2020-10-25
Redis系列 - 單執行緒的Redis為什麼那麼快?
Redis為什麼使用單執行緒?
在說這個問題之前我們先來了解下引入多執行緒常見的開銷:
1. 上下文切換:
即使是單核CPU也支援多執行緒執行程式碼,CPU通過給每個執行緒分配CPU時間片來實現這個機制。時間片是CPU分配給各個執行緒的時間,因為時間片非常短,所以CPU通過不停地切換執行緒執行,讓我們感覺多個執行緒時同時執行的,時間片一般是幾十毫秒(ms)。
CPU通過時間片分配演演算法來回圈執行任務,當前任務執行一個時間片後會切換到下一個任務。但是,在切換前會儲存上一個任務的狀態,以便下次切換回這個任務時,可以再次載入這個任務的狀態,從任務儲存到再載入的過程就是一次上下文切換。
當一個新的執行緒被切換進來,它所需要的資料可能不在當前處理器的本地快取中,因此上下文切換將導致一些快取缺失,因而執行緒在首次排程執行時會更加緩慢。這也是為什麼排程器為每個可執行的執行緒分配一個最小執行時間。
2. 記憶體同步
記憶體的可見性問題,這裡不過多介紹。
3. 阻塞:
存取共用資源時需要加鎖保證資料安全,當在鎖上發生競爭時,競爭失敗的執行緒會被阻塞。
通常情況下,在我們採用多執行緒後,如果沒有良好的系統設計,實際得到的結果,其實是右圖所展示的那樣。我們剛開始增加執行緒數時,系統吞吐率會增加,但是,再進一步增加執行緒時,系統吞吐率就增長遲緩了,有時甚至還會出現下降的情況。
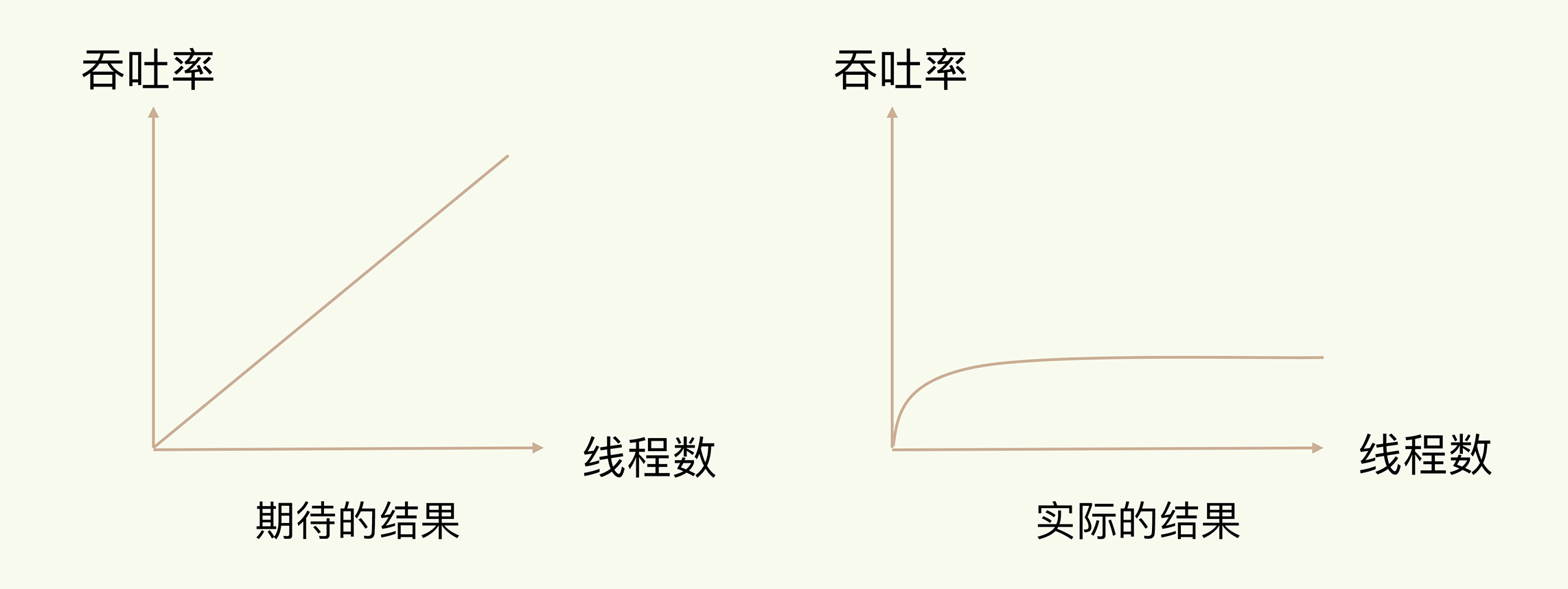
關鍵原因在於,系統中通常會存在被多執行緒同時存取的共用資源,比如一個共用的資料結構。當有多個執行緒要修改這個共用資源時,為了保證共用資源的正確性,就需要有額外的機制進行保證,而這個額外的機制,就會帶來額外的開銷。如果沒有精細的設計,比如說,只是簡單地採用一個粗粒度互斥鎖,就會出現不理想的結果:即使增加了執行緒,大部分執行緒也在等待獲取存取共用資源的互斥鎖,並行變序列,系統吞吐率並沒有隨著執行緒的增加而增加。
Redis為什麼那麼快?
-
Redis是基於記憶體實現的
完全基於記憶體,絕大部分請求是純粹的記憶體操作,非常快速。資料存在記憶體中,類似於HashMap,HashMap的優勢就是查詢和操作的時間複雜度都是O(1); -
資料結構簡單,對資料操作也簡單,Redis中的資料結構是專門進行設計的;
-
採用單執行緒,避免了不必要的上下文切換和競爭條件,也不存在多程序或者多執行緒導致的切換而消耗 CPU,不用去考慮各種鎖的問題,不存在加鎖釋放鎖操作,沒有因為可能出現死鎖而導致的效能消耗;
-
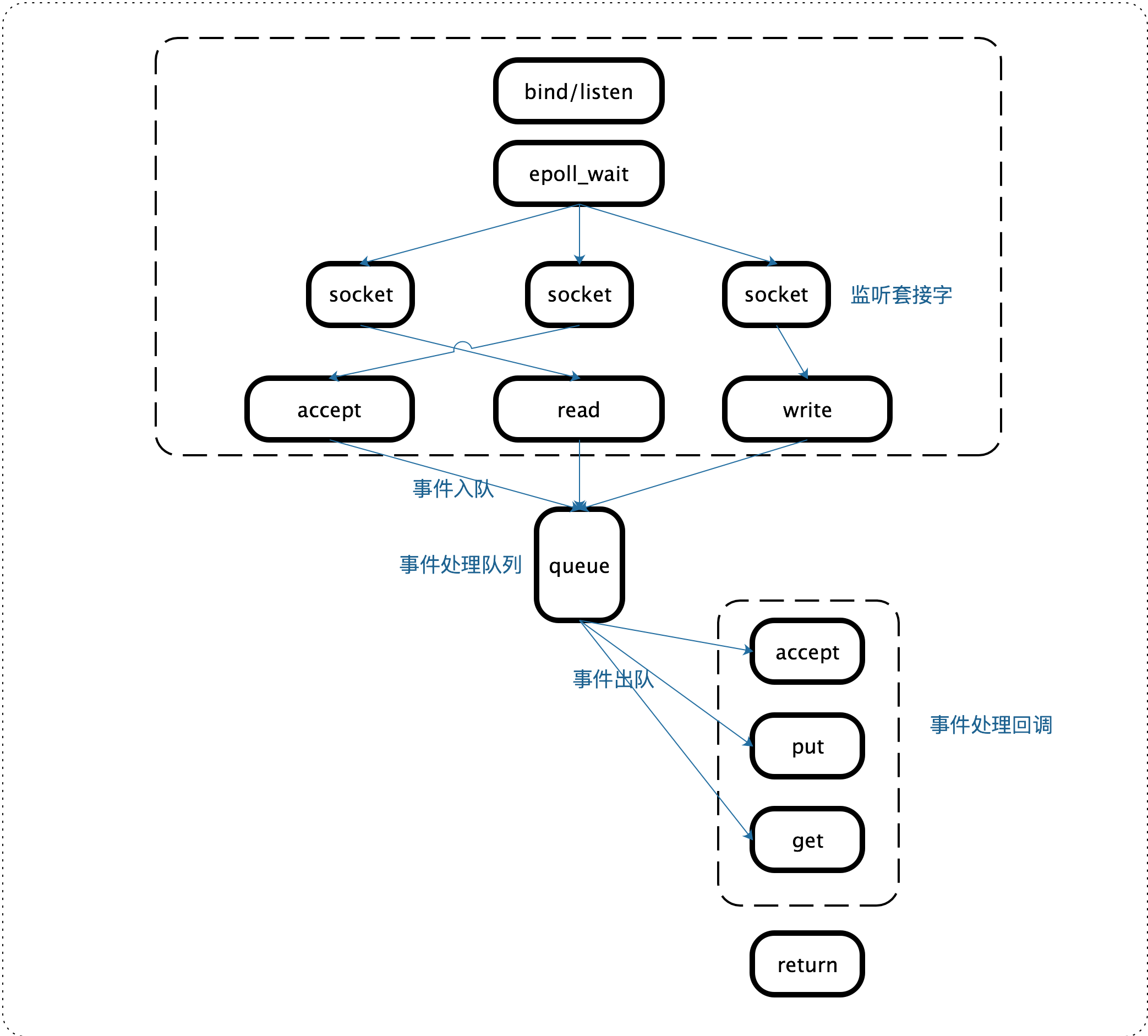
Redis的多路複用機制
Linux 中的 IO 多路複用機制是指一個執行緒處理多個 IO 流,就是我們經常聽到的 select/epoll 機制。簡單來說,在 Redis 只執行單執行緒的情況下,該機制允許核心中,同時存在多個監聽通訊端和已連線通訊端。核心會一直監聽這些通訊端上的連線請求或資料請求。一旦有請求到達,就會交給 Redis 執行緒處理,這就實現了一個 Redis 執行緒處理多個 IO 流的效果。