Redis為什麼這麼快?
Redis為什麼這麼快?
本文 GitHub https://github.com/JavaFamily 已收錄,有一線大廠面試完整考點、資料以及我的系列文章。
前言

說起當前主流NoSql資料庫非 Redis 莫屬。因為它讀寫速度極快,一般用於快取熱點資料加快查詢速度,大家在工作裡面也肯定和 Redis 打過交道,但是對於Redis 為什麼快,除了對八股文的背誦,好像都還沒特別深入的瞭解。
今天我們一起深入的瞭解下redis吧:

高效的資料結構
Redis 的底層資料結構一共有6種,分別是,簡單動態字串,雙向連結串列,壓縮列表,雜湊表,跳錶和整數陣列,它們和資料型別的對應關係如下圖所示:

本文暫時按下不表,後續會針對以上所有資料結構進行原始碼級深入分析
單執行緒vs多執行緒
在學習計算機作業系統時一定遇到過這個問題: 多執行緒一定比單執行緒快嗎? 相信各位看官們一定不會像上面的傻哪吒一樣落入敖丙的圈套中。
多執行緒有時候確實比單執行緒快,但也有很多時候沒有單執行緒那麼快。首先用一張3歲小孩都能看懂的圖解釋並行與並行的區別:
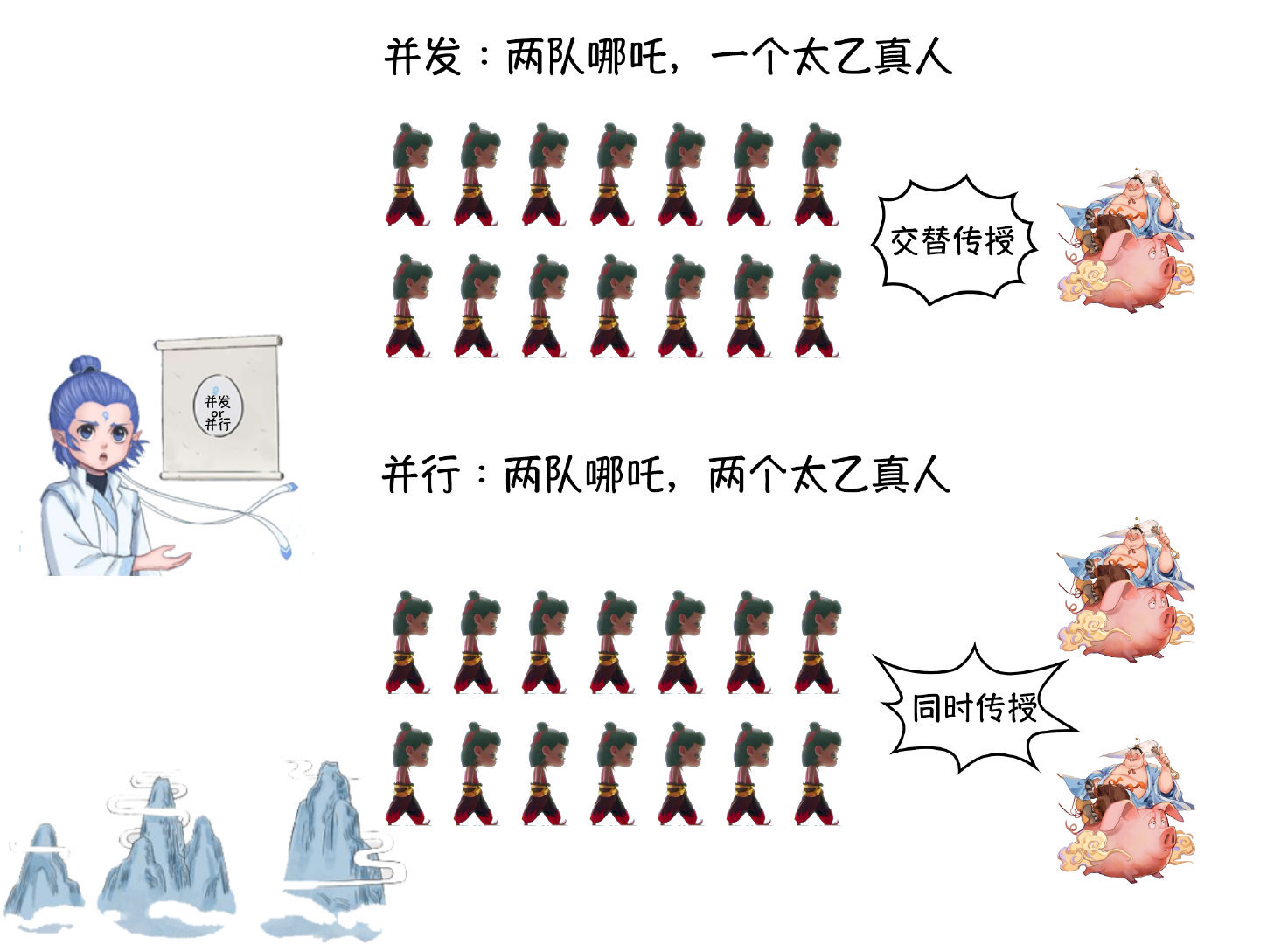
- 並行(concurrency):指在同一時刻只能有一條指令執行,但多個程序指令被快速的輪換執行,使得在宏觀上具有多個程序同時執行的效果,但在微觀上並不是同時執行的,只是把時間分成若干段,使多個程序快速交替的執行。
- 並行(parallel):指在同一時刻,有多條指令在多個處理器上同時執行。所以無論從微觀還是從宏觀來看,二者都是一起執行的。
不難發現並行在同一時刻只有一條指令執行,只不過程序(執行緒)在CPU中快速切換,速度極快,給人看起來就是「同時執行」的印象,實際上同一時刻只有一條指令進行。但實際上如果我們在一個應用程式中使用了多執行緒,執行緒之間的輪換以及上下文切換是需要花費很多時間的。

Talk is cheap,Show me the code
如下程式碼演示了序列和並行執行並累加操作的時間:
public class ConcurrencyTest {
private static final long count = 1000000000;
public static void main(String[] args) {
try {
concurrency();
} catch (InterruptedException e) {
e.printStackTrace();
}
serial();
}
private static void concurrency() throws InterruptedException {
long start = System.currentTimeMillis();
Thread thread = new Thread(new Runnable() {
@Override
public void run() {
int a = 0;
for (long i = 0; i < count; i++)
{
a += 5;
}
}
});
thread.start();
int b = 0;
for (long i = 0; i < count; i++) {
b--;
}
thread.join();
long time = System.currentTimeMillis() - start;
System.out.println("concurrency : " + time + "ms,b=" + b);
}
private static void serial() {
long start = System.currentTimeMillis();
int a = 0;
for (long i = 0; i < count; i++)
{
a += 5;
}
int b = 0;
for (long i = 0; i < count; i++) {
b--;
}
long time = System.currentTimeMillis() - start;
System.out.println("serial : " + time + "ms,b=" + b);
}
}
執行時間如下表所示,不難發現,當並行執行累加操作不超過百萬次時,速度會比序列執行累加操作要慢。
| 迴圈次數 | 序列執行耗時/ms | 並行執行耗時 | 並行比序列快多少 |
|---|---|---|---|
| 1億 | 130 | 77 | 約1倍 |
| 1千萬 | 18 | 9 | 約1倍 |
| 1百萬 | 5 | 5 | 相差無幾 |
| 10萬 | 4 | 3 | 相差無幾 |
| 1萬 | 0 | 1 | 慢 |
由於執行緒有建立和上下文切換的開銷,導致並行執行的速度會比序列慢的情況出現。

上下文切換

多個執行緒可以執行在單核或多核CPU上,單核CPU也支援多執行緒執行程式碼,CPU通過給每個執行緒分配CPU時間片(機會)來實現這個機制。CPU為了執行多個執行緒,就需要不停的切換執行的執行緒,這樣才能保證所有的執行緒在一段時間內都有被執行的機會。
此時,CPU分配給每個執行緒的執行時間段,稱作它的時間片。CPU時間片一般為幾十毫秒。CPU通過時間片分配演演算法來回圈執行任務,當前任務執行一個時間片後切換到下一個任務。
但是,在切換前會儲存上一個任務的狀態,以便下次切換回這個任務時,可以再載入這個任務的狀態。所以任務從儲存到再載入的過程就是一次上下文切換。
根據多執行緒的執行狀態來說明:多執行緒環境中,當一個執行緒的狀態由Runnable轉換為非Runnable(Blocked、Waiting、Timed_Waiting)時,相應執行緒的上下文資訊(包括CPU的暫存器和程式計數器在某一時間點的內容等)需要被儲存,以便相應執行緒稍後再次進入Runnable狀態時能夠在之前的執行進度的基礎上繼續前進。而一個執行緒從非Runnable狀態進入Runnable狀態可能涉及恢復之前儲存的上下文資訊。這個對執行緒的上下文進行儲存和恢復的過程就被稱為上下文切換。
基於記憶體
以MySQL為例,MySQL的資料和索引都是持久化儲存在磁碟上的,因此當我們使用SQL語句執行一條查詢命令時,如果目標資料庫的索引還沒被載入到記憶體中,那麼首先要先把索引載入到記憶體,再通過若干定址定位和磁碟I/O,把資料對應的磁碟塊載入到記憶體中,最後再讀取資料。
如果是機械硬碟,那麼首先需要找到資料所在的位置,即需要讀取的磁碟地址。可以看看這張示意圖:
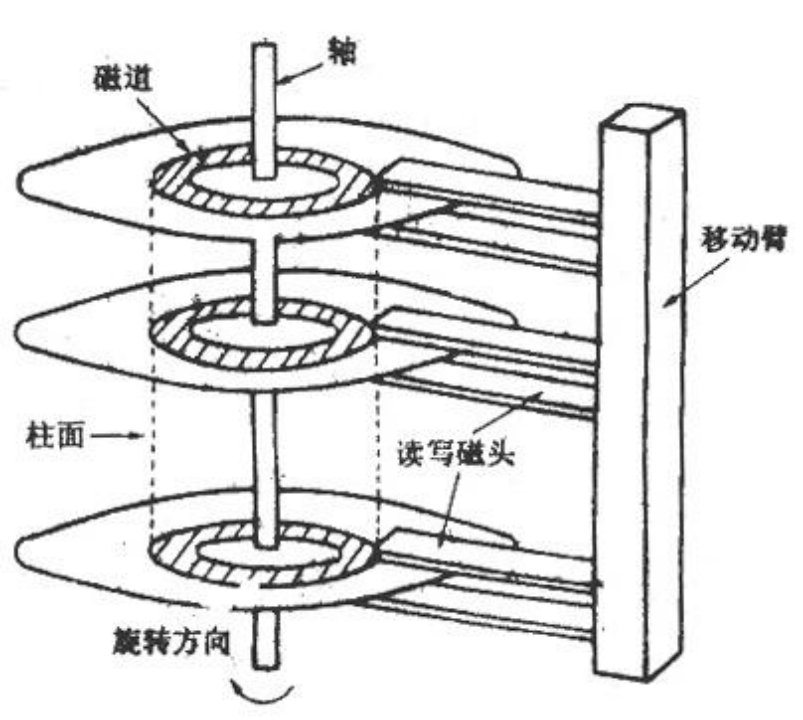
讀取硬碟上的資料,第一步就是找到所需的磁軌,磁軌就是以中間軸為圓心的圓環,首先我們需要找到所需要對準的磁軌,並將磁頭移動到對應的磁軌上,這個過程叫做尋道。
然後,我們需要等到磁碟轉動,讓磁頭指向我們需要讀取的資料開始的位置,這裡耗費的時間稱為旋轉延遲,平時我們說的硬碟轉速快慢,主要影響的就是耗費在這裡的時間,而且這個轉動的方向是單向的,如果錯過了資料的開頭位置,就必須等到碟片旋轉到下一圈的時候才能開始讀。
最後,磁頭開始讀取記錄著磁碟上的資料,這個原理其實與光碟的讀取原理類似,由於磁軌上有一層磁性媒介,當磁頭掃過特定的位置,磁頭感應不同位置的磁性狀態就可以將磁訊號轉換為電訊號。
可以看到,無論是磁頭的移動還是磁碟的轉動,本質上其實都是機械運動,這也是為什麼這種硬碟被稱為機械硬碟,而機械運動的效率就是磁碟讀寫的瓶頸。
扯得有點遠了,我們說回redis,如果像Redis這樣把資料存在記憶體中,讀寫都直接對資料庫進行操作,天然地就比硬碟資料庫少了到磁碟讀取資料的這一步,而這一步恰恰是計算機處理I/O的瓶頸所在。
在記憶體中讀取資料,本質上是電訊號的傳遞,比機械運動傳遞訊號要快得多。
因此,可以負責任地說,Redis這麼快當然跟它基於記憶體執行有著很大的關係。但是,這還遠遠不是全部的原因。
Redis FAQ
面對單執行緒的 Redis 你也許又會有疑問:敖丙,我的多核CPU發揮不了作用了呀!別急,Redis 針對這個問題專門進行了解答。

CPU成為Redis效能瓶頸的情況並不常見,因為Redis通常會受到記憶體或網路的限制。例如,在 Linux 系統上使用流水線 Redis 每秒甚至可以提供 100 萬個請求,所以如果你的應用程式主要使用O(N)或O(log(N))命令,它幾乎不會佔用太多的CPU。
然而,為了最大化CPU利用率,你可以在同一個節點中啟動多個Redis範例,並將它們視為不同的Redis服務。在某些情況下,一個單獨的節點可能是不夠的,所以如果你想使用多個cpu,你可以開始考慮一些更早的分片方法。
你可以在Partitioning頁面中找到更多關於使用多個Redis範例的資訊。
然而,在Redis 4.0中,我們開始讓Redis更加執行緒化。目前這僅限於在後臺刪除物件,以及阻塞通過Redis模組實現的命令。對於未來的版本,我們的計劃是讓Redis變得越來越多執行緒。
注意:我們一直說的 Redis 單執行緒,只是在處理我們的網路請求的時候只有一個執行緒來處理,一個正式的Redis Server執行的時候肯定是不止一個執行緒的!
例如Redis進行持久化的時候會 fork了一個子程序 執行持久化操作

四種IO模型
當一個網路IO發生(假設是read)時,它會涉及兩個系統物件,一個是呼叫這個IO的程序,另一個是系統核心。
當一個read操作發生時,它會經歷兩個階段:
①等待資料準備;
②將資料從核心拷貝到程序中。
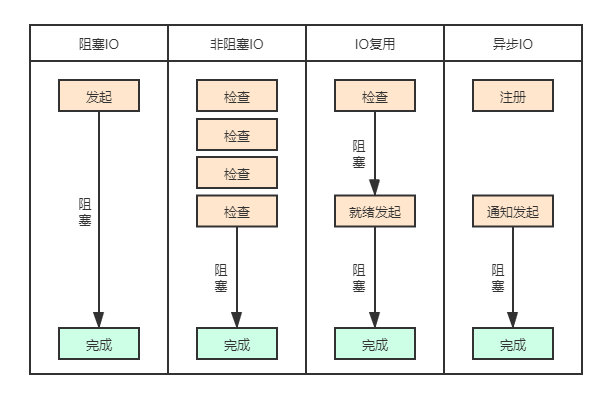
為了解決網路IO中的問題,提出了4中網路IO模型:
- 阻塞IO模型
- 非阻塞IO模型
- 多路複用IO模型
- 非同步IO模型
阻塞和非阻塞的概念描述的是使用者執行緒呼叫核心IO操作的方式:阻塞時指IO操作需要徹底完成後才返回到使用者空間;而非阻塞是指IO操作被呼叫後立即返回給使用者一個狀態值,不需要等到IO操作徹底完成。
阻塞IO模型
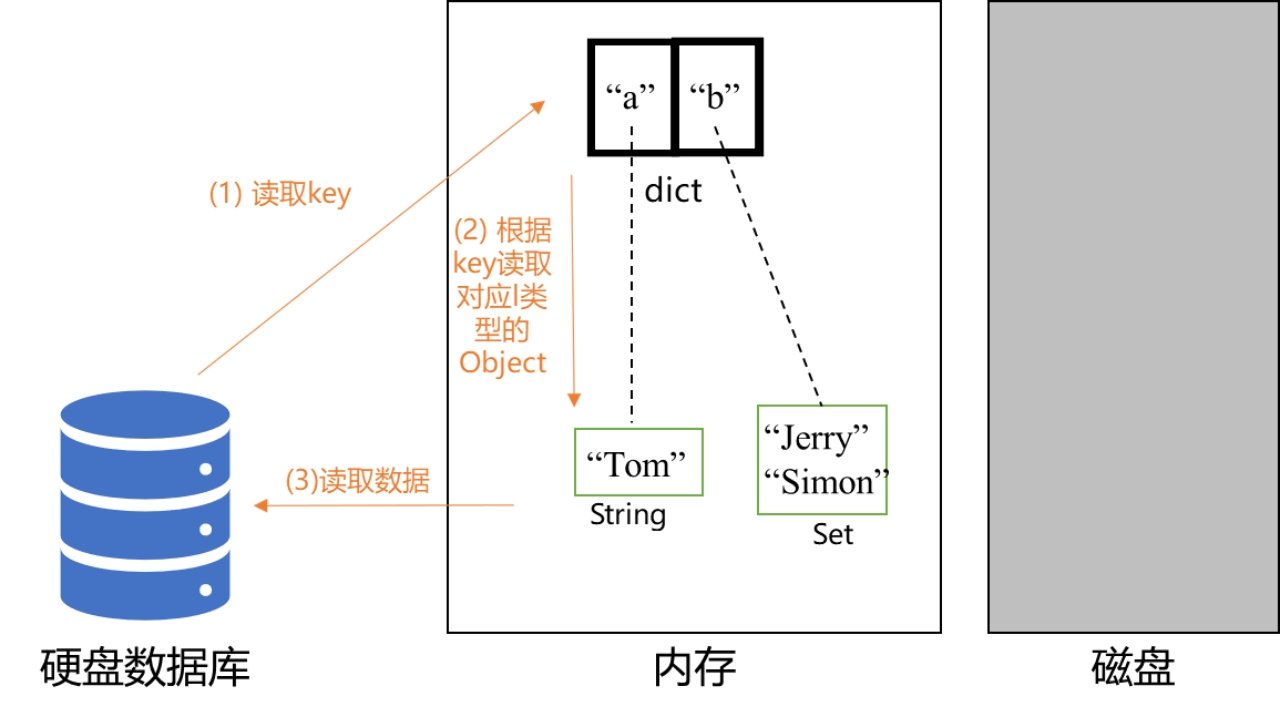
在Linux中,預設情況下所有socket都是阻塞的,一個典型的讀操作如下圖所示:
當應用程序呼叫了recvfrom這個系統呼叫後,系統核心就開始了IO的第一個階段:準備資料。
對於網路IO來說,很多時候資料在一開始還沒到達時(比如還沒有收到一個完整的TCP包),系統核心就要等待足夠的資料到來。而在使用者程序這邊,整個程序會被阻塞。
當系統核心一直等到資料準備好了,它就會將資料從系統核心中拷貝到使用者記憶體中,然後系統核心返回結果,使用者程序才解除阻塞的狀態,重新執行起來。所以,阻塞IO模型的特點就是在IO執行的兩個階段(等待資料和拷貝資料)都被阻塞了。
非阻塞IO模型
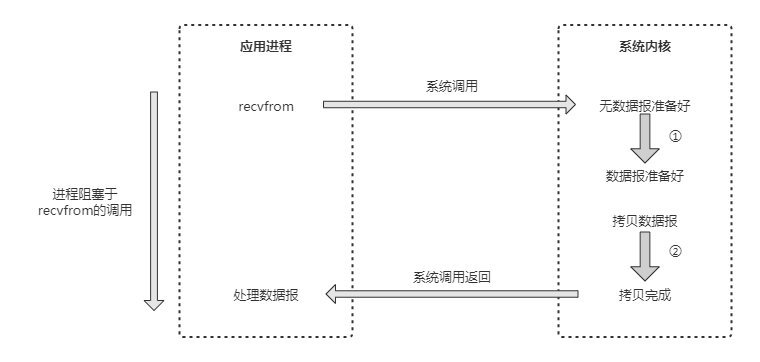
在Linux中,可以通過設定socket使IO變為非阻塞狀態。當對一個非阻塞的socket執行read操作時,讀操作流程如下圖所示:
從圖中可以看出,當使用者程序發出 read 操作時,如果核心中的資料還沒有準備好,那麼它不會阻塞使用者程序,而是立刻返回一個錯誤。
從使用者程序角度講,它發起一個read操作後,並不需要等待,而是馬上就得到了一個結果。當使用者程序判斷結果是一個錯誤時,它就知道資料還沒有準備好,於是它可以再次傳送read操作。
一旦核心中的資料準備好了,並且又再次收到了使用者程序的系統呼叫,那麼它馬上就將資料複製到了使用者記憶體中,然後返回正確的返回值。
所以,在非阻塞式IO中,使用者程序其實需要不斷地主動詢問kernel資料是否準備好。非阻塞的介面相比阻塞型介面的顯著差異在於被呼叫之後立即返回。
多路複用IO模型
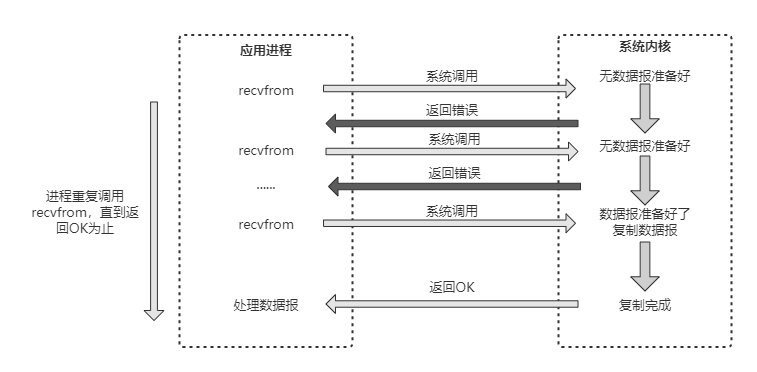
多路IO複用,有時也稱為事件驅動IO(Reactor設計模式)。它的基本原理就是有個函數會不斷地輪詢所負責的所有socket,當某個socket有資料到達了,就通知使用者程序,多路IO複用模型的流程如圖所示:
當使用者程序呼叫了select,那麼整個程序會被阻塞,而同時,核心會"監視"所有select負責的socket,當任何一個socket中的資料準備好了,select就會返回。這個時候使用者程序再呼叫read操作,將資料從核心拷貝到使用者程序。
這個模型和阻塞IO的模型其實並沒有太大的不同,事實上還更差一些。因為這裡需要使用兩個系統呼叫(select和recvfrom),而阻塞IO只呼叫了一個系統呼叫(recvfrom)。但是,用select的優勢在於它可以同時處理多個連線。所以,如果系統的連線數不是很高的話,使用select/epoll的web server不一定比使用多執行緒的阻塞IO的web server效能更好,可能延遲還更大;select/epoll的優勢並不是對單個連線能處理得更快,而是在於能處理更多的連線。
如果select()發現某控制程式碼捕捉到了"可讀事件",伺服器程式應及時做recv()操作,並根據接收到的資料準備好待傳送資料,並將對應的控制程式碼值加入writefds,準備下一次的"可寫事件"的select()檢測。同樣,如果select()發現某控制程式碼捕捉到"可寫事件",則程式應及時做send()操作,並準備好下一次的"可讀事件"檢測準備。
如下圖展示了基於事件驅動的工作模型,當不同的事件產生時handler將感應到並執行相應的事件,像一個多路開關似的。
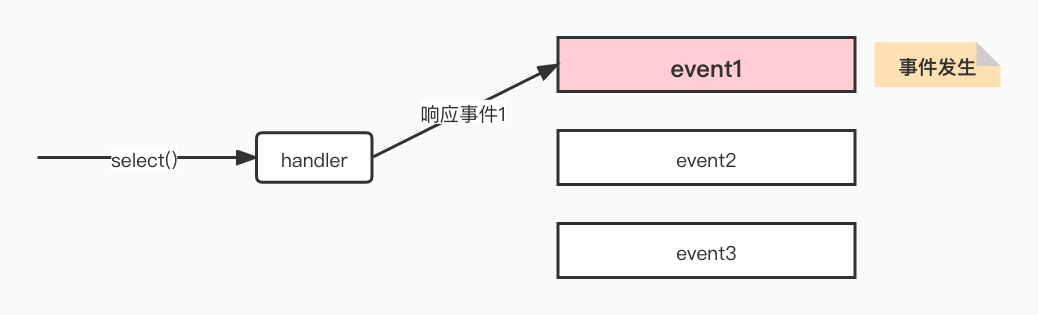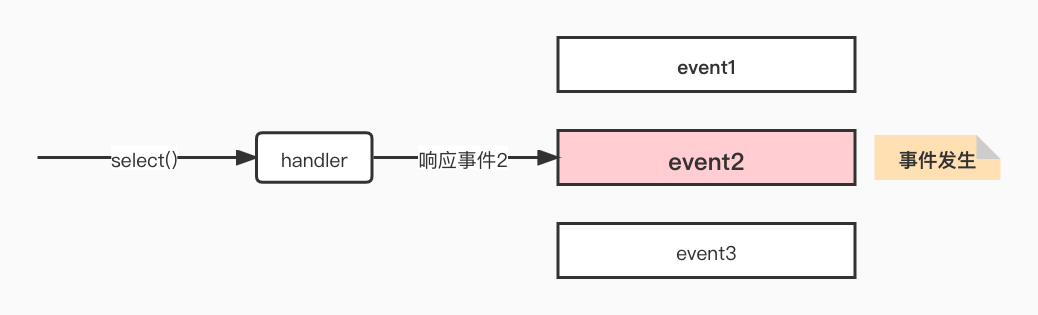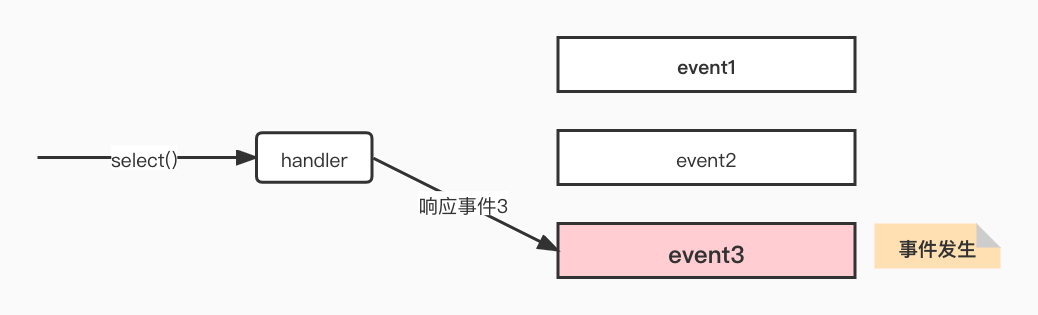
IO多路複用是最常使用的IO模型,但是其非同步程度還不夠「徹底」,因為它使用了會阻塞執行緒的select系統呼叫。因此IO多路複用只能稱為非同步阻塞IO,而非真正的非同步IO。
非同步IO模型
「真正」的非同步IO需要作業系統更強的支援。如下展示了非同步 IO 模型的執行流程(Proactor設計模式):

使用者程序發起read操作之後,立刻就可以開始去做其他的事;而另一方面,從核心的角度,當它收到一個非同步的read請求操作之後,首先會立刻返回,所以不會對使用者程序產生任何阻塞。
然後,核心會等待資料準備完成,然後將資料拷貝到使用者記憶體中,當這一切都完成之後,核心會給使用者程序傳送一個訊號,返回read操作已完成的資訊。
IO模型總結
呼叫阻塞IO會一直阻塞住對應的程序直到操作完成,而非阻塞IO在核心還在準備資料的情況下會立刻返回。
兩者的區別就在於同步IO進行IO操作時會阻塞程序。按照這個定義,之前所述的阻塞IO、非阻塞IO及多路IO複用都屬於同步IO。實際上,真實的IO操作,就是例子中的recvfrom這個系統呼叫。
非阻塞IO在執行recvfrom這個系統呼叫的時候,如果核心的資料沒有準備好,這時候不會阻塞程序。但是當核心中資料準備好時,recvfrom會將資料從核心拷貝到使用者記憶體中,這個時候程序則被阻塞。
而非同步IO則不一樣,當程序發起IO操作之後,就直接返回,直到核心傳送一個訊號,告訴程序IO已完成,則在這整個過程中,程序完全沒有被阻塞。
各個IO模型的比較如下圖所示:
Redis中的應用
Redis伺服器是一個事件驅動程式,伺服器需要處理以下兩類事件:
- 檔案事件:Redis伺服器端通過通訊端與使用者端(或其他Redis伺服器)進行連線,而檔案事件就是伺服器對通訊端操作的抽象。伺服器與使用者端(或者其他伺服器)的通訊會產生相應的檔案事件,而伺服器則通過監聽並處理這些事件來完成一系列網路通訊操作。
- 時間事件:Redis伺服器中的一些操作(如
serverCron)函數需要在給定的時間點執行,而時間事件就是伺服器對這類定時操作的抽象。
I/O多路複用程式
Redis的 I/O 多路複用程式的所有功能都是通過包裝常見的select、epoll、evport、kqueue這些多路複用函數庫來實現的。
因為Redis 為每個 I/O 多路複用函數庫都實現了相同的API,所以I/O多路複用程式的底層實現是可以互換的。
Redis 在 I/O 多路複用程式的實現原始碼中用 #include 宏定義了相應的規則,程式會在編譯時自動選擇系統中效能最高的 I/O 多路複用函數庫來作為 Redis 的 I/O 多路複用程式的底層實現(ae.c檔案):
/* Include the best multiplexing layer supported by this system.
* The following should be ordered by performances, descending. */
#ifdef HAVE_EVPORT
#include "ae_evport.c"
#else
#ifdef HAVE_EPOLL
#include "ae_epoll.c"
#else
#ifdef HAVE_KQUEUE
#include "ae_kqueue.c"
#else
#include "ae_select.c"
#endif
#endif
#endif
檔案事件處理器
Redis基於 Reactor 模式開發了自己的網路事件處理器:這個處理器被稱為檔案事件處理器:
- 檔案事件處理器使用 I/O 多路複用程式來同時監聽多個通訊端,並根據通訊端目前執行的任務來為通訊端關聯不同的事件處理器。
- 當被監聽的通訊端準備好執行連線應答(
accept)、讀取(read)、寫入(write)、關閉(close)等操作時,與操作相對應的檔案事件就會產生,這時檔案事件處理器就會呼叫通訊端之前關聯好的事件處理器來處理這些事件。
下圖展示了檔案事件處理器的四個組成部分:通訊端、I/O多路複用程式、檔案事件分派器(dispatcher)、事件處理器。
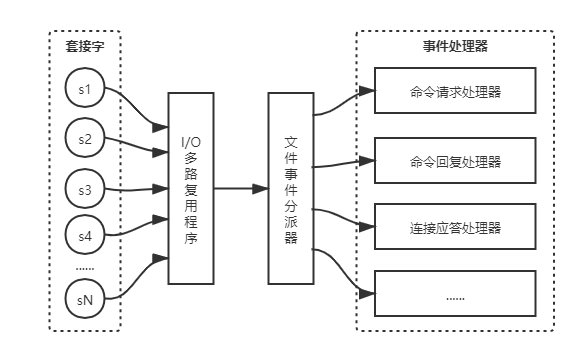
檔案事件是對通訊端操作的抽象,每當一個通訊端準備好執行連線應答、寫入、讀取、關閉等操作時,就會產生一個檔案事件。因為一個伺服器通常會連線多個通訊端,所以多個檔案事件有可能會並行地出現。I/O 多路複用程式負責監聽多個通訊端,並向檔案事件分派器傳送那些產生了事件的通訊端。

哪吒問的問題很棒,聯想一下,生活中一群人去食堂打飯,阿姨說的最多的一句話就是:排隊啦!排隊啦!一個都不會少!
沒錯,一切來源生活!Redis 的 I/O多路複用程式總是會將所有產生事件的通訊端都放到一個佇列裡面,然後通過這個佇列,以有序、同步、每次一個通訊端的方式向檔案事件分派器傳送通訊端。當上一個通訊端產生的事件被處理完畢之後,I/O 多路複用程式才會繼續向檔案事件分派器傳送下一個通訊端。

Redis為檔案事件處理器編寫了多個處理器,這些事件處理器分別用於實現不同的網路通訊需求:
- 為了對連線伺服器的各個使用者端進行應答,伺服器要為監聽通訊端關聯
連線應答處理器; - 為了接受使用者端傳來的命令請求,伺服器要為使用者端通訊端關聯
命令請求處理器; - 為了向用戶端返回命令的執行結果,伺服器要為使用者端通訊端關聯
命令回覆處理器; - 當主伺服器和從伺服器進行復制操作時,主從伺服器都需要關聯特別為複製功能編寫的
複製處理器。
連線應答處理器
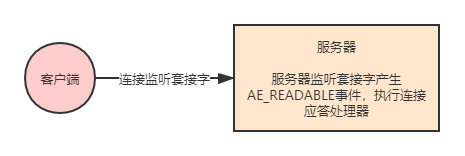
networking.c/acceptTcpHandler函數是Redis的連線應答處理器,這個處理器用於對連線伺服器監聽通訊端的使用者端進行應答,具體實現為sys/socket.h/acccept函數的包裝。
當Redis伺服器進行初始化的時候,程式會將這個連線應答處理器和伺服器監聽通訊端的AE_READABLE時間關聯起來,當有使用者端用sys/socket.h/connect函數連線伺服器監聽通訊端的時候,通訊端就會產生AE_READABLE事件,引發連線應答處理器執行,並執行相應的通訊端應答操作。
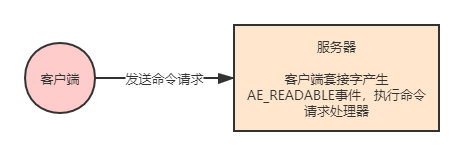
命令請求處理器
networking.c/readQueryFromClient函數是Redis的命令請求處理器,這個處理器負責從通訊端中讀入使用者端傳送的命令請求內容,具體實現為unistd.h/read函數的包裝。
當一個使用者端通過連線應答處理器成功連線到伺服器之後,伺服器會將使用者端通訊端的AE_READABLE事件和命令請求處理器關聯起來,當用戶端向伺服器傳送命令請求的時候,通訊端就會產生AE_READABLE事件,引發命令請求處理器執行,並執行相應的通訊端讀入操作。
在使用者端連線伺服器的整個過程中,伺服器都會一直為使用者端通訊端AE_READABLE事件關聯命令請求處理器。
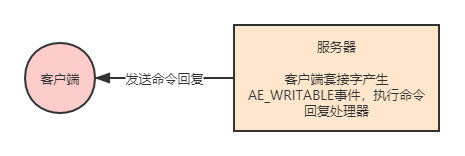
命令回覆處理器
networking.c/sendReplyToClient函數是Redis的命令回覆處理器,這個處理器負責從伺服器執行命令後得到的命令回覆通過通訊端返回給使用者端,具體實現為unistd.h/write函數的包裝。
當伺服器有命令回覆需要傳送給使用者端的時候,伺服器會將使用者端通訊端的AE_WRITABLE事件和命令回覆處理器關聯起來,當用戶端準備好接收伺服器傳回的命令回覆時,就會產生AE_WRITABLE事件,引發命令回覆處理器執行,並執行相應的通訊端寫入操作。
當命令回覆傳送完畢之後,伺服器就會解除命令回覆處理器與使用者端通訊端的AE_WRITABLE事件之間的關聯。
小總結
一句話描述 IO 多路複用在 Redis 中的應用:Redis 將所有產生事件的通訊端都放到一個佇列裡面,以有序、同步、每次一個通訊端的方式向檔案事件分派器傳送通訊端,檔案事件分派器根據通訊端對應的事件選擇響應的處理器進行處理,從而實現了高效的網路請求。
Redis的自定義協定
Redis使用者端使用RESP(Redis的序列化協定)協定與Redis的伺服器端進行通訊。 它實現簡單,解析快速並且人類可讀。
RESP 支援以下資料型別:簡單字串、錯誤、整數、批次字串和陣列。
RESP 在 Redis 中用作請求-響應協定的方式如下:
- 使用者端將命令作為批次字串的 RESP 陣列傳送到 Redis 伺服器。
- 伺服器根據命令實現以其中一種 RESP 型別進行回覆。
在 RESP 中,某些資料的型別取決於第一個位元組:
- 對於簡單字串,回覆的第一個位元組是「+」
- 對於錯誤,回覆的第一個位元組是「-」
- 對於整數,回覆的第一個位元組是「:」
- 對於批次字串,回覆的第一個位元組是「$」
- 對於陣列,回覆的第一個位元組是「*」
此外,RESP 能夠使用稍後指定的批次字串或陣列的特殊變體來表示 Null 值。在 RESP 中,協定的不同部分總是以「\r\n」(CRLF)終止。
下面只簡單介紹字串的編碼方式和錯誤的編碼方式,詳情可以檢視 Redis 官網對 RESP 進行了詳細的說明。
簡單字串
用如下方法編碼:一個「+」號後面跟字串,最後是「\r\n」,字串裡不能包含"\r\n"。簡單字串用來傳輸比較短的二進位制安全的字串。例如很多redis命令執行成功會返回「OK」,用RESP編碼就是5個位元組:
"+OK\r\n"
想要傳送二進位制安全的字串,需要用RESP的塊字串。當redis返回了一個簡單字串的時候,使用者端庫需要給呼叫者返回「+」號(不含)之後CRLF之前(不含)的字串。
RESP錯誤
RESP 有一種專門為錯誤設計的型別。實際上錯誤型別很像RESP簡單字串型別,但是第一個字元是「-」。簡單字串型別和錯誤型別的區別是使用者端把錯誤型別當成一個異常,錯誤型別包含的字串是異常資訊。格式是:
"-Error message\r\n"
有錯誤發生的時候才會返回錯誤型別,例如你執行了一個對於某型別錯誤的操作,或者命令不存在等。當返回一個錯誤型別的時候使用者端庫應該發起一個異常。下面是一個錯誤型別的例子
-ERR unknown command 'foobar' -WRONGTYPE Operation against a key holding the wrong kind of value
「-」號之後空格或者換行符之前的字串代表返回的錯誤型別,這只是慣例,並不是RESP要求的格式。例如ERR是一般錯誤,WRONGTYPE是更具體的錯誤表示使用者端的試圖在錯誤的型別上執行某個操作。這個稱為錯誤字首,能讓使用者端更方便的識別錯誤型別。
使用者端可能為不同的錯誤返回不同的異常,也可能只提供一個一般的方法來捕捉錯誤並提供錯誤名。但是不能依賴使用者端提供的這些特性,因為有的使用者端僅僅返回一般錯誤,比如false。
高效能 Redis 協定分析器
儘管 Redis 的協定非常利於人類閱讀, 定義也很簡單, 但這個協定的實現效能仍然可以和二進位制協定一樣快。
因為 Redis 協定將資料的長度放在資料正文之前, 所以程式無須像 JSON 那樣, 為了尋找某個特殊字元而掃描整個 payload , 也無須對傳送至伺服器的 payload 進行跳脫(quote)。
程式可以在對協定文字中的各個字元進行處理的同時, 查詢 CR 字元, 並計算出批次回覆或多條批次回覆的長度, 就像這樣:
#include <stdio.h>
int main(void) {
unsigned char *p = "$123\r\n";
int len = 0;
p++;
while(*p != '\r') {
len = (len*10)+(*p - '0');
p++;
}
/* Now p points at '\r', and the len is in bulk_len. */
printf("%d\n", len);
return 0;
}
得到了批次回覆或多條批次回覆的長度之後, 程式只需呼叫一次 read 函數, 就可以將回復的正文資料全部讀入到記憶體中, 而無須對這些資料做任何的處理。在回覆最末尾的 CR 和 LF 不作處理,丟棄它們。
Redis 協定的實現效能可以和二進位制協定的實現效能相媲美, 並且由於 Redis 協定的簡單性, 大部分高階語言都可以輕易地實現這個協定, 這使得使用者端軟體的 bug 數量大大減少。
冷知識:redis到底有多快?
在成功安裝了Redis之後,Redis自帶一個可以用來進行效能測試的命令 redis-benchmark,通過執行這個命令,我們可以模擬N個使用者端同時傳送請求的場景,並監測Redis處理這些請求所需的時間。
根據官方的檔案,Redis經過在60000多個連線中進行了基準測試,並且仍然能夠在這些條件下維持50000 q/s的效率,同樣的請求量如果打到MySQL上,那肯定扛不住,直接就崩掉了。也是因為這個原因,Redis經常作為快取存在,能夠起到對資料庫的保護作用。
](https://s3.ap-northeast-1.wasabisys.com/img.tw511.com/202201/65f747e992346b3a7ebb20322b2753falb2r2j2u3dw.png)
可以看出來啊,Redis號稱十萬吞吐量確實也沒吹牛,以後大家面試的時候也可以假裝不經意間提一嘴這個數量級,發現很多人對「十萬級「、」百萬級「這種量級經常亂用,能夠比較精準的說出來也是一個加分項呢。

我是敖丙,你知道的越多,你不知道的越多,感謝各位人才的:點贊、收藏和評論,我們下期見!
文章持續更新,可以微信搜一搜「 三太子敖丙 」第一時間閱讀,回覆【資料】有我準備的一線大廠面試資料和簡歷模板,本文 GitHub https://github.com/JavaFamily 已經收錄,有大廠面試完整考點,歡迎Star。