如何保證 Redis 高可用和高並行(主從+哨兵+叢集)
1. 概述
Redis 作為一種高效能的記憶體資料庫,普遍用於目前主流的分散式架構系統中。為了提高系統的容錯率,使用多範例的 Redis 也是必不可免的,但同樣複雜度也相比單範例高出很多。
那麼如何保證 Redis 的高並行和高可用?
Redis 主要有三種叢集方式用來保證高並行和高可用:主從複製,哨兵模式和叢集。
2. 主從複製
在分散式系統中為了解決單點問題,通常會把資料複製多個副本部署到其他機器,滿足故障恢復和負載均衡等需求。Redis 也是如此,它為我們提供了複製功能,實現了相同資料的多個 Redis 副本。
複製功能是高可用 Redis 的基礎,哨兵和叢集都是在複製的基礎上實現高可用的。
在複製的概念中,資料庫分為兩類。一類是主資料庫(master),一類是從資料庫(slave)。 master 可以進行讀寫操作,當寫操作發生變化時,會自動將資料同步給 slave。
slave 一般只提供讀操作,並接收主資料庫同步過來的資料。
一個 master 可以對應多個 slave。一個 slave 只能對應一個 master。
引入主從複製的目的有兩個:
- 讀寫分離,分擔 master 的壓力;
- 二是容災備份。
Redis 的複製拓撲結構可以支援單層或多層複制關係,根據拓撲復雜性可以分為以下三種:一主一從、一主多從、樹狀主從結構。
2.1 一主一從
1、建立複製
參與複製的 Redis 範例劃分為主節點(master)和從節點(slave)。預設情況下,Redis 都是主節點。每個從節點只能有一個主節點,而主節點可以同時具有多個從節點。複製的資料流是單向的,只能由主節點複製到從節點。
設定複製的方式有以下三種 :
-
組態檔
組態檔中加入
slaveof {masterHost } {masterPort},隨 Redis 啟動生效。 -
啟動命令
在 redis-server 啟動命令後加入
--slaveof {masterHost} {masterPort }生效。 -
使用者端命令
Redis伺服器啟動後,直接使用命令
slaveof {masterHost} { masterPort}生效。
綜上所述,slaveof 命令在使用時,可以執行期動態設定,也可以提前寫到組態檔中。
為了方便測試,我們在同一臺虛擬機器器上啟動 2 個 Redis 範例,埠分別為 6379 和 6380,由於在同一臺機器上,所以需要修改 6380 的組態檔,主要修改以下幾個選項:
# 埠號
port 6380
# 紀錄檔檔案
logfile "/usr/local/redis/log/6380.log"
# 快照檔案
dbfilename 6380-dump.rdb
# 快照檔案存放路徑
dir ../
此時分別啟動 6379 和 6380,這裡的 6379 埠由於之前的操作所以存在一部分資料,而 6380 由於上面組態檔的改動,所以並不會存在資料。
6379:
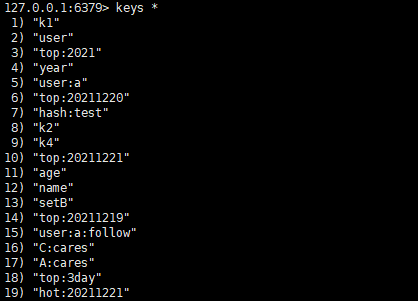
6380:

注:可通過以下命令進入指定埠的使用者端
./redis-cli -h ip -p port -a password
# 進入 6380 無密碼
./redis-cli -h 127.0.0.1 -p 6380
然後在127.0.0.1:6380執行如下命令:
slaveof 127.0.0.1 6379
slaveof 設定都是在從節點發起,這時 6379 作為主節點,6380 作為從節點。
複製關係建立後再去執行命令,可以看到如下:
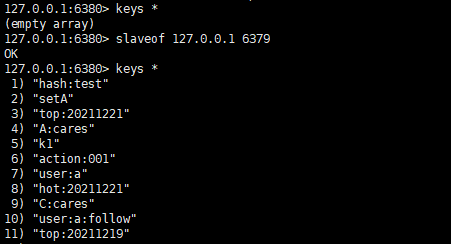
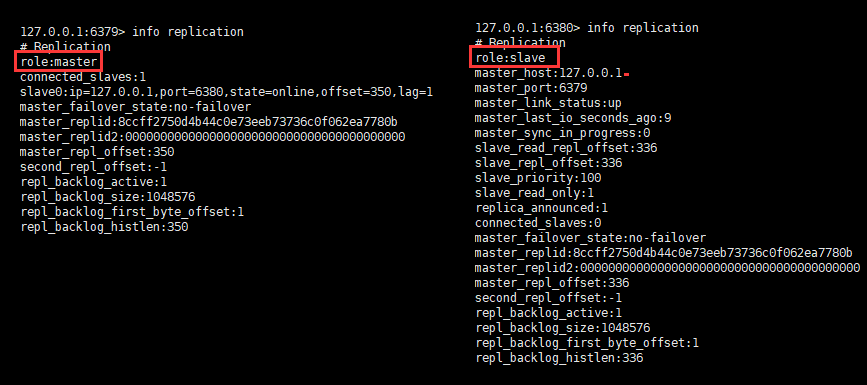
slaveof 本身是非同步命令,執行 slaveof 命令時,節點只儲存主節點資訊後返回,後續複製流程在節點內部非同步執行。主從節點複製成功建立後,可以使用 info replication 命令檢視複製相關狀態。
2、斷開復制
slaveof 命令不但可以建立複製,還可以在從節點執行以下命令來斷開與主節點複製關係。
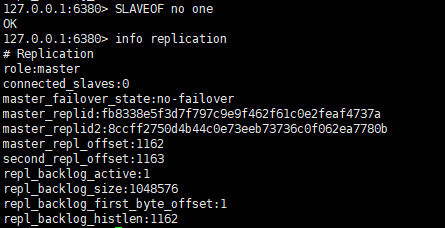
slaveof no one
例如在 6380 節點上執行 slaveof no one 來斷開復制。流程如下:
- 斷開與主節點複製關係;
- 從節點晉升為主節點。
從節點斷開復制後並不會拋棄原有資料,只是無法再獲取主節點上的資料變化。
3、切主
通過 slaveof 命令還可以實現切主操作,所謂切主是指把當前從節點對主節點的複製切換到另一個主節點。執行 slaveof {newMasterIp} {newMasterPort}命令即可。
流程如下:
- 斷開與舊主節點複製關係;
- 與新主節點建立複製關係;
- 刪除從節點當前所有資料;
- 對新主節點進行復制操作。
4、唯讀
預設情況下,從節點使用以下命令設定為唯讀模式。
slave-read-only = yes
由於複製只能從主節點到從節點,對於從節點的任何修改主節點都無法感知,修改從節點會造成主從資料不一致。因此建議線上不要修改從節點的唯讀模式。
5、傳輸延遲
實際上,主從節點一般部署在不同機器上,複製時的網路延遲就成為需要考慮的問題,Redis 為我們提供了以下引數用於控制是否關閉 TCP_NODELAY,預設關閉。
repl-disable-tcp-nodelay no
當關閉時,主節點產生的命令資料無論大小都會及時地傳送給從節點,這樣主從之間延遲會變小,但增加了網路頻寬的消耗。適用於主從之間的網路環境良好的場景,如同機架或同機房部署。
當開啟時,主節點會合並較小的 TCP 封包從而節省頻寬。預設傳送時間間隔取決於 Linux 的核心,一般預設為 40 毫秒。這種設定節省了頻寬但增大主從之間的延遲。適用於主從網路環境複雜或頻寬緊張的場景,如跨機房部署。
2.2 一主多從
一主多從針對讀較多的場景,讀由多個從節點來分擔,但節點越多,主節點同步到從節點的次數也越多,影響頻寬,也加重主節點的穩定。
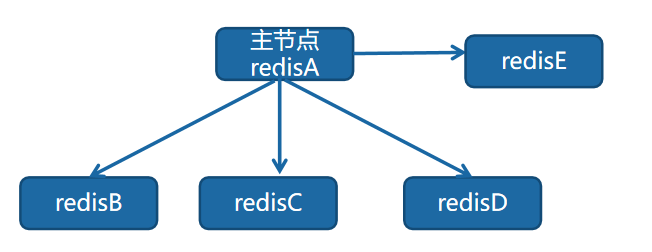
在實際場景中,主從節點一般部署在不同機器上,上面演示的操作雖然在一臺機器,但實際上就是一主一從的模式,這裡演示在 3 臺虛擬機器器上演示一主多從。
| IP | 埠 | 角色 |
|---|---|---|
| 192.168.153.128 | 6379 | master |
| 192.168.153.129 | 6379 | slave |
| 192.168.153.130 | 6379 | slave |
對於設定方式同樣採取上述方式進行設定,但還存在slaveof命令之外的設定方式,在redis.conf組態檔中可通過設定replicaof 的方式來設定:
replicaof <masterip> <masterport>
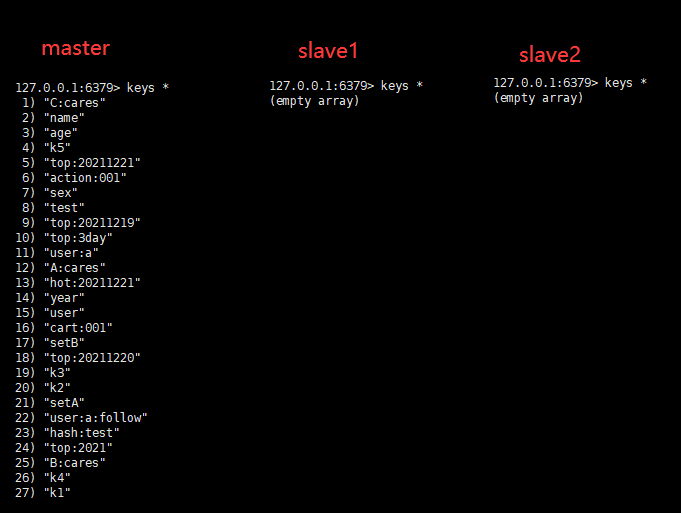
在未設定之前,我們檢視主節點和兩個從節點的資料:
然後通過組態檔的方式來設定並啟動。
1、主節點設定
實際上主節點無需做過多設定,但為了安全性可以設定從節點密碼(這裡不對組態檔做過多介紹,見文末附):
masterauth:123456789
我這裡為了方便演示不做任何設定。
2、從節點設定
兩從節點和主節點設定也類似,但從節點需要指定主節點的 IP 和埠,如下:
# slave1
replicaof 192.168.153.128 6379
# slave2
replicaof 192.168.153.128 6379
3、啟動
在啟動從節點時發現同步失敗,報錯如下:
1525:S 28 Dec 2021 20:50:29.690 # Error condition on socket for SYNC: Connection refused
1525:S 28 Dec 2021 20:50:30.714 * Connecting to MASTER 192.168.153.129:6379
1525:S 28 Dec 2021 20:50:30.714 * MASTER <-> REPLICA sync started
首先想到的是防火牆問題,在網上尋找解決方案時說是沒有開放埠,防火牆相關操作如下:
# 檢視狀態
systemctl status firewalld
# 啟動
systemctl start firewalld
# 開放埠
firewall-cmd --add-port=6379/tcp --permanent --zone=public
#重新啟動防火牆(修改設定後要重新啟動防火牆)
firewall-cmd --reload
## 其他命令
# 關閉
systemctl stop firewalld
# 開機禁用
systemctl disable firewalld
# 開機啟用
systemctl enable firewalld
但開啟防火牆之後還是不能解決問題,最後的解決方案為:
在redis主伺服器上的redis.conf中修改bind欄位,將:
bind 127.0.0.1
修改為:
bind 0.0.0.0
或者直接註釋掉bind欄位。
其主要原因是如果Redis主伺服器繫結了127.0.0.1,那麼跨伺服器 IP 的存取就會失敗,從伺服器用 IP 和埠存取主節點的時候,主伺服器發現本機 6379 埠綁在了 127.0.0.1 上,也就是隻能本機才能存取,外部請求會被過濾,這是 Linux 的網路安全策略管理的。如果 bind 的IP地址是192.168.153.128,那麼本機通過localhost和127.0.0.1、或者直接輸入命令redis-cli登入本機 Redis 也就會失敗了。只能加上本機 IP 才能存取到。
所以,在研發、測試環境可以考慮bind 0.0.0.0,線上生產環境建議繫結 IP 地址。
設定完成之後,啟動從節點會自動同步資料。
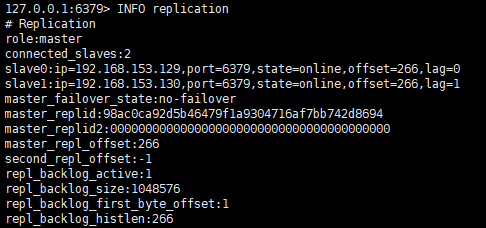
然後通過info replication命令在主節點檢視角色資訊:
192.168.153.128:6379> info replication
# Replication
# 主節點
role:master
# 從節點資訊
connected_slaves:2
slave0:ip=192.168.153.130,port=6379,state=online,offset=392,lag=0
slave1:ip=192.168.153.129,port=6379,state=online,offset=392,lag=0
master_failover_state:no-failover
master_replid:0a46120facfa0e24c05f9881057dc2fb5bfe5aee
master_replid2:0000000000000000000000000000000000000000
master_repl_offset:392
second_repl_offset:-1
repl_backlog_active:1
repl_backlog_size:1048576
repl_backlog_first_byte_offset:1
repl_backlog_histlen:392
另外的錯誤
如果啟動報如下錯誤:
1525:S 28 Dec 2021 20:50:29.690 * Connecting to MASTER 192.168.0.96:6379
1525:S 28 Dec 2021 20:50:29.690 * MASTER <-> REPLICA sync started
1525:S 28 Dec 2021 20:50:29.690 * Non blocking connect for SYNC fired the event.
1525:S 28 Dec 2021 20:50:29.690 * Master replied to PING, replication can continue...
1525:S 28 Dec 2021 20:50:29.690 * Partial resynchronization not possible (no cached master)
1525:S 28 Dec 2021 20:50:29.690 * Master is currently unable to PSYNC but should be in the future: -NOMASTERLINK Can't SYNC while not connected with my master
可能的原因如下:
-
你的主伺服器自定義了密碼,那麼從伺服器在連線時要指定主伺服器的密碼(上面測試未設定密碼);
-
主伺服器設定成了 slave 模式(從伺服器),登入使用者端,用
slaveof no one命令改回來。我就是設定 IP 時把主節點設定為自己了。
4、測試驗證
然後我們在主節點(master)新增資料,看從節點(slave)是否可以獲取到,如果能獲取,說明資料已經同步到了從節點,如下:
主節點:
192.168.153.128:6379> set master test
OK
從節點:
192.168.153.129:6379> get master
test
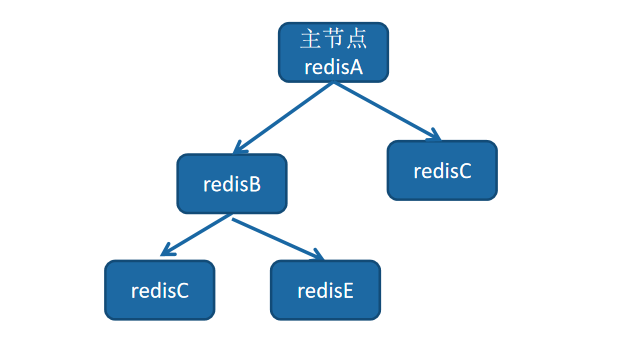
2.3 樹狀主從
樹狀主從結構,它可以使得從節點不但可以複製主節點資料,同時可以作為其他從節點的主節點繼續向下層複製。
通過引入複製中間層,可以有效降低主節點負載和需要傳送給從節點的資料量,它解決了一主多從的缺點(主節點推播次數多壓力大)。
對於其搭建這裡不做演示,因為一般用得少。
3. Redis Sentinel
3.1 主從複製的問題
Redis 的主從複製模式可以將主節點的資料改變同步給從節點,這樣從節點就可以起到兩個作用:
- 作為主節點的一個備份,一旦主節點出了故障不可達的情況,從節點可以作為後備頂上來,並且保證資料儘量不丟失(主從複製是最終一致性)。
- 從節點可以擴充套件主節點的讀能力,一旦主節點不能支撐住大並行量的讀操作,從節點可以在一定程度上幫助主節點分擔讀壓力。
但是主從複製也帶來了以下問題:
- 一旦主節點出現故障,需要手動將一個從節點晉升為主節點,同時需要修改應用方的主節點地址,還需要命令其他從節點去複製新的主節點,整個過程都需要人工干預。
- 主節點的寫能力受到單機的限制。
- 主節點的儲存能力受到單機的限制。
其中第一個問題就是 Redis 的高可用問題,可以通過Redis Sentinel實現高可用。第二、三個問題屬於 Redis 的分散式問題,需要使用 Redis Cluster,這裡先說Redis Sentinel。
3.2 可用性分析
為了方便描述,這裡先對幾個名詞做一下解釋:
| 名詞 | 說明 |
|---|---|
| 主節點(master) | Redis 主服務,一個獨立的 Redis 程序 |
| 從節點(slave) | Redis 從服務,一個獨立的 Redis 程序 |
| Redis 資料節點 | 即上面的主節點和從節點的統稱 |
| Sentinel 節點 | 監控 Redis 資料節點,一個獨立的 Sentinel 程序 |
| Sentinel 節點集合 | 若干 Sentinel 節點的組合 |
| Redis Sentine | Redis 高可用實現方案,Sentinel 節點集合和 Redis 資料節點集合 |
| 應用方 | 泛指一個或多個使用者端一個或者多個使用者端程序或者執行緒 |
Redis 主從複製模式下,一旦主節點出現了故障不可達,需要人工干預進行故障轉移,無論對於 Redis 的應用方還是運維方都帶來了很大的不便。
對於應用方來說無法及時感知到主節點的變化,必然會造成一定的寫資料丟失和讀資料錯誤,甚至可能造成應用方服務不可用。
對於 Redis 的運維方來說,整個故障轉移的過程是需要人工來介入的,故障轉移實時性和準確性上都無法得到保障。
當主節點出現故障時,Redis Sentinel 能自動完成故障發現和故障轉移,並通知應用方,從而實現真正的高可用。
Redis Sentinel 是一個分散式架構,其中包含若干個 Sentinel 節點和 Redis 資料節點,每個 Sentinel 節點會對資料節點和其餘 Sentinel 節點進行監控,當它發現節點不可達時,會對節點做下線標識。如果被標識的是主節點,它還會和其他 Sentinel 節點進行協商,當大多數 Sentinel 節點都認為主節點不可達時,它們會選舉出一個 Sentinel 節點來完成自動故障轉移的工作,同時會將這個變化實時通知給 Redis 應用方。整個過程完全是自動的,不需要人工來介入,所以這套方案很有效地解決了 Redis 的高可用問題。
注:這裡的分散式是指 Redis 資料節點、Sentinel 節點集合、使用者端分佈在多個物理節點的架構。
Redis Sentinel 與 Redis 主從複製模式相比只是多了若干 Sentinel 節點,所以 Redis Sentinel 並沒有針對 Redis 節點做了特殊處理。
從邏輯架構上看,Sentinel 節點集合會定期對所有節點進行監控,特別是對主節點的故障實現自動轉移。
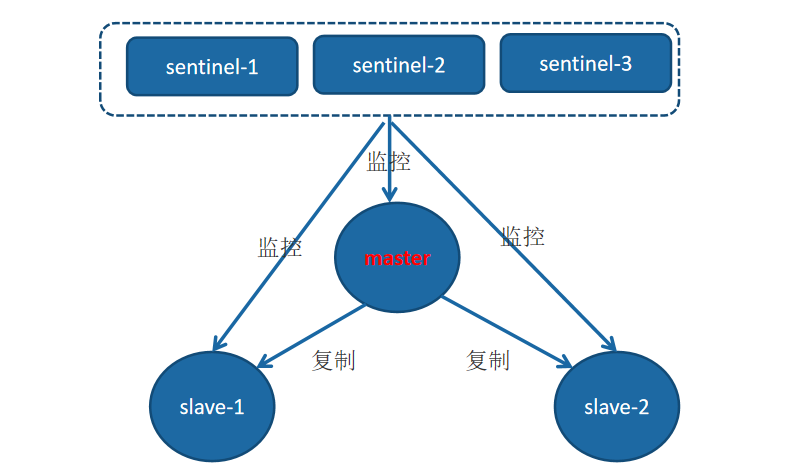
下面以 1 個主節點、2 個從節點、3 個 Sentinel 節點(官方檔案中建議為 3個)組成的 Redis Sentinel 為例子進行說明。
整個故障轉移的處理邏輯有下面 4 個步驟:
- 主節點出現故障,此時兩個從節點與主節點失去連線,主從複製失敗;
- 每個 Sentinel 節點通過定期監控發現主節點出現了故障;
- 多個 Sentinel 節點對主節點的故障達成一致,選舉出其中一個節點(假如為 sentinel-3)作為領導者負責故障轉移。
- Sentinel 領導者節點執行了自動化故障轉移,包括通知使用者端,重新選擇主節點,建立新的複製關係等等。
3.3 主要功能
通過上面介紹的 Redis Sentinel 邏輯架構以及故障轉移的處理,可以看出Redis Sentinel 具有以下幾個功能:
- 監控:Sentinel 節點會定期檢測 Redis 資料節點、其餘 Sentinel 節點是否可達;
- 通知:Sentinel 節點會將故障轉移的結果通知給應用方;
- 主節點故障轉移:實現從節點晉升為主節點並維護後續正確的主從關係;
- 設定提供者:在 Redis Sentinel 結構中,使用者端在初始化的時候連線的是 Sentinel 節點集合,從中獲取主節點資訊。
同時看到,Redis Sentinel 包含了若個 Sentinel 節點,這樣做也帶來了兩個好處
- 對於節點的故障判斷是由多個 Sentinel 節點共同完成,這樣可以有效地防止誤判;
- Sentinel 節點集合是由若干個 Sentinel 節點組成的,這樣即使個別 Sentinel 節 點不可用,整個 Sentinel 節點集合依然是健壯的。
但是 Sentinel 節點本身就是獨立的 Redis 節點,只不過它們有一些特殊,它們不儲存資料,只支援部分命令。
3.4 部署
這裡仍然使用三臺伺服器搭建 Redis Sentinel,3個 Redis 範例(1主2從)+ 3個哨兵範例,即一主兩從三哨兵。
3.4.1 部署 Redis 節點
| IP | 埠 | 角色 |
|---|---|---|
| 192.168.153.128 | 6379 | master |
| 192.168.153.129 | 6379 | slave |
| 192.168.153.130 | 6379 | slave |
通過在主從複製踩的坑,我們這邊直接把 Redis 範例的組態檔設定好。
1、主節點設定
# 允許所有 IP 連線,上面說過,生產環境為具體的 IP
bind 0.0.0.0
protected-mode yes
# 埠號
port 6379
# 後臺執行,可自行設定
daemonize yes
# 指定slave唯讀
replica-read-only yes
# 指定登入密碼,為方便測試不設定
# requirepass "123456"
# 指定 master 節點登入密碼,為方便測試不設定
# masterauth "123456"
2、從節點設定
基本設定和主節點相同,bind 地址各自對應各自的。
bind 0.0.0.0
# 指定master的ip,埠資訊
replicaof 192.168.153.128 6379
3、啟動
先啟動主節點,在啟動 2 個從節點。
注:我這裡清空了主節點的所有資料(FLASHALL),生產環境勿用。
然後檢視主從關係:
3.4.2 部署 Sentinel 節點
3個 Sentinel 節點的部署方法和設定是完全一致的,在 Redis 原始碼包下存在sentinel.conf檔案,Sentinel 節點的預設埠是 26379。
| IP | 埠 | 角色 |
|---|---|---|
| 192.168.153.128 | 26379 | sentinel-1 |
| 192.168.153.129 | 26379 | sentinel-2 |
| 192.168.153.130 | 26379 | sentinel-3 |
1、組態檔
# 埠預設為26379。
port 26379
# 關閉保護模式,可以外部存取,允許遠端連線。
protected-mode no
# 設定為後臺啟動。
daemonize yes
# 指定主機IP地址和埠,並且指定當有2臺哨兵認為主機掛了,則對主機進行容災切換。
sentinel monitor mymaster 192.168.153.128 6379 2
# 當在Redis範例中開啟了requirepass,這裡就需要提供密碼,這裡暫未設定。
# sentinel auth-pass mymaster 123456
# 設定5秒內沒有響應,說明伺服器掛了,需要將設定放在sentinel monitor master 192.168.153.128 6379 2下面
sentinel down-after-milliseconds mymaster 5000
# 設定18 秒內 master 沒有活起來,就重新選舉主節點,預設3分鐘
sentinel failover-timeout mymaster 180000
# 主備切換時,最多有多少個slave同時對新的master進行同步,這裡設定為預設的1。
# 表示如果 master 重新選出來後,其它 slave 節點能同時並行從新 master 同步快取的臺數有多少個,顯然該值越大,所有 slave 節點完成同步切換的整體速度越快,但如果此時正好有人在存取這些 slave,可能造成讀取失敗,影響面會更廣。最保定的設定為1,只同一時間,只能有一臺幹這件事,這樣其它 slave 還能繼續服務,但是所有 slave 全部完成快取更新同步的程序將變慢。
snetinel parallel-syncs mymaster 1
2、啟動 Sentinel 節點
Sentinel 節點的啟動方法有兩種,兩種方法本質上是—樣的。
-
使用 redis-sentinel 命令
./redis-sentinel ../sentinel.conf -
redis-server 命令加 --sentinel 引數
./redis-server ../sentinel.conf --sentinel
啟動之後如下:

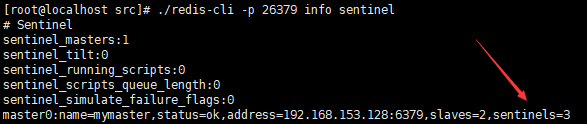
Sentinel 節點本質上是一個特殊的 Redis 節點,所以也可以通過 info 命令來查詢它的相關資訊,從下面 info 的 Sentinel 片段來看,Sentinel 節點找到了主節點 192.168.153.128:6379,發現了它的兩個從節點。
./redis-cli -p 26379 info sentinel
至此 Redis Sentinel 已經搭建起來了,整體上還是比較容易的,但是需要注意的是 Redis Sentinel 中的資料節點和普通的 Redis 資料節點在設定上沒有任何區別,只不過是新增了一些 Sentinel 節點對它們進行監控。
3.5 高可用測試
Sentinel 主要作用就是高可用,此時我們模擬主機宕機,即關掉主節點。
./redis-cli -p 6379 shutdown
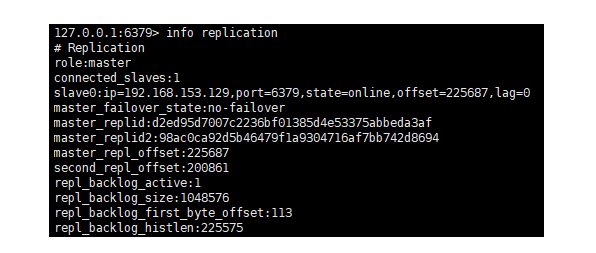
此時,在從節點通過info replication發現192.168.153.130變為了主節點,如下:
192.168.153.130
192.168.153.129
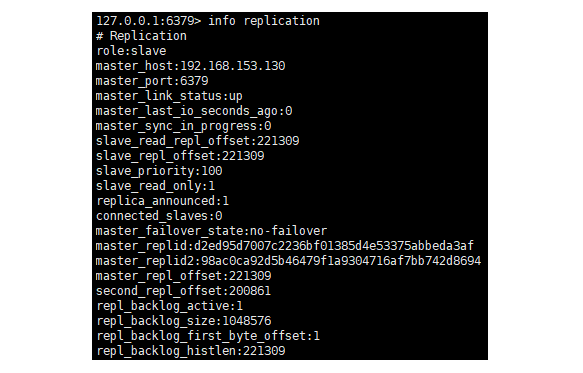
此時,通過哨兵機制,選舉了新的主節點,並把從節點重新選擇了新選舉出來的主節點。
需要注意的是,主從切換後組態檔會被自動更改。
3.6 部署建議
1、Sentinel 節點不應該部署在一臺物理機器上
這裡特意強調物理機是因為一臺物理機做成了若干虛擬機器器或者現今比較流 行的容器,它們雖然有不同的 IP 地址,但實際上它們都是同一臺物理機,同一臺物理機意味著如果這臺機器有什麼硬體故障,所有的虛擬機器器都會受到影響,為了實現 Sentinel 節點集合真正的高可用,請勿將 Sentinel 節點部署在同一臺物理機器上。
2、部署至少三個且奇數個的 Sentinel 節點
3 個以上是通過增加 Sentinel 節點的個數提高對於故障判定的準確性,因為領導者選舉需要至少一半加 1 個節點,奇數個節點可以在滿足該條件的基礎上節省一個節點。這是因為:
- 在節點數量是奇數個的情況下, 叢集總能對外提供服務(即使損失了一部分節點);
- 如果節點數量是偶數個,會存在叢集不能用的可能性(腦裂成兩個均等的子叢集的時候);
- 假如叢集 1 ,有 3 個節點,3/2=1.5 ,即叢集想要正常對外提供服務(即 leader 選舉成功),至少需要 2 個節點是正常的。換句話說,3 個節點的叢集,允許有一個節點宕機。
- 假如叢集 2,有 4 個節點,4/2=2,即想要正常對外提供服務(即 leader 選舉成功),至少需要 3 個節點是正常的。換句話說,4 個節點的叢集,也允許有一個節點宕機。
那麼問題就來了, 叢集 1 與叢集 2 都有允許 1 個節點宕機的容錯能力,但是叢集 2 比叢集 1 多了 1 個節點。在相同容錯能力的情況下,本著節約資源的原則,叢集的節點數維持奇數個更好一些。
3、只有一套 Sentinel,還是每個主節點設定一套 Sentinel
Sentinel 節點集合可以只監控一個主節點,也可以監控多個主節點。 那麼在實際生產環境中更偏向於哪一種部署方式呢,下面分別分析兩種方案的優缺點。
方案一:一套 Sentinel,很明顯這種方案在一定程度上降低了維護成本,因為只需要維護固定個數的 Sentinel 節點,集中對多個 Redis 資料節點進行管理就可以了。但是這同時也是它的缺點,如果這套 Sentinel 節點集合出現異常,可能會對多個 Redis 資料節點造成影響。還有如果監控的 Redis 資料節點較多,會造成 Sentinel 節點產生過多的網路連線,也會有一定的影響。
方案二:多套 Sentinel,顯然這種方案的優點和缺點和上面是相反的,每個 Redis 主節點都有自己的 Sentinel 節點集合,會造成資源浪費。但是優點也很明顯,每套 Redis Sentinel 都是彼此隔離的。
那麼如何選擇呢?
如果 Sentinel 節點集合監控的是同一個業務的多個主節點集合,那麼使用方案一,否則一般建議採用方案二。
4. Redis 叢集
前面我們知道 Sentinel 解決了高可用問題,但是它也存在一個缺點,由於一主二從每個節點都儲存著全部資料,隨著業務龐大,資料量會超過節點容量,即便是 Redis 可以設定清理策略,但也有極限,於是需要搭建 Redis 叢集,將資料分別儲存到不同的 Redis 上,並且可以橫向擴充套件。
Redis Cluster(叢集)是 Redis 的分散式解決方案(Redis官方推薦),在 3.0 版本正式推出,有效地解決了 Redis 分散式方面的需求。當遇到單機記憶體、並行、流量等瓶頸時,可以採用 Cluster 架構方案達到負載均衡的目的。
既然它是分散式儲存,也就有說每臺 Redis 節點上儲存不同的資料。把整個資料按分割區規則對映到多個節點,即把資料劃分到多個節點上,每個節點負責整體資料的一個子集。
比如我們庫有 900 條使用者資料,有 3 個 Redis 節點,將 900 條分成 3 份,分別存入到 3 個 Redis 節點:
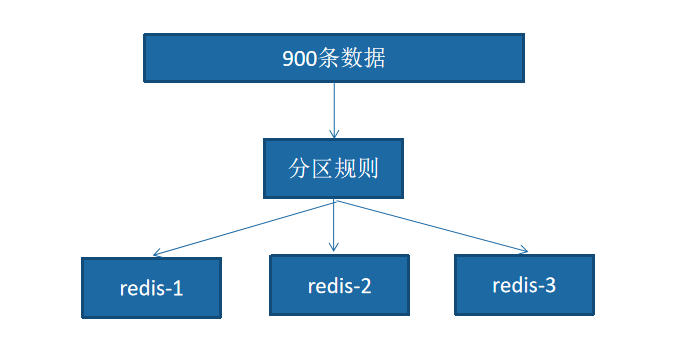
關於資料的分佈及分割區規則這裡不做細講,可自行百度,Redis Cluser 主要採用的是雜湊槽(hash slot)。
4.1 叢集說明
搭建叢集有以下 3 種方式:
- 依照 Redis 協定手工搭建,使用 cluster meet、cluster addslots、cluster replicate 命令。
- 5.0 之前使用由 ruby 語言編寫的 redis-trib.rb,在使用前需要安裝 ruby 語言環境。
- 5.0 及其之後 Redis 摒棄了 redis-trib.rb,將搭建叢集的功能合併到了redis-cli。
因此這裡直接採用第三種方式搭建,而叢集中至少應該有奇數個節點,所以至少有三個節點,官方推薦三主三從的設定方式,所以按照官方推薦搭建一個三主三從的叢集。
由於是三主三從,所以需要準備 6 臺 Redis,這裡啟用 6 臺虛擬機器器(記憶體 1G,實力不允許,就這點資本了🙃),設定相同,如下:
4.2 節點設定
三主三從,即三組一主一從。組內是主從關係,可以實現高可用;組間是叢集關係,實現分工儲存。
| 主 | 從 |
|---|---|
| 192.168.153.128 : 6379 | 192.168.153.129 : 6379 |
| 192.168.153.131 : 6379 | 192.168.153.130 : 6379 |
| 192.168.153.132 : 6379 | 192.168.153.133 : 6379 |
隨意對應,無任何規則。
修改 redis.conf組態檔,所有的節點的組態檔都是類似的:
bind 0.0.0.0
daemonize yes
logfile "/usr/local/redis/log/6379.log"
# 是否啟動叢集模式
cluster-enabled yes
# 指定叢集節點的組態檔(開啟註釋即可),這個檔案不需要手工編輯,它由 Redis 節點建立和更新,每個 Redis 群集節點 都需要不同的群集組態檔,確保在同一系統中執行的範例沒有重疊群集組態檔名
cluster-config-file nodes-6379.conf
# 指定叢集節點超時時間,超時則認為master宕機,隨後主備切換
cluster-node-timeout 15000
# 指定 redis 叢集持久化方式(預設 rdb,建議使用 aof 方式,此處是否修改不影響叢集的搭建)
appendonly yes
設定之後 6 臺 Redis 啟動:
./redis-server ../redis.conf
4.3 搭建叢集
通過redis-cli的方式搭建叢集也有兩種:
1、建立叢集主從節點
# 建立叢集,主節點和從節點比例為1,主從的對應關係會自動分配。
/redis-cli --cluster create 192.168.153.128:6379 192.168.153.129:6379 192.168.153.130:6379 192.168.153.131:6379 192.168.153.132:6379 192.168.153.133:6379 --cluster-replicas 1
說明:--cluster-replicas 1 ,1 表示每個主節點需要 1 個從節點。
通過該方式建立的帶有從節點的機器不能夠自己手動指定主節點,不符合我們的要求。所以如果需要指定的話,需要自己手動指定,先建立好主節點後,再新增從節點。
2、建立叢集並指定主從節點
① 建立叢集主節點
先建立叢集主節點,按照上面定義的主節點,然後在任一節點下執行如下命令:
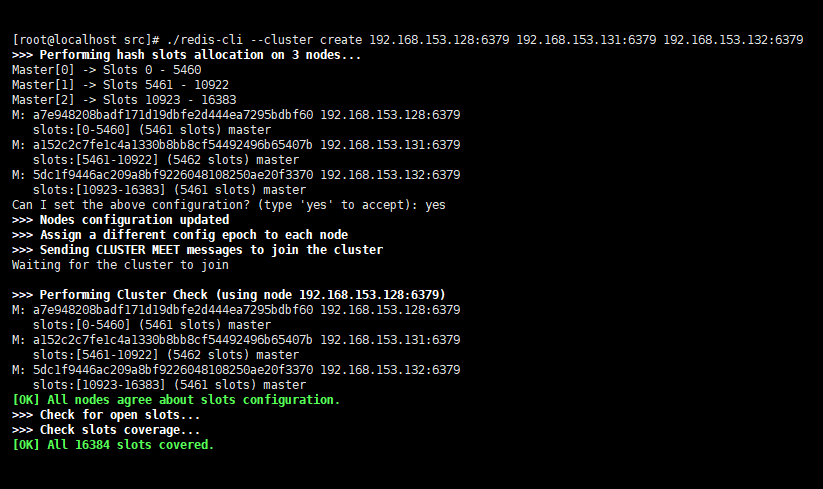
./redis-cli --cluster create 192.168.153.128:6379 192.168.153.131:6379 192.168.153.132:6379
需要注意以下問題:
- 記錄下每個 M 後如
a7e948208badf171d19dbfe2d444ea7295bdbf60的字串,在新增從節點時需要; - 如果伺服器存在著防火牆,那麼在進行安全設定的時候,除了 Redis 伺服器本身的埠,比如 6379 要加入允許列表之外,Redis 服務在叢集中還有一個叫叢集匯流排埠,其埠為使用者端連線埠加上 10000,即
6379 + 10000 = 16379。所以開放每個叢集節點的使用者端埠和叢集匯流排埠才能成功建立叢集。
② 新增叢集從節點
新增叢集從節點,命令如下:
./redis-cli --cluster add-node 192.168.153.129:6379 192.168.153.128:6379 --cluster-slave --cluster-master-id a7e948208badf171d19dbfe2d444ea7295bdbf60
說明:上述命令把 192.168.153.129:6379節點加入到 192.168.153.128:6379節點的叢集中,並且當做 node_id 為 a7e948208badf171d19dbfe2d444ea7295bdbf60的從節點。如果不指定 --cluster-master-id 會隨機分配到任意一個主節點。如下:
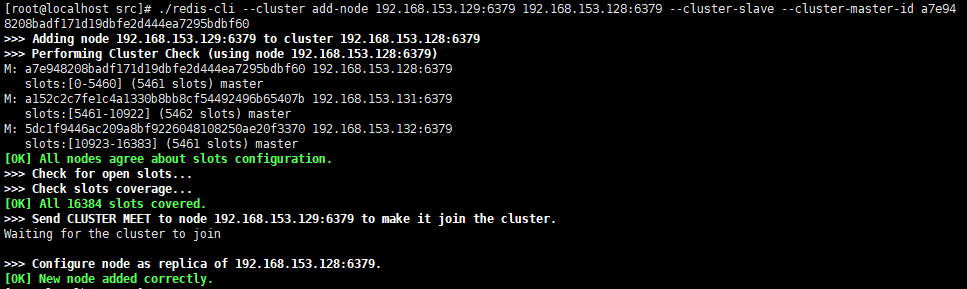
有 3 個節點,依次執行以下 3 條命令:
./redis-cli --cluster add-node 192.168.153.130:6379 192.168.153.131:6379 --cluster-slave --cluster-master-id a152c2c7fe1c4a1330b8bb8cf54492496b65407b
./redis-cli --cluster add-node 192.168.153.133:6379 192.168.153.132:6379 --cluster-slave --cluster-master-id 5dc1f9446ac209a8bf9226048108250ae20f3370
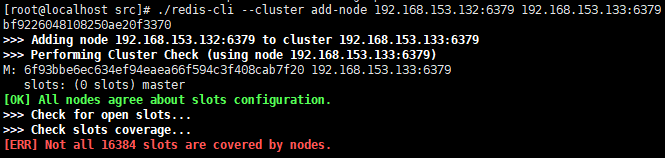
注:不要把主從節點順序顛倒了,否者會出現以下錯誤:
4.4 叢集管理
1、檢查叢集
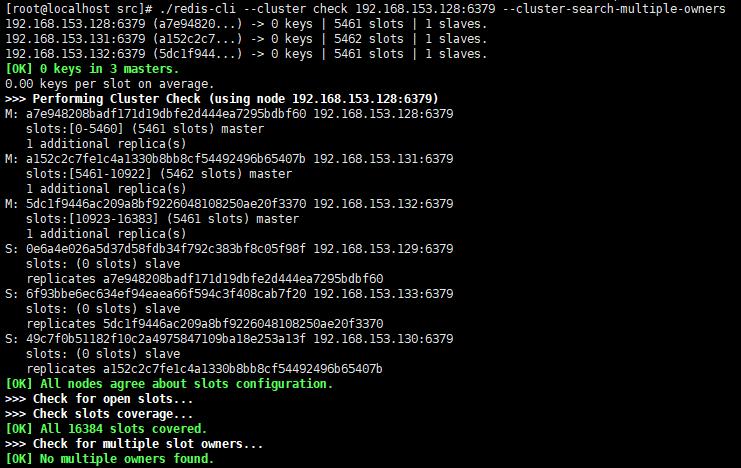
任意連線一個叢集節點,進行叢集狀態檢查
./redis-cli --cluster check 192.168.153.128:6379 --cluster-search-multiple-owners
2、叢集資訊檢視
檢查 key、slots、從節點個數的分配情況。
./redis-cli --cluster info 192.168.153.128:6379

4.5 redis-cli --cluster 引數參考
redis-cli –-cluster命令後有很多引數設定:
redis-cli --cluster help
Cluster Manager Commands:
create host1:port1 ... hostN:portN #建立叢集
--cluster-replicas <arg> #從節點個數
check host:port #檢查叢集
--cluster-search-multiple-owners #檢查是否有槽同時被分配給了多個節點
info host:port #檢視叢集狀態
fix host:port #修復叢集
--cluster-search-multiple-owners #修復槽的重複分配問題
reshard host:port #指定叢集的任意一節點進行遷移slot,重新分slots
--cluster-from <arg> #需要從哪些源節點上遷移slot,可從多個源節點完成遷移,以逗號隔開,傳遞的是節點的node id,還可以直接傳遞--from all,這樣源節點就是叢集的所有節點,不傳遞該引數的話,則會在遷移過程中提示使用者輸入
--cluster-to <arg> #slot需要遷移的目的節點的node id,目的節點只能填寫一個,不傳遞該引數的話,則會在遷移過程中提示使用者輸入
--cluster-slots <arg> #需要遷移的slot數量,不傳遞該引數的話,則會在遷移過程中提示使用者輸入。
--cluster-yes #指定遷移時的確認輸入
--cluster-timeout <arg> #設定migrate命令的超時時間
--cluster-pipeline <arg> #定義cluster getkeysinslot命令一次取出的key數量,不傳的話使用預設值為10
--cluster-replace #是否直接replace到目標節點
rebalance host:port #指定叢集的任意一節點進行平衡叢集節點slot數量
--cluster-weight <node1=w1...nodeN=wN> #指定叢集節點的權重
--cluster-use-empty-masters #設定可以讓沒有分配slot的主節點參與,預設不允許
--cluster-timeout <arg> #設定migrate命令的超時時間
--cluster-simulate #模擬rebalance操作,不會真正執行遷移操作
--cluster-pipeline <arg> #定義cluster getkeysinslot命令一次取出的key數量,預設值為10
--cluster-threshold <arg> #遷移的slot閾值超過threshold,執行rebalance操作
--cluster-replace #是否直接replace到目標節點
add-node new_host:new_port existing_host:existing_port #新增節點,把新節點加入到指定的叢集,預設新增主節點
--cluster-slave #新節點作為從節點,預設隨機一個主節點
--cluster-master-id <arg> #給新節點指定主節點
del-node host:port node_id #刪除給定的一個節點,成功後關閉該節點服務
call host:port command arg arg .. arg #在叢集的所有節點執行相關命令
set-timeout host:port milliseconds #設定cluster-node-timeout
import host:port #將外部redis資料匯入叢集
--cluster-from <arg> #將指定範例的資料匯入到叢集
--cluster-copy #migrate時指定copy
--cluster-replace #migrate時指定replace
5. 總結
回到我們最初的問題:如何保證 Redis 的高並行和高可用?
一般來說,使用 Redis 主要是用作快取,如果資料量大,一臺機器肯定是不夠的,肯定要考慮如何用 Redis 來加多臺機器,保證 Redis 是高並行的,還有就是如何讓 Redis 保證自己不是掛掉以後就直接死掉了,即 Redis 高可用。
對於高可用,通過 Redis 主從架構 + 哨兵可以實現高可用,一主多從,任何一個範例宕機,可以進行主備切換。一般來說,很多專案其實就足夠了,單主用來寫入資料,單機幾萬 QPS,多從用來查詢資料,多個從範例可以提供每秒 10w 的 QPS。
對於高並行,那麼就需要 Redis 叢集,多主多從,使用 Redis 叢集之後,可以提供每秒幾十萬的讀寫並行。
本文介紹了 Redis 的 3 種叢集架構,並且詳細講解了搭建過程,而在大部分公司會有專門的運維團隊去負責,或者直接使用一些雲 Redis (如阿里雲),所以我們其實最需要了解的是其原理。
附:組態檔詳解
redis.conf
# redis程序是否以守護行程的方式執行,yes為是,no為否(不以守護行程的方式執行會佔用一個終端)。
daemonize no
# 指定redis程序的PID檔案存放位置
pidfile /var/run/redis.pid
# redis程序的埠號
port 6379
#是否開啟保護模式,預設開啟。要是設定裡沒有指定bind和密碼。開啟該引數後,redis只會本地進行存取,拒絕外部存取。要是開啟了密碼和bind,可以開啟。否則最好關閉設定為no。
protected-mode yes
# 繫結的主機地址
bind 127.0.0.1
# 使用者端閒置多長時間後關閉連線,預設此引數為0即關閉此功能
timeout 300
# redis紀錄檔級別,可用的級別有debug.verbose.notice.warning
loglevel verbose
# log檔案輸出位置,如果程序以守護行程的方式執行,此處又將輸出檔案設定為stdout的話,就會將紀錄檔資訊輸出到/dev/null裡面去了
logfile stdout
# 設定資料庫的數量,預設為0可以使用select <dbid>命令在連線上指定資料庫id
databases 16
# 指定在多少時間內重新整理次數達到多少的時候會將資料同步到資料檔案
save <seconds> <changes>
# 指定儲存至本地資料庫時是否壓縮檔案,預設為yes即啟用儲存
rdbcompression yes
# 指定本地資料庫檔名
dbfilename dump.db
# 指定本地資料問就按存放位置
dir ./
# 指定當本機為slave服務時,設定master服務的IP地址及埠,在redis啟動的時候他會自動跟master進行資料同步
replicaof <masterip> <masterport>
# 當master設定了密碼保護時,slave服務連線master的密碼
masterauth <master-password>
# 設定redis連線密碼,如果設定了連線密碼,使用者端在連線redis是需要通過AUTH<password>命令提供密碼,預設關閉
requirepass footbared
# 設定同一時間最大客戶連線數,預設無限制。redis可以同時連線的使用者端數為redis程式可以開啟的最大檔案描述符,如果設定 maxclients 0,表示不作限制。當用戶端連線數到達限制時,Redis會關閉新的連線並向用戶端返回 max number of clients reached 錯誤資訊
maxclients 128
# 指定Redis最大記憶體限制,Redis在啟動時會把資料載入到記憶體中,達到最大記憶體後,Redis會先嚐試清除已到期或即將到期的Key。當此方法處理後,仍然到達最大記憶體設定,將無法再進行寫入操作,但仍然可以進行讀取操作。Redis新的vm機制,會把Key存放記憶體,Value會存放在swap區
maxmemory<bytes>
# 指定是否在每次更新操作後進行紀錄檔記錄,Redis在預設情況下是非同步的把資料寫入磁碟,如果不開啟,可能會在斷電時導致一段時間內的資料丟失。因為redis本身同步資料檔案是按上面save條件來同步的,所以有的資料會在一段時間內只存在於記憶體中。預設為no。
appendonly no
# 指定跟新紀錄檔檔名預設為appendonly.aof
appendfilename appendonly.aof
# 指定更新紀錄檔的條件,有三個可選引數 - no:表示等作業系統進行資料快取同步到磁碟(快),always:表示每次更新操作後手動呼叫fsync()將資料寫到磁碟(慢,安全), everysec:表示每秒同步一次(折衷,預設值);
appendfsync everysec
sentinel.conf
# 哨兵sentinel範例執行的埠,預設26379
port 26379
# 哨兵sentinel的工作目錄
dir ./
# 是否開啟保護模式,預設開啟。
protected-mode:no
# 是否設定為後臺啟動。
daemonize:yes
# 哨兵sentinel的紀錄檔檔案
logfile:./sentinel.log
# 哨兵sentinel監控的redis主節點的
## ip:主機ip地址
## port:哨兵埠號
## master-name:可以自己命名的主節點名字(只能由字母A-z、數位0-9 、這三個字元".-_"組成。)
## quorum:當這些quorum個數sentinel哨兵認為master主節點失聯 那麼這時 客觀上認為主節點失聯了
# sentinel monitor <master-name> <ip> <redis-port> <quorum>
sentinel monitor mymaster 127.0.0.1 6379 2
# 當在Redis範例中開啟了requirepass,所有連線Redis範例的使用者端都要提供密碼。
# sentinel auth-pass <master-name> <password>
sentinel auth-pass mymaster 123456
# 指定主節點應答哨兵sentinel的最大時間間隔,超過這個時間,哨兵主觀上認為主節點下線,預設30秒
# sentinel down-after-milliseconds <master-name> <milliseconds>
sentinel down-after-milliseconds mymaster 30000
# 指定了在發生failover主備切換時,最多可以有多少個slave同時對新的master進行同步。這個數位越小,完成failover所需的時間就越長;反之,但是如果這個數位越大,就意味著越多的slave因為replication而不可用。可以通過將這個值設為1,來保證每次只有一個slave,處於不能處理命令請求的狀態。
# sentinel parallel-syncs <master-name> <numslaves>
sentinel parallel-syncs mymaster 1
# 故障轉移的超時時間failover-timeout,預設三分鐘,可以用在以下這些方面:
## 1. 同一個sentinel對同一個master兩次failover之間的間隔時間。
## 2. 當一個slave從一個錯誤的master那裡同步資料時開始,直到slave被糾正為從正確的master那裡同步資料時結束。
## 3. 當想要取消一個正在進行的failover時所需要的時間。
## 4.當進行failover時,設定所有slaves指向新的master所需的最大時間。不過,即使過了這個超時,slaves依然會被正確設定為指向master,但是就不按parallel-syncs所設定的規則來同步資料了
# sentinel failover-timeout <master-name> <milliseconds>
sentinel failover-timeout mymaster 180000
# 當sentinel有任何警告級別的事件發生時(比如說redis範例的主觀失效和客觀失效等等),將會去呼叫這個指令碼。一個指令碼的最大執行時間為60s,如果超過這個時間,指令碼將會被一個SIGKILL訊號終止,之後重新執行。
# 對於指令碼的執行結果有以下規則:
## 1. 若指令碼執行後返回1,那麼該指令碼稍後將會被再次執行,重複次數目前預設為10。
## 2. 若指令碼執行後返回2,或者比2更高的一個返回值,指令碼將不會重複執行。
## 3. 如果指令碼在執行過程中由於收到系統中斷訊號被終止了,則同返回值為1時的行為相同。
# sentinel notification-script <master-name> <script-path>
sentinel notification-script mymaster /var/redis/notify.sh
# 這個指令碼應該是通用的,能被多次呼叫,不是針對性的。
# sentinel client-reconfig-script <master-name> <script-path>
sentinel client-reconfig-script mymaster /var/redis/reconfig.sh