汽車車牌識別系統實現(三)-- 車牌矯正+字元分割+程式碼實現
車牌矯正
一、前言
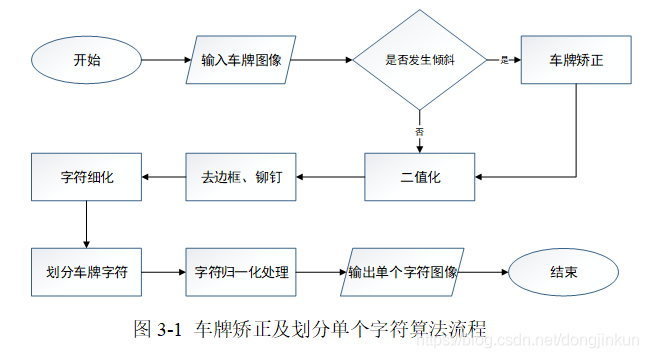
汽車車牌識別裝置往往都是固定於紅綠燈的支架或者是小區、學校入口的一側來採集獲取車牌影象,由於採集影象裝置的安裝位置不固定以及不同車輛車牌懸掛的高度也不確定等因素,這些外部因素都有可能導致車牌在一定程度上發生傾斜。發生傾斜的車牌如果不進行矯正,將會影響後續的字元劃分處理。所以,對車牌進行傾斜矯正處理是字元劃分演演算法得以成功的前提。車牌傾斜主要存在三種情形,分別是水平、垂直和包括水平、垂直傾斜兩種情況的混合傾斜。本文所研究的演演算法中只對水平方向傾斜情況進行校正。本文采用基於透視變換的傾斜校正演演算法來判斷車牌是否需要傾斜校正以及對車牌進行校正操作,整個矯正車牌及劃分字元的流程如圖3-1所示。
二、基於透視變換的傾斜矯正演演算法
透視變換的本質是將影象投影到一個新的視平面,也被稱為投影對映[4]。透視變換的通用變換公式為式 (3-1):
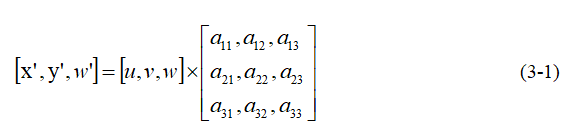
其中,(u,v)代表原始影象的座標,
代表變換矩陣,透視變化後的影象橫、縱座標分別如式 (3-2)和式 (3-3)所示:
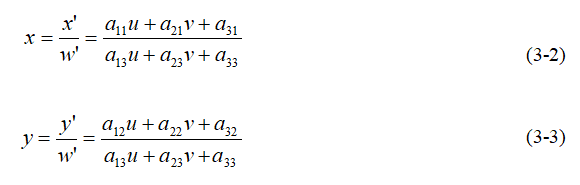
給定原始影象的四個頂點座標和變換後影象的四個頂點座標,即可求得變換矩陣。求得變換矩陣後,需要求出傾斜狀態下車牌的四個頂點座標,具體步驟如下:首先定位出車牌位置,判斷車牌是否傾斜。車牌傾斜主要有逆時針傾斜和順時針傾斜的兩種情況。本文只說明逆時針傾斜情況。逆、順時針情況可以簡化成如圖3-2和圖3-3的模型。
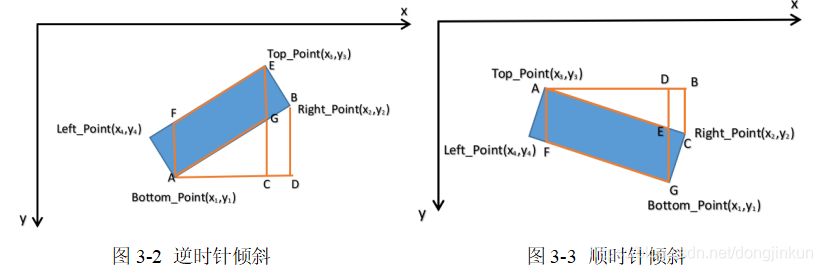
如圖3-1所示,根據求得A、E、F、G的座標(Top_Point、Right_Point、Bottom_Point、Left_Point),在圖3-2中,則是根據▲ABC~▲ADE來計算出A、E、F、G點的座標。本文只說明圖3-1中G點的求解步驟如下:
求解G點的橫座標,如式(3-4)所示:

依據三角形相似原理,寫出相似等式,如式(3-5)所示:

求解得到G的縱座標值,如式(3-6)所示:

求解後,原始影象中車牌的4個頂點均已知。根據上文車牌特徵分析可知,車牌尺寸為440×140,故變換後的車牌4個頂點依次為(0,140)、(440,0)、(0,0)、 (440,140)。根據變換矩陣與變換前後對應頂點關係,利用透視變換傾斜糾正演演算法對車牌進行矯正,矯正前後實驗結果分別如圖3-4和圖3-5所示。

三、跳變次數法去除車牌邊框和鉚釘

車牌傾斜矯正之後,車牌邊框和用於固定車牌的鉚釘會影響字元分割操作的結果,因此,去除車牌邊框和鉚釘是車牌字元分割演演算法能否取得成功的關鍵步驟。本文采用跳變次數法[5][6]去除邊框和鉚釘。跳變次數法去除邊框及鉚釘的原理及流程如圖3-6。

由於字元顏色與車牌底色不同,因此車牌區域中存在大量的顏色突變資訊,這就為跳變次數法的實施創造了條件。所謂的跳變是指由字元區域過渡到非字元區域或者由非字元區域過渡到字元區域。具體做法是從上至下掃描出二值化後的車牌影象,找到跳變次數超過預先設定閾值的第一行,且之後連續3行跳變次數均超過閾值,則認定該行為車牌字元上邊界;同理,從下至上掃描車牌影象,找到突變次數超過預先設定閾值的一行,且之後連續3行突變次數均超過閾值,則該行為車牌字元下邊界。在確定車牌上下邊界的前提下,接著確定車牌字元的左邊界、右邊界。因為車牌中可能存在數位1,數位1的跳變次數為2,為了防止濾除掉阿拉伯數位1,設定跳變次數的閾值為2。具體做法是從左至右掃描車牌影象,依次統計每列的跳變次數。找到跳變次數超過閾值的第一行,且之後連續3列跳變次數均超過閾值,則該行為車牌字元左邊界;同理,找到車牌字元右邊界。去除前後效果分別如圖3-8和圖3-9所示。

四、字元細化操作
去除邊框及鉚釘後,影象上仍有一些殘留的噪聲點,這些殘留的噪聲點會對垂直投影法劃分字元操作產生不良影響。因此,對去除邊框和鉚釘後的影象進行形態學腐蝕處理是非常有必要而且是至關重要的,腐蝕處理在去掉車牌字元區域殘留噪聲的同時,也可以對字元進行細化,形態學腐蝕處理效果如圖3-10所示。

五、垂直投影法分割字元

去除邊框、鉚釘,以及對字元進行細化處理後,接下來需要將車牌字元區域劃分為單個字元。本文采取基於垂直投影法的字元劃分方法[7][8]來劃分車牌字元區域,依據車牌特點可知,每個字元之間都存在一定的純黑區域。二值化後,字元區域為白色,車牌中的非字元區域為黑色。
劃分單個字元的原理及具體流程如圖3-11所示。首先計算每列中白色畫素點個數,垂直投影后得到直方圖,如圖3-12所示,並以此來判斷各個字元的起始位置。然後從左至右掃描投影直方圖,找到存在白色畫素點的第一列,則認定為該列是車牌第一個字元的左邊界。若上一列存在白色畫素點,而下一列是不存在白色畫素點的黑色區域,則認定該列為第一個字元的右邊界,同理,便可分割出其餘6個車牌字元左右邊界。投影得到的影象如圖3-12所示,劃分出的單個字元如圖3-13所示。

六、字元影象歸一化處理
由於從採集影象中提取出的車牌大小不完全相同,這就導致了劃分出來的單個字元的尺寸可能不同,為了能夠適應已經訓練好的車牌字元識別網路,需要對劃分出的單個車牌字元進行歸一化處理,使得從採集影象中定位出的車牌在字元分割操作完成後,所獲取的車牌單個字元影象大小都為2020畫素[2],如圖3-11所示。這裡至於為什麼都歸一化為2020畫素,是因為我的神經網路的輸入都是20*20畫素的。

七、程式碼實現
```python
for rect in car_contours:
rect = (rect[0], (rect[1][0]+20, rect[1][1]+5), rect[2])
box = cv2.boxPoints(rect)
#影象矯正 cv2.getAffineTransform(pos1,pos2),其中兩個位置就是變換前後的對應位置關係。輸出的就是仿射矩陣M,最後這個矩陣會被傳給函數 cv2.warpAffine() 來實現仿射變換
if rect[2] > ANGLE: #正角度
new_right_point_x = vertices[0, 0]
new_right_point_y = int(vertices[1, 1] - (vertices[0, 0] - vertices[1, 0]) / (vertices[3, 0] - vertices[1, 0]) * (vertices[1, 1] - vertices[3, 1]))
new_left_point_x = vertices[1, 0]
new_left_point_y = int(vertices[0, 1] + (vertices[0, 0] - vertices[1, 0]) / (vertices[0, 0] - vertices[2, 0]) * (vertices[2, 1] - vertices[0, 1]))
point_set_1 = np.float32([[440, 0], [0, 0], [0, 140], [440, 140]])
elif rect[2] < ANGLE: #負角度
new_right_point_x = vertices[1, 0]
new_right_point_y = int(vertices[0, 1] + (vertices[1, 0] - vertices[0, 0]) / (vertices[3, 0] - vertices[0, 0]) * (vertices[3, 1] - vertices[0, 1]))
new_left_point_x = vertices[0, 0]
new_left_point_y = int(vertices[1, 1] - (vertices[1, 0] - vertices[0, 0]) / (vertices[1, 0] - vertices[2, 0]) * (vertices[1, 1] - vertices[2, 1]))
point_set_1 = np.float32([[0, 0], [0, 140], [440, 140], [440, 0]])
new_box = np.array([(vertices[0, 0], vertices[0, 1]), (new_left_point_x, new_left_point_y), (vertices[1, 0], vertices[1, 1]),(new_right_point_x, new_right_point_y)])
point_set_0 = np.float32(new_box)
mat = cv2.getPerspectiveTransform(point_set_0, point_set_1)
dst = cv2.warpPerspective(img, mat, (440, 140))
cv_show('dst',dst)
#-------------------------------字元分割-------------------------------------
plate_original = dst.copy()
img_aussian = cv2.GaussianBlur(dst,(5,5),1)
# cv_show('img_aussian',img_aussian)
#中值濾波
dst = cv2.medianBlur(img_aussian,3)
# 對車牌進行精準定位
img_B = cv2.split(dst)[0]
img_G = cv2.split(dst)[1]
img_R = cv2.split(dst)[2]
for i in range(dst.shape[:2][0]):
for j in range(dst.shape[:2][1]):
if abs(img_B[i,j] - Blue) < THRESHOLD and abs(img_G[i,j] - Green) <THRESHOLD and abs(img_R[i,j] - Red) < THRESHOLD:
dst[i][j][0] = 0
dst[i][j][1] = 0
dst[i][j][2] = 0
else:
dst[i][j][0] = 255
dst[i][j][1] = 255
dst[i][j][2] = 255
# cv_show('dst',dst)
# 灰度化
gray = cv2.cvtColor(dst, cv2.COLOR_BGR2GRAY)
cv_show('gray',gray)
#-------------------------------跳變次數去掉鉚釘和邊框----------------------------------
times_row = [] #儲存哪些行符合跳變次數的閾值
for row in range(LICENSE_HIGH): # 按行檢測 白字黑底
pc = 0
for col in range(LICENSE_WIDTH):
if col != LICENSE_WIDTH-1:
if gray[row][col+1] != gray[row][col]:
pc = pc + 1
times_row.append(pc)
print("每行的跳變次數:",times_row)
#找車牌的下邊緣-從下往上掃描
row_end = 0
row_start = 0
for row in range(LICENSE_HIGH-2):
if times_row[row] < 16:
continue
elif times_row[row+1] < 16:
continue
elif times_row[row+2] < 16:
continue
else:
row_end = row + 2
print("row_end",row_end)
#找車牌的上邊緣-從上往下掃描
i = LICENSE_HIGH-1
row_num = [] #記錄row_start可能的位置
while i > 1:
if times_row[i] < 16:
i = i - 1
continue
elif times_row[i-1] < 16:
i = i - 1
continue
elif times_row[i-2] < 16:
i = i - 1
continue
else:
row_start = i - 2
row_num.append(row_start)
i = i - 1
print("row_num",row_num)
#確定row_start最終位置
for i in range(len(row_num)):
if i != len(row_num)-1:
if abs(row_num[i] - row_num[i+1])>3:
row_start = row_num[i]
print("row_start",row_start)
times_col = [0]
for col in range(LICENSE_WIDTH):
pc = 0
for row in range(LICENSE_HIGH):
if row != LICENSE_HIGH-1:
if gray[row,col] != gray[row+1,col]:
pc = pc + 1
times_col.append(pc)
print("每列的跳變次數",times_col)
# 找車牌的左右邊緣-從左到右掃描
col_start = 0
col_end = 0
for col in range(len(times_col)):
if times_col[col] > 2:
col_end = col
print('col_end',col_end)
j = LICENSE_WIDTH-1
while j >= 0:
if times_col[j] > 2:
col_start = j
j = j-1
print('col_start',col_start)
# 將車牌非字元區域變成純黑色
for i in range(LICENSE_HIGH):
if i > row_end or i < row_start:
gray[i] = 0
for j in range(LICENSE_WIDTH):
if j < col_start or j > col_end:
gray[:,j] = 0
cv_show("res",gray)
# plate_binary = gray.copy()
for i in range(LICENSE_WIDTH-1,LICENSE_WIDTH):
gray[:,i] = 0
# 字元細化操作
specify = cv2.erode(gray,kernel,iterations=2)
cv_show("specify",specify)
plate_specify = specify.copy()
#---------------------------垂直投影法切割字元-------------------------
lst_heise = [] #記錄每一列中的白色畫素點數量
for i in range(LICENSE_WIDTH):
pc = 0
for j in range(LICENSE_HIGH):
if specify[j][i] == 255:
pc = pc + 1
lst_heise.append(pc)
# print("lst_heise",lst_heise)
a = [0 for i in range(0,LICENSE_WIDTH)]
for j in range(0, LICENSE_WIDTH): # 遍歷一列
for i in range(0, LICENSE_HIGH): # 遍歷一行
if specify[i, j] == 255: # 如果該點為白點
a[j] += 1 # 該列的計數器加一計數
specify[i, j] = 0 # 記錄完後將其變為黑色
# print (j)
for j in range(0, LICENSE_WIDTH): # 遍歷每一列
for i in range((LICENSE_HIGH - a[j]), LICENSE_HIGH): # 從該列應該變白的最頂部的點開始向最底部塗白
specify[i, j] = 255
plt.imshow(specify,cmap=plt.gray())
plt.show()
cv_show("touying",specify)
#開始找字元的邊界
in_block = False #用來指示是否遍歷到字元區
startIndex = 0
endIndex = 0
threshold = 10
index = 0
char_Image = [] # 存放一個個分割後的字元
for i in range(LICENSE_WIDTH):
if lst_heise[i] != 0 and in_block == False: # 表示進入有白色畫素點的區域
in_block = True
startIndex = i
print("start", startIndex)
elif lst_heise[i] == 0 and in_block == True: # 表示進入純黑區域,且純黑區域前面是字元區域
endIndex = i
in_block = False
print("end", endIndex)
if endIndex < startIndex:
endIndex = 440
if endIndex - startIndex > 10:
res = plate_specify[row_start:row_end,startIndex:endIndex]
index = index + 1
res = cv2.resize(res, (20, 20), interpolation=cv2.INTER_LANCZOS4) # 分割出的各個字元進行歸一化
char_Image.append(res)
cv_show("res", res)
print("char_Image的長度:{}".format(len(char_Image)))
# print(char_Image)
char_Image = np.array(char_Image)
# print(char_Image.shape[0])
plate_char = np.hstack((char_Image[0],char_Image[1],char_Image[2],char_Image[3],
char_Image[4],char_Image[5],char_Image[6]))
cv2.imshow("plate",plate_char)
cv2.waitKey(0)
cv2.destroyAllWindows()
到這裡,車牌矯正的相關步驟都已講解完畢,剩下的就是關於深度學習的知識了,之後我會陸續分享深度學習的基礎知識。