神經網路學習小記錄66——Vision Transformer(VIT)模型的復現詳解
神經網路學習小記錄66——Vision Transformer(VIT)模型的復現詳解
學習前言
視覺Transformer最近非常的火熱,從VIT開始,我先學學看。

什麼是Vision Transformer(VIT)
Vision Transformer是Transformer的視覺版本,Transformer基本上已經成為了自然語言處理的標配,但是在視覺中的運用還受到限制。
Vision Transformer打破了這種NLP與CV的隔離,將Transformer應用於影象圖塊(patch)序列上,進一步完成影象分類任務。簡單來理解,Vision Transformer就是將輸入進來的圖片,每隔一定的區域大小劃分圖片塊。然後將劃分後的圖片塊組合成序列,將組合後的結果傳入Transformer特有的Multi-head Self-attention進行特徵提取。最後利用Cls Token進行分類。
程式碼下載
Github原始碼下載地址為:
https://github.com/bubbliiiing/classification-keras
複製該路徑到位址列跳轉。
Vision Transforme的實現思路
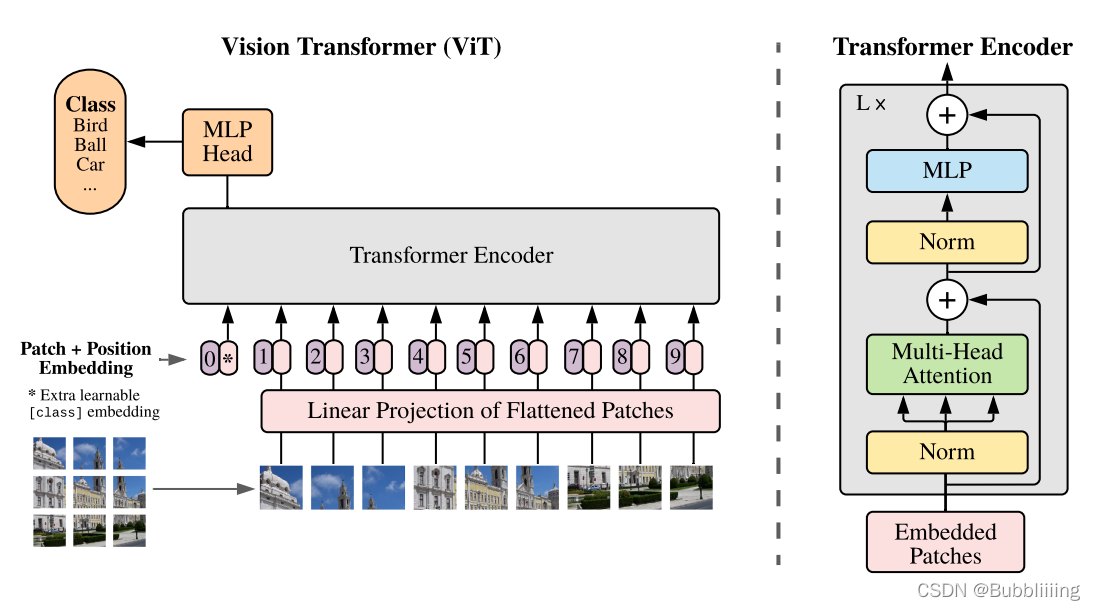
一、整體結構解析
與尋常的分類網路類似,整個Vision Transformer可以氛圍兩部分,一部分是特徵提取部分,另一部分是分類部分。
在特徵提取部分,VIT所做的工作是特徵提取。特徵提取部分在圖片中的對應區域是Patch+Position Embedding和Transformer Encoder。Patch+Position Embedding的作用主要是對輸入進來的圖片進行分塊處理,每隔一定的區域大小劃分圖片塊。然後將劃分後的圖片塊組合成序列。在獲得序列資訊後,傳入Transformer Encoder進行特徵提取,這是Transformer特有的Multi-head Self-attention結構,通過自注意力機制,關注每個圖片塊的重要程度。
在分類部分,VIT所做的工作是利用提取到的特徵進行分類。在進行特徵提取的時候,我們會在圖片序列中新增上Cls Token,該Token會作為一個單位的序列資訊一起進行特徵提取,提取的過程中,該Cls Token會與其它的特徵進行特徵互動,融合其它圖片序列的特徵。最終,我們利用Multi-head Self-attention結構提取特徵後的Cls Token進行全連線分類。
二、網路結構解析
1、特徵提取部分介紹
a、Patch+Position Embedding
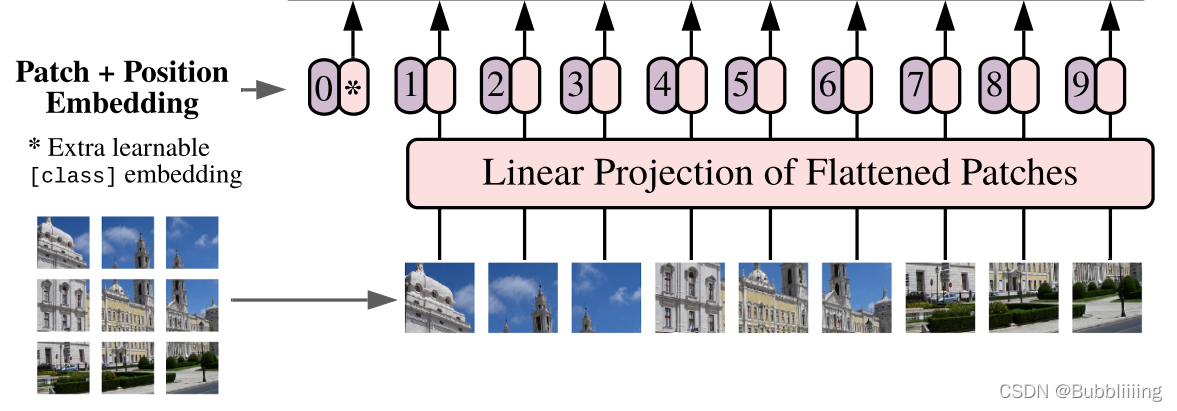
Patch+Position Embedding的作用主要是對輸入進來的圖片進行分塊處理,每隔一定的區域大小劃分圖片塊。然後將劃分後的圖片塊組合成序列。
該部分首先對輸入進來的圖片進行分塊處理,處理方式其實很簡單,使用的是現成的折積。由於折積使用的是滑動視窗的思想,我們只需要設定特定的步長,就可以輸入進來的圖片進行分塊處理了。
在VIT中,我們常設定這個折積的折積核大小為16x16,步長也為16x16,此時折積就會每隔16個畫素點進行一次特徵提取,由於折積核大小為16x16,兩個圖片區域的特徵提取過程就不會有重疊。當我們輸入的圖片是224, 224, 3的時候,我們可以獲得一個14, 14, 768的特徵層。
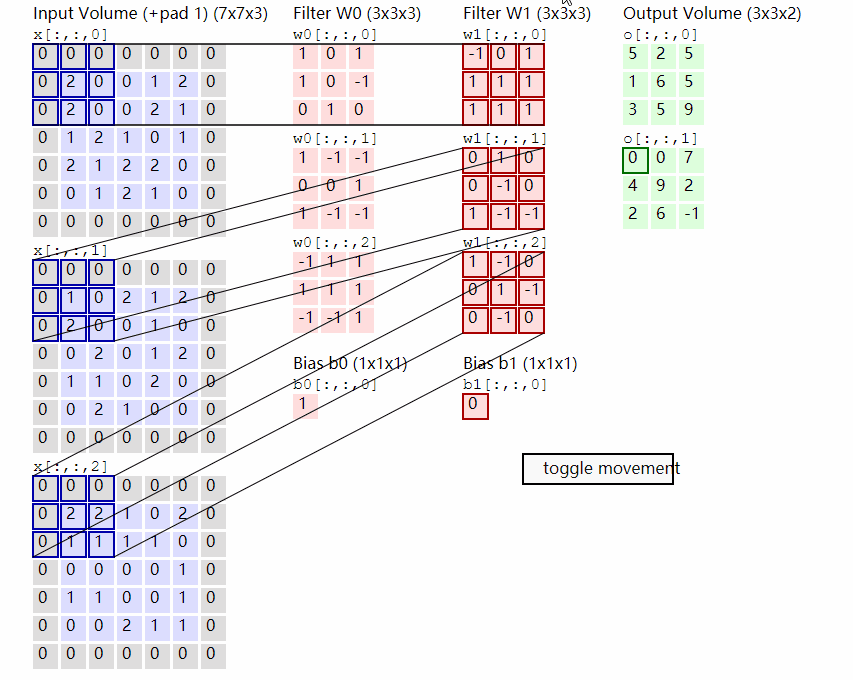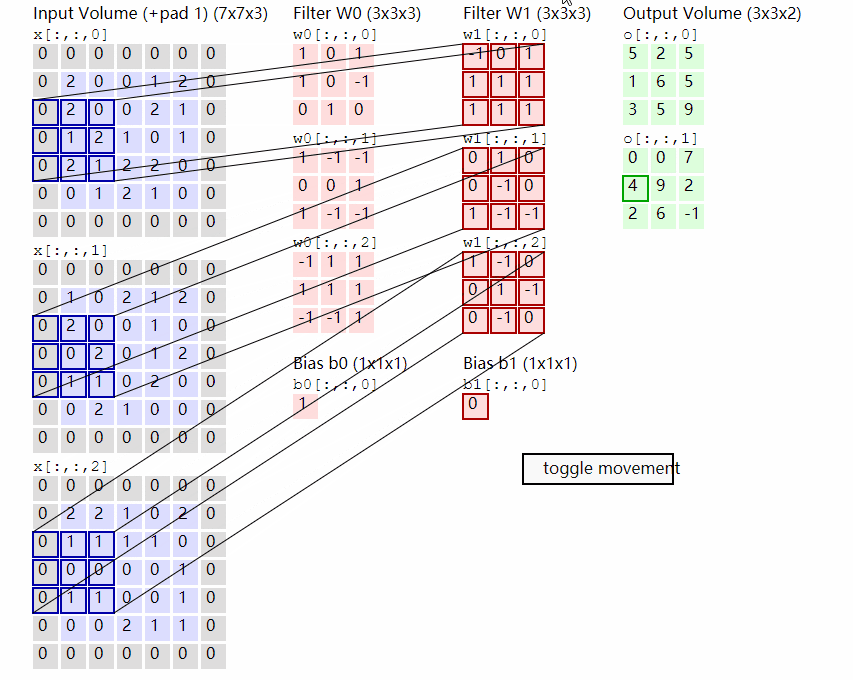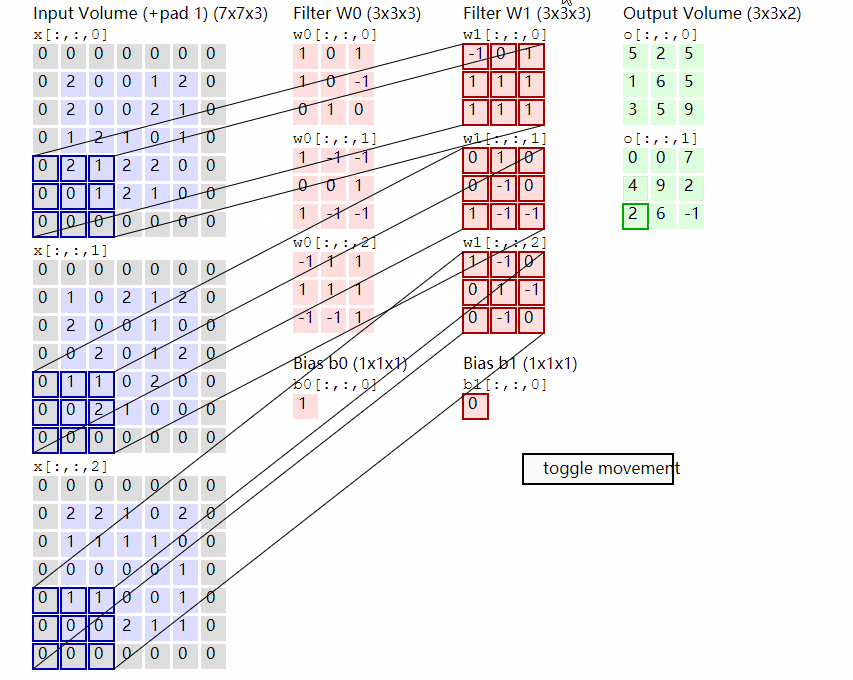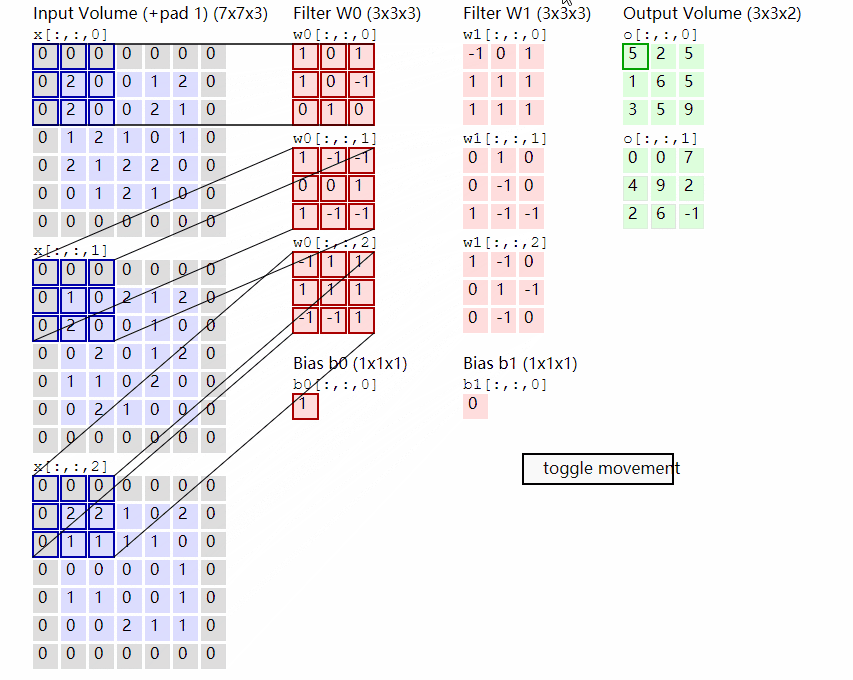
下一步就是將這個特徵層組合成序列,組合的方式非常簡單,就是將高寬維度進行平鋪,14, 14, 768在高寬維度平鋪後,獲得一個196, 768的特徵層。平鋪完成後,我們會在圖片序列中新增上Cls Token,該Token會作為一個單位的序列資訊一起進行特徵提取,圖中的這個0*就是Cls Token,我們此時獲得一個197, 768的特徵層。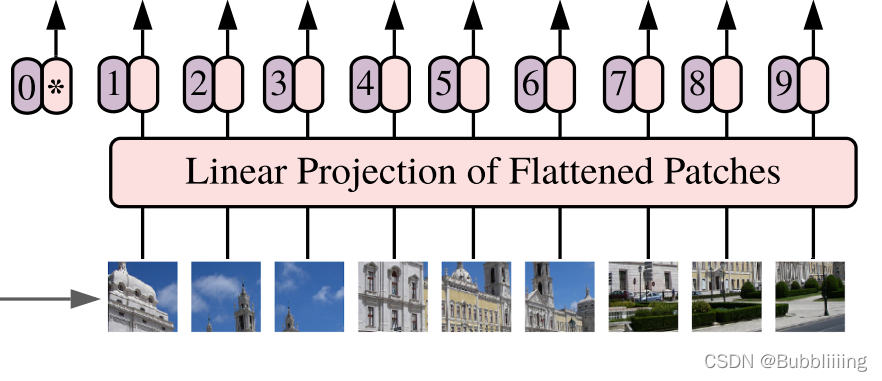
新增完成Cls Token後,再為所有特徵新增上位置資訊,這樣網路才有區分不同區域的能力。新增方式其實也非常簡單,我們生成一個197, 768的引數矩陣,這個引數矩陣是可訓練的,把這個矩陣加上197, 768的特徵層即可。
到這裡,Patch+Position Embedding就構建完成了,構建程式碼如下:
#--------------------------------------------------------------------------------------------------------------------#
# classtoken部分是transformer的分類特徵。用於堆疊到序列化後的圖片特徵中,作為一個單位的序列特徵進行特徵提取。
#
# 在利用步長為16x16的折積將輸入圖片劃分成14x14的部分後,將14x14部分的特徵平鋪,一幅圖片會存在序列長度為196的特徵。
# 此時生成一個classtoken,將classtoken堆疊到序列長度為196的特徵上,獲得一個序列長度為197的特徵。
# 在特徵提取的過程中,classtoken會與圖片特徵進行特徵的互動。最終分類時,我們取出classtoken的特徵,利用全連線分類。
#--------------------------------------------------------------------------------------------------------------------#
class ClassToken(Layer):
def __init__(self, cls_initializer='zeros', cls_regularizer=None, cls_constraint=None, **kwargs):
super(ClassToken, self).__init__(**kwargs)
self.cls_initializer = keras.initializers.get(cls_initializer)
self.cls_regularizer = keras.regularizers.get(cls_regularizer)
self.cls_constraint = keras.constraints.get(cls_constraint)
def get_config(self):
config = {
'cls_initializer': keras.initializers.serialize(self.cls_initializer),
'cls_regularizer': keras.regularizers.serialize(self.cls_regularizer),
'cls_constraint': keras.constraints.serialize(self.cls_constraint),
}
base_config = super(ClassToken, self).get_config()
return dict(list(base_config.items()) + list(config.items()))
def compute_output_shape(self, input_shape):
return (input_shape[0], input_shape[1] + 1, input_shape[2])
def build(self, input_shape):
self.num_features = input_shape[-1]
self.cls = self.add_weight(
shape = (1, 1, self.num_features),
initializer = self.cls_initializer,
regularizer = self.cls_regularizer,
constraint = self.cls_constraint,
name = 'cls',
)
super(ClassToken, self).build(input_shape)
def call(self, inputs):
batch_size = tf.shape(inputs)[0]
cls_broadcasted = tf.cast(tf.broadcast_to(self.cls, [batch_size, 1, self.num_features]), dtype = inputs.dtype)
return tf.concat([cls_broadcasted, inputs], 1)
#--------------------------------------------------------------------------------------------------------------------#
# 為網路提取到的特徵新增上位置資訊。
# 以輸入圖片為224, 224, 3為例,我們獲得的序列化後的圖片特徵為196, 768。加上classtoken後就是197, 768
# 此時生成的pos_Embedding的shape也為197, 768,代表每一個特徵的位置資訊。
#--------------------------------------------------------------------------------------------------------------------#
class AddPositionEmbs(Layer):
def __init__(self, image_shape, patch_size, pe_initializer='zeros', pe_regularizer=None, pe_constraint=None, **kwargs):
super(AddPositionEmbs, self).__init__(**kwargs)
self.image_shape = image_shape
self.patch_size = patch_size
self.pe_initializer = keras.initializers.get(pe_initializer)
self.pe_regularizer = keras.regularizers.get(pe_regularizer)
self.pe_constraint = keras.constraints.get(pe_constraint)
def get_config(self):
config = {
'pe_initializer': keras.initializers.serialize(self.pe_initializer),
'pe_regularizer': keras.regularizers.serialize(self.pe_regularizer),
'pe_constraint': keras.constraints.serialize(self.pe_constraint),
}
base_config = super(AddPositionEmbs, self).get_config()
return dict(list(base_config.items()) + list(config.items()))
def compute_output_shape(self, input_shape):
return input_shape
def build(self, input_shape):
assert (len(input_shape) == 3), f"Number of dimensions should be 3, got {len(input_shape)}"
length = (224 // self.patch_size) * (224 // self.patch_size) + 1
self.pe = self.add_weight(
# shape = [1, input_shape[1], input_shape[2]],
shape = [1, length, input_shape[2]],
initializer = self.pe_initializer,
regularizer = self.pe_regularizer,
constraint = self.pe_constraint,
name = 'pos_embedding',
)
super(AddPositionEmbs, self).build(input_shape)
def call(self, inputs):
num_features = tf.shape(inputs)[2]
cls_token_pe = self.pe[:, 0:1, :]
img_token_pe = self.pe[:, 1: , :]
img_token_pe = tf.reshape(img_token_pe, [1, (224 // self.patch_size), (224 // self.patch_size), num_features])
img_token_pe = tf.image.resize_bicubic(img_token_pe, (self.image_shape[0] // self.patch_size, self.image_shape[1] // self.patch_size), align_corners=False)
img_token_pe = tf.reshape(img_token_pe, [1, -1, num_features])
pe = tf.concat([cls_token_pe, img_token_pe], axis = 1)
return inputs + tf.cast(pe, dtype=inputs.dtype)
def VisionTransformer(input_shape = [224, 224], patch_size = 16, num_layers = 12, num_features = 768, num_heads = 12, mlp_dim = 3072,
classes = 1000, dropout = 0.1):
#-----------------------------------------------#
# 224, 224, 3
#-----------------------------------------------#
inputs = Input(shape = (input_shape[0], input_shape[1], 3))
#-----------------------------------------------#
# 224, 224, 3 -> 14, 14, 768
#-----------------------------------------------#
x = Conv2D(num_features, patch_size, strides = patch_size, padding = "valid", name = "patch_embed.proj")(inputs)
#-----------------------------------------------#
# 14, 14, 768 -> 196, 768
#-----------------------------------------------#
x = Reshape(((input_shape[0] // patch_size) * (input_shape[1] // patch_size), num_features))(x)
#-----------------------------------------------#
# 196, 768 -> 197, 768
#-----------------------------------------------#
x = ClassToken(name="cls_token")(x)
#-----------------------------------------------#
# 197, 768 -> 197, 768
#-----------------------------------------------#
x = AddPositionEmbs(input_shape, patch_size, name="pos_embed")(x)
b、Transformer Encoder
在上一步獲得shape為197, 768的序列資訊後,將序列資訊傳入Transformer Encoder進行特徵提取,這是Transformer特有的Multi-head Self-attention結構,通過自注意力機制,關注每個圖片塊的重要程度。
I、Self-attention結構解析
看懂Self-attention結構,其實看懂下面這個動圖就可以了,動圖中存在一個序列的三個單位輸入,每一個序列單位的輸入都可以通過三個處理(比如全連線)獲得Query、Key、Value,Query是查詢向量、Key是鍵向量、Value值向量。

如果我們想要獲得input-1的輸出,那麼我們進行如下幾步:
1、利用input-1的查詢向量,分別乘上input-1、input-2、input-3的鍵向量,此時我們獲得了三個score。
2、然後對這三個score取softmax,獲得了input-1、input-2、input-3各自的重要程度。
3、然後將這個重要程度乘上input-1、input-2、input-3的值向量,求和。
4、此時我們獲得了input-1的輸出。
如圖所示,我們進行如下幾步:
1、input-1的查詢向量為[1, 0, 2],分別乘上input-1、input-2、input-3的鍵向量,獲得三個score為2,4,4。
2、然後對這三個score取softmax,獲得了input-1、input-2、input-3各自的重要程度,獲得三個重要程度為0.0,0.5,0.5。
3、然後將這個重要程度乘上input-1、input-2、input-3的值向量,求和,即
0.0
∗
[
1
,
2
,
3
]
+
0.5
∗
[
2
,
8
,
0
]
+
0.5
∗
[
2
,
6
,
3
]
=
[
1.0
,
3.0
,
1.5
]
0.0 * [1, 2, 3] + 0.5 * [2, 8, 0] + 0.5 * [2, 6, 3] = [1.0, 3.0, 1.5]
0.0∗[1,2,3]+0.5∗[2,8,0]+0.5∗[2,6,3]=[1.0,3.0,1.5]。
4、此時我們獲得了input-1的輸出 [1.0, 3.0, 1.5]。
上述的例子中,序列長度僅為3,每個單位序列的特徵長度僅為3,在VIT的Transformer Encoder中,序列長度為197,每個單位序列的特徵長度為768 // num_heads。但計算過程是一樣的。在實際運算時,我們採用矩陣進行運算。
II、Self-attention的矩陣運算
實際的矩陣運算過程如下圖所示。我以實際矩陣為例子給大家解析:
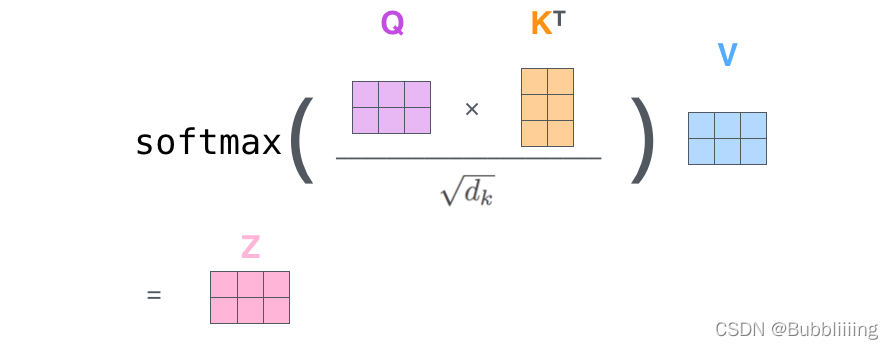
輸入的Query、Key、Value如下圖所示:
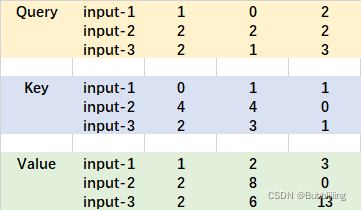
首先利用 查詢向量query 點乘 轉置後的鍵向量key,這一步可以通俗的理解為,利用查詢向量去查詢序列的特徵,獲得序列每個部分的重要程度score。
輸出的每一行,都代表input-1、input-2、input-3,對當前input的貢獻,我們對這個貢獻值取一個softmax。


然後利用 score 點乘 value,這一步可以通俗的理解為,將序列每個部分的重要程度重新施加到序列的值上去。

這個矩陣運算的程式碼如下所示,各位同學可以自己試試。
import numpy as np
def soft_max(z):
t = np.exp(z)
a = np.exp(z) / np.expand_dims(np.sum(t, axis=1), 1)
return a
Query = np.array([
[1,0,2],
[2,2,2],
[2,1,3]
])
Key = np.array([
[0,1,1],
[4,4,0],
[2,3,1]
])
Value = np.array([
[1,2,3],
[2,8,0],
[2,6,3]
])
scores = Query @ Key.T
print(scores)
scores = soft_max(scores)
print(scores)
out = scores @ Value
print(out)
III、MultiHead多頭注意力機制
多頭注意力機制的示意圖如圖所示:
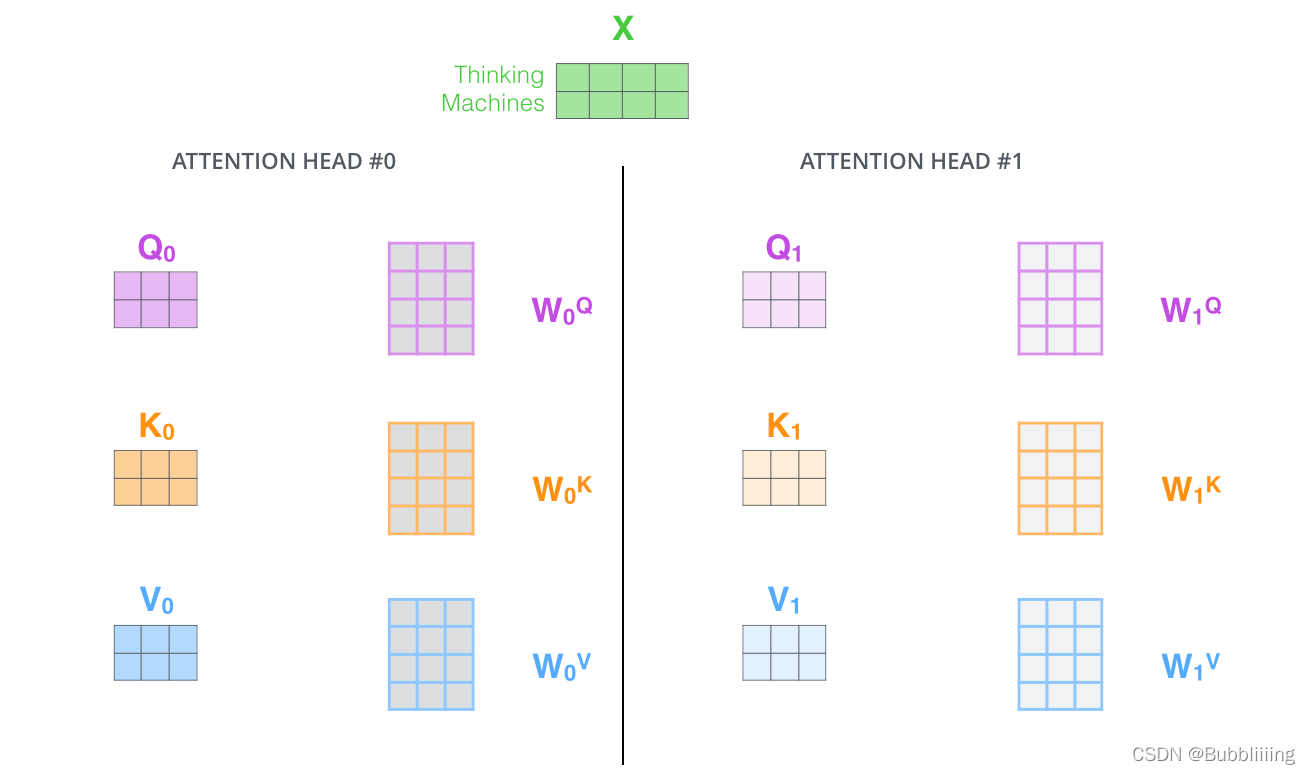
這幅圖給人的感覺略顯迷茫,我們跳脫出這個圖,直接從矩陣的shape入手會清晰很多。
在第一步進行影象的分割後,我們獲得的特徵層為197, 768。
在施加多頭的時候,我們直接對196, 768的最後一維度進行分割,比如我們想分割成12個頭,那麼矩陣的shepe就變成了196, 12, 64。
然後我們將196, 12, 64進行轉置,將12放到前面去,獲得的特徵層為12, 196, 64。之後我們忽略這個12,把它和batch維度同等對待,只對196, 64進行處理,其實也就是上面的注意力機制的過程了。
#--------------------------------------------------------------------------------------------------------------------#
# Attention機制
# 將輸入的特徵qkv特徵進行劃分,首先生成query, key, value。query是查詢向量、key是鍵向量、v是值向量。
# 然後利用 查詢向量query 點乘 轉置後的鍵向量key,這一步可以通俗的理解為,利用查詢向量去查詢序列的特徵,獲得序列每個部分的重要程度score。
# 然後利用 score 點乘 value,這一步可以通俗的理解為,將序列每個部分的重要程度重新施加到序列的值上去。
#--------------------------------------------------------------------------------------------------------------------#
class Attention(Layer):
def __init__(self, num_features, num_heads, **kwargs):
super(Attention, self).__init__(**kwargs)
self.num_features = num_features
self.num_heads = num_heads
self.projection_dim = num_features // num_heads
def compute_output_shape(self, input_shape):
return (input_shape[0], input_shape[1], input_shape[2] // 3)
def call(self, inputs):
#-----------------------------------------------#
# 獲得batch_size
#-----------------------------------------------#
bs = tf.shape(inputs)[0]
#-----------------------------------------------#
# b, 197, 3 * 768 -> b, 197, 3, 12, 64
#-----------------------------------------------#
inputs = tf.reshape(inputs, [bs, -1, 3, self.num_heads, self.projection_dim])
#-----------------------------------------------#
# b, 197, 3, 12, 64 -> 3, b, 12, 197, 64
#-----------------------------------------------#
inputs = tf.transpose(inputs, [2, 0, 3, 1, 4])
#-----------------------------------------------#
# 將query, key, value劃分開
# query b, 12, 197, 64
# key b, 12, 197, 64
# value b, 12, 197, 64
#-----------------------------------------------#
query, key, value = inputs[0], inputs[1], inputs[2]
#-----------------------------------------------#
# b, 12, 197, 64 @ b, 12, 197, 64 = b, 12, 197, 197
#-----------------------------------------------#
score = tf.matmul(query, key, transpose_b=True)
#-----------------------------------------------#
# 進行數量級的縮放
#-----------------------------------------------#
scaled_score = score / tf.math.sqrt(tf.cast(self.projection_dim, score.dtype))
#-----------------------------------------------#
# b, 12, 197, 197 -> b, 12, 197, 197
#-----------------------------------------------#
weights = tf.nn.softmax(scaled_score, axis=-1)
#-----------------------------------------------#
# b, 12, 197, 197 @ b, 12, 197, 64 = b, 12, 197, 64
#-----------------------------------------------#
value = tf.matmul(weights, value)
#-----------------------------------------------#
# b, 12, 197, 64 -> b, 197, 12, 64
#-----------------------------------------------#
value = tf.transpose(value, perm=[0, 2, 1, 3])
#-----------------------------------------------#
# b, 197, 12, 64 -> b, 197, 768
#-----------------------------------------------#
output = tf.reshape(value, (tf.shape(value)[0], tf.shape(value)[1], -1))
return output
def MultiHeadSelfAttention(inputs, num_features, num_heads, dropout, name):
#-----------------------------------------------#
# qkv b, 197, 768 -> b, 197, 3 * 768
#-----------------------------------------------#
qkv = Dense(int(num_features * 3), name = name + "qkv")(inputs)
#-----------------------------------------------#
# b, 197, 3 * 768 -> b, 197, 768
#-----------------------------------------------#
x = Attention(num_features, num_heads)(qkv)
#-----------------------------------------------#
# 197, 768 -> 197, 768
#-----------------------------------------------#
x = Dense(num_features, name = name + "proj")(x)
x = Dropout(dropout)(x)
return x
IV、TransformerBlock的構建。
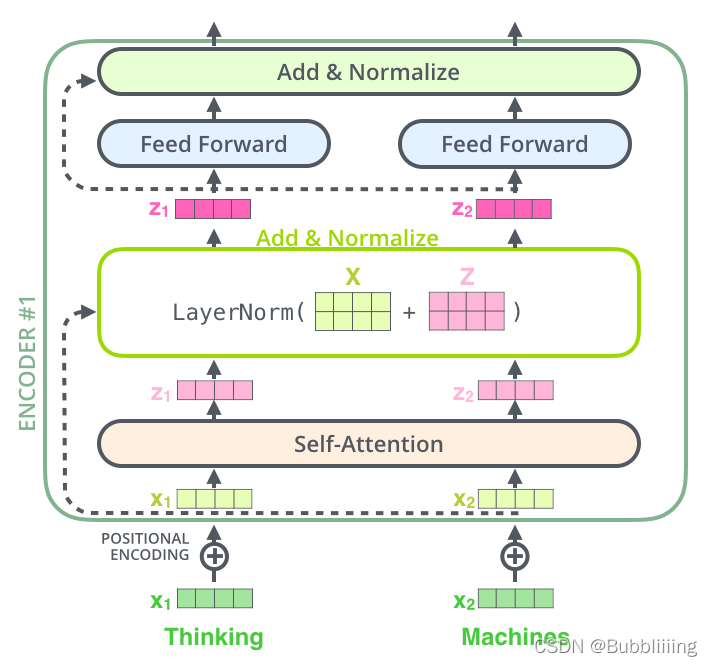
在完成MultiHeadSelfAttention的構建後,我們需要在其後加上兩個全連線。就構建了整個TransformerBlock。
def MLP(y, num_features, mlp_dim, dropout, name):
y = Dense(mlp_dim, name = name + "fc1")(y)
y = Gelu()(y)
y = Dropout(dropout)(y)
y = Dense(num_features, name = name + "fc2")(y)
return y
def TransformerBlock(inputs, num_features, num_heads, mlp_dim, dropout, name):
#-----------------------------------------------#
# 施加層標準化
#-----------------------------------------------#
x = LayerNormalization(epsilon=1e-6, name = name + "norm1")(inputs)
#-----------------------------------------------#
# 施加多頭注意力機制
#-----------------------------------------------#
x = MultiHeadSelfAttention(x, num_features, num_heads, dropout, name = name + "attn.")
x = Dropout(dropout)(x)
#-----------------------------------------------#
# 施加殘差結構
#-----------------------------------------------#
x = Add()([x, inputs])
#-----------------------------------------------#
# 施加層標準化
#-----------------------------------------------#
y = LayerNormalization(epsilon=1e-6, name = name + "norm2")(x)
#-----------------------------------------------#
# 施加兩次全連線
#-----------------------------------------------#
y = MLP(y, num_features, mlp_dim, dropout, name = name + "mlp.")
y = Dropout(dropout)(y)
#-----------------------------------------------#
# 施加殘差結構
#-----------------------------------------------#
y = Add()([x, y])
return y
c、整個VIT模型的構建
整個VIT模型由一個Patch+Position Embedding加上多個TransformerBlock組成。典型的TransforerBlock的數量為12個。
def VisionTransformer(input_shape = [224, 224], patch_size = 16, num_layers = 12, num_features = 768, num_heads = 12, mlp_dim = 3072,
classes = 1000, dropout = 0.1):
#-----------------------------------------------#
# 224, 224, 3
#-----------------------------------------------#
inputs = Input(shape = (input_shape[0], input_shape[1], 3))
#-----------------------------------------------#
# 224, 224, 3 -> 14, 14, 768
#-----------------------------------------------#
x = Conv2D(num_features, patch_size, strides = patch_size, padding = "valid", name = "patch_embed.proj")(inputs)
#-----------------------------------------------#
# 14, 14, 768 -> 196, 768
#-----------------------------------------------#
x = Reshape(((input_shape[0] // patch_size) * (input_shape[1] // patch_size), num_features))(x)
#-----------------------------------------------#
# 196, 768 -> 197, 768
#-----------------------------------------------#
x = ClassToken(name="cls_token")(x)
#-----------------------------------------------#
# 197, 768 -> 197, 768
#-----------------------------------------------#
x = AddPositionEmbs(input_shape, patch_size, name="pos_embed")(x)
#-----------------------------------------------#
# 197, 768 -> 197, 768 12次
#-----------------------------------------------#
for n in range(num_layers):
x = TransformerBlock(
x,
num_features= num_features,
num_heads = num_heads,
mlp_dim = mlp_dim,
dropout = dropout,
name = "blocks." + str(n) + ".",
)
x = LayerNormalization(
epsilon=1e-6, name="norm"
)(x)
2、分類部分
在分類部分,VIT所做的工作是利用提取到的特徵進行分類。
在進行特徵提取的時候,我們會在圖片序列中新增上Cls Token,該Token會作為一個單位的序列資訊一起進行特徵提取,提取的過程中,該Cls Token會與其它的特徵進行特徵互動,融合其它圖片序列的特徵。
最終,我們利用Multi-head Self-attention結構提取特徵後的Cls Token進行全連線分類。
def VisionTransformer(input_shape = [224, 224], patch_size = 16, num_layers = 12, num_features = 768, num_heads = 12, mlp_dim = 3072,
classes = 1000, dropout = 0.1):
#-----------------------------------------------#
# 224, 224, 3
#-----------------------------------------------#
inputs = Input(shape = (input_shape[0], input_shape[1], 3))
#-----------------------------------------------#
# 224, 224, 3 -> 14, 14, 768
#-----------------------------------------------#
x = Conv2D(num_features, patch_size, strides = patch_size, padding = "valid", name = "patch_embed.proj")(inputs)
#-----------------------------------------------#
# 14, 14, 768 -> 196, 768
#-----------------------------------------------#
x = Reshape(((input_shape[0] // patch_size) * (input_shape[1] // patch_size), num_features))(x)
#-----------------------------------------------#
# 196, 768 -> 197, 768
#-----------------------------------------------#
x = ClassToken(name="cls_token")(x)
#-----------------------------------------------#
# 197, 768 -> 197, 768
#-----------------------------------------------#
x = AddPositionEmbs(input_shape, patch_size, name="pos_embed")(x)
#-----------------------------------------------#
# 197, 768 -> 197, 768 12次
#-----------------------------------------------#
for n in range(num_layers):
x = TransformerBlock(
x,
num_features= num_features,
num_heads = num_heads,
mlp_dim = mlp_dim,
dropout = dropout,
name = "blocks." + str(n) + ".",
)
x = LayerNormalization(
epsilon=1e-6, name="norm"
)(x)
x = Lambda(lambda v: v[:, 0], name="ExtractToken")(x)
x = Dense(classes, name="head")(x)
x = Softmax()(x)
return keras.models.Model(inputs, x)
Vision Transforme的構建程式碼
import math
import keras
import tensorflow as tf
from keras import backend as K
from keras.layers import (Add, Conv2D, Dense, Dropout, Input, Lambda, Layer,
Reshape, Softmax)
#--------------------------------------#
# LayerNormalization
# 層標準化的實現
#--------------------------------------#
class LayerNormalization(keras.layers.Layer):
def __init__(self,
center=True,
scale=True,
epsilon=None,
gamma_initializer='ones',
beta_initializer='zeros',
gamma_regularizer=None,
beta_regularizer=None,
gamma_constraint=None,
beta_constraint=None,
**kwargs):
"""Layer normalization layer
See: [Layer Normalization](https://arxiv.org/pdf/1607.06450.pdf)
:param center: Add an offset parameter if it is True.
:param scale: Add a scale parameter if it is True.
:param epsilon: Epsilon for calculating variance.
:param gamma_initializer: Initializer for the gamma weight.
:param beta_initializer: Initializer for the beta weight.
:param gamma_regularizer: Optional regularizer for the gamma weight.
:param beta_regularizer: Optional regularizer for the beta weight.
:param gamma_constraint: Optional constraint for the gamma weight.
:param beta_constraint: Optional constraint for the beta weight.
:param kwargs:
"""
super(LayerNormalization, self).__init__(**kwargs)
self.supports_masking = True
self.center = center
self.scale = scale
if epsilon is None:
epsilon = K.epsilon() * K.epsilon()
self.epsilon = epsilon
self.gamma_initializer = keras.initializers.get(gamma_initializer)
self.beta_initializer = keras.initializers.get(beta_initializer)
self.gamma_regularizer = keras.regularizers.get(gamma_regularizer)
self.beta_regularizer = keras.regularizers.get(beta_regularizer)
self.gamma_constraint = keras.constraints.get(gamma_constraint)
self.beta_constraint = keras.constraints.get(beta_constraint)
self.gamma, self.beta = None, None
def get_config(self):
config = {
'center': self.center,
'scale': self.scale,
'epsilon': self.epsilon,
'gamma_initializer': keras.initializers.serialize(self.gamma_initializer),
'beta_initializer': keras.initializers.serialize(self.beta_initializer),
'gamma_regularizer': keras.regularizers.serialize(self.gamma_regularizer),
'beta_regularizer': keras.regularizers.serialize(self.beta_regularizer),
'gamma_constraint': keras.constraints.serialize(self.gamma_constraint),
'beta_constraint': keras.constraints.serialize(self.beta_constraint),
}
base_config = super(LayerNormalization, self).get_config()
return dict(list(base_config.items()) + list(config.items()))
def compute_output_shape(self, input_shape):
return input_shape
def compute_mask(self, inputs, input_mask=None):
return input_mask
def build(self, input_shape):
shape = input_shape[-1:]
if self.scale:
self.gamma = self.add_weight(
shape=shape,
initializer=self.gamma_initializer,
regularizer=self.gamma_regularizer,
constraint=self.gamma_constraint,
name='gamma',
)
if self.center:
self.beta = self.add_weight(
shape=shape,
initializer=self.beta_initializer,
regularizer=self.beta_regularizer,
constraint=self.beta_constraint,
name='beta',
)
super(LayerNormalization, self).build(input_shape)
def call(self, inputs, training=None):
mean = K.mean(inputs, axis=-1, keepdims=True)
variance = K.mean(K.square(inputs - mean), axis=-1, keepdims=True)
std = K.sqrt(variance + self.epsilon)
outputs = (inputs - mean) / std
if self.scale:
outputs *= self.gamma
if self.center:
outputs += self.beta
return outputs
#--------------------------------------#
# Gelu啟用函數的實現
# 利用近似的數學公式
#--------------------------------------#
class Gelu(Layer):
def __init__(self, **kwargs):
super(Gelu, self).__init__(**kwargs)
self.supports_masking = True
def call(self, inputs):
return 0.5 * inputs * (1 + tf.tanh(tf.sqrt(2 / math.pi) * (inputs + 0.044715 * tf.pow(inputs, 3))))
def get_config(self):
config = super(Gelu, self).get_config()
return config
def compute_output_shape(self, input_shape):
return input_shape
#--------------------------------------------------------------------------------------------------------------------#
# classtoken部分是transformer的分類特徵。用於堆疊到序列化後的圖片特徵中,作為一個單位的序列特徵進行特徵提取。
#
# 在利用步長為16x16的折積將輸入圖片劃分成14x14的部分後,將14x14部分的特徵平鋪,一幅圖片會存在序列長度為196的特徵。
# 此時生成一個classtoken,將classtoken堆疊到序列長度為196的特徵上,獲得一個序列長度為197的特徵。
# 在特徵提取的過程中,classtoken會與圖片特徵進行特徵的互動。最終分類時,我們取出classtoken的特徵,利用全連線分類。
#--------------------------------------------------------------------------------------------------------------------#
class ClassToken(Layer):
def __init__(self, cls_initializer='zeros', cls_regularizer=None, cls_constraint=None, **kwargs):
super(ClassToken, self).__init__(**kwargs)
self.cls_initializer = keras.initializers.get(cls_initializer)
self.cls_regularizer = keras.regularizers.get(cls_regularizer)
self.cls_constraint = keras.constraints.get(cls_constraint)
def get_config(self):
config = {
'cls_initializer': keras.initializers.serialize(self.cls_initializer),
'cls_regularizer': keras.regularizers.serialize(self.cls_regularizer),
'cls_constraint': keras.constraints.serialize(self.cls_constraint),
}
base_config = super(ClassToken, self).get_config()
return dict(list(base_config.items()) + list(config.items()))
def compute_output_shape(self, input_shape):
return (input_shape[0], input_shape[1] + 1, input_shape[2])
def build(self, input_shape):
self.num_features = input_shape[-1]
self.cls = self.add_weight(
shape = (1, 1, self.num_features),
initializer = self.cls_initializer,
regularizer = self.cls_regularizer,
constraint = self.cls_constraint,
name = 'cls',
)
super(ClassToken, self).build(input_shape)
def call(self, inputs):
batch_size = tf.shape(inputs)[0]
cls_broadcasted = tf.cast(tf.broadcast_to(self.cls, [batch_size, 1, self.num_features]), dtype = inputs.dtype)
return tf.concat([cls_broadcasted, inputs], 1)
#--------------------------------------------------------------------------------------------------------------------#
# 為網路提取到的特徵新增上位置資訊。
# 以輸入圖片為224, 224, 3為例,我們獲得的序列化後的圖片特徵為196, 768。加上classtoken後就是197, 768
# 此時生成的pos_Embedding的shape也為197, 768,代表每一個特徵的位置資訊。
#--------------------------------------------------------------------------------------------------------------------#
class AddPositionEmbs(Layer):
def __init__(self, image_shape, patch_size, pe_initializer='zeros', pe_regularizer=None, pe_constraint=None, **kwargs):
super(AddPositionEmbs, self).__init__(**kwargs)
self.image_shape = image_shape
self.patch_size = patch_size
self.pe_initializer = keras.initializers.get(pe_initializer)
self.pe_regularizer = keras.regularizers.get(pe_regularizer)
self.pe_constraint = keras.constraints.get(pe_constraint)
def get_config(self):
config = {
'pe_initializer': keras.initializers.serialize(self.pe_initializer),
'pe_regularizer': keras.regularizers.serialize(self.pe_regularizer),
'pe_constraint': keras.constraints.serialize(self.pe_constraint),
}
base_config = super(AddPositionEmbs, self).get_config()
return dict(list(base_config.items()) + list(config.items()))
def compute_output_shape(self, input_shape):
return input_shape
def build(self, input_shape):
assert (len(input_shape) == 3), f"Number of dimensions should be 3, got {len(input_shape)}"
length = (224 // self.patch_size) * (224 // self.patch_size) + 1
self.pe = self.add_weight(
# shape = [1, input_shape[1], input_shape[2]],
shape = [1, length, input_shape[2]],
initializer = self.pe_initializer,
regularizer = self.pe_regularizer,
constraint = self.pe_constraint,
name = 'pos_embedding',
)
super(AddPositionEmbs, self).build(input_shape)
def call(self, inputs):
num_features = tf.shape(inputs)[2]
cls_token_pe = self.pe[:, 0:1, :]
img_token_pe = self.pe[:, 1: , :]
img_token_pe = tf.reshape(img_token_pe, [1, (224 // self.patch_size), (224 // self.patch_size), num_features])
img_token_pe = tf.image.resize_bicubic(img_token_pe, (self.image_shape[0] // self.patch_size, self.image_shape[1] // self.patch_size), align_corners=False)
img_token_pe = tf.reshape(img_token_pe, [1, -1, num_features])
pe = tf.concat([cls_token_pe, img_token_pe], axis = 1)
return inputs + tf.cast(pe, dtype=inputs.dtype)
#--------------------------------------------------------------------------------------------------------------------#
# Attention機制
# 將輸入的特徵qkv特徵進行劃分,首先生成query, key, value。query是查詢向量、key是鍵向量、v是值向量。
# 然後利用 查詢向量query 點乘 轉置後的鍵向量key,這一步可以通俗的理解為,利用查詢向量去查詢序列的特徵,獲得序列每個部分的重要程度score。
# 然後利用 score 點乘 value,這一步可以通俗的理解為,將序列每個部分的重要程度重新施加到序列的值上去。
#--------------------------------------------------------------------------------------------------------------------#
class Attention(Layer):
def __init__(self, num_features, num_heads, **kwargs):
super(Attention, self).__init__(**kwargs)
self.num_features = num_features
self.num_heads = num_heads
self.projection_dim = num_features // num_heads
def compute_output_shape(self, input_shape):
return (input_shape[0], input_shape[1], input_shape[2] // 3)
def call(self, inputs):
#-----------------------------------------------#
# 獲得batch_size
#-----------------------------------------------#
bs = tf.shape(inputs)[0]
#-----------------------------------------------#
# b, 197, 3 * 768 -> b, 197, 3, 12, 64
#-----------------------------------------------#
inputs = tf.reshape(inputs, [bs, -1, 3, self.num_heads, self.projection_dim])
#-----------------------------------------------#
# b, 197, 3, 12, 64 -> 3, b, 12, 197, 64
#-----------------------------------------------#
inputs = tf.transpose(inputs, [2, 0, 3, 1, 4])
#-----------------------------------------------#
# 將query, key, value劃分開
# query b, 12, 197, 64
# key b, 12, 197, 64
# value b, 12, 197, 64
#-----------------------------------------------#
query, key, value = inputs[0], inputs[1], inputs[2]
#-----------------------------------------------#
# b, 12, 197, 64 @ b, 12, 197, 64 = b, 12, 197, 197
#-----------------------------------------------#
score = tf.matmul(query, key, transpose_b=True)
#-----------------------------------------------#
# 進行數量級的縮放
#-----------------------------------------------#
scaled_score = score / tf.math.sqrt(tf.cast(self.projection_dim, score.dtype))
#-----------------------------------------------#
# b, 12, 197, 197 -> b, 12, 197, 197
#-----------------------------------------------#
weights = tf.nn.softmax(scaled_score, axis=-1)
#-----------------------------------------------#
# b, 12, 197, 197 @ b, 12, 197, 64 = b, 12, 197, 64
#-----------------------------------------------#
value = tf.matmul(weights, value)
#-----------------------------------------------#
# b, 12, 197, 64 -> b, 197, 12, 64
#-----------------------------------------------#
value = tf.transpose(value, perm=[0, 2, 1, 3])
#-----------------------------------------------#
# b, 197, 12, 64 -> b, 197, 768
#-----------------------------------------------#
output = tf.reshape(value, (tf.shape(value)[0], tf.shape(value)[1], -1))
return output
def MultiHeadSelfAttention(inputs, num_features, num_heads, dropout, name):
#-----------------------------------------------#
# qkv b, 197, 768 -> b, 197, 3 * 768
#-----------------------------------------------#
qkv = Dense(int(num_features * 3), name = name + "qkv")(inputs)
#-----------------------------------------------#
# b, 197, 3 * 768 -> b, 197, 768
#-----------------------------------------------#
x = Attention(num_features, num_heads)(qkv)
#-----------------------------------------------#
# 197, 768 -> 197, 768
#-----------------------------------------------#
x = Dense(num_features, name = name + "proj")(x)
x = Dropout(dropout)(x)
return x
def MLP(y, num_features, mlp_dim, dropout, name):
y = Dense(mlp_dim, name = name + "fc1")(y)
y = Gelu()(y)
y = Dropout(dropout)(y)
y = Dense(num_features, name = name + "fc2")(y)
return y
def TransformerBlock(inputs, num_features, num_heads, mlp_dim, dropout, name):
#-----------------------------------------------#
# 施加層標準化
#-----------------------------------------------#
x = LayerNormalization(epsilon=1e-6, name = name + "norm1")(inputs)
#-----------------------------------------------#
# 施加多頭注意力機制
#-----------------------------------------------#
x = MultiHeadSelfAttention(x, num_features, num_heads, dropout, name = name + "attn.")
x = Dropout(dropout)(x)
#-----------------------------------------------#
# 施加殘差結構
#-----------------------------------------------#
x = Add()([x, inputs])
#-----------------------------------------------#
# 施加層標準化
#-----------------------------------------------#
y = LayerNormalization(epsilon=1e-6, name = name + "norm2")(x)
#-----------------------------------------------#
# 施加兩次全連線
#-----------------------------------------------#
y = MLP(y, num_features, mlp_dim, dropout, name = name + "mlp.")
y = Dropout(dropout)(y)
#-----------------------------------------------#
# 施加殘差結構
#-----------------------------------------------#
y = Add()([x, y])
return y
def VisionTransformer(input_shape = [224, 224], patch_size = 16, num_layers = 12, num_features = 768, num_heads = 12, mlp_dim = 3072,
classes = 1000, dropout = 0.1):
#-----------------------------------------------#
# 224, 224, 3
#-----------------------------------------------#
inputs = Input(shape = (input_shape[0], input_shape[1], 3))
#-----------------------------------------------#
# 224, 224, 3 -> 14, 14, 768
#-----------------------------------------------#
x = Conv2D(num_features, patch_size, strides = patch_size, padding = "valid", name = "patch_embed.proj")(inputs)
#-----------------------------------------------#
# 14, 14, 768 -> 196, 768
#-----------------------------------------------#
x = Reshape(((input_shape[0] // patch_size) * (input_shape[1] // patch_size), num_features))(x)
#-----------------------------------------------#
# 196, 768 -> 197, 768
#-----------------------------------------------#
x = ClassToken(name="cls_token")(x)
#-----------------------------------------------#
# 197, 768 -> 197, 768
#-----------------------------------------------#
x = AddPositionEmbs(input_shape, patch_size, name="pos_embed")(x)
#-----------------------------------------------#
# 197, 768 -> 197, 768 12次
#-----------------------------------------------#
for n in range(num_layers):
x = TransformerBlock(
x,
num_features= num_features,
num_heads = num_heads,
mlp_dim = mlp_dim,
dropout = dropout,
name = "blocks." + str(n) + ".",
)
x = LayerNormalization(
epsilon=1e-6, name="norm"
)(x)
x = Lambda(lambda v: v[:, 0], name="ExtractToken")(x)
x = Dense(classes, name="head")(x)
x = Softmax()(x)
return keras.models.Model(inputs, x)