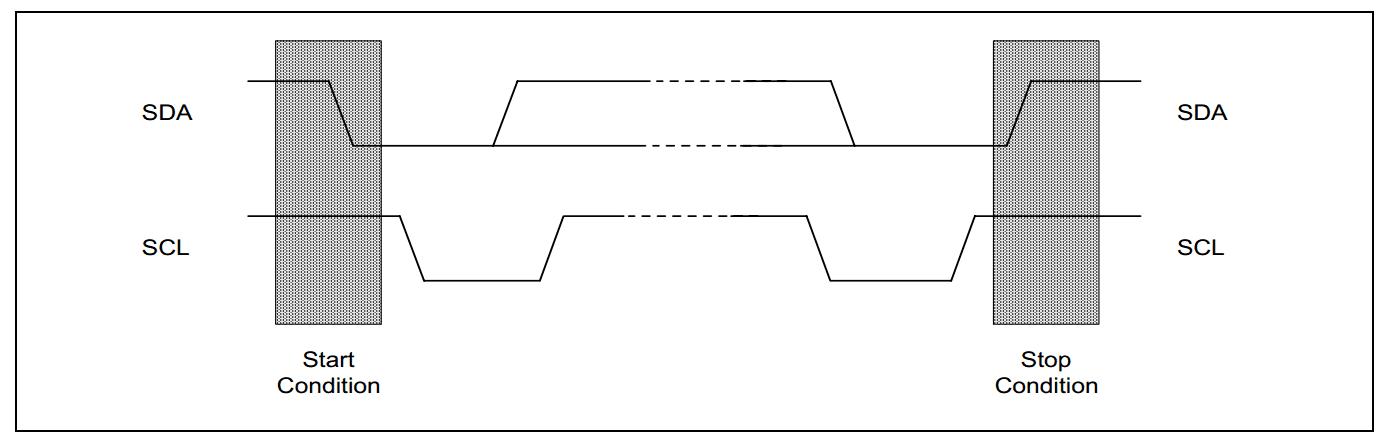
12.3、IIC協定時序圖
12.4、微控制器的SP指標始終指向
棧頂
12.5、IIC匯流排在傳送資料過程中共有三種型別訊號
它們分別是:開始訊號、結束訊號和應答訊號。
12.6、FIQ中斷向量入口地址
FIQ和IRQ是兩種不同型別的中斷,ARM為了支援這兩種不同的中斷,提供了對應的叫做FIQ和IRQ處理器模式(ARM有7種處理模式)。
FIQ的中斷向量地址在0x0000001C,而IRQ的在0x00000018。
12.7、SPI四種模式,簡述四種模式,並畫出時序圖
spi四種模式SPI的相位(CPHA)和極性(CPOL)分別可以為0或1,對應的4種組合構成了SPI的4種模式(mode)
Mode 0 CPOL=0, CPHA=0
Mode 1 CPOL=0, CPHA=1
Mode 2 CPOL=1, CPHA=0
Mode 3 CPOL=1, CPHA=1
簡述四種模式,並畫出時序圖參考連結:https://www.cnblogs.com/gmpy/p/12461461.html
十三、雜項
13.1、高耦合低內聚
高內聚低耦合,是軟體工程中的概念,是判斷軟體設計好壞的標準,主要用於程式的物件導向的設計,主要看類的內聚性是否高,耦合度是否低。目的是使程式模組的可重用性、移植性大大增強。通常程式結構中各模組的內聚程度越高,模組間的耦合程度就越低。
13.2、什麼是溢位,什麼是越界
溢位本義是算術溢位(arithmetic overflow),指算術計算結果無法在一定範圍內表示,細分上溢(overflow)和下溢(underflow)。
越界即存取越界(access out of range),指對儲存的存取不在預先指定的界限內。
邏輯上來說可能造成存取越界的計算結果也可以看成一種溢位,這是引申義。只不過兩種情況經常一起出現,所以混用了。