PyTorch學習筆記——詞向量簡介
引言
本系列文章是七月線上的<PyTorch入門與實戰>課程的一個筆記。
本文用的PyTorch版本是1.7.1。
為什麼需要詞向量
為了便於計算機處理,我們需要把檔案、單詞向量化。
而且除了向量化之後,還希望單詞的表達能計算相似詞資訊。
向量化單詞,最早的方法是one-hot表示法,但是這種表示沒有包含語意資訊,並且也不知道某個單詞在某篇文章中的重要性。
後來有人提出了TF-IDF方法,這種詞袋模型能考慮到單詞的重要性,但是語意的相似性還是捕捉不到。

所謂語意資訊,就是代表各種青蛙的單詞,向量化之後,這些向量的距離越接近越好。距離越近則表示它們的意思越近。
後來有人提出了分散式表示。假設你想知道某個單詞的含義,你只要知道這個單詞與哪些詞語同時出現。即一個單詞可以用周圍的單詞來表示。
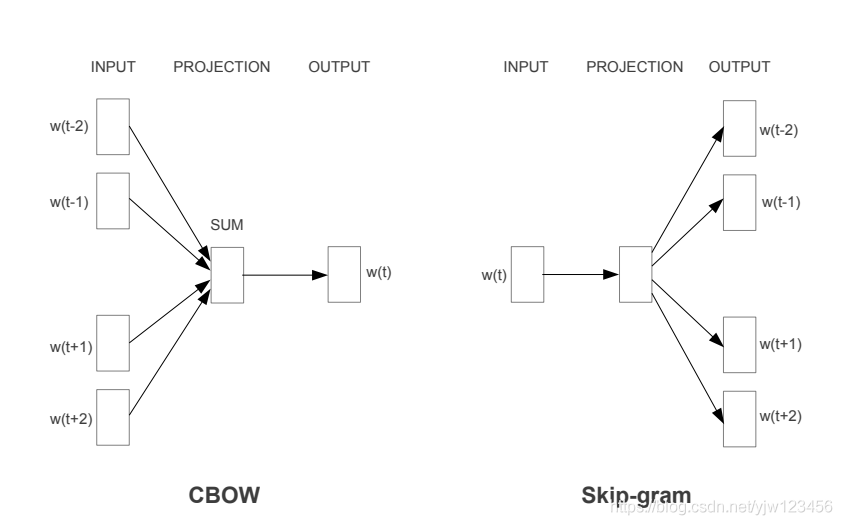
這就是Word2Vec,原理可以點進去看看。這裡補充下Skip-Gram模型的目標函數:
1
T
∑
t
=
1
T
∑
−
c
≤
j
≤
c
,
j
≠
0
log
p
(
w
t
+
j
∣
w
t
)
\frac{1}{T} \sum_{t=1}^T \sum_{ -c \leq j \leq c , j \neq 0} \log p(w_{t+j}|w_t)
T1t=1∑T−c≤j≤c,j=0∑logp(wt+j∣wt)
其中
T
T
T代表文字長度。
w
t
+
j
w_{t+j}
wt+j是
w
t
w_t
wt附近的單詞。
就是給定中心詞,它周圍單詞出現的概率越大越好。
本文的重點是學習PyTorch,用到的資料 見百度網路硬碟: 密碼:v2z5 。
接下來基於PyTorch實現Word2Vec:
import torch
import torch.nn as nn
import torch.nn.functional as F
import torch.utils.data as tud
from collections import Counter
import numpy as np
import random
import math
import pandas as pd
import scipy
import sklearn
from sklearn.metrics.pairwise import cosine_similarity
USE_CUDA = torch.cuda.is_available()
seed = 53113
random.seed(seed)
np.random.seed(seed)
torch.manual_seed(seed)
if USE_CUDA:
torch.cuda.manual_seed(seed)
# 實現Skip-gram模型
C = 3 # 視窗大小
K = 100 # 負取樣個數
NUM_EPOCHS = 2
MAX_VOCAB_SIZE = 30000
BATCH_SIZE = 128
LEARNING_RATE = 0.2
EMBEDDING_SIZE = 100
def word_tokenize(text):
return text.split()
首先是設定好引數。
然後讀取訓練資料:
with open('./datasets/text8/text8.train.txt','r') as fin:
text = fin.read()
text = text.split()
text[:200] # 看200個單詞
然後構造詞典和相應的對映。
# 詞典
vocab = dict(Counter(text).most_common(MAX_VOCAB_SIZE-1))
vocab['<unk>'] = len(text) - np.sum(list(vocab.values())) # 整個文字的單詞數,減去詞典中的對應的單詞數 得到未知單詞數
id_2_word = [word for word in vocab.keys()]
word_2_id = {word:i for i,word in enumerate(id_2_word)}
# 得到每個單詞出現的次數
word_counts = np.array([count for count in vocab.values()],dtype=np.float32)
# 計算每個單詞的頻率
word_freqs = word_counts / np.sum(word_counts)
word_freqs = word_freqs ** (3./4.)
word_freqs = word_freqs / np.sum(word_freqs)
VOCAB_SIZE = len(id_2_word)
PyTorch提供了Dataset結合DataLoader可以實現訓練資料的載入以及本文的負取樣。
繼承Dataset需要提供以下兩個方法的實現:
__len__返回資料集元素數量__getitem__支援索引操作,比如dataset[i]能獲得第i個元素
class WordEmbeddingDataset(tud.Dataset):
def __init__(self, text, word_2_id, id_2_word, word_freqs, word_counts):
'''
text: 單詞列表,訓練集中所有單詞
word_2_id : 單詞到id的字典
id_2_word: id到單詞的對映
word_freqs: 每個單詞的頻率
word_counts: 每個單詞出現的次數
'''
super(WordEmbeddingDataset,self).__init__()
# 將每個單詞轉換為id
self.text_encoded = [word_2_id.get(word, word_2_id['<unk>']) for word in text]
# 轉換成Tensor
self.text_encoded = torch.Tensor(self.text_encoded)
# 儲存word_2_id和id_2_wor
self.word_2_id = word_2_id
self.id_2_word = id_2_word
# 轉換成tensor並儲存
self.word_freqs = torch.Tensor(word_freqs)
self.word_counts = torch.Tensor(word_counts)
def __len__(self):
# 資料集大小就是text_encoded的長度
return len(self.text_encoded)
def __getitem__(self,idx):
'''
負取樣,用於訓練
返回:
中心詞
中心詞附近的positive單詞
隨機取樣K個單詞作為negative樣本
'''
# 中心詞
center_word = self.text_encoded[idx]
# 上文下單詞的索引
pos_indices = list(range(idx - C,idx)) + list(range(idx+1,idx+C+1))
# 可能會超出文字長度
pos_indices = [i % len(self.text_encoded) for i in pos_indices]
pos_words = self.text_encoded[pos_indices]
# 負取樣
neg_words = torch.multinomial(self.word_freqs, K * pos_words.shape[0],True)
return center_word, pos_words, neg_words # 形狀依次是: [] [6] [600]
其中用到的torch.multinomial
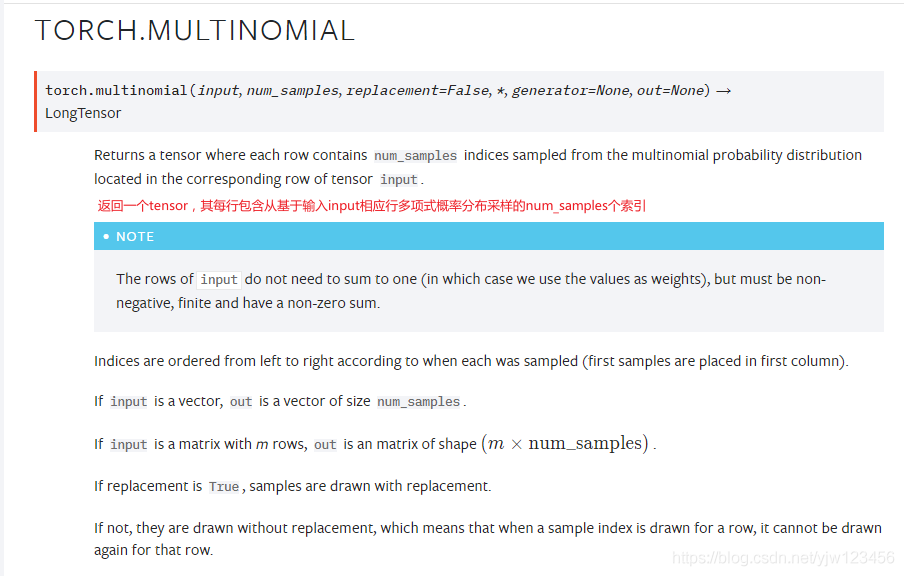
返回一個tensor,每行包含從input相應行中定義的多項分佈(概率)中抽取的num_samples個樣本,返回的是索引。
下面基於Dataset來構造DataLoader。
dataset = WordEmbeddingDataset(text, word_2_id, id_2_word, word_freqs, word_counts)
dataloader = tud.DataLoader(dataset,batch_size=BATCH_SIZE,shuffle=True,num_workers=0)
然後就開始定義模型了:
# 定義PyTorch模型
# 實現的是Skip-gram模型
class EmbeddingModel(nn.Module):
def __init__(self,vocab_size,embed_size):
super(EmbeddingModel,self).__init__()
self.vocab_size = vocab_size
self.embed_size = embed_size
initrange = 0.5 / self.embed_size
self.output_embed = nn.Embedding(self.vocab_size, self.embed_size, sparse=False)
# 對權重進行隨機初始化
self.output_embed.weight.data.uniform_(-initrange, initrange)
self.input_embed = nn.Embedding(self.vocab_size, self.embed_size, sparse=False)
self.input_embed.weight.data.uniform_(-initrange, initrange)
def forward(self,input_labels, pos_labels, neg_labels):
'''
input_labels: [batch_size]
pos_labels: [batch_size,(window_size * 2)]
neg_labels: [batch_size,(window_size * 2 * K)]
'''
batch_size = input_labels.size(0)
input_embedding = self.input_embed(input_labels) #[batch_size,embed_size]
pos_embedding = self.output_embed(pos_labels) #[batch_size,(window_size * 2),embed_size]
neg_embedding = self.output_embed(neg_labels) #[batch_size,(window_size * 2 * K),embed_size]
#input_embedding.unsqueeze(2) # unsqueeze在指定的位置插入1個維度,變成[batch_size, embed_size,1]
pos_dot = torch.bmm(pos_embedding,input_embedding.unsqueeze(2)).squeeze() # [batch_size,window_size * 2 ] squeeze()
neg_dot = torch.bmm(neg_embedding,-input_embedding.unsqueeze(2)).squeeze() # [batch_size,window_size * 2 * K]
log_pos = F.logsigmoid(pos_dot).sum(1)
log_neg = F.logsigmoid(neg_dot).sum(1)
loss = log_pos + log_neg
return -loss
def input_embeddings(self):
return self.input_embed.weight.data.cpu().numpy()
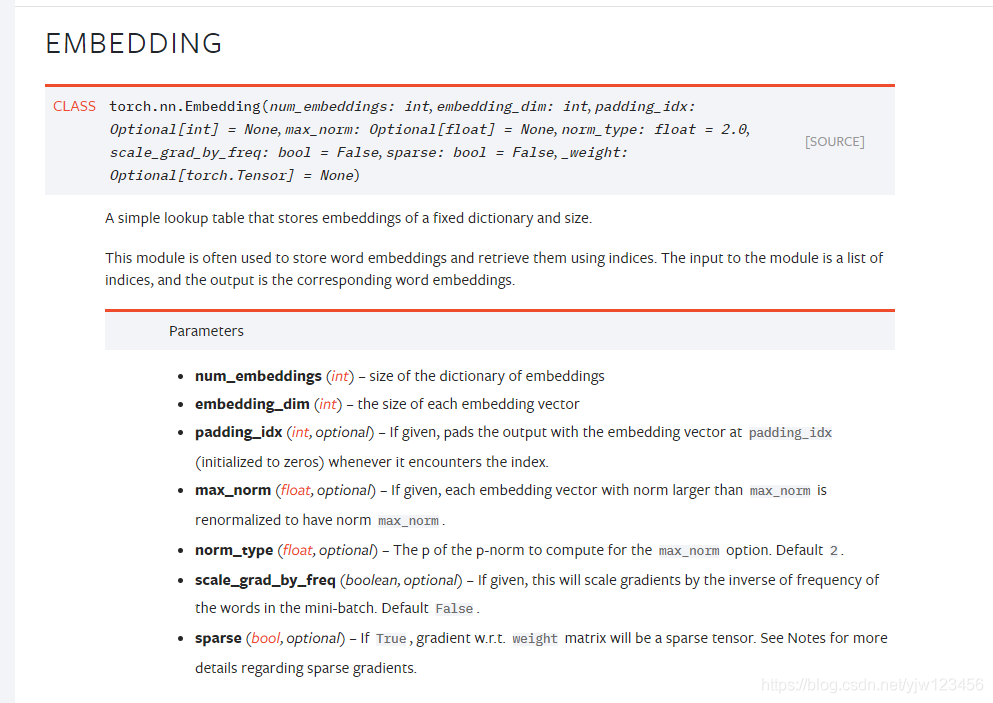
先來看一下nn.Embedding,說的是儲存了單詞的嵌入向量。實際上是根據指定的維度初始化了一個權重矩陣,本例可以理解為初始化了self.vocab_size個大小為self.embed_size的tensor,每個tensor就是一個單詞的詞嵌入向量。
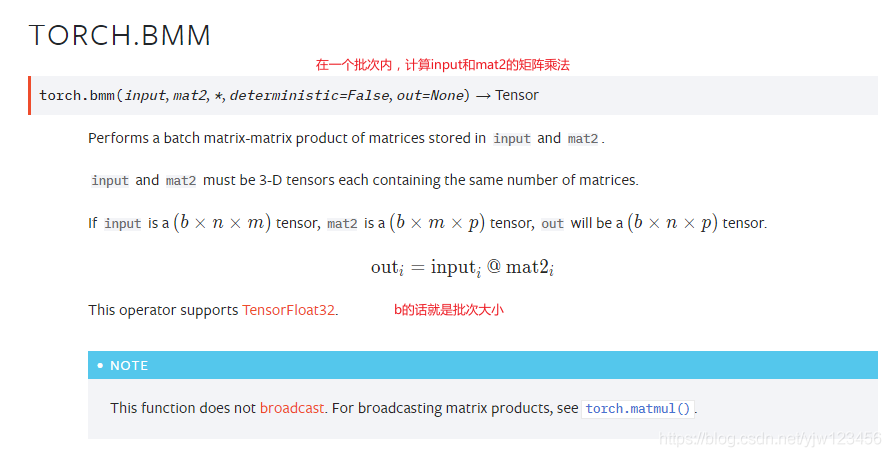
torch.bmm做的是批次內的矩陣乘法。
pos_dot = torch.bmm(pos_embedding,input_embedding.unsqueeze(2)).squeeze() # [batch_size,window_size * 2 ] squeeze()
neg_dot = torch.bmm(neg_embedding,-input_embedding.unsqueeze(2)).squeeze() # [batch_size,window_size * 2 * K]
log_pos = F.logsigmoid(pos_dot).sum(1)
log_neg = F.logsigmoid(neg_dot).sum(1)
loss = log_pos + log_neg
以上程式碼實現的是論文1中的公式 ( 4 ) (4) (4)。
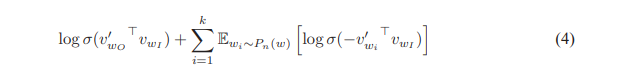
其中
v
w
I
v_{wI}
vwI是輸入詞向量input_embedding;
v
w
i
′
v^\prime_{wi}
vwi′是基於
P
n
(
w
)
P_n(w)
Pn(w)生成的負取樣單詞詞向量neg_embedding;
v
w
O
′
v^\prime_{wO}
vwO′是輸出詞向量pos_embedding。
下面定義模型:
# 定義一個模型以及把模型移動到GPU
model = EmbeddingModel(VOCAB_SIZE, EMBEDDING_SIZE)
if USE_CUDA:
model = model.cuda()
通過PyTorch這種框架,我們只需要實現好前向傳播,它能幫我進行反向傳播。
# 訓練模型
optimizer = torch.optim.SGD(model.parameters(),lr=LEARNING_RATE)
for e in range(NUM_EPOCHS):
for i, (input_labels,pos_labels,neg_labels) in enumerate(dataloader):
input_labels,pos_labels,neg_labels = input_labels.long(),pos_labels.long(),neg_labels.long()
if USE_CUDA:
input_labels,pos_labels,neg_labels = input_labels.cuda(),pos_labels.cuda(),neg_labels.cuda()
optimizer.zero_grad()
loss = model(input_labels,pos_labels,neg_labels).mean()
loss.backward()
optimizer.step()
if i % 100 == 0:
print('epoch ',e ,' iteration ', i , loss.item())
在我本機上要跑2個小時,基於使用GPU的情況。
下面我們測試得到的結果:
embedding_weights = model.input_embeddings()
def find_nearest(word):
index = word_2_id[word]
embedding = embedding_weights[index]
cos_dis = np.array([scipy.spatial.distance.cosine(e, embedding) for e in embedding_weights])
return [id_2_word[i] for i in cos_dis.argsort()[:10]]
for word in ["good", "fresh", "monster", "green", "like", "america", "chicago", "work", "computer", "language"]:
print(word, find_nearest(word))

可以看到,確實學到了一些相關的語意資訊。