五十八、Ubuntu搭建hadoopHA高可用(從零開始)
環境準備
| 編號 | 主機名 | 型別 | 使用者 | IP |
|---|---|---|---|---|
| 1 | master | 主節點 | root | 192.168.231.247 |
| 2 | slave1 | 從節點 | root | 192.168.231.248 |
| 3 | slave2 | 從節點 | root | 192.168.231.249 |
環境搭建
一、基礎設定
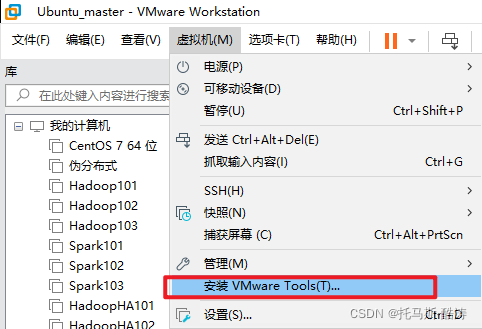
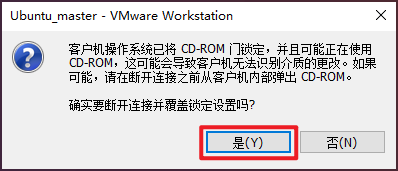
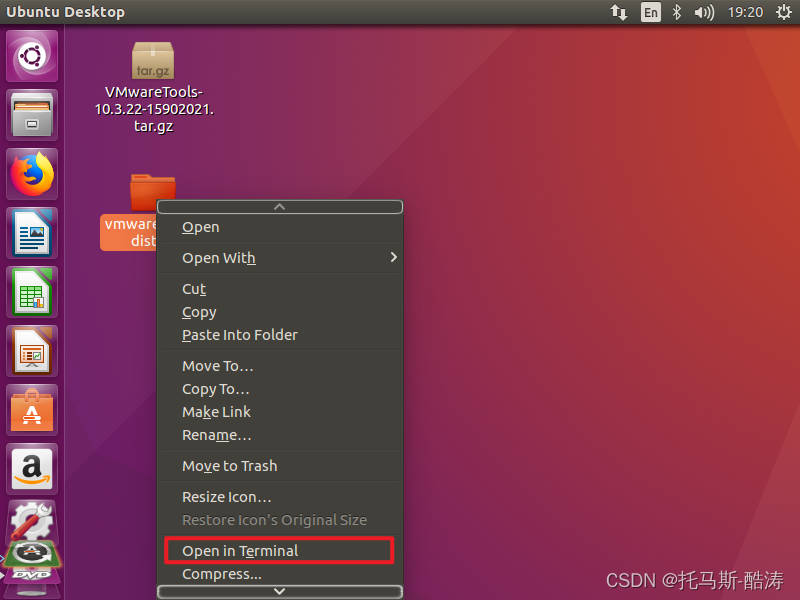
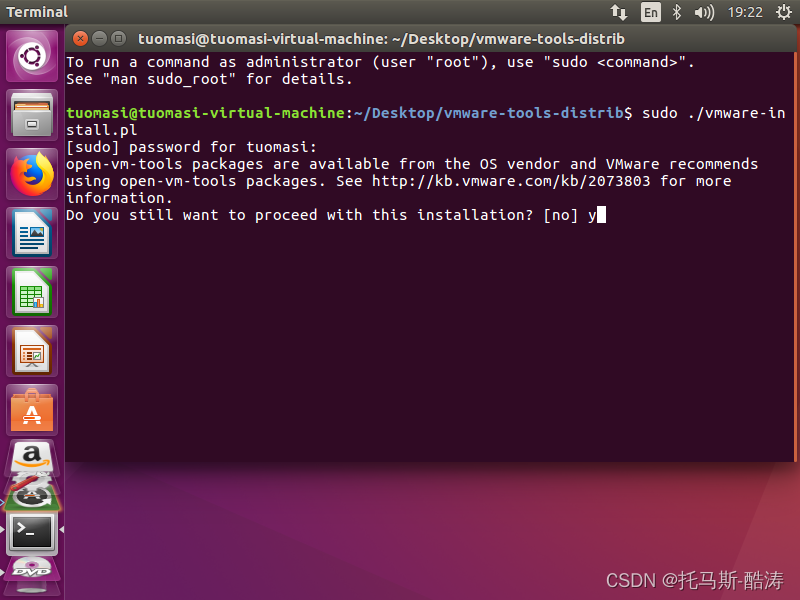
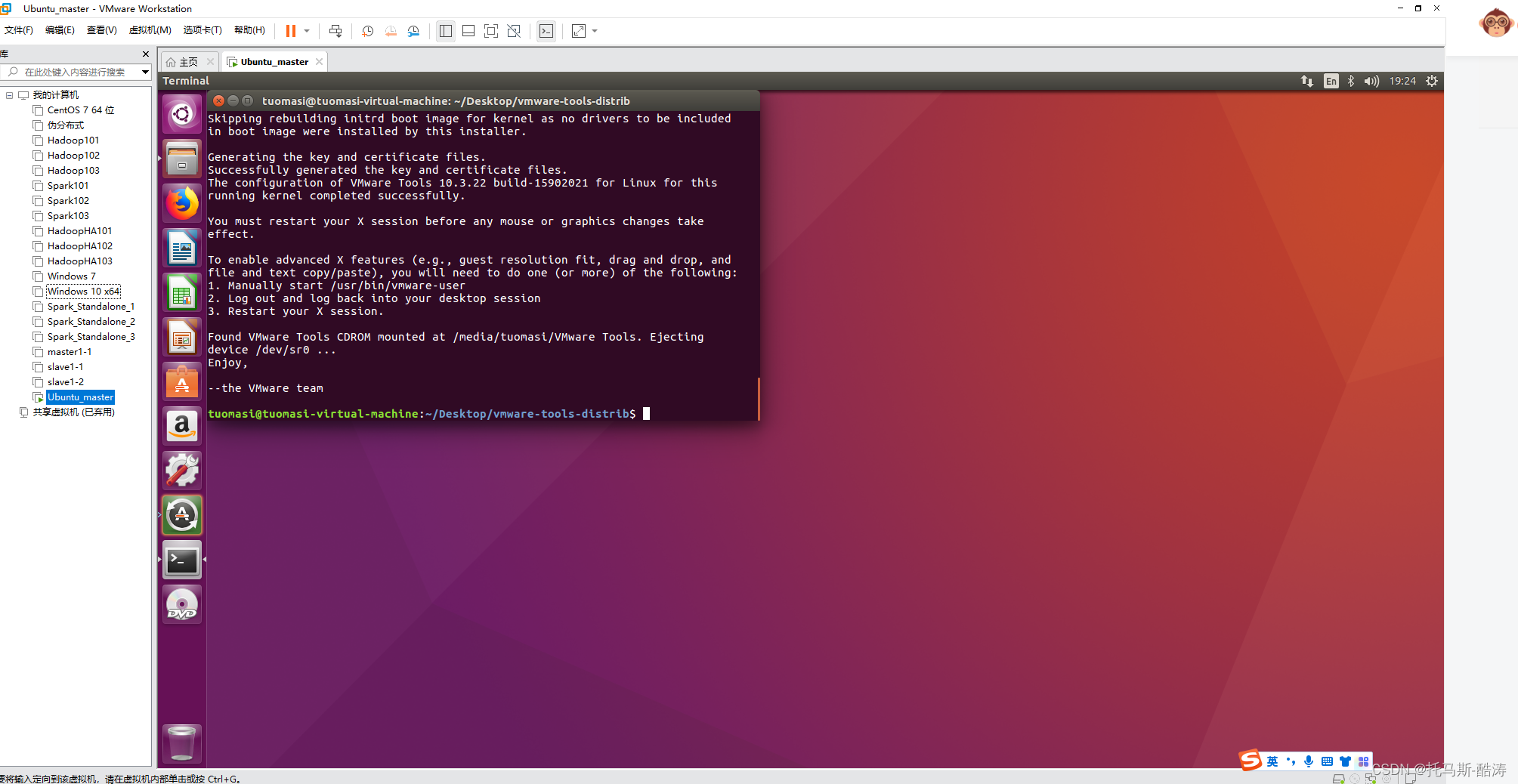
1、安裝VMware tools
將其複製到桌面
注:遇到提示按 '回車' 鍵,遇到 'yes/no' 輸入yes
安裝完成Tools後的效果如圖
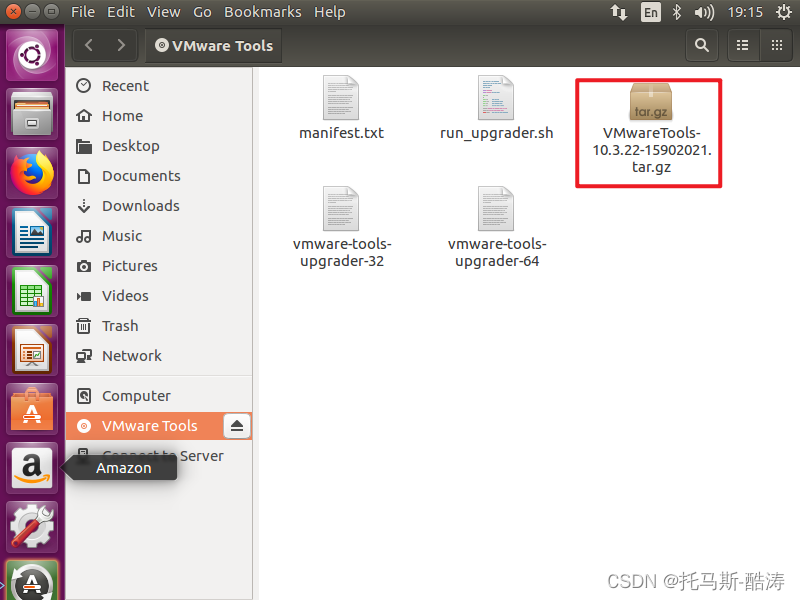
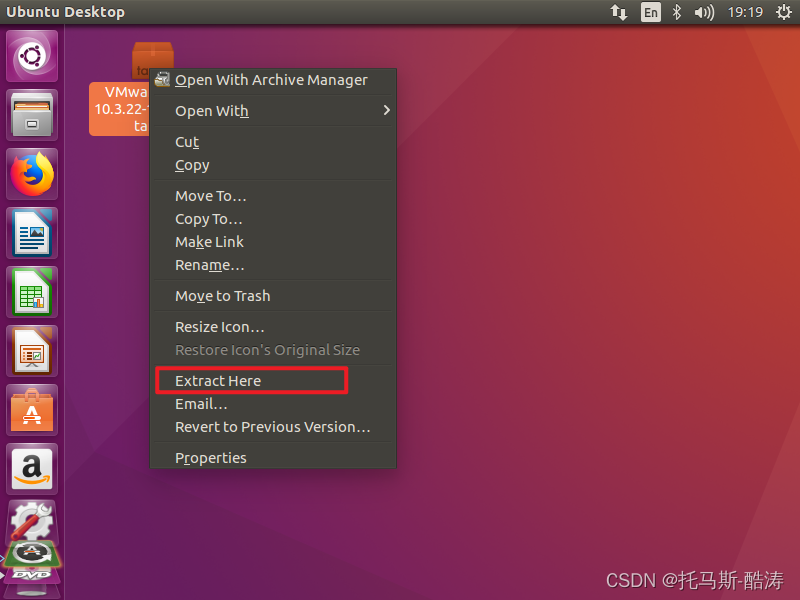
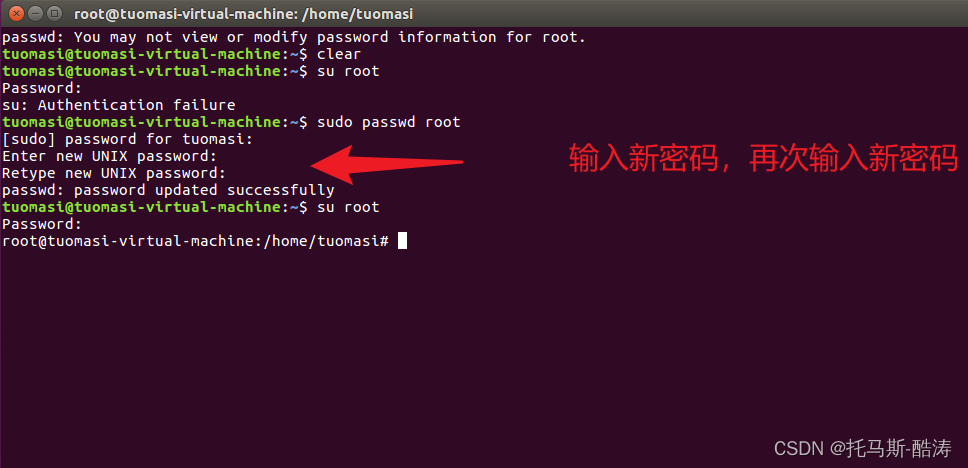
2、修改root密碼
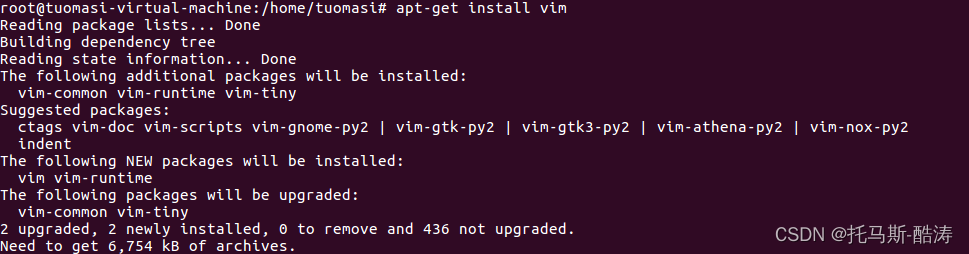
3、更新 apt,安裝vim編譯器
apt-get update
apt-get install vim
注:vim 編譯器相對於 vi 編譯器 對使用者來說更友好,使用便捷,且有高亮關鍵字的功能

4、安裝ssh服務
apt-get install openssh-server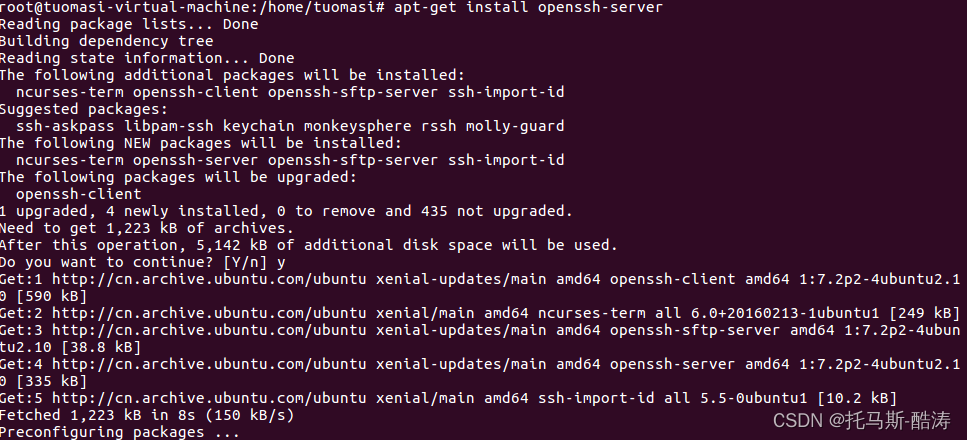
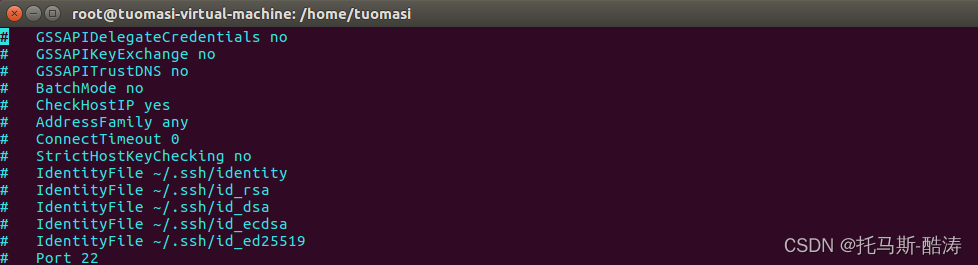
5、修改ssh組態檔,允許root遠端登入
vim /etc/ssh/sshd_config更改前:
更改後:
注:將 prohibit-password 更改為 yes


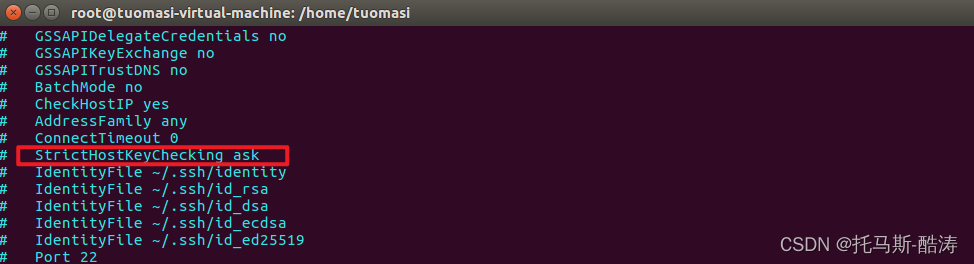
6、去掉初始詢問
vi /etc/ssh/ssh_config更改前:
更改後:
7、關閉防火牆
ufw disable
ufw status
8、環境設定
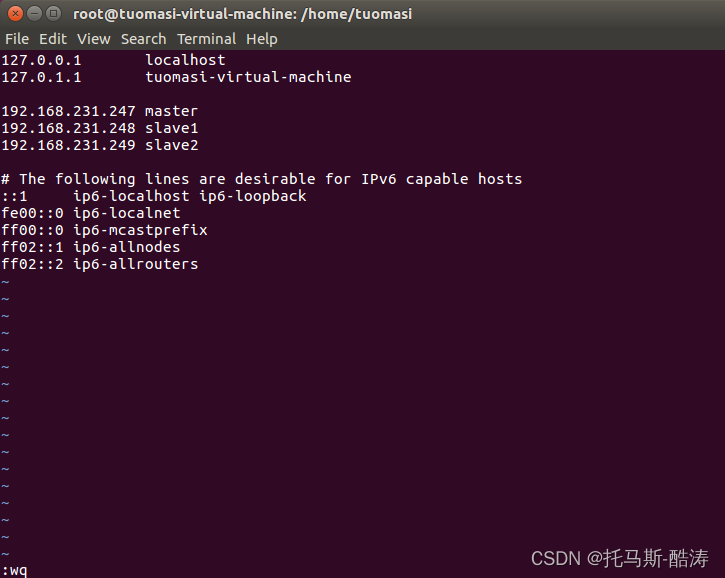
(1)修改hosts檔案
vim /etc/hosts
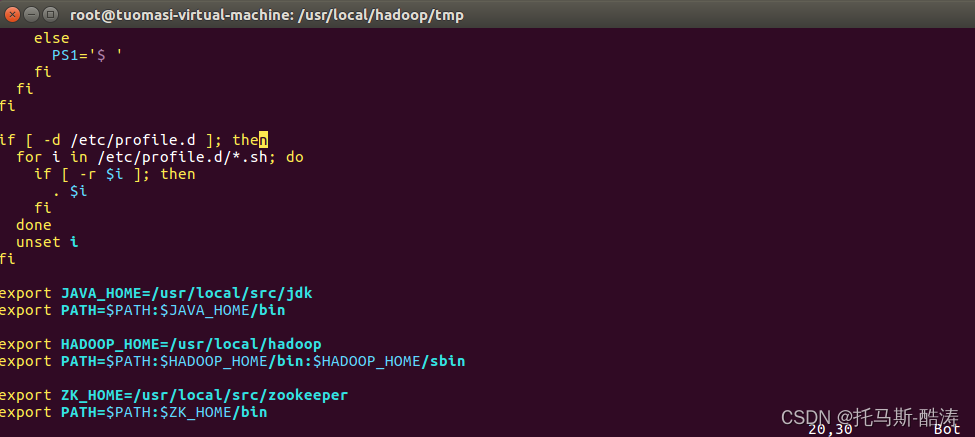
(2)新增環境變數
vim /etc/profile
(3)解壓 jdk
tar -zxvf jdk1.8.0_221.tar.gz -C /usr/local/src/重新命名其名稱為 jdk
mv jdk1.8.0_221 jdk
(4)hadoop設定
tar -zxvf hadoop-2.7.1.tar.gz -C /usr/local/重新命名其名稱為hadoop
mv hadoop-2.7.1 hadoop
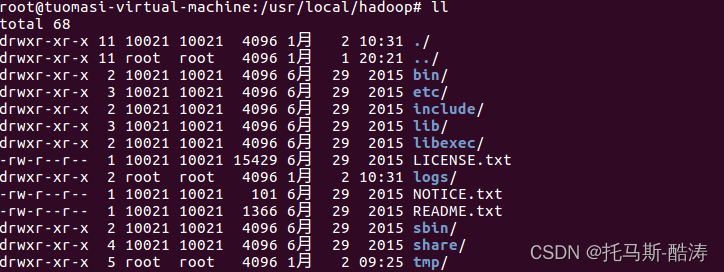
在hadoop安裝目錄下建立 tmp 和 logs目錄
在tmp目錄下建立 data 和 name 和 journal 目錄

進入hadoop組態檔目錄進行修改組態檔
hadoop-env.sh core-site.xml hdfs-site.xml mapred-site.xml yarn-site.xml yarn-env.sh slaves
其中hadoop-env.sh 與 yarn-env.sh 只需要修改其中的 jdk 路徑
hadoop-env.sh
yarn-env.sh
注:yarn-env.sh 檔案中jdk路徑需要去掉註釋,否則無法生效
core-site.xml
<configuration> <property> <name>fs.defaultFS</name> <value>hdfs://mycluster</value> </property> <property> <name>hadoop.tmp.dir</name> <value>/usr/local/hadoop/tmp</value> </property> <property> <name>ha.zookeeper.quorum</name> <value>master:2181,slave1:2181,slave2:2181</value> </property> <property> <name>ha.zookeeper.session-timeout.ms</name> <value>30000</value> <description>ms</description> </property> <property> <name>fs.trash.interval</name> <value>1440</value> </property> </configuration>hdfs-site.xml
<configuration> <property> <name>dfs.qjournal.start-segment.timeout.ms</name> <value>60000</value> </property> <property> <name>dfs.nameservices</name> <value>mycluster</value> </property> <property> <name>dfs.ha.namenodes.mycluster</name> <value>master,slave1</value> </property> <property> <name>dfs.namenode.rpc-address.mycluster.master</name> <value>master:9000</value> </property> <property> <name>dfs.namenode.rpc-address.mycluster.slave1</name> <value>slave1:9000</value> </property> <property> <name>dfs.namenode.http-address.mycluster.master</name> <value>master:50070</value> </property> <property> <name>dfs.namenode.http-address.mycluster.slave1</name> <value>slave1:50070</value> </property> <property> <name>dfs.namenode.shared.edits.dir</name> <value>qjournal://master:8485;slave1:8485;slave2:8485/mycluster</value> </property> <property> <name>dfs.client.failover.proxy.provider.mycluster</name> <value>org.apache.hadoop.hdfs.server.namenode.ha.ConfiguredFailoverProxyProvider</value> </property> <property> <name>dfs.ha.fencing.methods</name> <value> sshfence shell(/bin/true) </value> </property> <property> <name>dfs.permissions.enabled</name> <value>false</value> </property> <property> <name>dfs.support.append</name> <value>true</value> </property> <property> <name>dfs.ha.fencing.ssh.private-key-files</name> <value>/root/.ssh/id_rsa</value> </property> <property> <name>dfs.replication</name> <value>2</value> </property> <property> <name>dfs.namenode.name.dir</name> <value>/usr/local/hadoop/tmp/name</value> </property> <property> <name>dfs.datanode.data.dir</name> <value>/usr/local/hadoop/tmp/data</value> </property> <property> <name>dfs.journalnode.edits.dir</name> <value>/usr/local/hadoop/tmp/journal</value> </property> <property> <name>dfs.ha.automatic-failover.enabled</name> <value>true</value> </property> <property> <name>dfs.webhdfs.enabled</name> <value>true</value> </property> <property> <name>dfs.ha.fencing.ssh.connect-timeout</name> <value>30000</value> </property> <property> <name>ha.failover-controller.cli-check.rpc-timeout.ms</name> <value>60000</value> </property> </configuration>mapred-site.xml
<configuration> <property> <name>mapreduce.framework.name</name> <value>yarn</value> </property> <property> <name>mapreduce.jobhistory.address</name> <value>master:10020</value> </property> <property> <name>mapreduce.jobhistory.webapp.address</name> <value>master:19888</value> </property> </configuration>yarn-site.xml
<configuration> <property> <name>yarn.resourcemanager.ha.enabled</name> <value>true</value> </property> <property> <name>yarn.resourcemanager.cluster-id</name> <value>yrc</value> </property> <property> <name>yarn.resourcemanager.ha.rm-ids</name> <value>rm1,rm2</value> </property> <property> <name>yarn.resourcemanager.hostname.rm1</name> <value>master</value> </property> <property> <name>yarn.resourcemanager.hostname.rm2</name> <value>slave1</value> </property> <property> <name>yarn.resourcemanager.zk-address</name> <value>master:2181,slave1:2181,slave2:2181</value> </property> <property> <name>yarn.nodemanager.aux-services</name> <value>mapreduce_shuffle</value> </property> <property> <name>yarn.log-aggregation-enable</name> <value>true</value> </property> <property> <name>yarn.log-aggregation.retain-seconds</name> <value>86400</value> </property> <property> <name>yarn.resourcemanager.recovery.enabled</name> <value>true</value> </property> <property> <name>yarn.resourcemanager.store.class</name> <value>org.apache.hadoop.yarn.server.resourcemanager.recovery.ZKRMStateStore</value> </property> </configuration>slaves
master slave1 slave2(5)zookeeper設定
解壓zookeeper
tar -zxvf zookeeper-3.4.8.tar.gz -C /usr/local/src/重新命名其名稱為zookeeper
mv zookeeper-3.4.8 zookeeper在zookeeper安裝目錄下建立 logs 目錄和 data 目錄
在data目錄下建立myid檔案並寫入內容 「1」
進入zookeeper/conf目錄下,重新命名 zoo_sample.cfg 為 zoo.cfg
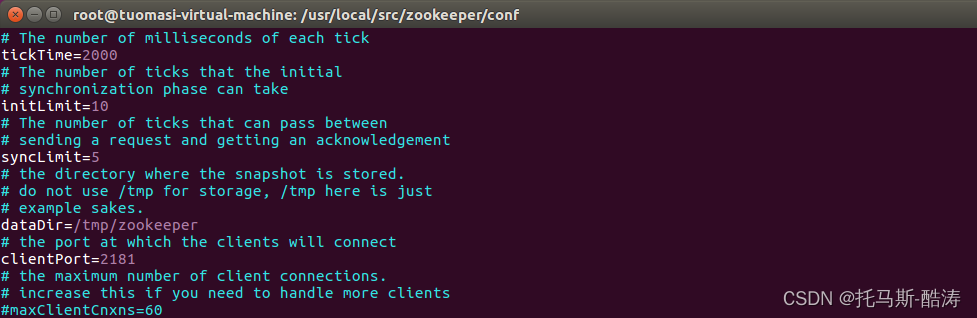
編輯zoo.cfg檔案
修改前:
修改後:






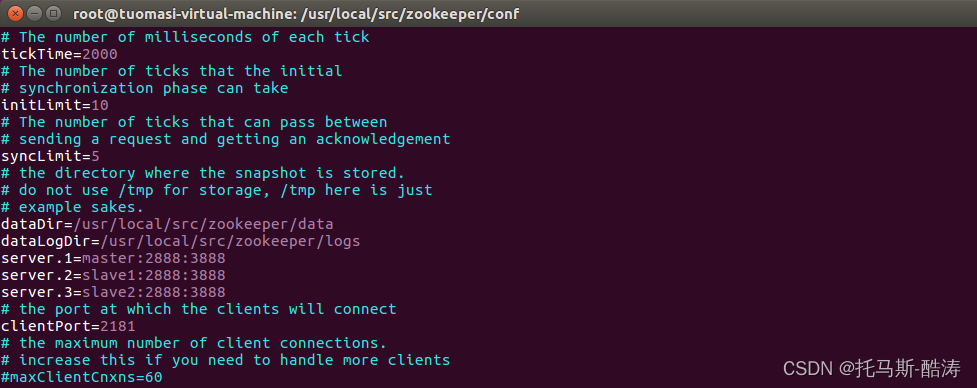
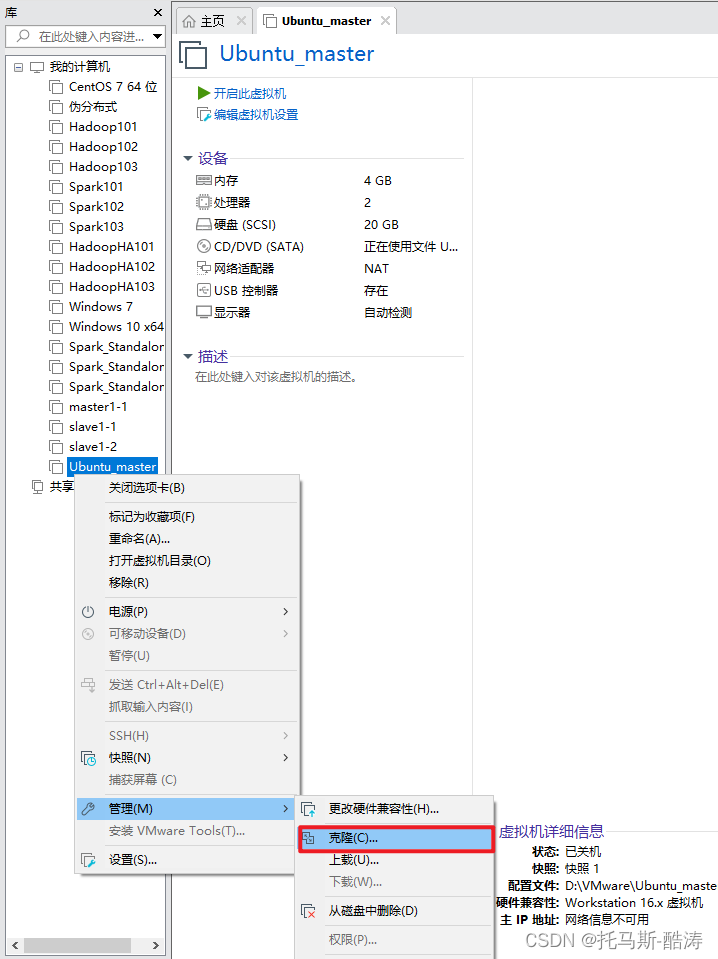
二、三臺機器叢集搭建
1、關機狀態下克隆出另外兩臺虛擬機器器
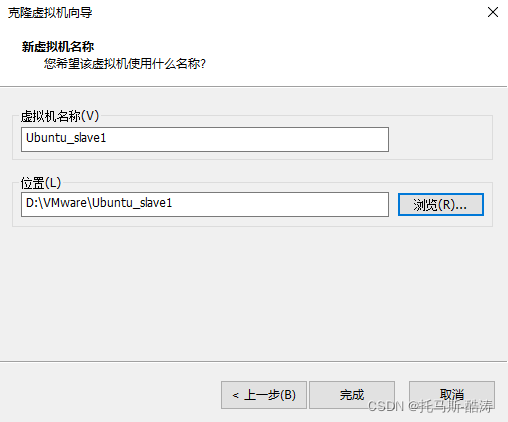
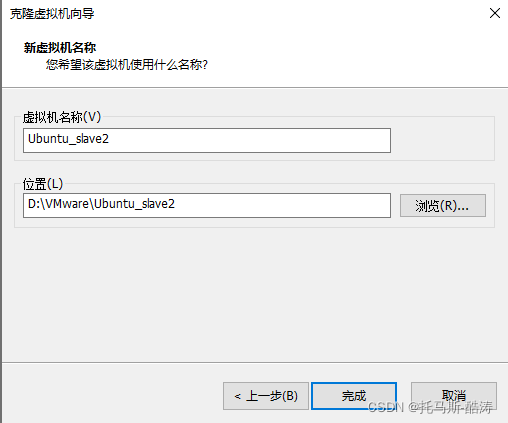
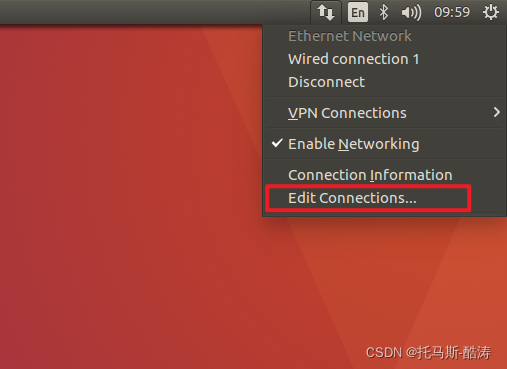
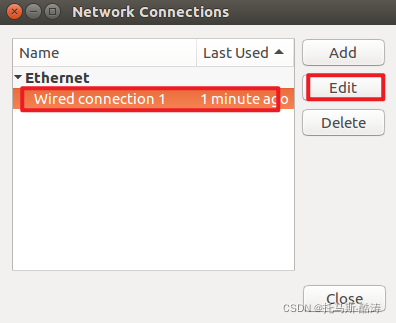
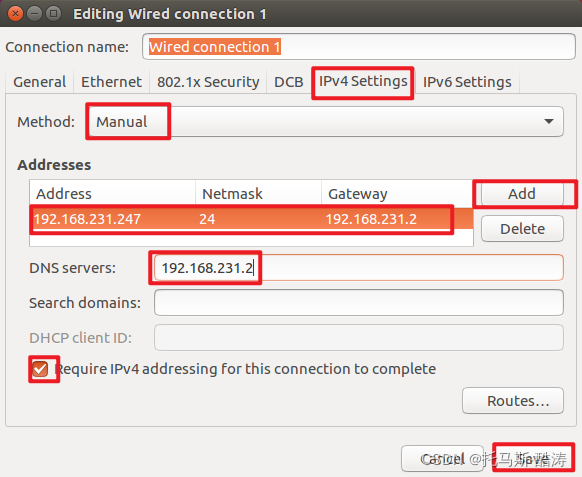
2、三臺機器分別修改靜態IP
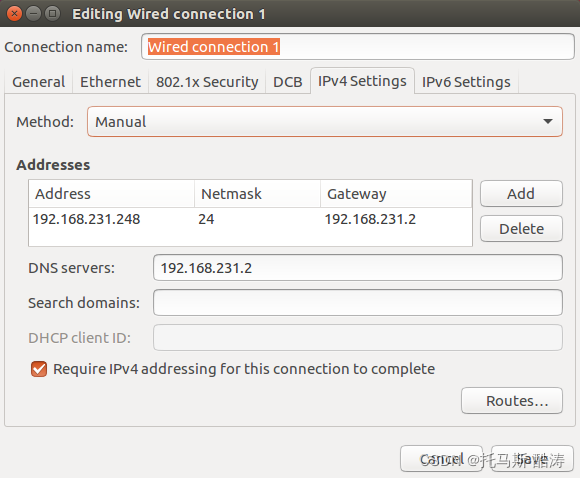
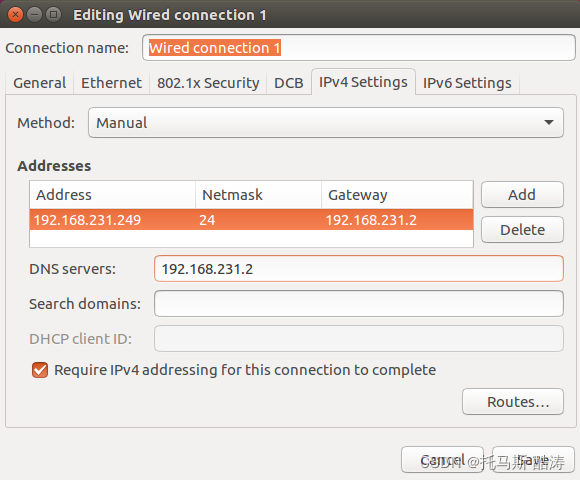
3、重新啟動三臺機器網路服務
service networking restart4、內網與外網的檢查
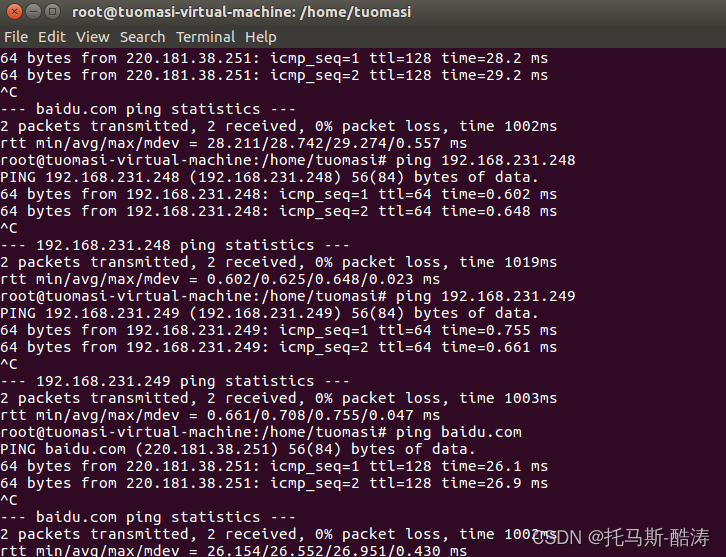
5、三臺機器分別修改其主機名
hostnamectl set-hostname master
hostnamectl set-hostname slave1
hostnamectl set-hostname slave2
6、修改其他兩臺機器zookeeper/data/myid檔案分別為2和3



7、重新啟動三臺機器
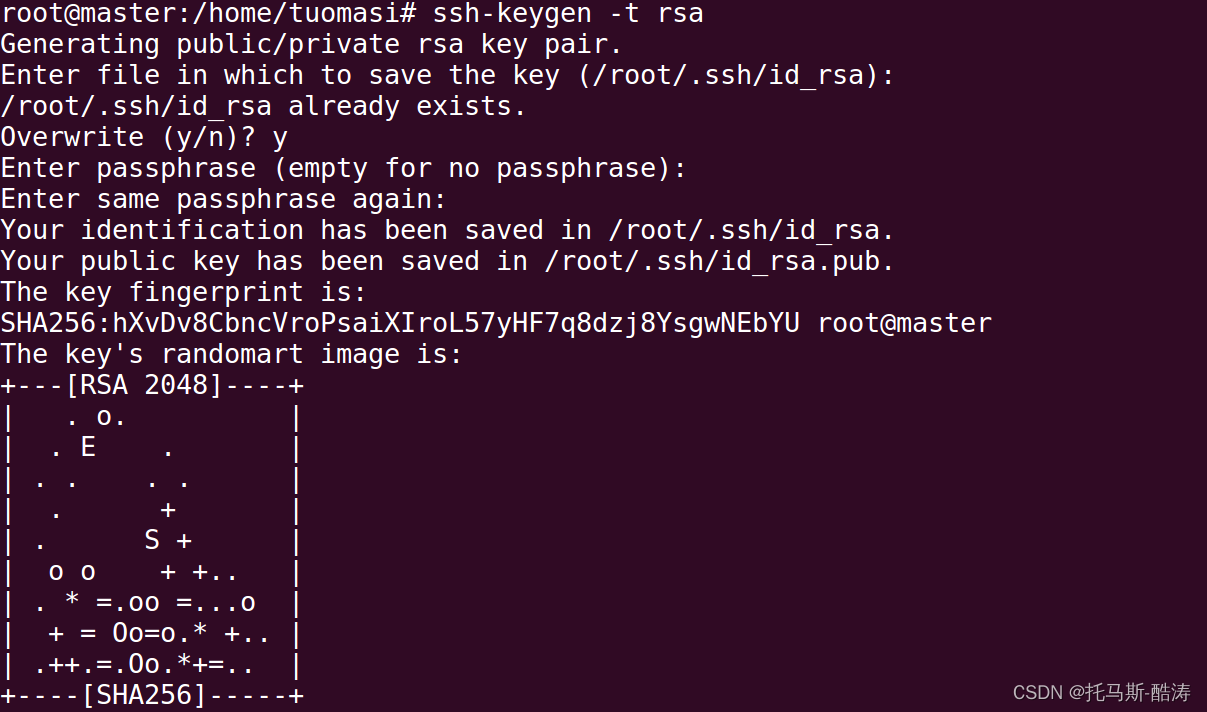
reboot8、設定ssh免密
生成金鑰
ssh-keygen -t rsa
分發金鑰
ssh-copy-id 192.168.231.248 ssh-copy-id 192.168.231.249
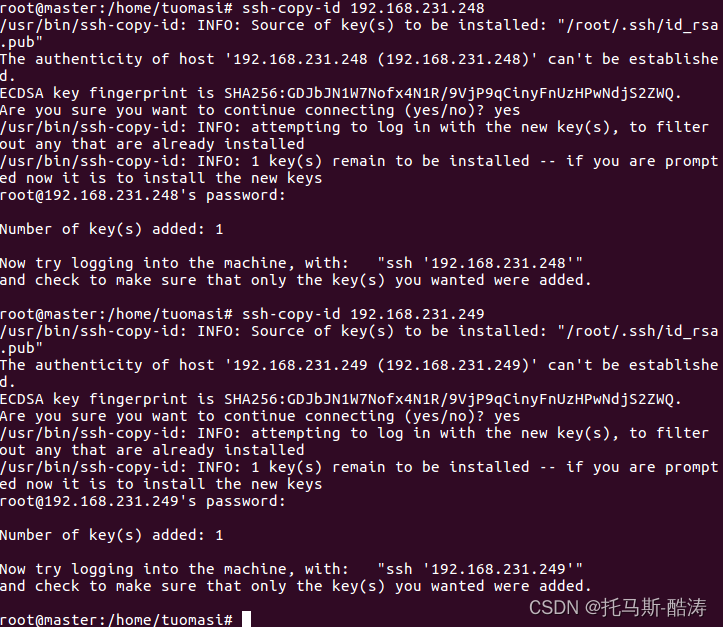
9、使三臺機器的環境變數生效
source /etc/profile10、啟動三臺機器的zookeeper叢集
bin/zkServer.sh startbin/zkServer.sh status


11、格式化zookeeper在HA中的狀態
bin/hdfs zkfc -formatZK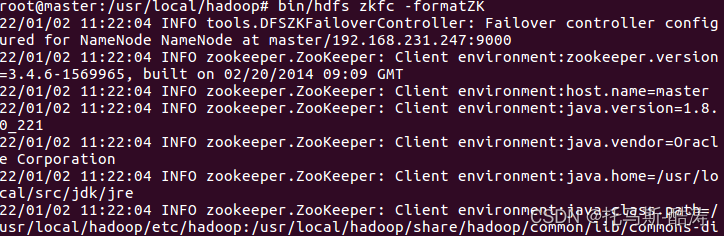
12、啟動三臺機器的 journalnode程序
sbin/hadoop-daemon.sh start journalnode


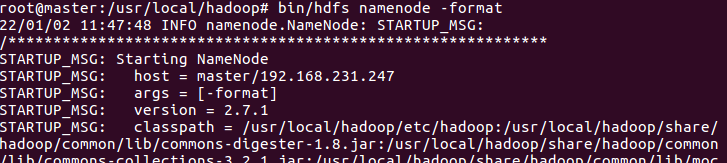
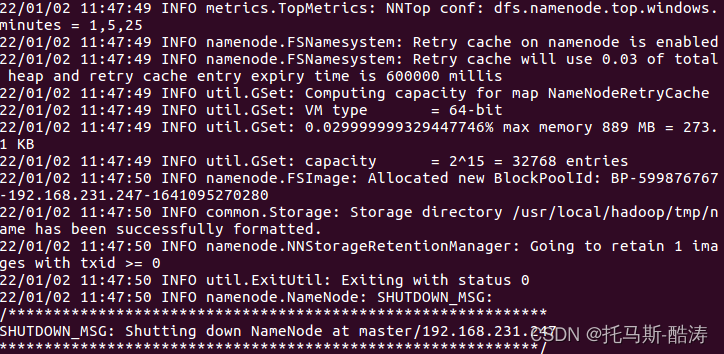
13、格式化namenode
bin/hdfs namenode -format
注:觀察是否有報錯資訊,status是否為0,0即為初始化成功,1則報錯,檢查組態檔是否有誤
14、啟動hadoop所有程序
sbin/start-all.sh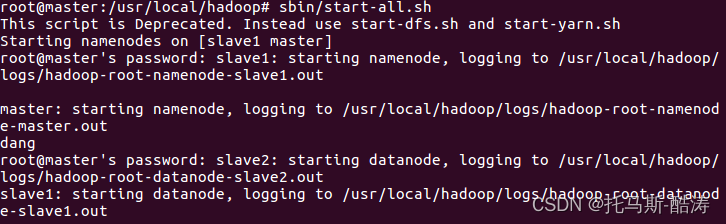
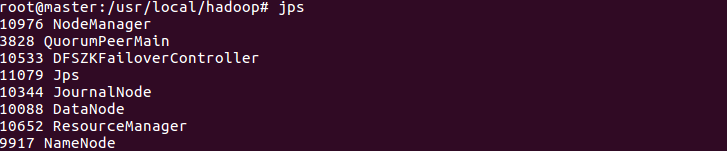


15、格式化主從節點
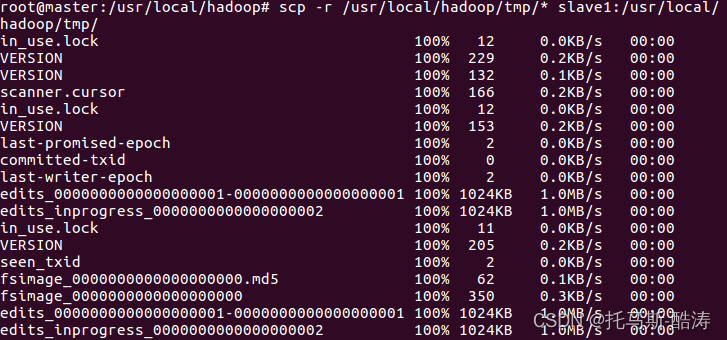
複製namenode後設資料到從節點
scp -r /usr/local/hadoop/tmp/* slave1:/usr/local/hadoop/tmp/
scp -r /usr/local/hadoop/tmp/* slave2:/usr/local/hadoop/tmp/
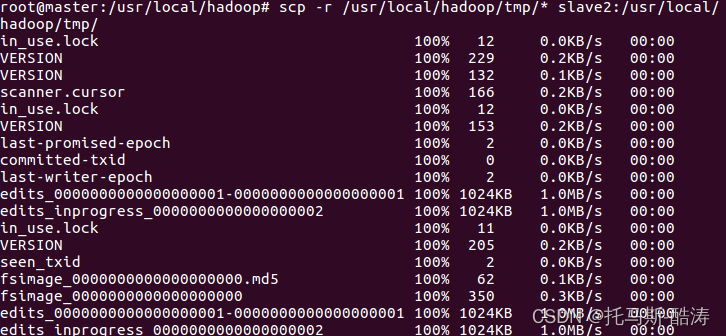
注:由於之前namenode,datanode,journalnode的資料全部存放在hadoop/tmp目錄下,所以直接複製 tmp 目錄至從節點
16、啟動slave1的resourcemanager 和 namenode 程序
sbin/yarn-daemon.sh start resourcemanagersbin/hadoop-daemon.sh start namenode
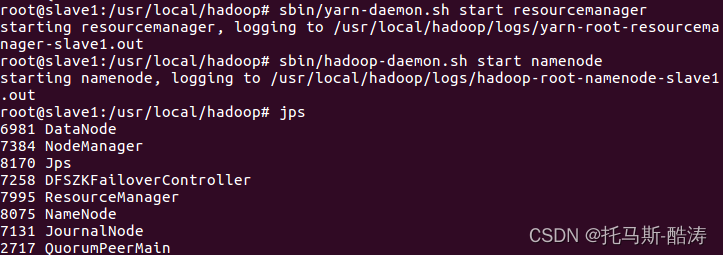
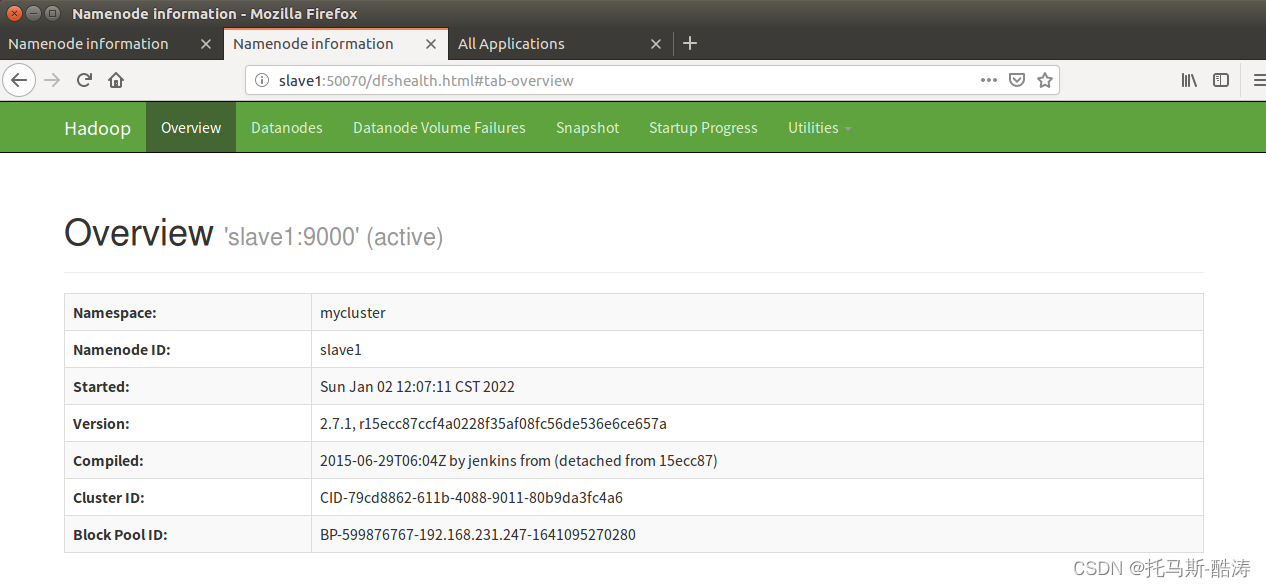
17、存取 resourcemanager 和 namenode 的web頁面
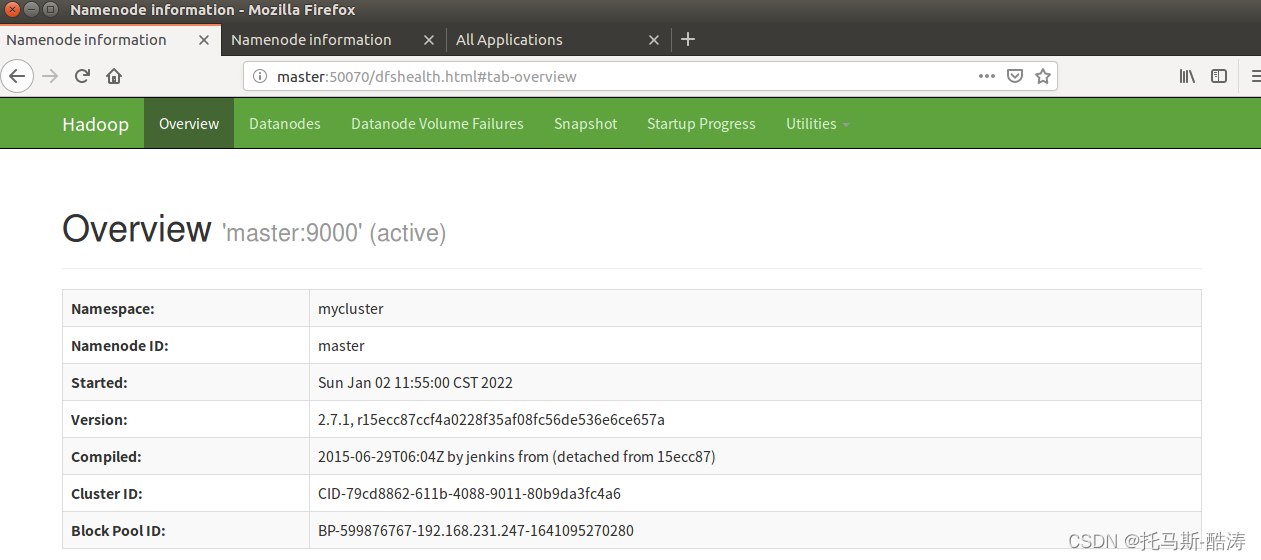
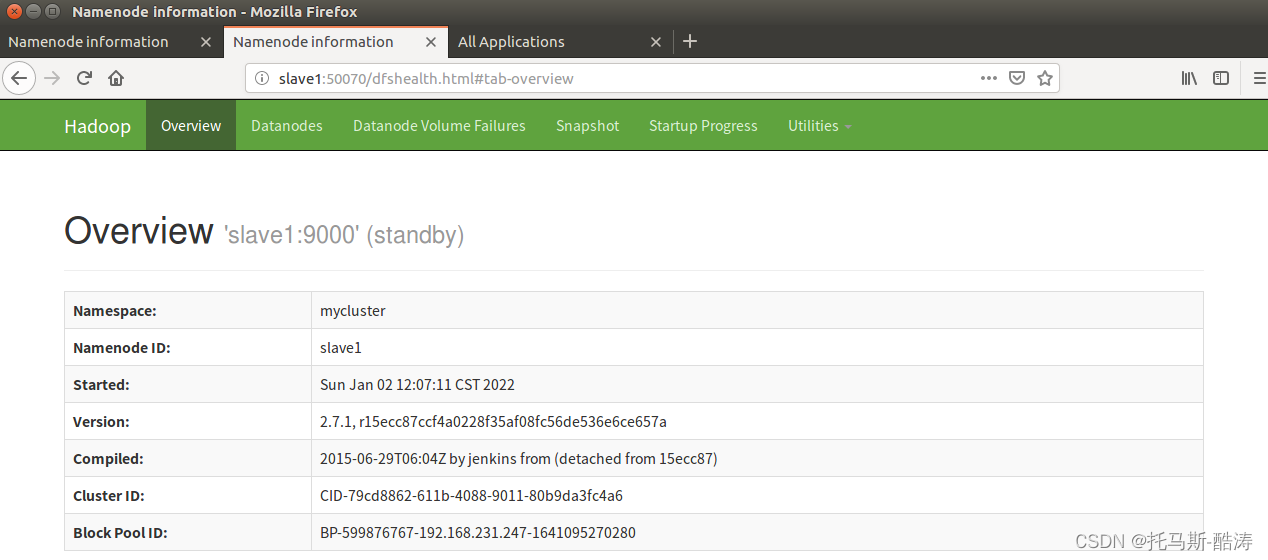
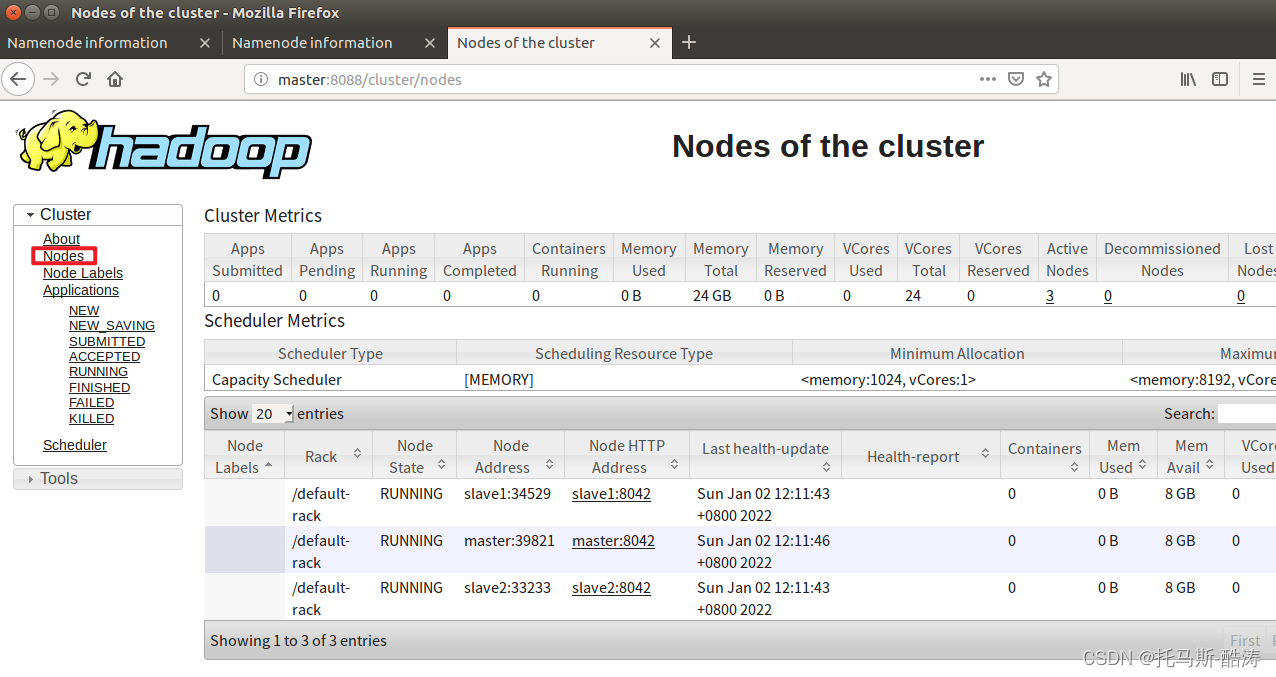
18、殺死master端的namenode(模擬master宕機後HA的故障轉移)
kill -9 (namenode程序號)
注: 可見,在naster宕機後,slave自動接替了master的工作,成為活躍狀態,此為HA 的故障轉移機制
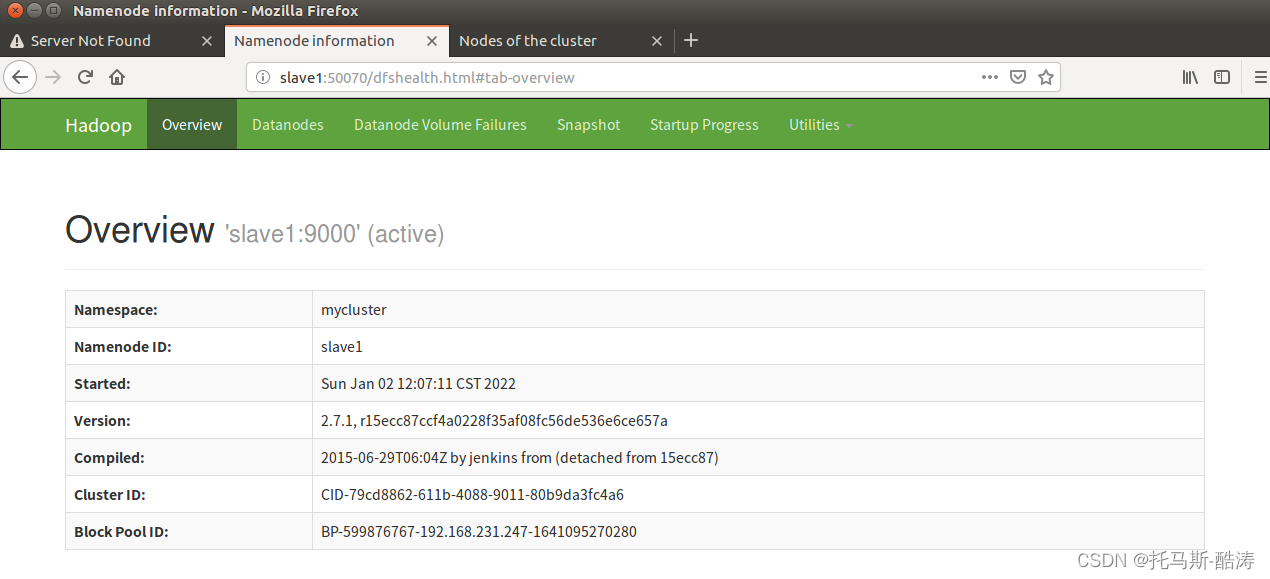
19、重新啟動master端的namenode程序,觀察工作狀態
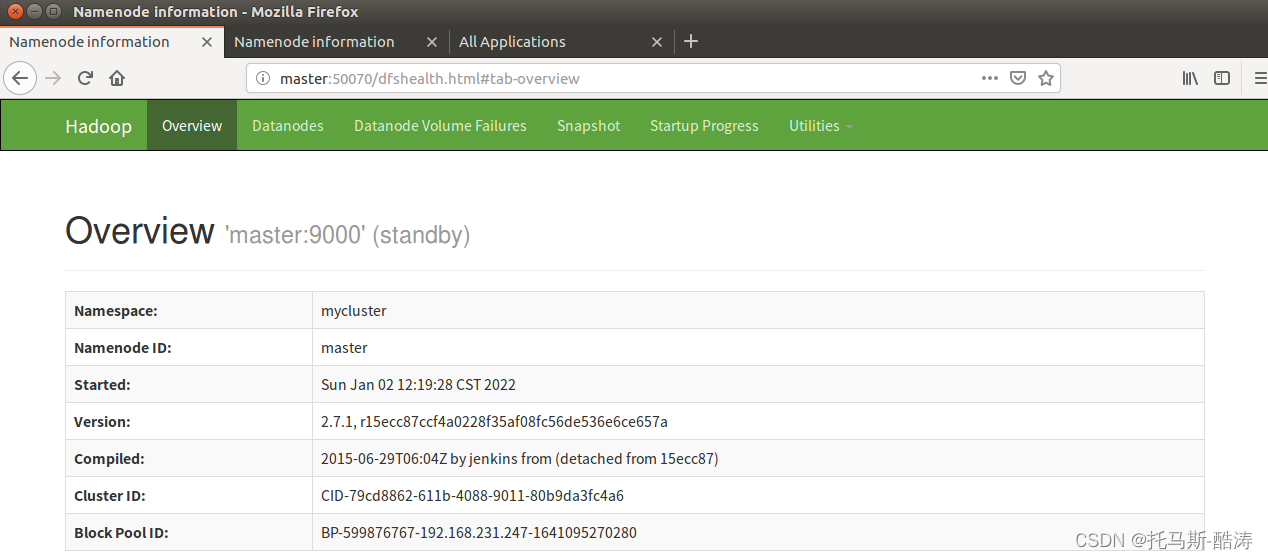
sbin/hadoop-daemon.sh start namenode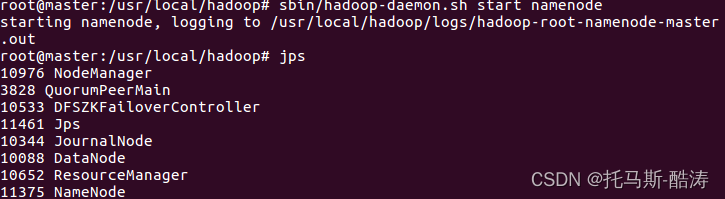
注:可見,在master重新恢復狀態後,slave依然為active狀態,master為備用狀態
連結參考
Centos搭建hadoopHA高可用![]() https://blog.csdn.net/m0_54925305/article/details/121566611?spm=1001.2014.3001.5502HadoopHA工作機制高可用理論
https://blog.csdn.net/m0_54925305/article/details/121566611?spm=1001.2014.3001.5502HadoopHA工作機制高可用理論![]() https://blog.csdn.net/m0_54925305/article/details/119838341?spm=1001.2014.3001.5502
https://blog.csdn.net/m0_54925305/article/details/119838341?spm=1001.2014.3001.5502
更多環境搭建參見主頁
托馬斯-酷濤的部落格主頁![]() https://blog.csdn.net/m0_54925305?type=blog
https://blog.csdn.net/m0_54925305?type=blog
每日一悟:將時間和精力投資於自己一定是一筆穩賺不賠的交易
--托馬斯