巨量資料高階開發工程師——巨量資料相關工具之一 Sqoop
2022-01-03 13:00:41
文章目錄
巨量資料相關工具
Sqoop ETL工具
Sqoop簡介
- Sqoop是apache旗下的一款 」Hadoop和關聯式資料庫之間傳輸資料」的工具
- 匯入資料:將 MySQL、Oracle 匯入資料到 Hadoop 的 HDFS、HIVE、HBASE 等資料儲存系統
- 匯出資料:從 Hadoop 的檔案系統中匯出資料到關聯式資料庫
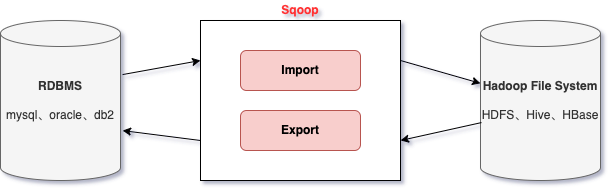
- 工作機制:
- 將匯入和匯出的命令翻譯成mapreduce程式實現
- 在翻譯出的mapreduce中主要是對inputformat和outputformat進行客製化
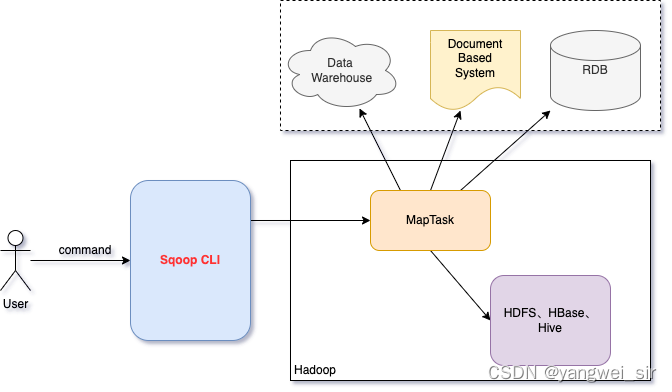
Sqoop1與Sqoop2架構對比
sqoop在發展中的過程中演進出來了兩種不同的架構——架構演變史
- Sqoop1 架構:
- 版本號:1.4.x
- 使用 sqoop 使用者端直接提交方式,CLI 控制檯進行存取
- 安全性:命令或指令碼中指定使用者資料庫名及密碼
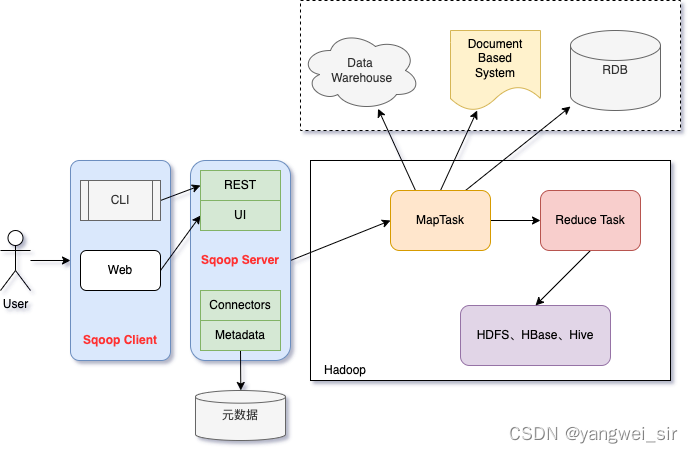
- Sqoop2 架構:
- 版本號:1.99.x
- 引入了sqoop server,對connector實現了集中的管理,可以通過 REST API、 JAVA API、 WEB UI 以及CLI 控制檯方式進行存取
| 比較 | Sqoop1 | Sqoop2 |
|---|---|---|
| 架構 | 僅僅使用一個 Sqoop 使用者端 | 引入了 Sqoop Server 集中化管理連線,以及 rest api、web ui,引入安全機制 |
| 部署 | 簡單,使用 root 許可權安裝,聯結器必須符合 JDBC | 架構稍複雜,設定部署更加繁瑣 |
| 使用 | 命令方式容易出錯,格式緊耦合,無法支援所有資料型別,安全機制不夠完善,容易暴露密碼 | 多種互動方式:命令列、WebUI、REST API,連線集中管理,完善的許可權管理機制,connector僅僅負責資料的讀寫。 |
Sqoop安裝部署
- Sqoop安裝很簡單,解壓好進行簡單的修改就可以使用
- 安裝包下載&解壓
wget http://archive.apache.org/dist/sqoop/1.4.7/sqoop-1.4.7.bin__hadoop-2.6.0.tar.gz
# 解壓
tar -zxvf sqoop-1.4.7.bin__hadoop-2.6.0.tar.gz -C /bigdata/install/
- 修改組態檔:
cd /bigdata/install/sqoop-1.4.7.bin__hadoop-2.6.0/conf
mv sqoop-env-template.sh sqoop-env.sh
vim sqoop-env.sh
# 根據自己實際的安裝目錄填寫
#Set path to where bin/hadoop is available
export HADOOP_COMMON_HOME=/bigdata/install/hadoop-3.1.4
#Set path to where hadoop-*-core.jar is available
export HADOOP_MAPRED_HOME=/bigdata/install/hadoop-3.1.4
#set the path to where bin/hbase is available
export HBASE_HOME=/bigdata/install/hbase-2.2.6
#Set the path to where bin/hive is available
export HIVE_HOME=/bigdata/install/hive-3.1.2
#Set the path for where zookeper config dir is
export ZOOCFGDIR=/usr/apps/zookeeper-3.4.14/conf
- 新增兩個必要的jar包:將
java-json.jar,mysql-connector-java-5.1.38.jar拷貝到sqoop的lib目錄下
scp java-json.jar mysql-connector-java-5.1.38.jar hadoop@node03:/bigdata/install/sqoop-1.4.7.bin__hadoop-2.6.0/lib
- 設定 sqoop 的環境變數
sudo vim /etc/profile
export SQOOP_HOME=/bigdata/install/sqoop-1.4.7.bin__hadoop-2.6.0
export PATH=$PATH:$SQOOP_HOME/bin
source /etc/profile
- 執行命令
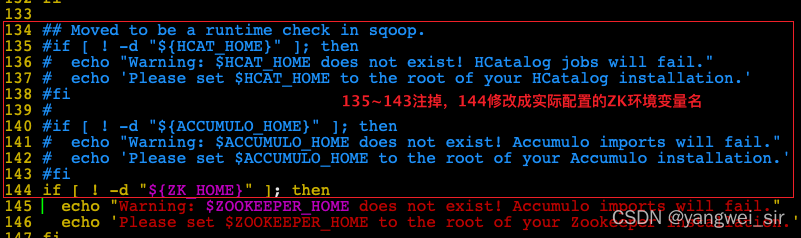
sqoop help命令,有warning紀錄檔
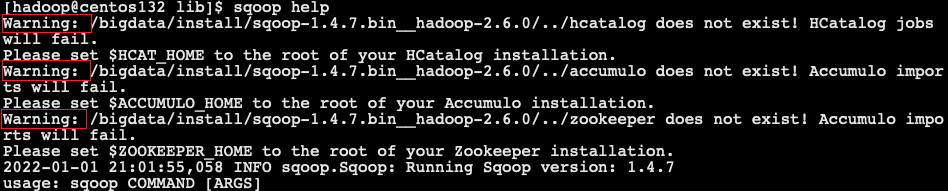
- 解決方案:
# pwd = /bigdata/install/sqoop-1.4.7.bin__hadoop-2.6.0
vim bin/configure-sqoop
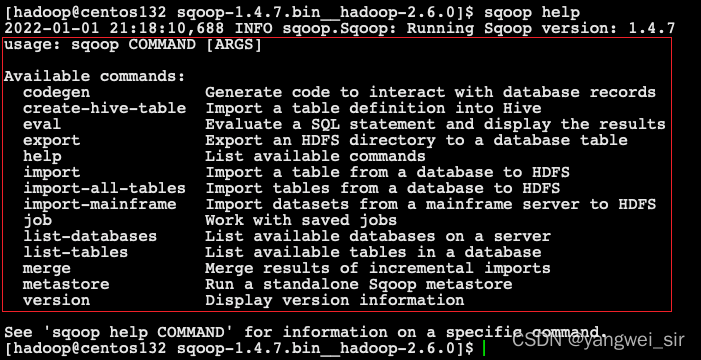
- 再次執行命令
sqoop help命令,一切正常啦!
Sqoop的資料匯入
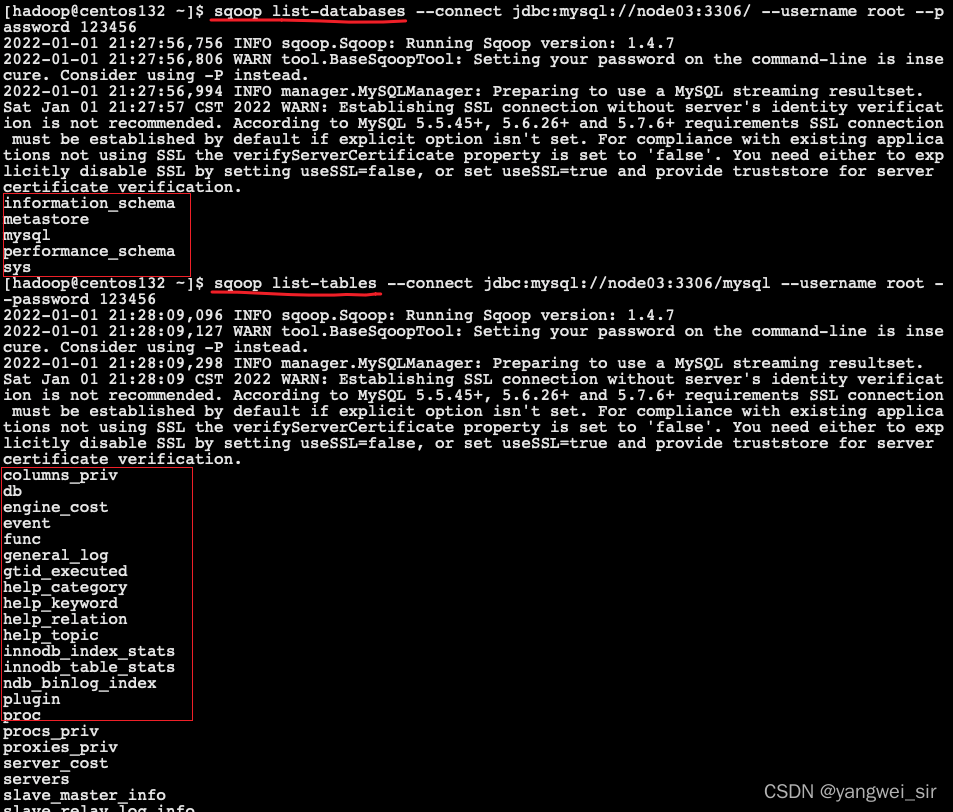
1. 列出所有資料庫
# 列出node03主機所有的資料庫
sqoop list-databases --connect jdbc:mysql://node03:3306/ --username root --password 123456
# 檢視某一個資料庫下面的所有資料表
sqoop list-tables --connect jdbc:mysql://node03:3306/mysql --username root --password 123456
2. 準備表資料
- 初始化資料:
CREATE DATABASE /*!32312 IF NOT EXISTS*/`userdb` /*!40100 DEFAULT CHARACTER SET utf8 */;
USE `userdb`;
DROP TABLE IF EXISTS `emp`;
CREATE TABLE `emp` (
`id` INT(11) DEFAULT NULL,
`name` VARCHAR(100) DEFAULT NULL,
`deg` VARCHAR(100) DEFAULT NULL,
`salary` INT(11) DEFAULT NULL,
`dept` VARCHAR(10) DEFAULT NULL,
`create_time` TIMESTAMP NOT NULL DEFAULT CURRENT_TIMESTAMP,
`update_time` TIMESTAMP NOT NULL DEFAULT CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP,
`is_delete` BIGINT(20) DEFAULT '1'
) ENGINE=INNODB DEFAULT CHARSET=latin1;
INSERT INTO `emp`(`id`,`name`,`deg`,`salary`,`dept`) VALUES (1201,'gopal','manager',50000,'TP'),(1202,'manisha','Proof reader',50000,'TP'),(1203,'khalil','php dev',30000,'AC'),(1204,'prasanth','php dev',30000,'AC'),(1205,'kranthi','admin',20000,'TP');
DROP TABLE IF EXISTS `emp_add`;
CREATE TABLE `emp_add` (
`id` INT(11) DEFAULT NULL,
`hno` VARCHAR(100) DEFAULT NULL,
`street` VARCHAR(100) DEFAULT NULL,
`city` VARCHAR(100) DEFAULT NULL,
`create_time` TIMESTAMP NOT NULL DEFAULT CURRENT_TIMESTAMP,
`update_time` TIMESTAMP NOT NULL DEFAULT CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP,
`is_delete` BIGINT(20) DEFAULT '1'
) ENGINE=INNODB DEFAULT CHARSET=latin1;
INSERT INTO `emp_add`(`id`,`hno`,`street`,`city`) VALUES (1201,'288A','vgiri','jublee'),(1202,'108I','aoc','sec-bad'),(1203,'144Z','pgutta','hyd'),(1204,'78B','old city','sec-bad'),(1205,'720X','hitec','sec-bad');
DROP TABLE IF EXISTS `emp_conn`;
CREATE TABLE `emp_conn` (
`id` INT(100) DEFAULT NULL,
`phno` VARCHAR(100) DEFAULT NULL,
`email` VARCHAR(100) DEFAULT NULL,
`create_time` TIMESTAMP NOT NULL DEFAULT CURRENT_TIMESTAMP,
`update_time` TIMESTAMP NOT NULL DEFAULT CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP,
`is_delete` BIGINT(20) DEFAULT '1'
) ENGINE=INNODB DEFAULT CHARSET=latin1;
INSERT INTO `emp_conn`(`id`,`phno`,`email`) VALUES (1201,'2356742','gopal@tp.com'),(1202,'1661663','manisha@tp.com'),(1203,'8887776','khalil@ac.com'),(1204,'9988774','prasanth@ac.com'),(1205,'1231231','kranthi@tp.com');
- 檢視資料:
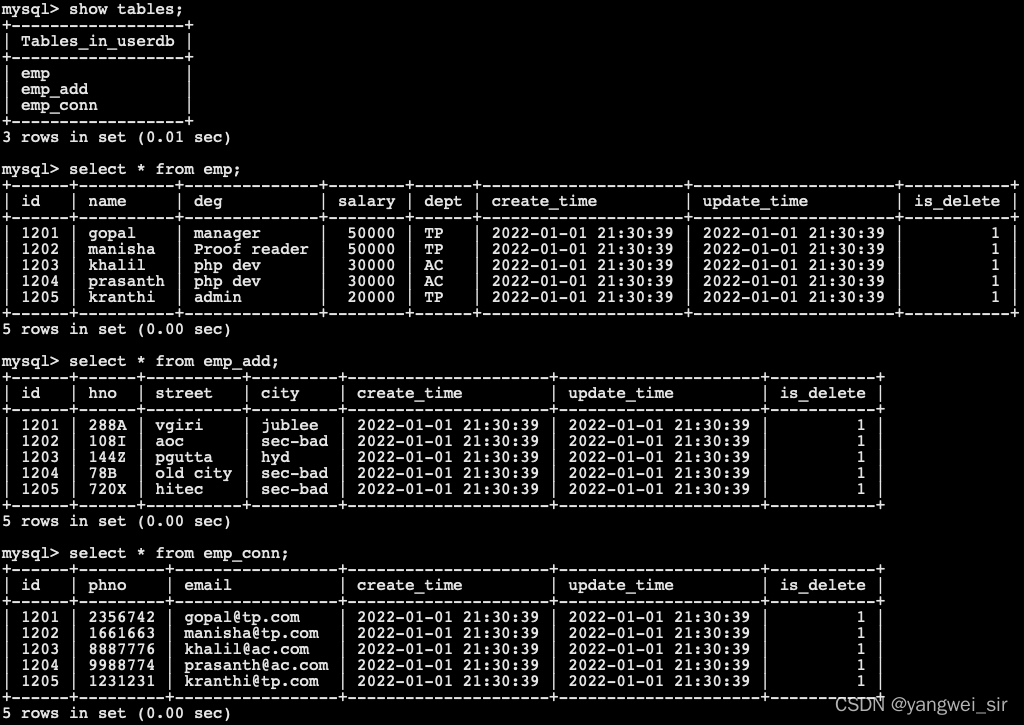
3. 匯入資料庫表資料到HDFS
- 使用sqoop命令匯入、匯出資料前,要先啟動hadoop叢集。下面的命令用於從MySQL資料庫伺服器中的emp表匯入HDFS:
sqoop import --connect jdbc:mysql://node03:3306/userdb --password 123456 --username root --table emp -m 1
# 引數`--m 1`,表示只啟動一個map task進行資料的匯入
- 為了驗證在HDFS匯入的資料,可以使用以下命令檢視匯入的資料
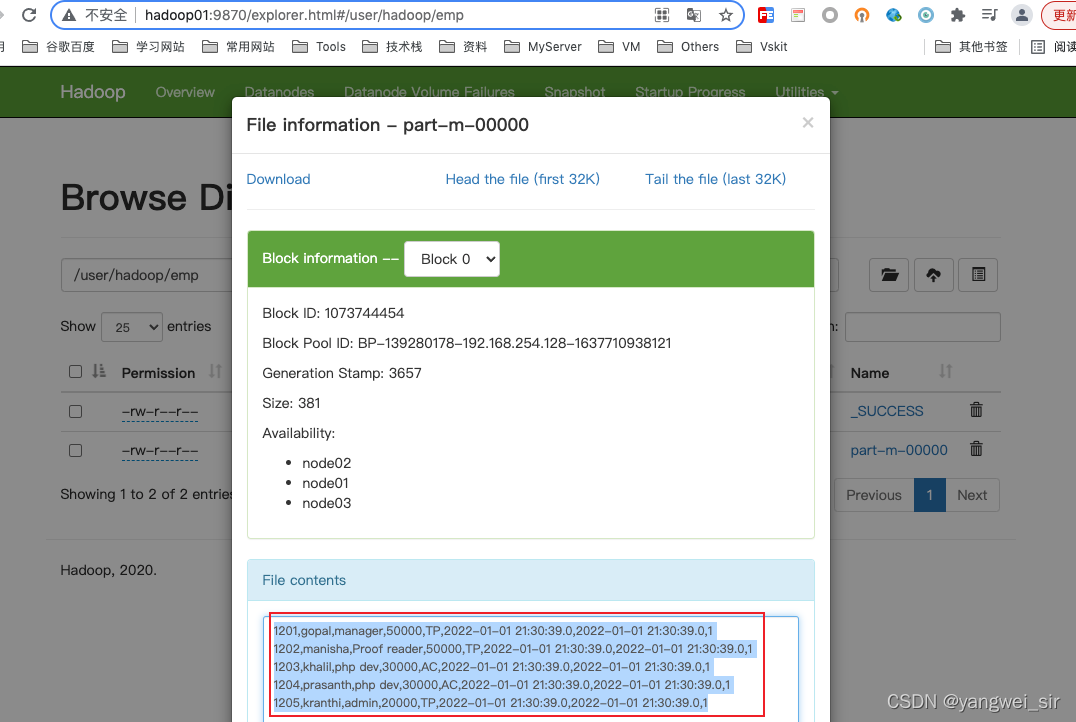
hdfs dfs -ls /user/hadoop/emp
Found 2 items
-rw-r--r-- 3 hadoop supergroup 0 2022-01-01 21:35 /user/hadoop/emp/_SUCCESS
-rw-r--r-- 3 hadoop supergroup 381 2022-01-01 21:35 /user/hadoop/emp/part-m-00000
- 也可以到 hadoop web 頁面檢視:
- 如果要開啟多個map task的話,需要在命令中新增
--split-by column-name,如下,其中map個數為4
sqoop import --connect jdbc:mysql://node03:3306/userdb --password 123456 --username root --table emp -m 4 --split-by id
4. 匯入到HDFS指定目錄
- 在匯入表資料到HDFS使用Sqoop匯入工具,我們可以指定目標目錄。
- 使用引數
--target-dir來指定匯出目的地,使用引數--delete-target-dir來判斷匯出目錄是否存在,如果存在就刪掉
sqoop import --connect jdbc:mysql://node03:3306/userdb --username root --password 123456 --delete-target-dir --table emp --target-dir /sqoop/emp -m 1
- 檢視匯出資料
hdfs dfs -text /sqoop/emp/part-m-00000
# 它會用逗號(,)分隔emp表的資料和欄位
1201,gopal,manager,50000,TP,2022-01-01 21:30:39.0,2022-01-01 21:30:39.0,1
1202,manisha,Proof reader,50000,TP,2022-01-01 21:30:39.0,2022-01-01 21:30:39.0,1
1203,khalil,php dev,30000,AC,2022-01-01 21:30:39.0,2022-01-01 21:30:39.0,1
1204,prasanth,php dev,30000,AC,2022-01-01 21:30:39.0,2022-01-01 21:30:39.0,1
1205,kranthi,admin,20000,TP,2022-01-01 21:30:39.0,2022-01-01 21:30:39.0,1
5. 匯入到hdfs指定目錄並指定欄位之間的分隔符
- 使用引數
--fields-terminated-by指定分隔符
sqoop import --connect jdbc:mysql://node03:3306/userdb --username root --password 123456 --delete-target-dir --table emp --target-dir /sqoop/emp2 -m 1 --fields-terminated-by '\t'
- 再檢視資料
hdfs dfs -text /sqoop/emp2/part-m-00000
# 它會用(\t)分隔emp表的資料和欄位
1201 gopal manager 50000 TP 2022-01-01 21:30:39.0 2022-01-01 21:30:39.0 1
1202 manisha Proof reader 50000 TP 2022-01-01 21:30:39.0 2022-01-01 21:30:39.0 1
1203 khalil php dev 30000 AC 2022-01-01 21:30:39.0 2022-01-01 21:30:39.0 1
1204 prasanth php dev 30000 AC 2022-01-01 21:30:39.0 2022-01-01 21:30:39.0 1
1205 kranthi admin 20000 TP 2022-01-01 21:30:39.0 2022-01-01 21:30:39.0 1
6. 匯入關係表到HIVE
- 將我們 mysql 表當中的資料直接匯入到 hive 表中的話,需要將 hive 的一個叫做 hive-exec-3.1.2.jar 的 jar 包拷貝到 sqoop 的 lib 目錄下
cp /bigdata/install/hive-3.1.2/lib/hive-exec-3.1.2.jar /bigdata/install/sqoop-1.4.7.bin__hadoop-2.6.0/lib/
- 準備 hive 表資料,進入 hive 使用者端執行以下命令初始化資料
hive (default)> create database sqooptohive;
hive (default)> use sqooptohive;
hive (sqooptohive)> create external table emp_hive(id int,name string,deg string,salary int ,dept string) row format delimited fields terminated by '\001';
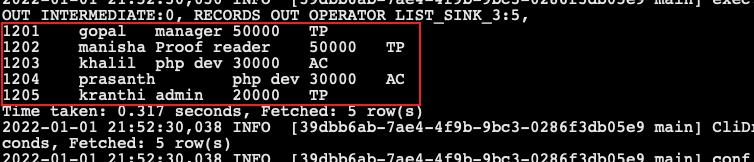
- 開始使用 sqoop 匯入:
sqoop import --connect jdbc:mysql://node03:3306/userdb --username root --password 123456 --table emp --fields-terminated-by '\001' --hive-import --hive-table sqooptohive.emp_hive --hive-overwrite --delete-target-dir --m 1
- 在 hive 中查詢資料:
select * from emp_hive;
7. 匯入關係表到hive並自動建立hive表
- 可以通過命令來將我們的 mysql 的表直接匯入到 hive 表當中去
# 通過這個命令,我們可以直接將我們mysql表當中的資料以及表結構一起倒入到hive當中去
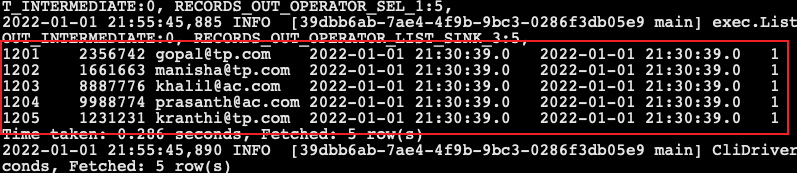
sqoop import --connect jdbc:mysql://node03:3306/userdb --username root --password 123456 --table emp_conn --hive-import -m 1 --hive-database sqooptohive
- 匯入完成後,到 hive 查詢資料:
select * from emp_conn;
8. 將mysql表資料匯入到hbase當中去
-
sqoop1的最新版本1.4.7只與hbase 1.x相相容,因此這裡修改 sqoop 的組態檔 sqoop-env.sh,指定 hbase-2.2.2 版本的 HBase
-
初始化 mysql 表資料
CREATE DATABASE IF NOT EXISTS library;
USE library;
CREATE TABLE book(
id INT(4) PRIMARY KEY NOT NULL AUTO_INCREMENT,
NAME VARCHAR(255) NOT NULL,
price VARCHAR(255) NOT NULL);
-- 插入資料
INSERT INTO book(NAME, price) VALUES('Lie Sporting', '30');
INSERT INTO book (NAME, price) VALUES('Pride & Prejudice', '70');
INSERT INTO book (NAME, price) VALUES('Fall of Giants', '50');
- 執行如下命令將 mysql 表當中的資料匯入到HBase當中去
sqoop import --connect jdbc:mysql://node03:3306/library --username root --password 123456 --table book --columns "id,name,price" --column-family "info" --hbase-create-table --hbase-row-key "id" --hbase-table "hbase_book" --num-mappers 1 --split-by id
- HBase當中檢視表資料
hbase(main):057:0> scan 'hbase_book'
ROW COLUMN+CELL
1 column=info:name, timestamp=1550634017823, value=Lie Sporting
1 column=info:price, timestamp=1550634017823, value=30
2 column=info:name, timestamp=1550634017823, value=Pride & Prejudice
2 column=info:price, timestamp=1550634017823, value=70
3 column=info:name, timestamp=1550634017823, value=Fall of Giants
3 column=info:price, timestamp=1550634017823, value=50
9. 匯入表資料子集
-
可以使用Sqoop工具匯入表的「where」子句的一個子集,它執行在各自的資料庫伺服器相應的SQL查詢,並將結果儲存在HDFS的目標目錄。
-
通過
--where引數來查詢表 emp_add 當中 city 欄位的值為 sec-bad 的所有資料匯入到 hdfs 上面去
sqoop import --connect jdbc:mysql://node03:3306/userdb --username root --password 123456 --table emp_add --target-dir /sqoop/emp_add -m 1 --delete-target-dir --where "city = 'sec-bad'"
- hdfs 檢視資料
hdfs dfs -text /sqoop/emp_add/part-*
1202,108I,aoc,sec-bad,2022-01-01 21:30:39.0,2022-01-01 21:30:39.0,1
1204,78B,old city,sec-bad,2022-01-01 21:30:39.0,2022-01-01 21:30:39.0,1
1205,720X,hitec,sec-bad,2022-01-01 21:30:39.0,2022-01-01 21:30:39.0,1
10. sql語句查詢匯入hdfs
- 還可以通過
--query引數來指定我們的 sql 語句,通過 sql 語句來過濾我們的資料進行匯入
import --connect jdbc:mysql://node03:3306/userdb --username root --password 123456 --delete-target-dir -m 1 --query 'select phno from emp_conn where 1=1 and $CONDITIONS' --target-dir /sqoop/emp_conn
- hdfs 檢視資料
hdfs dfs -text /sqoop/emp_conn/part-*
2356742
1661663
8887776
9988774
1231231
注意:使用sql語句來進行查詢是不能加引數–table,並且必須要新增where條件,並且where條件後面必須帶一個$CONDITIONS 這個字串,並且這個sql語句必須用單引號,不能用雙引號。
11. 增量匯入
- 在實際工作當中,資料的匯入,很多時候都是隻需要匯入增量資料即可,並不需要將表中的資料全部匯入到hive或者hdfs當中去。全部匯入會出現重複的資料的狀況,所以我們一般都是選用一些欄位進行增量的匯入,為了支援增量的匯入,sqoop也給我們考慮到了這種情況並且支援增量的匯入資料。
- 增量匯入是僅匯入新新增的表中的行的技術。
- 它需要新增
incremental,check-column和last-value選項來執行增量匯入。語法如下:
--incremental <Append> //基於遞增列的增量匯入
--check-column <column name> //遞增列
--last-value <last check column value> //閾值
- 方式一:使用上面的選項來實現
- 注意:增量匯入的時候,一定不能加引數
--delete-target-dir否則會報錯
- 注意:增量匯入的時候,一定不能加引數
sqoop import --connect jdbc:mysql://node03:3306/userdb --username root --password 123456 --table emp --incremental append --check-column id --last-value 1202 -m 1 --target-dir /sqoop/increment
# 檢視
hdfs dfs -text /sqoop/increment/part*
1203,khalil,php dev,30000,AC,2022-01-01 21:30:39.0,2022-01-01 21:30:39.0,1
1204,prasanth,php dev,30000,AC,2022-01-01 21:30:39.0,2022-01-01 21:30:39.0,1
1205,kranthi,admin,20000,TP,2022-01-01 21:30:39.0,2022-01-01 21:30:39.0,1
- 方式二:通過
--where條件來實現
sqoop import --connect jdbc:mysql://node03:3306/userdb --username root --password 123456 --table emp --incremental append --where "create_time > '2021-12-30 00:00:00' and is_delete='1' and create_time < '2022-01-02 23:59:59'" --target-dir /sqoop/increment2 --check-column id --m 1
# 檢視
hdfs dfs -text /sqoop/increment2/part*
1201,gopal,manager,50000,TP,2022-01-01 21:30:39.0,2022-01-01 21:30:39.0,1
1202,manisha,Proof reader,50000,TP,2022-01-01 21:30:39.0,2022-01-01 21:30:39.0,1
1203,khalil,php dev,30000,AC,2022-01-01 21:30:39.0,2022-01-01 21:30:39.0,1
1204,prasanth,php dev,30000,AC,2022-01-01 21:30:39.0,2022-01-01 21:30:39.0,1
1205,kranthi,admin,20000,TP,2022-01-01 21:30:39.0,2022-01-01 21:30:39.0,1
Sqoop的資料匯出
1. 將資料從HDFS把檔案匯出到RDBMS資料庫
- 匯出前,目標表必須存在於目標資料庫中。
- 預設操作是將檔案中的資料使用 INSERT 語句插入到表中,更新模式下,是生成 UPDATE 語句更新表資料。
- 資料是在HDFS當中的如下目錄/sqoop/emp,資料內容如下:
1201,gopal,manager,50000,TP,2022-01-01 21:30:39.0,2022-01-01 21:30:39.0,1
1202,manisha,Proof reader,50000,TP,2022-01-01 21:30:39.0,2022-01-01 21:30:39.0,1
1203,khalil,php dev,30000,AC,2022-01-01 21:30:39.0,2022-01-01 21:30:39.0,1
1204,prasanth,php dev,30000,AC,2022-01-01 21:30:39.0,2022-01-01 21:30:39.0,1
1205,kranthi,admin,20000,TP,2022-01-01 21:30:39.0,2022-01-01 21:30:39.0,1
- 建立 mysql 表
use userdb;
CREATE TABLE `emp_out` (
`id` INT(11) DEFAULT NULL,
`name` VARCHAR(100) DEFAULT NULL,
`deg` VARCHAR(100) DEFAULT NULL,
`salary` INT(11) DEFAULT NULL,
`dept` VARCHAR(10) DEFAULT NULL,
`create_time` TIMESTAMP NOT NULL DEFAULT CURRENT_TIMESTAMP,
`update_time` TIMESTAMP NOT NULL DEFAULT CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP,
`is_delete` BIGINT(20) DEFAULT '1'
) ENGINE=INNODB DEFAULT CHARSET=utf8;
- 執行匯出命令:
sqoop export --connect jdbc:mysql://node03:3306/userdb --username root --password 123456 --table emp_out --export-dir /sqoop/emp --input-fields-terminated-by ","
- 驗證:去 mysql 表查詢資料

Sqoop常用命令及引數詳解
1. 常用命令列表
| 命令 | 類 | 說明 |
|---|---|---|
| import | ImportTool | 將資料匯入到叢集 |
| export | ExportTool | 將叢集資料匯出 |
| codegen | CodeGenTool | 獲取資料庫中某張表資料生成Java並打包Jar |
| create-hive-table | CreateHiveTableTool | 建立Hive表 |
| eval | EvalSqlTool | 檢視SQL執行結果 |
| import-all-tables | ImportAllTablesTool | 匯入某個資料庫下所有表到HDFS中 |
| job | JobTool | 用來生成一個sqoop的任務,生成後,該任務並不執行,除非使用命令執行該任務。 |
| list-databases | ListDatabasesTool | 列出所有資料庫名 |
| list-tables | ListTablesTool | 列出某個資料庫下所有表 |
| merge | MergeTool | 將HDFS中不同目錄下面的資料合在一起,並存放在指定的目錄中 |
| metastore | MetastoreTool | 記錄sqoop job的後設資料資訊,如果不啟動metastore範例,則預設的後設資料儲存目錄為:~/.sqoop,如果要更改儲存目錄,可以在組態檔sqoop-site.xml中進行更改。 |
| help | HelpTool | 列印sqoop幫助資訊 |
| version | VersionTool | 列印sqoop版本資訊 |
2. 資料庫連線公共引數
| 引數 | 說明 |
|---|---|
| –connect | 連線關係型資料庫的URL |
| –connection-manager | 指定要使用的連線管理類 |
| –driver | JDBC的driver class |
| –help | 列印幫助資訊 |
| –password | 連線資料庫的密碼 |
| –username | 連線資料庫的使用者名稱 |
| –verbose | 在控制檯列印出詳細資訊 |
3. import 公共引數
| 引數 | 說明 |
|---|---|
| –enclosed-by <char> | 給欄位值前後加上指定的字元 |
| –escaped-by <char> | 對欄位中的雙引號加跳脫符 |
| –fields-terminated-by <char> | 設定每個欄位是以什麼符號作為結束,預設為逗號 |
| –lines-terminated-by <char> | 設定每行記錄之間的分隔符,預設是\n |
| –mysql-delimiters | Mysql預設的分隔符設定,欄位之間以逗號分隔,行之間以\n分隔,預設跳脫符是\,欄位值以單引號包裹。 |
| –optionally-enclosed-by <char> | 給帶有雙引號或單引號的欄位值前後加上指定字元。 |
4. export 公共引數
| 引數 | 說明 |
|---|---|
| –input-enclosed-by <char> | 對欄位值前後加上指定字元 |
| –input-escaped-by <char> | 對含有轉移符的欄位做跳脫處理 |
| –input-fields-terminated-by <char> | 欄位之間的分隔符 |
| –input-lines-terminated-by <char> | 行之間的分隔符 |
| –input-optionally-enclosed-by <char> | 給帶有雙引號或單引號的欄位前後加上指定字元 |
5. hive 公共引數
| 引數 | 說明 |
|---|---|
| –hive-delims-replacement <arg> | 用自定義的字串替換掉資料中的\r\n和\013 \010等字元 |
| –hive-drop-import-delims | 在匯入資料到hive時,去掉資料中的\r\n\013\010這樣的字元 |
| –map-column-hive <map> | 生成hive表時,可以更改生成欄位的資料型別 |
| –hive-partition-key | 建立分割區,後面直接跟分割區名,分割區欄位的預設型別為string |
| –hive-partition-value <v> | 匯入資料時,指定某個分割區的值 |
| –hive-home <dir> | hive的安裝目錄,可以通過該引數覆蓋之前預設設定的目錄 |
| –hive-import | 將資料從關聯式資料庫中匯入到hive表中 |
| –hive-overwrite | 覆蓋掉在hive表中已經存在的資料 |
| –create-hive-table | 預設是false,即,如果目標表已經存在了,那麼建立任務失敗。 |
| –hive-table | 後面接要建立的hive表,預設使用MySQL的表名 |
| –table | 指定關聯式資料庫的表名 |
6. import 特有引數
- 將關係型資料庫中的資料匯入到HDFS(包括Hive,HBase)中,如果匯入的是Hive,那麼當Hive中沒有對應表時,則自動建立。
- 1、匯入資料到hive中:
sqoop import \
--connect jdbc:mysql://node03:3306/userdb \
--username root \
--password 123456 \
--table emp \
--hive-import
- 2、增量匯入到hive中
mode=append
sqoop import \
--connect jdbc:mysql://node03:3306/userdb \
--username root \
--password 123456 \
--table emp \
--num-mappers 1 \
--fields-terminated-by "\t" \
--target-dir /user/hive/warehouse/emp \
--check-column id \
--incremental append \
--last-value 3
append不能與–hive-等引數同時使用(Append mode for hive imports is not yet supported. Please remove the parameter --append-mode)
- 3、增量匯入資料到hdfs中,
mode=lastmodified
# 先在mysql中建表並插入幾條資料
create table company.staff_timestamp(id int(4), name varchar(255), sex varchar(255), last_modified timestamp DEFAULT CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP);
insert into company.staff_timestamp (id, name, sex) values(1, 'AAA', 'female');
insert into company.staff_timestamp (id, name, sex) values(2, 'BBB', 'female');
# 先匯入一部分資料
sqoop import --connect jdbc:mysql://node03:3306/userdb --username root --password 123456 --table emp_conn --delete-target-dir --m 1
insert into company.staff_timestamp (id, name, sex) values(3, 'CCC', 'female');
# 再增量匯入一部分資料
sqoop import --connect jdbc:mysql://node03:3306/userdb --username root --password 123456 --table emp_conn --check-column last_modified --incremental lastmodified --last-value "2018-0-28 22:20:38" -m 1 --append
使用lastmodified方式匯入資料要指定增量資料是要–append(追加)還是要–merge-key(合併)
–incremental lastmodified模式下,last-value指定的值是會包含於增量匯入的資料中。
| 引數 | 說明 |
|---|---|
| –append | 將資料追加到HDFS中已經存在的DataSet中,如果使用該引數,sqoop會把資料先匯入到臨時檔案目錄,再合併。 |
| –as-avrodatafile | 將資料匯入到一個Avro資料檔案中 |
| –as-sequencefile | 將資料匯入到一個sequence檔案中 |
| –as-textfile | 將資料匯入到一個普通文字檔案中 |
| –boundary-query <statement> | 邊界查詢,匯入的資料為該引數的值(一條sql語句)所執行的結果區間內的資料。 |
| –columns <col1, col2, col3> | 指定要匯入的欄位 |
| –direct | 直接匯入模式,使用的是關聯式資料庫自帶的匯入匯出工具,以便加快匯入匯出過程。 |
| –direct-split-size | 在使用上面direct直接匯入的基礎上,對匯入的流按位元組分塊,即達到該閾值就產生一個新的檔案 |
| –inline-lob-limit | 設定大物件資料型別的最大值 |
| –m或–num-mappers | 啟動N個map來並行匯入資料,預設4個。 |
| –query或–e | 將查詢結果的資料匯入,使用時必須伴隨參–target-dir,–hive-table,如果查詢中有where條件,則條件後必須加上$CONDITIONS關鍵字 |
| –split-by <column-name> | 按照某一列來切分表的工作單元,不能與–autoreset-to-one-mapper連用(請參考官方檔案) |
| –table <table-name> | 關聯式資料庫的表名 |
| –target-dir <dir> | 指定HDFS路徑 |
| –warehouse-dir <dir> | 與14引數不能同時使用,匯入資料到HDFS時指定的目錄 |
| –where | 從關聯式資料庫匯入資料時的查詢條件 |
| –z或–compress | 允許壓縮 |
| –compression-codec | 指定hadoop壓縮編碼類,預設為gzip(Use Hadoop codec default gzip) |
| –null-string <null-string> | string型別的列如果null,替換為指定字串 |
| –null-non-string <null-string> | 非string型別的列如果null,替換為指定字串 |
| –check-column <col> | 作為增量匯入判斷的列名 |
| –incremental <mode> | mode:append或lastmodified |
| –last-value <value> | 指定某一個值,用於標記增量匯入的位置 |
7. export 特有引數
- 從HDFS(包括Hive和HBase)中將資料匯出到關係型資料庫中
sqoop export \
--connect jdbc:mysql://node03:3306/userdb \
--username root \
--password 123456 \
--table emp_add \
--export-dir /user/company \
--input-fields-terminated-by "\t" \
--num-mappers 1
| 引數 | 說明 |
|---|---|
| –direct | 利用資料庫自帶的匯入匯出工具,以便於提高效率 |
| –export-dir <dir> | 存放資料的HDFS的源目錄 |
| -m或–num-mappers <n> | 啟動N個map來並行匯入資料,預設4個 |
| –table <table-name> | 指定匯出到哪個RDBMS中的表 |
| –update-key <col-name> | 對某一列的欄位進行更新操作 |
| –update-mode <mode> | updateonly allowinsert(預設) |
| –input-null-string <null-string> | 請參考import該類似引數說明 |
| –input-null-non-string <null-string> | 請參考import該類似引數說明 |
| –staging-table <staging-table-name> | 建立一張臨時表,用於存放所有事務的結果,然後將所有事務結果一次性匯入到目標表中,防止錯誤。 |
| –clear-staging-table | 如果第9個引數非空,則可以在匯出操作執行前,清空臨時事務結果表 |
8. codegen 特有引數
- 將關係型資料庫中的表對映為一個Java類,在該類中有各列對應的各個欄位
sqoop codegen \
--connect jdbc:mysql://node03:3306/userdb \
--username root \
--password 123456 \
--table emp_add \
--bindir /home/admin/Desktop/staff \
--class-name Staff \
--fields-terminated-by "\t"
| 引數 | 說明 |
|---|---|
| –bindir <dir> | 指定生成的Java檔案、編譯成的class檔案及將生成檔案打包為jar的檔案輸出路徑 |
| –class-name <name> | 設定生成的Java檔案指定的名稱 |
| –outdir <dir> | 生成Java檔案存放的路徑 |
| –package-name <name> | 包名,如com.z,就會生成com和z兩級目錄 |
| –input-null-non-string <null-str> | 在生成的Java檔案中,可以將null字串或者不存在的字串設定為想要設定的值(例如空字串) |
| –input-null-string <null-str> | 將null字串替換成想要替換的值(一般與5同時使用) |
| –map-column-java <arg> | 資料庫欄位在生成的Java檔案中會對映成各種屬性,且預設的資料型別與資料庫型別保持對應關係。該引數可以改變預設型別,例如:–map-column-java id=long, name=String |
| –null-non-string <null-str> | 在生成Java檔案時,可以將不存在或者null的字串設定為其他值 |
| –null-string <null-str> | 在生成Java檔案時,將null字串設定為其他值(一般與8同時使用) |
| –table <table-name> | 對應關聯式資料庫中的表名,生成的Java檔案中的各個屬性與該表的各個欄位一一對應 |
9. create-hive-table 特有引數
- 生成與關聯式資料庫表結構對應的hive表結構
sqoop create-hive-table \
--connect jdbc:mysql://node03:3306/userdb \
--username root \
--password 123456 \
--table emp_add \
--hive-table emp_add
| 引數 | 說明 |
|---|---|
| –hive-home <dir> | Hive的安裝目錄,可以通過該引數覆蓋掉預設的Hive目錄 |
| –hive-overwrite | 覆蓋掉在Hive表中已經存在的資料 |
| –create-hive-table | 預設是false,如果目標表已經存在了,那麼建立任務會失敗 |
| –hive-table | 後面接要建立的hive表 |
| –table | 指定關聯式資料庫的表名 |
10. eval 特有引數
- 可以快速的使用SQL語句對關係型資料庫進行操作,經常用於在 import 資料之前,瞭解一下 SQL 語句是否正確,資料是否正常,並可以將結果顯示在控制檯。
sqoop eval \
--connect jdbc:mysql://node03:3306/userdb \
--username root \
--password 123456 \
--query "SELECT * FROM emp"
| 引數 | 說明 |
|---|---|
| –query或–e | 後跟查詢的SQL語句 |
11. import-all-tables 特有引數
- 可以將RDBMS中的所有表匯入到HDFS中,每一個表都對應一個HDFS目錄
$ bin/sqoop import-all-tables \
--connect jdbc:mysql://node03:3306/userdb \
--username root \
--password 123456 \
--warehouse-dir /all_tables
| 引數 | 說明 |
|---|---|
| –as-avrodatafile | 這些引數的含義均和import對應的含義一致 |
| –as-sequencefile | |
| –as-textfile | |
| –direct | |
| –direct-split-size <n> | |
| –inline-lob-limit <n> | |
| –m或—num-mappers <n> | |
| –warehouse-dir <dir> | |
| -z或–compress | |
| –compression-codec |
12. job 特有引數
- 用來生成一個sqoop任務,生成後不會立即執行,需要手動執行。
$ bin/sqoop job \
--create myjob -- import-all-tables \
--connect jdbc:mysql://node03:3306/userdb \
--username root \
--password 123456
$ bin/sqoop job \
--list
$ bin/sqoop job \
--exec myjob
注意 import-all-tables 和它左邊的–之間有一個空格
如果需要連線metastore,則–meta-connect jdbc:hsqldb:hsql://node03:16000/sqoop
| 引數 | 說明 |
|---|---|
| –create <job-id> | 建立job引數 |
| –delete <job-id> | 刪除一個job |
| –exec \ | 執行一個job |
| –help | 顯示job幫助 |
| –list | 顯示job列表 |
| –meta-connect <jdbc-uri> | 用來連線metastore服務 |
| –show <job-id> | 顯示一個job的資訊 |
| –verbose | 列印命令執行時的詳細資訊 |
在執行一個job時,如果需要手動輸入資料庫密碼,可以做如下優化
<property>
<name>sqoop.metastore.client.record.password</name>
<value>true</value>
<description>If true, allow saved passwords in the metastore.</description>
</property>
13. list-databases 特有引數
- 列出所有資料庫名稱
sqoop list-databases \
--connect jdbc:mysql://node03:3306/userdb \
--username root \
--password 123456
- 引數與公用引數一樣
14. list-tables 特有引數
- 列出某個資料庫下所有表
$ bin/sqoop list-tables \
--connect jdbc:mysql://node03:3306/userdb \
--username root \
--password 123456
**引數:**與公用引數一樣
15. merge 特有引數
- 將HDFS中不同目錄下面的資料合併在一起並放入指定目錄中
# 資料準備
# 資料的列之間的分隔符應該為\t,行與行之間的分割符為\n
new_staff
1 AAA male
2 BBB male
3 CCC male
4 DDD male
old_staff
1 AAA female
2 CCC female
3 BBB female
6 DDD female
# 建立JavaBean
sqoop codegen \
--connect jdbc:mysql://node03:3306/userdb \
--username root \
--password 123456 \
--table emp_conn \
--bindir /home/admin/Desktop/staff \
--class-name EmpConn \
--fields-terminated-by "\t"
- 開始合併:
sqoop merge \
--new-data /test/new/ \
--onto /test/old/ \
--target-dir /test/merged \
--jar-file /home/admin/Desktop/staff/EmpConn.jar \
--class-name Staff \
--merge-key id
- 結果:
1 AAA MALE
2 BBB MALE
3 CCC MALE
4 DDD MALE
6 DDD FEMALE
| 引數 | 說明 |
|---|---|
| –new-data <path> | HDFS 待合併的資料目錄,合併後在新的資料集中保留 |
| –onto <path> | HDFS合併後,重複的部分在新的資料集中被覆蓋 |
| –merge-key <col> | 合併鍵,一般是主鍵ID |
| –jar-file \ | 合併時引入的jar包,該jar包是通過Codegen工具生成的jar包 |
| –class-name <class> | 對應的表名或物件名,該class類是包含在jar包中的 |
| –target-dir <path> | 合併後的資料在HDFS裡存放的目錄 |
16. metastore 特有引數
- 記錄了Sqoop job的後設資料資訊,如果不啟動該服務,那麼預設job後設資料的儲存目錄為~/.sqoop,可在sqoop-site.xml中修改。
# 啟動sqoop的metastore服務
sqoop metastore
| 引數 | 說明 |
|---|---|
| –shutdown | 關閉metastore |
Sqoop作業
- Sqoop作業:將事先定義好的資料匯入匯出任務按照指定流程執行
1. 語法
$ sqoop job (generic-args) (job-args) [-- [subtool-name] (subtool-args)]
$ sqoop-job (generic-args) (job-args) [-- [subtool-name] (subtool-args)]
2. 建立作業(–create)
- 建立一個名為 myjob,可以從 RDBMS 表的資料匯入到 HDFS 的作業。
sqoop job --create myjob -- import --connect jdbc:mysql://node03:3306/userdb --username root --password 123456 --table emp --delete-target-dir
3. 驗證作業 (–list)
- –list 引數用來驗證儲存的作業
sqoop job --list
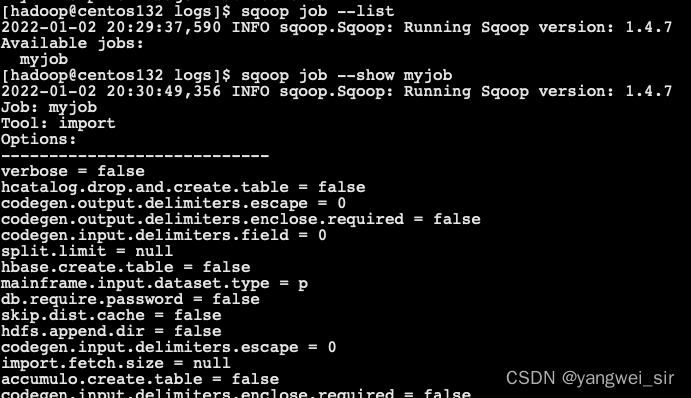
4. 檢查作業(–show)
- –show 引數用於檢查或驗證特定的工作,及其詳細資訊
sqoop job --show myjob
5. 執行作業 (–exec)
- –exec 選項用於執行儲存的作業
sqoop job --exec myjob