資料庫-Elasticsearch進階學習筆記(分片、對映、分詞器、即時搜尋、全文搜尋等)
本文基於資料庫-ElasticSearch入門(索引、檔案、查詢),假設讀者已學會安裝ES,使用Postman和某語言的包或模組來對索引和檔案進行基本的增刪改查。
基礎概念
定義
Elasticsearch 是一個開源的搜尋引擎,建立在一個全文搜尋引擎庫 Apache Lucene基礎之上。Elasticsearch 也是使用** Java** 編寫的,它的內部使用 Lucene 做索引與搜尋,但是它的目的是使全文檢索變得簡單, 通過隱藏 Lucene 的複雜性,取而代之的提供一套簡單一致的 RESTful API。
特點
- 一個分散式的實時檔案儲存,每個欄位可以被索引與搜尋
- 一個分散式實時分析搜尋引擎
- 能勝任上百個服務節點的擴充套件,並支援 PB 級別的結構化或者非結構化資料
curl "http://localhost:9200/"
{
"name" : "DESKTOP-BT64DM0",
"cluster_name" : "elasticsearch",
"cluster_uuid" : "Xk7sJl7OSei9DIyrn1G-vg",
"version" : {
"number" : "7.10.0",
"build_flavor" : "default",
"build_type" : "zip",
"build_hash" : "51e9d6f22758d0374a0f3f5c6e8f3a7997850f96",
"build_date" : "2020-11-09T21:30:33.964949Z",
"build_snapshot" : false,
"lucene_version" : "8.7.0",
"minimum_wire_compatibility_version" : "6.8.0",
"minimum_index_compatibility_version" : "6.0.0-beta1"
},
"tagline" : "You Know, for Search"
}
啟動後存取9200埠,可以看到ES版本,叢集名稱,lucence版本等內容。
兩個 Java 使用者端都是通過 9300 埠並使用 Elasticsearch 的原生傳輸協定和叢集互動。叢集中的節點通過埠 9300 彼此通訊。如果這個埠沒有開啟,節點將無法形成一個叢集。
索引(Index)
可以建立索引時,攜帶請求體body,設定分片,mapping等
分片(Shards)
類似分表,進行容量擴充套件。ES可以將一個索引的分片放到不同的節點上,這樣可以進行快速的分散式搜尋。總的來說,分片可以
- 允許水平分分割/擴充套件容量。
- 允許進行分散式、並行的操作,提高吞吐量/效能。
副本(Replicas)
在一些情況下,可能導致某個節點/分片處於離線狀態,為了保證出現故障時不影響服務,提出了副本,進行容災備份,提供高可用性。
分配(Allocation)
master節點完成分配主分片和副本的過程。
對映(Mapping)
mapping是處理資料的方式和規則的限制。如欄位的資料型別、是否被索引、分析器等。
動態對映
為了對新手友好一些,可以直接建立index,不用指定欄位及型別,ES自動新增。
顯式對映
瞭解欄位型別之後,給不同的欄位自定義資料型別,建立索引時進行指定。
PUT my-index
{
"mappings": {
"properties": {
"city": {
"type": "text",
"fields": {
"raw": {
"type": "keyword"
}
}
}
}
}
}
properties新增欄位,fields使一個欄位在不同型別搜尋時是否可分析
city欄位全文檢索
city.raw欄位是city的keyword版本,可被用於排序和聚合操作。
接下來先了解欄位等概念,之後再配合搜尋對對映進行深入理解。
常見資料型別
- boolean:true、false
- Numeric:
- byte:8位元有符號整數
- short:16位元有符號整數
- integer:32位元有符號整數
- long、unsigned_long:有(無)符號64位元整數
- Keywords:
- keyword:用於結構化內容,例如 ID、電子郵件地址、主機名、狀態程式碼、郵政編碼或標籤。
- constant_keyword:始終包含相同值的關鍵字欄位。
- wildcard:非結構化,機器生成的長資料
- date:日期,可使用format自定義
- Range:
- integer_range:32位元有字元整數,-231 ~ 231-1
- long_range:64位元有符號整數
- double_range:64位元IEEE754型別浮點數
- date_range:日期,可以使用format自定義格式
- ip_range:ipv4和ipv6均支援
- Text:
- text:全文,一般是會進行分析和分析,郵件正文,商品描述等
- match_only_text:空間優化,禁用評分,適合紀錄檔訊息。
檔案(document)
- _index:檔案存放在的索引
- _type:檔案表示的物件類別,之前與關係型資料庫的table對應,現在不再強調這個
- _id:檔案唯一標識
- _version:版本,更新檔案時,該欄位會改變
- _source:資料
領域特定語言 (DSL)
使用 JSON 構造了一個請求。包含了filter range過濾器。
分詞器
在全文檢索情況下,對text等型別分詞,方便建立倒排索引。常見的分詞器有
- ik分詞器
- icu分詞器
- smartcn分詞器
- pinyin分詞器
更多分詞器見參考,es官方github上有一些。騰訊雲可支援大部分外掛,點選ES叢集->外掛列表。如下圖所示。
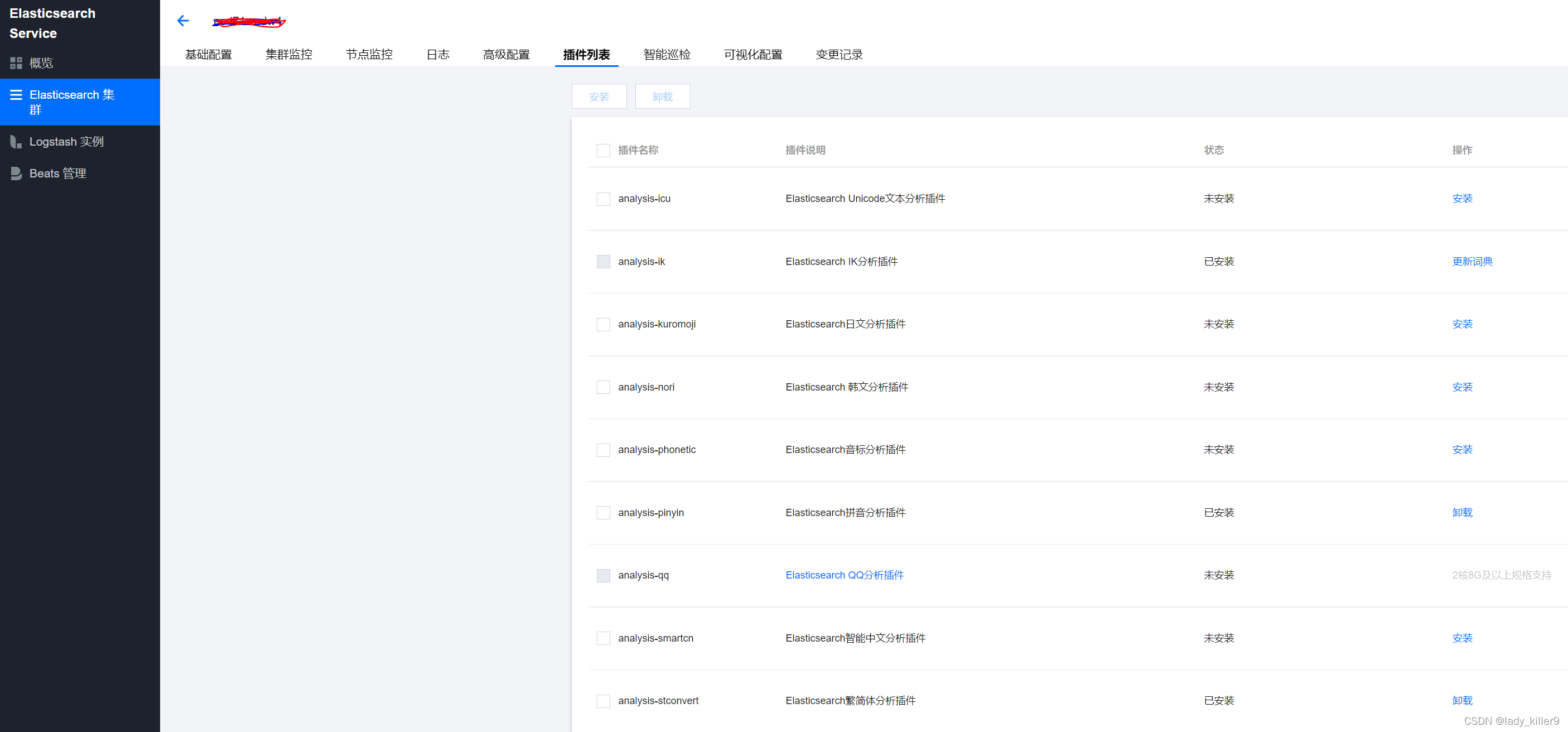
得分排序
按照相關性得分排序,一般使用TF-IDF演演算法(見參考,本文主要還是在ES實踐方面,演演算法不贅述),通過_score返回得分
後臺執行的操作
- 分配檔案到不同的容器 或 分片 中,檔案可以儲存在一個或多個節點中
- 按叢集節點來均衡分配這些分片,從而對索引和搜尋過程進行負載均衡
- 複製每個分片以支援資料冗餘,從而防止硬體故障導致的資料丟失
- 將叢集中任一節點的請求路由到存有相關資料的節點
- 叢集擴容時無縫整合新節點,重新分配分片以便從離群節點恢復
深入搜尋(實踐)
ES,you know, for search, 搜尋才是重點!!!
資料新增
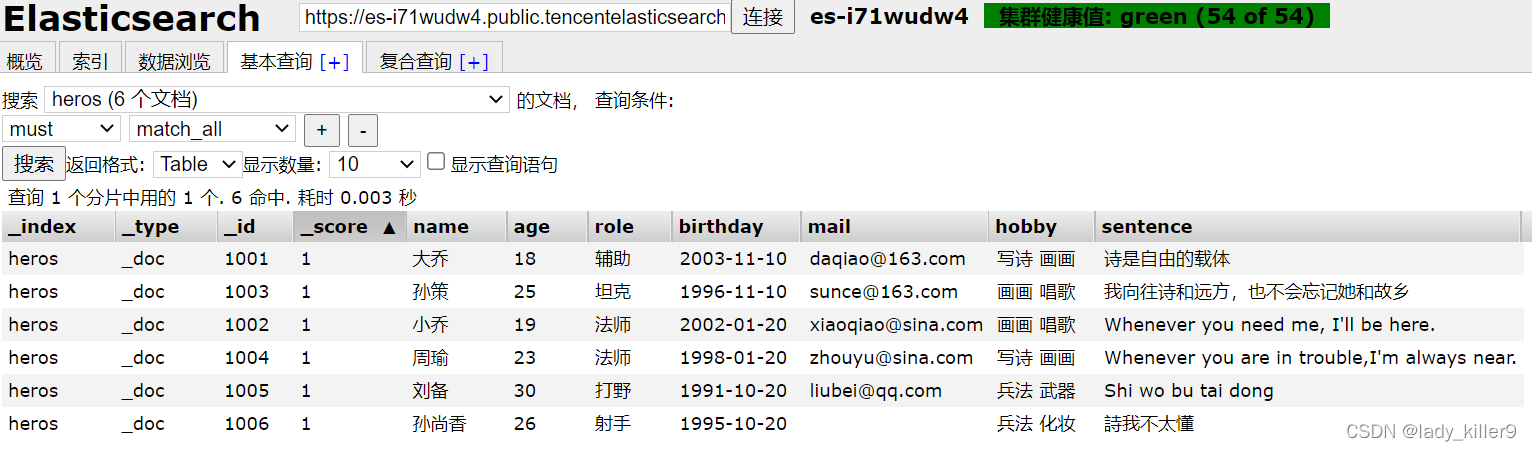
索引heros,欄位及型別如下:
- name:keyword
- age:byte
- role:keyword
- birthday:date
- mail:text
- hobby:text
- sentence:text
資料如下:
| name | age | role | birthday | hobby | sentence | |
|---|---|---|---|---|---|---|
| 大喬 | 18 | 輔助 | 2003-11-10 | daqiao@163.com | 寫詩 畫畫 | 詩是自由的載體 |
| 小喬 | 19 | 法師 | 2002-01-20 | xiaoqiao@sina.com | 畫畫 唱歌 | Whenever you need me, I’ll be here. |
| 孫策 | 25 | 坦克 | 1996-11-10 | sunce@163.com | 畫畫 唱歌 | 我向往詩和遠方,也不會忘記她和故鄉 |
| 周瑜 | 23 | 法師 | 1998-01-20 | zhouyu@sina.com | 寫詩 畫畫 | Whenever you are in trouble,I’m always near. |
| 劉備 | 30 | 打野 | 1991-10-20 | liubei@qq.com | 兵法 武器 | Shi wo bu tai dong |
| 孫尚香 | 26 | 射手 | 1995-10-20 | 兵法 化妝 | 詩我不太懂 |
建立索引及檔案
PUT /heros
這裡使用的Kibana的DevTools,如果你看了ES系列第一篇文章,有白嫖騰訊雲的ES叢集,可以點選視覺化設定,給Kibana設定公網白名單即可,由於我前面的文章還沒有介紹Kibana的使用,你可以繼續使用Postman、curl或elasticsearch-head外掛來發起請求。
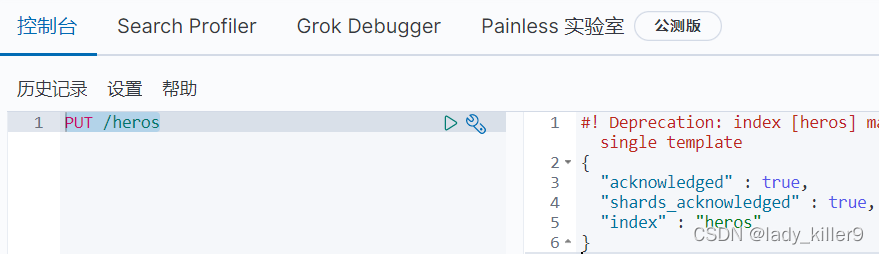
檢視setting和mapping情況
GET /heros?pretty
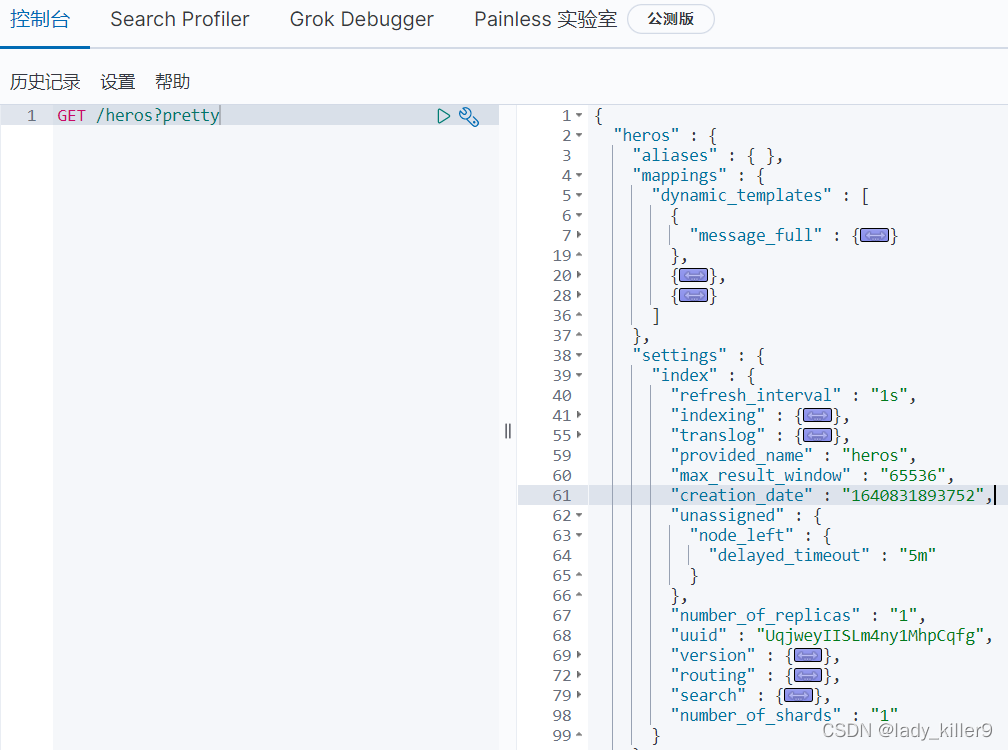
新增一個檔案
POST /heros/_doc/1001
{
"name":"大喬",
"age":18,
"role":"輔助",
"birthday":"2003-11-10",
"mail":"daqiao@163.com",
"hobby":"寫詩 畫畫",
"sentence":"詩是自由的載體"
}
結果如下
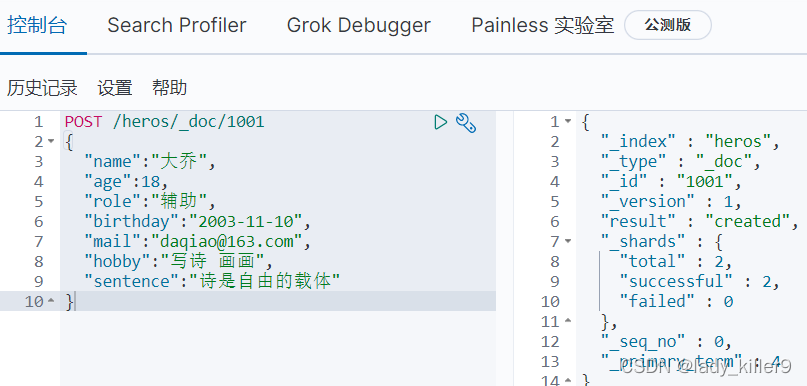
再次查詢mapping
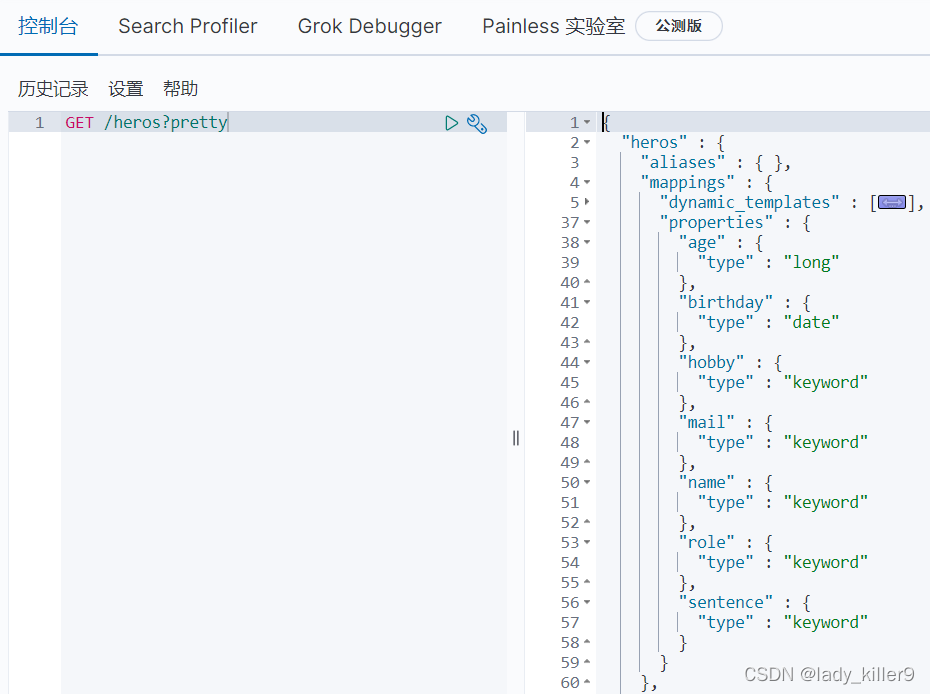
可以看到ES自動新增了型別,但是與我們要求的不符合。有些不會自動分詞,無法進行後序的搜尋。
刪除索引,再次新增
PUT /heros
{
"settings": {
"number_of_shards": 1,
"number_of_replicas": 1
},
"mappings": {
"properties": {
"name":{
"type": "keyword"
},
"age":{
"type": "byte"
},
"role":{
"type": "keyword"
},
"mail":{
"type":"text"
},
"birthday":{
"type":"date"
},
"hobby":{
"type": "text"
},
"sentence":{
"type":"text"
}
}
}
}
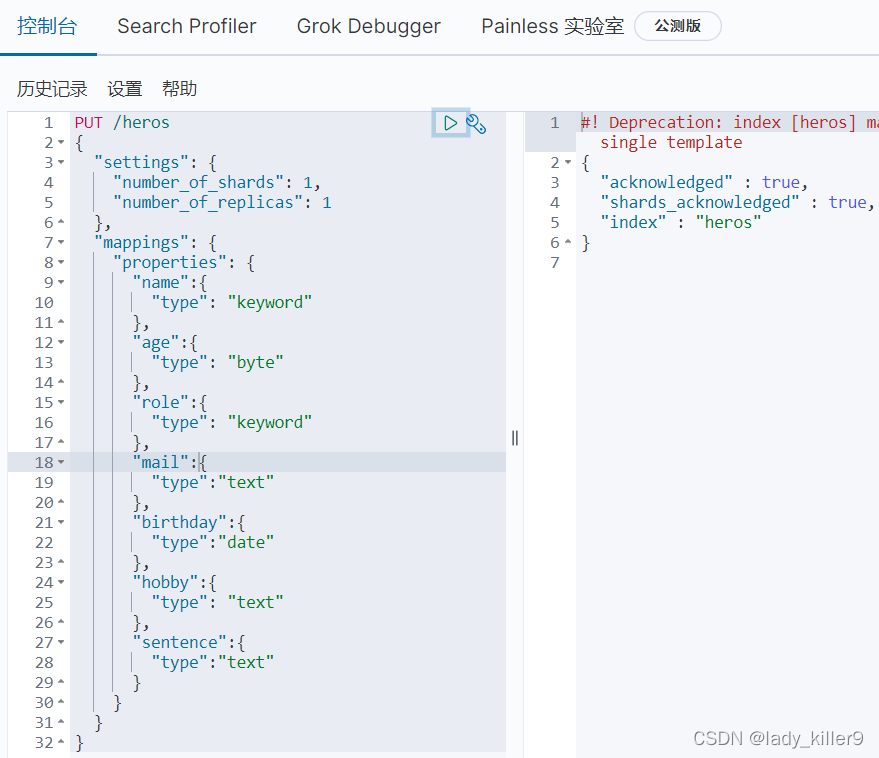
之後新增檔案,其他英雄的放在附錄了,最終的索引應該如下圖所示:
結構化搜尋
結構化搜尋(Structured search) 是指有關探詢那些具有內在結構資料的過程。比如日期、時間和數位都是結構化的:它們有精確的格式,我們可以對這些格式進行邏輯操作。
在結構化查詢中,要麼存於集合之中,要麼存在集合之外。結構化查詢不關心檔案的相關度或評分;它簡單的對檔案包括或排除處理。
單一過濾器(term)
我們首先來看最為常用的 term 查詢, 可以用它處理數位(numbers)、布林值(Booleans)、日期(date)等。
注意:ES5.0後,已經沒有string型別了
警告:儘量不要用於text型別欄位
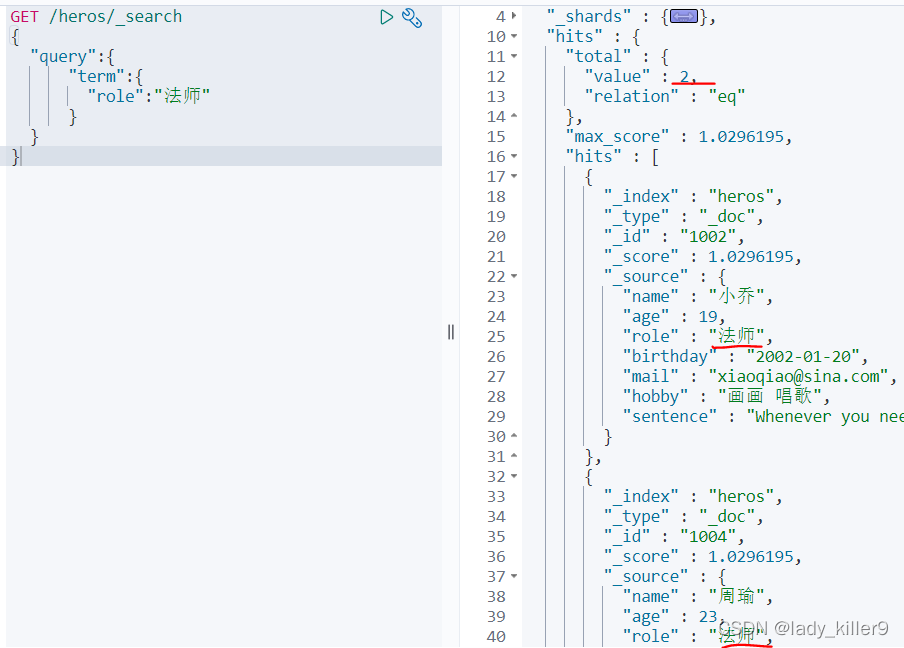
查詢角色是「法師」的英雄
GET /heros/_search
{
"query":{
"term":{
"role":"法師"
}
}
}
結果如下圖所示
多個精確值terms
查詢角色是「法師」或「射手」的英雄
GET /heros/_search
{
"query":{
"terms":{
"role":["法師","射手"]
}
}
}
結果如圖所示
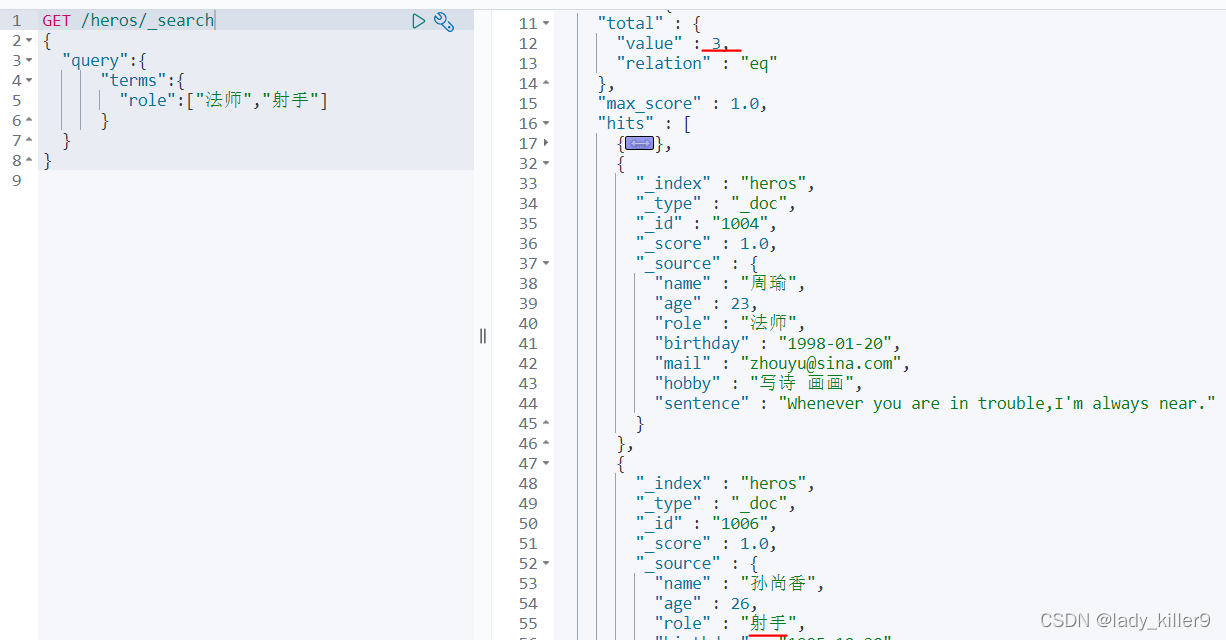
可以看到,多了射手角色的英雄。
範圍過濾器(range)
{
"range":{
"field_name":{
},
}
}
對欄位進行範圍過濾,常用的如下
- gt: > 大於(greater than)
- lt: < 小於(less than)
- gte: >= 大於或等於(greater than or equal to)
- lte: <= 小於或等於(less than or equal to)
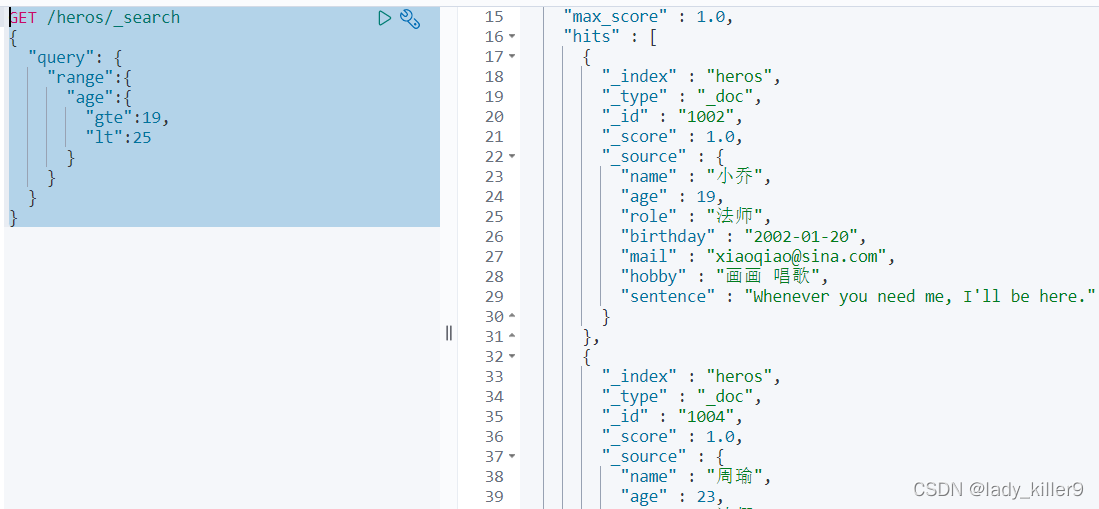
查詢19<=age<25的英雄
GET /heros/_search
{
"query": {
"range":{
"age":{
"gte":19,
"lt":25
}
}
}
}
結果如下圖所示
組合過濾器(bool過濾器)
將多個過濾器進行組組合
{
"bool" : {
"must" : [],
"must_not" : [],
"should" : [],
"filter":[],
}
}
- must:所有語句必須匹配,相當於and
- must_not:所有語句不能匹配,相當於not
- should:至少有一個語句匹配,相當於or
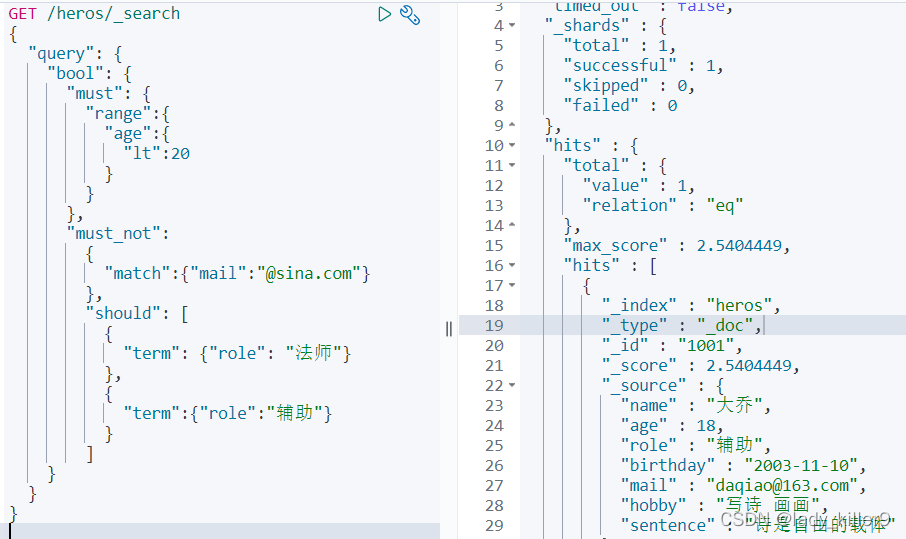
查詢角色是法師或輔助,年齡必須小於20,郵箱不能是新浪郵箱的英雄
GET /heros/_search
{
"query": {
"bool": {
"must": {
"range":{
"age":{
"lt":20
}
}
},
"must_not":
{
"match":{"mail":"@sina.com"}
},
"should": [
{
"term": {"role": "法師"}
},
{
"term":{"role":"輔助"}
}
]
}
}
}
看前面的資料可以發現,就剩大喬了,結果如下圖所示
NULL值處理(exists)
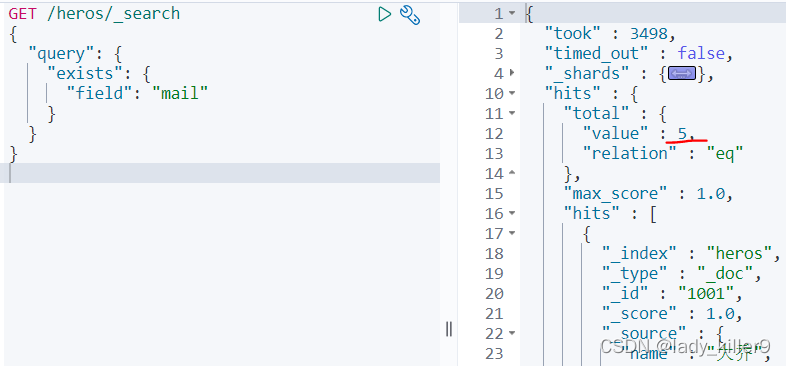
查詢有郵箱的英雄
GET /heros/_search
{
"query": {
"exists": {
"field": "mail"
}
}
}
結果如下圖所示
那麼,如何查詢不存在郵箱的英雄呢?之前有missing,現在不支援了,可以使用must_not進行巢狀
GET /heros/_search
{
"query": {
"bool": {
"must_not": {
"exists":{
"field": "mail"
}
}
}
}
}
結果如下圖所示
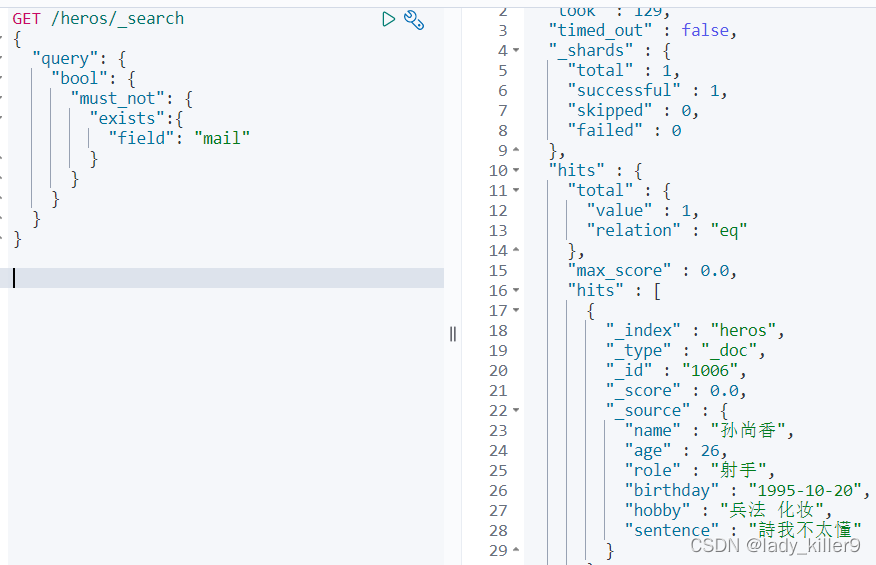
全文搜尋
基於詞項與基於全文
如 term 或 fuzzy 這樣的底層查詢不需要分析階段,它們對單個詞項進行操作。
像 match 或 query_string 這樣的查詢是高層查詢,它們瞭解欄位對映的資訊
匹配搜尋(match)與操作符(operator)
查詢sentence中含詩的英雄
GET /heros/_search
{
"query": {
"match": {
"sentence": "詩"
}
}
}
結果如下圖所示
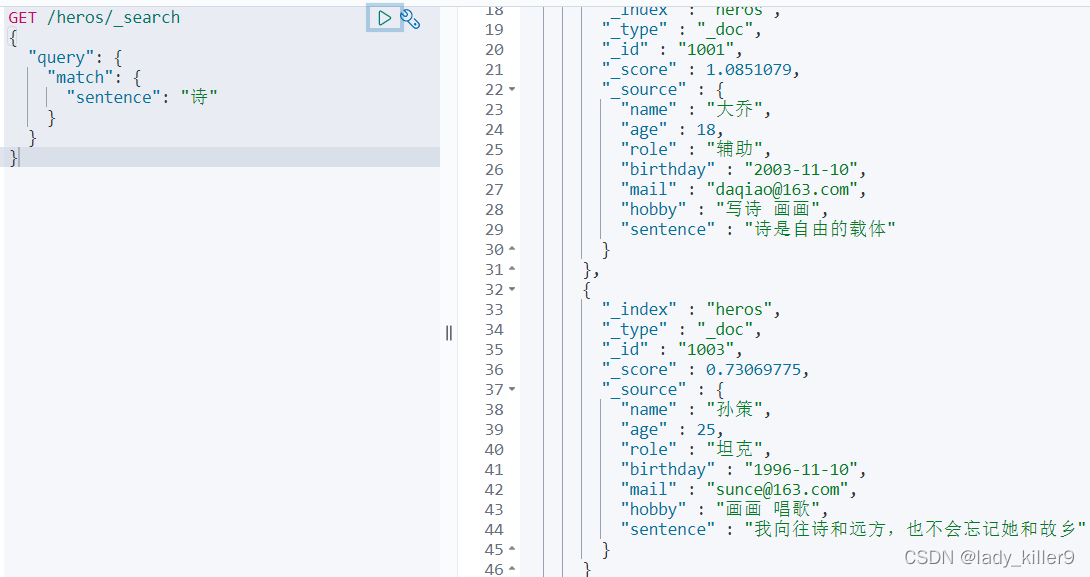
可以看到,評分語句更短的評分更高
多詞搜尋情況下
查詢sentence中含「我 詩」的英雄
GET /heros/_search
{
"query": {
"match": {
"sentence": "我 詩"
}
}
}
結果如下圖所示
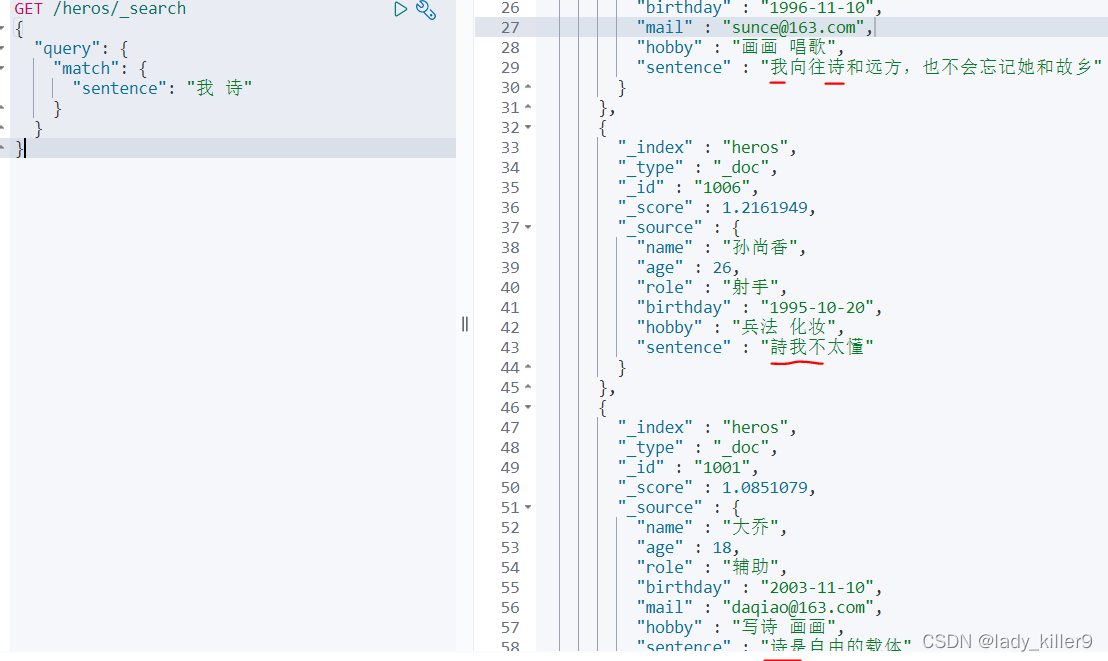
可以看到有些只包含我或詩的內容也出來了,雖然排名落後,如何做到且呢,前面使用了must,這裡使用operator實現
GET /heros/_search
{
"query": {
"match": {
"sentence": {
"query": "我 詩",
"operator": "and"
}
}
}
}
結果如下圖所示
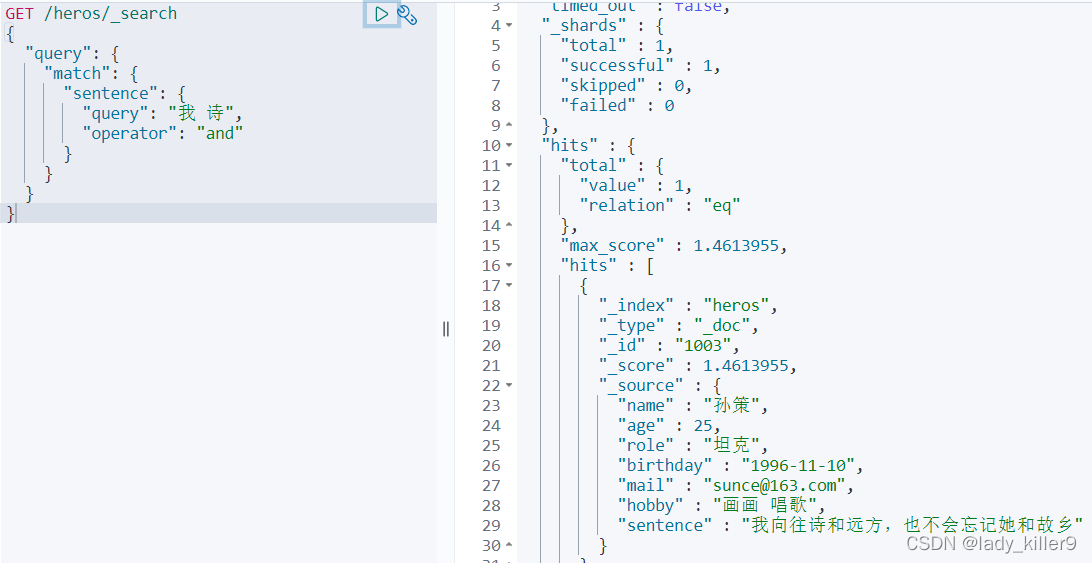
權重提升(boost)
查詢sentence中必須包含"Whenever",有"in"或者"be"的英雄
GET /heros/_search
{
"query": {
"bool": {
"must": [
{"match": {
"sentence": "Whenever"
}}
],
"should": [
{ "match": { "sentence": "in" }
},
{ "match": { "sentence": "be" }}
]
}
}
}
結果如下圖所示
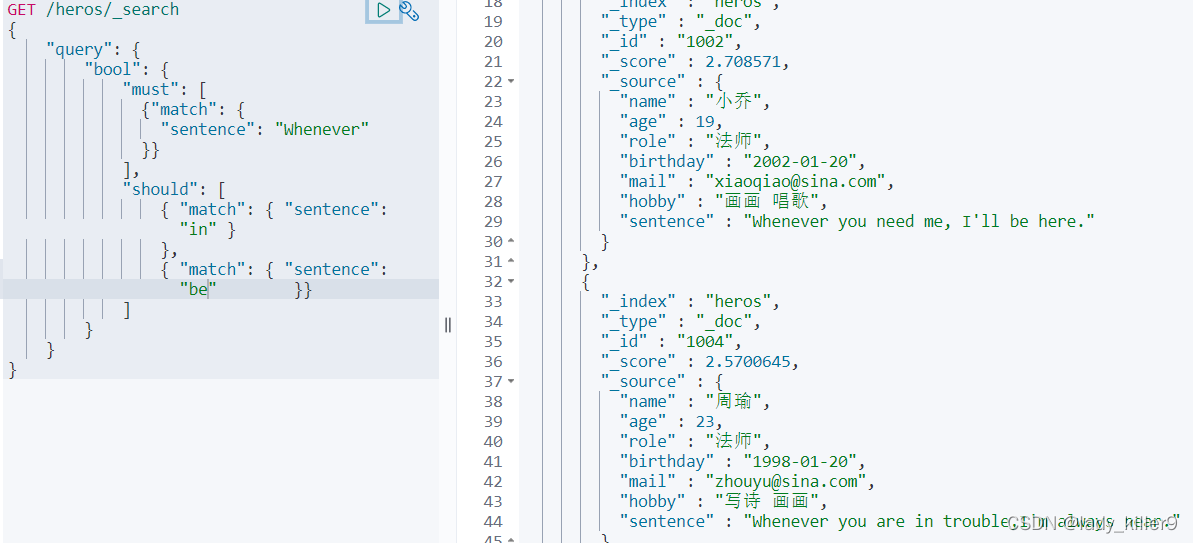
現要求含in的權重更高,也就是提高_score來提高搜尋排名
boost預設為1,通過增加in的boost來提高in的排名
GET /heros/_search
{
"query": {
"bool": {
"must": [
{"match": {
"sentence": "Whenever"
}}
],
"should": [
{ "match": {
"sentence": {
"query": "in",
"boost": 2
}
}
},
{ "match": { "sentence": "be" }}
]
}
}
}
結果如下圖所示
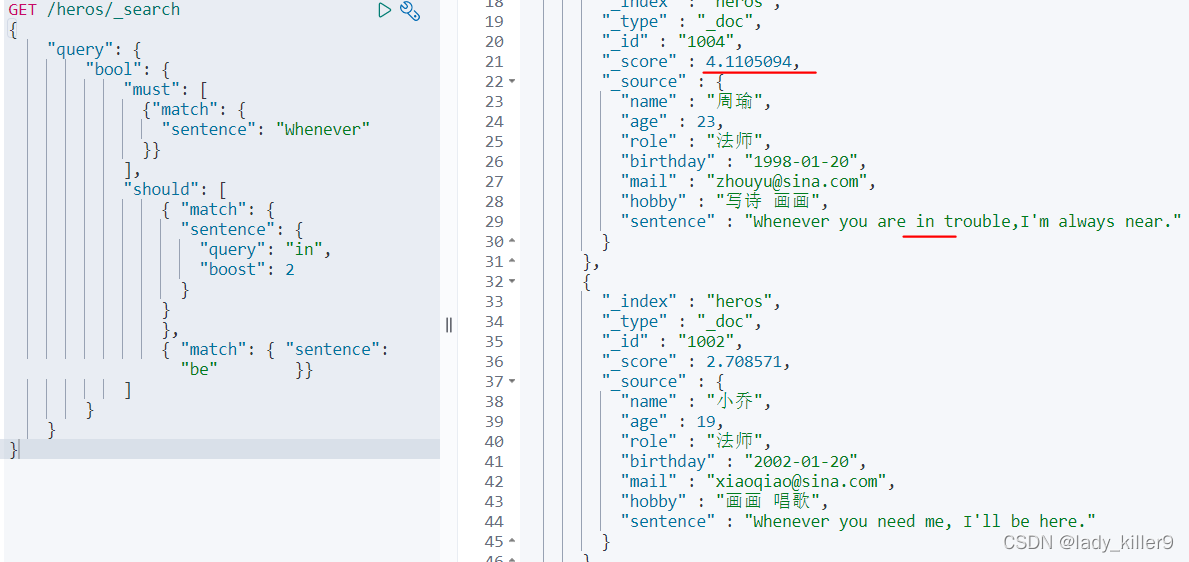
多欄位搜尋
前面已經進行了簡單的多字串搜尋,不過,還有一些多欄位時複雜的搜尋情況。
最佳欄位查詢(dis_max與tie_breaker)
查詢愛好有詩,sentence(隨便起的名字,可以理解為個性簽名或一句話介紹)中有詩或她的英雄
GET /heros/_search
{
"query": {
"bool": {
"should": [
{ "match": { "hobby": "詩" }},
{ "match": { "sentence": "詩 她" }}
]
}
}
}
結果如下圖所示
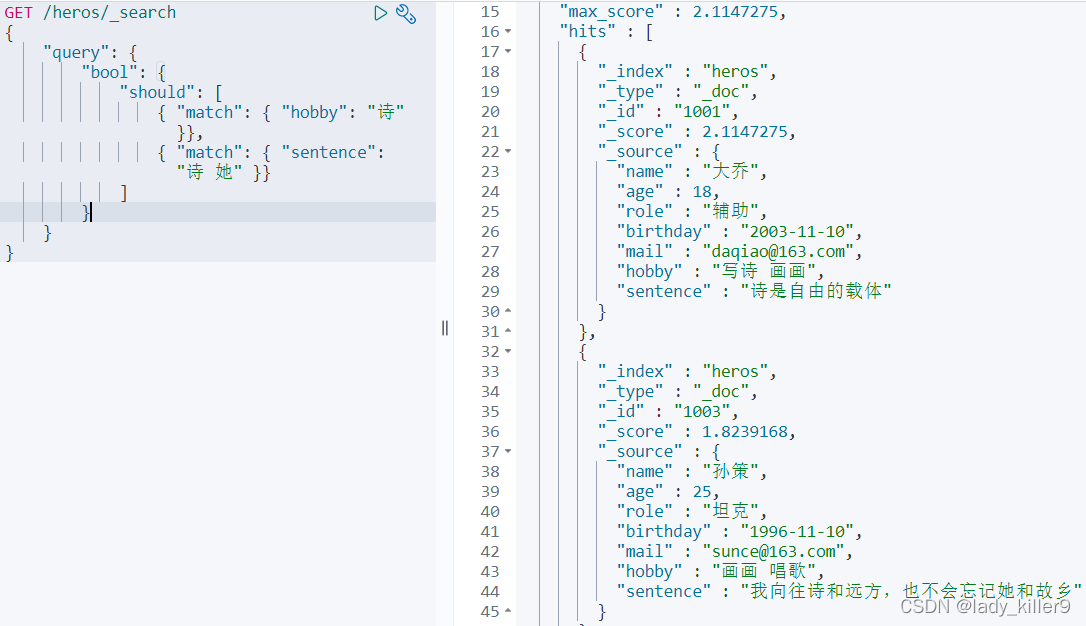
可以看到,第二個結果是我們更想得到的。bool會打兩次分,再除以語句總數2,第一個結果hobby和sentence都有詩,導致第一個結果就靠前了,由於hobby和sentence的競爭關係,所以需要找到最佳匹配欄位。
使用dis_max來得到想要的結果
GET /heros/_search
{
"query": {
"dis_max": {
"queries": [
{ "match": { "hobby": "詩" }},
{ "match": { "sentence": "詩 她" }}
]
}
}
}
結果如下圖所示
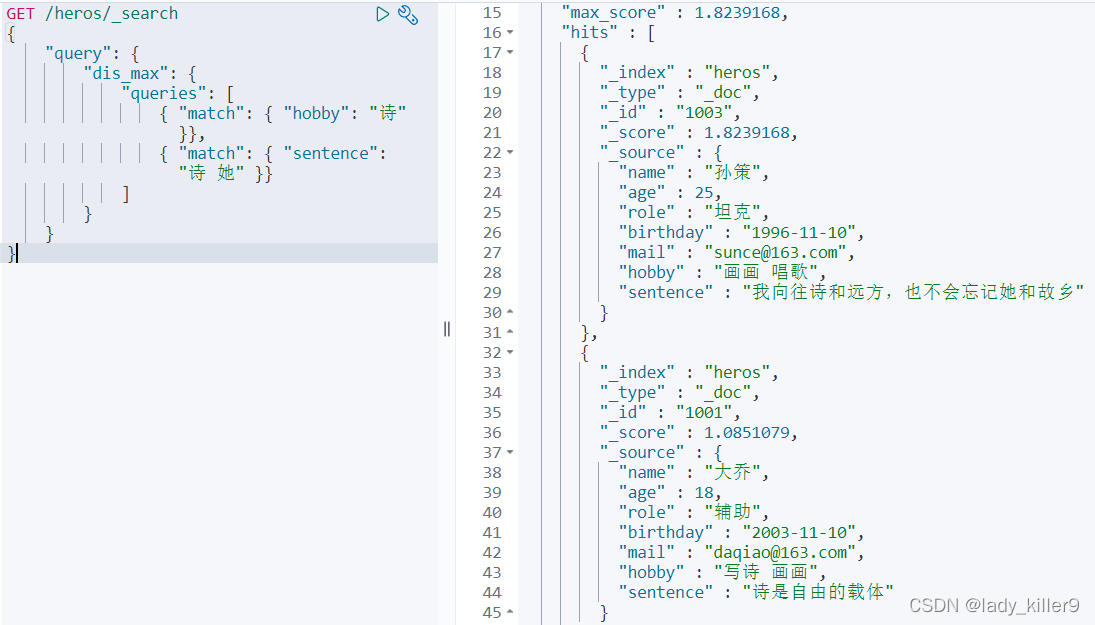
tips:想要在bool和dis_max之間,可以使用tie_breaker引數,請讀者自行深入瞭解。
多欄位進行相同搜尋(multi_match)
查詢hobby或sentence中含詩的英雄,也就是對hobby sentence做同一搜尋,如果寫多個match會比較繁瑣,可以採用multi_match,欄位使用列表的方式填寫多個即可。
GET /heros/_search
{
"query": {
"multi_match": {
"query": "詩",
"fields": ["hobby","sentence"]
}
}
}
結果如下圖所示
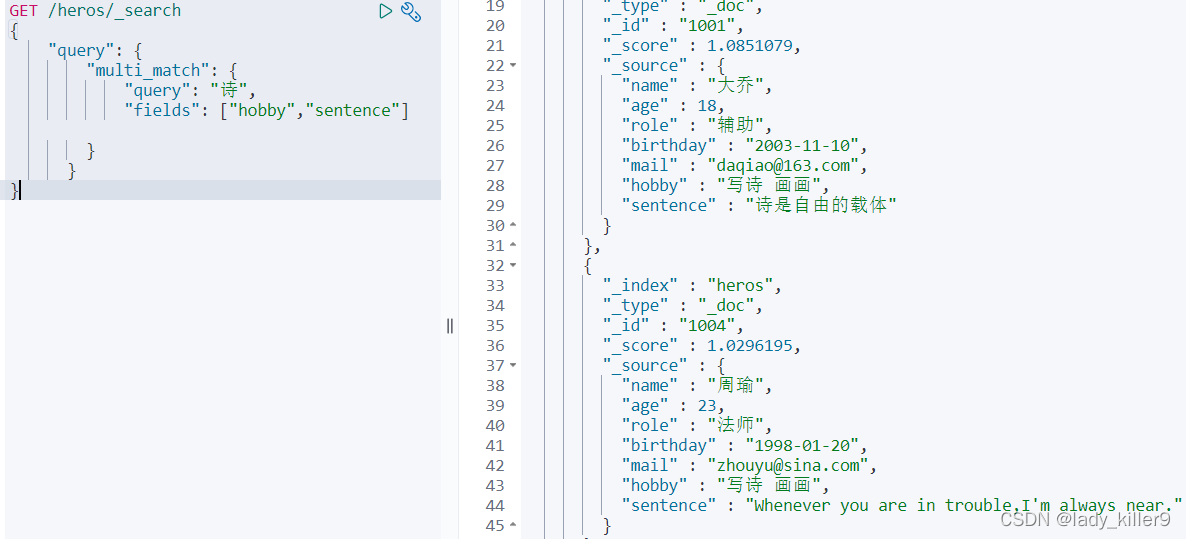
hobby和sentence都含詩的會排名靠前
部分匹配
即只輸入一部分,也能匹配到,最經典的就是邊輸入邊搜尋,也。
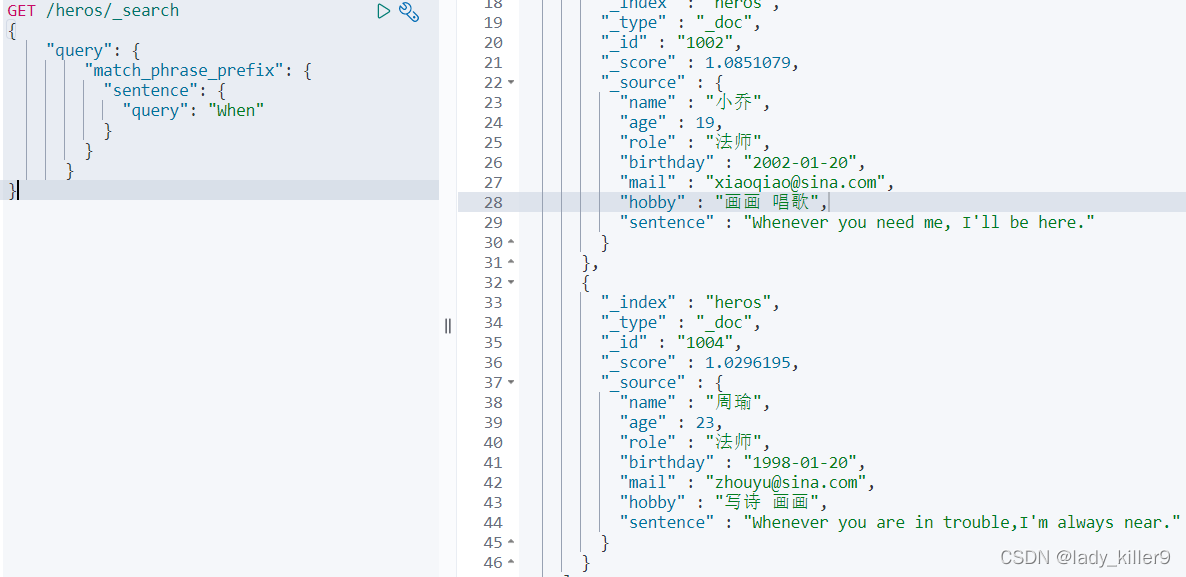
輸入即搜尋(match_phrase_prefix)
現在很多搜尋引擎都有使用者邊輸入邊提示的功能,不必等使用者Enter,提高了使用者體驗
使用者查詢sentence,輸入了when,查詢此時的下拉框的結果
GET /heros/_search
{
"query": {
"match_phrase_prefix": {
"sentence": {
"query": "When"
}
}
}
}
結果如下圖所示
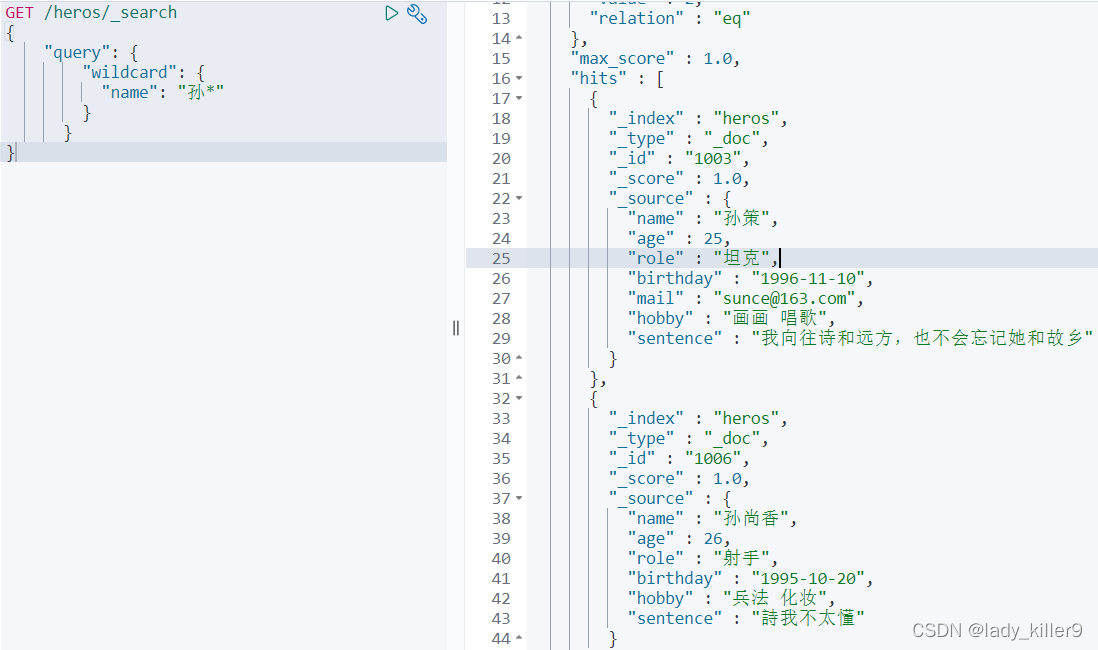
萬用字元搜尋(wildcard)
包含兩個萬用字元"?「和」*",? 匹配任意字元, * 匹配 0 或多個字元
搜尋姓孫的英雄
GET /heros/_search
{
"query": {
"wildcard": {
"name": "孫*"
}
}
}
結果如下圖所示
正規表示式搜尋(regexp)
正規表示式更加的豐富,包含數位、特殊字元等
搜尋郵箱含s、n,s在n前面的英雄
GET /heros/_search
{
"query": {
"regexp": {
"mail": "s.*n.*"
}
}
}
結果如下圖所示
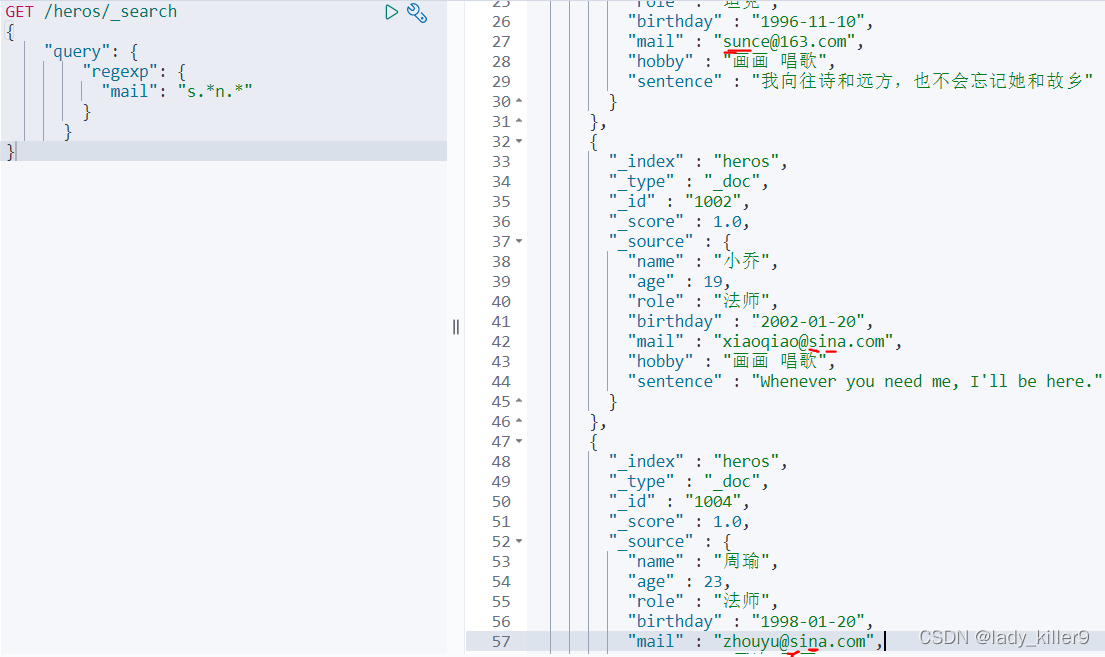
sunce符合,新浪郵箱也符合。
總結
本文講了一些基礎概念,深入研究了一些搜尋(拋轉引玉,官網還有很多搜尋方式),本來想寫叢集的,白嫖騰訊雲的只能固定三個節點,沒法演示擴容之類的,下篇文章再說一下叢集。
練習
查詢角色是「坦克」的英雄?
查詢年齡>18的「法師」英雄?
查詢姓"孫"的且名字是兩個字的英雄?
附錄
POST /heros/_doc/1002
{
"name":"小喬",
"age":19,
"role":"法師",
"birthday":"2002-01-20",
"mail":"xiaoqiao@sina.com",
"hobby":"畫畫 唱歌",
"sentence":"Whenever you need me, I'll be here."
}
POST /heros/_doc/1003
{
"name":"孫策",
"age":25,
"role":"坦克",
"birthday":"1996-11-10",
"mail":"sunce@163.com",
"hobby":"畫畫 唱歌",
"sentence":"我向往詩和遠方,也不會忘記她和故鄉"
}
POST /heros/_doc/1004
{
"name":"周瑜",
"age":23,
"role":"法師",
"birthday":"1998-01-20",
"mail":"zhouyu@sina.com",
"hobby":"寫詩 畫畫",
"sentence":"Whenever you are in trouble,I'm always near."
}
POST /heros/_doc/1005
{
"name":"劉備",
"age":30,
"role":"打野",
"birthday":"1991-10-20",
"mail":"liubei@qq.com",
"hobby":"兵法 武器",
"sentence":"Shi wo bu tai dong"
}
POST /heros/_doc/1006
{
"name":"孫尚香",
"age":26,
"role":"射手",
"birthday":"1995-10-20",
"hobby":"兵法 化妝",
"sentence":"詩我不太懂"
}
參考
ES權威指南
ES Guide
ES中文社群
騰訊-ES服務產品檔案
IK分詞器
ICU分詞器
smartcn分詞器
TF-IDF與餘弦相似性的應用(一):自動提取關鍵詞
更多ELK相關內容:資料庫-ElasticSearch學習筆記_lady_killer9的部落格-CSDN部落格
喜歡本文的請動動小手點個贊,收藏一下,有問題請下方評論,轉載請註明出處,並附有原文連結,謝謝!
如有侵權,請及時聯絡。如果您感覺有所收穫,自願打賞,可選擇支付寶18833895206(小於),您的支援是我不斷更新的動力。