java,從入土到出棺——3.邏輯結構與程式控制
java,從入土到出棺——3.邏輯結構與程式控制
寫在前面:
其實這個系列的文章更加偏向於總結向,是對以往一些知識做個系統的總結,也是為已經有一定基礎的人鋪路,提供一個系統的思考。
對新人可能是很不友好的,可能有些人是剛接觸,上來就是組合代理的,建議新人上網先做個學習,再把我這個對比記憶,說不定還能發現我的錯誤呢,說不準哦,三人行,必有我師;如果想和我討論的,可以直接留言,也可以和我私信,我會很樂意和大家來討論的。
同時也請大佬們不吝賜教!
1 邏輯結構
1.1 概述
邏輯結構分為業務邏輯結構(又稱系統邏輯結構)和資料邏輯結構:
業務邏輯結構是對整個整個業務進行細分,把一整套的產品分成若干個業務邏輯單元,分別實現自己的功能。一般在系統開發時,業務邏輯結構往往都由架構師完成。業務邏輯結構對系統的開發起到重要性的決定,可以說是產品的靈魂。
資料邏輯結構是對資料之間關係的描述,有時就把資料邏輯結構簡稱為資料結構。資料結構是計算機儲存、組織資料的方式。這裡有兩個重點,一個是儲存:畢竟我們計算機如果儲存不了資料,那也只是個一次性的物件,每次運算都去去源重新呼叫,計算的結果在沒法重複使用,就無法進行復雜的計算;另一個是組織:通過內在的邏輯將資料有序(並不只是常識認知上的有序)地存放,以便後期取用時可以更高效,對演演算法提供大力的支援。
關於資料結構的總結已經在上一篇文章:《java,從入土到出棺——2.資料結構(從容器(集合等)到底層原理)》進行了詳細的彙總,本文主要來講述另外一種邏輯結構:業務邏輯結構。
1.2 業務邏輯結構的「五常」
1.2.1 控制——排程者
根據資料採集者所傳入的引數進行不同的功能分配,實現不同功能與不同引數的排程,是整個邏輯的領導者。
1.2.2 處理——業務處理
根據不同的業務進行邏輯運算與資料處理,對排程者所傳入的資料進行加工,加工成適合資料庫可以儲存的訊息型別,是整個業務邏輯結構中的核心。
1.2.3 儲存——資料的時效儲存
儲存所有處理過後的資源,可以進行臨時性或者永久性儲存,並且在業務需要的時候可以隨時取出,是整個業務的大倉庫。
1.2.4 輸入——資料的獲取
前端對於後端的資料傳遞,並將之交給排程者進行分配
1.2.5 輸出——資料的處理反饋
對於前端的請求,經過所有的業務邏輯處理之後,給其的反饋,是整個業務處理的成果,也是使用者所需要的資料。
2 程式控制結構
程式控制結構主要是「五常」中的處理功能,前端所需要的結果卻是各種各樣的,因此,需要不同的業務處理方式來進行操作,這就需要程式控制結構來進行不同邏輯的體現。
理論和實踐證明,無論多複雜的演演算法均可通過順序、選擇、迴圈3種基本控制結構構造出來。每種結構僅有一個入口和出口。
2.1 順序結構
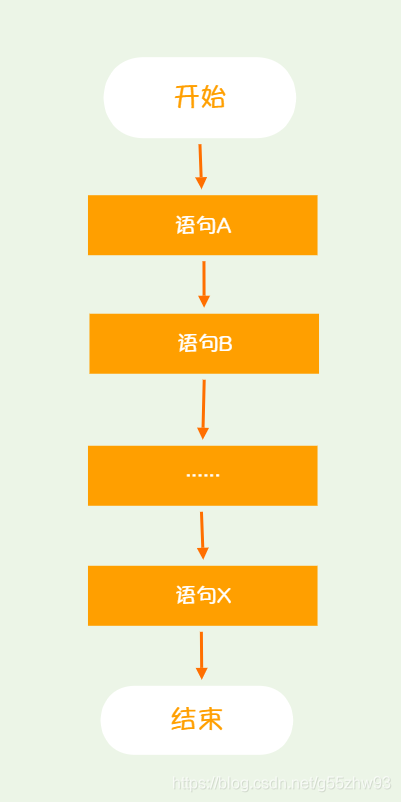
順序結構是程式中最簡單最基本的流程控制,沒有特定的語法結構,按照程式碼的先後順序,依次執行,程式中大多數的程式碼都是這樣執行的。
順序結構執行流程圖:
2.2 選擇結構
2.2.1 邏輯判斷
在數學中,一個資料x,大於3,小於6,我們可以這樣來進行表示:3 < x < 6;而在計算機語言中,需要把上面的式子先進行拆解,再進行合併表達。
拆解為:x>3 和 x<6;合併後:x>3 & x<6
&其實就是一個邏輯運運算元。我們可以這樣說,邏輯運運算元,是用來連線關係表示式的運運算元。當然,邏輯運運算元也可以直接連線布林型別的常數或者變數。
分類
| 種類 | 符號 | 作用 | 說明 |
|---|---|---|---|
| 基礎邏輯運運算元 | & | 邏輯與, 和,並且 | a&b,a和b都是true,結果為true,否則為false |
| 基礎邏輯運運算元 | | | 邏輯或 | a|b,a和b都是false,結果為false,否則為true |
| 基礎邏輯運運算元 | ^ | 邏輯互斥或 | a^b,a和b結果不同為true,相同為false |
| 基礎邏輯運運算元 | ! | 邏輯非 | !a,結果和a的結果正好相反 |
| 短路邏輯運運算元 | && | 短路與 | 作用和&相同,但是有短路效果 |
| 短路邏輯運運算元 | || | 短路或 | 作用和|相同,但是有短路效果 |
注意事項
- 邏輯與 & ,無論左邊真假,右邊都要執行;
- 短路與 &&,如果左邊為真,右邊執行;如果左邊為假,右邊不執行。
- 邏輯或 |,無論左邊真假,右邊都要執行;
- 短路或 ||,如果左邊為假,右邊執行;如果左邊為真,右邊不執行
其中最為常用的是「&&」、「||」和「!」。
2.2.2 if語句
①單路分支
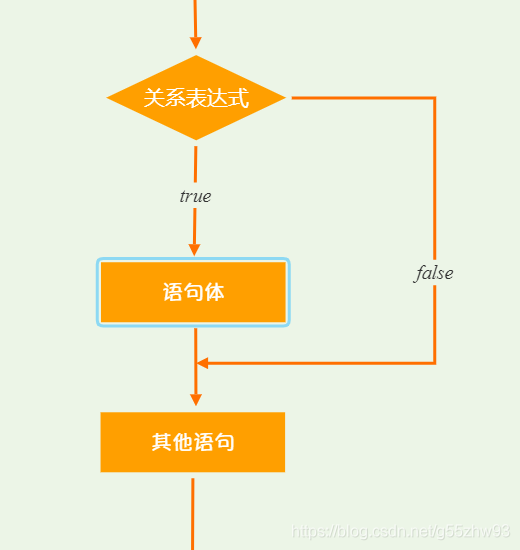
執行流程
①首先計算關係表示式的值
②如果關係表示式的值為true就執行語句體
③如果關係表示式的值為false就不執行語句體
④繼續執行後面的語句內容
格式
if (比較表示式) {
語句體;
}
執行流程圖
(太過簡單,僅總結,不做程式碼演示)
②兩路分支
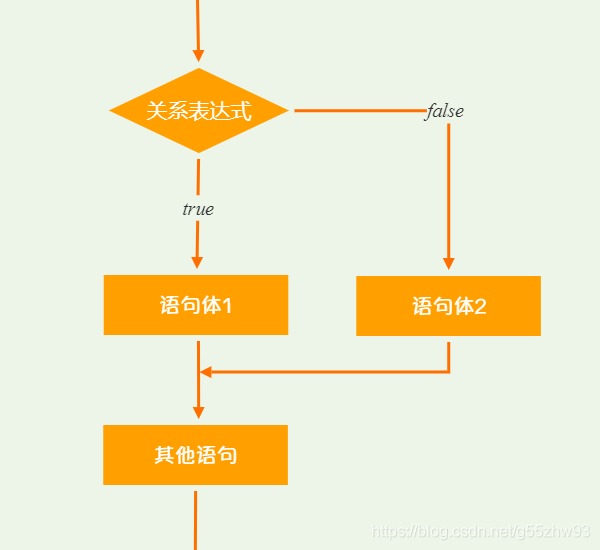
執行流程
①首先計算關係表示式的值
②如果關係表示式的值為true就執行語句體1
③如果關係表示式的值為false就執行語句體2
④繼續執行後面的語句內容
格式
if (關係表示式) {
語句體1;
} else {
語句體2;
}
執行流程圖
(太過簡單,僅總結,不做程式碼演示)
思考:兩路分支時,if與三元運算誰的效率更高效?
這個主要與三元運運算元的規則有關,三元運運算元的轉換規則:
- 若兩個運算元不可轉換,則不做轉換,返回值為Object型別
- 若兩個運算元是明確型別的表示式(比如變數),則按照正常的二進位制數位來轉換,int型別轉換為long型別,long型別轉換為float型別等。
- 若兩個運算元中有一個是數位S,另外一個是表示式,且其型別標示為T,那麼,若數位S在T的範圍內,則轉換為T型別;若S超出了T型別的範圍,則T轉換為S型別。
- 若兩個運算元都是直接量數位,則返回值型別為範圍較大者。
但是大家可以實驗一下,if與三元運算兩者所耗費時間其實是相差不多的,但是三元運算的程式碼是很美觀和簡潔的,可讀性也較強。
使用三元運運算元是先運算的,所以可以避免使用if語句時候出現的分支預判錯誤的情況發生,而 if 語句是直接賦值 ,不存在運算,所以快了一點(也僅僅是一點,其實差不太多)。
結論
- 三元運算是必須要有返回值,而if-else語句並不一定有返回值,其執行結果可能是賦值語句或者列印輸出語句;如果不涉及返回值的需求情況,三元運算是首選;其餘情況if-else更易於使用和理解;
- java三元運算字元強轉(雙目數值提升)的功能,返回值型別為兩個返回值中型別精度更高的的那個型別,所以在特殊情況下,用三元運算更方便。
③多路分支
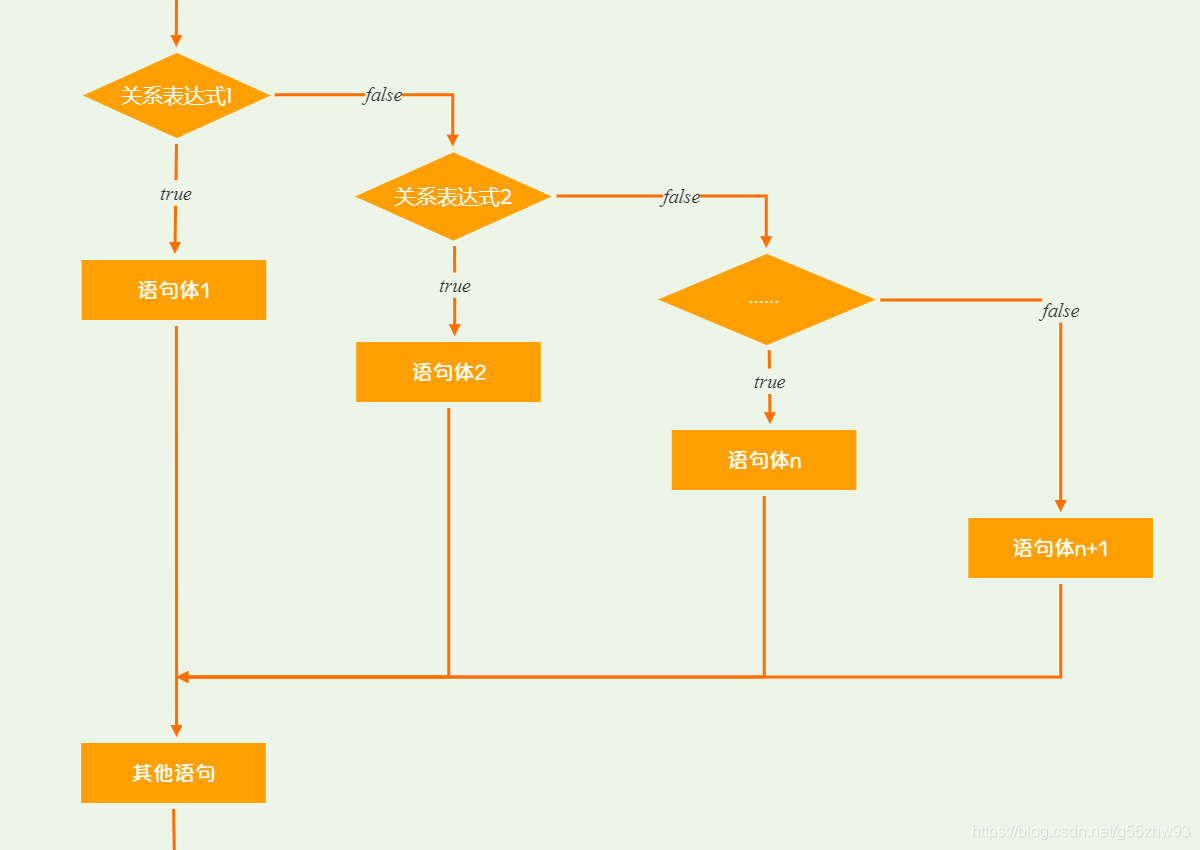
執行流程
①首先計算關係表示式1的值
②如果值為true就執行語句體1;如果值為false就計算關係表示式2的值
③如果值為true就執行語句體2;如果值為false就計算關係表示式3的值
④…
⑤如果沒有任何關係表示式為true,就執行語句體n+1
格式
if (關係表示式) {
語句體1;
} else if {
語句體2;
} else if {
······
} else {
語句體n + 1;
}
執行流程圖
(太過簡單,僅總結,不做程式碼演示)
2.2.3 switch語句
執行流程
①將要匹配的值,,與case給出的值, 逐個進行匹配(從上到下)
②如果匹配成功,則執行對應的語句體,,然後由break語句結束掉整個switch語句
③如果所有的case全部匹配失敗,將會執行default語句當中的語句體,然後由break結束switch
格式
// 將要匹配的值 : 可以是一個常數, 也可以是變數(常用的方式)
switch(將要匹配的值) {
case 值1:
語句體1;
break;
case 值2:
語句體2;
break;
...
default:
語句體n+1;
break;
}
特別注意
- case後面的值只能是常數,不能是變數;
- case後面的值不允許重複定義;
- break語句可以省略,但會出現case穿透的現象;
- default語句可以省略,但是不建議,因為需要default對範圍外的錯誤值,給出提示;
- 表示式(將要匹配的值)可以接受的型別為基本資料型別(byte short char (int) -> 只要是能夠提升為int型別的)和參照資料型別(jdk1.5之後可以接收列舉,jdk1.7之後可以接收(String字串))。
2.2.4 switch與if的選擇
switch與if各有各的應用環境,通常:switch主要用於匹配一個值,if 可以用來匹配一個值, 也可以用匹配區間範圍。
但是,當兩者都可以使用的時候,我們需要了解一下他們的優缺點,才可以根據需要去選擇不同的用法。這裡我們需要檢視他們的組合指令來分析,過程我就不在這個整理的文章的說了(如果感興趣的人比較多,後期我可以出一篇文章專門講這個),直接展示結論:switch與if的根本區別在於,switch中,每個case會生成一個地址,並且可以根據索引(switch傳入值)直接指向相應的地址。而if是順序遍歷條件,直到命中。 所以switch是用一定的記憶體空間來節約了查詢時間。
- 在多路分支時,switch比if結構要效率高;
- 當case常數分佈範圍很大但實際有效值又比較少的情況,switch的空間利用率將變得很低;
- switch只能處理分支為常數的情況:但是像 ( x > 1 (x > 1 (x>1 && x < 10 ) x < 10) x<10) 的非常數處理能力有限。所以,switch在常數選擇分支時比if效率高,但是if能應用於更多的場合,比較靈活。
程式碼寫的複雜,讓人看不懂,不NB;程式碼寫的簡潔,又能實現功能,才NB😀😀😀😀
2.3 迴圈結構
2.3.1 for
執行流程
①執行初始化語句
②執行條件判斷語句,看其結果是true還是false
如果是false,迴圈結束
如果是true,繼續執行
③執行迴圈體語句
④執行條件控制語句
⑤回到②繼續
格式
for (初始化語句;條件判斷語句;條件控制語句) {
迴圈體語句;
}
/*
* 初始化語句: 用於表示迴圈開啟時的起始狀態,簡單說就是迴圈開始的時候什麼樣
* 條件判斷語句:用於表示迴圈反覆執行的條件,簡單說就是判斷迴圈是否能一直執行下去
* 迴圈體語句: 用於表示迴圈反覆執行的內容,簡單說就是迴圈反覆執行的事情
* 條件控制語句:用於表示迴圈執行中每次變化的內容,簡單說就是控制迴圈是否能執行下去
*/
2.3.2 while
執行流程(與for相同)
①執行初始化語句
②執行條件判斷語句,看其結果是true還是false
如果是false,迴圈結束
如果是true,繼續執行
③執行迴圈體語句
④執行條件控制語句
⑤回到②繼續
格式
初始化語句;
while (條件判斷語句) {
迴圈體語句;
條件控制語句;
}
/*
* 初始化語句: 用於表示迴圈開啟時的起始狀態,簡單說就是迴圈開始的時候什麼樣
* 條件判斷語句:用於表示迴圈反覆執行的條件,簡單說就是判斷迴圈是否能一直執行下去
* 迴圈體語句: 用於表示迴圈反覆執行的內容,簡單說就是迴圈反覆執行的事情
* 條件控制語句:用於表示迴圈執行中每次變化的內容,簡單說就是控制迴圈是否能執行下去
*/
2.3.3 do-while
執行流程
① 執行初始化語句
② 執行迴圈體語句
③ 執行條件控制語句
④ 執行條件判斷語句,看其結果是true還是false
如果是false,迴圈結束
如果是true,繼續執行
⑤ 回到②繼續
格式
初始化語句;
do {
迴圈體語句;
條件控制語句;
}while(條件判斷語句);
/*
* 初始化語句: 用於表示迴圈開啟時的起始狀態,簡單說就是迴圈開始的時候什麼樣
* 條件判斷語句:用於表示迴圈反覆執行的條件,簡單說就是判斷迴圈是否能一直執行下去
* 迴圈體語句: 用於表示迴圈反覆執行的內容,簡單說就是迴圈反覆執行的事情
* 條件控制語句:用於表示迴圈執行中每次變化的內容,簡單說就是控制迴圈是否能執行下去
*/
2.3.4 三種迴圈的區別與選擇
- for迴圈和while迴圈先判斷條件是否成立,然後決定是否執行迴圈體(先判斷後執行)
- do…while迴圈先執行一次迴圈體,然後判斷條件是否成立,是否繼續執行迴圈體(先執行後判斷)
for迴圈和while的區別:
- 條件控制語句所控制的自增變數,因為歸屬for迴圈的語法結構中,在for迴圈結束後,就不能再次被存取到了
- 條件控制語句所控制的自增變數,對於while迴圈來說不歸屬其語法結構中,在while迴圈結束後,該變數還可以繼續使用
思考:for和while使用哪一個?
- 如果明確迴圈次數, 使用for迴圈
- 如果不明確迴圈次數, 使用while迴圈
PS
鑑於前兩篇寫的有點兒偏底層,所以這一篇總結一篇較為簡單且非常容易理解的,但其實重點並不是程式控制結構,而是邏輯結構,萬事程式碼為後,業務為先!!
有不瞭解的先動手自己查查,實在不明白了來問我,不是裝13,而是這樣大家自己搜尋只是並且整合知識的能力才會增強,我是真的不支援白嫖,原因就是這會影響大家的學習態度,不過來問我我是來者不拒的。😄😄
再次謝謝大家支援!!!