計算機網路面試題彙總
文章目錄
- TCP/IP體系結構
- 五層模型的作用 : (位元組跳動)
- TCP、UDP的區別
- 如何在應用層保證udp可靠傳輸
- TCP流量控制
- TCP擁塞控制
- TCP的三次握手過程
- TCP的四次揮手過程
- tcp [keep]()alive實現原理
- tcp三次握手四次揮手過程及各個狀態
- SYN攻擊是什麼?
- TCP建立連線過程中,第三次握手seq=1000,ack=2000.問第二次握手seq和ack分別為多少?
- tcp粘包
- XSS(Cross Site Scripting) 跨域指令碼攻擊
- CSRF(Cross-Site Request Forgery) 跨站請求偽造
- sql注入和防範(美團)
- HTTP/TCP/IP
- HTTP的報文結構
- HTTP與HTTPS的區別
- HTTP1.0 和 HTTP1.1之間的區別
- HTTP1.1 和 HTTP2.0之間的區別
- HTTP的請求
- HTTP常見的狀態碼
- 請求轉發(Redirect)和重定向(Forward)之間的區別
- RPC和HTTP的區別
- Socket是什麼?
- Socket中的time-wait狀態多,如何解決
- TIME_WAIT的作用 :
- 為什麼TIME_WAIT 狀態需要保持2MSL這麼長的時間?
- 程序和執行緒有什麼關係與區別(美團)
- 程序間的通訊方式有哪些?(美團)
- 輸入一個網址,執行過程是怎樣的
- 輸入一個網址之後會發生什麼,用到了哪些協定
- 網路間兩個主機通訊過程,用到了哪些裝置
- ARP協定和ARP攻擊
- ICMP協定
- 路由器和交換機的區別
- cdn (網易雲音樂)(位元組)
- Nginx反向代理
- 其他計算機網路問題
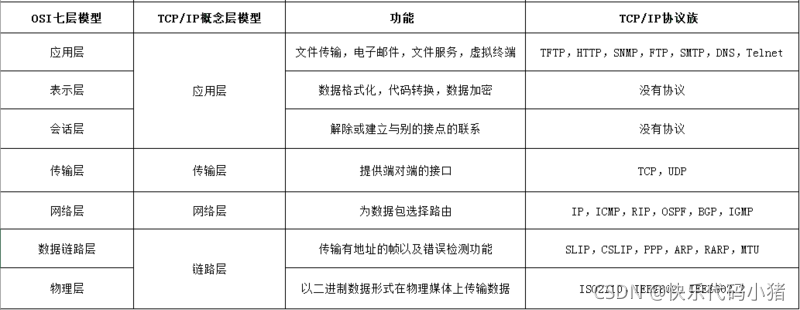
TCP/IP體系結構
1. TCP/IP的四層模型指的是哪些?
TCP/IP按照層次劃分,可以分為以下四層 :
①網路介面層:對應物理層和資料鏈路層
②網路層
③傳輸層
④應用層:包括對談層、表示層、應用層
各層舉例如下表所示:
| 網路介面層 | 控制作業系統,硬體裝置驅動.網路介面卡等等硬體裝置 |
|---|---|
| 網路層 | IP |
| 傳輸層 | TCP(傳輸控制協定),UDP(使用者資料包協定) |
| 應用層 | FTP(檔案傳輸協定),DNS(域名系統),HTTP(超文字傳輸協定) |
2. OSI的七層模型
- 物理層:在物理通道上實現原始位元流的傳輸。(乙太網, IEEE 802.2 等)
- 資料鏈路層:實現無差錯地將資料框(將網路層的資料封裝成資料框,便於物理層傳輸)從一個節點傳送到下一個相鄰節點。(Wi-Fi(IEEE 802.11) , WiMAX(IEEE 802.16), GPRS, HDLC, PPP 等協定)
- 網路層:實現將資料分組從源站通過網路傳送到目的站,即網路上一臺主機與另一臺主機之間的資料傳輸。(IP, ICMP, IGMP, ARP, RARP, OSPF 等協定)
- 傳輸層:實現源端到目的端資料的傳輸,即某主機的某程序與另一臺主機的某程序之間的資料傳輸。(TCP, UDP 等協定)
- 對談層:實現在不同機器上使用者建立、維護和終止對談關係。即對談層對對談提供控制管理服務、對談同步服務等。(ZIP, ASP, SSH 等協定)
- 表示層:確保各種通訊裝置能夠互相操作,不及考慮其資料的內部表示。即確保即使各種通訊裝置其資料的內部表示不同,但仍然能相互正確操作。(SSL等協定)
- 應用層:使使用者能夠存取網路,為各類應用提供相應的服務、提供各種使用者介面支援服務。應用層不是應用程式,應用層是一個為應用程式提供各類應用支援的服務層。(HTTP, FTP, SMTP, POP3, DHCP, DNS等協定)
五層模型的作用 : (位元組跳動)
物理層 : 在物理通道中實現原始的位元流的傳輸(物理層協定例如乙太網,IEEE 808.2等等)
資料鏈路層 : 實現將資料框(將網路層的資料封裝成資料框),從一個節點傳送到另一個節點
網路層 : 實現將資料分組從源站通過網路傳送到目的站,即我們說的網路上一臺主機與另一臺主機的資料傳輸,其中IP,ARP協定即為網路層協定
傳輸層 : 實現源端到目的端資料的傳輸,即某主機的某個程序與另一個主機的某一個程序之間的資料傳輸,TCP,UDP
應用層 : 是使用者能夠存取網路,為各類應用提供相應的服務,提供各種使用者介面支援服務
在七層模型中,還多出來了兩層 :
表示層 : 確保各種通訊裝置能夠互相操作,不及考慮其資料的內部表示。即確保即使各種通訊裝置其資料的內部表示不同,但仍然能相互正確操作。(SSL等協定)
對談層:實現在不同機器上使用者建立、維護和終止對談關係。即對談層對對談提供控制管理服務、對談同步服務等。(ZIP, ASP, SSH 等協定)
TCP、UDP的區別
TCP和UDP是TCP/IP體系結構運輸層中的兩個重要協定
TCP(Transmission Control Protocol):傳輸控制協定
UDP(User Datagram Protocol):使用者資料包協定
(1)TCP:面向有連線,可靠的,速度慢,效率低。
(2)UDP:面向無連線, 不可靠,速度快,效率高。
當程序需要傳輸可靠的資料時應使用TCP,當程序需要高效傳輸資料,可以忽略可靠性時應使用UDP協定
[外連圖片轉存失敗,源站可能有防盜鏈機制,建議將圖片儲存下來直接上傳(img-2M2v5aZL-1632465301638)(.\imgs\TCP和UDP的區別.jpg)]
注意 : UDP的不可靠性就在於它的面向無連線的,不需要建立連線,就可以傳送資料,即UDP只會把想發的資料包文一股腦的丟給對方,並不在意資料有無安全完整到達.
[外連圖片轉存失敗,源站可能有防盜鏈機制,建議將圖片儲存下來直接上傳(img-adxLq68d-1632465301641)(.\imgs\UDP.gif)]
如何在應用層保證udp可靠傳輸
因為udp是面向無連線的,不能保證傳輸的可靠性,此時我們只能在應用層實現可靠傳輸
目前有如下開源程式利用udp實現了可靠的資料傳輸。分別為RUDP、RTP、UDT
RUDP
RUDP 提供一組資料服務品質增強機制,如擁塞控制的改進、重發機制及淡化伺服器演演算法等,從而在包丟失和網路擁塞的情況下, RTP 客戶機(實時位置)面前呈現的就是一個高品質的 RTP 流。在不干擾協定的實時特性的同時,可靠 UDP 的擁塞控制機制允許 TCP 方式下的流控制行為。
RTP
實時傳輸協定(RTP)為資料提供了具有實時特徵的端對端傳送服務,如在組播或單播網路服務下的互動式視訊音訊或模擬資料。應用程式通常在 UDP 上執行 RTP 以便使用其多路結點和校驗服務;這兩種協定都提供了傳輸層協定的功能。但是 RTP 可以與其它適合的底層網路或傳輸協定一起使用。如果底層網路提供組播方式,那麼 RTP 可以使用該組播表傳輸資料到多個目的地。
RTP 本身並沒有提供按時傳送機制或其它服務品質(QoS)保證,它依賴於底層服務去實現這一過程。 RTP 並不保證傳送或防止無序傳送,也不確定底層網路的可靠性。 RTP 實行有序傳送, RTP 中的序列號允許接收方重組傳送方的包序列,同時序列號也能用於決定適當的包位置,例如:在視訊解碼中,就不需要順序解碼。
UDT
基於UDP的資料傳輸協定(UDP-basedData Transfer Protocol,簡稱UDT)是一種網際網路資料傳輸協定。UDT的主要目的是支援高速廣域網上的海量資料傳輸,而網際網路上的標準資料傳輸協定TCP在高頻寬長距離網路上效能很差。顧名思義,UDT建於UDP之上,並引入新的擁塞控制和資料可靠性控制機制。UDT是面向連線的雙向的應用層協定。它同時支援可靠的資料流傳輸和部分可靠的資料包傳輸。由於UDT完全在UDP上實現,它也可以應用在除了高速資料傳輸之外的其它應用領域,例如點到點技術(P2P),防火牆穿透,多媒體資料傳輸等等
TCP流量控制
流量控制:讓傳送方的傳送速率不要太快,要讓接收方來得及接收
利用滑動視窗機制可以很方便地在TCP連線上實現對傳送方的流量控制
假設A傳送的每個TCP資料包文段可攜帶100位元組資料;
在A和B建立連線時,B告訴A:我的接收視窗為400;
於是,A將自己的傳送視窗也設定為400,也就是能傳送1-400的資料
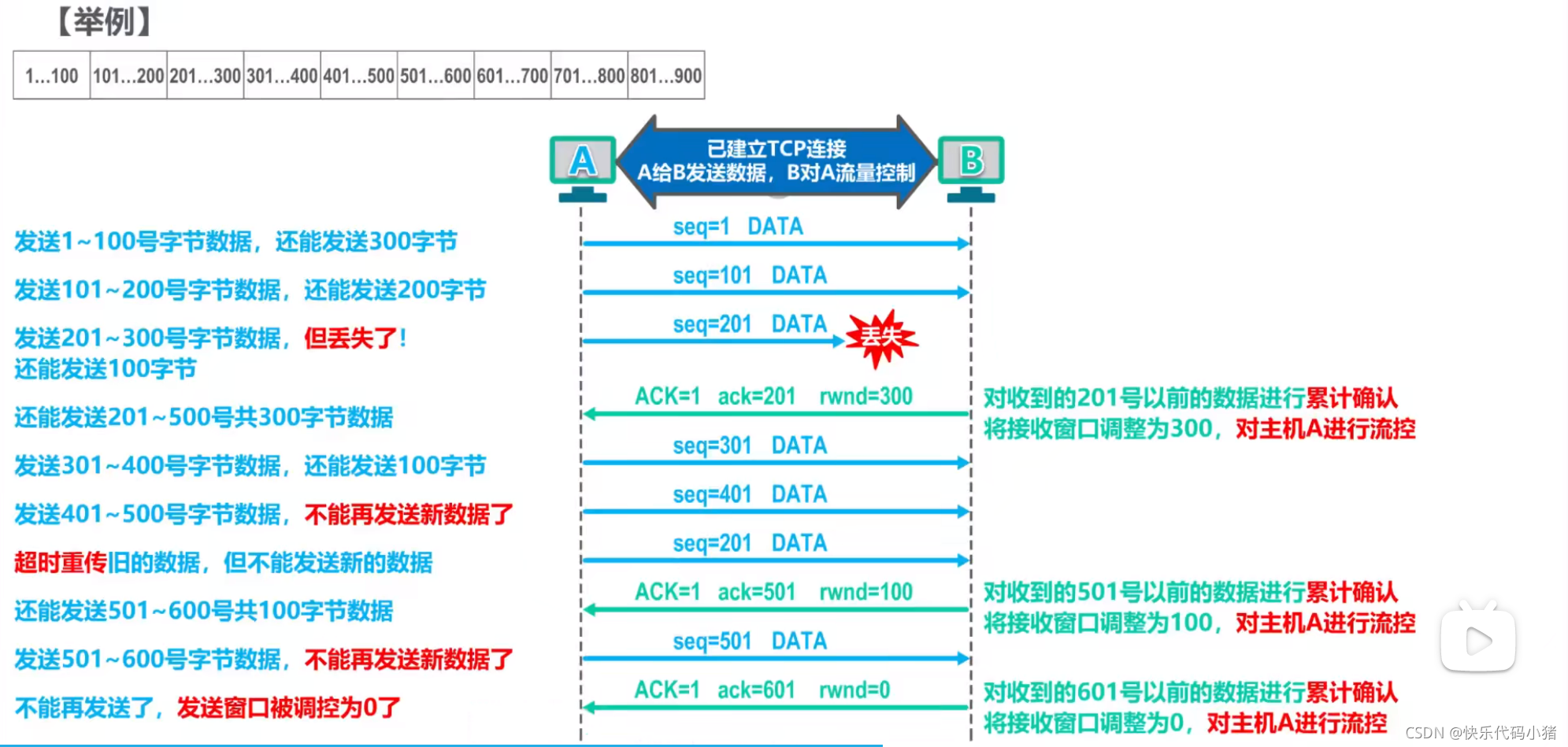

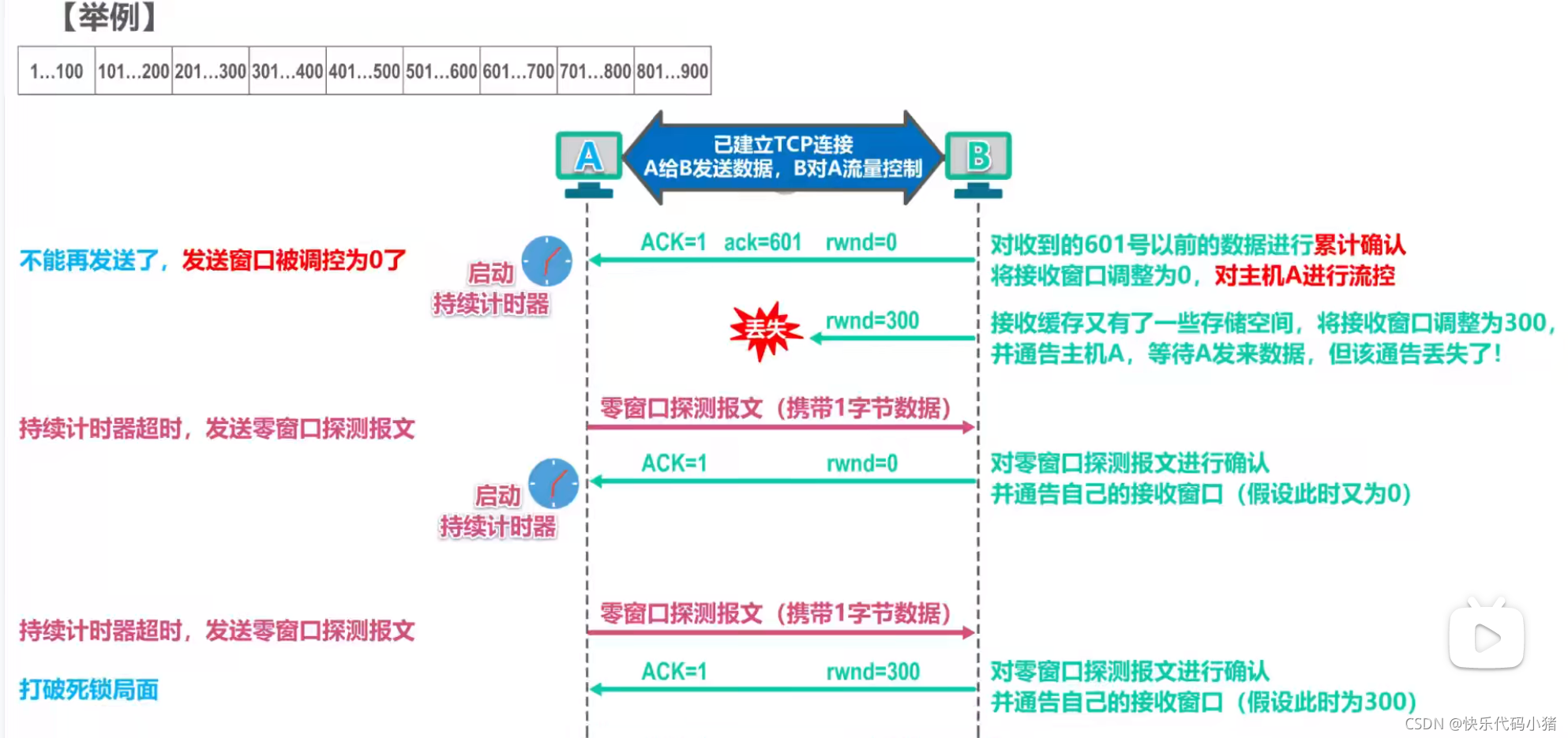
當B又有儲存空間時,會向A傳送視窗值,則A又可以繼續傳送資料了
但是如果B傳送的這個視窗值丟失,就會造成死鎖
解決:
當A收到的視窗值為0時就開啟一個持續計時器,當持續計時器超時,會向B傳送一個零視窗探測報文
如果B返回的視窗還是0,A就重新啟動持續計時器
零視窗探測報文也會丟失,解決:零視窗探測報文也存在一個重傳計時器
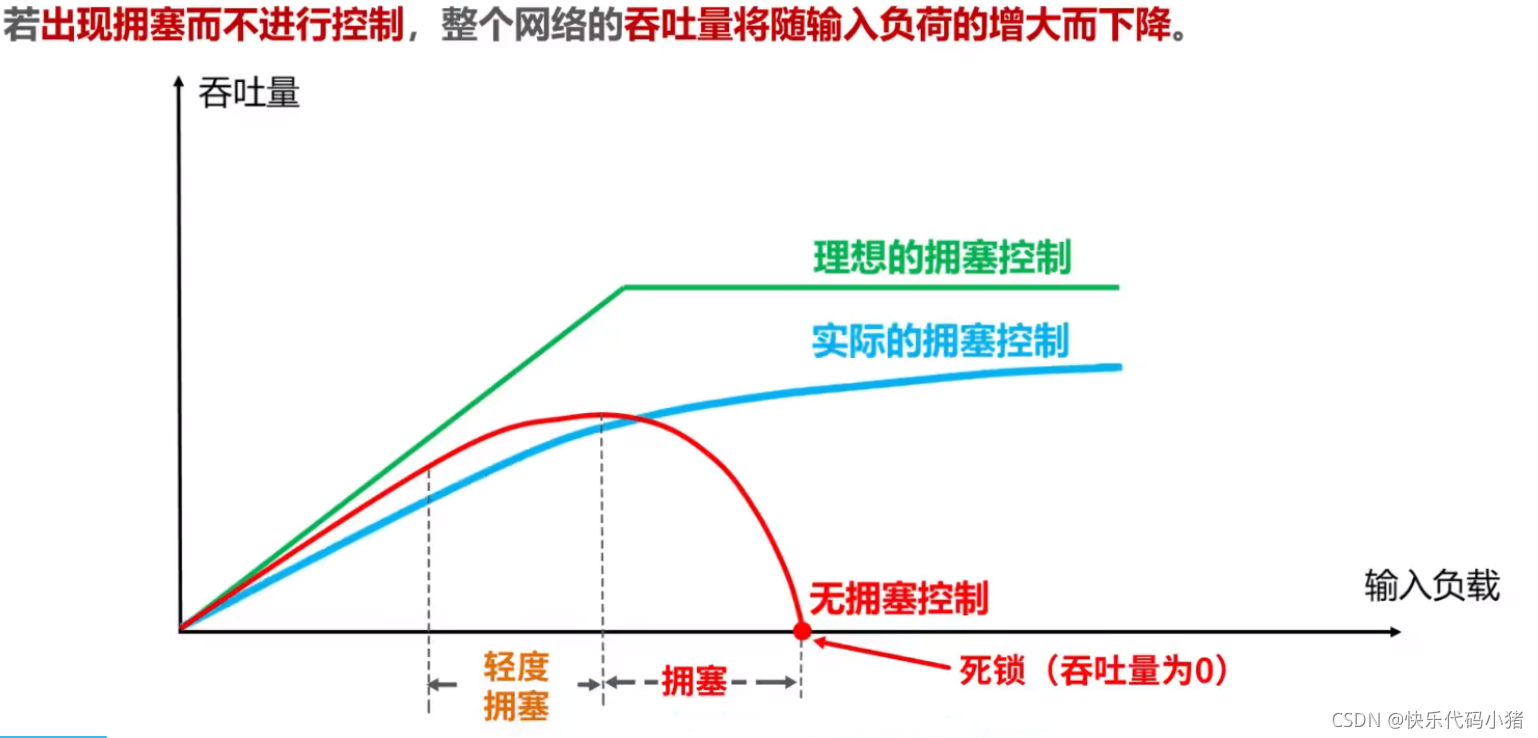
在某段時間,若對網路中某一資源的需求超過了該資源所能提供的可用部分,網路效能就要變壞,這種情況就叫做網路擁塞.
TCP擁塞控制
若對網路中某一資源的需求超過了該資源所能提供的可用部分,網路效能就會變壞,這種情況叫網路擁塞。
網路擁塞的原因主要有以下三點:
- 處理器的速度太慢
- 線路容量的限制
- 節點輸出包的能力小於輸入包的能力
而我們所說的TCP的擁塞控制和流量控制的原理是相關的 :
流量控制在資料鏈路層對一條通訊路徑上的流量進行控制,其的是保證傳送者的傳送速度不超過接收者的接收速度,它只涉及一全傳送者和一個接收者,是區域性控制。
擁塞控制是對整個通訊子網的流量進行控制,其目的是保證通訊子網中的流量與其資源相匹配,使子網不會出現效能下降和惡化、甚至崩潰,是全域性控制。
擁塞控制的目的:
- 防止由於過載而使得吞吐量下降,損失效率
- 合理分配網路資源
- 避免死鎖
- 匹配傳輸速度
擁塞控制的方法:
開環控制: 開環控制的思想是通過良好的設計避免擁塞問題的出現,確保擁塞問題在開始時就不可能發生。開環控制方法包括何時接受新的通訊何時丟棄包、丟棄哪些包。其特點是在作出決定時不考慮網路當前的狀態
閉環控制: 閉環控制的思想是反饋控制。即通過將網路工作的動態資訊反饋給網路中節點的有關程序,節點根據網路當前的動態資訊,調整轉發封包的策略。閉環控制過程包括三部分:
① 監視系統 檢測網路發生或將要發生擁塞的時間和地點
② 報告 將監視中檢測到的資訊傳送到可以進行擁塞控制的節點
③ 決策 調整系統的操作行為,以解決問題
擁塞控制的常見演演算法:
- 1.慢開始 : 先指數級增長連線,到達閾值時,保持不變…
- 2.擁塞控制 : 每一次只增1(線性增長)
- 3.快重傳 : 有沒有在規定時間內返回響應…
- 4.快恢復
傳送方維護一個擁塞視窗的狀態變數cwnd,其值取決於網路的擁塞程度,且動態變化。傳送方將擁塞視窗作為傳送視窗swnd = cwnd。傳送方維護一個慢開始門限ssthresh狀態變數。
擁塞視窗的維護原則:只要網路沒有出現擁塞,擁塞視窗就增大;出現擁塞,擁塞視窗就減小。
判斷是否出現網路擁塞的依據:判斷有沒有按時收到確認報文。
cwnd < ssthresh慢開始
cwnd >=ssthresh擁塞控制
1.慢開始
初始擁塞視窗cwnd=1,傳送方只能傳送1個資料包文(cwnd是幾,就傳送幾個),接收方收到報文,傳送1個確認報文;
擁塞視窗變為cwnd=2,傳送方傳送2個資料包文,接收方收到報文,傳送2個確認報文;
擁塞視窗cwnd=4。傳送方傳送4個報文資料,接收方收到報文,傳送4個確認報文;
擁塞視窗cwnd=8 …
…
擁塞視窗cwnd=16(cwnd按指數增長)
當擁塞視窗值>=慢開始門限時,改為擁塞控制演演算法
2.擁塞控制
擁塞控制:cwnd只能每次線性+1。
擁塞視窗cwnd=16。傳送方傳送16個報文資料,接收方收到報文,傳送1個確認報文;
擁塞視窗cwnd=17。傳送方傳送17個報文資料,接收方收到報文,傳送1個確認報文;
擁塞視窗cwnd=18。傳送方傳送18個報文資料,接收方收到報文,傳送1個確認報文;
…
擁塞視窗cwnd=18(cwnd線性增長)
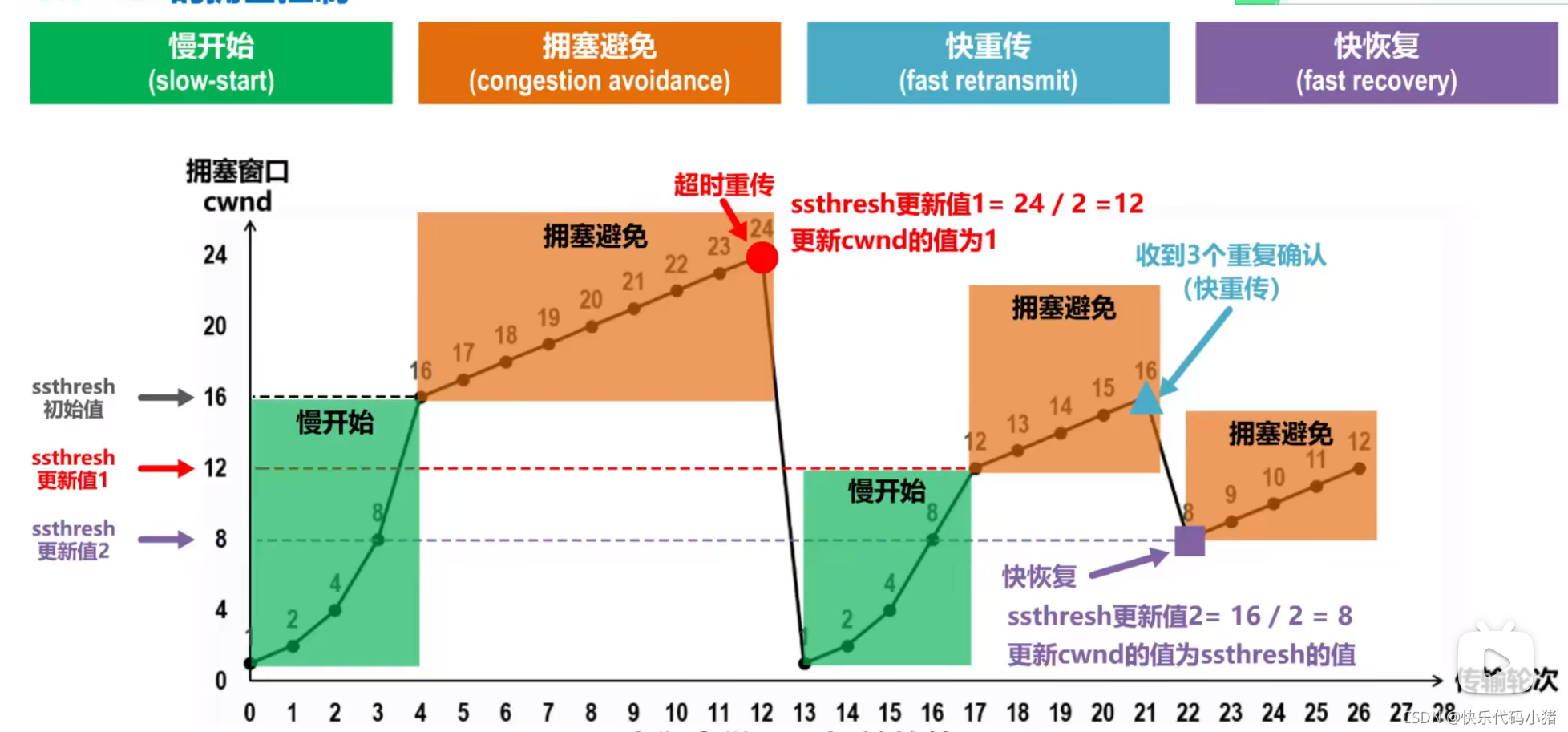
如果傳送方傳送了24個報文,但是隻接收到了20個確認報文,丟失的4個報文的重傳計時器超時了,
傳送方判斷出現擁塞,重置ssthresh=cwnd/2;cwnd=1
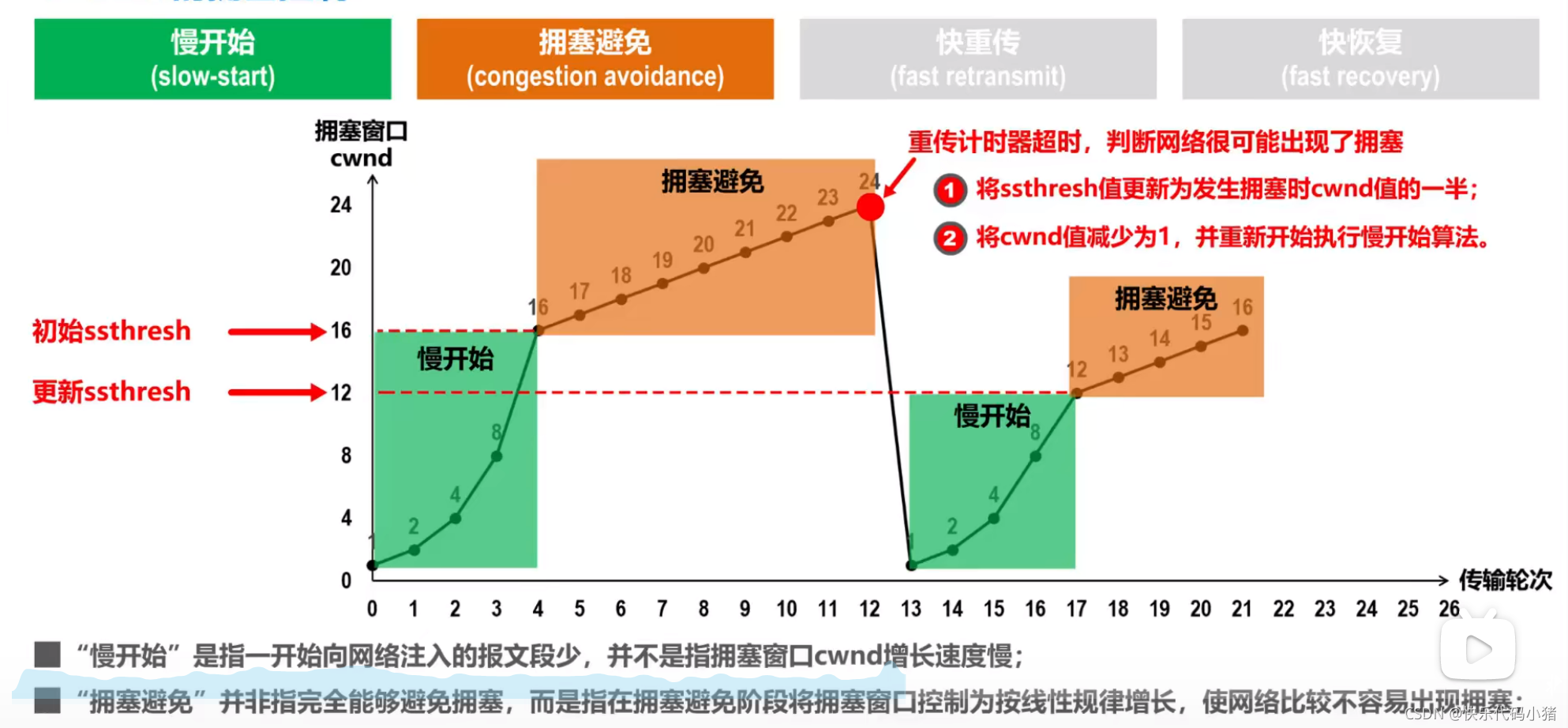
3.快重傳-快恢復
快重傳-快恢復:使傳送方儘快重傳,而不是等重傳計時器超時再重傳。
(傳送M1,確認M1;傳送M2,確認M2;傳送M3,M3丟失;傳送M4,確認M2;傳送M5,確認M2;傳送M6,確認M2;)收到3個重複的確認,立即重傳。
快恢復:ssthresh=cwnd/2;cwnd=ssthren(丟失了3個報文段,擁塞視窗可以不置為1)

綜合
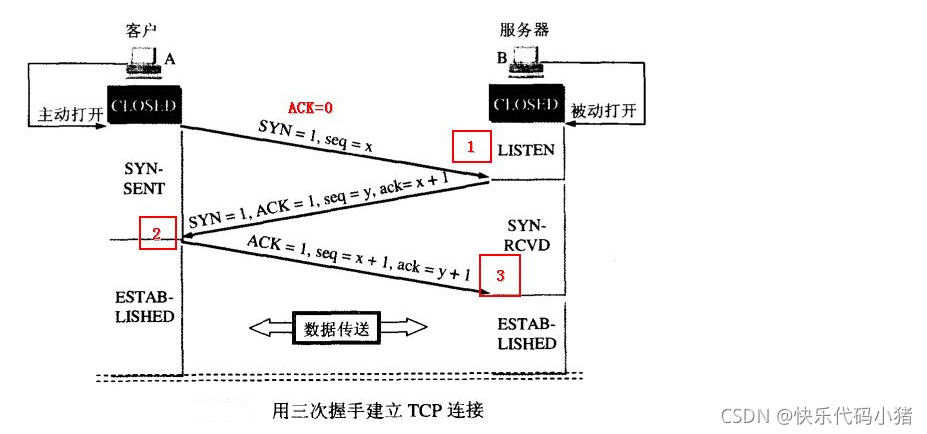
TCP的三次握手過程
所謂三次握手,是指建立一個TCP連線時,需要使用者端和伺服器總共傳送 3個包
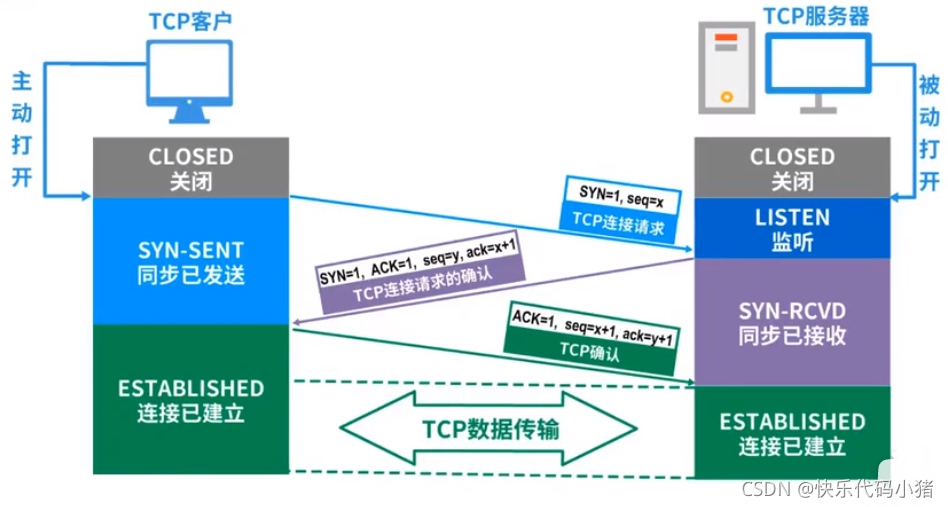
三次握手的目的是: 使用者端連線伺服器到指定的埠,建立TCP連線.並同步連線雙方的序列號和確認號並交換TCP視窗大小資訊.
在Socket程式設計中,使用者端執行connect()時,將觸發三次握手
首先我們需要知道以下四個概念:
序列號seq: 佔4個位元組,用來標記資料段的順序,就是這個報文段中的第一個位元組的資料編號
確認號ack: 佔4個位元組,期待收到對方下一個報文段的第一個資料位元組的序號
同步SYN: 連線建立時用於同步序號。
當SYN=1,ACK=0時表示:這是一個連線請求報文段。
若同意連線,則在響應報文段中使得SYN=1,ACK=1。因此,SYN=1表示這是一個連線請求,或連線接受報文。
SYN這個標誌位只有在TCP建產連線時才會被置1,握手完成後SYN標誌位被置0。
確認ACK: 佔1位,僅當ACK=1時,確認號欄位才有效。ACK=0時,確認號無效
- 第一次握手: 建立連線時,使用者端A傳送SYN包(seq = x)到伺服器B,並進入SYN_SEND狀態,等待伺服器B確認
- 第二次握手: 伺服器B收到伺服器傳送的SYN包.必須確認使用者端A的SYN(ack = x + 1,seq = y),同時自己也會傳送一個SYN包,即SYN + ACK包,此時伺服器進入SYN_RECV狀態
- 第三次握手: 使用者端A收到伺服器B的SYN包 + ACK包,向伺服器B傳送確認包ACK,此時無需將SYN標識置為1(seq = x + 1,ack = y + 1),此包傳送完畢,使用者端A和伺服器B進入ESTABLISHED狀態
- 完成三次握手以後,使用者端和伺服器端即可以開始進行傳送資料
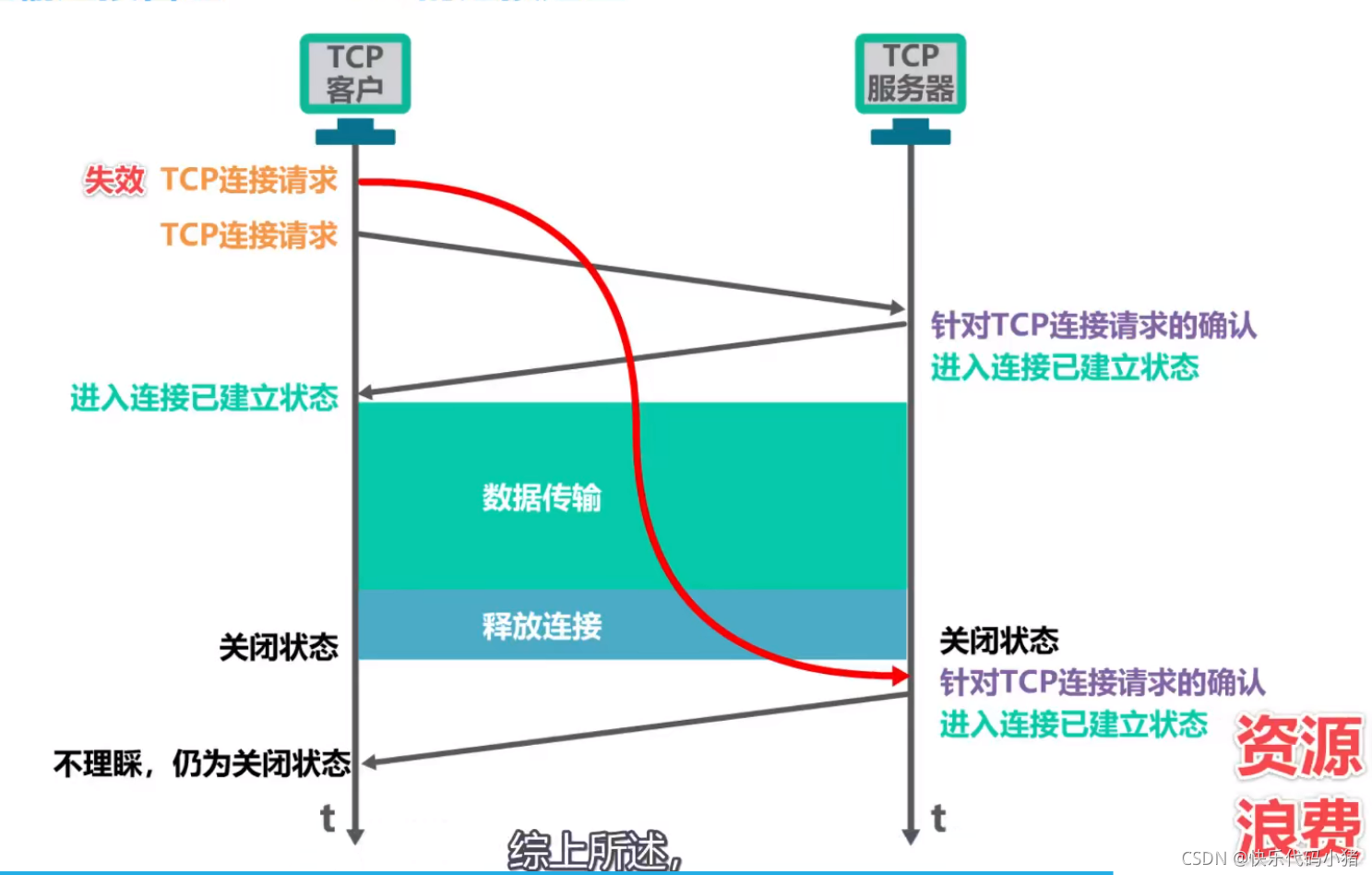
能否變為二次握手
滯留在網路中的請求到達伺服器,會導致伺服器給客服傳送請求,並進入已建立連線狀態;
伺服器不理睬該請求,仍為關閉狀態
伺服器處於已建立連線狀態會等待使用者端的請求,造成伺服器資源浪費
accept connect listen對應三次握手什麼階段
使用者端呼叫connect的時候,就是發一個syn包
伺服器端accept的時候,實際上是從核心的accept佇列裡面取一個連線,如果這個佇列為空,則程序阻塞(阻塞模式下)。如果accept返回則說明成功取到一個連線,返回到應用層。
大致的過程是使用者端發一個syn之後,伺服器端將這個連線放入到backlog佇列,在收到使用者端的ack之後將這個請求移到accept佇列。所以accept一定是發生在三次握手之後,connect只是發一個syn而已
Accept根本不參與三次握手,伺服器只要Listen,使用者端connect是與伺服器核心握手,connect完成之後,伺服器都不需要寫Accept,使用者端就已經可以傳送資料了,你完全可以讓這批資料在伺服器裡躺一年之後,再Accept也可以
tcp三次握手的過程,accept發生在三次握手哪個階段?
第一次握手:使用者端傳送syn包(syn=j)到伺服器。
第二次握手:伺服器收到syn包,必須確認客戶的SYN(ack=j+1),同時自己也傳送一個ASK包(ask=k)。
第三次握手:使用者端收到伺服器的SYN+ACK包,向伺服器傳送確認包ACK(ack=k+1)。
三次握手完成後,使用者端和伺服器就建立了tcp連線。這時可以呼叫accept函數獲得此連線
TCP的四次揮手過程
TCP通訊雙方都可以釋放連線
TCP的連線的拆除需要傳送四個包,因此稱為四次揮手。使用者端或伺服器均可主動發起揮手動作,在socket程式設計中,任何一方執行close()操作即可產生揮手操作。
TCP連線是全雙工的,因此每個方向都必須單獨進行關閉。這原則是當一方完成它的資料傳送任務後就能傳送一個FIN來終止這個方向的連線。收到一個 FIN只意味著這一方向上沒有資料流動,一個TCP連線在收到一個FIN後仍能傳送資料。首先進行關閉的一方將執行主動關閉,而另一方執行被動關閉。
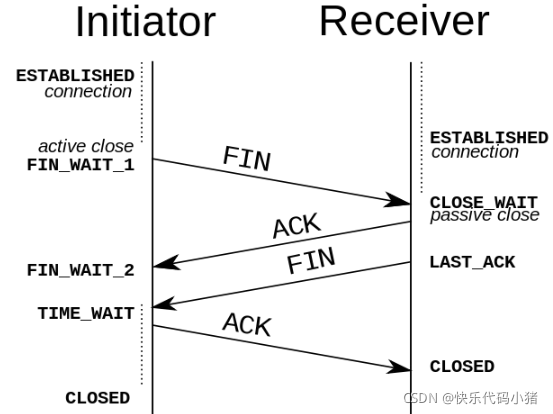
- (1) TCP使用者端傳送一個FIN,用來關閉使用者端到伺服器端的資料傳送(即告訴伺服器我要和你斷開連線)
- (2) 伺服器收到這個FIN,它會傳送一個ACK,確認序號為收到的序號加1.和SYN一樣,一個FIN將佔用一個序號(即告訴使用者端你不能給我發了,但是此時伺服器端還是可以給使用者端傳送資訊的)
- (3) 伺服器端關閉與使用者端的連線,傳送一個FIN包給使用者端(此時伺服器端也告訴使用者端我也要和你斷開連線)
- (4) 使用者端傳送ACK報文確認,並將確認序號設定為收到的序號加1(使用者端同意了伺服器端的請求,此時確認以後,伺服器端也不能給伺服器端傳送資料了)
以第一次揮手為例各個標誌位的含義:
FIN:表明這是一個TCP連線釋放報文段
ACK:對之前接收的報文段進行確認
ack:伺服器端傳送過來的位元組的最後一個位元組序號+1
seq:使用者端傳送位元組的最後一個位元組序號+1
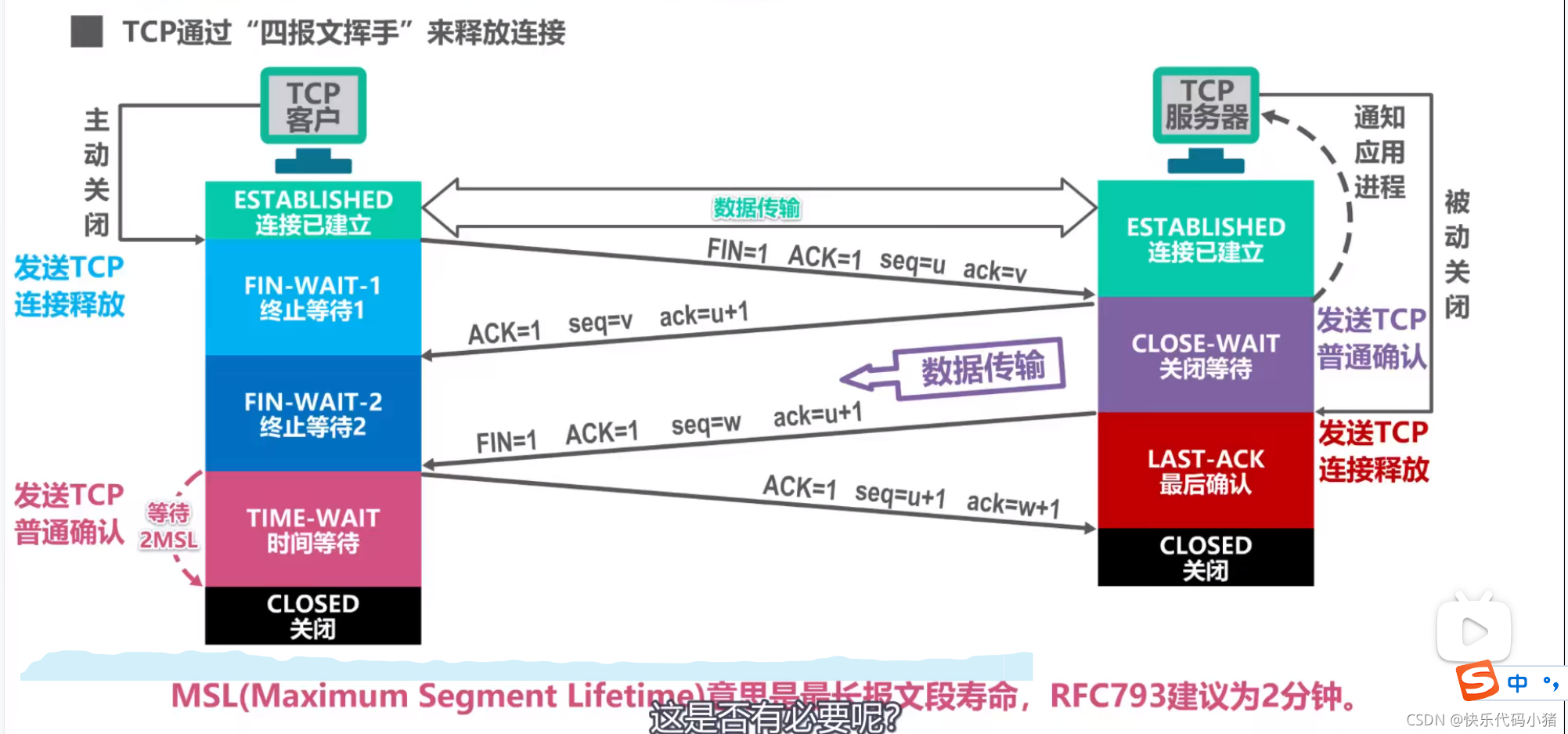
使用者端時間等待狀態是否有必要?
如果使用者端最後一次揮手傳送過程中丟失,會導致伺服器一直重傳TCP連線釋放,無法進入關閉狀態
新增等待狀態可以確保伺服器收到最後一個TCP確認報文段而進入關閉狀態,另外,使用者端在發完最後一個TCP確認報文段後再經過2MLS,可以使本次連線持續時間內所產生的所有報文段都從網路中消失,使下一個TCP連線中不會出現舊連線中的報文段。
如果使用者端出現故障,使用者端如何發現?
TCP伺服器每次收到一次TCP使用者端程序的資料,就重新設定並啟動保活計時器(2h),若保活週期內未收到TCP使用者端的資料,TCP伺服器就像TCP使用者端傳送探測報文段,以後每75s傳送一次,若一臉傳送10個仍沒收到TCP使用者端的響應,TCP伺服器端就認為TCP使用者端出現了故障,接著就關閉這個連結。
四次揮手timewait
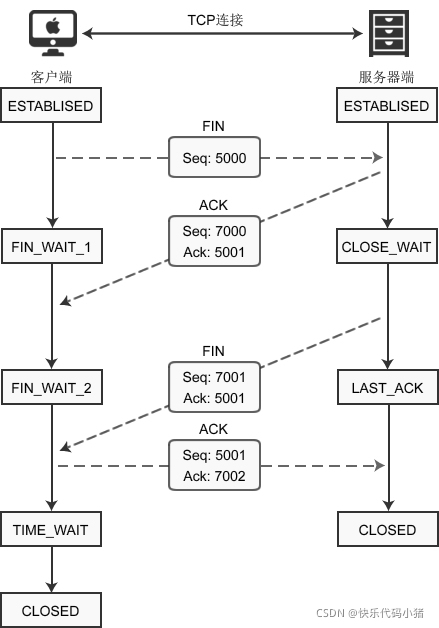
當用戶端最後一次傳送訊息時並沒有直接進入close狀態而是進入TIME_WAIT狀態,這是因為TCP是面向連線的協定,每一次傳送都需要確認對方是否收到訊息。使用者端最後一次傳送訊息時可能會由於網路等其他原因導致伺服器收不到訊息,伺服器就會選擇從新給使用者端傳送一個FIN的包,如果使用者端處於關閉狀態將永遠也收不到伺服器發給它的訊息了。至於這個時間要等多久才能確認對方收到了訊息呢。
報文在網路中有一個最大生存時間MSL超過這個時間就會被丟棄並通知源主機。
TIME_WAIT 要等待 2MSL 才會進入 CLOSED 狀態。
ACK包到達伺服器需要MSL時間,伺服器重傳 FIN 包也需要MSL時間,2MSL 是封包往返的最大時間,通常為2min,如果2MSL後還未收到伺服器重傳的FIN 包,就說明伺服器已經收到了ACK包,此時由TIME_WAIT狀態轉變為CLOSED狀態.
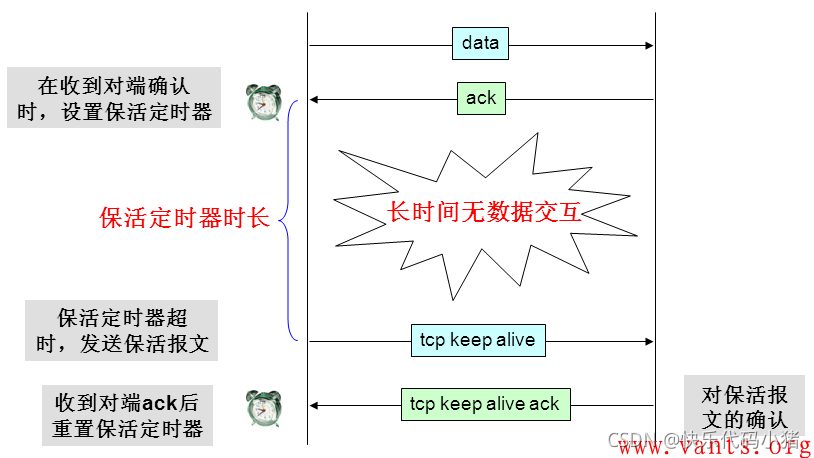
tcp keepalive實現原理
TCP的keepalive的來源
雙方建立互動的連線,但是並不是一直存在資料互動,有些連線會在資料互動完畢後,主動釋放連線,而有些不會,那麼在長時間無資料互動的時間段內,互動雙方都有可能出現掉電、宕機、異常重新啟動等各種意外,當這些意外發生之後,這些TCP連線並未來得及正常釋放,那麼,連線的另一方並不知道對端的情況,它會一直維護這個連線,長時間的積累會導致非常多的半開啟連線,造成端系統資源的消耗和浪費,為了解決這個問題,在傳輸層可以利用TCP的保活報文來實現。
TCP的keepalive的作用
利用保活探測功能,可以探知這種對端的意外情況,從而保證在意外發生時,可以釋放半開啟的TCP連線。
tcp三次握手四次揮手過程及各個狀態
三次握手狀態:
(1) 第一次握手[同步已傳送狀態,SYN-SENT]
(2) 第二次握手[同步收到狀態,SYN-REVD]
(3) 第三次握手[已建立連線狀態,ESTABLISHED]
四次揮手狀態:
(1) FIN-WAIT-1(終止等待1)狀態[使用者端]
(2) CLOSE-WAIT(關閉等待)狀態[伺服器端]
(3) FIN-WAIT-2(終止等待2)狀態[使用者端]
(4) LAST-ACK(最後確認)狀態[伺服器端]
(5) TIME-WAIT(時間等待)狀態[使用者端] 這個是考點!!!
(6) CLOSED狀態[伺服器端]
為什麼三次為什麼四次
TCP連線為什麼是三次的問題?
TCP協定為了實現可靠傳輸,通訊雙方需要判斷自己已經傳送的封包是否都被接收方收到, 如果沒收到, 就需要重發。 為了實現這個需求,很自然地就會引出序號(sequence number) 和 確認號(acknowledgement number) 的使用。
故為了可靠傳輸,傳送方和接收方始終需要同步SYN序號,不僅使用者端向伺服器端傳送SYN包請求連線,並且伺服器端傳送ACK包(確認包)同意請求,也需要向用戶端傳送SYN包請求連線,並得到使用者端的ACK包(確認包),只有雙方都傳送並接收響應,才算連線成功!
TCP斷開連線為什麼是四次的問題?
TCP協定是一種面向連線的、可靠的、基於位元組流的運輸層通訊協定。
TCP是全雙工模式,這就意味著,當用戶端發出
FIN報文段給伺服器端時,只是表示使用者端已經沒有資料要傳送了,即表示它的資料已經全部傳送完畢了;但是,這個時候使用者端還是可以接受來自伺服器端的資料的;當伺服器端返回ACK報文段時,表示它已經知道了使用者端沒有資料傳送了,但是伺服器還是可以傳送資料到使用者端的;當伺服器也傳送了FIN報文段時,這個時候就表示使用者端也沒有資料要傳送了,就等於告訴我也沒有資料要傳送了,之後等到使用者端返回ACK報文段的時候,彼此才會真正的,愉快的中斷這次TCP連線。
SYN攻擊是什麼?
我們說在建立TCP連線的過程中,伺服器傳送SYN-ACK包之後,收到使用者端的ACK包之前的狀態叫做半連線狀態,此時伺服器處於SYN-RECV狀態,當伺服器收到ACK包後,稱為ESTABLISHED狀態
**SYN攻擊指的是攻擊使用者端,在短時間內偽造出大量的不存在的IP地址,向伺服器端進行傳送SYN包,此時伺服器回覆確認包(ACK),並等待使用者端的確認,由於很大的IP地址是不存在的,導致伺服器需要不斷地進行重複傳送直至超時!**而這些偽造的SYN包將長時間佔用未連線佇列,正常的SYN請求被丟棄,目標系統執行緩慢,嚴重者將引起網路堵塞甚至系統癱瘓.
解決方案:
在Linux系統下可以如下命令檢測是否被Syn攻擊
netstat -n -p TCP | grep SYN_RECV
一般較新的TCP/IP協定棧都對這一過程進行修正來防範Syn攻擊,修改tcp協定實現。主要方法有SynAttackProtect保護機制、SYN cookies技術、增加最大半連線和縮短超時時間等等,但是都不能完全地防範SYN攻擊.
TCP建立連線過程中,第三次握手seq=1000,ack=2000.問第二次握手seq和ack分別為多少?
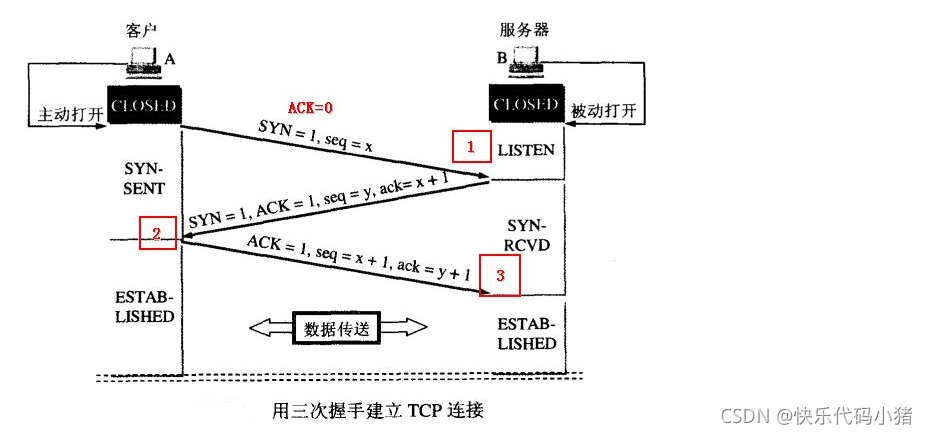
首先我們需要知道幾個概念:
- 序列號seq: 佔4個位元組,用來標記資料段的順序,就是這個報文段中的第一個位元組的資料編號
- 確認號ack: 佔4個位元組,期待收到對方下一個報文段的第一個資料位元組的序號
- 同步SYN: 連線建立時用於同步序號。當SYN=1,ACK=0時表示:這是一個連線請求報文段。若同意連線,則在響應報文段中使得SYN=1,ACK=1。因此,SYN=1表示這是一個連線請求,或連線接受報文。SYN這個標誌位只有在TCP建產連線時才會被置1,握手完成後SYN標誌位被置0。
- 確認ACK: 佔1位,僅當ACK=1時,確認號欄位才有效。ACK=0時,確認號無效
第一次握手:建立連線時,使用者端傳送SYN包(seq=x)到伺服器,並進入SYN_SENT狀態,等待伺服器確認;SYN:同步序列編號(Synchronize Sequence Numbers)。
第二次握手:伺服器收到SYN包,將SYN和ACK標識都置為1,然後設定(seq=y,ack=x+1),向用戶端傳送一個SYN+ACK包,此時伺服器進入SYN_RECV狀態.
第三次握手:使用者端收到伺服器的SYN+ACK包,向伺服器傳送確認包,將ACK置為1,S此時無需SYN,(seq=x+1,ack=y+1),此包傳送完畢,使用者端和伺服器進入ESTABLISHED(TCP連線成功)狀態,完成三次握手。
所以 :
這題中,第三次的seq = x + 1 = 2000,ack = y + 1 = 1000,說明第二次的seq = y = 1999,ack = x + 1 = 1000
tcp粘包
什麼是TCP粘包?
TCP粘包就是指傳送方傳送的若干包資料到達接收方時粘成了一包,從接收緩衝區來看,後一包資料的頭緊接著前一包資料的尾,出現粘包的原因是多方面的,可能是來自傳送方,也可能是來自接收方。
粘包產生的原因
(1) 傳送方原因
TCP預設使用Nagle演演算法(主要作用:減少網路中報文段的數量),而Nagle演演算法主要做兩件事:
- 只有上一個分組得到確認,才會傳送下一個分組
- 收集多個小分組,在一個確認到來時一起傳送
Nagle演演算法造成了傳送方可能會出現粘包問題
(2) 接收方原因
TCP接收到封包時,並不會馬上交到應用層進行處理,或者說應用層並不會立即處理。實際上,TCP將接收到的封包儲存在接收快取裡,然後應用程式主動從快取讀取收到的分組。這樣一來,如果TCP接收封包到快取的速度大於應用程式從快取中讀取封包的速度,多個包就會被快取,應用程式就有可能讀取到多個首尾相接粘到一起的包。
如何解決粘包問題
(1)傳送方
對於傳送方造成的粘包問題,可以通過關閉Nagle演演算法來解決,使用TCP_NODELAY選項來關閉演演算法。
(2)接收方
接收方沒有辦法來處理粘包現象,只能將問題交給應用層來處理。
(2)應用層
應用層的解決辦法簡單可行,不僅能解決接收方的粘包問題,還可以解決傳送方的粘包問題。
解決辦法:迴圈處理,應用程式從接收快取中讀取分組時,讀完一條資料,就應該回圈讀取下一條資料,直到所有資料都被處理完成,但是如何判斷每條資料的長度呢?
- 格式化資料:每條資料有固定的格式(開始符,結束符),這種方法簡單易行,但是選擇開始符和結束符時一定要確保每條資料的內部不包含開始符和結束符。
- 傳送長度:傳送每條資料時,將資料的長度一併行送,例如規定資料的前4位元是資料的長度,應用層在處理時可以根據長度來判斷每個分組的開始和結束位置。
UDP會不會產生粘包問題呢?
TCP為了保證可靠傳輸並減少額外的開銷(每次發包都要驗證),採用了基於流的傳輸,基於流的傳輸不認為訊息是一條一條的,是無保護訊息邊界的(保護訊息邊界:指傳輸協定把資料當做一條獨立的訊息在網上傳輸,接收端一次只能接受一條獨立的訊息)。
UDP則是訊息導向傳輸的,是有保護訊息邊界的,接收方一次只接受一條獨立的資訊,所以不存在粘包問題。
舉個例子:有三個封包,大小分別為2k、4k、6k,如果採用UDP傳送的話,不管接受方的接收快取有多大,我們必須要進行至少三次以上的傳送才能把封包傳送完,但是使用TCP協定傳送的話,我們只需要接受方的接收快取有12k的大小,就可以一次把這3個封包全部傳送完畢。
XSS(Cross Site Scripting) 跨域指令碼攻擊
攻擊原理 :
XSS攻擊的核心原理是:不需要你做任何的登入認證,它會通過合法的操作(比如在url中輸入、在評論框中輸入),向你的頁面注入指令碼(可能是js、hmtl程式碼塊等)
最後導致的結果可能是:盜用Cookie破壞頁面的正常結構,插入廣告等惡意內容D-doss攻擊
如何防禦XSS攻擊?
- 編碼 :把js程式碼跳脫成字串
- 過濾 :移除使用者輸入的和事件相關的屬性。如onerror可以自動觸發攻擊,還有onclick等。(總而言是,過濾掉一些不安全的內容)移除使用者輸入的Style節點、Script節點、Iframe節點。(尤其是Script節點,它可是支援跨域的呀,一定要移除)。
- 校正:避免直接對HTML Entity進行解碼。使用DOM Parse轉換,校正不配對的DOM標籤。DOM Parse這個概念,它的作用是把文字解析成DOM結構。比較常用的做法是,通過第一步的編碼轉成文字,然後第三步轉成DOM物件,然後經過第二步的過濾。
CSRF(Cross-Site Request Forgery) 跨站請求偽造
攻擊原理 :
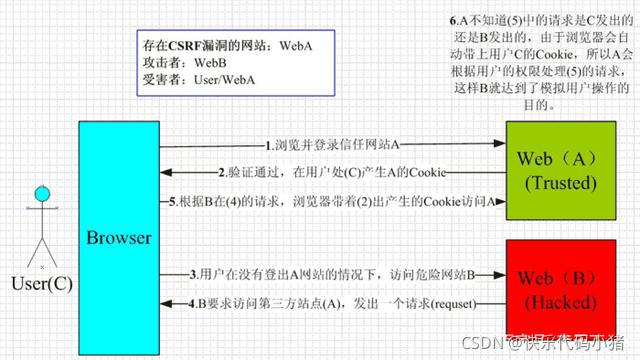
如何防禦CSRF攻擊?
- Token 驗證:(用的最多)
(1)伺服器傳送給使用者端一個token;
(2)使用者端提交的表單中帶著這個token。
(3)如果這個 token 不合法,那麼伺服器拒絕這個請求。
-
隱藏令牌:把 token 隱藏在 http 的 head頭中。方法二和方法一有點像,本質上沒有太大區別,只是使用方式上有區別。
-
Referer 驗證:Referer 指的是頁面請求來源。意思是,只接受本站的請求,伺服器才做響應;如果不是,就攔截。
XSS和CSRF區別
- csrf中B利用C獲取A的信任,得到cookie,再破壞A;XSS:不需要登入。
- csrf利用A本身的漏洞;xss注入js程式碼,篡改a的內容。
sql注入和防範(美團)
什麼是SQL隱碼攻擊?
簡單的理解,SQL隱碼攻擊就是我們將SQL命令插入到WEB表單或者是頁面請求url的請求字串,最終達到欺騙伺服器的執行惡意的SQL命令的目的。
總結來說,SQL隱碼攻擊就是指通過構建特殊的輸入作為引數傳入WEB應用程式,而這些輸入大多數情況下都是SQL語法中的一些組合,通過執行SQL語句進而執行了攻擊者攜帶的操作。
導致SQL隱碼攻擊的主要原因是沒有細緻地過濾使用者輸入的資料,致使非法資料侵入系統
SQL隱碼攻擊的典型案例 - 使用者登入問題
案例 : 我們在使用者登入的時候,需要輸入使用者名稱和密碼進行登入,此時如果我們沒有防範SQL隱碼攻擊,在使用者登入資訊中輸入以下資訊,將會免密登入,這導致對我們的系統造成了極大的不安全性!
使用者名稱 :or 1 = 1 –
密碼 :
首先我們來說一下後臺驗證使用者名稱和密碼的SQL語句為 :
select * form user_table where username = 'username' and password = 'password';
此時我們輸入上面的使用者名稱和密碼以後 :
select * form user_table where username = '' or 1 = 1 -- and password = 'password';
這裡就會出現問題了:
我們說在SQL語句中, – 表示註釋,此時 1 = 1為true,前面用 ‘or‘進行連線,則該條件一定成立,故我們登陸成功
此時如果我們注入的語句不是登陸,而是刪除資料表結構,那如果沒有對SQ注入進行防範,這樣的危害是及其大的!!!
SQL防範
1. 對於普通使用者和系統管理員使用者的許可權進行嚴格的劃分
如果是對資料庫的一些刪除,建立等操作,我們需要系統管理使用者才能進行操作,即我們在設計資料庫時,把系統管理員的使用者與普通使用者區分開來。
2.強迫使用引數化語句
如果在編寫SQL語句的時候,使用者輸入的變數不是直接嵌入到SQL語句。而是通過引數來傳遞這個變量的話,那麼就可以有效的防治SQL隱碼攻擊式攻擊
3. 加強對使用者輸入的驗證
加強對使用者輸入內容的檢查與驗證
4. 使用預編譯(PreStatement)
PreparedStatement會對SQL進行了預編譯,在第一次執行SQL前資料庫會進行分析、編譯和優化,同時執行計劃同樣會被快取起來,它允許資料庫做引數化查詢。在使用引數化查詢的情況下,資料庫不會將引數的內容視為SQL執行的一部分,而是作為一個欄位的屬性值來處理,這樣就算引數中包含破環性語句(or ‘1=1’),也只能作為引數,而不能作為SQL語句內容,故不會被執行。
大部分的SQL框架,例如: Hibernate,Mybatis,JPA等都支援預編譯,故能夠防範SQL隱碼攻擊問題
HTTP/TCP/IP
1. HTTP(HyperText Transport Protocol)
HTTP是超文字傳輸協定的縮寫,它是用來傳送WWW方式的資料,按層次劃分,它屬於應用層.HTTP協定採用了請求/響應模型.
2. TCP(Transmission Control Protocol )
TCP是指傳輸控制協定,是一種面向連線的,可靠的,基於位元組流的傳輸層通訊協定. 其中使用者資料包協定(UDP)也是傳輸層另一種重要的傳輸協定(後面會進行比較) ,他屬於傳輸層。
3. IP(Internet Protocol)
IP指的是網路之間互連的協定,也就是為計算機網路相互連線進行通訊而設計的協定,它屬於網路層.
如今的IP網路使用32位元地址,以點分十進位制表示,如192.168.0.1
地址格式為:IP地址 = 網路地址+主機地址 或 IP地址 = 網路地址 + 子網地址 + 主機地址
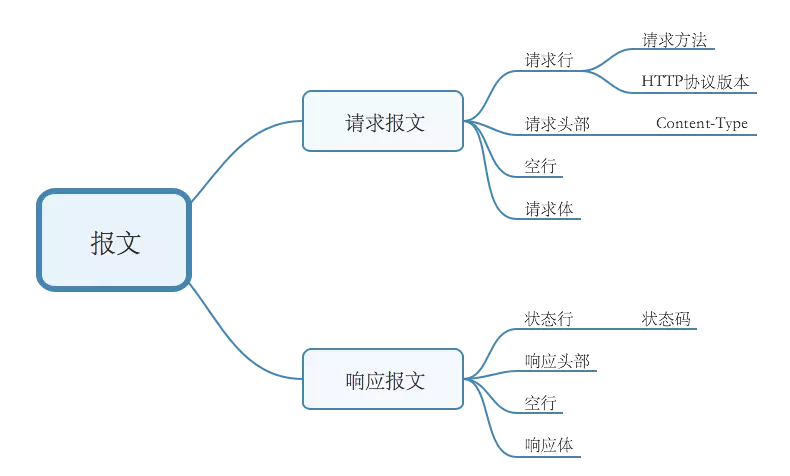
HTTP的報文結構
一個HTTP請求報文由四個部分組成 : 請求行、請求頭部、空行和請求資料(請求體)
一個HTTP響應報文也由四個部分組成:狀態行、響應頭部,空行和響應體
HTTP與HTTPS的區別
HTTP協定傳輸的資料都是未加密的,也就是明文的,因此使用HTTP協定傳輸隱私資訊非常不安全,為了保證這些隱私資料能加密傳輸,於是網景公司設計了SSL(Secure Sockets Layer)協定用於對HTTP協定傳輸的資料進行加密,從而就誕生了HTTPS。
簡單來說,HTTPS協定是由SSL+HTTP協定構建的可進行加密傳輸、身份認證的網路協定,要比HTTP協定安全
總結兩者主要的區別如下所示:
1、https協定需要到ca申請證書,一般免費證書較少,因而需要一定費用。
2、http是超文字傳輸協定,資訊是明文傳輸,https則是具有安全性的ssl加密傳輸協定。
3、http和https使用的是完全不同的連線方式,用的埠也不一樣,前者是80,後者是443。
4、http的連線很簡單,是無狀態的;HTTPS協定是由SSL+HTTP協定構建的可進行加密傳輸、身份認證的網路協定,比http協定安全。
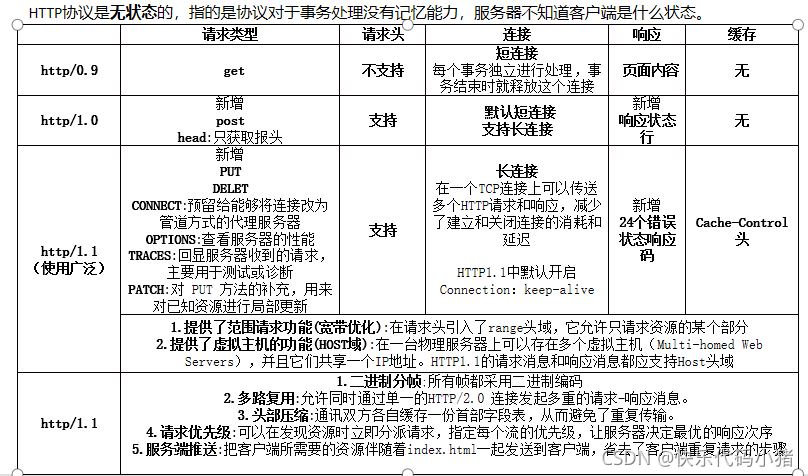
HTTP1.0 和 HTTP1.1之間的區別
1. 長連線(Persistent Connection)
HTTP1.1支援長連線和請求的流水線處理,在一個TCP連線上可以傳送多個HTTP請求和響應,減少了建立和關閉連線的消耗和延遲,在HTTP1.1中預設開啟長連線keep-alive,一定程度上彌補了HTTP1.0每次請求都要建立連線的缺點。HTTP1.0需要使用keep-alive引數來告知伺服器端要建立一個長連線。
2. 節約頻寬
HTTP1.0中存在一些浪費頻寬的現象,例如使用者端只是需要某個物件的一部分,而伺服器卻將整個物件送過來了,並且不支援斷點續傳功能。HTTP1.1支援只傳送header資訊(不帶任何body資訊),如果伺服器認為使用者端有許可權請求伺服器,則返回100,使用者端接收到100才開始把請求body傳送到伺服器;如果返回401,使用者端就可以不用傳送請求body了節約了頻寬。
3. HOST域
在HTTP1.0中認為每臺伺服器都繫結一個唯一的IP地址,因此,請求訊息中的URL並沒有傳遞主機名(hostname),HTTP1.0沒有host域。隨著虛擬主機技術的發展,在一臺物理伺服器上可以存在多個虛擬主機(Multi-homed Web Servers),並且它們共用一個IP地址。HTTP1.1的請求訊息和響應訊息都支援host域,且請求訊息中如果沒有host域會報告一個錯誤(400 Bad Request)。
4. 快取處理
在HTTP1.0中主要使用header裡的If-Modified-Since,Expires來做為快取判斷的標準,HTTP1.1則引入了更多的快取控制策略例如Entity tag,If-Unmodified-Since, If-Match, If-None-Match等更多可供選擇的快取頭來控制快取策略。
5. 錯誤通知的管理
在HTTP1.1中新增了24個錯誤狀態響應碼,如409(Conflict)表示請求的資源與資源的當前狀態發生衝突;410(Gone)表示伺服器上的某個資源被永久性的刪除。
https為什麼要採用對稱和非對稱加密結合的方式
雖然說非對稱加密安全,但是由於和對稱加密比較來說,速度較慢(指的是加密和解密的速度而言),故我們https採用了將對稱加密和非對稱加密結合的方式,即我們將對稱加密的祕鑰使用非對稱加密的公鑰進行加密,然後傳送出去,接收方使用非對稱的私鑰進行解密得到對稱加密的祕鑰,此時雙方就可以使用對稱加密的祕鑰進行通訊溝通了,這樣既保證了安全性,又增加了通訊的速度,即加密和解密的速度.
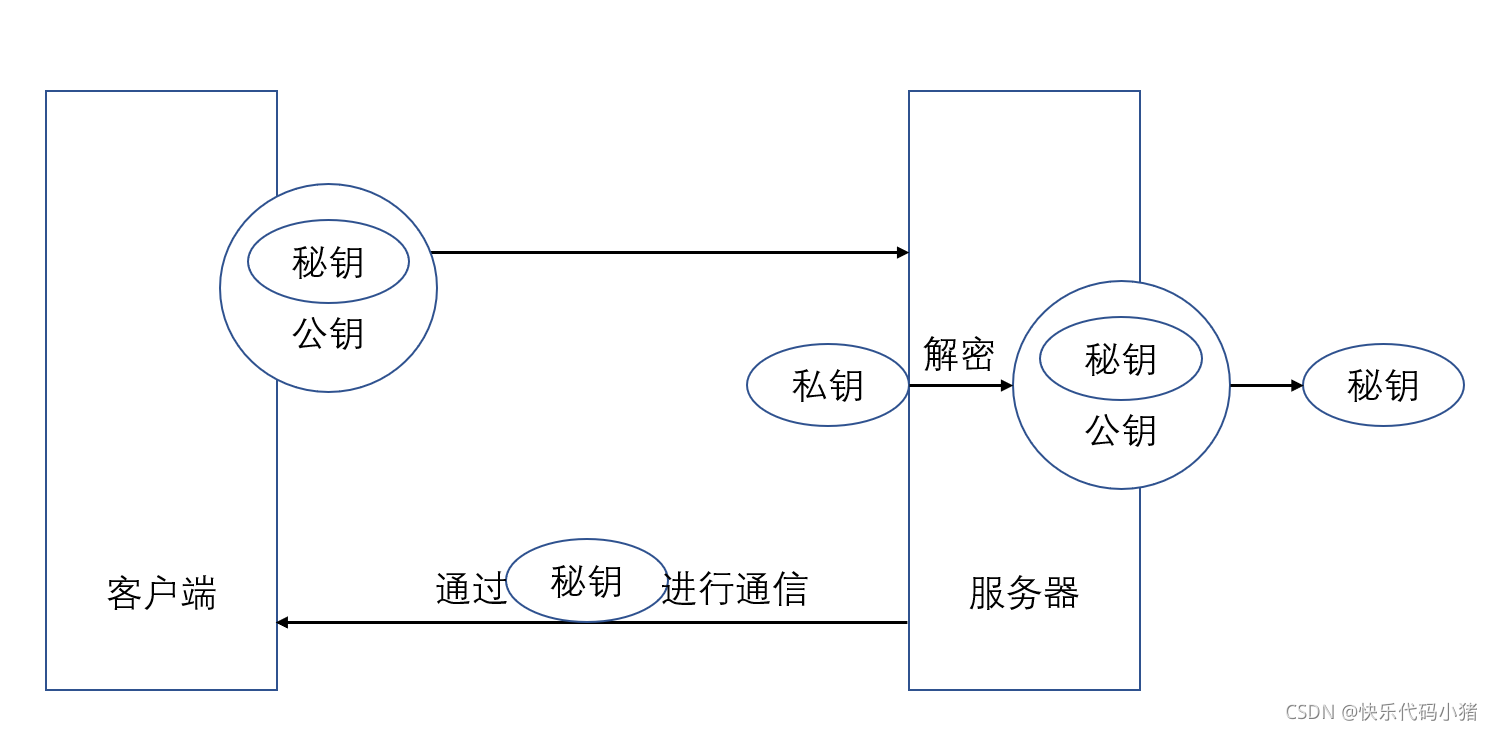
對稱加密和非對稱加密的區別
對稱加密:快速簡單,加密和解密都使用同樣的祕鑰。
非對稱加密:安全,使用一對金鑰,公鑰/私鑰。私鑰由一方安全保管,公鑰可以發給任何請求他的人,傳送請求時通過公鑰對訊息進行加密,只有擁有私鑰的人才能對你的訊息進行解密,安全性大大提高。
SSL加密過程:
1.使用者端向伺服器端傳送請求
2.伺服器端返回給使用者端公鑰
3.使用者端使用公鑰對資訊加密後在想伺服器端傳送請求
4.伺服器端通過私鑰對資訊解密
公鑰私鑰加密原理
RSA加密演演算法:
一種公鑰密碼體制,公鑰公開,私鑰保密,它的加密解密演演算法是公開的。 RSA的這一對公鑰、私鑰都可以用來加密和解密,並且一方加密的內容可以由並且只能由對方進行解密。
- 對稱加密與非對稱加密結合
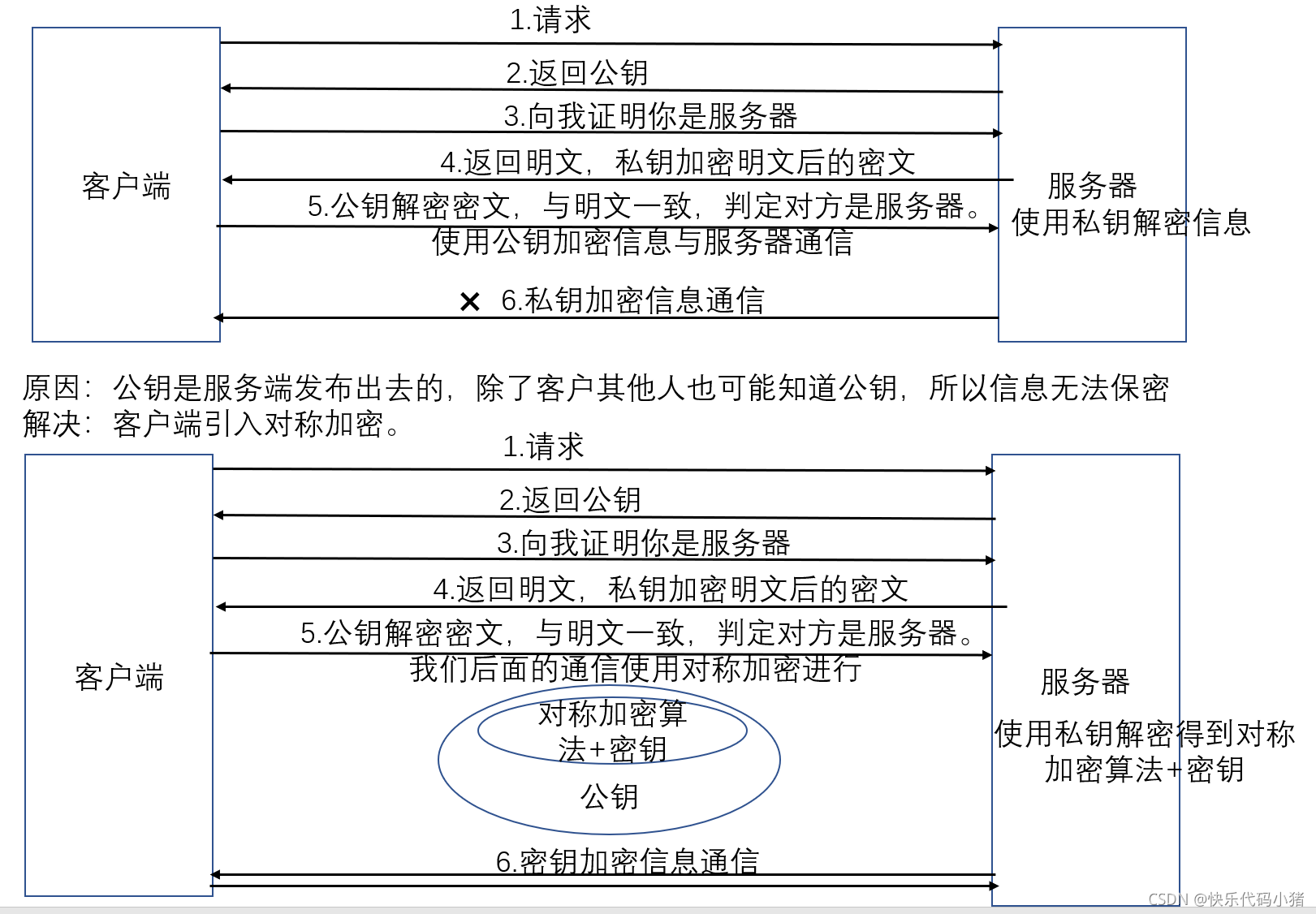
- 判別公鑰是否屬於使用者端
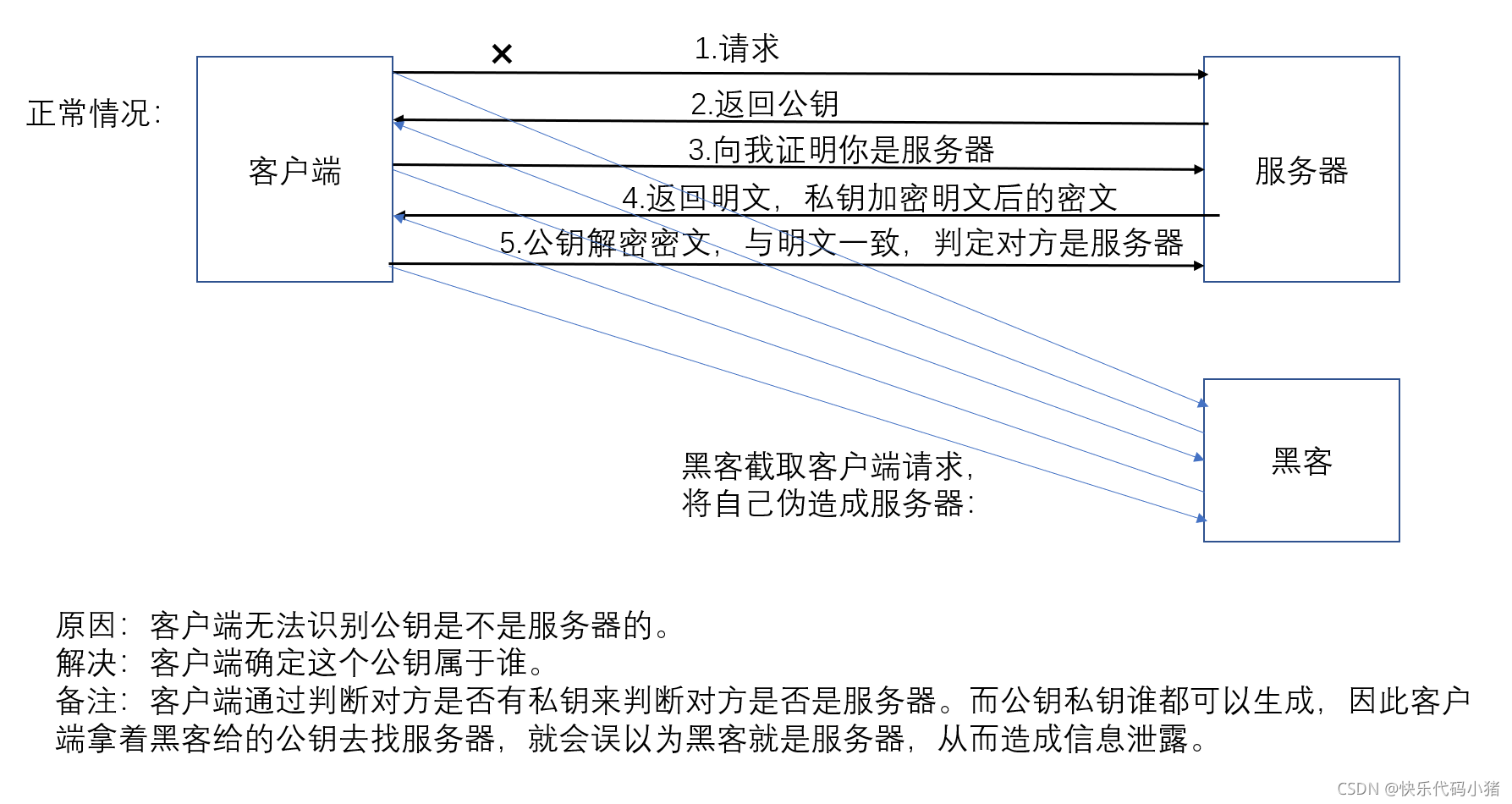
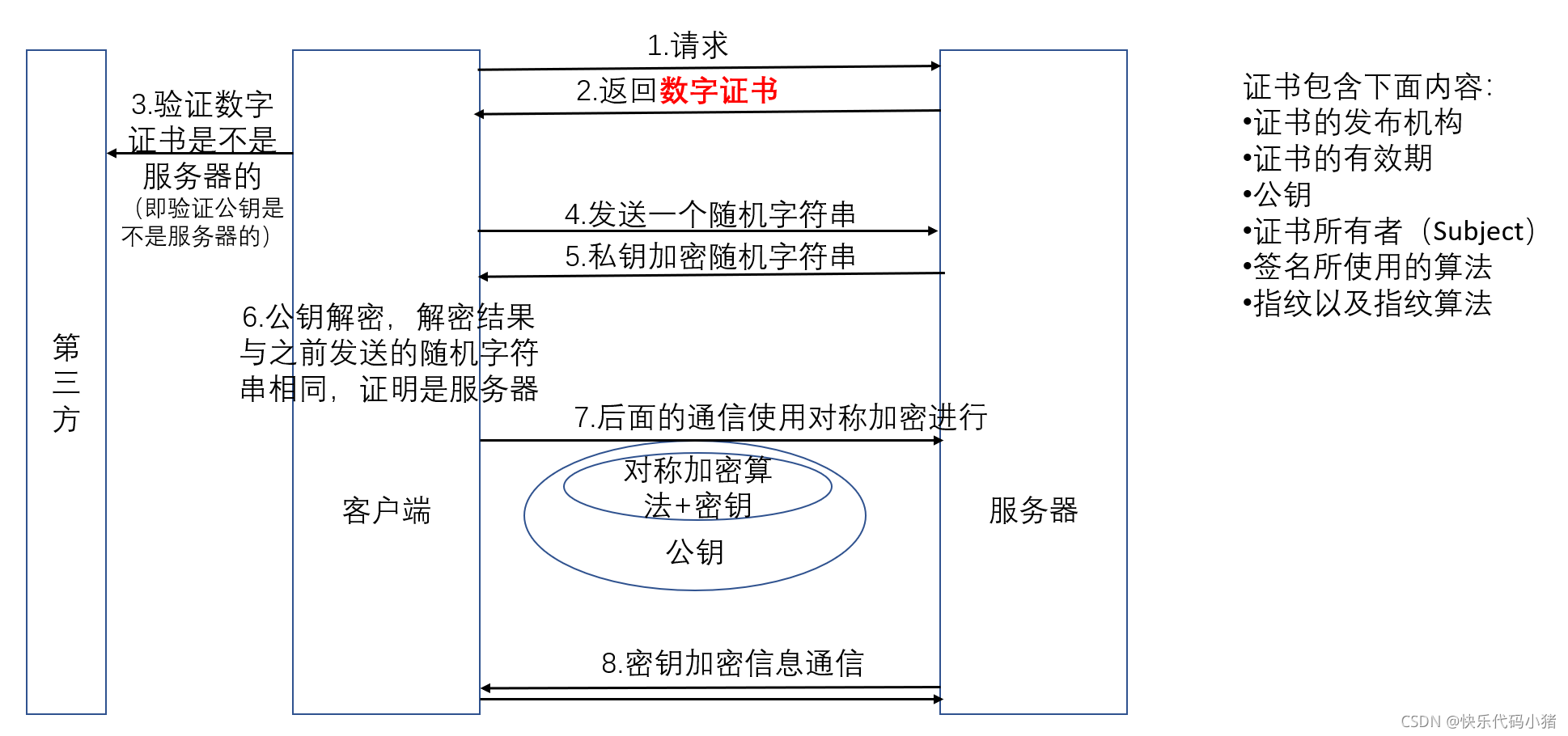
-
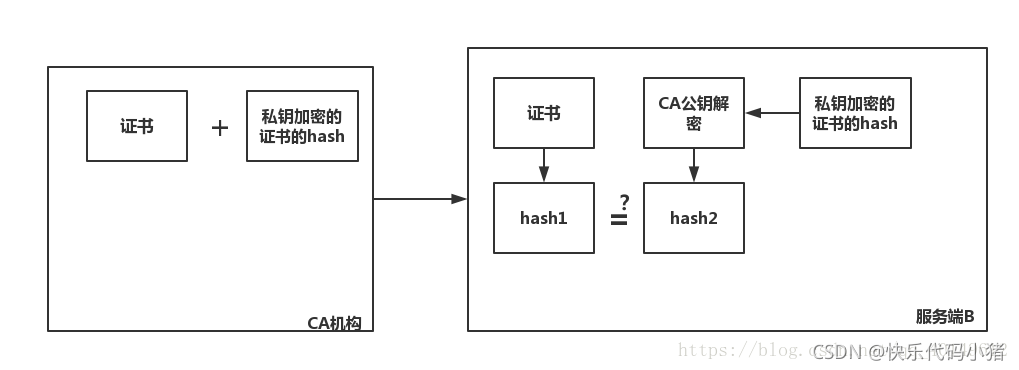
數位簽章
為了防止證書頒發過程中被人修改,出現了數位簽章。
CA機構將證書內容用hash演演算法生成hash字串1,並用CA私鑰加密傳送給伺服器端
伺服器端用CA公鑰解密得到hash字串1,同時也將證書內容用hash演演算法生成hash字串2,如果hash字串1與hash字串2相同,說明證書沒被修改過
HTTP1.1 和 HTTP2.0之間的區別
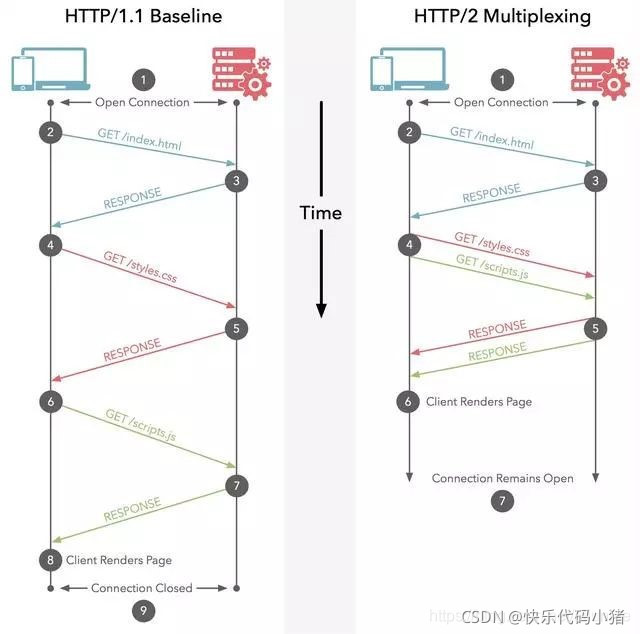
1.多路複用
HTTP2.0使用了多路複用的技術,做到**同一個連線並行處理多個請求,而且並行請求的數量比HTTP1.1大了好幾個數量級。**HTTP1.1也可以多建立幾個TCP連線,來支援處理更多並行的請求,但是建立TCP連線本身也是有開銷的。
2. 頭部資料壓縮
HTTP1.1不支援header資料的壓縮,HTTP2.0使用HPACK演演算法對header的資料進行壓縮,這樣資料體積小了,在網路上傳輸就會更快。
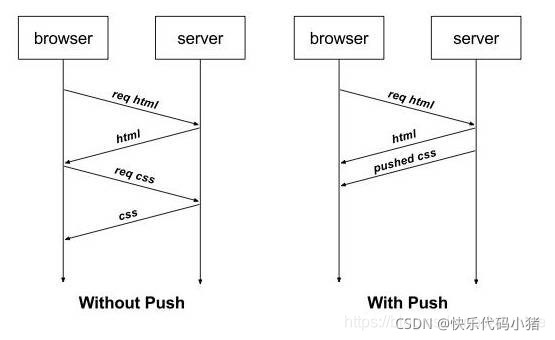
3. 伺服器推播
伺服器端推播是一種在使用者端請求之前傳送資料的機制。網頁使用了許多資源:HTML、樣式表、指令碼、圖片等等。在HTTP1.1中這些資源每一個都必須明確地請求。這是一個很慢的過程。瀏覽器從獲取HTML開始,然後在它解析和評估頁面的時候,增量地獲取更多的資源。因為伺服器必須等待瀏覽器做每一個請求,網路經常是空閒的和未充分使用的.
為了改善延遲,HTTP2.0引入了server push,它允許伺服器端推播資源給瀏覽器,在瀏覽器明確地請求之前,免得使用者端再次建立連線傳送請求到伺服器端獲取。這樣使用者端可以直接從本地載入這些資源,不用再通過網路。
下面這張圖是由TMX總結 :
HTTP0.9 /HTTP1.0/HTTP1.1 /HTTP2.0/HTTP3.0
超文字傳輸協定,基於TCP/IP通訊協定來傳遞資料
1.HTTP0.9
HTTP/0.9是第一個版本的HTTP協定,已過時。它的組成極其簡單,只允許使用者端傳送GET這一種請求,且不支援請求頭。由於沒有協定頭,造成了HTTP/0.9協定只支援一種內容,即純文字。
HTTP/0.9具有典型的無狀態性,每個事務獨立進行處理,事務結束時就釋放這個連線。由此可見,HTTP協定的無狀態特點在其第一個版本0.9中已經成型。一次HTTP/0.9的傳輸首先要建立一個由使用者端到Web伺服器的TCP連線,由使用者端發起一個請求,然後由Web伺服器返回頁面內容,然後連線會關閉。如果請求的頁面不存在,也不會返回任何錯誤碼。
2.HTTP1.0
相對於HTTP/0.9增加了如下主要特性:
-
開始支援使用者端通過POST方法向Web伺服器提交資料,支援GET、HEAD、POST方法
-
請求與響應支援頭域
-
響應物件不只限於超文字
-
響應物件以一個響應狀態行開始
-
支援長連線(但預設還是使用短連線),快取機制,以及身份認證
3.HTTP1.1
是目前使用最廣泛的協定版本。相對於HTTP/1.0新增了以下內容:
3.1 預設為長連線
HTTP 1.1支援長連線(PersistentConnection)和請求的流水線(Pipelining)處理,在一個TCP連線上可以傳送多個HTTP請求和響應,減少了建立和關閉連線的消耗和延遲,在HTTP1.1中預設開啟Connection:keep-alive,一定程度上彌補了HTTP1.0每次請求都要建立連線的缺點。
3.2 寬頻優化
提供了範圍請求功能,HTTP1.0中,存在一些浪費頻寬的現象,例如使用者端只是需要某個物件的一部分,而伺服器卻將整個物件送過來了,並且不支援斷點續傳功能,HTTP1.1則在請求頭引入了range頭域,它允許只請求資源的某個部分,即返回碼是206(Partial Content),這樣就方便了開發者自由的選擇以便於充分利用頻寬和連線。這是支援檔案斷點續傳的基礎。
3.3 提供了HOST域
提供了虛擬主機的功能,在HTTP1.0中認為每臺伺服器都繫結一個唯一的IP地址,因此,請求訊息中的URL並沒有傳遞主機名(hostname)。但隨著虛擬主機技術的發展,在一臺物理伺服器上可以存在多個虛擬主機(Multi-homed Web Servers),並且它們共用一個IP地址。HTTP1.1的請求訊息和響應訊息都應支援Host頭域,且請求訊息中如果沒有Host頭域會報告一個錯誤(400 Bad Request)。
3.4 多了一些快取處理欄位
HTTP/1.1在1.0的基礎上加入了一些cache的新特性,引入了實體標籤,一般被稱為e-tags,新增更為強大的Cache-Control頭。
3.5 錯誤通知的管理
在HTTP1.1中新增了24個錯誤狀態響應碼,如409(Conflict)表示請求的資源與資源的當前狀態發生衝突;410(Gone)表示伺服器上的某個資源被永久性的刪除。
4.HTTP2.0
相對於HTTP/1.1新增了以下內容:
4.1 二進位制分幀
HTTP 2.0 的所有幀都採用二進位制編碼
幀:使用者端與伺服器通過交換幀來通訊,幀是基於這個新協定通訊的最小單位。
訊息:是指邏輯上的 HTTP 訊息,比如請求、響應等,由一或多個幀組成。
流:流是連線中的一個虛擬通道,可以承載雙向的訊息;每個流都有一個唯一的整數識別符號(1、2 … N);
4.2 多路複用
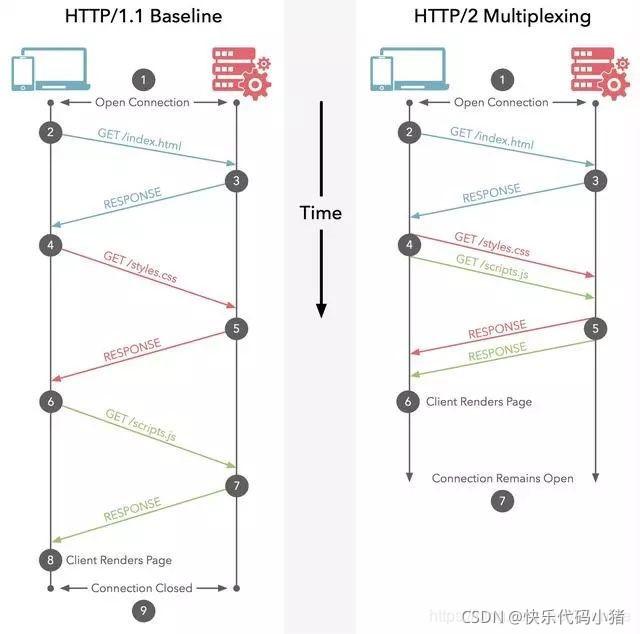
多路複用允許同時通過單一的HTTP/2.0 連線發起多重的請求-響應訊息。有了新的分幀機制後,HTTP/2.0不再依賴多個TCP 連線去處理更多並行的請求。每個資料流都拆分成很多互不依賴的幀,而這些幀可以交錯(亂序傳送),還可以分優先順序。最後再在另一端根據每個幀首部的流識別符號把它們重新組合起來。HTTP 2.0 連線都是持久化的,而且使用者端與伺服器之間也只需要一個連線(每個域名一個連線)即可。
4.3 頭部壓縮
HTTP/1.1 的首部帶有大量資訊,而且每次都要重複傳送。HTTP/2.0 要求通訊雙方各自快取一份首部欄位表,從而避免了重複傳輸。
4.4 請求優先順序
瀏覽器可以在發現資源時立即分派請求,指定每個流的優先順序,**讓伺服器決定最優的響應次序。**這樣請求就不必排隊了,既節省了時間,也最大限度地利用了每個連線。
4.5 伺服器端推播Server Push
把使用者端所需要的資源伴隨著index.html一起傳送到使用者端,省去了使用者端重複請求的步驟。正因為沒有發起請求,建立連線等操作,所以靜態資源通過伺服器端推播的方式可以極大地提升速度。
5.http3.0(QUIC)
快速UDP網際網路連線
2個主要特徵:
5.1 解決阻塞問題
基於TCP的HTTP/2,儘管從邏輯上來說,不同的流之間相互獨立,不會相互影響,但在實際傳輸方面,資料還是要一幀一幀的傳送和接收**,一旦某一個流的資料有丟包,則同樣會阻塞在它之後傳輸的流資料傳輸**。而基於UDP的QUIC協定則可以更為徹底地解決這樣的問題,讓不同的流之間真正的實現相互獨立傳輸,互不干擾。
5.2切換網路時的連線保持
當前行動端的應用環境,使用者的網路可能會經常切換,比如從辦公室或家裡出門,WiFi斷開,網路切換為3G或4G。基於TCP的協定,由於切換網路之後,IP會改變,因而之前的連線不可能繼續保持。而基於UDP的QUIC協定,則可以內建與TCP中不同的連線標識方法,從而在網路完成切換之後,恢復之前與伺服器的連線。
HTTP的請求
- OPTIONS:返回伺服器針對特定資源所支援的HTTP請求方法。也可以利用向Web伺服器傳送’*'的請求來測試伺服器的功能性。
- HEAD:向伺服器索要與GET請求相一致的響應,只不過響應體將不會被返回。這一方法可以在不必傳輸整個響應內容的情況下,就可以獲取包含在響應訊息頭中的元資訊。
- GET:向特定的資源發出請求。
- POST:向指定資源提交資料進行處理請求(例如提交表單或者上傳檔案)。資料被包含在請求體中。POST請求可能會導致新的資源的建立和/或已有資源的修改。
- PUT:向指定資源位置上傳其最新內容。
- DELETE:請求伺服器刪除Request-URI所標識的資源。
- TRACE:回顯伺服器收到的請求,主要用於測試或診斷。
- CONNECT:HTTP/1.1協定中預留給能夠將連線改為管道方式的代理伺服器。
get /post請求的區別(位元組)
-
get引數包含在URL中,長度有限制,會保留在歷史記錄裡,post通過request body傳遞引數,長度沒有限制,不會保留
-
回退時,get請求會從快取中讀取資料,而post會重新傳送請求
-
get請求的URL地址可以被收藏,post不可以
-
get請求只能進行url編碼,post支援多種編碼方式
GET和POST本質上沒有區別
HTTP是基於TCP/IP的關於資料如何在全球資訊網中如何通訊的協定。HTTP的底層是TCP/IP。所以GET和POST的底層也是TCP/IP,也就是說,GET/POST都是TCP連結。不同的瀏覽器(發起http請求)和伺服器(接受http請求)就是不同的運輸公司,他們對get/post請求的資料處理不同。
GET和POST還有一個重大區別
GET產生一個TCP封包;POST產生兩個TCP封包。
對於GET方式的請求,瀏覽器會把http header和data一併行送出去,伺服器響應200(返回資料);
而對於POST,瀏覽器先傳送header,伺服器響應100 continue,瀏覽器再傳送data,伺服器響應200 ok(返回資料)。
HTTP常見的狀態碼
| 狀態碼 | 類別 | 原因短語 |
|---|---|---|
| 1XX | Informational(資訊性狀態碼,伺服器給使用者端的資訊) | 接收的請求正在處理 |
| 2XX | Success(成功狀態碼) | 請求正常處理完畢 |
| 3XX | Redirection(重定向狀態碼) | 需要進行附加操作以完成請求 |
| 4XX | Client Error(使用者端錯誤狀態碼) | 伺服器無法進行處理請求 |
| 5XX | Server Error(伺服器錯誤狀態碼) | 伺服器處理請求出錯 |
| 狀態碼 | 描述 |
|---|---|
| 200 OK | 請求已正常處理 |
| 301 Moved Permanently | 永久性重定向 : 請求的資源已經被分配了新的URI,以後應使用資源現在所指的URI |
| 302 Found | 臨時性重定向 : 和301相似,但302代表的資源不是永久性移動,只是臨時性性質的。換句話說,已移動的資源對應的URI將來還有可能發生改變 |
| 303 See Other | 303狀態碼和302狀態碼有著相同的功能,但303狀態碼明確表示使用者端應當採用GET方法獲取資源,這點與302狀態碼有區別 |
| 304 Not Modified | 該狀態碼錶示使用者端傳送附帶條件的請求時(採用GET方法的請求報文中包含If-Match,If-Modified-Since,If-None-Match,If-Range,If-Unmodified-Since中任一首部)伺服器端允許請求存取資源,但因發生請求未滿足條件的情況後,直接返回304.。 |
| 400 Bad Request | 伺服器端無法理解使用者端傳送的請求,請求報文中可能存在語法錯誤((前端提交到後臺的資料應該是json字串型別,但是前端沒有將物件JSON.stringify轉化成字串)) |
| 401 Unauthorized | 該狀態碼錶示傳送的請求需要有通過HTTP認證(BASIC認證,DIGEST認證)的認證資訊 |
| 403 Forbidden | 不允許存取那個資源。該狀態碼錶明對請求資源的存取被伺服器拒絕了。(許可權,未授權IP等) |
| 404 Not Found | 伺服器上沒有請求的資源。路徑錯誤等 |
| 500 Internal Server Error | 該狀態碼錶明伺服器端在執行請求時發生了錯誤。也有可能是web應用存在bug或某些臨時故障 |
| 503 Service Unavailable | 伺服器暫時處於超負載或正在停機維護,現在無法處理請求 |
| 502 | 作為閘道器或者代理工作的伺服器嘗試執行請求時,從上游伺服器接收到無效的響應。 |
| 504 | 作為閘道器或者代理工作的伺服器嘗試執行請求時,未能及時從上游伺服器(URI標識出的伺服器,例如HTTP、FTP、LDAP)或者輔助伺服器(例如DNS)收到響應。 |
HTTP的only(美團優選)
如果在cookie中設定了HttpOnly,那麼通過程式(js指令碼)將無法讀取到cookie資訊,這樣能有效防止XSS攻擊
HTTP的Referer
表示來源,正確英語拼法是Referrer,為了向後相容,將錯就錯
在www.google.com裡有一個
www.baidu.com連結,那麼點選這個www.baidu.com,它的header資訊裡就有:Referer=http://www.google.com,可以利用這個來防止盜鏈了,比如我只允許我自己的網站存取我自己的圖片伺服器,那我的域名是www.google.com,那麼圖片伺服器每次取到Referer來判斷一下是不是我自己的域名www.google.com,如果是就繼續存取,不是就攔截。直接在位址列中輸入URL的地址是不會包含referer欄位的,因為他不是藏一個地方連結過去的
允許 Referer 為空,意味著你允許比如瀏覽器直接存取,就是空
請求轉發(Redirect)和重定向(Forward)之間的區別
- 位址列資訊 : 重定向會顯示轉向以後的地址,而請求轉發不會顯示轉向的地址
- 請求次數 : 重定向至少提交了兩次請求
- 資料 : 請求轉發對request物件的資訊不會丟失,因此可以在多個頁面互動過程中實現請求資料的共用; 而重定向之前request域資訊將丟失
- 原理 : 請求轉發是在伺服器內部控制權的轉移,是由伺服器區請求,使用者端並不知道是怎樣轉移的,因此使用者端的地址不會顯示出轉向的地址; 重定向則是伺服器告訴使用者端要轉向哪個地址,使用者端再自己去請求轉向的地址,因此會顯示轉向後的地址,也可以理解為瀏覽器至少進行了兩次的存取請求
- 速度 : 請求轉發的速度遠遠快於重定向
請求轉發和重定向的應用場景
- 1、重定向的速度比轉發慢,因為瀏覽器還得發出一個新的請求,如果在使用轉發和重定向都無所謂的時候建議使用轉發。
- 2、因為轉發只能存取當前WEB的應用程式,所以不同WEB應用程式之間的存取,特別是要存取到另外一個WEB站點上的資源的情況,這個時候就只能使用重定向了。
RPC和HTTP的區別
RPC(Remote Produce Call) 遠端過程呼叫
是一個計算機通訊協定,該協定允許執行於一臺計算機的程式呼叫另一臺計算機的子程式,而程式設計師無需額外地為這個互動作用程式設計.它是建立在Socket之上
RPC實現遠端呼叫的策略:
(1) 採用何種網路通訊協定?
比較流行的RPC框架,採用的都是TCP作為底層傳輸協定
(2)資料傳輸的格式是怎麼樣的?
不同於HTTP,RPC遠端過程呼叫需要讓呼叫者和被呼叫者採用相同的資料傳輸格式,就好比兩個人使用同一種語言進行交流溝通一樣.
下面是RPC的呼叫流程圖:
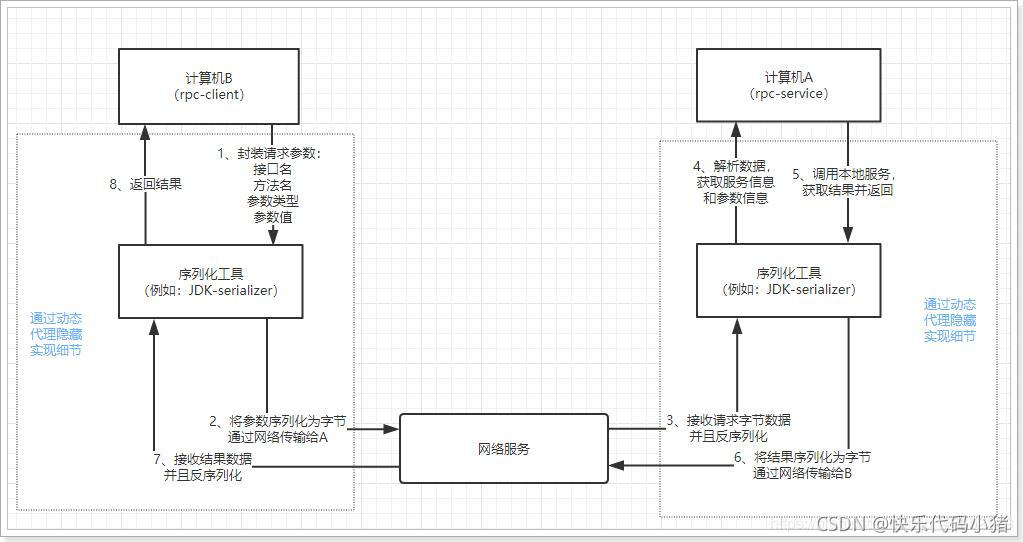
HTTP(HyperText Transport Protocol)
HTTP稱為超文字傳輸協定,是一種應用層的協定,規定了網路傳輸的請求格式、響應格式、資源定位和操作的方式等。但是底層採用什麼網路傳輸協定,並沒有規定,不過現在都是採用TCP協定作為底層傳輸協定.
使用者端通過HTTP向伺服器端傳送請求,並接受響應的流程:

比較RPC和HTTP
- RPC通過Thrift二進位制進行傳輸,而HTTP的json序列化更消耗效能 (即在序列化和反序列化方式上的區別)
- RPC自帶負載均衡,而HTTP需要自己設定負載均衡
- RPC可以自定義TCP協定,報文相對來說較小
- RPC是一種API,HTTP是一種無狀態的網路協定。RPC可以基於HTTP協定實現,也可以直接在TCP協定上實現
- RPC主要是用在大型網站裡面,因為大型網站裡面系統繁多,業務線複雜,而且效率優勢非常重要的一塊,這個時候RPC的優勢就比較明顯了.HTTP主要是用在中小型企業裡面,業務線沒那麼繁多的情況下
- HTTP需要事先通知,修改Nginx/HAProxy設定。RPC能做到自動通知,不影響上游
常用的RPC框架: webservie(cxf)、dubbo
HTTP使用者端工具: HTTPClient
Socket是什麼?
網路上的兩個程式通過一個雙向的通訊連線實現資料的交換,這個連線的一端稱為一個Socket。建立網路通訊連線至少要一對埠號(Socket)。Socket本質是程式設計介面(API).
當然我們也可以理解為: Socket是應用層與TCP/IP協定族通訊的中間軟體抽象層,它是一組介面。在設計模式中,Socket其實就是一個門面模式,它把複雜的TCP/IP協定族隱藏在Socket介面後面,對使用者來說,一組簡單的介面就是全部,讓Socket去組織資料,以符合指定的協定。
Socket中的time-wait狀態多,如何解決
在高並行短連線的server端,當server處理完client的請求後立刻close socket此時會出現time_wait狀態,然後如果client再並行2000個連線,此時部分連線就連線不上了,用linger強制關閉可以解決此問題,但是linger會導致資料丟失,linger值為0時是強制關閉,無論並行多少多能正常連線上,如果非0會發生部分連線不上的情況!(可呼叫setsockopt設定通訊端的linger延時標誌,同時將延時時間設定為0。)
TIME_WAIT是TCP連線斷開時必定會出現的狀態。是無法避免掉的,這是TCP協定實現的一部分。
在WINDOWS下,可以修改登入檔讓這個時間變短一些,time_wait的時間為2msl,預設為4min.你可以通過改變TcpTimedWaitDelay的量,把它縮短到30s.TCP要保證在所有可能的情況下使得所有的資料都能夠被投遞。當你關閉一個socket時,主動關閉一端的socket將進入TIME_WAIT狀態,而被動關閉一方則轉入CLOSED狀態,這的確能夠保證所有的資料都被傳輸。但是這樣也會給我們帶來兩個問題 :
(1) 我們沒有任何機制保證最後的一個ACK能夠正常傳輸
(2) 網路上仍然有可能有殘餘的封包(wandering duplicates),我們也必須能夠正常處理
解決方案 :
由於TIME_WAIT狀態所帶來的相關問題,我們可以通過設定SO_LINGER標誌來避免socket進入TIME_WAIT狀態,這可以通過傳送RST而取代正常的TCP四次握手的終止方式。但這並不是一個很好的主意,TIME_WAIT對於我們來說往往是有利的,下面我們來談談TIME_WAIT的作用
TIME_WAIT的作用 :
1. 可靠地實現TCP全雙工連線的終止;
如果伺服器最後傳送的ACK因為某種原因丟失了,那麼客戶一定會重新傳送FIN,這樣因為有TIME_WAIT的存在,伺服器會重新傳送ACK給客戶,如果沒有TIME_WAIT,那麼無論客戶有沒有收到ACK,伺服器都已經關掉連線了,此時客戶重新傳送FIN,伺服器將不會傳送ACK,而是RST,從而使使用者端報錯。也就是說,TIME_WAIT有助於可靠地實現TCP全雙工連線的終止。
2. 允許老的重複分節在網路中消逝。
如果沒有TIME_WAIT,我們可以在最後一個ACK還未到達客戶的時候,就建立一個新的連線。那麼此時,如果客戶收到了這個ACK的話,就亂套了,必須保證這個ACK完全死掉之後,才能建立新的連線。也就是說,TIME_WAIT允許老的重複分節在網路中消逝。
為什麼TIME_WAIT 狀態需要保持2MSL這麼長的時間?
ACK包到達伺服器需要MSL時間,伺服器重傳 FIN 包也需要MSL時間,2MSL 是封包往返的最大時間,通常為2min,如果2MSL後還未收到伺服器重傳的FIN 包,就說明伺服器已經收到了ACK包,此時由TIME_WAIT狀態轉變為CLOSED狀態.
如果 TIME_WAIT 狀態保持時間不足夠長(比如小於2MSL),第一個連線就正常終止了。第二個擁有相同相關五元組的連線出現,而第一個連線的重複報文到達,干擾了第二個連線。TCP實現必須防止某個連線的重複報文在連線終止後出現,所以讓TIME_WAIT狀態保持時間足夠長(2MSL),連線相應方向上的TCP報文要麼完全響應完畢,要麼被丟棄。建立第二個連線的時候,不會混淆。
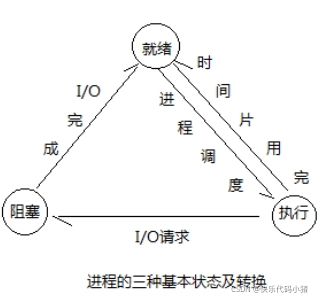
程序和執行緒有什麼關係與區別(美團)
程序
每個應用程式都是一個程序,每個程序都有自己獨立的一塊記憶體空間,一個程序可以有多個執行緒。
程序的三種狀態:就緒態(以獲得除cpu外的所有資源),阻塞態,執行態
執行緒
程序中的一個執行任務(控制單元)。一個程序至少有一個執行緒,一個程序可以執行多個執行緒,多個執行緒可以共用資料。
區別
-
根本區別:程序是作業系統分配資源的基本單位,執行緒是處理器任務排程和執行的基本單位
-
資源開銷:每個程序都有獨立的程式碼和資料空間,程式之間切換開銷大;執行緒是輕量級的執行緒,切換開銷少
-
記憶體分配:程序的地址空間和資源是相互獨立的,執行緒共用本程序的地址空間和資源
程序間的通訊方式有哪些?(美團)
1.管道
1.1匿名管道(半雙工,資料只能單向移動,面向位元組流,允許具有血緣關係的程序通訊)
兩個檔案描述符指向管道的兩端
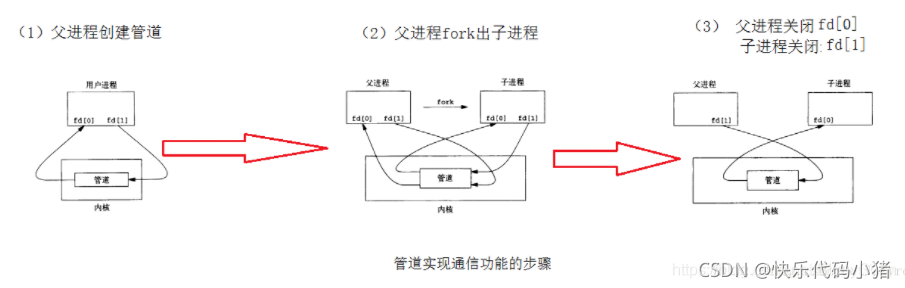
1.2有名管道(半雙工,允許無親緣關係的程序通訊)
2.訊息佇列
(傳送程序新增訊息到佇列的末尾,接收程序在佇列頭部接收訊息,訊息一旦被接收就會從佇列中刪除,類似FIFO)
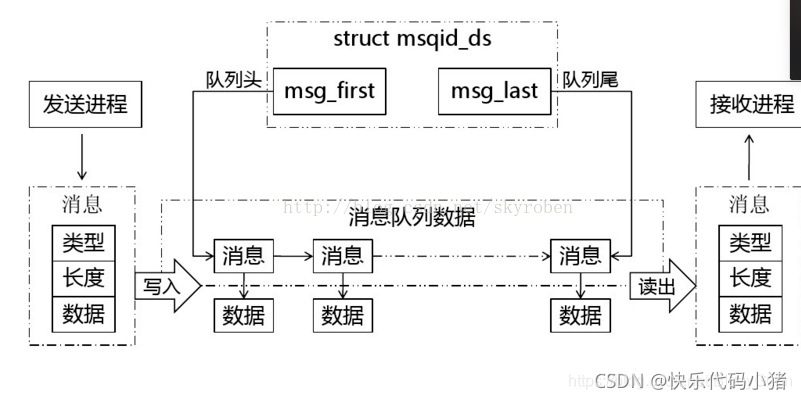
3.號誌
號誌是一個計數器,可以用來控制多個程序對共用資源的存取。它常作為一種鎖機制,防止某程序正在存取共用資源時,其他程序也存取該資源。
號誌工作原理 :
由於號誌只能進行兩種操作等待和傳送訊號,即P(sv)和V(sv),他們的行為是這樣的:
- P(sv):如果sv的值大於零,就給它減1;如果它的值為零,就掛起該程序的執行
- V(sv):如果有其他程序因等待sv而被掛起,就讓它恢復執行,如果沒有程序因等待sv而掛起,就給它加1.
在號誌進行PV操作時都為原子操作(因為它需要保護臨界資源)
4.共用記憶體
共用記憶體就是允許兩個或多個程序共用一定的儲存區。共用記憶體沒有任何的同步與互斥機制,所以要使用號誌來實現對共用記憶體的存取的同步
5.通訊端
可用於不同機器間的程序通訊
輸入一個網址,執行過程是怎樣的
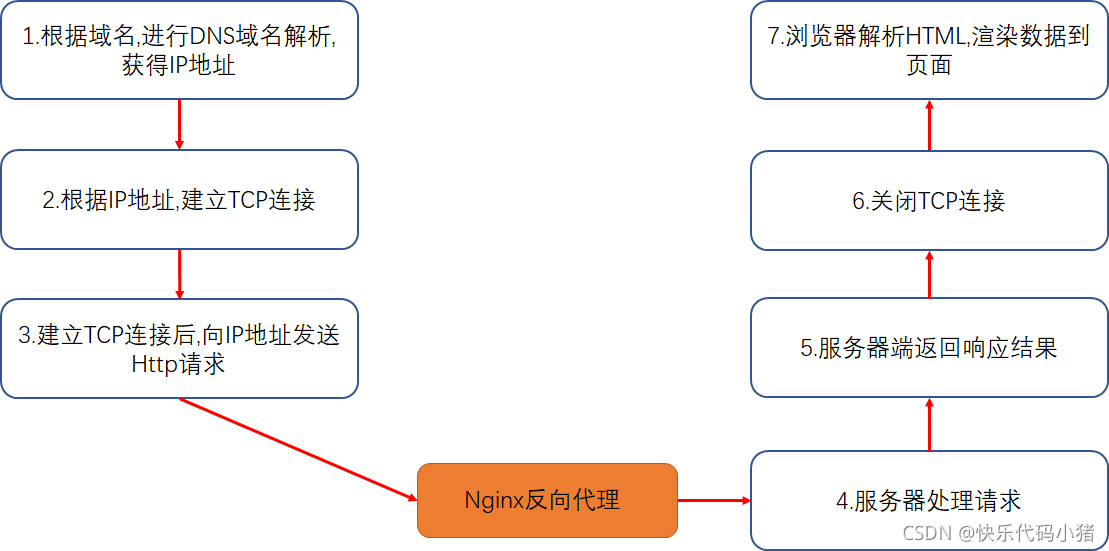
如上圖所示,在瀏覽器的位址列中輸入url : 此時執行過程簡單地介紹如下所示
第一步 : 我們的DNS域名解析器會對url進行域名解析,找到對應的IP節點進行返回
第二步 : 拿到我們存取的IP,我們就要與對應的伺服器建立TCP連線(三次握手)
第三步 : TCP連線建立成功,我們就可以向伺服器傳送HTTP請求了,當伺服器獲取我們的請求,進行處理,然後將請求的響應返回給我們
第四步 : 關閉TCP連線(四次揮手)
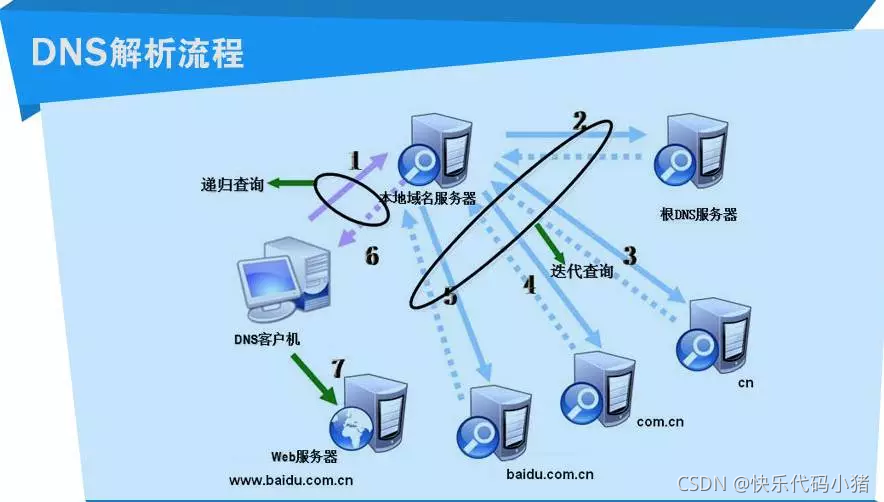
1.DNS域名解析(找到ip地址)
DNS是進行域名和與之相對應的IP地址轉換的伺服器
瀏覽器會首先搜尋瀏覽器自身的DNS快取,如果瀏覽器自身的快取裡面沒有找到對應的條目,
那麼瀏覽器會搜尋作業系統自身的DNS快取,作業系統域名解析的過程是讀取hosts檔案(位於C:\Windows\System32\drivers\etc),如果在hosts檔案中也沒有找到對應的條目,
瀏覽器就會找TCP/IP引數中設定的首選DNS伺服器(本地DNS伺服器)發起一個DNS的系統呼叫(運營商dns-->根(13臺)域名伺服器-->頂級域名伺服器-->域名註冊商伺服器)
從使用者端到本地DNS伺服器是屬於遞迴查詢,而DNS伺服器之間就是的互動查詢就是迭代查詢。
2.發起TCP三次握手,建立連線
3.發起http請求,伺服器響應給瀏覽器html程式碼
4.瀏覽器解析html程式碼,並請求html程式碼中的資源(如js,css,圖片等)
5.瀏覽器對頁面進行渲染呈現給使用者
將URL對應的各種資源,通過瀏覽器渲染引擎,輸出視覺化的影象
渲染引擎主要包括:html解析器,css解析器,佈局,js引擎
html引擎:將html文字解釋成DOM樹(檔案物件模型)
css直譯器:為dom中的各個元素物件加上樣式資訊(CSS物件模型)
佈局:將dom和css樣式資訊結合起來,計算他們的大小及位置資訊,構建(渲染樹)
js引擎:解釋js程式碼並把程式碼邏輯對應的dom和css改動資訊應用到佈局中去
輸入一個網址之後會發生什麼,用到了哪些協定
輸入一個網址以後,首先會進行DNS域名解析,找到目標的IP地址,然後和目標地址建立TCP連線,連線成功以後,傳送HTTP請求,目標伺服器處理完請求以後,返回響應結果,最後關閉TCP連線
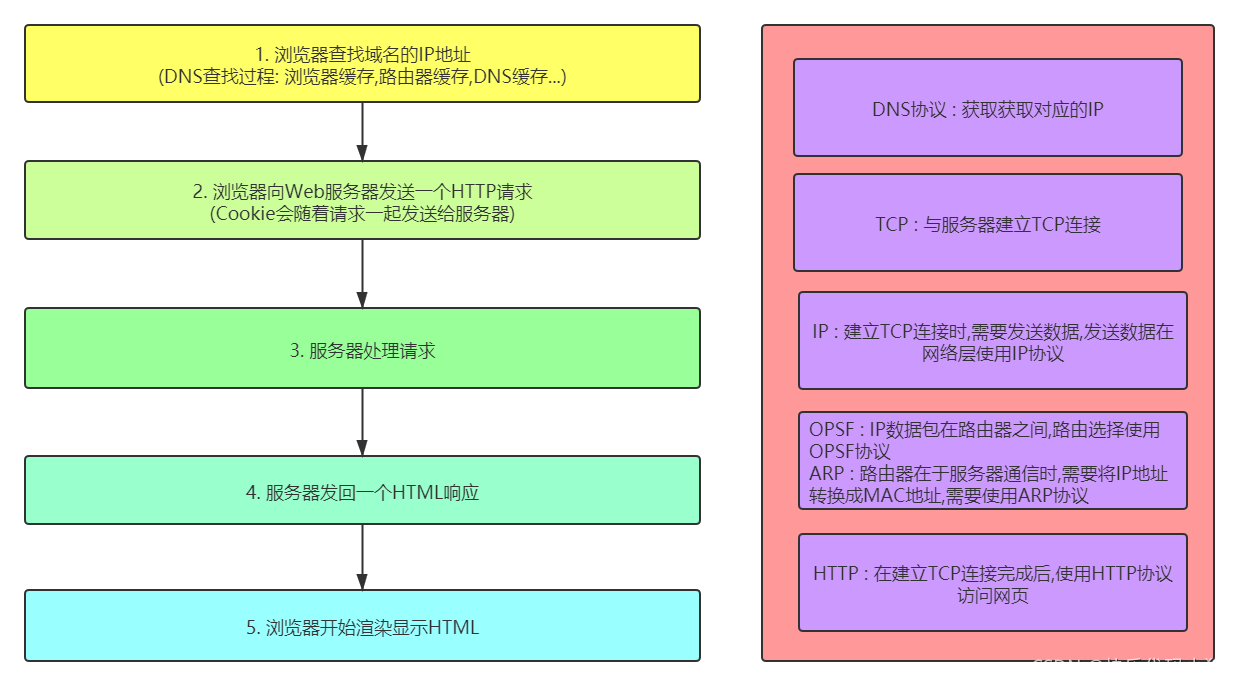
網路間兩個主機通訊過程,用到了哪些裝置
設存在兩個主機 : 主機A和主機B,網路間主機A和主機B的通訊過程分為兩種情況
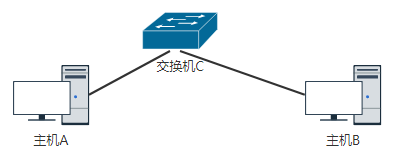
情況1 : 主機A和主機B位於同一個二層網路中,此時直接走二層交換機
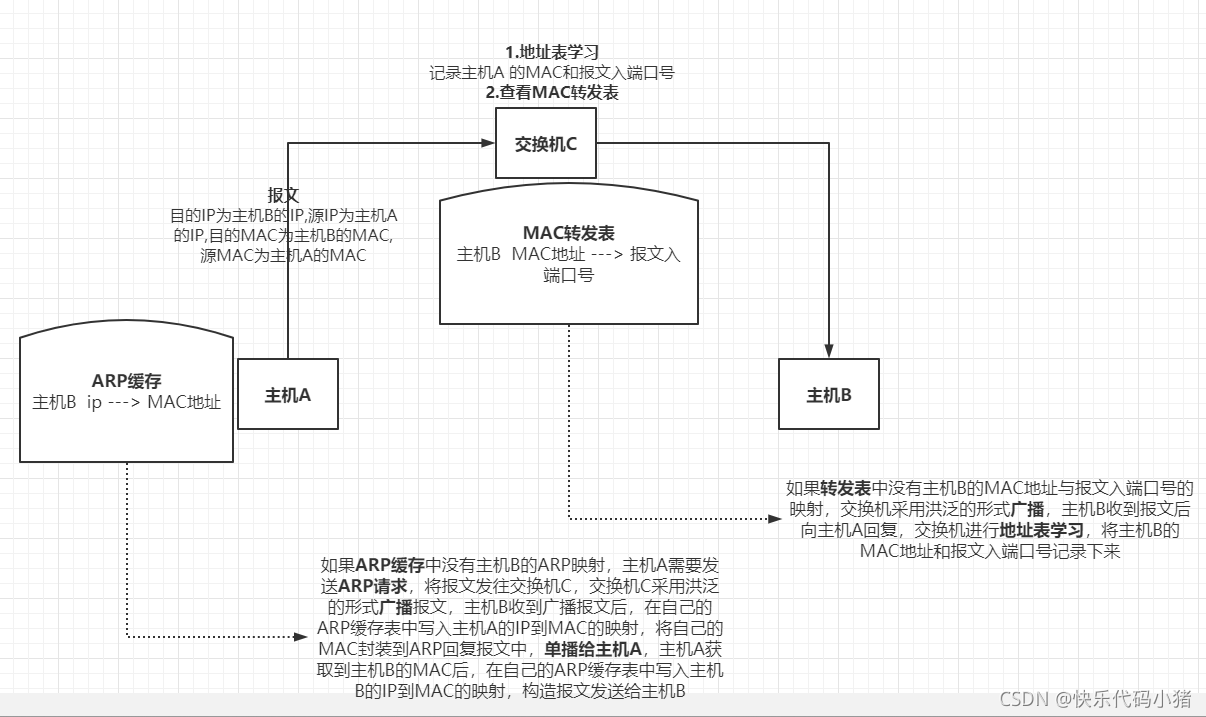
主機A首先檢視自己的ARP快取,檢查是否含有主機B的IP到MAC地址的對映,如果存在對映,則構造報文,目的IP為主機B的IP,源IP為主機A的IP,目的MAC為主機B的MAC,源MAC為主機A的MAC,將報文傳送給交換機C.交換機C進行MAC地址表學習,將主機A和MAC和報文入埠號記錄下來,然後交換機C檢視自己的MAC轉發表,檢查是否含有主機B的MAC到埠的對映,如果有對應的埠,則獲取對應的埠,將報文從此埠轉發出去,報文到達主機B.如果交換機C沒有主機B的MAC轉發對映表,則採用洪泛的形式廣播報文,主機B收到報文後向主機A進行回覆,交換機C進行MAC表學習,將主機B的MAC和報文入埠號記錄下來
如果主機A沒有主機B的ARP對映,主機A需要傳送ARP請求,以獲取主機B的MAC,將報文發往交換機C,交換機C採用洪泛的形式廣播報文,主機B收到廣播報文後,在自己的ARP快取表中寫入主機A的IP到MAC的對映,將自己的MAC封裝到ARP回覆報文中,單播給主機A,主機A獲取到主機B的MAC後,在自己的ARP快取表中寫入主機B的IP到MAC的對映,構造報文傳送給主機B,過程同上。
主機B向主機A回覆報文的過程類似。
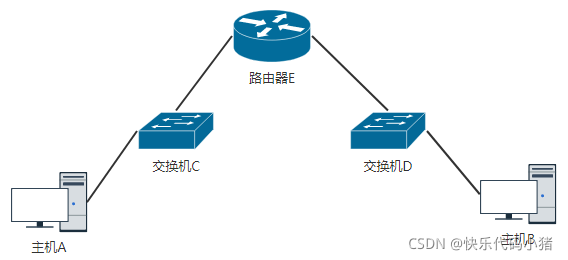
情況2 : 主機A和主機B不在同一層網路中,需要走三層路由器 + 二層交換機
主機A檢視自己的ARP快取表,檢查是否有路由器E的IP到MAC的對映,如果有對映,獲取路由器E的MAC,構造報文,目的IP為主機B的IP,源IP為主機A的IP,目的MAC為路由器E的MAC,源MAC為主機A的MAC,將報文通過交換機C發往路由器E,過程同上。 如果主機A沒有路由器E的IP到MAC的對映,需要傳送ARP請求,獲取路由器E的MAC,過程同上。路由器E收到主機A的報文後,剝離報文的MAC幀頭,查詢路由表,發現目標主機B所在的網路是直連的,檢視自己的ARP快取表,如果有主機B的IP到MAC的對映關係,獲取主機B的MAC,封裝報文MAC幀頭,目的MAC為主機B的MAC,源MAC為路由器E的MAC,將報文通過交換機D發往主機B,如果路由器E沒有主機B的IP到MAC的對映關係,需要傳送ARP請求,獲取主機B的MAC,過程同上。
主機B向主機A回覆報文的過程類似。
注意 :
- 路由器上的路由表一般是設定靜態路由或者通過路由協定自動學習的
ARP協定和ARP攻擊
ARP協定
ARP協定指的是地址解析協定(Address Resolution Protocol),是根據**IP地址獲取實體地址(MAC地址)**的一個TCP/IP協定.
在計算機間通訊的時候,計算機要知道目的計算機是誰(就像我們人交流一樣,要知道對方是誰),這中間需要涉及到MAC地址,而MAC是真正的電腦的唯一識別符號。
我們通過兩個主機之間的ping連線,來看一下簡單的ARP請求應答
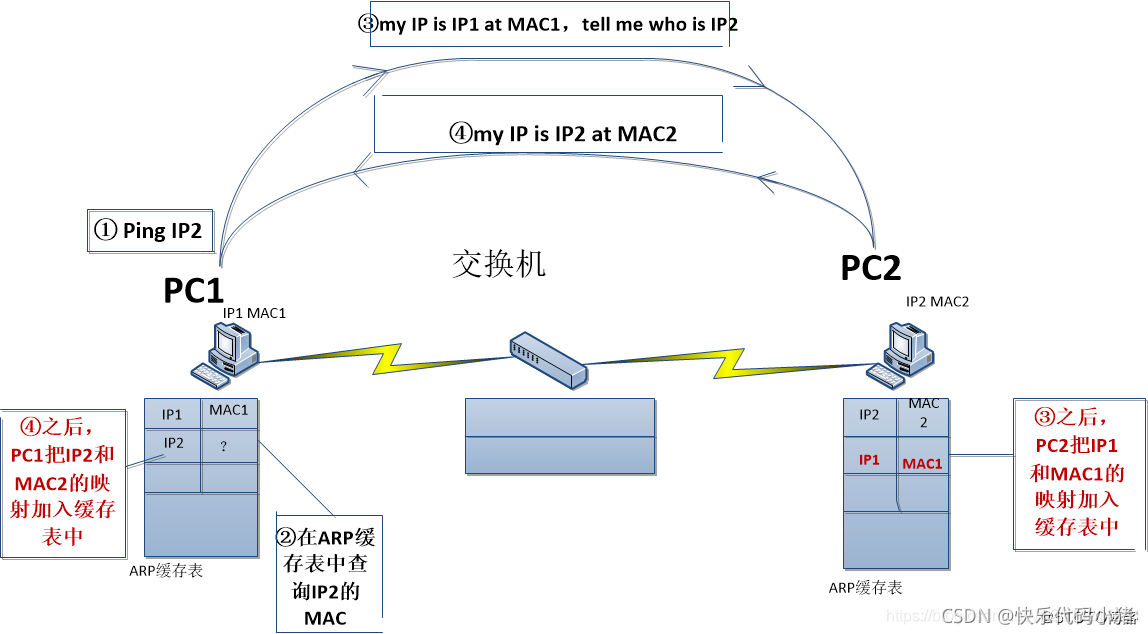
PC1依據OSI模型 :
① 依次從上至下對資料進行封裝,包括對ICMP Date加IP包頭的封裝,但是到了封裝MAC地址的時候
② PC1首先查詢自己的ARP快取表,發現沒有IP2和他的MAC地址的對映,這個時候MAC資料框封裝失敗。我們使用ping命令的時候,是指定PC2的IP2的,計算機是知道目的主機的IP地址,能夠完成網路層的資料封裝,因為裝置通訊還需要對方的MAC地址,但是PC1的快取表裡沒有,所以在MAC封裝的時候填入不了目的MAC地址。
那麼PC1為了獲取PC2的MAC地址 :
③ PC1要傳送詢問資訊,詢問PC2的MAC地址,詢問資訊包括PC1的IP和MAC地址、PC2的IP地址,這裡我們想到一個問題,即使是詢問資訊,也是需要進行MAC資料框的封裝,那這個詢問資訊的目的MAC地址填什麼呢,規定當目的MAC地址為ff-ff-ff-ff-ff-ff時,就代表這是一個詢問資訊,也即使後面我要說的廣播。
PC2收到這個詢問資訊後,將這裡面的IP1和MAC1(PC1的IP和MAC)新增到原生的ARP快取表中,然後 :
④ PC2傳送應答資訊,對資料進行IP和MAC的封裝,傳送給PC1,因為快取表裡已經有PC1的IP和MAC的對映了呢。這個應答資訊包含PC2的IP2和MAC2。PC1收到這個應答資訊,理所應當的就獲取了PC2的MAC地址,並新增到自己的快取表中。
經過這樣互動式的一問一答,PC1和PC2都獲得了對方的MAC地址,值得注意的是,目的主機先完成ARP快取,然後才是源主機完成ARP快取。之後PC1和PC2就可以真正交流了。
ARP攻擊
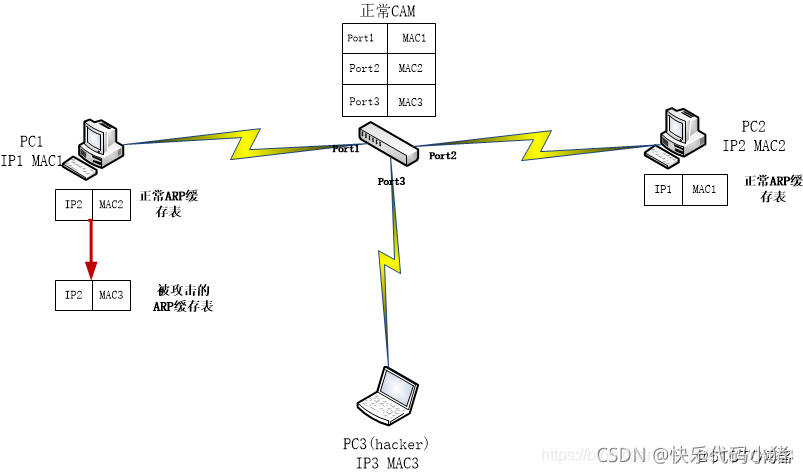
對於交換機而言,它也具有記憶功能,會基於源MAC地址建立一個CAM快取表(記錄MAC對應介面的資訊),理解為當PC1傳送訊息至交換機的Port1時,交換機會把源MAC(也就是MAC1)記錄下來,新增一條MAC1和Port1的對映,之後交換機可以根據MAC幀的目的MAC進行埠轉發
ICMP協定
它是TCP/IP協定族的一個子協定,用於在IP主機、路由器之間傳遞控制訊息。控制訊息是指網路通不通、主機是否可達、路由是否可用等網路本身的訊息。這些控制訊息雖然並不傳輸使用者資料,但是對於使用者資料的傳遞起著重要的作用。
路由器和交換機的區別
(1)外形上:
交換機通常埠比較多看起來比較笨重,而路由器的埠就少得多體積也小得多
(2)工作層次不同:
最初的交換機工作在資料鏈路層,而路由器則工作網路層
(3)資料的轉發物件不同:
交換機是根據MAC地址轉發資料框,而路由器則是根據IP地址來轉發IP資料。
(4)」分工「不同
交換機主要是用於組建區域網,而路由器則是負責讓主機連線外網。
(5)衝突域和廣播域
交換機分割衝突域,但是不分割廣播域,而路由器分割廣播域。
(6)工作原理
交換機的原理比較簡單,一般都是採用硬體電路實現資料框的轉發
路由器工作在網路層,肩負著網路互聯的重任,要實現更加複雜的協定,具有更加智慧的轉發決策功能,一般都會在在路由器中跑作業系統,實現複雜的路由演演算法,更偏向於軟體實現其功能。
(7)安全效能
路由器一般有防火牆的功能,能夠對一些網路封包選擇性過濾。現在的一些路由器都具備交換機的功能,一些交換機具備路由器的功能,被稱為3層交換機,廣泛使用。相比較而言,路由器的功能較交換機要強大,但是速度也較慢,價格昂貴,三層交換機既有交換機的線性轉發報文的能力,又有路由器的良好的路由功能因此得到廣泛的使用
cdn (網易雲音樂)(位元組)
由於我們使用本地域名解析器進行解析,獲取源伺服器IP導致每一次獲取資料,都要去源伺服器進行存取獲取,造成效能的損失的降低,故我們在網路各處部署節點伺服器,構建CDN系統,當我們使用本地DNS域名系統進行解析的時候,DNS系統會將域名解析交給CNAME指向的專用的DNS伺服器,通過CDN的DNS伺服器獲取到一臺合適的快取伺服器IP給我們,這裡的合適性指的是(伺服器距離我們的距離位置,該伺服器上是否存在我們需要的內容等等…),此時我們就與該快取伺服器建立TCP連線,已經後續的HTTP請求獲取資料,得到響應等過程,如果該節點伺服器不能滿足我們的需求,我們會層層向它的上級伺服器進行存取,直到源伺服器為止.
cdn(內容分發網路)
(Content Delivery Network)
就近存取原理:採用各種快取伺服器,將這些快取伺服器分佈到使用者存取相對集中的地區或網路,在使用者存取網站時,利用全域性負載技術將使用者的存取指向距離最近的工作正常的快取伺服器上,由快取伺服器直接響應使用者請求。cdn就是用來加速的,他能讓使用者就近存取資料,這樣就更更快的獲取到需要的資料。
舉個例子,現在伺服器在北京,深圳的使用者想要獲取伺服器上的資料就需要跨越一個很遠的距離,這顯然就比北京的使用者存取北京的伺服器速度要慢。但是現在我們在深圳建立一個cdn伺服器,上面快取住一些資料,深圳使用者存取時先存取這個cdn伺服器,如果伺服器上有使用者請求的資料就可以直接返回,這樣速度就大大的提升了。
代售點優勢:大部分請求在CDN邊緣完成,起到了分流的作用,減輕源站的負載。
dns(域名解析)
我們怎麼知道使用者的所在位置從而給他分配最佳的cdn節點呢。這就需要dns服務來進行定位了。
當我們在瀏覽器中輸入一個域名時,首先需要將域名轉換為ip地址,再將ip地址轉換為mac地址,這樣才能在網路上找到該伺服器。當我們向dns伺服器發起解析域名的請求時,dns伺服器首先會查詢自己的快取中有沒有該域名,如果快取中存在該域名,則可以直接返回ip地址。如果快取中沒有,伺服器則會以遞迴的方式層層存取。例如,我們要存取www.baidu.com,首先我們會先向全球13個根伺服器發起請求,詢問com域名的地址,然後再向負責com域名的名稱伺服器傳送請求,找到baidu.com,這樣層層遞迴,最終找到我們需要的ip地址。
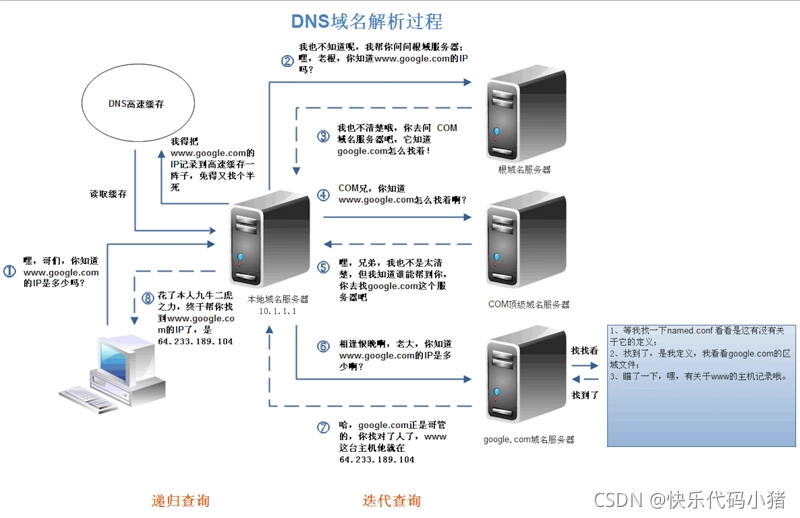
dns劫持
DNS劫持又稱為域名劫持,是一種惡意攻擊,駭客或其他方通過使用流氓DNS伺服器或其他策略來重定向使用者,該策略更改了Internet使用者被重定向到的IP地址。
防範DNS汙染
DNS汙染最常見的就是篡改host主機檔案,通過篡改DNS主機檔案ip地址和網址將不再一一對應,開啟的網站將不是最初想要存取的網站。
- 53埠為DNS伺服器所開放,主要用於域名解析。如果開放DNS服務,駭客可以通過分析DNS伺服器而直接獲取web伺服器等主機的ip地址,在利用53埠突破某些不穩定的防火牆,從而實施攻擊。如果不用於提供域名解析服務,建議關閉該埠。
- 使用RNDC加密,存根區域,減少DNS的生命週期(RNDC是一種控制域名伺服器的工具,通過網路與DNS伺服器進行連線,實現不停止DNS伺服器工作的情況下進行資料更新)
- 檢查授權名稱伺服器是否和主機上的解析一致。早期的網際網路連線需要進行反向地址解析,至今SMTP右鍵伺服器還在使用。
DNS使用什麼協定
DNS區域傳輸的時候使用TCP協定:
輔域名伺服器會定時向主域名伺服器進行查詢以便瞭解資料是否變動。如有變動,會執行一次區域傳送,進行資料同步。
域名解析時使用UDP協定:
使用者端向DNS伺服器查詢域名,一般返回的內容都不超過512位元組,用UDP傳輸即可。不用經過三次握手,這樣DNS伺服器負載更低,響應更快。
cdn快取的兩種方式
cdn中快取了伺服器上的部分資源。
-
伺服器主動去更新快取,cdn節點被動接受
-
另一種方式是當使用者請求的資源不存在時,cdn伺服器向上遊伺服器發起請求,更新快取,然後將資料返回給使用者,這種方式是cdn伺服器主動,源站伺服器被動。(一般採用這種方式)
Nginx反向代理
當我們與DNS域名解析器解析的IP伺服器建立TCP連線以後,此時向其傳送請求時,我們可以在其中建立Nginx反向代理,可以實現
負載均衡,遮蔽真實地址,安全管理,解決跨域問題,節約有效的IP資源,減少web伺服器壓力,提高響應速度
Nginx是一個輕量級/高效能的反向代理Web伺服器,他實現非常高效的反向代理、負載均衡.
使用Nginx的好處
- 保護了真實的web伺服器,使得web伺服器對外不可見。外網只能看到反向代理伺服器,而反向代理伺服器上並沒有真實資料,因此保護了web伺服器的資源安全。
- 節約了有限的IP地址資源
企業內部所有的網站共用一個在Internet中註冊的IP地址,這些伺服器分配私有地址,採用虛擬主機的方式對外提供服務。
- 減少web伺服器壓力,提高響應速度
反向代理就是通常所說的web伺服器加速,它是一種通過在繁忙的web伺服器和外部網路之間增加一個高速的web緩衝伺服器來降低實際的web伺服器的負載的一種技術。反向代理伺服器會強制將外部網路對要代理的伺服器的存取經過它,它會將從源伺服器上獲取到的靜態內容快取到本地,以便日後再收到同樣的資訊請求時,直接將本地快取的內容發給使用者端,減少後端web伺服器的壓力,提高響應速度。
-
其他優點
請求的統一控制,包括設定許可權,過濾規則等。
區分動態和靜態可快取內容。
實現負載均衡,內部可以採用多臺伺服器來組成伺服器叢集,外部還是可以採用一個地址存取。
解決ajax跨域問題。
作為真實伺服器的快取,解決瞬間負載量大的問題。
設定簡單
佔記憶體小,可實現高並行連線,處理響應快
Nginx的缺點
處理動態頁面很慢
為什麼Nginx的效能這麼高?
因為他的事件處理機制:非同步非阻塞事件處理機制(運用了epoll模型,提供了一個佇列,排隊解決)
Nginx怎麼處理請求的?
nginx接收一個請求後,首先由listen和server_name指令匹配server模組,再匹配server模組裡的location,location就是實際地址
server { # 第一個Server區塊開始,表示一個獨立的虛擬主機站點
listen 80; # 提供服務的埠,預設80
server_name localhost; # 提供服務的域名主機名
location / { # 第一個location區塊開始
root html; # 站點的根目錄,相當於Nginx的安裝目錄
index index.html index.htm; # 預設的首頁檔案,多個用空格分開
} # 第一個location區塊結果
什麼是正向代理和反向代理?
-
正向代理類似一個跳板機,代理存取外部資源。(正向代理就是一個人傳送一個請求直接就到達了目標的伺服器)
比如我們國記憶體取谷歌,直接存取存取不到,我們可以通過一個正向代理伺服器,請求發到代理服,代理伺服器能夠存取谷歌,這樣由代理去谷歌取到返回資料,再返回給我們,這樣我們就能存取谷歌了

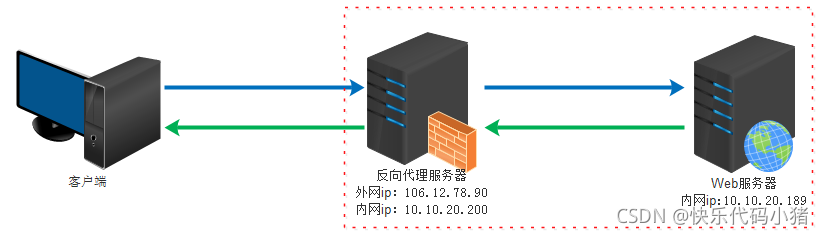
2.反向代理(Reverse Proxy)對外就表現為一個伺服器。(反方代理就是請求統一被Nginx接收,nginx反向代理伺服器接收到之後,按照一定的規則分發給了後端的業務處理伺服器進行處理了)
實際執行方式是指以代理伺服器來接受internet上的連線請求,然後將請求轉發給內部網路上的伺服器,並將從伺服器上得到的結果返回給internet上請求連線的使用者端,此時代理伺服器對外就表現為一個伺服器
Nginx的應用場景
- http伺服器。Nginx是一個http服務可以獨立提供http服務。可以做網頁靜態伺服器。
- 虛擬主機。可以實現在一臺伺服器虛擬出多個網站,例如個人網站使用的虛擬機器器。
- 反向代理,負載均衡。當網站的存取量達到一定程度後,單臺伺服器不能滿足使用者的請求時,需要用多臺伺服器叢集可以使用nginx做反向代理。並且多臺伺服器可以平均分擔負載,不會應為某臺伺服器負載高宕機而某臺伺服器閒置的情況。
- Nginx 中也可以設定安全管理、比如可以使用Nginx搭建API介面閘道器,對每個介面服務進行攔截。
Nginx目錄結構有哪些?
[root@localhost ~]# tree /usr/local/nginx
/usr/local/nginx
├── client_body_temp
├── conf # Nginx所有組態檔的目錄
│ ├── fastcgi.conf # fastcgi相關引數的組態檔
│ ├── fastcgi.conf.default # fastcgi.conf的原始備份檔案
│ ├── fastcgi_params # fastcgi的引數檔案
│ ├── fastcgi_params.default
│ ├── koi-utf
│ ├── koi-win
│ ├── mime.types # 媒體型別
│ ├── mime.types.default
│ ├── nginx.conf # Nginx主組態檔,很重要!!!
│ ├── nginx.conf.default
│ ├── scgi_params # scgi相關引數檔案
│ ├── scgi_params.default
│ ├── uwsgi_params # uwsgi相關引數檔案
│ ├── uwsgi_params.default
│ └── win-utf
├── fastcgi_temp # fastcgi臨時資料目錄
├── html # Nginx預設站點目錄
│ ├── 50x.html # 錯誤頁面優雅替代顯示檔案,例如當出現502錯誤時會呼叫此頁面
│ └── index.html # 預設的首頁檔案
├── logs # Nginx紀錄檔目錄
│ ├── access.log # 存取紀錄檔檔案
│ ├── error.log # 錯誤紀錄檔檔案
│ └── nginx.pid # pid檔案,Nginx程序啟動後,會把所有程序的ID號寫到此檔案
├── proxy_temp # 臨時目錄
├── sbin # Nginx命令目錄
│ └── nginx # Nginx的啟動命令
├── scgi_temp # 臨時目錄
└── uwsgi_temp # 臨時目錄
其他計算機網路問題
1. 你怎麼理解認證和許可權的,為什麼使用jwt不使用session、cookie?
答: 首先當前我們的網路存在很多的惡意攻擊,例如XSS,CSRF等等,我們使用者端給伺服器傳送請求,存取伺服器時,伺服器需要對我們的請求進行相應的認證,同時對於我們使用者端授予不同的許可權,擁有相應的許可權才能存取伺服器,傳送相應的請求資訊。
1.1 對於jwt,我們首先需要了解它是什麼?
jwt(Json web token) : 是為了在網路應用環境中傳遞宣告而執行的一種基於JSON的開放標準(RFC 7519)
其中對應生成的token被設計成緊湊且安全的,特別適用於分散式站點的單點登入(SSO)場景
JWT的宣告一般被用來在身份提供者和服務提供者間傳遞被認證的使用者身份資訊,以便於從資源伺服器獲取資源,也可以增加一些額外的其它業務邏輯所必須的宣告資訊,該token可直接被用於認證,也可被加密。

1.2 JWT的組成
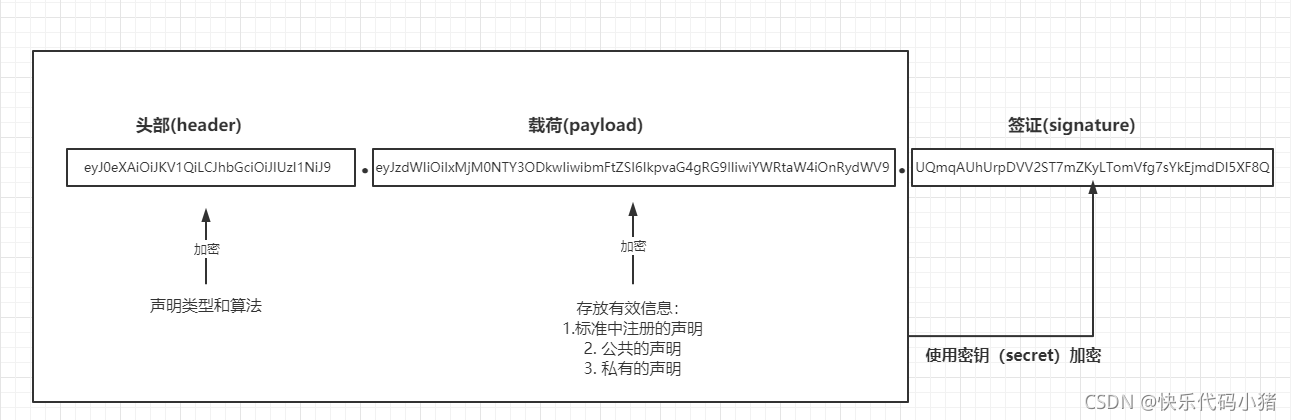
JWT生成編碼以後是以下的樣子:
eyJ0eXAiOiJKV1QiLCJhbGciOiJIUzI1NiJ9.eyJzdWIiOiIxMjM0NTY3ODkwIiwibmFtZSI6IkpvaG4gRG9lIiwiYWRtaW4iOnRydWV9.UQmqAUhUrpDVV2ST7mZKyLTomVfg7sYkEjmdDI5XF8Q
JWT由三個部分組成:
- 頭部(header)
- 載荷(payload)
- 簽證(signature)
頭部(header):
- 宣告型別,這裡是jwt
- 宣告加密的演演算法,通常為HMAC演演算法
HMAC演演算法介紹:
完整的頭部head資訊就像下面的JSON:
{
'typ': 'JWT',
'alg': 'HS256'
}
然後我們會對頭部資訊進行加密,構成第一部分:
eyJ0eXAiOiJKV1QiLCJhbGciOiJIUzI1NiJ9
載荷(payload):
載荷是存放有效資訊的地方,有效資訊包括三個部分:
- 標準中註冊的宣告
- 公共的宣告
- 私有的宣告
其中,標準中註冊的宣告(建議但是不強制使用) :
- iss: jwt簽發者
- sub: jwt所面向的使用者
- aud: 接收jwt的一方
- exp: jwt的過期時間,這個過期時間必須要大於簽發時間
- nbf: 定義在什麼時間之前,該jwt都是不可用的.
- iat: jwt的簽發時間
- jti: jwt的唯一身份標識,主要用來作為一次性token,從而回避重放攻擊。
公共的宣告:
- 可以新增任何資訊,一般新增使用者的相關資訊或其他業務需要的必要資訊.但不建議新增敏感資訊,因為該部分在使用者端可解密.
私有宣告:
- 提供者和消費者所共同定義的宣告,一般不建議存放敏感資訊,因為base64是對稱解密的,意味著該部分資訊可以歸類為明文資訊
我們這裡定義一個payload:
{
"sub": "1234567890",
"name": "John Doe",
"admin": true
}
進行加密處理以後,構成第二部分:
eyJzdWIiOiIxMjM0NTY3ODkwIiwibmFtZSI6IkpvaG4gRG9lIiwiYWRtaW4iOnRydWV9
簽證(signature):
jwt的第三部分是一個簽證資訊,一般由三個部分組成:
- header(加密以後的)
- payload(加密以後的)
- secret
UQmqAUhUrpDVV2ST7mZKyLTomVfg7sYkEjmdDI5XF8Q
其中金鑰是儲存在伺服器端的,伺服器端會根據這個金鑰生成token和驗證,所以必須要儲存好!!!
1.3 簽名的目的:
最後一步簽名的過程,實際上是對頭部以及載荷內容進行簽名。一般而言,加密演演算法對於不同的輸入產生的輸出總是不一樣的。對於兩個不同的輸入,產生同樣的輸出的概率極其地小.
所以,如果有人對頭部以及載荷的內容解碼之後進行修改,再進行編碼的話,那麼新的頭部和載荷的簽名和之前的簽名就將是不一樣的。而且,如果不知道伺服器加密的時候用的金鑰的話,得出來的簽名也一定會是不一樣的.
伺服器應用在接受到JWT後,會首先對頭部和載荷的內容用同一演演算法再次簽名。那麼伺服器應用是怎麼知道我們用的是哪一種演演算法呢?別忘了,我們在JWT的頭部中已經用alg欄位指明瞭我們的加密演演算法了。
如果伺服器應用對頭部和載荷再次以同樣方法簽名之後發現,自己計算出來的簽名和接受到的簽名不一樣,那麼就說明這個Token的內容被別人動過的,我們應該拒絕這個Token,返回一個HTTP 401 Unauthorized響應。
注意:
- 在JWT中不應該在載荷中存放任何敏感的資訊,比如使用者的密碼等等
1.4 JWT如何使用?
一般會在請求頭中加入Authoriation,並加入Bearer標註:
fetch('api/user/1', {
headers: {
'Authorization': 'Bearer ' + token
}
})
伺服器端會驗證token,如果驗證通過就會返回相應的資源!
1.5 JWT的安全相關
- 不應該在jwt的payload部分存放敏感資訊,因為該部分是使用者端可解密的部分。
- 保護好secret私鑰,該私鑰非常重要。
- 如果可以,請使用https協定
1.6 對Token認證的五點認識:
- 一個Token就是一些資訊的集合;
- 在Token中包含足夠多的資訊,以便在後續請求中減少查詢資料庫的機率;
- 伺服器端需要對cookie和HTTP Authrorization Header進行Token資訊的檢查;
- 基於上一點,你可以用一套token認證程式碼來面對瀏覽器類使用者端和非瀏覽器類使用者端;
- 因為token是被簽名的,所以我們可以認為一個可以解碼認證通過的token是由我們系統發放的,其中帶的資訊是合法有效的;
2. JWT認證和傳統的Session認證的比較
2.1 傳統的session認證
我們知道,http協定本身是一種無狀態的協定,而這就意味著如果使用者向我們的應用提供了使用者名稱和密碼來進行使用者認證,那麼下一次請求時,使用者還要再一次進行使用者認證才行,因為根據http協定,我們並不能知道是哪個使用者發出的請求,所以為了讓我們的應用能識別是哪個使用者發出的請求,我們只能在伺服器儲存一份使用者登入的資訊,這份登入資訊會在響應時傳遞給瀏覽器,告訴其儲存為cookie,以便下次請求時傳送給我們的應用,這樣我們的應用就能識別請求來自哪個使用者了,這就是傳統的基於session認證。
2.2 基於session認證所顯露的問題
Session: 每個使用者經過我們的應用認證之後,我們的應用都要在伺服器端做一次記錄,以方便使用者下次請求的鑑別,通常而言session都是儲存在記憶體中,而隨著認證使用者的增多,伺服器端的開銷會明顯增大。
擴充套件性: 使用者認證之後,伺服器端做認證記錄,如果認證的記錄被儲存在記憶體中的話,這意味著使用者下次請求還必須要請求在這臺伺服器上,這樣才能拿到授權的資源,這樣在分散式的應用上,相應的限制了負載均衡器的能力。這也意味著限制了應用的擴充套件能力。
CSRF: 因為是基於cookie來進行使用者識別的, cookie如果被截獲,使用者就會很容易受到跨站請求偽造的攻擊。
2.3 基於token的鑑權機制
基於token的鑑權機制類似於http協定也是無狀態的,它不需要在伺服器端去保留使用者的認證資訊或者對談資訊。這就意味著基於token認證機制的應用不需要去考慮使用者在哪一臺伺服器登入了,這就為應用的擴充套件提供了便利。
它的流程如下所示:
- 使用者使用使用者名稱和密碼來請求伺服器
- 伺服器進行驗證使用者的資訊
- 伺服器通過驗證傳送給使用者一個token
- 使用者端儲存token,並在每次請求時附上這個token值
- 伺服器端驗證token值,並返回資料
這個token值必須在每次請求時傳遞給伺服器端,它應該儲存在請求頭中,另外,伺服器端要支援CORS(跨來源資源共用)策略,一般我們在伺服器端這麼做就可以了(Access-Control-Allow-Origin)
2.4 token方式的優點
- 支援跨域存取: Cookie是不允許垮域存取的,這一點對Token機制是不存在的,前提是傳輸的使用者認證資訊通過HTTP頭傳輸。
- 無狀態(也稱:伺服器端可延伸行):Token機制在伺服器端不需要儲存session資訊,因為Token 自身包含了所有登入使用者的資訊,只需要在使用者端的cookie或本地媒介儲存狀態資訊。
- 更適用CDN: 可以通過內容分發網路請求你伺服器端的所有資料(如:javascript,HTML,圖片等),而你的伺服器端只要提供API即可。
- 去耦: 不需要繫結到一個特定的身份驗證方案。Token可以在任何地方生成,只要在你的API被呼叫的時候,你可以進行Token生成呼叫即可。
- 更適用於移動應用: 當你的使用者端是一個原生平臺(iOS, Android,Windows 8等)時,Cookie是不被支援的(你需要通過Cookie容器進行處理),這時採用Token認證機制就會簡單得多。
- CSRF:因為不再依賴於Cookie,所以你就不需要考慮對CSRF(跨站請求偽造)的防範。
- 效能: 一次網路往返時間(通過資料庫查詢session資訊)總比做一次HMACSHA256計算 的Token驗證和解析要費時得多。
- 不需要為登入頁面做特殊處理: 如果你使用Protractor 做功能測試的時候,不再需要為登入頁面做特殊處理。
- 基於標準化:你的API可以採用標準化的 JSON Web Token (JWT). 這個標準已經存在多個後端庫(.NET, Ruby, Java,Python, PHP)和多家公司的支援(如:Firebase,Google, Microsoft)。
- 因為json的通用性,所以JWT是可以進行跨語言支援的,像JAVA,JavaScript,NodeJS,PHP等很多語言都可以使用。
- 因為有了payload部分,所以JWT可以在自身儲存一些其他業務邏輯所必要的非敏感資訊。
- 便於傳輸,jwt的構成非常簡單,位元組佔用很小,所以它是非常便於傳輸的。
- 它不需要在伺服器端儲存對談資訊, 所以它易於應用的擴充套件。
2.5 java實現JWT
2.6 JWT和SpringSecurity的比較
JWT的優點:
- 無需再伺服器端儲存使用者資料,減輕伺服器端壓力
- 輕量級,json風格,比較簡單
- 跨語言
JWT的缺點:
- token一旦簽發,無法修改
- 無法更新token有效期,使用者登入狀態重新整理難以實現
- 無法銷燬一個token,伺服器端不能對使用者狀態進行絕對控制
- 不包含許可權控制
SpringSecurity的優點:
- 使用者資訊儲存在伺服器端,伺服器端可以對使用者狀態絕對控制
- 基於Spring,無縫整合,修改登入邏輯,其實就是新增過濾器
- 整合許可權管理
SpringSecurity的缺點:
- 實現複雜,基於一連串的過濾器鏈
- 需要再伺服器端儲存使用者資訊,增加伺服器端壓力
2.7 使用JWT做登入認證,如何解決token的登出問題
方案1 : 適當減短token的有效期,讓token儘快失效
方案2 : 使用redis (即使用JWT還要使用redis的場景)
(1) 我們在使用者登入時,生成JWT
(2) 把JWT的id儲存到redis中,只有redis資料庫中有id的JWT,才是有效的JWT
(3) 退出登入時,將對應的id從redis中刪除,即間接解決了token的登出問題
2.8 如何解決異地登入問題?
答:JWT設計為了實現無狀態的登入,因此token無法修改,難以實現異地登入的判斷,或者強制讓登入token失效。
因此如果有類似需求, 就不應選擇JWT作為登入方案,而是使用傳統session登入方案。
但是,如果一定要用JWT實現類似要過,就需要在Redis中記錄登入使用者的JWT的token資訊,這樣就成了有狀態的登入,但是這樣還不如一開始就選擇Session方案.
2.9 你覺得在微服務中是在微服務中實現認證和登入好還是在閘道器中實現好,為什麼?
我們一般選擇在閘道器中實現認證和登入.
我們的微服務隱藏在閘道器的後面,而且整個服務被Nginx反向代理,使用者只能看到nginx的地址,微服務暴露的可能性很低。
然後,即便真的暴露了,我們的微服務都做了嚴格的服務間鑑權處理,任何對微服務的存取都會被驗證是否有授權,如果沒有則會被攔截。具體實現:
- 會有一張表記錄每個微服務的id,和金鑰資訊
- 服務啟動時,需要去授權中心,認證身份,攜帶id和secret
- 授權中心認證通過,會頒發一個JWT給微服務
- 微服務存取其它服務時,需要攜帶JWT
- 被存取的服務,需要驗證JWT,如果沒有攜帶,或token時偽造的直接攔截請求即可
3. Session和Cookie的面試題
3.1 對談
當一個使用者開啟一個瀏覽器或者存取一個網站時,只要不關閉這個瀏覽器,不管該使用者點選多少個超連結,存取多少個資源,直到該使用者關閉瀏覽器或者伺服器關閉.這樣一個過程稱為一個對談.
那麼在對談過程中需要解決一些問題 : 主要就是儲存使用者在存取過程中產生的資料
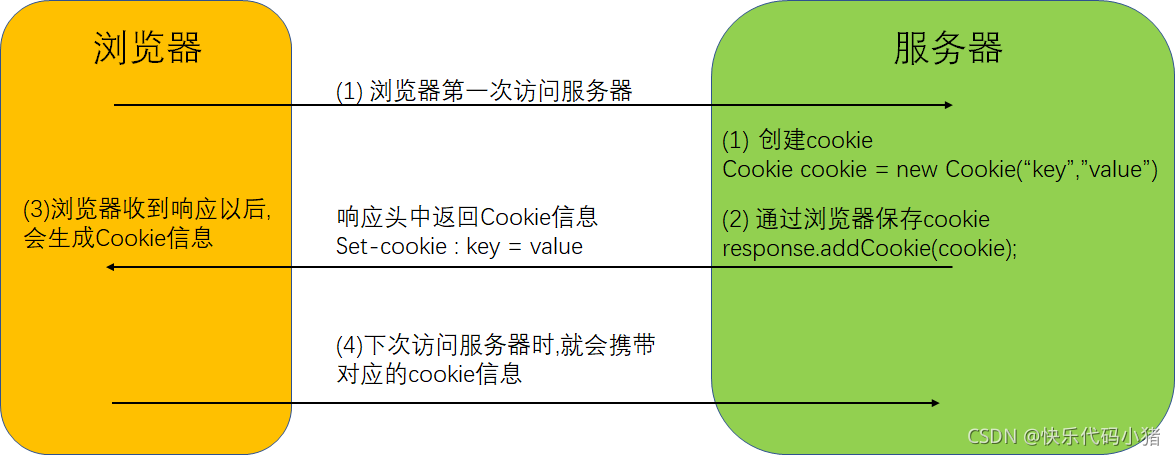
3.2 Cookie(瀏覽器端對談技術)
-
當瀏覽器第一次存取伺服器,給伺服器傳送請求時,伺服器端會建立一個鍵值對形式的Cookie,該Cookie中會包含當前使用者的資訊,然後通過響應(響應頭set-cookie)返回給瀏覽器端,cookie會儲存在瀏覽器端
-
下次存取的時候,瀏覽器會攜帶伺服器端建立的cookie(請求頭cookie),伺服器端就可以拿到這些cookie攜帶的資料區分不同的使用者,並拿到對應的資訊
注意:
- cookie不能跨瀏覽器
- cookie不支援中文
3.3 Session(伺服器端對談技術)
- 瀏覽器端第一次傳送請求到伺服器端,伺服器端會建立一個Session,同時會建立一個特殊的Cookie(name: JSESSIONID ,value: sessionid),然後將該cookie傳送給瀏覽器端
- 當瀏覽器端下次存取伺服器端時,都會攜帶這份JSESSIONID的Cookie物件
- 伺服器端會根據對應的sessionid會查詢Session物件,從而區分不同的使用者
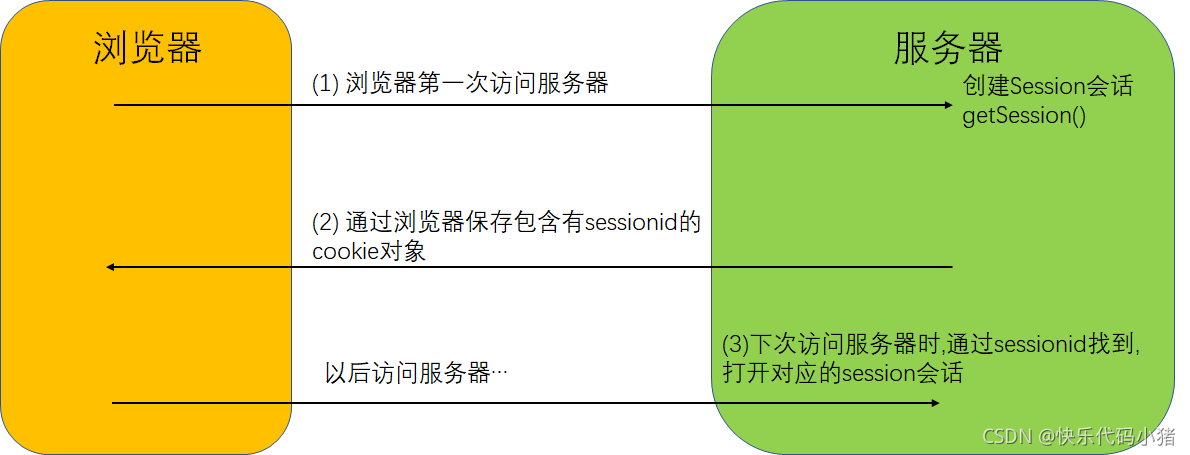
session的生命週期
-
建立 : 第一次存取伺服器,呼叫getSession()方法獲取session對談的時候
-
銷燬 : (1) 伺服器非正常關閉 (2) 設定超時時間(預設tomat伺服器是30分鐘) (3)瀏覽器關閉(手動銷燬)
3.4 Cookie和Session的區別
- 資料儲存的位置不同 : Cookie資料儲存在使用者端,而Session資料儲存在伺服器端
- 安全性不同 : cookie資訊一般是以明文的方式存放在使用者端的,安全性比較低,可以通過一個加密演演算法進行加密存放;session資訊存放在伺服器的記憶體中,安全性較好(所以我們一般將使用者密碼等安全級別較高的資訊存放在session中)
- 儲存大小的限制 : 單個cookie在使用者端的限制為4k,就是說一個站點在使用者端存放的cookie不能超過3k;session一般沒有限制,存放在伺服器端的記憶體中,但是存取過多,會增加伺服器的記憶體和效能.
- cookie為多個使用者瀏覽器共用; session為一個使用者瀏覽器獨享
3.5設定失效時間
session:
關閉瀏覽器,只會使瀏覽器中的sessionid消失,但不會使伺服器端的session物件消失。因此伺服器端需要設定一個過期時間,當距離客戶上一次使用session的時間超過了這個失效時間時就認為使用者端已經停止了活動,從而刪除session。session.setMaxInactiveInterval(3600);
cookie:
- 當設定失效時間大於1天時
Cookies.set('name', 'value', {
expires: 7, //設定失效時間為7天
});
- 當設定失效時間小於1天時,需要在當前時間上加上失效時間
var millisecond = new Date().getTime();
var expiresTime = new Date(millisecond + 60 * 1000 * 15); //設定過期時間為15分鐘後
Cookies.set('name', 'value', {
expires: expiresTime, //如果設定一個過去的時間點會直接刪除
});
4.sessionStorage和localStorage的區別
sessionStorage和localStorage均用於使用者端本地儲存資料
localStroage
不能設定過期時間。生命週期是永久性的,即使關閉瀏覽器也不會讓資料消失,除非主動去刪除資料。
if(window.localStroage){ //判斷瀏覽器是否支援localstroage
window.localStroage.setItem('name','zs') //儲存資料
window.localStroage.getItem('name') //獲取資料
window.localStroage.removeItem('name') //移除資料
}
sessionStroage
生命週期是在瀏覽器關閉前,在瀏覽器關閉前,其資料一直存在。使用方法與localStroage一致。
- 頁面重新整理不會消除資料
- 只有在當前頁面開啟的連結,才可以存取sessionStroage
5.垃圾回收機制(招銀網路)
標記清除
當變數進入環境時,例如:在一個函數中宣告一個變數,就將這個變數標記為「進入環境」;當變數離開時,則將其標記為離開環境。
(從邏輯上講,永遠不能釋放進入環境的變數所佔的記憶體,因為只要執行流進入相應的環境,就可能還會用到它們)
參照計數
跟蹤記錄每個值被參照的次數。
當申明瞭一個變數並將一個參照型別值A賦給該變數時,則這個參照型別值A的參照次數就是1。如果同一個參照型別值A被賦給另一個變數,則這個參照型別值A的參照次數+1;相反,如果包含這個參照型別值A的變數又取得了另外一個參照型別值B,則這個參照型別值A的參照次數-1;當這個值的參照次數變成 0 時,則說明沒有辦法再存取這個值了,因而就可以將其佔用的記憶體空間回收回來。
迴圈參照
function circularReference() {
let obj1 = {
};
let obj2 = {
b: obj1
};
obj1.a = obj2;
}
//當obj1這個變數指向obj1這個物件時,obj1這個物件的參照計數為1
//當obj2這個變數指向obj2這個物件時,obj2這個物件的醫用計數為1;obj2中的b屬性指向obj1,obj1這個物件的參照計數變為2
//obj1的a屬性指向obj2,obj2這個物件的參照計數變為2
//當程式碼執行完畢,會將obj1和obj2賦值為null,但此時obj1物件和obj2物件的參照計數仍為1,不為0,所以不會進行垃圾回收,造成垃圾洩露。
//這兩個物件已經沒什麼作用了,在函數外部也存取不到他們。
深拷貝如何解決迴圈參照(騰訊)
解決問題的關鍵也就是可以將這些參照儲存起來並在發現參照時返回被參照過的物件,從而結束遞迴的呼叫。
原理:
利用uniqueList儲存拷貝過的物件,如果之前拷貝過就把他的拷貝結果返回,否則遍歷該物件的各個屬性,是物件的話繼續深拷貝,不是物件就直接賦值
//arr中儲存了多個物件
//[{source:xxx, target:xxx},{source:xxx, target:xxx},]
function find(arr,item){
for(var i=0; i<arr.length; i++){
if(arr[i].source === item){
return arr[i] //返回的是這整個物件{source:xxx, target:xxx}
}
}
return null;
}
function isObject(obj) {
return typeof obj === 'object' && obj != null;
}
function deepClone(source,uniqueList){
//被拷貝的source必須是物件
if(!isObject(source)) return source;
if(!uniqueList) uniqueList = []; //初始化資料
//儲存結果
var target = Array.isArray(source) ? [] : {};
var uniqueData = find(uniqueList,source); //在初始化資料中檢視是否存在source
if(uniqueData) return uniqueData.target;
uniqueList.push({
source:source, //拷貝源
target:target //拷貝結果
});
for(var key in source){
if(Object.prototype.hasOwnProperty.call(source,key)){
if(isObject(source[key])){
target[key] = deepClone(source[key], uniqueList) // 傳入陣列
}else{
target[key] = source[key];
}
}
}
return target;
}
var a = {
name:"key1",
eat:[
"蘋果",
"香蕉"
]
}
a.eat[2] = "桃";
a.d = a;
console.log(a);
//{name: "key1", eat: Array(3), d: {
// {name: "key1", eat: Array(3), d: {…}}
//}}
b = deepClone(a);
console.log(b);
//{name: "key1", eat: Array(3), d: {
// {name: "key1", eat: Array(3), d: {…}}
//}}
6.跨域
同源策略是瀏覽器最核心也是最基本的安全功能,如果缺少了同源策略,瀏覽器很容易受到XSS、CSFR等攻擊。
同源是指"協定+域名+埠"三者相同,即便兩個不同的域名指向同一個ip地址,也非同源。
JsonP
通常為了減輕web伺服器的負載,我們把js、css,img等靜態資源分離到另一臺獨立域名的伺服器上,在html頁面中再通過相應的標籤從不同域名下載入靜態資源,而被瀏覽器允許,基於此原理,我們可以通過動態建立script,再請求一個帶參網址實現跨域通訊。
缺點:只能實現get一種請求
<script>
var script = document.createElement('script');
script.type = 'text/javascript';
// 傳參一個回撥函數名給後端,方便後端返回時執行這個在前端定義的回撥函數
script.src = 'http://www.domain2.com:8080/login?user=admin&callback=handleCallback';
document.head.appendChild(script);
// 回撥執行函數
function handleCallback(res) {
alert(JSON.stringify(res));
}
</script>
伺服器端返回如下(返回時即執行全域性函數):
handleCallback({"status": true, "user": "admin"})
後端node.js程式碼範例:
var querystring = require('querystring');
var http = require('http');
var server = http.createServer();
server.on('request', function(req, res) {
var params = qs.parse(req.url.split('?')[1]);
var fn = params.callback;
// jsonp返回設定
res.writeHead(200, { 'Content-Type': 'text/javascript' });
res.write(fn + '(' + JSON.stringify(params) + ')');
res.end();
});
server.listen('8080');
console.log('Server is running at port 8080...');
跨域資源共用CORS
主要是後端設定,如果前端傳送請求需要攜帶cookie,前端才需要設定
前端設定:
var xhr = new XMLHttpRequest(); // IE8/9需用window.XDomainRequest相容
// 前端設定是否帶cookie
xhr.withCredentials = true;
xhr.open('post', 'http://www.domain2.com:8080/login', true);
xhr.setRequestHeader('Content-Type', 'application/x-www-form-urlencoded');
xhr.send('user=admin');
xhr.onreadystatechange = function() {
if (xhr.readyState == 4 && xhr.status == 200) {
alert(xhr.responseText);
}
};
後端設定
/*
* 匯入包:import javax.servlet.http.HttpServletResponse;
* 介面引數中定義:HttpServletResponse response
*/
// 允許跨域存取的域名:若有埠需寫全(協定+域名+埠),若沒有埠末尾不用加'/'
response.setHeader("Access-Control-Allow-Origin", "http://www.domain1.com");
// 允許前端帶認證cookie:啟用此項後,上面的域名不能為'*',必須指定具體的域名,否則瀏覽器會提示
response.setHeader("Access-Control-Allow-Credentials", "true");
// 提示OPTIONS預檢時,後端需要設定的兩個常用自定義頭
response.setHeader("Access-Control-Allow-Headers", "Content-Type,X-Requested-With");
nginx代理
同源策略是瀏覽器的安全策略,不是HTTP協定的一部分。伺服器端呼叫HTTP介面只是使用HTTP協定,不會執行JS指令碼,不需要同源策略,也就不存在跨越問題。
前端請求:
var xhr = new XMLHttpRequest();
// 前端開關:瀏覽器是否讀寫cookie
xhr.withCredentials = true;
// 存取nginx中的代理伺服器
xhr.open('get', 'http://www.domain1.com:81/?user=admin', true);
xhr.send();
代理伺服器處理請求:
#proxy伺服器
server {
listen 81;
server_name www.domain1.com;
location / {
proxy_pass http://www.domain2.com:8080; #反向代理
proxy_cookie_domain www.domain2.com www.domain1.com; #修改cookie裡域名
index index.html index.htm;
# 當用webpack-dev-server等中介軟體代理介面存取nignx時,此時無瀏覽器參與,故沒有同源限制,下面的跨域設定可不啟用
add_header Access-Control-Allow-Origin http://www.domain1.com; #當前端只跨域不帶cookie時,可為*
add_header Access-Control-Allow-Credentials true;
}
}
後臺:
var http = require('http');
var server = http.createServer();
var qs = require('querystring');
server.on('request', function(req, res) {
var params = qs.parse(req.url.substring(2));
// 向前臺寫cookie
res.writeHead(200, {
'Set-Cookie': 'l=a123456;Path=/;Domain=www.domain2.com;HttpOnly' // HttpOnly:指令碼無法讀取
});
res.write(JSON.stringify(params));
res.end();
});
server.listen('8080');
console.log('Server is running at port 8080...');
nodejs中介軟體代理(vue框架)
//在webpack.config.js中設定
module.exports = {
entry: {},
module: {},
...
devServer: {
historyApiFallback: true,
proxy: [{
context: '/login',
target: 'http://www.domain2.com:8080', // 代理跨域目標介面
changeOrigin: true,
secure: false, // 當代理某些https服務報錯時用
cookieDomainRewrite: 'www.domain1.com' // 可以為false,表示不修改
}],
noInfo: true
}
}
提示OPTIONS預檢時,後端需要設定的兩個常用自定義頭
response.setHeader(「Access-Control-Allow-Headers」, 「Content-Type,X-Requested-With」);
### nginx代理
> 同源策略是瀏覽器的安全策略,不是HTTP協定的一部分。**伺服器端呼叫HTTP介面**只是使用HTTP協定,不會執行JS指令碼,不需要同源策略,也就**不存在跨越問題。**
前端請求:
```js
var xhr = new XMLHttpRequest();
// 前端開關:瀏覽器是否讀寫cookie
xhr.withCredentials = true;
// 存取nginx中的代理伺服器
xhr.open('get', 'http://www.domain1.com:81/?user=admin', true);
xhr.send();
代理伺服器處理請求:
#proxy伺服器
server {
listen 81;
server_name www.domain1.com;
location / {
proxy_pass http://www.domain2.com:8080; #反向代理
proxy_cookie_domain www.domain2.com www.domain1.com; #修改cookie裡域名
index index.html index.htm;
# 當用webpack-dev-server等中介軟體代理介面存取nignx時,此時無瀏覽器參與,故沒有同源限制,下面的跨域設定可不啟用
add_header Access-Control-Allow-Origin http://www.domain1.com; #當前端只跨域不帶cookie時,可為*
add_header Access-Control-Allow-Credentials true;
}
}
後臺:
var http = require('http');
var server = http.createServer();
var qs = require('querystring');
server.on('request', function(req, res) {
var params = qs.parse(req.url.substring(2));
// 向前臺寫cookie
res.writeHead(200, {
'Set-Cookie': 'l=a123456;Path=/;Domain=www.domain2.com;HttpOnly' // HttpOnly:指令碼無法讀取
});
res.write(JSON.stringify(params));
res.end();
});
server.listen('8080');
console.log('Server is running at port 8080...');
nodejs中介軟體代理(vue框架)
//在webpack.config.js中設定
module.exports = {
entry: {},
module: {},
...
devServer: {
historyApiFallback: true,
proxy: [{
context: '/login',
target: 'http://www.domain2.com:8080', // 代理跨域目標介面
changeOrigin: true,
secure: false, // 當代理某些https服務報錯時用
cookieDomainRewrite: 'www.domain1.com' // 可以為false,表示不修改
}],
noInfo: true
}
}