二萬字《演演算法和資料結構》三張動圖,三十張彩圖,C語言基礎教學,之 二元搜尋樹詳解 (建議收藏)
前言
我們知道,「 順序表 」 可以 「 快速索引 」 資料,而 「 連結串列 」 則可以快速的進行資料的「 插入 和 刪除 」。那麼,有沒有一種資料結構,可以快速的實現 「 增 」「 刪 」「 改 」「 查 」 呢?
本文,我們就來聊一下一種 「 樹形 」 的資料結構,它既有連結串列的快速插入與刪除的特點,又有順序錶快速查詢的優勢。它就是:
「 二元搜尋樹 」

二元樹的查詢
二元搜尋樹的刪除
二元搜尋樹的插入
點選我跳轉末尾 獲取 粉絲專屬 《演演算法和資料結構》原始碼。
一、二元樹的概念
在學習二元搜尋樹之前,我們首先需要了解下什麼是二元樹。
1、二元樹的性質
二元樹是一種樹,它有如下幾個特徵:
1)每個結點最多 2 棵子樹,即每個結點的孩子結點個數為 0、1、2;
2)這兩棵子樹是有順序的,分別叫:左子樹 和 右子樹;
3)如果只有一棵子樹的情況,也需要區分順序,如圖所示:

b
b
b 為
a
a
a 的左子樹;

c
c
c 為
a
a
a 的右子樹;
2、特殊二元樹
1)斜樹
所有結點都只有左子樹的二元樹被稱為左斜樹。

所有結點都只有右子樹的二元樹被稱為右斜樹。

斜樹有點類似線性表,所以線性表可以理解為一種特殊形式的樹。
2)滿二元樹
對於一棵二元樹,如果它的所有根結點和內部結點都存在左右子樹,且所有葉子結點都在同一層,這樣的樹就是滿二元樹。

滿二元樹有如下幾個特點:
1)葉子結點一定在最後一層;
2)非葉子結點的度為 2;
3)深度相同的二元樹,滿二元樹的結點個數最多,為
2
h
−
1
2^h-1
2h−1(其中
h
h
h 代表深度)。
3)完全二元樹
對一棵具有
n
n
n 個結點的二元樹按照層序進行編號,如果編號
i
i
i 的結點和同樣深度的滿二元樹中的編號
i
i
i 的結點在二元樹中位置完全相同,則被稱為 完全二元樹。

滿二元樹一定是完全二元樹,而完全二元樹則不一定是滿二元樹。
完全二元樹有如下幾個特點:
1)葉子結點只能出現在最下面兩層。
2)最下層的葉子結點一定是集中在左邊的連續位置;倒數第二層如果有葉子結點,一定集中在右邊的連續位置。
3)如果某個結點度為 1,則只有左子樹,即 不存在只有右子樹 的情況。
4)同樣結點數的二元樹,完全二元樹的深度最小。
如下圖所示,就不是一棵完全二元樹,因為 5 號結點沒有右子樹,但是 6 號結點是有左子樹的,不滿足上述第 2 點。

3、二元樹的性質
接下來我們來看下,二元樹有哪些重要的性質。
1)性質1
【性質1】二元樹的第 i ( i ≥ 1 ) i (i \ge 1) i(i≥1) 層上至多有 2 i − 1 2^{i-1} 2i−1 個結點。
既然是至多,就只需要考慮滿二元樹的情況,對於滿二元樹而言,當前層的結點數是上一層的兩倍,第一層的結點數為 1,所以第 i i i 的結點數可以通過等比數列公式計算出來,為 2 i − 1 2^{i-1} 2i−1。
2)性質2
【性質2】深度為 h h h 的二元樹至多有 2 h − 1 2^{h}-1 2h−1 個結點。
對於任意一個深度為
h
h
h 的二元樹,滿二元樹的結點數一定是最多的,所以我們可以拿滿二元樹進行計算,它的每一層的結點數為
1
1
1、
2
2
2、
4
4
4、
8
8
8、…、
2
h
−
1
2^{h-1}
2h−1。
利用等比數列求和公式,得到總的結點數為:
1
+
2
+
4
+
.
.
.
+
2
h
−
1
=
2
h
−
1
1 + 2 + 4 + ... + 2^{h-1} = 2^h - 1
1+2+4+...+2h−1=2h−1
3)性質3
【性質3】對於任意一棵二元樹 T T T,如果葉子結點數為 x 0 x_0 x0,度為 2 的結點數為 x 2 x_2 x2,則 x 0 = x 2 + 1 x_0 = x_2 + 1 x0=x2+1
令
x
1
x_1
x1 代表度 為 1 的結點數,總的結點數為
n
n
n,則有:
n
=
x
0
+
x
1
+
x
2
n = x_0 + x_1 + x_2
n=x0+x1+x2
任意一個結點到它孩子結點的連線我們稱為這棵樹的一條邊,對於任意一個非空樹而言,邊數等於結點數減一,令邊數為
e
e
e,則有:
e
=
n
−
1
e = n-1
e=n−1

對於度為 1 的結點,可以提供 1 條邊,如圖中的黃色結點;對於度為 2 的結點,可以提供 2 條邊,如圖中的紅色結點。所以邊數又可以通過度為 1 和 2 的結點數計算得出:
e
=
x
1
+
2
x
2
e = x_1 + 2 x_2
e=x1+2x2 聯立上述三個等式,得到:
e
=
n
−
1
=
x
0
+
x
1
+
x
2
−
1
=
x
1
+
2
x
2
e = n-1 = x_0+x_1+x_2 - 1 = x_1 + 2 x_2
e=n−1=x0+x1+x2−1=x1+2x2 化簡後,得證:
x
0
=
x
2
+
1
x_0 = x_2 + 1
x0=x2+1
4)性質4
【性質4】具有 n n n 個結點的完全二元樹的深度為 ⌊ l o g 2 n ⌋ + 1 \lfloor log_2n \rfloor + 1 ⌊log2n⌋+1。
由【性質2】可得,深度為
h
h
h 的二元樹至多有
2
h
−
1
2^{h}-1
2h−1 個結點。所以,假設一棵樹的深度為
h
h
h,它的結點數為
n
n
n,則必然滿足:
n
≤
2
h
−
1
n \le 2^{h}-1
n≤2h−1 由於是完全二元樹,它一定比深度為
h
−
1
h-1
h−1 的結點數要多,即:
2
h
−
1
−
1
<
n
2^{h-1}-1 \lt n
2h−1−1<n 將上述兩個不等式,稍加整理,得到:
2
h
−
1
≤
n
<
2
h
2^{h-1} \le n \lt 2^h
2h−1≤n<2h 然後,對不等式兩邊取以2為底的對數,得到:
h
−
1
≤
l
o
g
2
n
<
h
h-1 \le log_2n \lt h
h−1≤log2n<h 這裡,由於
h
h
h 一定是整數,所以有:
h
=
⌊
l
o
g
2
n
⌋
+
1
h = \lfloor log_2n \rfloor + 1
h=⌊log2n⌋+1
二、二元樹的儲存
1、順序表儲存
二元樹的順序儲存就是指利用陣列對二元樹進行儲存。結點的儲存位置即陣列下標,能夠體現結點之間的邏輯關係,比如父結點和孩子結點之間的關係,左右兄弟結點之間的關係 等等。
1)完全二元樹
來看一棵完全二元樹,我們對它進行如下儲存。

編號代表了陣列下標的絕對位置,對映後如下:
| 下標 | 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 | 11 | 12 |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| d a t a data data | − - − | a a a | b b b | c c c | d d d | e e e | f f f | g g g | h h h | i i i | j j j | k k k | l l l |
這裡為了方便,我們把陣列下標為 0 的位置給留空了。這樣一來,當知道某個結點的下標 x x x,就可以知道它左右兒子的下標分別為 2 x 2x 2x 和 2 x + 1 2x+1 2x+1;反之,當知道某個結點的下標 x x x,也能知道它父結點的下標為 ⌊ x 2 ⌋ \lfloor \frac x 2 \rfloor ⌊2x⌋。
2)非完全二元樹
對於非完全二元樹,只需要將對應不存在的結點設定為空即可。

編號代表了陣列下標的絕對位置,對映後如下:
| 下標 | 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 | 11 | 12 |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| d a t a data data | − - − | a a a | b b b | c c c | d d d | e e e | f f f | g g g | − - − | − - − | − - − | k k k | l l l |
3)稀疏二元樹
對於較為稀疏的二元樹,就會有如下情況出現,這時候如果用這種方式進行儲存,就比較浪費記憶體了。

編號代表了陣列下標的絕對位置,對映後如下:
| 下標 | 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 | 11 | 12 |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| d a t a data data | − - − | a a a | b b b | c c c | d d d | − - − | − - − | g g g | h h h | − - − | − - − | − - − | − - − |
於是,我們可以採取連結串列進行儲存。
2、連結串列儲存
二元樹每個結點至多有兩個孩子結點,所以對於每個結點,設定一個 資料域 和 兩個 指標域 即可,指標域 分別指向 左孩子結點 和 右孩子結點。
typedef struct TreeNode {
DataType data;
struct TreeNode *left; // (1)
struct TreeNode *right; // (2)
}TreeNode;
-
(
1
)
(1)
(1)
left指向左孩子結點; -
(
2
)
(2)
(2)
right指向右孩子結點;

三、二元樹的遍歷
二元樹的遍歷是指從根結點出發,按照某種次序依次存取二元樹中的所有結點,使得每個結點存取一次且僅被存取一次。
對於線性表的遍歷,要麼從頭到尾,要麼從尾到頭,遍歷方式較為單純,但是樹不一樣,它的每個結點都有可能有兩個孩子結點,所以遍歷的順序面臨著不同的選擇。
二元樹的常用遍歷方法有以下四種:前序遍歷、中序遍歷、後序遍歷、層序遍歷。
我們用 void visit(TreeNode *root)這個函數代表存取某個結點,這裡為了簡化問題,存取結點的過程就是列印對應資料域的過程。如下程式碼所示:
void visit(TreeNode *root) {
printf("%c", root->data);
}
1、 前序遍歷
1)演演算法描述
【前序遍歷】如果二元樹為空,則直接返回。否則,先存取根結點,再遞迴前序遍歷左子樹,再遞迴前序遍歷右子樹。
前序遍歷的結果如下: a b d g h c e f i abdghcefi abdghcefi。

2)原始碼詳解
void preorder(TreeNode *root) {
if(root == NULL) {
return ; // (1)
}
visit(root); // (2)
preorder(root->left); // (3)
preorder(root->right); // (4)
}
- ( 1 ) (1) (1) 待存取結點為空時,直接返回;
- ( 2 ) (2) (2) 先存取當前樹的根;
- ( 3 ) (3) (3) 再前序遍歷左子樹;
- ( 4 ) (4) (4) 最後前序遍歷右子樹;
2、 中序遍歷
1)演演算法描述
【中序遍歷】如果二元樹為空,則直接返回。否則,先遞迴中序遍歷左子樹,再存取根結點,再遞迴中序遍歷右子樹。
中序遍歷的結果如下: g d h b a e c i f gdhbaecif gdhbaecif。
2)原始碼詳解
void inorder(TreeNode *root) {
if(root == NULL) {
return ; // (1)
}
inorder(root->left); // (2)
visit(root); // (3)
inorder(root->right); // (4)
}
- ( 1 ) (1) (1) 待存取結點為空時,直接返回;
- ( 2 ) (2) (2) 先中序遍歷左子樹;
- ( 3 ) (3) (3) 再存取當前樹的根;
- ( 4 ) (4) (4) 最後中序遍歷右子樹;
3、 後序遍歷
1)演演算法描述
【後序遍歷】如果二元樹為空,則直接返回。否則,先遞迴後遍歷左子樹,再遞迴後序遍歷右子樹,再存取根結點。
後序遍歷的結果如下: g h d b e i f c a ghdbeifca ghdbeifca。

2)原始碼詳解
void postorder(TreeNode *root) {
if(root == NULL) {
return ; // (1)
}
postorder(root->left); // (2)
postorder(root->right); // (3)
visit(root); // (4)
}
- ( 1 ) (1) (1) 待存取結點為空時,直接返回;
- ( 2 ) (2) (2) 先後序遍歷左子樹;
- ( 3 ) (3) (3) 再後序遍歷右子樹;
- ( 4 ) (4) (4) 再存取當前樹的根;
四、二元搜尋樹的概念
1、定義
二元搜尋樹,又稱為二叉排序樹,二叉查詢樹,它滿足如下四點性質:
1)空樹是二元搜尋樹;
2)若它的左子樹不為空,則左子樹上所有結點的值均小於它根結點的值;
3)若它的右子樹不為空,則右子樹上所有結點的值均大於它根結點的值;
4)它的左右子樹均為二元搜尋樹;

如圖所示,對於任何一棵子樹而言,它的根結點的值一定大於左子樹所有結點的值,且一定小於右子樹所有結點的值。
2、用途
從二元搜尋樹的定義可知,它的前提是二元樹,並且採用了遞迴的方式進行定義,它的結點間滿足一個偏序關係,左子樹根結點的值一定比父結點小,右子樹根結點的值一定比父結點大。
正如它的名字所說,構造這樣一棵樹的目的是為了提高搜尋的速度,如果對二元搜尋樹進行中序遍歷,我們可以發現,得到的序列是一個遞增序列。

3、資料結構
我們用孩子表示法來定義一棵二元搜尋樹的結點。如下:
struct TreeNode {
int val; // (1)
struct TreeNode *left; // (2)
struct TreeNode *right; // (3)
};
- ( 1 ) (1) (1) 二元搜尋樹結點的值,注意,這裡的型別其實可以是任意型別,只要這種型別支援 關係運算子 的比較即可,本文為了把問題簡單話,一律採用整數進行講解。
-
(
2
)
(2)
(2) 二元搜尋樹結點的左兒子結點的指標,沒有左兒子結點時,值為
NULL; -
(
3
)
(3)
(3) 二元搜尋樹結點的右兒子結點的指標,沒有右兒子結點時,置為
NULL;
4、結點建立
結點建立就是給結點分配一塊記憶體,並且填充它的資料域和指標域,然後返回這個結點。C語言實現如下:
struct TreeNode* createNode(int val) {
struct TreeNode* node = (struct TreeNode*) malloc( sizeof(struct TreeNode) );
node->val = val;
node->left = NULL;
node->right = NULL;
return node;
}
五、二元搜尋樹的操作
1、查詢
二元搜尋樹的查詢指的是:在樹上查詢某個數是否存在,存在返回true,不存在返回false。
1)演演算法原理
對於要查詢的數val,從根結點出發,總共四種情況依次判斷:
1)若為空樹,直接返回false;
2)val的值 等於 樹根結點的值,則直接返回true;
3)val的值 小於 樹根結點的值,說明val對應的結點不在根結點,也不在右子樹上,則遞迴返回左子樹的 查詢 結果;
4)val的值 大於 樹根結點的值,說明val對應的結點不在根結點,也不在左子樹上,則遞迴返回右子樹的 查詢 結果;
2)動圖演示
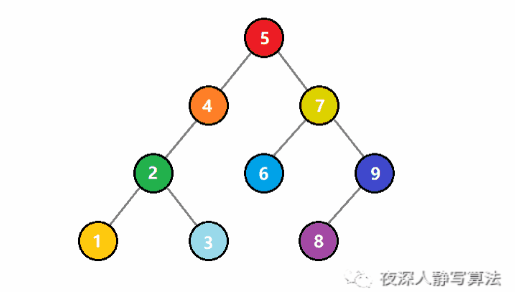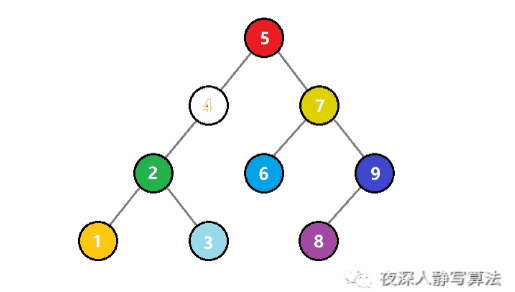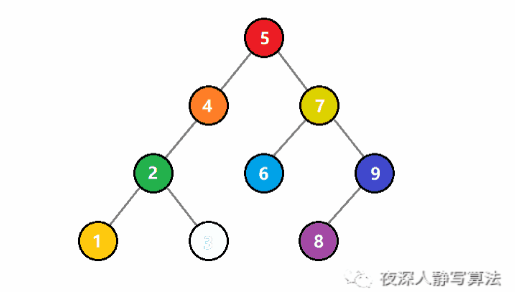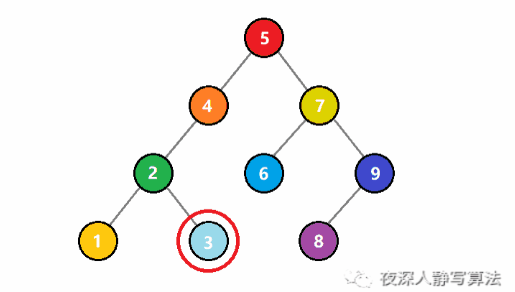
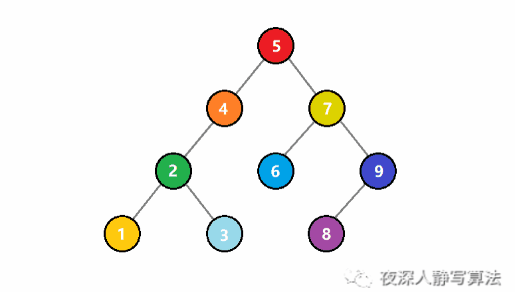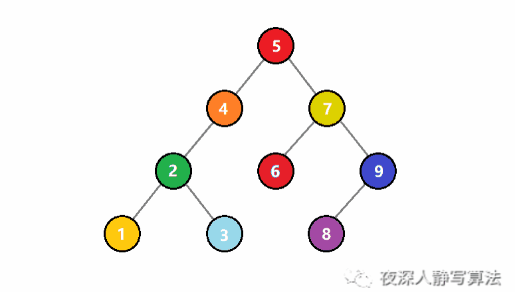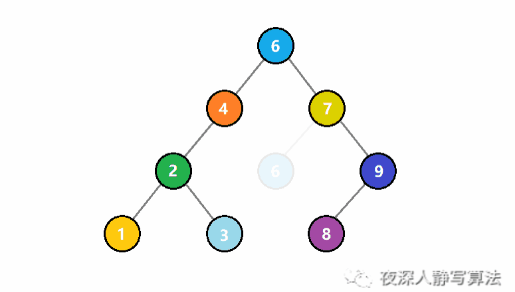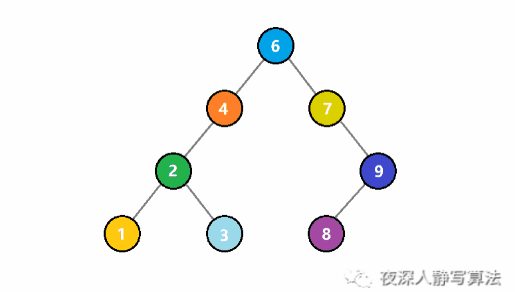
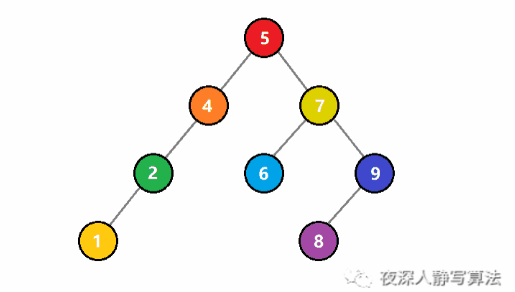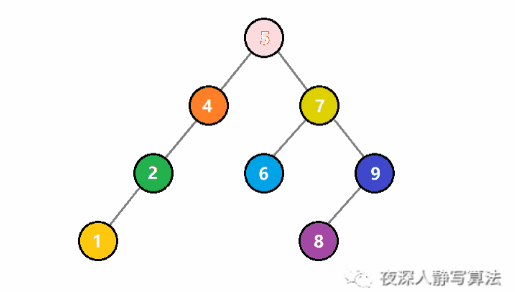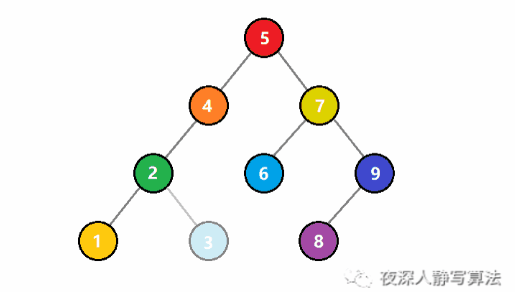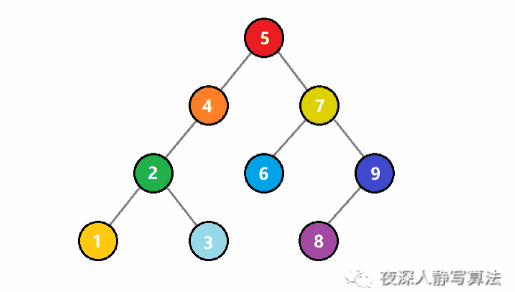
如圖所示,代表的是從一個二元搜尋樹中查詢一個值為 3 的結點。一開始, 3 比根結點 5 小,於是遞迴存取左子樹;還是比子樹的根結點 4 小,於是繼續遞迴存取左子樹;這時候比根結點 2 大,於是遞迴存取右子樹,正好找到值為 3 的結點,回溯結束查詢。

3)原始碼詳解
bool BSTFind(struct TreeNode* root, int val) { // (1)
if(root == NULL) {
return false; // (2)
}
if(root->val == val) {
return true; // (3)
}
if(val < root->val) {
return BSTFind(root->left, val); // (4)
}else {
return BSTFind(root->right, val); // (5)
}
}
-
(
1
)
(1)
(1)
BSTFind這個函數用於查詢以now為根結點的樹中是否存在值為val這個結點; -
(
2
)
(2)
(2) 空樹是不可能存在值為
val的結點的,直接返回false; -
(
3
)
(3)
(3) 一旦發現有值為
val的結點,直接返回true; -
(
4
)
(4)
(4)
val的值 小於 樹根結點的值,說明val對應的結點不在根結點,也不在右子樹上,則遞迴返回左子樹的 查詢 結果; -
(
5
)
(5)
(5)
val的值 大於 樹根結點的值,說明val對應的結點不在根結點,也不在左子樹上,則遞迴返回右子樹的 查詢 結果;
2、插入
二元搜尋樹的插入指的是:將給定的值生成結點後,插入到樹上的某個位置,並且保持這棵樹還是二元搜尋樹。
1)演演算法原理
對於要插入的數val,從根結點出發,總共四種情況依次判斷:
1)若為空樹,則建立一個值為val的結點並且返回;
2)val的值 等於 樹根結點的值,無須執行插入,直接返回根結點;
3)val的值 小於 樹根結點的值,那麼插入位置一定在 左子樹,遞迴執行插入左子樹的過程,並且返回插入結果作為新的左子樹;
4)val的值 大於 樹根結點的值,那麼插入位置一定在 右子樹,遞迴執行插入右子樹的過程,並且返回插入結果作為新的右子樹;
2)動圖演示
如圖所示,代表的是將一個值為 3 的結點插入到一個二元搜尋樹中。一開始, 3 比根結點 5 小,於是遞迴插入左子樹;還是比子樹的根結點 4 小,於是繼續遞迴插入左子樹;這時候比根結點 2 大,於是遞迴插入右子樹,右子樹為空,則直接生成一個值為 3 的結點,回溯結束插入。

3)原始碼詳解
struct TreeNode* BSTInsert(struct TreeNode* root, int val){ // (1)
if(root == NULL) {
return createNode(val); // (2)
}
if(val == root->val) {
return root; // (3)
}
if(val < root->val) { // (4)
root->left = BSTInsert(root->left, val);
}else { // (5)
root->right = BSTInsert(root->right, val);
}
return root;
}
-
(
1
)
(1)
(1)
BSTInsert函數用於將值為val的結點插入到以root為根結點的子樹中; -
(
2
)
(2)
(2) 如果是空樹,則建立一個值為
val的結點並且返回; -
(
3
)
(3)
(3)
val的值 等於 樹根結點的值,無須執行插入,直接返回根結點; -
(
4
)
(4)
(4)
val的值 小於 樹根結點的值,那麼插入位置一定在 左子樹,遞迴執行插入左子樹的過程,並且返回插入結果作為新的左子樹; -
(
5
)
(5)
(5)
val的值 大於 樹根結點的值,那麼插入位置一定在 右子樹,遞迴執行插入右子樹的過程,並且返回插入結果作為新的右子樹;
3、刪除
二元搜尋樹的刪除指的是:在樹上刪除給定值的結點。
1)演演算法原理
刪除值為val的結點的過程,從根結點出發,總共四種情況依次判斷:
1)空樹,不存在結點直接返回空樹;
2)val的值 小於 樹根結點的值,則需要刪除的結點一定不在右子樹上,遞迴呼叫刪除左子樹的對應結點;
3)val的值 大於 樹根結點的值,則需要刪除的結點一定不在左子樹上,遞迴呼叫刪除右子樹的對應結點;
4)val的值 等於 樹根結點的值,相當於是要刪除根結點,這時候又要分三種情況:
4.1)當前樹只有左子樹,則直接將左子樹返回,並且釋放當前樹根結點的空間;
4.2)當前樹只有右子樹,則直接將右子樹返回,並且釋放當前樹根結點的空間;
4.3)當左右子樹都存在時,需要在右子樹上找到一個值最小的結點,替換新的樹根,而其它結點組成的樹作為它的子樹,並且在子樹中刪掉這個最小的結點,而這一步刪除的過程正是繼續遞迴呼叫結點刪除的過程;
2)動圖演示
如圖所示,下圖展示的是,從這棵樹刪除根結點 5 的過程。首先,由於它有左右兒子結點,所以這個過程,根結點並不是真正的刪除。而是從右子樹中找到最小的結點 6,替換根結點,並且從根結點為 7 的子樹中刪除 6 的過程。由於 6 沒有子結點所以這個過程就直接結束了。

3)原始碼詳解
3.1)介面簡介
在介紹二元搜尋樹的結點刪除演演算法前,我們首先需要知道以下四個介面:
int BSTFindMin(struct TreeNode* root); // (2)
struct TreeNode* BSTDelete(struct TreeNode* root, int val); // (3)
struct TreeNode* Delete(struct TreeNode* root); // (4)
-
(
1
)
(1)
(1)
BSTFindMin:查詢root為根的樹中,值最小的那個結點的值,根據二元搜尋樹的性質,如果左子樹存在,則必然存在更小的值,遞迴搜尋左子樹;如果左子樹不存在,則根結點的值必然最小,直接返回,具體實現見下文; -
(
2
)
(2)
(2)
BSTDelete:在root為根的樹中,刪除值為val的結點,是我們需要實現的刪除介面,具體實現見下文; -
(
3
)
(3)
(3)
Delete:在root為根的樹中,將根結點刪除,並且使得剩下的樹還是二元搜尋樹,具體實現見下文;
3.2)查詢最小結點
int BSTFindMin(struct TreeNode* root) {
if(root->left)
return BSTFindMin(root->left); // (1)
return root->val; // (2)
}
- ( 1 ) (1) (1) 如果左子樹存在,則遞迴呼叫左子樹的查詢最小結點介面;
- ( 2 ) (2) (2) 如果左子樹不存在,則當前根結點的值一定是最小的,直接返回介面;
3.3)刪除給定結點
struct TreeNode* BSTDelete(struct TreeNode* root, int val){
if(NULL == root) {
return NULL; // (1)
}
if(val == root->val) {
return Delete(root); // (2)
}
else if(val < root->val) {
root->left = BSTDelete(root->left, val); // (3)
}else if(val > root->val) {
root->right = BSTDelete(root->right, val); // (4)
}
return root; // (5)
}
- ( 1 ) (1) (1) 如果為空樹,則直接返回空結點;
-
(
2
)
(2)
(2) 如果需要刪除的結點,是這棵樹的根結點,則直接呼叫介面
Delete,下文會介紹它的實現; - ( 3 ) (3) (3) 如果需要刪除的結點的值 小於 樹根結點的值,則需要刪除的結點必定在左子樹上,遞迴呼叫左子樹的刪除,並且將返回值作為新的左子樹的根結點;
- ( 4 ) (4) (4) 如果需要刪除的結點的值 大於 樹根結點的值,則需要刪除的結點必定在右子樹上,遞迴呼叫右子樹的刪除,並且將返回值作為新的右子樹的根結點;
- ( 5 ) (5) (5) 最後,返回當前樹的根結點;
3.4)刪除給定二元搜尋樹的根結點,並且返回新的樹根
struct TreeNode* Delete(struct TreeNode* root) {
struct TreeNode *delNode, *retNode;
if(root->left == NULL) { // (1)
delNode = root, retNode = root->right, free(delNode);
}else if(root->right == NULL) { // (2)
delNode = root, retNode = root->left, free(delNode);
}else { // (3)
retNode = (struct TreeNode*) malloc (sizeof(struct TreeNode));
retNode->val = BSTFindMin(root->right);
retNode->right = BSTDelete(root->right, retNode->val);
retNode->left = root->left;
}
return retNode;
}
- ( 1 ) (1) (1) 如果左子樹為空,則用右子樹做為新的樹根;
- ( 2 ) (2) (2) 如果右子樹為空,則用左子樹作為新的樹根;
-
(
3
)
(3)
(3) 否則,當左右子樹都為非空時,利用
BSTFindMin,從右子樹上找出最小的結點,作為新的根,並且在右子樹中刪除對應的結點,刪除過程就是遞迴呼叫BSTDelete的過程;
4、構造
二元搜尋樹的構造就是:給定一個陣列序列,構造出一個棵二元搜尋樹。
1)演演算法原理
原理比較簡單,一開始是一棵空樹,然後遍歷陣列,對每個元素生成一個結點,不斷執行插入操作,並且返回新的樹根,就完成了構造的過程。
2)原始碼詳解
struct TreeNode* BSTConstruct(int *vals, int valSize) {
int i;
struct TreeNode* root = NULL; // (1)
for(i = 0; i < valSize; ++i) {
root = BSTInsert(root, vals[i]); // (2)
}
return root;
}
- ( 1 ) (1) (1) 初始化空樹;
- ( 2 ) (2) (2) 根據陣列給定順序執行插入樹的操作;
插入過程需要明確一點,就是如果給定的陣列是嚴格遞增,或者嚴格遞減,就會導致每次插入都要遍歷樹的所有結點,這樣就使得整個插入過程的時間複雜度變成了
O
(
n
2
)
O(n^2)
O(n2),改善的方法有幾種:
方法1:隨機將陣列打亂順序,再執行插入;
方法2:每次插入後,變換成平衡樹,對於平衡樹相關內容,下篇文章會詳細講解;
六、二元搜尋樹的遍歷
1、先序遍歷
給定一個某個二元搜尋樹的先序遍歷序列,構造出一棵二元搜尋樹,方法如下:
1)首先,考慮先序遍歷的特點:先存取根結點,再依次存取左右子樹;所以,第一個結點一定是根結點;
2)然後,陣列往後遍歷的過程中,遇到的所有小於當前根結點的結點,都必然是左子樹上的結點,後面的結點必然是右子樹的(當然,如果檢測到後面的結點有比這個根結點小的,則這個序列無法構造出一棵二元搜尋樹);
3)遍歷找到左右子樹的分界點後,就可以進行左右子樹遞迴計算了,注意遞迴時返回構造完的子樹的根結點。
2、中序遍歷
二元搜尋樹的中序遍歷是最常用的,一棵二元搜尋樹的中序遍歷是一個遞增序列。
遞增序列是存在單調性的,所以可以利用這個特性,在有效的時間內找出這棵樹的第
k
k
k 大結點。
3、後序遍歷
給定一個整數陣列,判斷該陣列是不是某二元搜尋樹的後序遍歷結果,方法如下:
1)從後序遍歷的定義出發,先左子樹,再右子樹,最後根結點。所以,這個序列的最後一個元素,一定是根結點,且所有小於它的元素作為左子樹,所有大於它的元素作為右子樹。
2)如果能夠分成這樣兩部分,則遞迴計算左右子樹;
3)否則,在出現第一個大於 最後一個元素的情況下,又出現小於 最後一個元素的情況,則表示這是一種非法情況,直接返回false。
七、二元搜尋樹的總結
縱觀二元搜尋樹的查詢、插入 和 刪除。完全取決於二元搜尋樹的形狀,如果是完全二元樹或者接近完全二元樹,則這三個過程都是
O
(
l
o
g
2
n
)
O(log_2n)
O(log2n) 的,如果是斜樹,則三個過程近似操作線性表,為
O
(
n
)
O(n)
O(n)。


有關 🌳 二元搜尋樹 🌳 的的內容到這裡就完全結束了,如果還有什麼疑問,可以新增作者微信諮詢。
有關🌳《畫解資料結構》🌳 的原始碼均開源,連結如下:《畫解資料結構》

相信看我文章的大多數都是「 大學生 」,能上大學的都是「 精英 」,那麼我們自然要「 精益求精 」,如果你還是「 大一 」,那麼太好了,你擁有大把時間,當然你可以選擇「 刷劇 」,然而,「 學好演演算法 」,三年後的你自然「 不能同日而語 」。
那麼這裡,我整理了「 幾十個基礎演演算法 」 的分類,點選開啟:
如果連結被遮蔽,或者有許可權問題,可以私聊作者解決。
大致題集一覽:







為了讓這件事情變得有趣,以及「 照顧初學者 」,目前題目只開放最簡單的演演算法 「 列舉系列 」 (包括:線性列舉、雙指標、字首和、二分列舉、三分列舉),當有 一半成員刷完 「 列舉系列 」 的所有題以後,會開放下個章節,等這套題全部刷完,你還在群裡,那麼你就會成為「 夜深人靜寫演演算法 」專家團 的一員。
不要小看這個專家團,三年之後,你將會是別人 望塵莫及 的存在。如果要加入,可以聯絡我,考慮到大家都是學生, 沒有「 主要經濟來源 」,在你成為神的路上,「 不會索取任何 」。
🔥讓天下沒有難學的演演算法🔥
C語言免費動漫教學,和我一起打卡! 🌞《光天化日學C語言》🌞
入門級C語言真題彙總 🧡《C語言入門100例》🧡
幾張動圖學會一種資料結構 🌳《畫解資料結構》🌳
組團學習,抱團生長 🌌《演演算法入門指引》🌌
競賽選手金典圖文教學 💜《夜深人靜寫演演算法》💜 這篇文章的主要目的是講解二元搜尋樹的一些基礎概念,以及和二元搜尋樹相關的一些經典演演算法。但是實際學習過程還是需要看個人的毅力和堅持。下圖代表的是 LeetCode 經典的二元搜尋樹的題集,其中樹是很重要的一個章節,涉及了諸多演演算法,希望可以供讀者參考和學習。

粉絲專屬福利
語言入門:《光天化日學C語言》(範例程式碼)
語言訓練:《C語言入門100例》試用版
資料結構:《畫解資料結構》原始碼
演演算法入門:《演演算法入門》指引
演演算法進階:《夜深人靜寫演演算法》演演算法模板