Kafka 概述、Kafa 系統架構、kafka使用場景
1.1 kafaka 簡介
Apache Kafka 是一個快速、可延伸的、高吞吐的、可容錯的分散式「釋出-訂閱」訊息系統,
使用 Scala 與 Java 語言編寫,能夠將訊息從一個端點傳遞到另一個端點,較之傳統的訊息中介軟體(例如 ActiveMQ、RabbitMQ),Kafka 具有高吞吐量、內建分割區、支援訊息副本和高容錯的特性,非常適合大規模訊息處理應用程式。
Kafka 官網: http://kafka.apache.org/
1.2 Kafa 系統架構
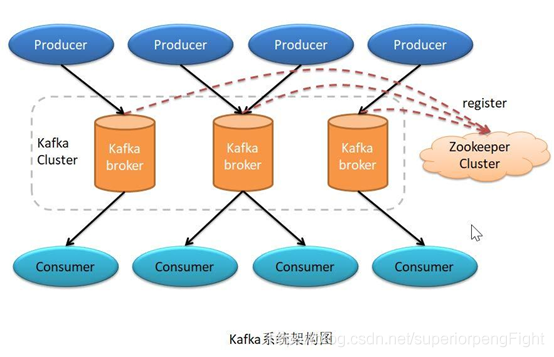
1.3 應用場景
Kafka 的應用場景很多,這裡就舉幾個最常見的場景。
1.3.1 使用者的活動追蹤
使用者在網站的不同活動訊息釋出到不同的主題中心,然後可以對這些訊息進行實時監測實時處理。當然,也可載入到 Hadoop 或離線處理資料倉儲,對使用者進行畫像。像淘寶、京東這些大型的電商平臺,使用者的所有活動都是要進行追蹤的。
1.3.2 紀錄檔聚合
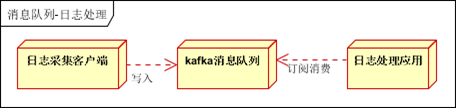
1.3.3 限流削峰
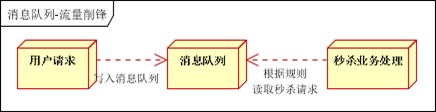
1.4 kafka 高吞吐率實現
Kafka 與其它 MQ 相比,其最大的特點就是高吞吐率。為了增加儲存能力,Kafka 將所有的訊息都寫入到了低速大容的硬碟。按理說,這將導致效能損失,但實際上,kafka 仍可保持超高的吞吐率,效能並未受到影響。其主要採用瞭如下的方式實現了高吞吐率。
順序讀寫:Kafka 將訊息寫入到了分割區 partition 中,而分割區中訊息是順序讀寫的。順序讀寫要遠快於隨機讀寫。
零拷貝:生產者、消費者對於 kafka 中訊息的操作是採用零拷貝實現的。
批次傳送:Kafka 允許使用批次訊息傳送模式。
訊息壓縮:Kafka 支援對訊息集合進行壓縮。
1.5 流處理
kafka訊息處理包含多個階段。其中原始輸入資料是從kafka主題消費的,然後彙總,豐富,或者以其他的方式處理轉化為新主題,例如,一個推薦新聞文章,文章內容可能從「articles」主題獲取;然後進一步處理內容,得到一個處理後的新內容,最後推薦給使用者。這種處理是基於單個主題的實時資料流。從0.10.0.0開始,輕量,但功能強大的流處理,就進行這樣的資料處理了