PyTorch_簡單神經網路搭建_MNIST資料集
今天用PyTorch參考《Python深度學習基於PyTorch》搭建了一個簡單的神經網路,在這裡做一下筆記。
首先附上PyTorch中文檔案連結,下面的各介面函數在這裡面基本都能查到,寶藏檔案,對於像我一樣的新手菜鳥特別友好,強推!!!
PyTorch中文檔案連結
正文開始:
這是本次搭建神經網路的結構圖
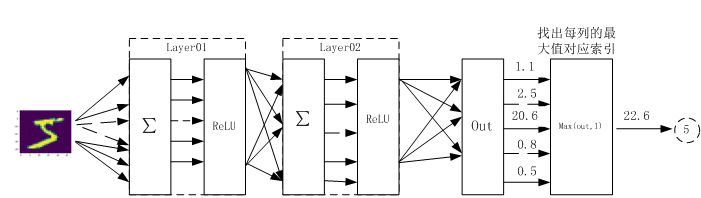
此網路包含兩個隱藏層,啟用函數都為relu函數,最後用torch.max(out,1)找出張量out最大值索引作為預測值。
下面不廢話了,直接程式碼實現
1. 先匯入必要的模組
import numpy as np
import torch
#匯入PyTorch內建的mnist資料
from torchvision.datasets import mnist
#匯入預處理模組
from torchvision import transforms
from torch.utils.data import DataLoader
#匯入神經網路工具
import torch.nn as nn
import torch.nn.functional as F
import torch.optim as optim
from torch.utils.data import DataLoader:
該介面主要用來將自定義的資料讀取介面的輸出或者PyTorch已有的資料讀取介面的輸入按照batch size封裝成Tensor。
2. 定義超引數
#定義後面要用到的超引數
train_batch_size = 64
test_batch_size = 128
#學習率與訓練次數
learning_rate = 0.01
nums_epoches = 20
#優化器的時候使用的引數
lr = 0.1
momentum = 0.5
batch_size:相當於每次匯入訓練的樣本量大小(相比較於一次匯入完,一次匯入一張,需要設定一個合適的量)一般高階演演算法要注意設定量,簡單神經網路不用太過在意。
3.下載資料並對資料進行預處理
#用compose來定意預處理常式
transform = transforms.Compose([transforms.ToTensor(),transforms.Normalize([0.5],[0.5])])
#下載資料,在工程資料夾裡新建一個data資料夾儲存下載的資料
train_dataset = mnist.MNIST('./data', train=True, transform=transform, target_transform=None, download=True)
test_dataset = mnist.MNIST('./data', train=False, transform=transform, target_transform=None, download=False)
#資料載入器,組合資料集和取樣器,並在資料集上提供單程序或多程序迭代器
train_loader = DataLoader(train_dataset, batch_size=train_batch_size, shuffle=True)
test_loader = DataLoader(test_dataset, batch_size=test_batch_size, shuffle=False)
把預處理需要用到的東西組合在Compose裡面。
transforms.ToTensor()是把一個取值範圍是[0,255]的PIL.Image或者shape為(H,W,C)的numpy.ndarray,轉換成形狀為[C,H,W],取值範圍是[0,1.0]的torch.FloadTensor。(這句話我的理解是把資料格式轉換成網路里可以使用的資料格式)
transforms.Normalize則是將灰度影象正則化。
4.視覺化資料
import matplotlib.pyplot as plt
%matplotlib inline
examples = enumerate(test_loader)
batch_idx,(example_data,example_targets) = next(examples)
fig = plt.figure()
for i in range(6):
plt.subplot(2,3,i+1)
plt.tight_layout()
plt.imshow(example_data[i][0],cmap='gray',interpolation='none')
plt.title("Ground Truth:{}".format(example_targets[i]))
plt.xticks([])
plt.yticks([])
資料視覺化這部分我沒有仔細看,直接把程式碼列出,以後如果之後再用到的時候我再單獨寫一個筆記。
下面是視覺化後的結果:

5.構建模型
class CNN(nn.Module):
def __init__(self,in_dim,hidden_1,hidden_2,out_dim):
super(CNN,self).__init__()
self.layer1 = nn.Sequential(nn.Linear(in_dim, hidden_1, bias=True),nn.BatchNorm1d(hidden_1))
self.layer2 = nn.Sequential(nn.Linear(hidden_1,hidden_2,bias=True),nn.BatchNorm1d(hidden_2))
self.layer3 = nn.Sequential(nn.Linear(hidden_2,out_dim))
def forward(self,x):
#注意 F 與 nn 下的啟用函數使用起來不一樣的
x = F.relu(self.layer1(x))
x = F.relu(self.layer2(x))
x = self.layer3(x)
return x
class torch.nn.Sequential(* args):一個時序容器,Modules 會以他們傳入的順序被新增到容器中,當然,也可以傳入一個。
**注:**我敲的時候還不知道CNN 跟簡單神經網路的區別,所以把這個類名定義為CNN了,大家在實現的時候可以定義為Net。
6.範例化網路
#範例化網路,只考慮使用CPU
model = CNN(28*28,300,100,10)
#定義損失函數和優化器
criterion = nn.CrossEntropyLoss()
#momentum:動量因子有什麼用處?
optimizer = optim.SGD(model.parameters(),lr=lr,momentum=momentum)
class torch.nn.CrossEntropyLoss(weight=None, size_average=True):此標準將LogSoftMax和NLLLoss整合到一個類中。當訓練一個多類分類器的時候,這個方法是十分有用的。
動量因子的作用後面會了我再來修改!
7.訓練模型
#開始訓練 先定義儲存損失函數和準確率的陣列
losses = []
acces = []
#測試用
eval_losses = []
eval_acces = []
for epoch in range(nums_epoches):
#每次訓練先清零
train_loss = 0
train_acc = 0
#將模型設定為訓練模式
model.train()
#動態學習率
if epoch%5 == 0:
optimizer.param_groups[0]['lr'] *= 0.1
for img,label in train_loader:
#例如 img=[64,1,28,28] 做完view()後變為[64,1*28*28]
#把圖片資料格式轉換成與網路匹配的格式
img = img.view(img.size(0),-1)
#前向傳播,將圖片資料傳入模型中
out = model(img)
loss = criterion(out,label)
#反向傳播
#optimizer.zero_grad()意思是把梯度置零,也就是把loss關於weight的導數變成0
optimizer.zero_grad()
loss.backward()
#這個方法會更新所有的引數,一旦梯度被如backward()之類的函數計算好後,我們就可以呼叫這個函數
optimizer.step()
#記錄誤差
train_loss += loss.item()
#計算分類的準確率,找到概率最大的下標
_,pred = out.max(1)
num_correct = (pred == label).sum().item()#記錄標籤正確的個數
acc = num_correct/img.shape[0]
train_acc += acc
losses.append(train_loss/len(train_loader))
acces.append(train_acc/len(train_loader))
eval_loss = 0
eval_acc = 0
model.eval()
for img,label in test_loader:
img = img.view(img.size(0),-1)
out = model(img)
loss = criterion(out,label)
optimizer.zero_grad()
loss.backward()
optimizer.step()
eval_loss += loss.item()
_,pred = out.max(1)
num_correct = (pred == label).sum().item()
acc = num_correct/img.shape[0]
eval_acc += acc
eval_losses.append(eval_loss/len(test_loader))
eval_acces.append(eval_acc/len(test_loader))
print('epoch:{},Train Loss:{:.4f},Train Acc:{:.4f},Test Loss:{:.4f},Test Acc:{:.4f}'
.format(epoch,train_loss/len(train_loader),train_acc/len(train_loader),
eval_loss/len(test_loader),eval_acc/len(test_loader)))
這是訓練後的輸出:
epoch:0,Train Loss:0.3494,Train Acc:0.9190,Test Loss:0.1510,Test Acc:0.9550
epoch:1,Train Loss:0.1290,Train Acc:0.9644,Test Loss:0.1037,Test Acc:0.9687
epoch:2,Train Loss:0.0882,Train Acc:0.9756,Test Loss:0.0848,Test Acc:0.9744
epoch:3,Train Loss:0.0676,Train Acc:0.9818,Test Loss:0.0686,Test Acc:0.9778
epoch:4,Train Loss:0.0535,Train Acc:0.9853,Test Loss:0.0569,Test Acc:0.9824
epoch:5,Train Loss:0.0385,Train Acc:0.9906,Test Loss:0.0308,Test Acc:0.9906
epoch:6,Train Loss:0.0345,Train Acc:0.9920,Test Loss:0.0306,Test Acc:0.9911
epoch:7,Train Loss:0.0321,Train Acc:0.9930,Test Loss:0.0301,Test Acc:0.9916
epoch:8,Train Loss:0.0324,Train Acc:0.9931,Test Loss:0.0293,Test Acc:0.9919
epoch:9,Train Loss:0.0304,Train Acc:0.9937,Test Loss:0.0288,Test Acc:0.9921
epoch:10,Train Loss:0.0302,Train Acc:0.9935,Test Loss:0.0282,Test Acc:0.9925
epoch:11,Train Loss:0.0294,Train Acc:0.9937,Test Loss:0.0274,Test Acc:0.9929
epoch:12,Train Loss:0.0289,Train Acc:0.9938,Test Loss:0.0274,Test Acc:0.9931
epoch:13,Train Loss:0.0294,Train Acc:0.9941,Test Loss:0.0274,Test Acc:0.9930
epoch:14,Train Loss:0.0286,Train Acc:0.9944,Test Loss:0.0280,Test Acc:0.9925
epoch:15,Train Loss:0.0289,Train Acc:0.9939,Test Loss:0.0279,Test Acc:0.9924
epoch:16,Train Loss:0.0287,Train Acc:0.9939,Test Loss:0.0277,Test Acc:0.9925
epoch:17,Train Loss:0.0290,Train Acc:0.9937,Test Loss:0.0272,Test Acc:0.9929
epoch:18,Train Loss:0.0295,Train Acc:0.9938,Test Loss:0.0277,Test Acc:0.9924
epoch:19,Train Loss:0.0285,Train Acc:0.9942,Test Loss:0.0275,Test Acc:0.9932
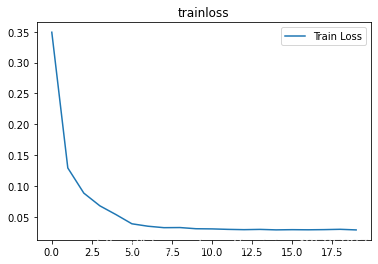
8.視覺化訓練及測試損失值
plt.title('trainloss')
plt.plot(np.arange(len(losses)),losses)
plt.legend(['Train Loss'],loc='upper right')
視覺化訓練次數於損失函數值的關係:
end
第一次在CSDN上寫筆記,希望可以堅持,慢慢成長。