Linux篇--高頻常用命令
2021-05-14 22:00:17
一、檢索內容(grep)
我們先準備兩個檔案:
[root@192 mnt]# cat hehe1.txt
hello world
hello hadoop
hello hive
[root@192 mnt]# cat hehe2.txt
I love you!
Hello world.
查詢帶有ve的內容:

管道操作符|:多個指令連線起來,前一個指令的結果作為下一個指令的輸入

grep -v:是反向查詢的意思,比如 grep -v "grep" 就是查詢不含有 grep 欄位的行
二、內容處理(awk)
我們先準備個檔案:
[root@192 mnt]# cat emp.txt
empno enname job mgr hiredate sal comm deptno
7369 劉一 職員 7902 1980-12-17 800 null 20
7499 陳二 推銷員 7698 1981-02-20 1600 300 30
7521 張三 推銷員 7698 1981-02-22 1250 500 30
7566 李四 經理 7839 1981-04-02 2975 null 20
7654 王五 推銷員 7698 1981-09-28 1250 1400 30
7698 趙六 經理 7839 1981-05-01 2850 null 30
7782 孫七 經理 7839 1981-06-09 2450 null 10
7788 周八 分析師 7566 1987-06-13 3000 null 20
7839 吳九 總裁 null 1981-11-17 5000 null 10
7844 鄭十 推銷員 7698 1981-09-08 1500 0 30
7876 郭十一 職員 7788 1987-06-13 1100 null 20
7900 錢多多 職員 7698 1981-12-03 950 null 30
7902 大錦鯉 分析師 7566 1981-12-03 3000 null 20
7934 木有錢 職員 7782 1983-01-23 1300 null 10
我們只要第一和第二列:
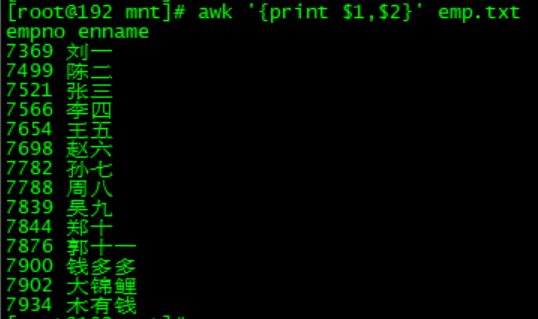
注:第0列其實就是完整,awk '{print $0}' emp.txt命令會將所有內容都列印出來。
我們只要第一列員工編號為7654的行:

你還想要第一行頭的話:

如果檔案中把分隔符由預設製表符改為逗號的話需要加-F:awk -F "," '{print $1}' emp.txt
三、內容替換(sed)
替換hehe1.txt檔案中的hadoop替換為spark(檔案中的真實內容並沒有被替換掉,只是輸出的結果被替換掉了):

如果想讓替換在檔案中生效需要加-i引數:

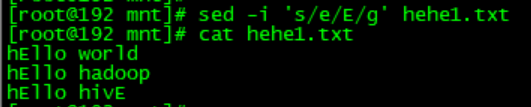
如果要替換特殊字元如;需要加跳脫字元\:sed -i 's/\;//' hehe1.txt
想要把e換成E(但是發現並沒有把所有的e都替換了):sed -i 's/e/E/' hehe1.txt
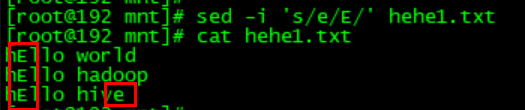
預設是隻替換一個,如果想要全域性替換的話後面需要加一個g: